

![Gitting Things Done – Un guide visuel et pratique de Git [Livre complet]](https://www.freecodecamp.org/news/content/images/size/w2000/2023/12/Gitting-Things-Done-Cover-with-Photo.png)
Article original : Gitting Things Done – A Visual and Practical Guide to Git [Full Book]
Introduction
Git est génial.
La plupart des développeurs de logiciels utilisent Git au quotidien. Mais combien comprennent vraiment Git ? Avez-vous l'impression de savoir ce qui se passe sous le capot lorsque vous utilisez Git pour effectuer diverses tâches ?
Par exemple, que se passe-t-il lorsque vous utilisez git commit ? Qu'est-ce qui est stocké entre les commits ? Est-ce juste une différence (diff) entre le commit actuel et le précédent ? Si oui, comment la différence est-elle encodée ? Ou bien un instantané complet du dépôt est-il stocké à chaque fois ?
La plupart des gens qui utilisent Git ne connaissent pas les réponses aux questions posées ci-dessus. Mais est-ce vraiment important ? Avez-vous vraiment besoin de savoir toutes ces choses ?
Je dirais que oui, c'est important. En tant que professionnels, nous devrions nous efforcer de comprendre les outils que nous utilisons, surtout si nous les utilisons tout le temps, comme Git.
Plus précisément, j'ai constaté que comprendre comment Git fonctionne réellement est utile dans de nombreux scénarios — que ce soit pour résoudre des conflits de fusion (merge conflicts), chercher à effectuer un rebasage (rebase) intéressant, ou même simplement lorsque quelque chose ne va pas tout à fait bien.
J'ai reçu tant de fois des questions sur Git de la part d'ingénieurs logiciels expérimentés et hautement qualifiés. J'ai vu des développeurs merveilleux réagir avec peur lorsque quelque chose se passait dans leur historique de commit, et qu'ils ne savaient tout simplement pas quoi faire. Il ne doit pas nécessairement en être ainsi.
En lisant ce livre, vous acquerrez une nouvelle perspective sur Git. Vous vous sentirez confiant lorsque vous travaillerez avec Git, et vous comprendrez les mécanismes sous-jacents de Git, du moins ceux qu'il est utile de comprendre. Vous allez comprendre Git. Vous allez Gitting things done.
Table des matières
- Introduction
- Partie 1 - Objets principaux et introduction de changements
- Partie 2 - Brancher et intégrer les changements
- Partie 3 - Annuler des changements
- Partie 4 - Outils Git incroyables et utiles
- Résumé
- Annexes
À qui s'adresse ce livre ?
À tout développeur logiciel qui souhaite approfondir ses connaissances sur Git.
Si vous êtes expérimenté avec Git - je suis sûr que vous pourrez approfondir vos connaissances. Même si vous débutez avec Git - je commencerai par un aperçu des mécanismes de Git et des termes utilisés tout au long de ce livre.
Ce livre est pour vous. Je l'ai écrit pour que vous puissiez en apprendre davantage sur Git, et aussi pour que vous puissiez apprécier, voire aimer Git.
Vous remarquerez également que j'utilise un style décontracté tout au long du livre. Je crois qu'apprendre Git devrait être instructif et amusant. Apprendre de nouvelles choses est toujours difficile, et j'ai senti qu'écrire dans un style moins décontracté ne rendrait pas vraiment service. Et comme je l'ai déjà mentionné - ce livre est pour vous.
Qui suis-je ?
Ce livre parle de vous et de votre parcours avec Git. Mais j'aimerais vous dire un peu pourquoi je pense pouvoir contribuer à votre parcours.
Je suis le CTO et l'un des cofondateurs de Swimm.io, un outil de gestion des connaissances pour le code. Une partie de ce que nous faisons consiste à lier des parties du code dans les dépôts Git à des parties de la documentation, puis à suivre les modifications dans le dépôt pour mettre à jour la documentation si nécessaire.
Chez Swimm, j'ai eu l'occasion de disséquer des parties de Git, de comprendre ses mécanismes sous-jacents et aussi d'acquérir une intuition sur les raisons pour lesquelles Git est implémenté de la sorte.
Avant de fonder Swimm, j'ai enseigné dans de nombreux environnements différents - notamment en gérant la filière Cyber de l'Israel Tech Challenge, en fondant la Check Point Security Academy et en écrivant un manuel complet.
Ce livre est ma tentative de tirer le meilleur des deux mondes - mon expérience d'enseignement ainsi que mon expérience pratique approfondie avec Git, et de vous offrir la meilleure expérience d'apprentissage possible.
L'approche de ce livre
Ce n'est certainement pas le premier livre sur Git. En m'asseyant pour l'écrire, j'avais trois principes en tête.
- Pratique - dans ce livre, vous apprendrez comment accomplir des choses dans Git. Comment introduire des changements, comment les annuler et comment réparer les choses quand elles tournent mal. Vous comprendrez comment Git fonctionne non seulement pour le plaisir de comprendre, mais avec un état d'esprit pratique. Je fais parfois référence à cela comme le "principe de praticité" - qui me guide pour décider s'il faut inclure certains sujets, et dans quelle mesure.
- Approfondi - vous plongerez profondément dans le mode de fonctionnement de Git pour comprendre ses mécanismes. Vous construirez votre compréhension progressivement, et lierez toujours vos connaissances à des scénarios réels auxquels vous pourriez être confronté dans votre travail. Afin d'atteindre une compréhension approfondie, je préfère presque toujours la ligne de commande aux interfaces graphiques, afin que vous puissiez vraiment voir quelles commandes sont exécutées.
- Visuel - comme je m'efforce de vous fournir de l'intuition, les chapitres seront accompagnés d'aides visuelles.
Pourquoi ce livre est-il accessible au public ?
Je pense que tout le monde devrait avoir accès à un contenu de haute qualité sur Git, et j'aimerais que ce livre atteigne le plus grand nombre de personnes possible.
Si vous souhaitez soutenir ce livre, vous êtes invité à acheter la version papier, une version E-Book, ou à m'offrir un café. Merci !
