


Article original : An Introduction to High Availability Computing: Concepts and Theory
Concentrons-nous davantage sur certains des principes architecturaux plus larges de la gestion de cluster que sur une solution technologique unique.
Nous verrons quelques implémentations réelles plus tard dans le livre - et vous pouvez en apprendre beaucoup sur le fonctionnement de cela sur AWS d'Amazon dans mon livre Learn Amazon Web Services in a Month of Lunches de Manning. Mais pour l'instant, assurons-nous d'abord que nous sommes à l'aise avec les bases.
Exécuter des opérations de serveur en utilisant des clusters de machines physiques ou virtuelles consiste à améliorer à la fois la fiabilité et les performances par rapport à ce que vous pourriez attendre d'un serveur unique et puissant. Vous ajoutez de la fiabilité en évitant de suspendre toute votre infrastructure à un seul point de défaillance (c'est-à-dire un seul serveur). Et vous pouvez augmenter les performances grâce à la capacité d'ajouter très rapidement de la puissance et de la capacité de calcul en montant en charge et en étendant.
Cela peut se produire en répartissant intelligemment vos charges de travail parmi divers environnements géographiques et de demande (équilibrage de charge), en fournissant des serveurs de secours qui peuvent être rapidement mis en service en cas de défaillance d'un nœud de travail (basculement), en optimisant la manière dont votre couche de données est déployée, ou en permettant la tolérance aux pannes grâce à des architectures faiblement couplées.
Nous aborderons tout cela. Mais d'abord, voici quelques définitions de base :
Nœud : Une machine unique (physique ou virtuelle) exécutant des opérations de serveur de manière indépendante sur son propre système d'exploitation. Comme tout nœud unique peut tomber en panne, la réalisation des objectifs de disponibilité nécessite que plusieurs nœuds fonctionnent dans le cadre d'un cluster.
Cluster : Deux nœuds de serveur ou plus fonctionnant en coordination les uns avec les autres pour accomplir des tâches individuelles dans le cadre d'un service plus large, où la conscience mutuelle permet à un ou plusieurs nœuds de compenser la perte d'un autre.
Défaillance du serveur : L'incapacité d'un nœud de serveur à répondre de manière adéquate aux demandes des clients. Cela peut être dû à un crash complet, à des problèmes de connectivité ou parce qu'il a été submergé par une demande élevée.
Basculer : La manière dont un cluster tente de répondre aux besoins des clients orphelins en raison de la défaillance d'un nœud de serveur unique en lançant ou en redirigeant d'autres nœuds pour combler un vide de service.
Rétablissement : La restauration des responsabilités à un nœud de serveur alors qu'il se rétablit d'une défaillance.
Réplication : La création de copies de magasins de données critiques pour permettre un accès synchrone fiable à partir de plusieurs nœuds de serveur ou clients et pour garantir leur survie en cas de catastrophe. La réplication est également utilisée pour permettre un équilibrage de charge fiable.
Redondance : La fourniture de plusieurs nœuds de serveur physiques ou virtuels identiques, dont chacun peut adopter les clients orphelins d'un autre qui tombe en panne.
Split brain : Un état d'erreur dans lequel la communication réseau entre les nœuds ou le stockage partagé s'est somehow rompu et plusieurs nœuds individuels, chacun croyant être le seul nœud encore actif, continuent d'accéder et de mettre à jour une source de données commune. Bien que cela n'impacte pas les conceptions partagées, cela peut entraîner des erreurs client et une corruption des données au sein des clusters partagés.
Clôture : Pour éviter le split brain, le démon stonithd peut être configuré pour éteindre automatiquement un nœud défectueux ou pour imposer une clôture virtuelle entre celui-ci et les ressources de données du reste d'un cluster. Tant qu'il y a une chance que le nœud puisse encore être actif, mais ne coordonne pas correctement avec le reste du cluster, il restera derrière la clôture. Stonith signifie « Shoot the other node in the head ». Vraiment.
