

Article original : The Next Step Towards Artificial General Intelligence — StarCraft II
Par Daniel Bourke
Je travaille sur mon propre master en intelligence artificielle que j'ai créé moi-même. Les créations qui proviennent de DeepMind me fascinent. Lorsqu'ils publient un mixtape avec l'un des plus grands noms du gaming afin de faire avancer la recherche en intelligence artificielle (IA), je l'écoute.
Avant d'entrer dans les détails de cette collaboration, un rapide historique de l'IA et du gaming.
AlphaGo a choqué le monde du Go en introduisant des coups qui allaient à l'encontre de centaines d'années de stratégie de jeu tout en battant plusieurs champions du monde. DeepBlue a fait de même pour les échecs en 1997, battant alors le champion du monde Gary Kasparov.
Un ordinateur a battu un champion du monde aux échecs en 1997, pourquoi a-t-il fallu attendre 2016 pour conquérir le jeu de Go ? Et pourquoi StarCraft II maintenant ?
Permettez-moi d'éclairer un peu la situation.
Après 4 coups (2 coups pour les blancs et 2 coups pour les noirs) aux échecs, le nombre de combinaisons possibles sur le plateau est de 8 902. Au total, il y a plus de combinaisons possibles sur le plateau qu'il n'y a d'électrons dans l'univers observable. Mais le nombre total de coups sensés (comme ne pas sacrifier inutilement une reine à un pion) aux échecs est un peu plus bas, de l'ordre de dix duodécillions ou 10 suivi de 40 zéros.
40,000,000,000,000,000,000,000,000,000,000,000,000,000
Pour que le superordinateur le plus rapide de 1997 calcule l'ensemble exact des coups gagnants pour chaque disposition possible du plateau d'échecs (fin de partie), il faudrait que le soleil ait englouti la Terre plusieurs fois. Évidemment, une approche par force brute comme celle-ci n'était pas réalisable.
Comment Deep Blue a-t-il fait ?
Deep Blue a utilisé un système sélectif qui évaluait l'état du plateau avant de choisir une certaine séquence de coups à explorer. Les coups qui ne maximisaient pas la probabilité de succès étaient éliminés.
Cette stratégie de sélection combinée au traitement parallèle a permis à Deep Blue de calculer 60 milliards de coups possibles en trois minutes, le temps alloué pour chaque coup d'un joueur aux échecs classiques.
Ce genre de puissance a conduit Kasparov à accuser IBM de tricherie après sa destitution.
Pourquoi a-t-il fallu presque deux autres décennies pour conquérir le Go ?
Sans règles, comparons les deux plateaux de jeu. Comme vous pouvez le voir, le plateau d'échecs semble élégant avec ses cases colorées, mais le plateau de Go a cinq fois plus de cases.

Vous vous souvenez des 8 902 coups possibles après les quatre premiers coups aux échecs ? Le Go a 46 655 640 coups possibles après les trois premiers coups. Le nombre de positions légales de Go sur un plateau 19x19 a été calculé comme suit :
208,168,199,381,979,984,699,478,633,344,862,770,286,522,453,884,530,548,425,639,456,820,927,419,612,738,015,378,525,648,451,698,519,643,907,259,916,015,628,128,546,089,888,314,427,129,715,319,317,557,736,620,397,247,064,840,935.
D'accord, des nombres vraiment grands, la puissance de calcul a augmenté depuis 1997, le Go doit être facile à conquérir.
Pas entièrement.
Le Go devient plus complexe lorsque l'on considère l'objectif d'influence incrémentielle du plateau et de capture d'une quantité indéfinie de territoire plutôt que d'essayer de capturer le roi de l'adversaire.
Même avec toute la puissance de la loi de Moore, la force brute n'était pas une option pour conquérir le Go.
Comment AlphaGo a-t-il fait ?
Une combinaison de trois techniques : recherche avancée dans l'arbre, réseaux de neurones profonds et apprentissage par renforcement.