Vidéos d'accompagnement
J'ai couvert de nombreux sujets de ce livre sur ma chaîne YouTube - Brief (https://www.youtube.com/@BriefVid). Vous êtes invités à les consulter également.
Mettez les mains dans le cambouis
Tout au long de ce livre, j'utiliserai principalement la deuxième personne du singulier - et je m'adresserai directement à vous. Je vous demanderai de vous salir les mains, d'exécuter les commandes vous-même, afin que vous puissiez réellement ressentir ce que c'est que de faire des choses avec Git, et pas seulement lire à ce sujet.
Les sentiments de Git
Tout au long du livre, je fais parfois référence à Git avec des mots tels que "croit", "pense" ou "veut". Comme vous pouvez le dire, Git n'est pas un humain, et il n'a ni sentiments ni croyances. Eh bien, c'est vrai, mais pour que nous puissions prendre plaisir à jouer avec Git, et pour vous aider à apprécier la lecture (et moi l'écriture) de ce livre, j'ai l'impression que faire référence à Git comme étant plus que du simple code rend le tout beaucoup plus agréable.
Ma configuration
J'inclurai des captures d'écran. Il n'est pas nécessaire que votre configuration corresponde à la mienne, mais si vous êtes curieux de connaître ma configuration, alors :
- J'utilise Ubuntu 20.04 (WSL).
- Pour mon terminal, j'utilise Oh My Zsh
- J'utilise également des plugins pour Oh My Zsh, vous pouvez suivre ce tutoriel sur freeCodeCamp.
- git-graph (mon alias est
gg)
Les retours sont les bienvenus
Ce livre a été créé pour vous aider, vous et des gens comme vous, à apprendre, comprendre Git et appliquer ces connaissances dans la vie réelle.
Dès le début, j'ai demandé des retours et j'ai eu la chance d'en recevoir de personnes formidables (voir Remerciements) pour m'assurer que le livre atteignait ces objectifs. Si vous avez aimé quelque chose dans ce livre, si vous avez senti qu'il manquait quelque chose ou que quelque chose devait être amélioré, j'aimerais beaucoup vous entendre. N'hésitez pas à me contacter à gitting.things@gmail.com.
Note
Ce livre est fourni gratuitement sur freeCodeCamp comme décrit ci-dessus et selon la licence Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International.
Si vous souhaitez soutenir ce livre, vous êtes invité à acheter la version papier, une version E-Book, ou à m'offrir un café. Merci !
Partie 1 - Objets principaux et introduction de changements
Chapitre 1 - Les objets Git
Il est temps de commencer votre voyage dans les profondeurs de Git. Dans ce chapitre - en commençant par les bases - vous découvrirez les objets Git les plus importants et adopterez une façon de penser à propos de Git. Allons-y !
Git en tant que système de maintenance d'un système de fichiers
Bien qu'il existe différentes façons d'utiliser Git, j'adopterai ici celle que j'ai trouvée la plus claire et la plus utile : voir Git comme un système maintenant un système de fichiers, et spécifiquement — des instantanés (snapshots) de ce système de fichiers au fil du temps.
Un système de fichiers commence par un répertoire racine (dans les systèmes basés sur UNIX, /), qui contient généralement d'autres répertoires (par exemple, /usr ou /bin). Ces répertoires contiennent d'autres répertoires et/ou fichiers (par exemple, /usr/1.txt). Sur une machine Windows, un répertoire racine d'un lecteur serait C:\, et un sous-répertoire pourrait être C:\users. J'adopterai la convention des systèmes basés sur UNIX tout au long de ce livre.
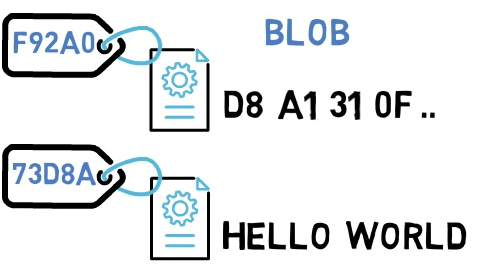
Blobs
Dans Git, le contenu des fichiers est stocké dans des objets appelés blobs, abréviation de "binary large objects".
La différence entre les blobs et les fichiers est que les fichiers contiennent également des métadonnées. Par exemple, un fichier "se souvient" de sa date de création, donc si vous déplacez ce fichier d'un répertoire à un autre, son heure de création reste la même.
Les blobs, en revanche, ne sont que des flux binaires de données, comme le contenu d'un fichier. Un blob n'enregistre pas sa date de création, son nom ou quoi que ce soit d'autre que son contenu.
Chaque blob dans Git est identifié par son hachage SHA-1. Les hachages SHA-1 sont constitués de 20 octets, généralement représentés par 40 caractères sous forme hexadécimale. Tout au long de ce livre, je n'afficherai parfois que les premiers caractères de ce hachage. Comme les hachages, et spécifiquement les hachages SHA-1, sont omniprésents dans Git, il est important que vous compreniez les caractéristiques de base des hachages.
Hachages (Hashes)
Un hachage est une fonction mathématique déterministe à sens unique.
Déterministe signifie que la même entrée fournira la même sortie. C'est-à-dire que vous prenez un flux de données, exécutez une fonction de hachage sur ce flux et vous obtenez un résultat.
Par exemple, si vous fournissez à la fonction de hachage SHA-1 le flux hello, vous obtiendrez 0xaaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d. Si vous exécutez à nouveau la fonction de hachage SHA-1, à partir d'une autre machine, et que vous lui fournissez les mêmes données (hello), vous obtiendrez la même valeur.
Git utilise SHA-1 comme fonction de hachage afin d'identifier les objets. Il compte sur son caractère déterministe, de sorte qu'un objet aura toujours le même identifiant.
Une fonction à sens unique est une fonction difficile à inverser étant donné une sortie. C'est-à-dire qu'il est impossible (ou du moins très difficile) de dire, étant donné le résultat de la fonction de hachage (par exemple 0xaaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d), quelle entrée a donné ce résultat (dans cet exemple, hello).
Retour à Git
Revenons à Git - Les blobs, tout comme les autres objets Git, ont des hachages SHA-1 associés.