Quorum : Vous pouvez configurer la clôture (ou l'arrêt forcé) pour qu'elle soit imposée aux nœuds qui ont perdu le contact les uns avec les autres ou avec une ressource partagée. Le quorum est souvent défini comme plus de la moitié de tous les nœuds du cluster total. En utilisant de telles configurations définies, vous évitez d'avoir deux sous-clusters de nœuds, chacun croyant que l'autre est défectueux, tentant de se faire sortir.
Récupération après sinistre : Votre infrastructure peut difficilement être considérée comme hautement disponible si vous n'avez pas de système de sauvegarde automatisé en place ainsi qu'un plan de récupération après sinistre intégré et testé. Votre plan devra tenir compte du redéploiement de chacun des serveurs de votre cluster.
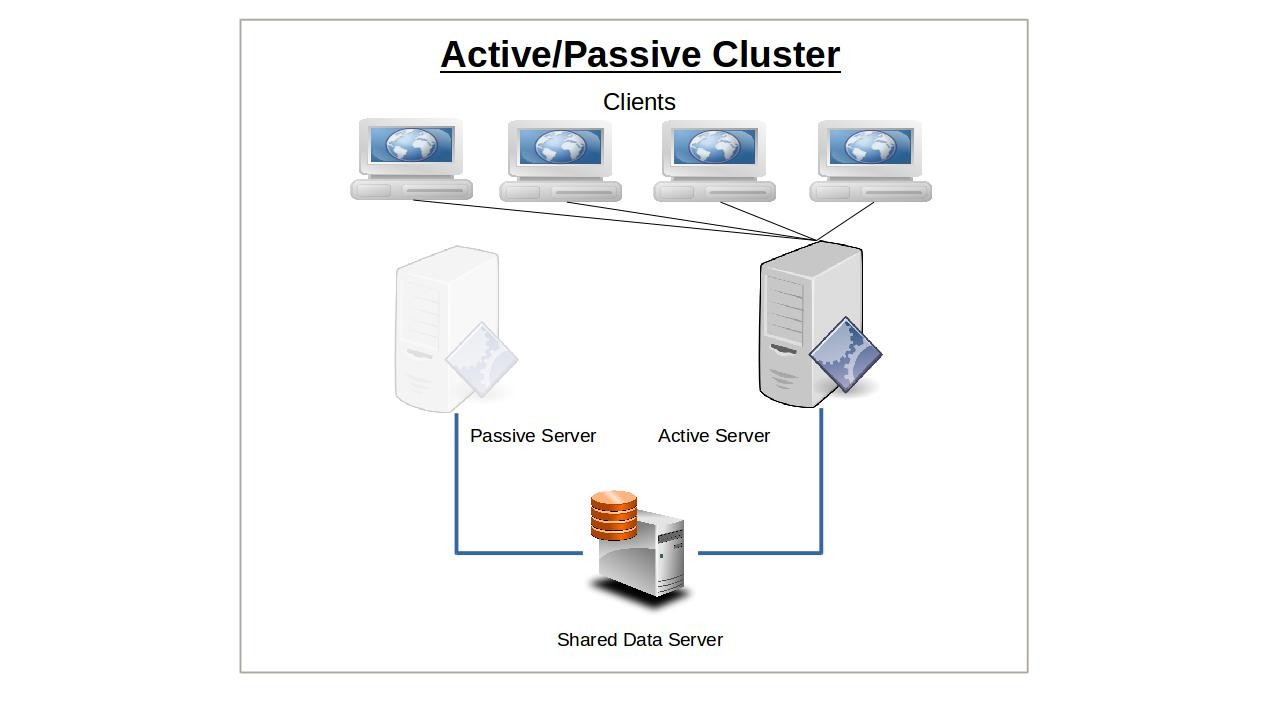
Cluster Actif/Passif
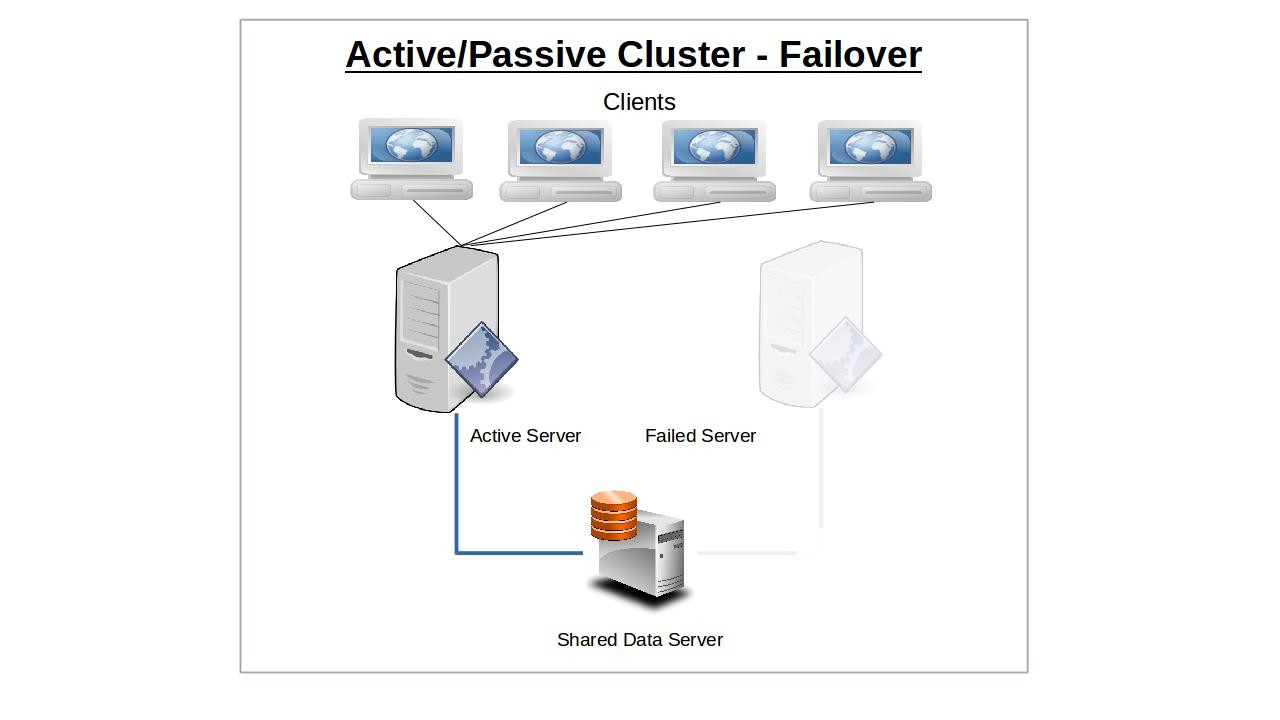
L'idée derrière le basculement de service est que la perte soudaine de tout nœud dans un cluster de service serait rapidement compensée par un autre nœud prenant sa place. Pour que cela fonctionne, l'adresse IP est automatiquement déplacée vers le nœud de secours en cas de basculement. Alternativement, des outils de routage réseau comme les équilibreurs de charge peuvent être utilisés pour rediriger le trafic loin des nœuds défaillants. La manière précise dont le basculement se produit dépend de la façon dont vous avez configuré vos nœuds.
Un seul nœud sera initialement configuré pour servir les clients et continuera à le faire seul jusqu'à ce qu'il tombe en panne d'une manière ou d'une autre. La responsabilité des clients existants et nouveaux passera alors (c'est-à-dire « basculera ») au nœud passif ou de secours qui jusqu'à présent a été gardé passivement en réserve. En appliquant le modèle à plusieurs serveurs ou composants de salle de serveur (comme les alimentations), la redondance n+1 fournit juste assez de ressources pour la demande actuelle plus une unité supplémentaire pour couvrir une défaillance.