La recherche dans l'arbre est une technique populaire utilisée en IA pour trouver le chemin optimal vers un objectif. Imaginez que vous êtes au sommet d'un sapin de Noël et que votre objectif est de trouver un ornement bleu quelques branches plus bas, cependant, vous n'avez aucune idée de la branche sur laquelle il se trouve. Pour trouver l'ornement, vous devez rechercher dans les branches de l'arbre.
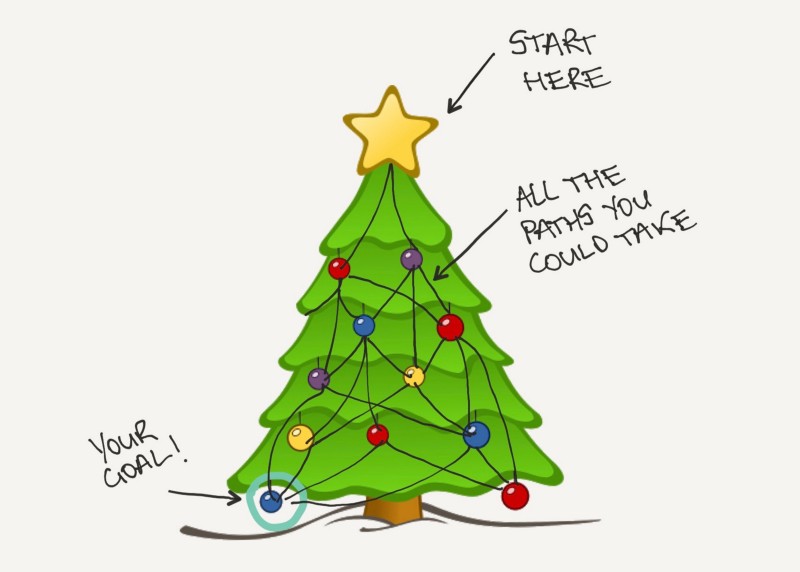
Les réseaux de neurones profonds impliquent de prendre une grande source de données d'entrée et d'effectuer plusieurs transformations mathématiques sur celle-ci. Cela résulte en une source de données de sortie qui est plus petite mais toujours dans la même distribution de probabilité que les données d'entrée.
Par exemple, disons que vous avez 1 million d'exemples de la manière dont vous avez trouvé l'ornement bleu dans le passé, ce serait votre source de données d'entrée. La sortie pourrait être un ensemble des meilleurs et des motifs les plus efficaces pour trouver l'ornement bleu.

Pour AlphaGo, remplacez le sommet du sapin de Noël par votre position actuelle sur un plateau de Go, les branches sont vos différentes options de mouvement et l'ornement bleu est le prochain mouvement optimal à faire.
Si vous avez déjà donné une friandise à votre chien pour qu'il s'assoie sur commande, vous avez pratiqué une forme d'apprentissage par renforcement. Au début, AlphaGo a été montré des millions d'exemples de la manière dont les humains jouent au Go afin qu'il puisse établir un niveau de base de jeu. Lorsque AlphaGo s'entraînait à jouer, il était récompensé pour avoir fait de bons coups.
En combinant ces techniques et beaucoup de puissance de calcul, on obtient un très bon joueur de Go, le meilleur au monde.
Le Go est conquis, qu'est-ce qui suit ?
StarCraft II est un jeu de stratégie en temps réel. Les joueurs construisent des armées pour s'affronter en espérant prendre le contrôle du champ de bataille. Mais ne vous laissez pas tromper par la simplicité de cette description.
Si vous pensiez que le Go était un cran au-dessus des échecs, StarCraft II le monte à 11.
Pourquoi StarCraft II est-il une si grande étape ?
Pour commencer, les armées peuvent contenir une variété de personnages différents et l'interface du jeu est en couleur. Les échecs et le Go n'ont que deux personnages et couleurs, noir et blanc.