 Les blobs ont des valeurs SHA-1 correspondantes
Les blobs ont des valeurs SHA-1 correspondantes
Comme je l'ai dit au début, Git peut être considéré comme un système pour maintenir un système de fichiers. Les systèmes de fichiers sont constitués de fichiers et de répertoires. Un blob est l'objet Git représentant le contenu d'un fichier.
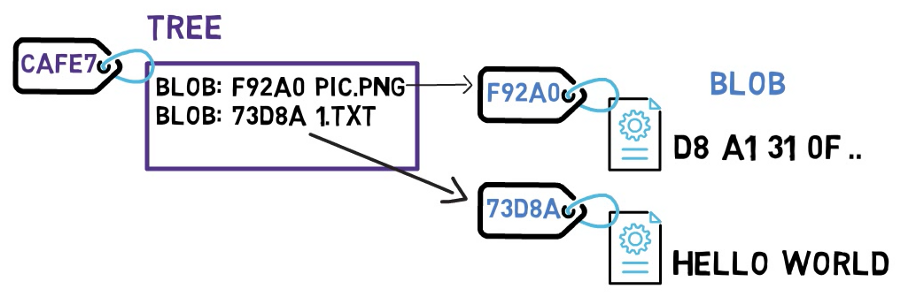
Arbres (Trees)
Dans Git, l'équivalent d'un répertoire est un tree (arbre). Un arbre est fondamentalement une liste de répertoire, faisant référence à des blobs, ainsi qu'à d'autres arbres.
Les arbres sont également identifiés par leurs hachages SHA-1. La référence à ces objets, qu'il s'agisse de blobs ou d'autres arbres, se fait via le hachage SHA-1 des objets.
 Un arbre est une liste de répertoire
Un arbre est une liste de répertoire
Considérez le dessin ci-dessus. Notez que l'arbre CAFE7 fait référence au blob F92A0 en tant que fichier pic.png. Dans un autre arbre, ce même blob peut avoir un autre nom - mais tant que le contenu est le même, ce sera toujours le même objet blob, et il aura toujours la même valeur SHA-1.
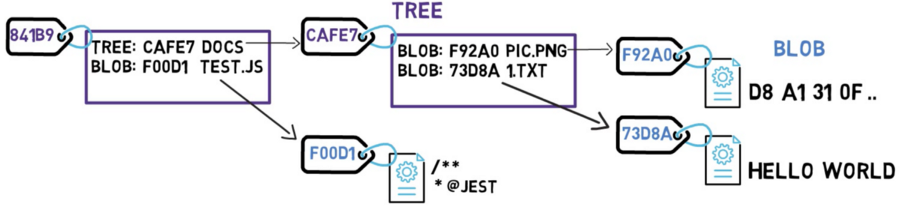 Un arbre peut contenir des sous-arbres, ainsi que des blobs
Un arbre peut contenir des sous-arbres, ainsi que des blobs
Le diagramme ci-dessus est équivalent à un système de fichiers avec un répertoire racine qui a un fichier à /test.js, et un répertoire nommé /docs composé de deux fichiers : /docs/pic.png et /docs/1.txt.
Commits
Il est maintenant temps de prendre un instantané de ce système de fichiers — et de stocker tous les fichiers qui existaient à ce moment-là, avec leur contenu.
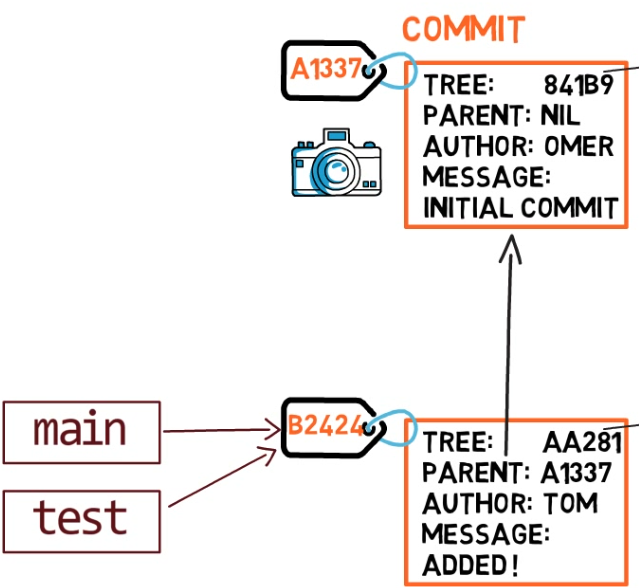
Dans Git, un instantané est un commit. Un objet commit inclut un pointeur vers l'arbre principal (le répertoire racine du système de fichiers), ainsi que d'autres métadonnées telles que le "committer" (l'utilisateur qui a créé le commit), un message de commit et l'heure du commit.
Dans la plupart des cas, un commit a également un ou plusieurs commits parents — l'instantané précédent (ou les instantanés). Bien sûr, les objets commit sont également identifiés par leurs hachages SHA-1. Ce sont les hachages que vous avez probablement l'habitude de voir lorsque vous utilisez des commandes telles que git log.
 Un commit est un instantané dans le temps. Il fait référence à l'arbre racine. Comme c'est le premier commit, il n'a pas de parents
Un commit est un instantané dans le temps. Il fait référence à l'arbre racine. Comme c'est le premier commit, il n'a pas de parents
Chaque commit contient l'instantané entier, pas seulement les différences entre lui-même et son ou ses commits parents.
Comment cela peut-il fonctionner ? Cela ne signifie-t-il pas que Git doit stocker beaucoup de données pour chaque commit ?
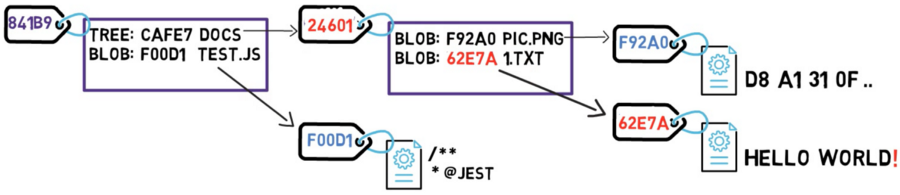
Examinez ce qui se passe si vous modifiez le contenu d'un fichier. Disons que vous modifiez le fichier 1.txt et ajoutez un point d'exclamation — c'est-à-dire que vous avez changé le contenu de HELLO WORLD à HELLO WORLD!.
