

Article original : I left my full-time job one year ago to ride the indie hacker road. This is what I've learned.
Par Pierre de Wulf
Mon partenaire Kevin et moi travaillons et parlons de différents projets secondaires/démarrages depuis plus de 5 ans. Il y a deux ans, nous avons lancé notre premier produit au public, mais c'est il y a un an que nous avons décidé de nous engager à temps plein sur la voie de l'indie hacker. Dans cet article, je vais expliquer notre parcours, notre parcours et comment nous l'avons fait après de nombreuses tentatives infructueuses.
Cet article ne parle pas d'un produit magique que nous avons lancé en 2 jours tout en obtenant 10k inscriptions et en atteignant 20k MRR en un mois tout en travaillant 4 heures par semaine à Hawaï. Cet article parle davantage des petites victoires et défaites que nous avons eues lors de notre première année dans le monde de l'Indie Hacker, et des choses que nous aurions aimé savoir avant de commencer.
Cet article parle de 3 produits : un pivot d'irrigation, un pivot de démarrage, et bien sûr, un peu de MRR.
(Avis de non-responsabilité : ScrapingBee a été initialement lancé sous le nom de ScrapingNinja, mais en raison de certains problèmes de droits d'auteur, nous avons dû rapidement le rebrand. Nous en parlerons dans un futur article de blog.)
Contexte
Tout a commencé lorsque nous étions tous les deux employés dans différentes startups en tant que développeurs logiciels. Nous avions beaucoup d'idées et nous aimions construire des projets secondaires pour le plaisir.
Kevin et moi faisions beaucoup de Web Scraping dans nos emplois. Kevin travaillait dans une startup Fintech appelée Fiduceo qui a été acquise par une grande banque française, et ils faisaient de l'agrégation de comptes bancaires, comme Mint.com aux États-Unis. Il dirigeait une petite équipe gérant le code et l'infrastructure de web scraping.
J'ai travaillé aux États-Unis puis je suis revenu en France pour travailler dans le plus grand fournisseur de données immobilières françaises en tant qu'ingénieur data. Une partie de mon travail consistait à trouver, rassembler, extraire et charger de nouveaux ensembles de données à partir du web.
Nous avions donc tous les deux de l'expérience avec le Web Scraping et les données à grande échelle.
Notre premier projet : ShopToList
L'un des premiers « mini-succès » que nous avons eus était Shoptolist.com, un site web/extension de navigateur B2C qui est une liste de souhaits universelle qui vous envoie des alertes s'il voit une baisse de prix. Ce n'était vraiment qu'un projet secondaire amusant qui n'était jamais censé être plus.
Cela nous a permis d'essayer beaucoup de choses différentes et de découvrir que l'acquisition est vraiment, vraiment, vraiment difficile. Nous avons rapidement atteint 1k utilisateurs en soumettant simplement notre produit sur les subreddits frugal/fashion. Nous étions très heureux à ce sujet car ce n'était qu'une expérience.
Chaque jour, nous avions un script qui scrappait chaque produit dans notre base de données pour mettre à jour son prix, et nous envoyions un email en cas de baisse de prix. Les liens dans l'email étaient des liens d'affiliation, donc nous prenions un petit pourcentage si l'utilisateur finissait par acheter le produit.
En théorie, ce modèle fonctionne très bien, mais en pratique, voici ce qui s'est passé :
- Sur 1000 emails envoyés, environ 20–30% étaient ouverts
- 2% cliquent sur les liens des produits qui étaient en vente
- Sur ce 2 %, 5–10% achètent le produit
Le pourcentage que nous avons gagné était très petit, selon la niche, il était de 0,5–5%, donc ce modèle commercial ne fonctionne qu'avec des millions d'utilisateurs.
Et c'est là que nous avons heurté un mur, nous n'avons pas réussi à créer une croissance durable. Nous avons testé beaucoup de choses, le marketing de contenu, l'affiliation, un peu de publicité payante, mais nous n'avons simplement pas réussi à créer de la croissance. Et comme ce n'était qu'un petit projet secondaire qui ne nous a pris que 2 semaines à construire, nous étions d'accord avec cela.
