

Article original : GraphQL vs REST API – Which Should You Use for Back End API Development?
Par Aagam Vadecha
REST et GraphQL sont deux méthodes standard pour développer des API backend. Mais au cours de la dernière décennie, les API REST ont dominé comme choix pour le développement d'API backend. Et de nombreuses entreprises et développeurs l'utilisent activement dans leurs projets.
Mais REST a certaines limitations, et il existe une autre alternative disponible – GraphQL. GraphQL est un excellent choix pour développer des API dans de grandes bases de code.
Qu'est-ce que GraphQL ?
GraphQL a été développé par Facebook en 2012 pour un usage interne et rendu public en 2015. C'est un langage de requête pour les API et un runtime pour répondre à ces requêtes avec vos données existantes. De nombreuses entreprises l'utilisent en production.
Le site officiel présente GraphQL comme suit :
GraphQL fournit une description complète et compréhensible des données dans votre API, donne aux clients le pouvoir de demander exactement ce dont ils ont besoin et rien de plus, facilite l'évolution des API au fil du temps et permet des outils de développement puissants.
Et nous verrons comment tout cela fonctionne dans ce blog.
Problèmes avec les API REST
- Requêtes sur plusieurs endpoints
- Sur-récupération (OverFetching)
- Sous-récupération et problème de requêtes n+1
- Pas super rapide pour s'adapter aux changements des exigences du client
- Couplage élevé entre les contrôleurs backend et les vues frontend
Alors, quels sont ces problèmes et comment GraphQL les résout-il ? Eh bien, nous en apprendrons davantage en avançant. Mais d'abord, nous devons nous assurer que vous êtes à l'aise avec les concepts de base de GraphQL comme le système de types, le schéma, les requêtes, les mutations, et ainsi de suite.
Maintenant, nous allons examiner quelques exemples pour mieux comprendre les inconvénients de l'utilisation des API REST.
Sur-récupération (Overfetching)
Supposons que nous devons afficher cette Carte Utilisateur dans l'interface utilisateur.
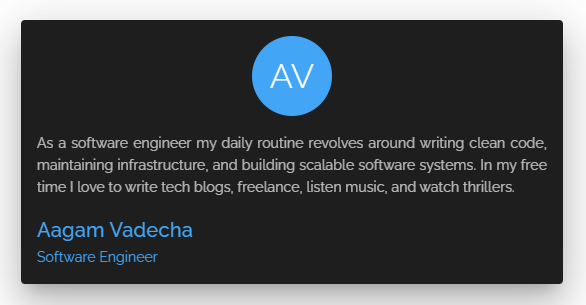
Avec REST, la requête sera un GET à /users/1.
Le problème ici est que le serveur retourne une structure de données fixe, quelque chose comme ceci :
{
"_id": "1",
"name": "Aagam Vadecha",
"username": "aagam",
"email": "testemail@gmail.com",
"currentJobTitle": "Software Engineer",
"phone": "9876543210",
"intro": "As a software engineer my daily routine revolves around writing cleancode, maintaining infrastructure, and building scalable softwaresystems. In my free time I love to write tech blogs, freelance, listenmusic, and watch thrillers.",
"website": "https://www.aagam.tech",
"gender": "MALE",
"city": "Surat",
"state": "Gujarat",
"country": "India",
"display_picture": "8ba58af0-1212-4938-8b4a-t3m9c4371952",
"phone_verified": true,
"email_verified": true,
"_created_at": "2021-03-08T14:13:41Z",
"_updated_at": "2021-03-08T14:13:41Z",
"_deleted": false
}
Le serveur retourne des données supplémentaires (en plus du Nom, de l'Intro et du Titre de l'Emploi) qui ne sont pas nécessaires côté client pour construire la carte à ce stade – mais la réponse les contient toujours. Cela s'appelle la sur-récupération.
La sur-récupération apporte des données supplémentaires dans chaque requête qui ne sont pas nécessaires par le client. Et cela augmente la taille de la charge utile et finit par avoir un effet sur le temps de réponse global de la requête.
Ce qui est pire, la situation s'aggrave lorsqu'une requête récupère des données à partir de plusieurs tables même si le client n'en a pas besoin à ce moment-là. Donc, si nous pouvons l'éviter, nous devrions définitivement le faire.
Avec GraphQL, la requête à l'intérieur du corps de la requête ressemblerait à quelque chose comme ceci :

Elle ne retournera que le name, intro et currentJobTitle comme requis par le client, donc le problème de sur-récupération est résolu.
Sous-récupération et le problème de requêtes n+1
Maintenant, supposons que cette UserList doit être affichée dans l'interface utilisateur.