Eh bien, ce changement signifie que Git crée un nouvel objet blob, avec un nouveau hachage SHA-1. Cela a du sens, car sha1("HELLO WORLD") est différent de sha1("HELLO WORLD!").
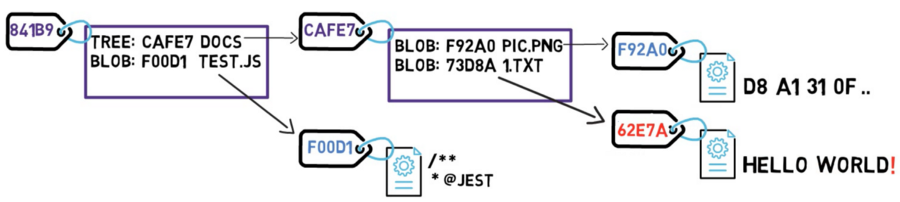 Changer le blob entraîne un nouveau SHA-1
Changer le blob entraîne un nouveau SHA-1
Puisque vous avez un nouveau hachage, alors la liste de l'arbre doit également changer. Après tout, votre arbre ne pointe plus vers le blob 73D8A, mais plutôt vers le blob 62E7A. Puisque vous changez le contenu de l'arbre, vous changez également son hachage.
 L'arbre qui pointe vers le blob modifié doit également changer
L'arbre qui pointe vers le blob modifié doit également changer
Et maintenant, puisque le hachage de cet arbre est différent, vous devez également changer l'arbre parent — car ce dernier ne pointe plus vers l'arbre CAFE7, mais plutôt vers l'arbre 24601. Par conséquent, l'arbre parent aura également un nouveau hachage.
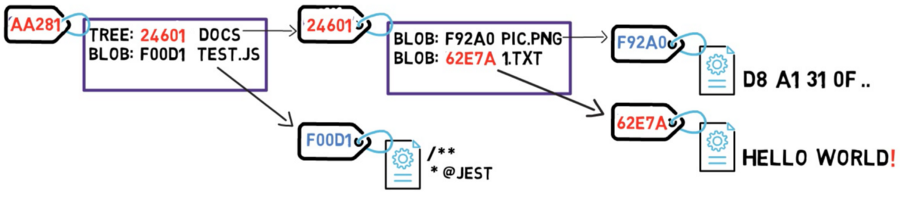 L'arbre racine change également, tout comme son hachage
L'arbre racine change également, tout comme son hachage
Presque prêt à créer un nouvel objet commit, et il semble que vous allez stocker beaucoup de données — tout le système de fichiers, encore une fois ! Mais est-ce vraiment nécessaire ?
En fait, certains objets, spécifiquement les objets blob, n'ont pas changé depuis le commit précédent — le blob F92A0 est resté intact, tout comme le blob F00D1.
C'est donc l'astuce — tant qu'un objet ne change pas, Git ne le stocke pas à nouveau. Dans ce cas, Git n'a pas besoin de stocker le blob F92A0 ou le blob F00D1 une fois de plus. Git peut y faire référence en utilisant uniquement leurs valeurs de hachage. Vous pouvez alors créer votre objet commit.
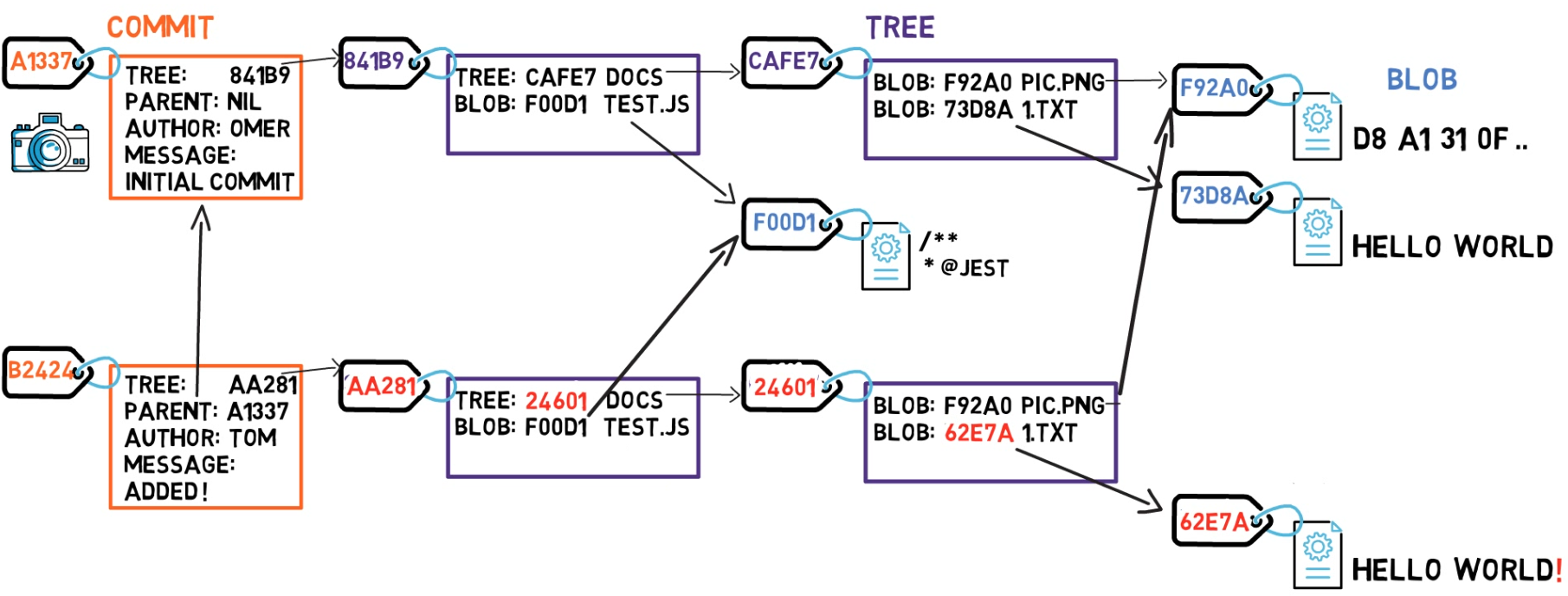 Les blobs restés intacts sont référencés par leurs valeurs de hachage
Les blobs restés intacts sont référencés par leurs valeurs de hachage
Puisque ce commit n'est pas le premier commit, il a également un commit parent — le commit A1337.