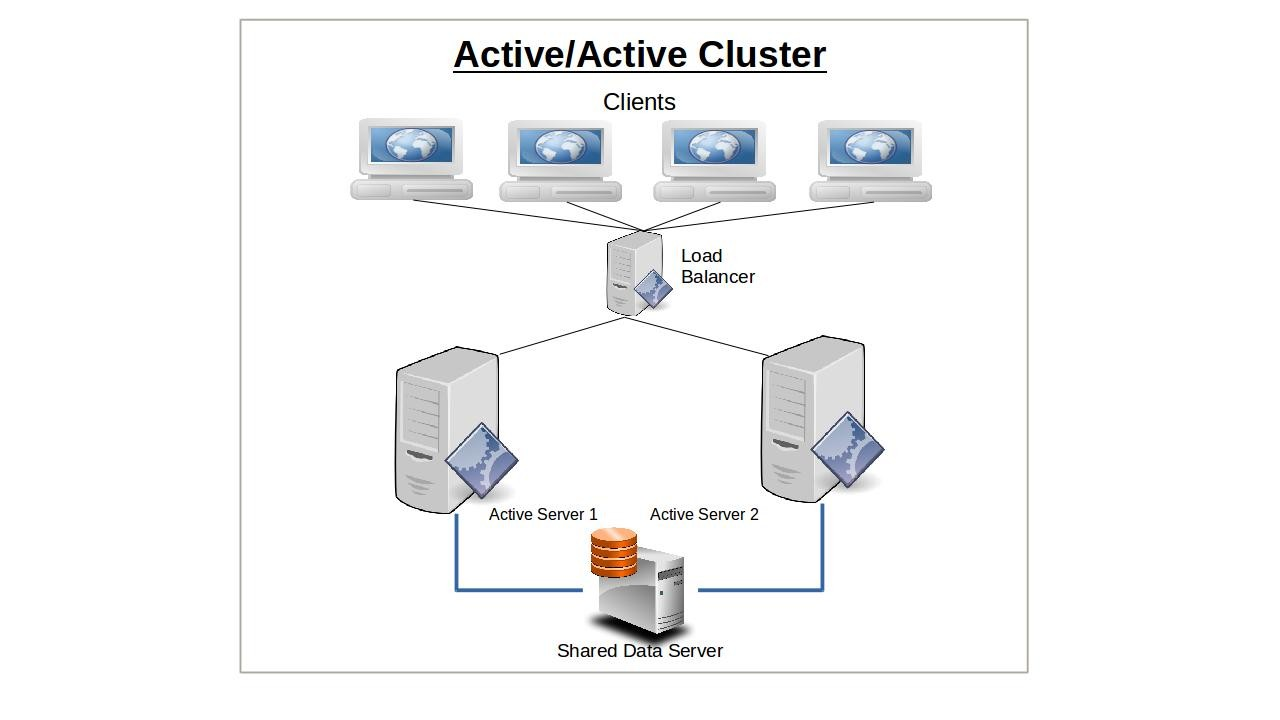
Cluster Actif/Actif
Un cluster utilisant une conception active/active aura deux nœuds ou plus configurés de manière identique servant indépendamment les clients.
Si un nœud tombe en panne, ses clients se connecteront automatiquement au deuxième nœud et, dans la mesure où les ressources le permettent, recevront un accès complet aux ressources.
