

Article original : Google BigQuery Beginner's Guide – How to Analyze Large Datasets
Par Ambreen Khan
Les jours où l'on stockait ses données dans un fichier CSV ou une feuille de calcul Excel sont révolus. Si vous souhaitez analyser rapidement des millions de lignes de données en quelques secondes, BigQuery est la solution.
Dans ce guide de démarrage, nous allons découvrir BigQuery et comment l'utiliser pour interroger et analyser des données.
Qu'est-ce que BigQuery ?
BigQuery est un entrepôt de données d'entreprise que de nombreuses sociétés utilisent pour une solution cloud entièrement gérée pour leurs ensembles de données massifs.
L'architecture serverless de BigQuery vous permet d'exécuter rapidement des requêtes SQL standard et d'analyser des millions de lignes de données en quelques secondes. Vous pouvez ensuite stocker vos données à la fois dans Google Cloud Storage dans des fichiers et des buckets ou dans le stockage BigQuery.
BigQuery offre également d'excellentes intégrations avec d'autres produits GCP, comme Data Flow et Data Studio, ce qui en fait un excellent choix pour les tâches d'analyse de données.
Avant de commencer :
Nous allons interroger des tables dans un ensemble de données public que Google a fourni pour essayer BigQuery en utilisant la plateforme Google Cloud. Par conséquent, ce guide suppose que :
- Vous avez un accès à la Google Cloud Platform.
- Vous avez déjà créé un projet Google Cloud.
- L'environnement sandbox de Google est opérationnel.
Comment accéder à un ensemble de données public
Un ensemble de données public est disponible pour le grand public via le Programme de jeux de données publics Google Cloud. Nous utiliserons un ensemble de données Hacker News qui contient toutes les histoires et commentaires de Hacker News depuis son lancement en 2006 jusqu'à aujourd'hui. Commençons.
Accédez à l'ensemble de données Hacker News et cliquez sur le bouton VIEW DATASET. Cela vous mènera à l'écran de connexion de la plateforme Google Cloud. Connectez-vous au compte et cela ouvrira la fenêtre de l'éditeur BigQuery avec l'ensemble de données.