Considérer les hachages
Après avoir introduit les blobs, les arbres et les commits - considérez les hachages de ces objets. Supposons que j'ai écrit la chaîne Git is awesome!, et créé un objet blob à partir de celle-ci. Vous avez fait la même chose sur votre système. Aurions-nous le même hachage ?
La réponse est — Oui. Puisque les blobs sont constitués des mêmes données, ils auront les mêmes valeurs SHA-1.
Et si je créais un arbre qui référence le blob de Git is awesome!, et lui donnais un nom spécifique et des métadonnées, et que vous fassiez exactement la même chose sur votre système. Aurions-nous le même hachage ?
Encore une fois, oui. Puisque les objets arbre sont les mêmes, ils auraient le même hachage.
Et si je créais un commit pointant vers cet arbre avec le message de commit Hello, et que vous fassiez la même chose sur votre système ? Aurions-nous le même hachage ?
Dans ce cas, la réponse est — Non. Même si nos objets commit font référence au même arbre, ils ont des détails de commit différents — heure, committer, et ainsi de suite.
Comment les objets sont-ils stockés ?
Vous comprenez maintenant le but des blobs, des arbres et des commits. Dans les prochains chapitres, vous créerez également ces objets vous-même. Bien qu'il soit intéressant, comprendre comment ces objets sont réellement encodés et stockés n'est pas vital pour votre compréhension, et pour "gitting things done".
Court résumé - Objets Git
Pour récapituler, dans cette section, nous avons introduit trois objets Git :
- Blob — contenu d'un fichier.
- Tree (Arbre) — une liste de répertoire (de blobs et d'arbres).
- Commit — un instantané de l'arbre de travail.
Dans le prochain chapitre, nous comprendrons les branches dans Git.
Chapitre 2 - Les branches dans Git
Dans le chapitre précédent, j'ai suggéré que nous devrions voir Git comme un système pour maintenir un système de fichiers.
L'une des merveilles de Git est qu'il permet à plusieurs personnes de travailler sur ce système de fichiers, en parallèle, (la plupart du temps) sans interférer avec le travail des autres. La plupart des gens diraient qu'ils "travaillent sur la branche X". Mais qu'est-ce que cela signifie réellement ?
Une branche est juste une référence nommée à un commit.
Vous pouvez toujours référencer un commit par son hachage SHA-1, mais les humains préfèrent généralement d'autres moyens de nommer les objets. Une branche est une façon de référencer un commit, mais ce n'est vraiment que cela.
Dans la plupart des dépôts, la ligne principale de développement se fait dans une branche appelée main. C'est juste un nom, et il est créé lorsque vous utilisez git init, ce qui le rend largement utilisé. Cependant, vous pourriez utiliser n'importe quel autre nom que vous voudriez.
Généralement, la branche pointe vers le dernier commit dans la ligne de développement sur laquelle vous travaillez actuellement.
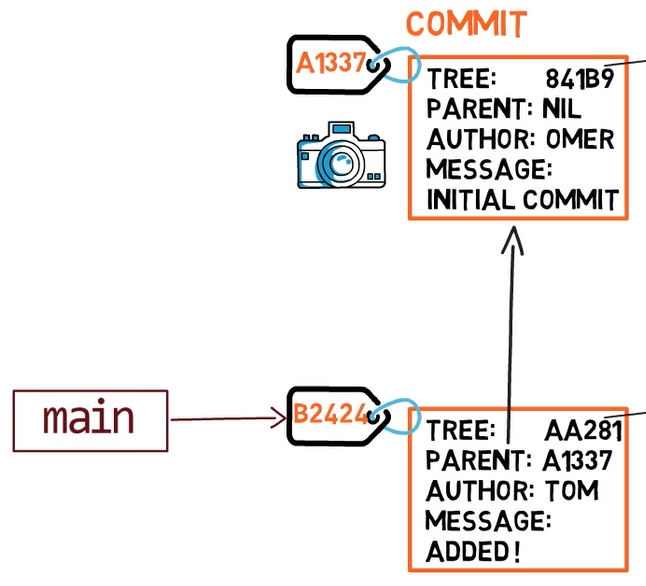 Une branche est juste une référence nommée à un commit
Une branche est juste une référence nommée à un commit
Pour créer une autre branche, vous pouvez utiliser la commande git branch. Lorsque vous faites cela, Git crée un autre pointeur. Si vous avez créé une branche appelée test, en utilisant git branch test, vous créeriez un autre pointeur qui pointe vers le même commit que la branche sur laquelle vous vous trouvez :
 Utiliser
Utiliser git branch crée un autre pointeur
Comment Git sait-il sur quelle branche vous vous trouvez actuellement ? Il garde un autre pointeur désigné, appelé HEAD. Généralement, HEAD pointe vers une branche, qui à son tour pointe vers un commit. Dans le cas décrit, HEAD pourrait pointer vers main, qui à son tour pointe vers le commit B2424. Dans certains cas, HEAD peut également pointer directement vers un commit.
