


Article original : K-Means Clustering – How to Unveil Hidden Patterns in Your Data
Le K-means clustering est une technique puissante qui peut vous aider à découvrir des motifs et des regroupements cachés dans vos ensembles de données. Examinons comment cela fonctionne.
Le K-means clustering est un outil de base mais puissant en science des données. Il a changé la façon dont nous regardons et comprenons les grands ensembles de données.
Dans cet article, nous allons apprendre ce qu'est le K-means clustering, comment il fonctionne, à quoi il sert et quelques problèmes qu'il pourrait avoir. Ce guide est utile et facile à comprendre, que vous appreniez la science des données ou que vous soyez simplement intéressé par celle-ci.
Bases du Clustering
Le clustering est une méthode pour regrouper des points de données similaires. Il nous aide à trouver des motifs et des formes dans les données, ce qui est très utile dans des domaines comme le marketing et la biologie.
C'est un type d'« apprentissage non supervisé », ce qui signifie que les données forment leurs propres groupes sans que nous connaissions les réponses à l'avance.
Il existe de nombreux types de méthodes de clustering comme les méthodes hiérarchiques, basées sur la densité, basées sur la distribution et les méthodes de partitionnement. Le K-means appartient à la catégorie des « méthodes de partitionnement ».
Qu'est-ce que le K-Means Clustering ?
Le K-means clustering est une méthode pour diviser les données en groupes, ou « clusters ».
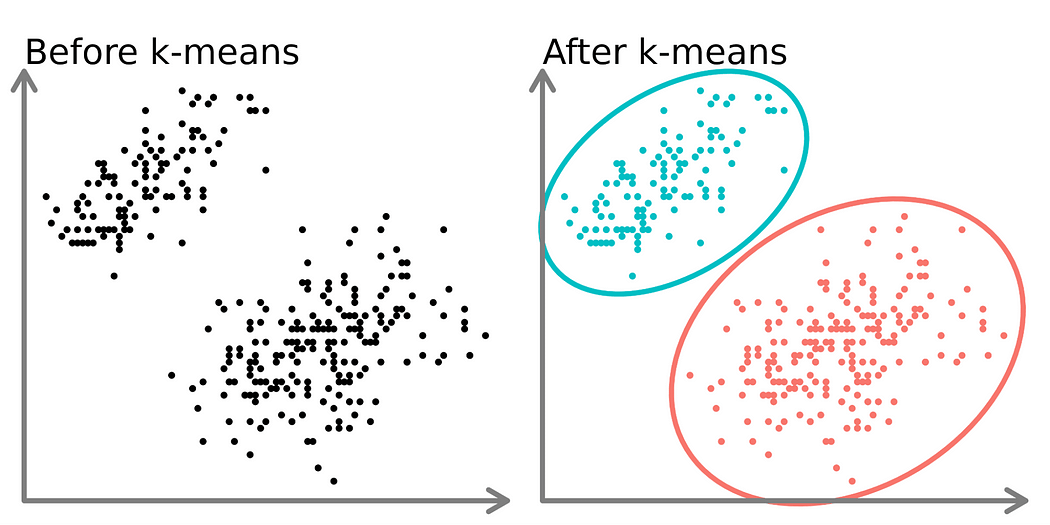 Image de graphiques représentant des points de données avant et après le K-means clustering
Image de graphiques représentant des points de données avant et après le K-means clustering
Nous décidons du nombre de groupes que nous voulons, appelé « K ». Le but est de rendre les éléments de chaque groupe aussi similaires que possible tout en rendant les groupes différents les uns des autres.
Le K-means crée généralement des groupes de taille similaire. Cela est différent du clustering hiérarchique, qui peut créer des groupes de tailles différentes.
Comment Fonctionne l'Algorithme K-means
Le K-means est populaire car c'est une méthode simple mais intelligente de clustering de données. Voici comment cela fonctionne.
Un cluster est un groupe de points de données qui sont regroupés ensemble parce qu'ils sont similaires. Vous choisirez un nombre, k, qui est le nombre de points centraux, appelés centroïdes, que vous voulez dans vos données.
Un centroïde est un point central qui se trouve au milieu d'un cluster. Chaque point de données est placé dans l'un de ces clusters. Cela est fait en minimisant la distance totale au sein de chaque cluster.