Comment l'interface BigQuery est organisée
BigQuery est structuré en une hiérarchie avec 4 niveaux :
- Projets : Conteneurs de niveau supérieur qui stockent les données
- Ensembles de données : Au sein des projets, les ensembles de données vous permettent d'organiser vos données et de contenir une ou plusieurs tables de données
- Tables : Au sein des ensembles de données, les tables contiennent les données réelles.
- Jobs : tâche effectuée sur les données telles que l'exécution de requêtes, le chargement de données et l'exportation de données.
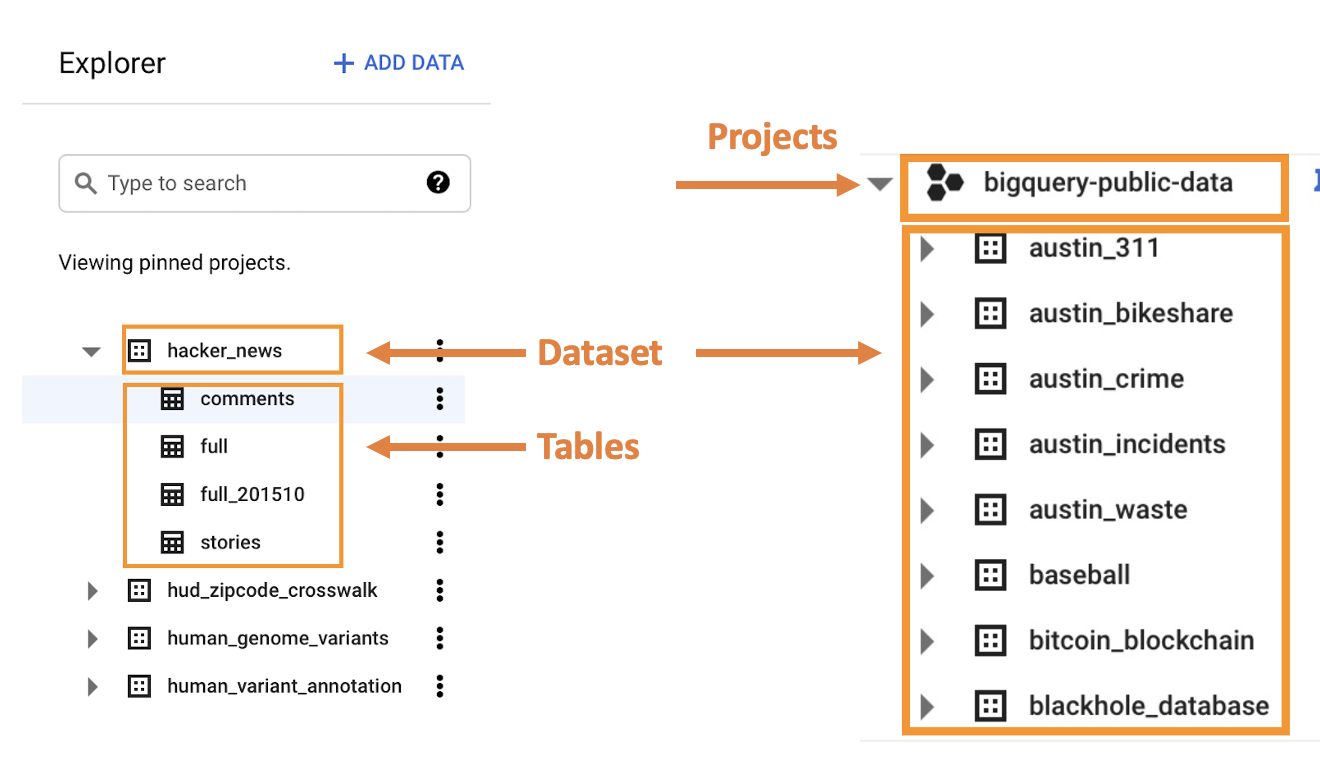
Note : Veuillez noter que lors de la manipulation de tables, vous remarquerez également que :
- Les tables sont divisées par jour, ce qui signifie que vous devrez utiliser un caractère générique, ou *, pour obtenir une plage de dates plus large.
- Il existe également une table "intraday" qui vous donnera les données des dernières 24 heures.
Comment vérifier le schéma de la table
Cliquez sur le nom de la table. Cela vous permettra de voir quelles colonnes se trouvent dans la table, ainsi que quelques boutons pour effectuer diverses opérations sur la table.
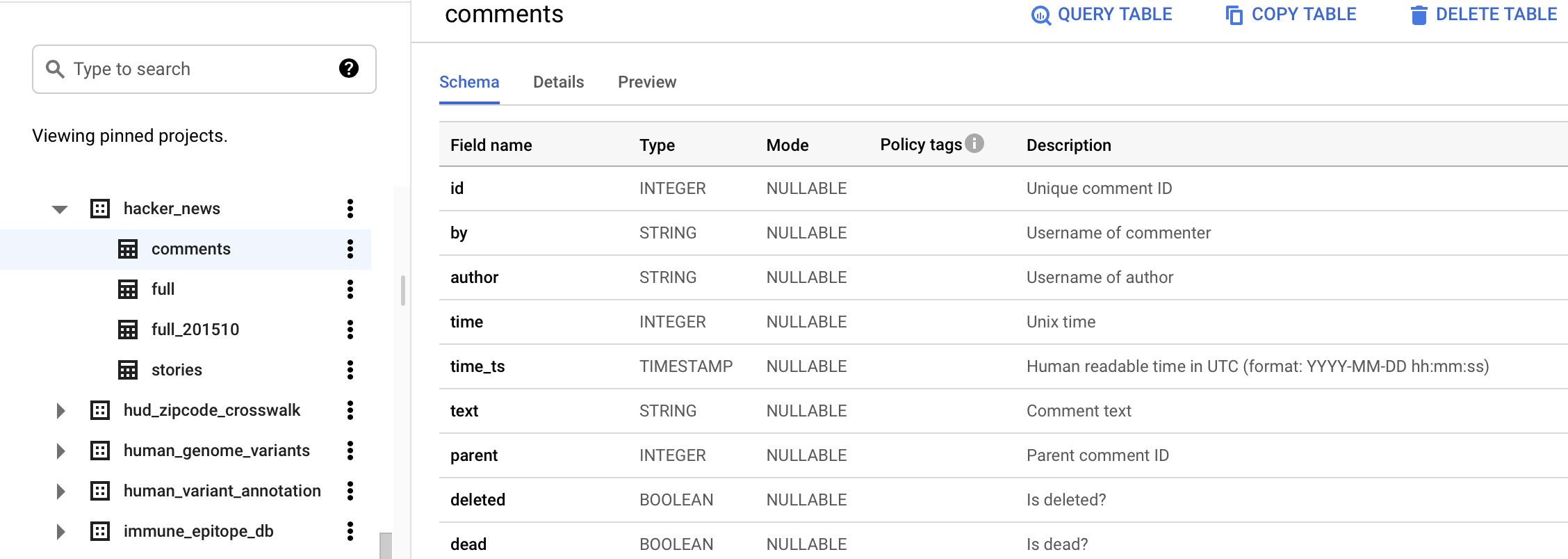
Comment prévisualiser les données
Utilisez le bouton de prévisualisation pour obtenir un échantillon de certaines lignes de la table. Ne faites pas de SELECT * dans BigQuery :