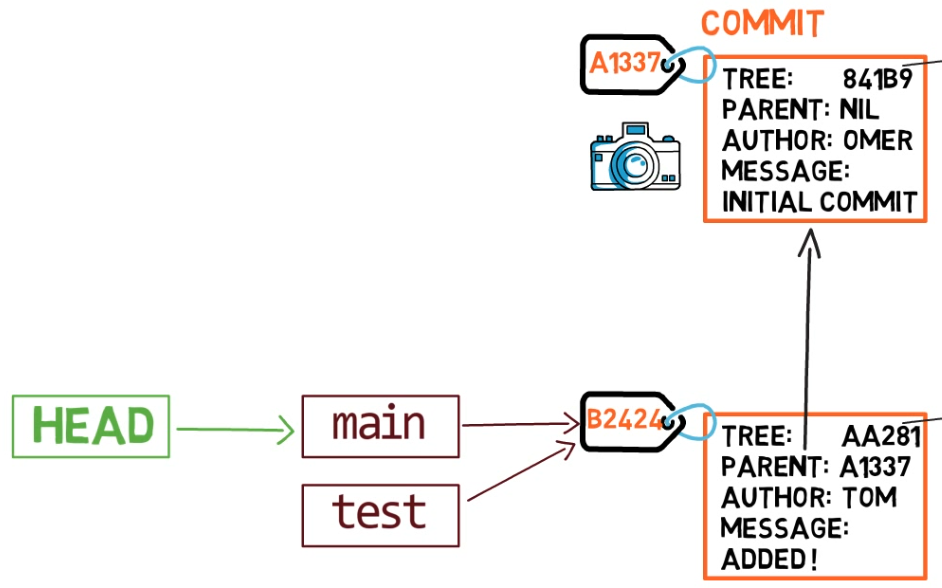
HEAD pointe vers la branche sur laquelle vous êtes actuellement
Pour changer la branche active pour être test, vous pouvez utiliser la commande git checkout test, ou git switch test. Maintenant, vous pouvez déjà deviner ce que fait réellement cette commande — elle change simplement HEAD pour pointer vers test.
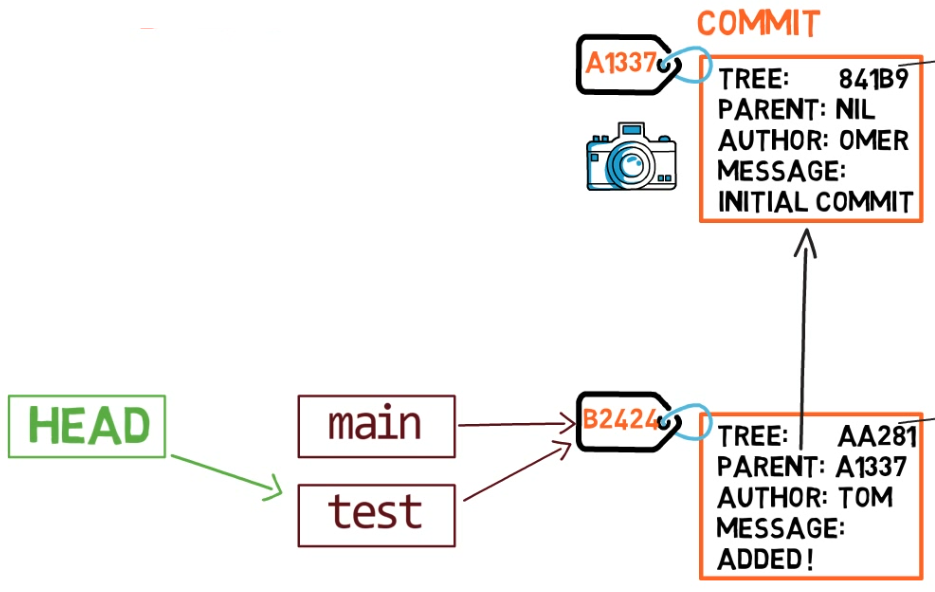
git checkout test change où pointe HEAD
Vous pourriez également utiliser git checkout -b test avant de créer la branche test, ce qui équivaut à exécuter git branch test pour créer la branche, puis git checkout test pour déplacer HEAD pour pointer vers la nouvelle branche.
Au point représenté dans le dessin ci-dessus, que se passerait-il si vous apportiez des modifications et créiez un nouveau commit en utilisant git commit ? À quelle branche le nouveau commit sera-t-il ajouté ?
La réponse est la branche test, car c'est la branche active (puisque HEAD pointe vers elle). Ensuite, le pointeur test se déplacera vers le commit nouvellement ajouté. Notez que HEAD pointe toujours vers test.
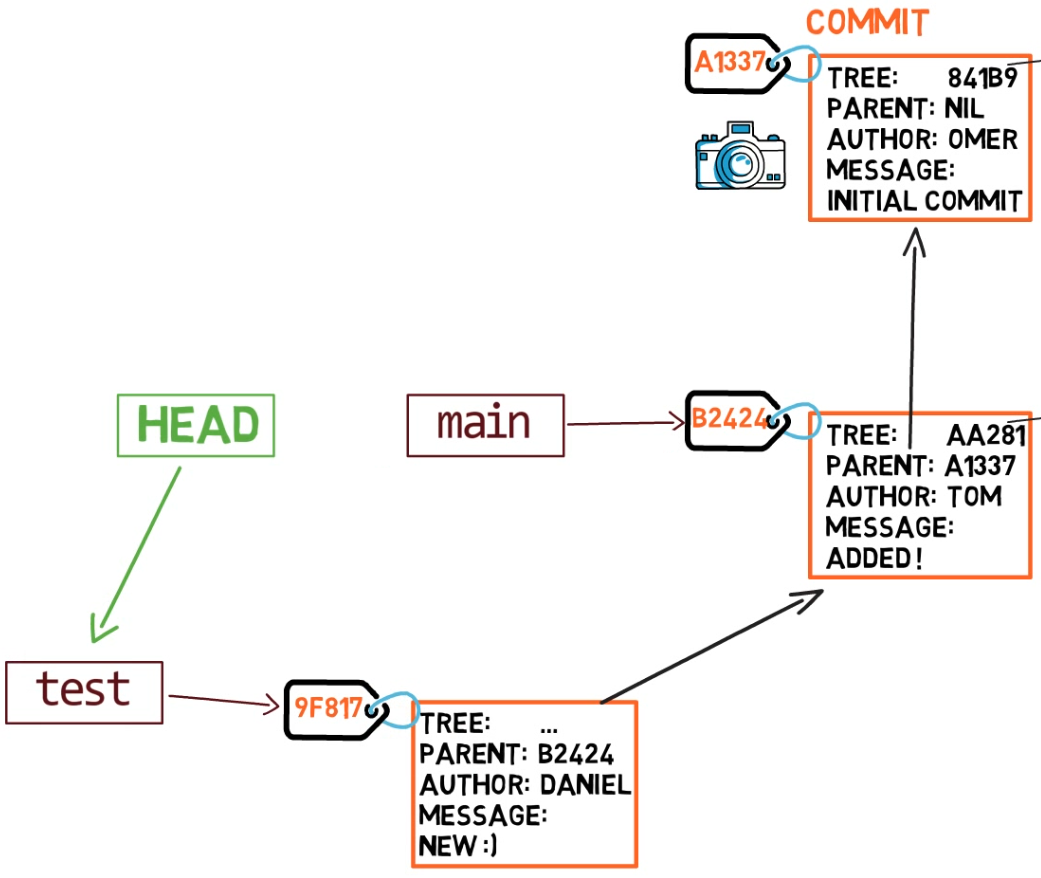 Chaque fois que nous utilisons
Chaque fois que nous utilisons git commit, le pointeur de branche se déplace vers le commit nouvellement créé
Si vous revenez à main en utilisant git checkout main, Git déplacera HEAD pour pointer à nouveau vers main.