En termes simples, l'algorithme K-means choisit k centroïdes, puis attribue chaque point de données au cluster le plus proche. Le but est de garder ces points centraux, ou centroïdes, aussi proches que possible.
Ici, le terme « means » dans K-means concerne la recherche de la moyenne ou du centroïde des données.
Voici une approche étape par étape :
- Choisir le Nombre de Groupes (K) : Tout d'abord, décidez du nombre de groupes que vous voulez, appelé « K ». Vous pouvez choisir cela en fonction de ce que vous savez ou utiliser des méthodes comme la méthode du coude.
- Commencer avec les Centroïdes : Choisissez K points de vos données aléatoirement comme points de départ, appelés centroïdes.
- Grouper les Points de Données : Placez chaque point de vos données dans le groupe le plus proche, en fonction de sa proximité avec les centroïdes.
- Mettre à Jour les Centroïdes : Changez le point central de chaque groupe pour qu'il soit la moyenne de tous les points de ce groupe.
- Continuer Jusqu'à Ce Que Ce Soit Parfait : Répétez les étapes 3 et 4 jusqu'à ce que les groupes ne changent plus.
Choisir le bon nombre pour K est important. Si vous avez trop de groupes, cela pourrait devenir trop compliqué. Si vous en avez trop peu, cela pourrait être trop simple.
Si vous voulez voir comment cela fonctionne en code, voici un exemple simple :
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# Étape 1 : Générer des données aléatoires
np.random.seed(0)
x = -2 * np.random.rand(100, 2) # Générer des points aléatoires autour de (-2, -2)
x1 = 1 + 2 * np.random.rand(50, 2) # Générer des points aléatoires autour de (3, 3)
x[50:100, :] = x1 # Combiner les deux ensembles de points
# Étape 2 : Visualiser les données (non clusterisées)
plt.scatter(x[:, 0], x[:, 1], s=50, c='b')
plt.xlabel('Axe X')
plt.ylabel('Axe Y')
plt.show()
# Étape 3 : Appliquer le clustering KMeans
kmeans = KMeans(n_clusters=2) # Initialiser KMeans avec 2 clusters
kmeans.fit(x) # Ajuster le modèle aux données
# Étape 4 : Obtenir les coordonnées des centres des clusters et les étiquettes des clusters
centroids = kmeans.cluster_centers_ # Centroïdes des clusters
labels = kmeans.labels_ # Étiquettes de chaque point
# Étape 5 : Visualiser les données clusterisées
plt.scatter(x[:, 0], x[:, 1], s=50, c=labels, cmap='viridis') # Tracer les points de données avec la couleur du cluster
plt.scatter(centroids[:, 0], centroids[:, 1], s=200, c='red', marker='*') # Tracer les centroïdes
plt.xlabel('Axe X')
plt.ylabel('Axe Y')
plt.title('K-Means Clustering')
plt.show()
Voici le résultat final après le clustering.
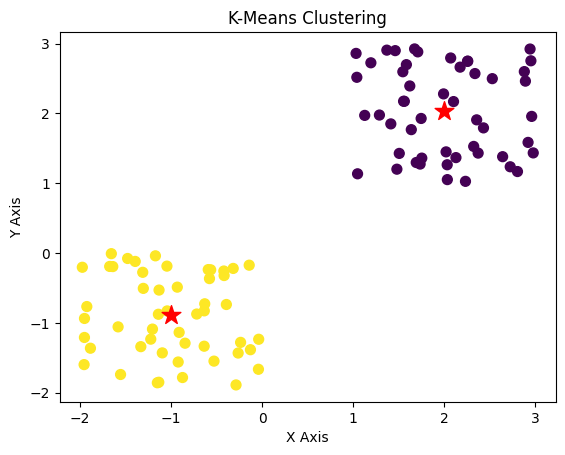 K-means clustering
K-means clustering
Où Utilise-t-on le K-Means Clustering ?
Le K-means clustering est utilisé dans de nombreux domaines. Examinons quelques-uns d'entre eux :
Segmentation de Marché
Le K-means clustering est un outil que les entreprises utilisent pour en apprendre davantage sur leurs clients. Il regroupe les clients par achats, intérêts ou localisation.
Il est utile dans le commerce de détail et l'e-commerce pour élaborer des stratégies marketing intelligentes ainsi que pour recommander des produits similaires. Un bon exemple est les suggestions d'articles connexes d'Amazon après un achat.