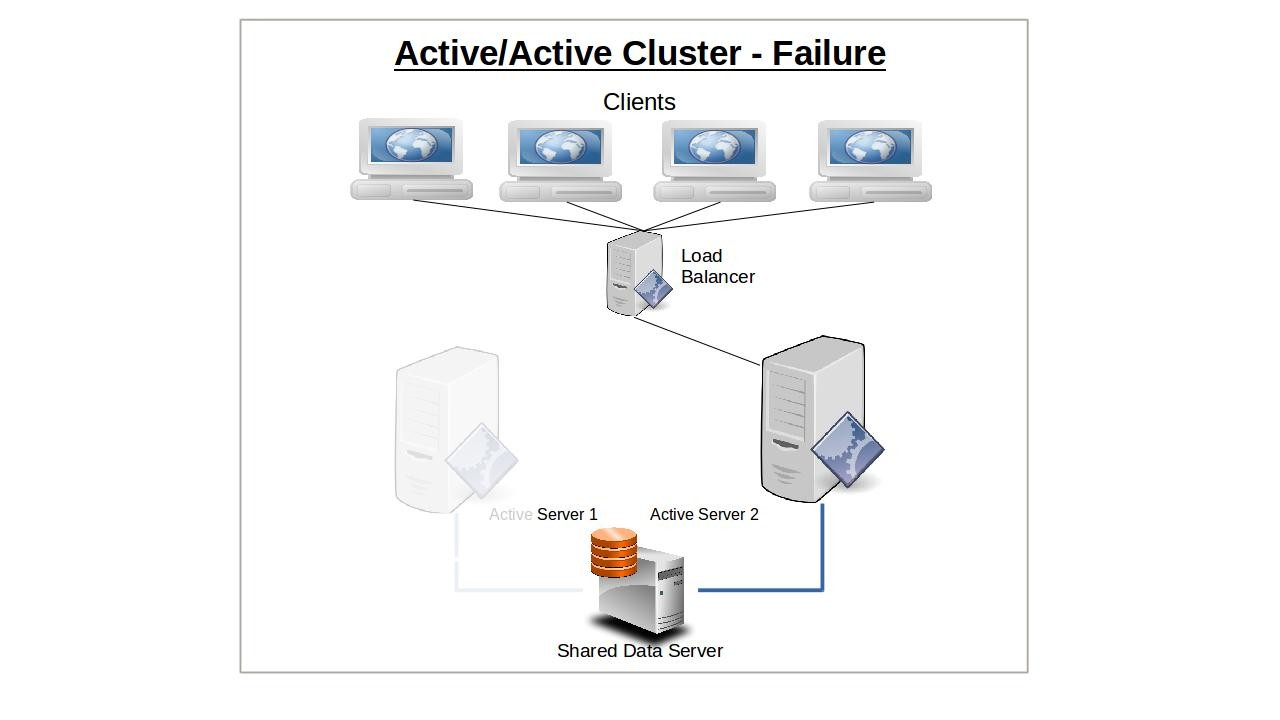
Une fois que le premier nœud a récupéré ou a été remplacé, les clients seront à nouveau répartis entre les deux nœuds de serveur.
L'avantage principal de l'exécution de clusters actifs/actifs réside dans la capacité à équilibrer efficacement une charge de travail entre les nœuds et même les réseaux. L'équilibreur de charge, qui dirige toutes les demandes des clients vers les serveurs disponibles, est configuré pour surveiller l'activité des nœuds et du réseau et utiliser un algorithme prédéterminé pour router le trafic vers les nœuds les mieux à même de le gérer. Les politiques de routage peuvent suivre un motif round-robin, où les demandes des clients sont simplement alternées entre les nœuds disponibles, ou par un poids prédéfini où un nœud est favorisé par rapport à un autre selon un certain ratio.
Avoir un nœud passif agissant comme un remplacement en attente pour son partenaire dans une configuration de cluster actif/passif offre une redondance intégrée significative. Si votre opération nécessite absolument un service ininterrompu et des transitions de basculement transparentes, alors une variation d'une architecture actif/passif devrait être votre objectif.
Clusters Partagé-Rien vs Partagé-Disque
L'un des principes directeurs de l'informatique distribuée est d'éviter que votre opération ne dépende d'un seul point de défaillance. C'est-à-dire que chaque ressource doit être soit activement répliquée (redondante), soit indépendamment remplaçable (basculement), et qu'il ne doit pas y avoir d'élément unique dont la défaillance pourrait faire tomber l'ensemble de votre service.
Maintenant, imaginez que vous exécutez quelques dizaines de nœuds qui dépendent tous d'un seul serveur de base de données pour leur fonctionnement. Même si la défaillance de n'importe quel nombre de nœuds n'affectera pas la santé continue de ceux qui restent, si la base de données tombe en panne, l'ensemble du cluster deviendrait inutile. Les nœuds dans un cluster partagé-rien, cependant, maintiendront (généralement) leurs propres bases de données de sorte que - en supposant qu'elles sont correctement synchronisées et configurées pour la sécurité continue des transactions - une défaillance externe ne les affectera pas.
Cela aura un impact plus significatif sur un cluster à charge équilibrée, car chaque nœud à charge équilibrée a un besoin constant et critique d'accès simultané aux données. Le nœud passif d'un système de basculement simple, cependant, pourrait être en mesure de survivre un certain temps sans accès.