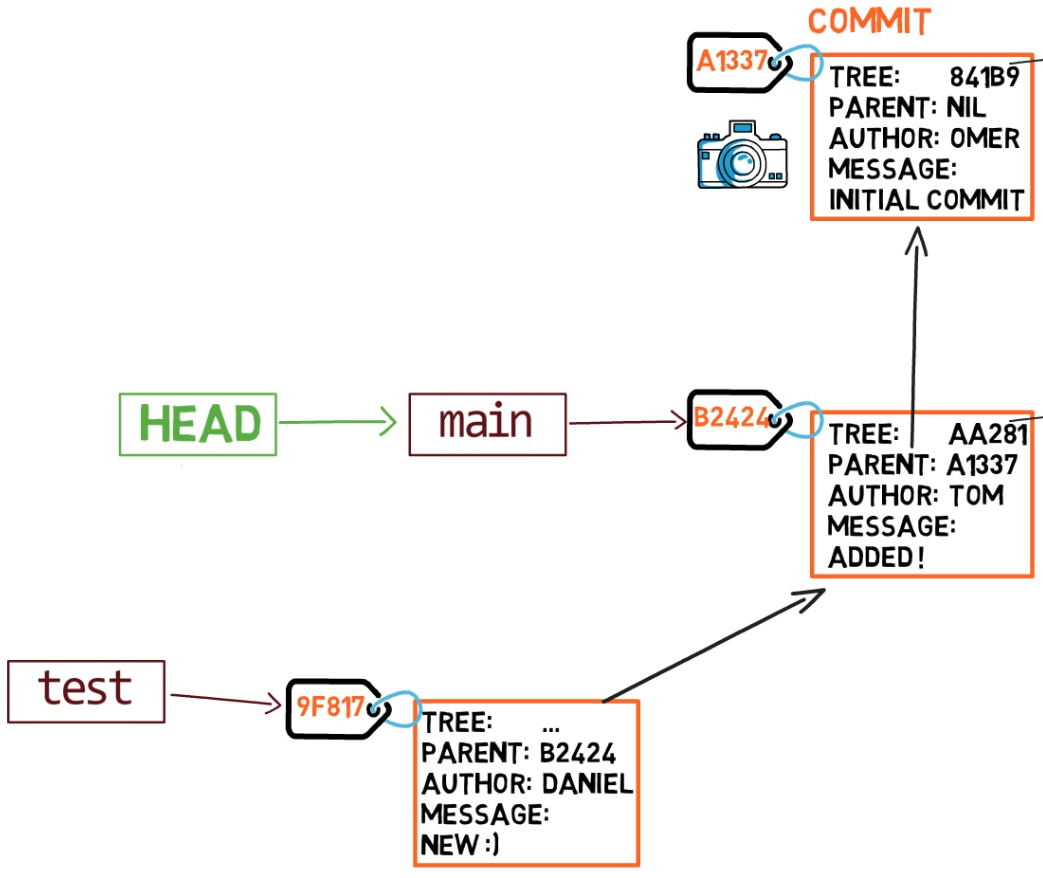 L'état résultant après avoir utilisé
L'état résultant après avoir utilisé git checkout main
Maintenant, si vous créez un autre commit, à quelle branche sera-t-il ajouté ?
C'est exact, il sera ajouté à la branche main (et son parent sera le commit B2424).
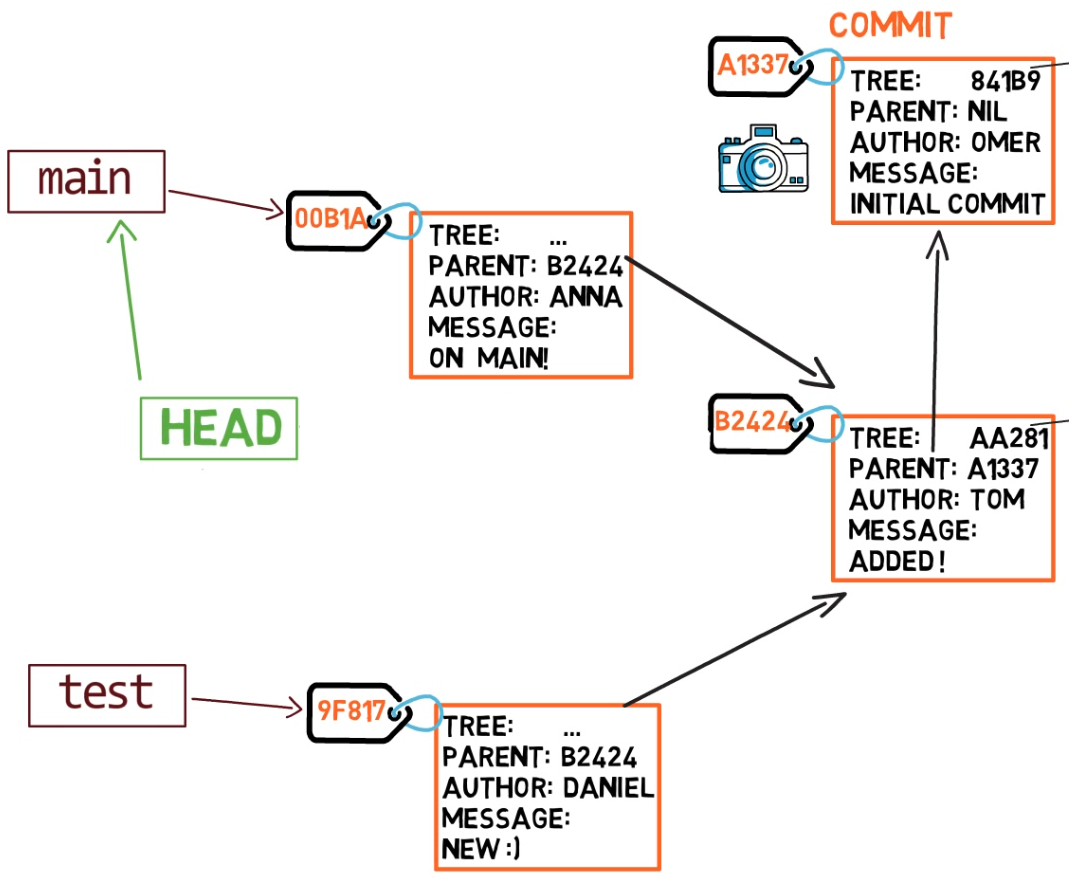 L'état résultant après la création d'un autre commit sur la branche
L'état résultant après la création d'un autre commit sur la branche main
Court résumé - Branches
- Une branche est une référence nommée à un commit.