Pour nous, ce fut une très bonne expérience, car ce fut le premier projet que nous avons vraiment livré à de vrais utilisateurs, et nous avons beaucoup appris.
En creusant dans la base de données, nous avons remarqué que quelques utilisateurs avaient des milliers de produits enregistrés dans ShopToList. Cela semble étrange à moins qu'ils ne soient des acheteurs impulsifs fous, la majorité des utilisateurs avaient environ 20 produits enregistrés en moyenne...
Donc après une petite « investigation », nous avons découvert que ces utilisateurs étaient des propriétaires de commerce électronique qui « espionnaient » leurs concurrents...
Notre premier pivot : PricingBot
Nous avons supposé que ces personnes faisaient cela pour recevoir des alertes lorsque les produits de leurs concurrents changeaient de prix. Il existait de nombreuses solutions sur le web qui permettaient à quelqu'un de faire cela, mais ShopToList leur permettait de surveiller des milliers de produits gratuitement lorsque d'autres solutions étaient assez chères.
Nous avons fait une petite étude de marché et découvert que de nombreux outils offraient de surveiller les produits de vos concurrents, cependant, tous ces outils semblaient soit vraiment difficiles à utiliser, soit vraiment chers.
Parce que nous sentions que nous pouvions faire mieux, l'idée de PricingBot est née. J'ai quitté mon emploi et nous avons tous les deux décidé de nous engager à temps plein sur ce projet. L'ère des projets secondaires était terminée ?.
Nous avons créé une page de destination expliquant notre proposition de valeur, rien de fantaisiste mais quelque chose de clair et de suffisamment agréable pour que les gens puissent nous faire confiance. Nous avons obtenu 60 inscriptions de différents propriétaires de commerce électronique dans différentes niches.
Bien que techniquement difficile, l'extraction des données des produits de commerce électronique était quelque chose que nous savions faire grâce à ShopToList, donc la construction du MVP a été assez rapide.
Nous avons lancé notre bêta sur ProductHunt en novembre 2018 et ce fut un grand succès, suivi d'un grand crash, le classique creux de la tristesse des startups.
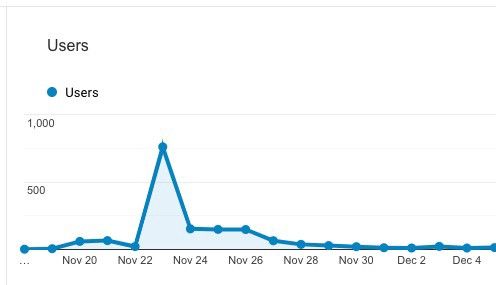 Lancement de ProductHunt
Lancement de ProductHunt
Vous deviez télécharger un fichier CSV avec votre catalogue de produits, et pour chaque produit, le faire correspondre avec une URL de produit concurrent.nC'est bien pour plusieurs dizaines de produits, mais les gens avaient souvent des centaines ou des milliers de produits dans leur boutique en ligne.
Avec ce retour, nous avons créé quelques intégrations avec des plateformes de commerce électronique populaires comme Shopify et Woocommerce pour permettre aux gens d'importer leur catalogue en un clic.
Notre activation a triplé ?, nous étions très heureux de la façon dont les choses se passaient. Une chose à noter, cependant, est qu'à ce moment-là, le produit était complètement gratuit et nous n'avons pas demandé d'argent aux gens.
À ce moment-là, voici les quelques chiffres qui nous ont rendu heureux :
- Nous avons réussi à avoir environ 200 inscriptions avec 0 $ dépensé
- 20 utilisateurs semblaient utiliser le produit et avaient leur compte entièrement configuré
Qu'est-ce qui pourrait mal se passer, n'est-ce pas ?
Nous décidons de fermer la bêta et de commencer à demander à nos utilisateurs de payer pour notre logiciel avec un modèle SaaS classique avec trois plans, 29 $/99 $/299 $ par mois en fonction du volume.
Le premier jour était magique car littéralement quelques secondes après l'envoi de l'email annonçant la fin de la bêta, nous avons obtenu notre premier client pour un plan à 29 $ ?