Le champ de bataille n'est pas entièrement visible, des parties de la carte sont cachées à moins qu'un joueur n'ait exploré ce territoire. Imaginez essayer de planifier un coup aux échecs si vous ne pouvez voir que votre côté du plateau.
Attribution de crédit différée — certains coups ne sont pas récompensés avant plus tard dans le jeu. Les échecs et le Go ont tous deux cela, mais nowhere near the level of StarCraft II.
Les adversaires peuvent être un ou plusieurs. Les échecs et le Go se jouent tous deux un contre un. Imaginez essayer de prendre sur trois personnes à la fois aux échecs, sauf que les trois ont un ensemble de règles différent du vôtre. C'est l'équivalent de prendre sur différentes armées dans StarCraft II.
Ces facteurs font de StarCraft II une entreprise digne en effet. Mais quel est le but ?
Pourquoi créer des systèmes intelligents pour jouer à des jeux ?
Le but de DeepMind est de résoudre l'intelligence et de l'utiliser pour rendre le monde meilleur. Créer des systèmes qui peuvent apprendre à résoudre des problèmes complexes est une étape fondamentale vers l'achèvement de cet objectif.
Entrez les jeux.
Les jeux sont des états très répétables. Cela signifie que je peux jouer au même jeu que vous et que nous pouvons tous deux comprendre ce qu'il faut pour gagner et ce que signifie être un bon joueur. Ils deviennent également de plus en plus complexes à mesure que le développement de jeux s'améliore parallèlement à la technologie.
Même avec le développement de jeux de plus en plus complexe, un aspect fondamental des jeux restera toujours, la nécessité de résoudre des problèmes.
Un jeu offre une riche opportunité de résolution de problèmes répétables. Le Go était considéré comme un défi en raison des grands nombres que vous avez vus ci-dessus. Ce que ces grands nombres ne transmettent pas, c'est que tous sont des solutions à des problèmes.
Les systèmes qui apprennent à jouer à des jeux peuvent sembler une perte de temps. Mais ces systèmes ne jouent pas à des jeux, ils apprennent à résoudre des problèmes.
Créer des systèmes intelligents qui apprennent à jouer à des jeux comme le Go et StarCraft II est une étape cruciale vers la création de systèmes qui sont adaptables dans le jeu ultime, la vie réelle.
Le monde extérieur est bien plus complexe que n'importe quel jeu, mais il est toujours composé d'une série de résolution de problèmes. Chaque jour, vous vous réveillez, vous devez résoudre le problème de la manière dont vous allez aller à la salle de bain, résoudre le problème de décider quoi prendre pour le petit-déjeuner. Nous nous sommes habitués à ces choses parce que nous les avons faites des milliers de fois. Lorsque nous sommes confrontés à un problème que nous n'avons pas résolu auparavant, la difficulté est accrue.
Une fois qu'un système intelligent apprend à résoudre un problème encore et encore, il perd lentement son image d'être intelligent. C'est en train de devenir le cas pour AlphaGo.
Les humains ont la capacité de transférer leurs capacités de résolution de problèmes d'un domaine à un autre. Jusqu'à présent, les systèmes intelligents échouent dans ce domaine.
Nous savons qu'AlphaGo peut jouer au Go mieux que n'importe quel autre humain, mais peut-il apprendre à faire du vélo ? Un humain peut facilement passer de jouer au Go à faire du vélo. AlphaGo ne peut pas.
Afin d'atteindre cette capacité d'apprentissage par transfert ou ce que certains pourraient appeler l'intelligence artificielle générale (IAG), les systèmes intelligents doivent apprendre à résoudre de nouveaux problèmes et plus complexes.
Entrez l'environnement d'apprentissage de StarCraft II (SC2LE).
DeepMind, en collaboration avec Blizzard (les créateurs de StarCraft II), a publié SC2LE avec l'objectif de catalyser la recherche en IA dans un jeu non spécifiquement conçu à cet effet.