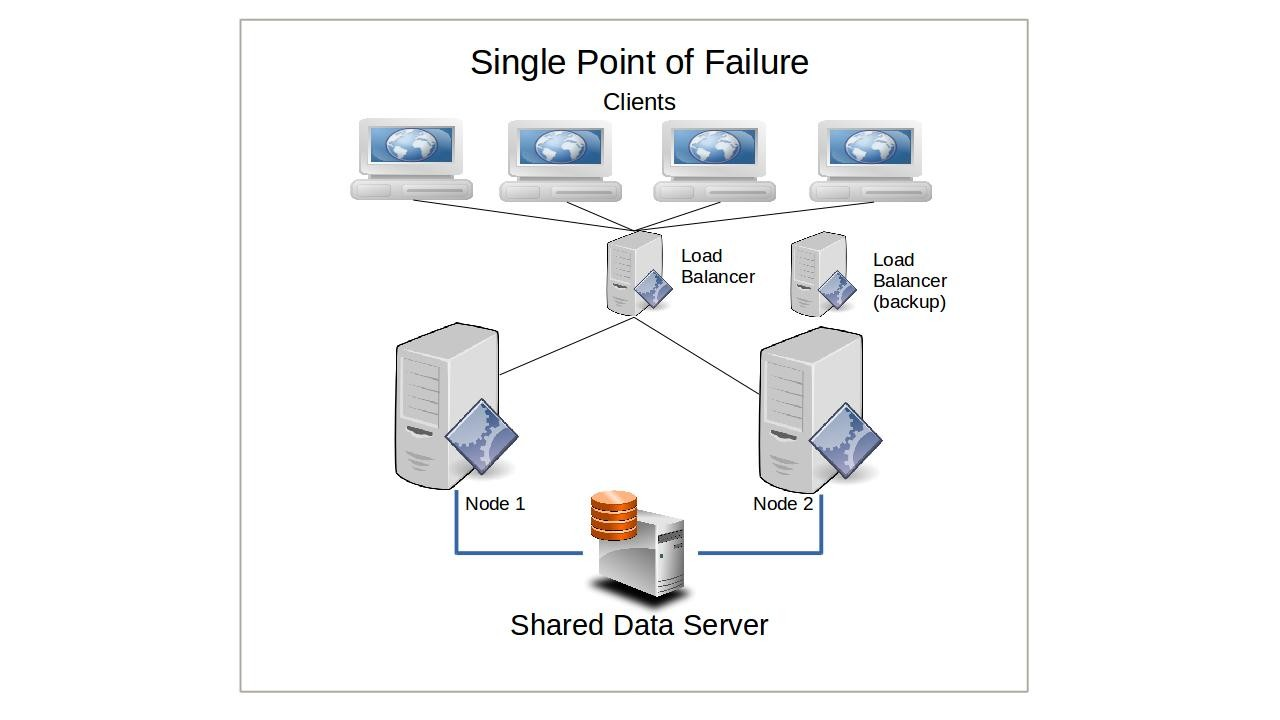
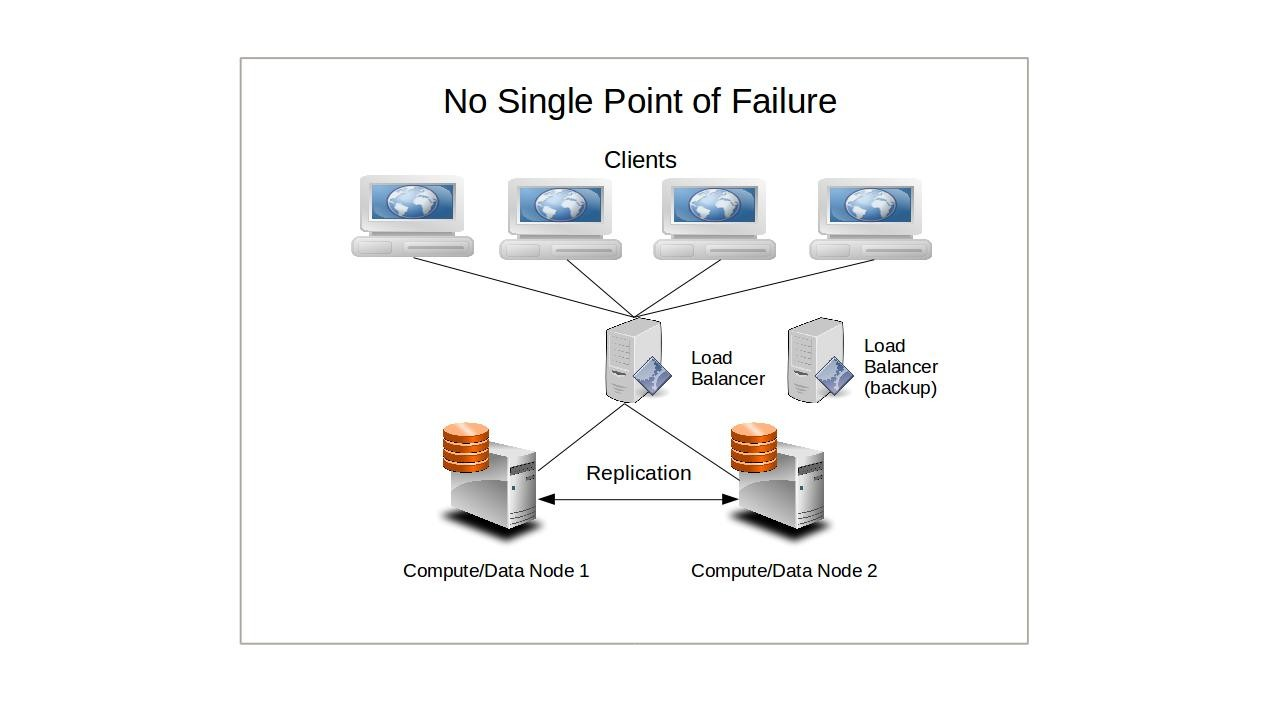
Bien qu'une telle configuration puisse ralentir la manière dont le cluster répond à certaines demandes - en partie parce que les craintes de défaillances split-brain peuvent nécessiter une clôture périodique via stonith - le compromis peut être justifié pour les déploiements critiques où la fiabilité est la considération principale.
Disponibilité
Lors de la conception de votre cluster, vous devrez avoir une assez bonne idée de la tolérance aux pannes que vous pouvez avoir. Ou, en d'autres termes, étant donné les besoins des personnes ou des machines consommant vos services, combien de temps une interruption de service peut durer avant que la foule ne se précipite à travers vos portes avec des fourches et des torches enflammées. Il est important de le savoir, car le niveau de redondance que vous intégrez dans votre conception aura un impact énorme sur les temps d'arrêt que vous rencontrerez éventuellement.