Nous avons également réussi à inscrire un client à 299 $ peu après, mais pour lui, nous avons dû configurer manuellement son compte et faire correspondre manuellement 1000 produits sur 10 sites web. C'était long mais nous pensions que cela en valait la peine. Nous avions tort ! Juste avant de renouveler, il a abandonné en nous disant que PricingBot était très bon mais pas assez utile pour lui. Nous étions tristes et en colère, surtout contre nous-mêmes, mais nous avons décidé d'avancer et de continuer.
Il semblait que nous étions sur la bonne voie et que nous devions simplement nous lancer à fond dans le marketing. Et c'est ce que nous avons fait. Marketing de contenu, prospection à froid, affiliation, SEO, vous l'appelez !
Mais avant de plonger dans cela, parlons à nouveau de notre activation.
Erreur #1 : de mauvaises métriques conduisent à de mauvaises conclusions, de mauvaises conclusions conduisent à de mauvaises décisions (dans la voix de Yoda)
Lorsque nous avons décidé pour la première fois de surveiller notre taux d'activation, nous avons supposé qu'un utilisateur était activé lorsqu'il faisait deux choses :
- Ajouter au moins un de ses produits, (ou lier sa boutique avec notre intégration intégrée)
- Ajouter au moins un des produits de ses concurrents
Et donc, avec cette définition, nous avions environ 10% de nos utilisateurs qui étaient « activés ». Considérant qu'à cette époque, la plupart de nos utilisateurs venaient de ProductHunt et que les chasseurs sont connus pour s'inscrire facilement à des produits qu'ils ne prévoient pas d'utiliser et juste pour le plaisir, nous étions heureux avec ces chiffres.
Mais nous avions tort.
Cette définition signifiait que quelqu'un qui possède une boutique Shopify avec 4000 produits, et qui ajoute seulement un produit concurrent, était activé. C'était stupide. Quelqu'un qui n'ajoute qu'un seul produit concurrent sur 4000 de son propre catalogue n'utilisera pas PricingBot pour faire du suivi de prix et ne paiera certainement pas pour cela. Nous l'avons appris à nos dépens.
Parce que peu après avoir eu ce premier client payant, personne n'a suivi, littéralement personne. Au début, nous n'avons pas compris. Puis ce fut évident : sur 200 inscriptions, nous avions 20 utilisateurs actifs, sur 20 utilisateurs actifs nous avions 1 client payant, donc les seules solutions étaient d'avoir plus d'inscriptions.
Ce fut une autre erreur.
Erreur #2 : Penser que notre seul problème était l'acquisition
Nous pensions que nous avions seulement besoin de plus d'utilisateurs et nous nous sommes simplement lancés à fond dans le marketing. Parce que nous ne connaissions pas très bien la communauté du e-commerce, nous avons eu quelques difficultés à commencer. Mais nous avons finalement réussi à écrire quelques contenus qui ont été partagés sur des groupes Facebook/Reddit/LinkedIn pertinents, ce qui a apporté quelques leads.
Nous avons également fait de la publicité payante et de la prospection à froid, mais cela a lamentablement échoué.
Un mois plus tard, nous devions voir l'évidence : nous n'étions pas sur la bonne voie.
Nos leads utilisaient le produit mais ne payaient pas, et même si tous les leads que nous avons apportés payaient, cela n'aurait pas été durable.
À ce moment-là, nous avons enfin décidé de mieux comprendre pourquoi les utilisateurs n'utilisaient pas plus notre produit et avec des demandes de feedback et de nombreuses informations analytiques, nous avons découvert deux choses :
- Pour la plupart de nos utilisateurs, PricingBot était un plus, mais ce n'était pas quelque chose qui valait la peine de payer
- La plupart de nos utilisateurs ne voulaient pas faire la configuration car c'était trop fastidieux, mais ils ne voulaient pas nous payer pour le faire à leur place.
La prochaine chose que nous avons faite a été de réviser tout notre processus d'onboarding et d'essayer d'automatiser autant que possible. Mais cela ne fonctionnait toujours pas.