Comment interroger les Big Data
Les instructions SQL sont utilisées pour effectuer diverses tâches de base de données, telles que l'interrogation de données, la création de tables et la mise à jour de bases de données.
Requêtes de base
Les requêtes de base contiennent les composants suivants :
SELECT(obligatoire) : identifie les colonnes à inclure dans la requêteFROM(obligatoire) : la table qui contient les colonnes dans l'instruction SELECTWHERE: une condition pour filtrer les enregistrementsORDER BY: Utilisé pour trier le jeu de résultats par ordre croissant ou décroissant.GROUP BY: comment agréger les données dans le jeu de résultats
Comment composer une requête dans BigQuery
Pour notre première requête, découvrons quels sont les 5 principaux domaines partagés dans Hacker News en 2021 jusqu'à présent (requête exécutée le 9 juillet 2021).
Cliquez sur le bouton Composer une nouvelle requête. Cela ouvrira l'onglet de l'éditeur.

Écrivez votre première requête comme suit :
SELECT REGEXP_EXTRACT(url, '//([^/]*)/?') domain, COUNT(*) total
FROM `bigquery-public-data.hacker_news.full`
WHERE url!='' AND EXTRACT(YEAR FROM timestamp)=2021
GROUP BY domain ORDER BY total DESC LIMIT 5
Vous remarquerez que BigQuery débogue votre code au fur et à mesure que vous le construisez. Si la requête est valide, une coche apparaît avec la quantité de données que la requête traitera. Cela vous aide à déterminer le coût de l'exécution de la requête.
Si la requête est invalide, un point d'exclamation apparaît avec un message d'erreur.

Pour exécuter cette requête, cliquez sur le bouton Exécuter. En quelques secondes, vous devriez voir les résultats retournés par la requête :

Vous pouvez cliquer sur l'onglet JSON si vous souhaitez les résultats au format JSON. Vous trouverez également des détails intéressants sous la colonne 'Détails d'exécution'.
Comment interroger plusieurs tables à l'aide d'une table générique
Les tables génériques vous permettent d'interroger plusieurs tables à l'aide d'instructions SQL concises. Une table générique représente une union de toutes les tables qui correspondent à l'expression générique :
FROMtablename.stories_*``
Colonne pseudo _TABLE_SUFFIX
Les requêtes avec des tables génériques prennent en charge la colonne pseudo _TABLE_SUFFIX dans la clause WHERE. Pour restreindre une requête afin qu'elle ne parcourt qu'un ensemble spécifié de tables, utilisez la colonne pseudo _TABLE_SUFFIX dans une clause WHERE avec une condition qui est une expression constante.
L'utilisation de _TABLE_SUFFIX peut grandement réduire le nombre d'octets scannés, ce qui aide à réduire le coût de l'exécution de vos requêtes.
Comment obtenir des données en fournissant une plage de dates
WHERE _TABLE_SUFFIX BETWEEN
FORMAT_DATE('YYYYMMDD',DATE_SUB(CURRENT_DATE(), INTERVAL 36 MONTH))
AND
FORMAT_DATE('YYYYMMDD',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
Comment utiliser UNNEST pour aplatir la date
Pour convertir un ARRAY en un ensemble de lignes, également connu sous le nom d'"aplatissement", utilisez l'opérateur UNNEST. UNNEST prend un ARRAY et retourne une table avec une seule ligne pour chaque élément dans le ARRAY :
SELECT * FROM UNNEST (['Ambreen', 'Abdul', 'Adam', 'David']) AS names;

Comment sauvegarder et partager des requêtes
Vous pouvez sauvegarder vos requêtes pour une utilisation ultérieure. Il existe 3 types de requêtes sauvegardées :
- Privé : Les requêtes sauvegardées privées sont visibles uniquement par l'utilisateur qui les crée.
- Niveau projet : Les requêtes sauvegardées au niveau du projet sont visibles par les membres des rôles IAM BigQuery prédéfinis avec les autorisations requises.
- Public : Les requêtes sauvegardées publiques sont visibles par toute personne disposant d'un lien vers la requête.
Résumé
BigQuery est beaucoup plus sophistiqué que ce que nous avons exploré dans ce simple tutoriel. Vous pouvez également exporter les données Firebase Analytics vers BigQuery, ce qui vous permettra d'exécuter des requêtes ad hoc sophistiquées sur vos données d'analyse.
Et avec BigQuery ML, vous pouvez créer et exécuter des modèles de machine learning en utilisant des requêtes SQL standard.
Si vous êtes enthousiaste et souhaitez en savoir plus sur BigQuery, consultez les liens ci-dessous.