Vous pouvez imaginer SC2LE comme une salle de sport où les systèmes intelligents peuvent aller s'entraîner dans l'espoir de pouvoir battre un joueur humain professionnel.
Les outils que l'on peut trouver dans SC2LE incluent une API de Machine Learning développée par Blizzard pour permettre aux chercheurs de creuser plus profondément dans les mécaniques du jeu, un ensemble de données initial de 60 000+ replays de jeu, et PySC2, une bibliothèque Python open source créée par DeepMind pour tirer parti de l'API de couche de fonctionnalités de Blizzard.
Un article conjoint de Blizzard et DeepMind a montré des résultats surprenants. Même les meilleurs systèmes de résolution de problèmes du laboratoire DeepMind n'ont pas réussi à terminer une seule partie complète de StarCraft II. Cela inclut l'algorithme de Deep Reinforcement Learning que DeepMind a créé et qui a obtenu des scores surhumains sur 49 différents jeux Atari en 2015.
Même dans les minijeux de StarCraft II (publiés dans SC2LE), une version simplifiée du jeu complet, aucun des systèmes intelligents de l'article original n'a atteint des scores proches de ceux d'un professionnel humain jouant au même jeu. Certains des agents ont cependant obtenu des résultats comparables à ceux d'un joueur novice dans des minijeux plus simples.
Ces résultats initiaux sont passionnants. Le fait que les systèmes intelligents actuels ne parviennent pas à produire des résultats optimaux même sur une version simplifiée de StarCraft II signifie qu'il y a beaucoup de place pour s'améliorer.
La publication de SC2LE et l'article conjoint fournissent un niveau de performance de base pour les chercheurs en IA à relever à l'avenir.
Où aller ensuite ?
Avec l'accès ouvert à SC2LE, DeepMind et Blizzard espèrent que la communauté contribuera à la construction de systèmes intelligents que les humains peuvent considérer comme des adversaires dignes de StarCraft II.
Les futures mises à jour promettent la suppression des simplifications du jeu, le rendant plus proche de la manière dont un humain jouerait, et l'accès à plus de replays de jeux humains pour aider à former des agents d'apprentissage par renforcement.
J'ai toujours été un gamer. J'ai joué à RuneScape sans relâche étant enfant. Ce type de recherche sur les jeux me fascine. Cependant, construire les meilleurs joueurs de jeux au monde n'est pas ce qui m'excite le plus.
La vraie valeur sera obtenue lorsqu'un système intelligent sera capable d'apprendre à adapter les principes qu'il a appris d'un jeu à un autre, ou même dans un environnement complètement différent sans avoir à recommencer.
Si un système intelligent peut apprendre à jouer à StarCraft II, quels autres problèmes pourrait-il apprendre à résoudre ?
Pour ceux qui souhaitent en savoir plus sur le SC2LE, vous pouvez lire davantage sur la publication complète sur le blog de DeepMind et Siraj Raval a une excellente vidéo d'introduction sur la façon de commencer avec sur sa chaîne YouTube.
DeepMind relève des défis qui me donnent envie de me lever le matin. Alors que j'écris cet article, ils ont publié un article sur AlphaGo Zero, la version la plus avancée d'AlphaGo à ce jour, qui a appris à jouer au Go sans aucune intervention humaine.
Je vais déconstruire AlphaGo Zero dans les semaines à venir, assurez-vous de me suivre si vous êtes intéressé à en apprendre davantage.
Si vous souhaitez me rejoindre dans ma mission de déconstruction de l'intelligence, je publie une vidéo hebdomadaire sur YouTube documentant mon parcours à travers mon master en IA auto-créé.
Avez-vous des conseils pour moi ou pour apprendre l'IA ? J'adorerais avoir de vos nouvelles !
Dites bonjour sur : YouTube | Twitter | Email | GitHub | Patreon