Lorsque vous voulez, en tant que propriétaire de commerce électronique, surveiller vos concurrents, vous devez d'abord lier vos produits avec ceux de vos concurrents - et c'était la partie difficile. Cette partie seule signifiait environ 1 heure de travail pour 100 produits que vous souhaitez faire correspondre. C'était beaucoup trop de temps pour un propriétaire de commerce électronique travaillant seul avec un catalogue de 10k produits.
Peur, Incertitude et Doute
Pour vous aider à comprendre comment nous nous sentions à ce moment-là, laissez-moi simplement résumer la chronologie :
- Janvier 2018 : ? nous lançons ShopToList
- Juillet 2018 : ? je quitte mon emploi et nous décidons de construire PricingBot
- Octobre 2018 : ? Après un été chargé et 1 mois de code, nous lançons le MVP en bêta
- Janvier 2019 : ? Premier client payant
- Février-Mars 2019 : Acquisition, développement de produit
En mai 2019, nous avons atteint un mur. Rien de ce que nous avons fait n'a vraiment fonctionné et il était difficile de rester motivé. Le seul point positif était que nous avons réussi à bien nous classer sur Google, donc nous avions, chaque jour, environ 3 nouvelles inscriptions sans aucune acquisition.
Mais nous n'avons toujours pas réussi à les faire payer. Et nous n'avons toujours pas réussi à les faire configurer leur compte.
Cette période a été difficile car elle était pleine de négativité. Mon cofondateur et moi savions tous les deux que nous n'avancions pas. Bien que cela n'ait pas dégradé notre relation de travail, cela a certainement dégradé notre productivité.
Nous avions tous les deux le sentiment que, peu importe ce que nous faisions, nous n'étions pas capables de faire bouger une aiguille significative qui aurait pu stimuler notre entreprise.
Nous avons beaucoup amélioré le produit, réussi à rassembler quelques inscriptions en cours de route, mais ce n'était pas suffisant. Voici un aperçu de nos revenus.
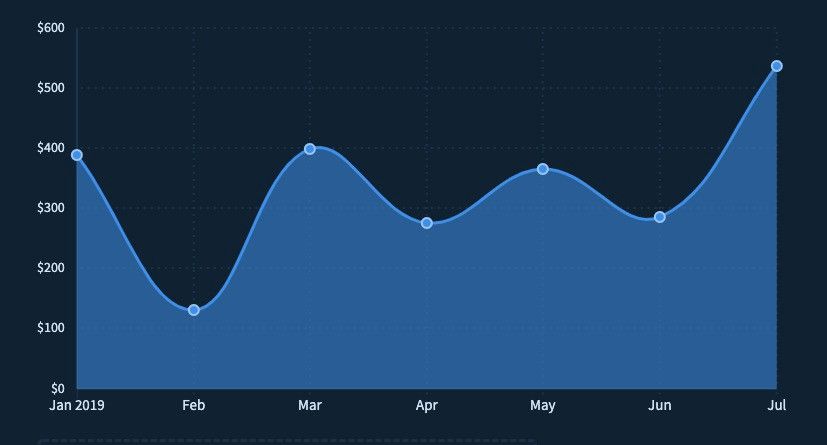
Un pivot agricole à construire, un pivot de startup à faire
Mi-juin 2019, les choses ne s'annoncent pas bien, nous n'avons que 3 mois pour lancer une entreprise réussie. Nous avons tous les deux convenu en 2018 que nous nous donnions 1 an pour lancer quelque chose qui fonctionnait, 1 an pour atteindre la « rentabilité ramen » ?.
Nous avons eu une longue discussion début juin et nous avons tous les deux convenu que nous devions faire un pas en arrière. Nous avions actuellement 3 options :
- Continuer avec PricingBot en espérant que quelque chose de magique se produise et que nous dépassions 4k MRR en 3 mois
- Quitter l'entreprise et commencer à aller chacun de notre côté
- Construire quelque chose d'autre
Le point 1 était difficile car nous étions tous les deux fatigués du produit. Tout ce que nous faisions semblait inutile et cela ne fonctionnait pas. Le point 2 devait être abordé, mais bien que ce ne soit pas un succès, nous avions le sentiment que travailler ensemble fonctionnait vraiment bien (dans le côté humain des choses). Ce serait dommage d'abandonner.