Évidemment, le système que vous construisez pour un service qui peut tomber en panne pendant un week-end sans que personne ne le remarque sera très différent d'un site de commerce électronique dont les clients s'attendent à un accès 24/7. À tout le moins, vous devriez généralement viser une disponibilité moyenne d'au moins 99 % - avec certaines opérations nécessitant des résultats réels significativement plus élevés. Une disponibilité de 99 % se traduirait par une perte de moins de quatre jours au total chaque année.
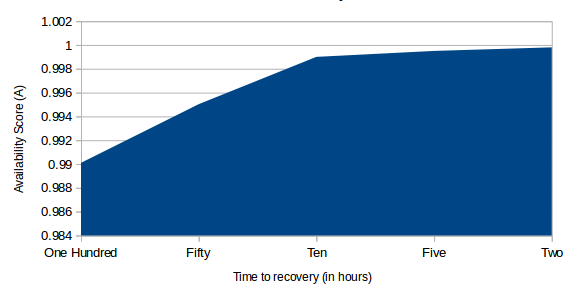
Il existe une formule relativement simple que vous pouvez utiliser pour établir une estimation utile de la Disponibilité (A). L'idée est de diviser le Temps Moyen Avant Défaillance par le Temps Moyen Avant Défaillance plus le Temps Moyen de Réparation.