Cette méthode rend le service client et la promotion des produits plus efficaces. Elle aide les entreprises à adapter leurs offres aux différents besoins des clients, améliorant ainsi les ventes et la satisfaction des clients.
Compression et Traitement d'Images
L'algorithme K-means est important pour travailler avec des images numériques, surtout lorsqu'il s'agit de les réduire. Il le fait en regroupant des couleurs similaires et en les remplaçant par une seule couleur.
Lorsque le nombre de couleurs est réduit, le fichier image devient plus petit, ce qui économise de l'espace de stockage et facilite l'envoi et l'utilisation de l'image. Ce processus ne réduit pas seulement la taille du fichier image – il simplifie également l'image pour que les ordinateurs l'analysent.
Cette réduction de couleur est utile dans des domaines comme l'imagerie médicale. Les médecins utilisent souvent des scans détaillés comme les IRM pour diagnostiquer et traiter les maladies. Ces scans montrent beaucoup de petits détails, et parfois il y a trop d'informations. En utilisant K-means pour simplifier l'image, les médecins peuvent plus facilement voir les parties importantes.
Clustering de Documents pour la Récupération d'Informations
Le K-means clustering peut aider à gérer des piles d'informations en ligne. Il fonctionne en mettant des documents similaires dans des groupes. Cela est utile pour les moteurs de recherche, les bibliothèques numériques et d'autres grandes bases de données de documents.
Imaginez une bibliothèque en ligne avec des millions d'articles. K-means peut aider en triant ces articles en clusters liés. Cela peut aider les moteurs de recherche à rechercher rapidement du contenu pertinent au lieu de parcourir chaque article de la base de données.
Lorsque vous cherchez quelque chose de spécifique, K-means rend la recherche plus facile et plus rapide.
Détection d'Anomalies dans la Sécurité Réseau
Dans la sécurité réseau, le K-means clustering est comme un garde intelligent. Il aide les équipes de sécurité en repérant des motifs inhabituels dans le trafic de données qui pourraient être des signes de menaces.
Voici comment cela fonctionne : Normalement, les données dans un réseau ont un motif régulier. K-means examine toutes ces données et les regroupe en fonction de ces motifs. Mais parfois, quelque chose d'étrange apparaît – comme des pics inattendus de trafic ou des mouvements de données étranges. Ceux-ci pourraient être des indices de risques de sécurité, comme des tentatives de piratage.
K-means est excellent pour trouver rapidement ces motifs étranges. Il signale les données qui ne s'intègrent pas dans les groupes habituels. Les équipes de sécurité peuvent ensuite vérifier ces signaux pour voir s'ils sont de réels dangers. Cette détection rapide est cruciale car dans la sécurité réseau, répondre rapidement peut prévenir beaucoup de dégâts.
Recherche sur le Génome
Le K-means clustering est un outil utile dans la recherche génétique, surtout pour les études médicales. Il trie les gènes en groupes qui agissent de manière similaire et aide à mieux comprendre les gènes.
Ce regroupement est précieux dans la médecine personnalisée qui examine les gènes uniques d'une personne pour décider du meilleur traitement. K-means aide en montrant quels gènes sont similaires. De cette façon, les médecins peuvent comprendre les traitements qui fonctionneront bien pour quelqu'un en fonction de ses gènes.
Ainsi, K-means ne concerne pas seulement le regroupement des gènes. C'est une partie clé de la fabrication de médicaments qui sont juste bons pour chaque personne. Il aide les médecins à choisir des traitements qui correspondent aux détails génétiques d'une personne, ce qui est un grand pas en avant dans les soins de santé.
Conclusion
Le K-means clustering est une méthode puissante pour découvrir des motifs dans les données. En regroupant des éléments similaires, il aide à prendre des décisions basées sur les données dans divers domaines.
Bien qu'il ait ses limitations, sa facilité d'utilisation et son efficacité en font une méthode de choix pour l'analyse exploratoire des données. Que vous soyez un scientifique des données expérimenté ou un débutant curieux, se plonger dans le K-means clustering peut ouvrir de nouvelles perspectives et insights dans vos données.
Merci d'avoir lu cet article. Vous pouvez en apprendre davantage sur https://manishmshiva.com.