Mais nous avons choisi l'option 3, et nous sommes tous les deux très heureux du résultat de cette discussion et pleins d'énergie. Nous avions besoin d'une seule chose : choisir ce que nous construirions.
Nous avons également décidé de faire quelque chose que nous aurions dû faire plus tôt, nous avons vendu ShopToList. L'ensemble de l'affaire a été conclu en moins d'un mois grâce à 1kprojects.com et cela a apporté un peu d'argent bienvenu dans le compte bancaire de notre entreprise.
En même temps, mon beau-père, un agriculteur dans le sud de la France, a appelé parce qu'il avait besoin d'aide pour assembler un pivot d'irrigation. La vague de chaleur devait être difficile en juin (et devinez quoi, elle l'a été), et c'était un travail urgent. Nous avons tous les deux décidé que c'était une bonne opportunité pour faire une pause, réfléchir, chacun de notre côté, au futur produit, et revenir pleins d'idées et de motivation.

C'était un peu ironique car ce pivot a en quelque sorte financé notre pivot.
Avis de non-responsabilité : Si vous devez acheter un pivot d'irrigation, je vous suggère fortement de regarder les pivots Valley (PS : cet article n'a pas été sponsorisé par Valley de quelque manière que ce soit)
ScrapingBee
Deux semaines plus tard, nous nous sommes retrouvés avec une liste de produits, certains bons, certains mauvais, certains fous, certains ennuyeux, certains excitants, vous voyez l'idée. Les deux listes étaient diverses. Cependant, nous avons rapidement convenu d'une idée, car elle se démarquait vraiment des autres. Laissez-moi expliquer.
En travaillant sur Shoptolist et Pricingbot, et aussi dans nos expériences de travail précédentes, il y avait trois choses que nous devions toujours faire pour notre infrastructure de web scraping :
- Transformer les sites web en une API structurée,
- Exécuter des navigateurs headless à grande échelle,
- et gérer un pool de proxies.
Lorsque vous extrayez des données de nombreux sites web différents, vous devez toujours gérer les sites web lourds en Javascript / les applications à page unique, et vous n'avez pas vraiment d'autres choix que d'exécuter des navigateurs headless pour rendre tout ce Javascript.
Exécuter un navigateur headless comme Chrome est vraiment douloureux car la même chose qui se produit sur votre bureau (utilisation élevée de la mémoire, application à page unique mal codée consommant 100% de votre CPU) se produira sur vos serveurs. Donc ce n'est pas seulement douloureux mais très coûteux à faire soi-même lorsque l'on ne sait pas ce que l'on fait.
Lorsque l'on fait du web scraping à grande échelle, on doit souvent utiliser des proxies pour différentes raisons. Le site web que vous visitez avec votre bot peut afficher des informations différentes en fonction de votre localisation - par exemple, un prix en Euro dans la zone Euro et un prix en dollars aux États-Unis.
Gérer les proxies est également douloureux. Il y a beaucoup d'entreprises douteuses qui vendent des proxies de mauvaise qualité, donc vous devez soit exécuter vos propres proxies, soit tester des dizaines d'entreprises de proxies pour vous assurer que votre pool de proxies est toujours opérationnel.
Nous avions l'habitude de résoudre tous ces problèmes en utilisant des API qui étaient soit pas vraiment efficaces, soit extrêmement chères. Ce sont des problèmes que nous avons résolus à plusieurs reprises dans nos projets, donc nous avons pensé à les regrouper dans une API et à tirer parti de notre expérience pour créer toutes sortes d'API de web scraping.
Cette fois, nous avons décidé de faire les choses correctement et d'essayer d'éviter de faire les erreurs que nous avons commises avec PricingBot tout en créant ScrapingBee.
Erreur évitée #1 : créer un produit que vous n'utiliserez pas
L'un des plus grands problèmes que nous avons eus avec PricingBot était de trouver où nos utilisateurs potentiels se rassemblaient en ligne. Quel groupe suivaient-ils, quel blog lisaient-ils, quels influenceurs écoutaient-ils. Et la raison était simple, n'ayant jamais travaillé avec ou dans l'industrie du e-commerce sauf pour quelques missions freelance, tout le paysage nous était inconnu.