Avec REST, en considérant que "experience" est une table qui a une clé étrangère de user_id, il y a trois options possibles
- Une consiste à envoyer une structure de données fixe exacte à partir de toutes les tables liées par clé étrangère vers la table des utilisateurs dans la requête GET /users, et de nombreux frameworks fournissent cette option.
{
"_id": "1",
"name": "Aagam Vadecha",
"username": "aagam",
"email": "testemail@gmail.com",
"currentJobTitle": "Software Engineer",
"phone": "9876543210",
"intro": "As a software engineer my daily routine revolves around writing cleancode, maintaining infrastructure, and building scalable softwaresystems. In my free time I love to write tech blogs, freelance, listenmusic, and watch thrillers.",
"website": "https://www.aagam.tech",
"gender": "MALE",
"city": "Surat",
"state": "Gujarat",
"country": "India",
"display_picture": "8ba58af0-1212-4938-8b4a-t3m9c4371952",
"phone_verified": true,
"email_verified": true,
"_created_at": "2021-03-08T14:13:41Z",
"_updated_at": "2021-03-08T14:13:41Z",
"_deleted": false,
"experience": [
{
"organizationName": "Bharat Tech Labs",
"jobTitle": "Software Engineer",
"totalDuration": "1 Year"
}
],
"address": [
{
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "929983874",
"geo": {
"lat": "-37,3159",
"lng": "81.1496"
}
}
]
}
Mais cette méthode crée des requêtes coûteuses, sur-récupère toutes les autres requêtes /users ainsi, et finit par ramener beaucoup de données de toutes les tables étrangères (address, experience) qui ne sont pas nécessaires dans la plupart des cas.
Par exemple, vous voulez des données utilisateur ailleurs dans le frontend où vous devez simplement afficher le site web de l'utilisateur, donc vous faites une requête GET user/1. Mais elle sur-récupère des données de la table experience ainsi que de la table address, dont vous n'avez pas besoin du tout.
- La deuxième option est que le client peut faire plusieurs allers-retours vers le serveur comme ceci :
GET /users
GET users/1/experience
Ceci est un exemple de sous-récupération, car un endpoint n'a pas assez de données. Mais plusieurs appels réseau ralentissent le processus et affectent l'expérience utilisateur. :(
De plus, dans ce cas spécifique d'une Liste, la sous-récupération s'aggrave et nous rencontrons le problème de requêtes n+1.
Vous devez faire un appel API pour obtenir tous les utilisateurs puis des appels API individuels pour chaque utilisateur pour obtenir leur expérience, quelque chose comme ceci :
GET /users
GET /users/1/experience
GET /users/2/experience
...
GET /users/n/experience.
Ceci est connu comme le problème de requêtes n+1. Pour résoudre ce problème, ce que nous faisons généralement est la troisième option, que nous allons discuter maintenant.
- Une autre option est de créer un contrôleur personnalisé sur le serveur qui retourne la structure de données qui répond aux exigences du client à ce moment-là.
C'est ce qui est fait dans la plupart des cas réels d'API REST.GET /user-experience
D'autre part, une simple requête GraphQL qui fonctionnerait sans aucun développement requis côté serveur, ressemblerait à quelque chose comme ceci :

Pas de sur-récupération, pas de sous-récupération, et pas de développement sur le serveur. Simplement fantastique !
Couplage serré entre les vues frontend et les API backend
D'accord, vous pourriez argumenter que vous pouvez simplement utiliser REST, créer le contrôleur serveur avec un effort de développement initial ponctuel, et être heureux – n'est-ce pas ?
Mais il y a un inconvénient majeur qui accompagne l'utilisation de contrôleurs personnalisés.
Nous avons formé un couplage serré avec la vue frontend et le contrôleur backend, donc globalement, cela nécessite plus d'efforts pour s'adapter aux changements du côté client. Cela nous donne également moins de flexibilité.
En tant qu'ingénieurs logiciels, nous savons à quel point les exigences changent souvent. Le contrôleur personnalisé à ce stade GET /user-experience retourne des données en fonction de ce que la vue frontend veut afficher (nom de l'utilisateur et rôle actuel). Donc, lorsqu'une exigence change, nous devons refactoriser à la fois le client et le serveur.
Par exemple, après une période considérable, les exigences changent et au lieu des données d'expérience, l'interface utilisateur doit afficher les informations de la dernière transaction d'un utilisateur.
Avec REST, nous devrions apporter les modifications pertinentes dans la couche frontend. De plus, afin de retourner les données de transaction au lieu des données d'expérience du backend, le contrôleur personnalisé devra soit être refactorisé (données envoyées, route, etc.) soit nous devrons créer un nouveau contrôleur au cas où nous souhaiterions préserver l'ancien.
Donc, en gros, un changement dans les exigences du client influence grandement ce qui doit être retourné par le serveur – ce qui signifie que nous avons un couplage serré entre le frontend et le backend !
Il serait préférable de ne pas avoir à apporter de modifications sur le serveur mais seulement sur le frontend.
Avec GraphQL, nous n'aurons pas besoin d'apporter de modifications côté serveur. Le changement dans la requête frontend serait aussi minimal que ceci :

Pas de refactorisation, de déploiement, de test de l'API serveur – cela signifie du temps et des efforts économisés !
Conclusion
Comme je l'espère, vous pouvez le voir dans cet article, GraphQL a un certain nombre d'avantages par rapport à REST dans de nombreux domaines.
Cela peut prendre plus de temps pour configurer GraphQL initialement, mais il existe de nombreux échafaudages qui facilitent ce travail. Et même si cela prend plus de temps au début, cela vous donne des avantages à long terme et en vaut totalement la peine.
Merci d'avoir lu!
J'espère que vous avez aimé cet article et qu'il vous a donné plus d'informations pour vous aider à faire votre prochain choix. Si vous avez besoin d'aide, n'hésitez pas à me contacter sur LinkedIn.