A = MTBF / (MTBF + MTTR)
Plus la valeur de A se rapproche de 1, plus votre cluster sera hautement disponible. Pour obtenir une valeur réaliste pour le MTBF, vous devrez probablement passer du temps à exposer un système réel à une sérieuse punition et à le surveiller attentivement pour les défaillances logicielles, matérielles et réseau. Je suppose que vous pourriez également consulter les métriques de cycle de vie publiées par les fournisseurs de matériel ou les grands consommateurs comme Backblaze pour avoir une idée de la durée pendant laquelle un matériel fortement utilisé peut être attendu pour durer.
Le MTTR sera un produit du temps qu'il faut à votre cluster pour remplacer la fonctionnalité d'un nœud de serveur qui a échoué (un processus similaire, bien que non identique, à la récupération après sinistre - qui se concentre sur le remplacement rapide du matériel et de la connectivité défaillants). Idéalement, ce serait une valeur aussi proche de zéro seconde que possible.
 Disponibilité du serveur
Disponibilité du serveur
Le problème est que, dans le monde réel, il y a généralement trop de variables inconnues pour que cette formule soit vraiment précise, car les nœuds exécutant différentes configurations logicielles et construits avec du matériel de profils et d'âges variés auront une large gamme d'espérances de vie. Néanmoins, cela peut être un bon outil pour vous aider à identifier la conception de cluster qui convient le mieux à votre projet.
Avec ces informations, vous pouvez facilement générer une estimation de la quantité de temps d'arrêt global que votre service est susceptible de subir au cours d'une année entière.
Une considération connexe, si vous déployez vos ressources sur un fournisseur de plateforme tiers comme VMWare ou Amazon Web Services, est l'Accord de Niveau de Service (SLA) du fournisseur. Par exemple, EC2 d'Amazon garantit que leurs instances de calcul et leurs dispositifs de stockage de blocs livreront un Pourcentage de Disponibilité Mensuelle d'au moins 99,95 % - ce qui représente moins de cinq heures de temps d'arrêt par an. AWS émettra des crédits pour les mois où ils n'ont pas atteint leurs objectifs - bien que cela ne soit pas suffisamment proche pour compenser les coûts commerciaux totaux de votre temps d'arrêt. Avec ces informations, vous pouvez organiser un niveau de redondance de service qui convient à vos besoins uniques.
Naturellement, en tant que fournisseur de services à vos propres clients, vous devrez peut-être publier votre propre SLA basé sur vos estimations de MTBF et de MTTR.
Gestion des Sessions
Pour toute relation serveur-client, les données générées par les sessions HTTP avec état doivent être enregistrées de manière à ce qu'elles soient disponibles pour les interactions futures. Les architectures de cluster peuvent introduire une complexité sérieuse dans ces relations, car le serveur spécifique avec lequel un client ou un utilisateur interagit peut changer entre une étape et la suivante.
Pour illustrer, imaginez que vous êtes connecté à Amazon.com, en parcourant leurs livres sur la formation LPIC, et en ajoutant périodiquement un article à votre panier (espérons-le, plus de copies de ce livre). Au moment où vous êtes prêt à entrer vos informations de paiement et à passer à la caisse, cependant, le serveur que vous avez utilisé pour naviguer peut ne plus exister. Comment votre serveur actuel saura-t-il quels livres vous avez décidé d'acheter ?
Je ne sais pas exactement comment Amazon gère cela, mais le problème est souvent résolu par un outil de réplication de données comme memcached fonctionnant sur un nœud externe (ou des nœuds). L'objectif est de fournir un accès constant à une source de données fiable et cohérente à tout nœud qui pourrait en avoir besoin.
_Cet article est adapté de « Teach Yourself Linux Virtualization and High Availability: prepare for the LPIC-3 304 certification exam ». Consultez mes autres livres sur AWS et l'administration Linux, y compris Linux in Action et Linux in Motion — un cours hybride composé de plus de deux heures de vidéo et d'environ 40 % du texte de Linux in Action._