Avec ScrapingBee, nous serions nos propres utilisateurs et cela a tout changé. Je sais que ce conseil n'est pas nouveau, mais souvent ce conseil est destiné à construire un meilleur produit. Et bien sûr, être l'un de ses propres utilisateurs permet de construire un meilleur produit.
Mais pour nous, le fait de changer la donne était que d'être nos propres utilisateurs signifiait que nous savions exactement où trouver et comment atteindre des leads potentiels.
Kevin et moi avons également nos propres blogs depuis un certain temps et j'ai écrit l'année dernière un livre dédié au web scraping en Java. Cela s'est directement traduit par 20k visites mensuelles que nous pouvions utiliser pour promouvoir ScrapingBee.
Et cela a fonctionné. En environ 2 mois, nous avons atteint 150 inscriptions bêta, 4 fois le nombre de testeurs bêta que nous avions pour PricingBot.
Erreur évitée #2 : Dépenser trop d'argent
En construisant PricingBot, nous avons dépensé beaucoup d'argent en infrastructure inutile, en API et en logiciels sans atteindre le Product-Market Fit.
Nous avons réussi à récupérer notre argent grâce à la vente de ShopToList et à mes compétences agricoles avant de lancer ScrapingBee, mais cette fois, nous étions beaucoup plus prudents quant à la manière dont nous le dépensions.
Je sais que dépenser plusieurs milliers de dollars pour démarrer un projet n'est pas une grosse somme d'argent, mais nous n'étions pas à l'aise avec l'idée de dépenser plus. Nous avons donc décidé d'être prudents avec la manière dont nous le dépenserions avec ScrapingBee.
Nous avons essentiellement réduit nos coûts en ne trouvant que des offres (❤️ Crédits AWS) comme Secret qui vous offrent essentiellement 6 mois gratuits pour de nombreux SaaS ou une énorme réduction.
Nous avons décidé de faire plus avec ce que nous avions, et jusqu'à présent, nous ne le regrettons pas.
Je parlerai plus des produits et des outils que nous avons utilisés dans un futur article de blog, celui-ci est déjà assez long.
? Lancement ? et erreur évitée #3 : ne pas demander d'argent dès le premier jour
Une chose qui n'a pas bien fonctionné avec PricingBot est que pendant des mois, nous avons construit un produit qui était gratuit à utiliser. Je sais que c'est une erreur classique, mais ce n'est pas la pire partie. La pire partie est que nous savions que c'était une erreur. Au cours des 4 dernières années, nous avons lu des tonnes de livres, d'interviews, d'articles de blog sur les startups et tout le monde semble d'accord sur le fait que plus tôt vous demandez de l'argent, mieux c'est.
Mais c'était plus facile à dire qu'à faire et nous n'avons pas osé demander de l'argent en construisant PricingBot. Nous ne pensions simplement pas que quelqu'un paierait pour un produit inachevé.
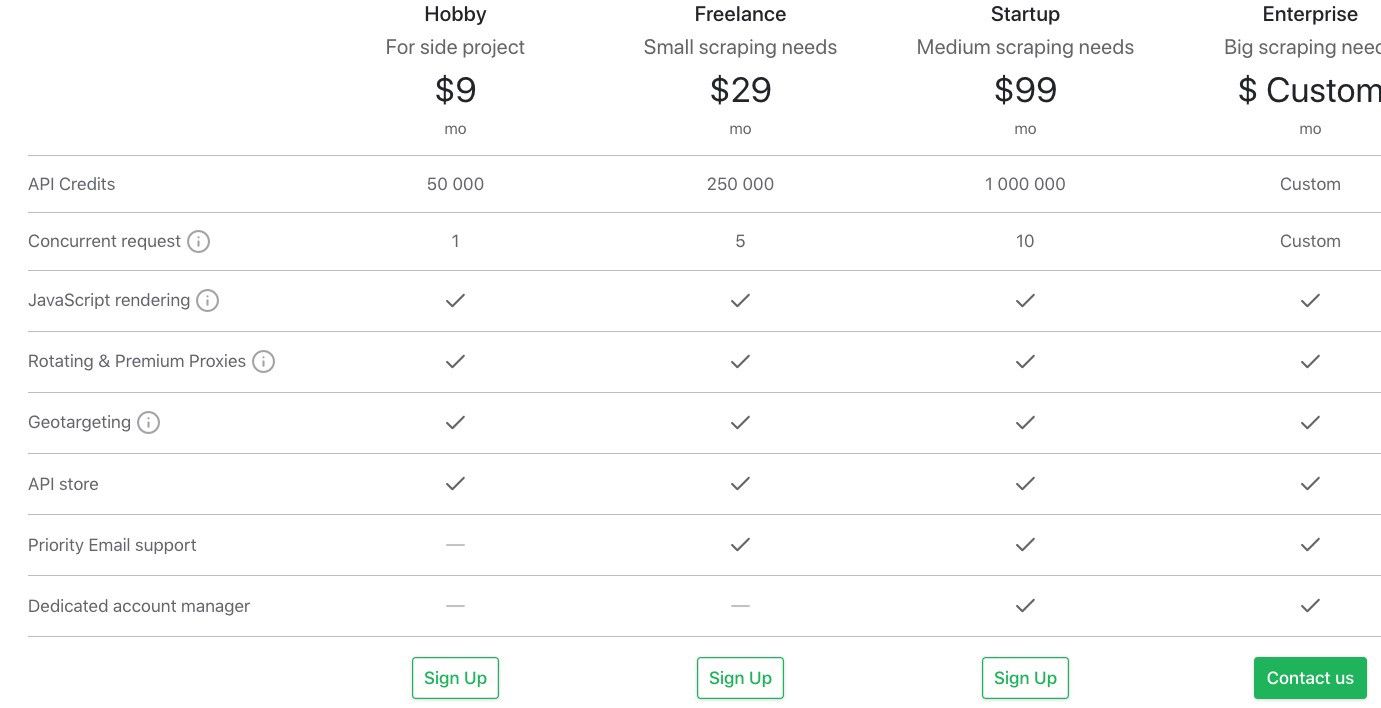
Nous l'avons fait pour ScrapingBee. La tarification pour ScrapingBee est à nouveau un classique trois plans SaaS basé sur le volume d'appels API/fonctionnalités à partir de 9 $ / 29 $ / 99 $ par mois et un plan Entreprise.
Nous avons d'abord « lancé en douceur » auprès de notre liste de diffusion et obtenu nos premiers petits clients payants. Encore une fois, nous avons eu la même expérience avec PricingBot mais cette fois c'était différent. Avec PricingBot, chaque client payant que nous avions était vraiment difficile à obtenir, nous leur avions envoyé des tonnes et des tonnes d'emails et ils ont mis longtemps à payer enfin.
Avec ScrapingBee, c'était différent. Nos deux premiers clients n'avaient jamais parlé avec nous auparavant.
Nous avons ensuite commencé à bloguer et obtenu des tonnes de leads ainsi que quelques clients payants supplémentaires, y compris un grand plan Entreprise comme vous pouvez le voir dans le graphique MRR ci-dessous.
Ensuite, tout s'est passé rapidement, Kevin et moi avons tous les deux blogué sur la programmation, créer du contenu perspicace sur le Web scraping n'est pas un problème pour nous, et nous savions comment et où le promouvoir.
Un contenu particulier que nous avons écrit, un guide de web scraping, a complètement dépassé nos attentes.
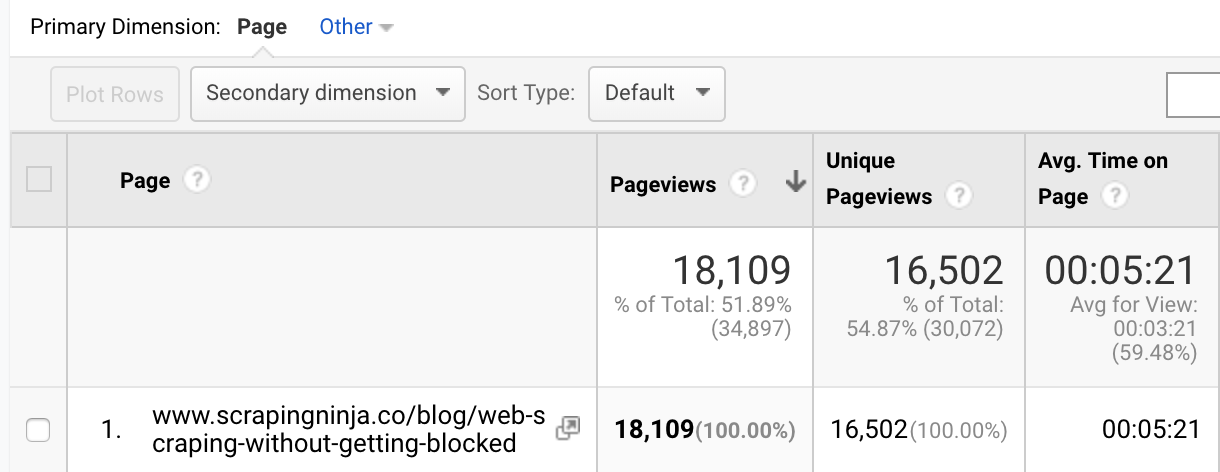
Ce post seul signifiait qu'en 2 mois nous avions 3 fois le trafic que nous avions en un an de PricingBot. Ce post n'a pas seulement apporté du trafic mais aussi des clients avec de vrais $. Il nous a également permis de signer le premier grand plan entreprise qui nous a permis d'atteindre et de dépasser 1000 $ MRR.
Le futur
Bien sûr, il est encore trop tôt pour dire si ScrapingBee sera un succès ou non.
Ces grands clients entreprises grâce au succès de notre premier article de blog pourraient n'être qu'un phénomène aberrant qui ne se reproduira pas à l'avenir. Peut-être que si. Mais une chose est certaine, les choses s'annoncent bien mieux avec ScrapingBee.
Nous avons beaucoup d'engagement de la part de nos utilisateurs et leads, le taux de conversion de l'essai à client payant étant proche de 5%.
Nous aimons aussi parler avec nos clients potentiels (❤️ Zoom) et nous avons le sentiment que ScrapingBee est vraiment un must-have pour eux, au lieu d'un « nice to have ». (petits conseils : nous offrons 10 000 crédits API gratuits pour les utilisateurs qui acceptent d'avoir une petite conversation de 15 minutes avec nous, cela nous a déjà permis d'avoir 50 conversations réelles avec de vraies personnes sur ScrapingBee)
 Message dans l'application pour inciter les utilisateurs à planifier un appel avec nous.
Message dans l'application pour inciter les utilisateurs à planifier un appel avec nous.
Dans les mois à venir, un grand défi sera de trouver des canaux d'acquisition rentables et scalables. Nous espérons que le marketing de contenu continuera à fonctionner et qu'il améliorera notre SEO pour obtenir du trafic organique. Écrire un bon contenu peut ne pas être suffisant et nous devons vraiment découvrir d'autres canaux d'acquisition.
L'autre grand défi est de prioriser les fonctionnalités dans le magasin d'API. Cela signifie comprendre ce dont les utilisateurs ont besoin et non pas implémenter aveuglément ce qu'ils veulent, et espérons, réussir à les faire payer avant que la fonctionnalité ne soit implémentée.
Nous ne savons toujours pas ce que nous voulons faire avec PricingBot, nous pensons sérieusement à le vendre mais avons un peu peur de toute la paperasse impliquée (c'était beaucoup plus facile avec ShopToList car ShopToList ne rapportait pas d'argent, donc pas de compte bancaire, de compte Stripe, etc.)
Nous avons encore beaucoup à apprendre et beaucoup à prouver avant de pouvoir dire que nous avons construit une entreprise durable et rentable, mais pour la première fois de nos vies, nous avons le sentiment que cela peut être fait, le temps nous dira si nous avons raison.
J'espère vraiment que vous avez aimé notre petite histoire et que vous avez appris quelques choses intéressantes en cours de route. Nous prévoyons de faire ce genre de posts tous les 3 mois au moins, dites-moi si vous aimeriez lire le prochain ;).