- Lorsque vous utilisez
git commit, Git crée un objet commit et déplace la branche pour pointer vers le commit nouvellement créé. HEADest un pointeur spécial indiquant à Git quelle branche est la branche active (dans de rares cas, il peut pointer directement vers un commit).
Dans les prochains chapitres, vous apprendrez comment introduire des changements dans Git. Vous créerez un dépôt à partir de zéro — sans utiliser git init, git add ou git commit. Cela vous permettra d'approfondir votre compréhension de ce qui se passe sous le capot lorsque vous travaillez avec Git. Vous créerez également de nouvelles branches, changerez de branche et créerez des commits supplémentaires — le tout sans utiliser git branch ou git checkout. Je ne sais pas pour vous, mais je suis déjà excité !
Chapitre 3 - Comment enregistrer des changements dans Git
Jusqu'à présent, nous avons découvert quatre entités différentes dans Git :
- Blob — contenu d'un fichier.
- Tree (Arbre) — une liste de répertoire (de blobs et d'arbres).
- Commit — un instantané de l'arbre de travail, avec certaines métadonnées telles que l'heure ou le message de commit.
- Branch (Branche) — une référence nommée à un commit.
Les trois premiers sont des objets, tandis que le quatrième est un moyen de faire référence à des objets (spécifiquement, des commits).
Maintenant, il est temps de comprendre comment introduire des changements dans Git.
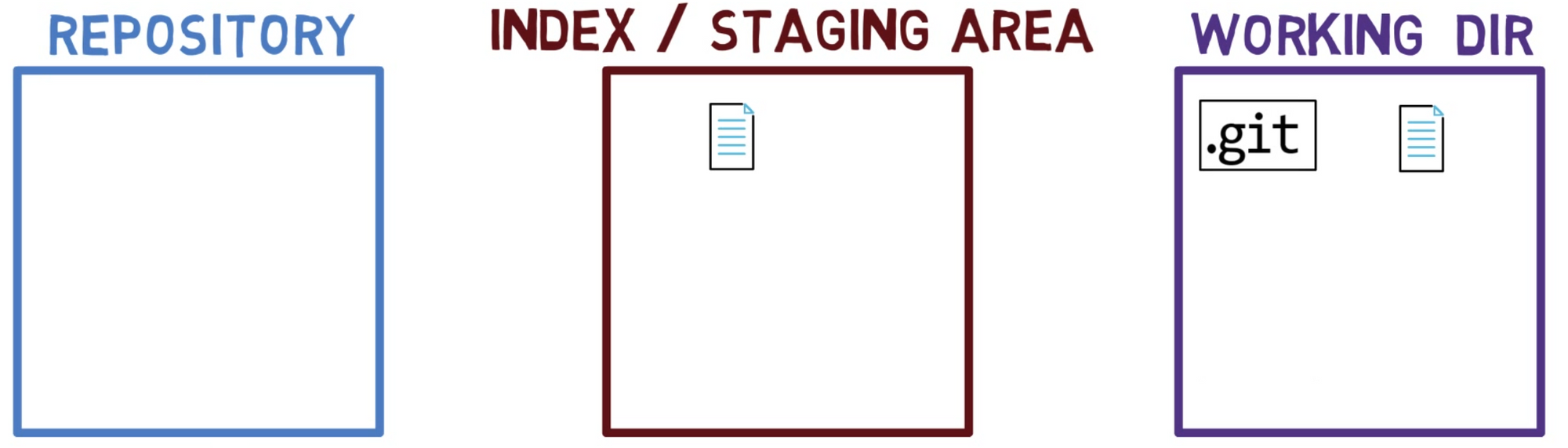
Lorsque vous travaillez sur votre code source, vous travaillez à partir d'un répertoire de travail (working dir). Un répertoire de travail (également appelé "working tree" ou arbre de travail) est tout répertoire de votre système de fichiers auquel est associé un dépôt. Il contient les dossiers et fichiers de votre projet, ainsi qu'un répertoire appelé .git dont nous parlerons plus tard. Rappelez-vous que nous avons dit que Git est un système pour maintenir un système de fichiers. Le répertoire de travail est la racine du système de fichiers pour Git.
Après avoir apporté quelques modifications, vous voudrez peut-être les enregistrer dans votre dépôt. Un dépôt (en abrégé : "repo") est une collection de commits, chacun étant une archive de ce à quoi ressemblait l'arbre de travail du projet à une date passée, que ce soit sur votre machine ou celle de quelqu'un d'autre. C'est-à-dire, comme je l'ai dit plus tôt, un commit est un instantané de l'arbre de travail.
Un dépôt comprend également des éléments autres que vos fichiers de code, tels que HEAD et branches.
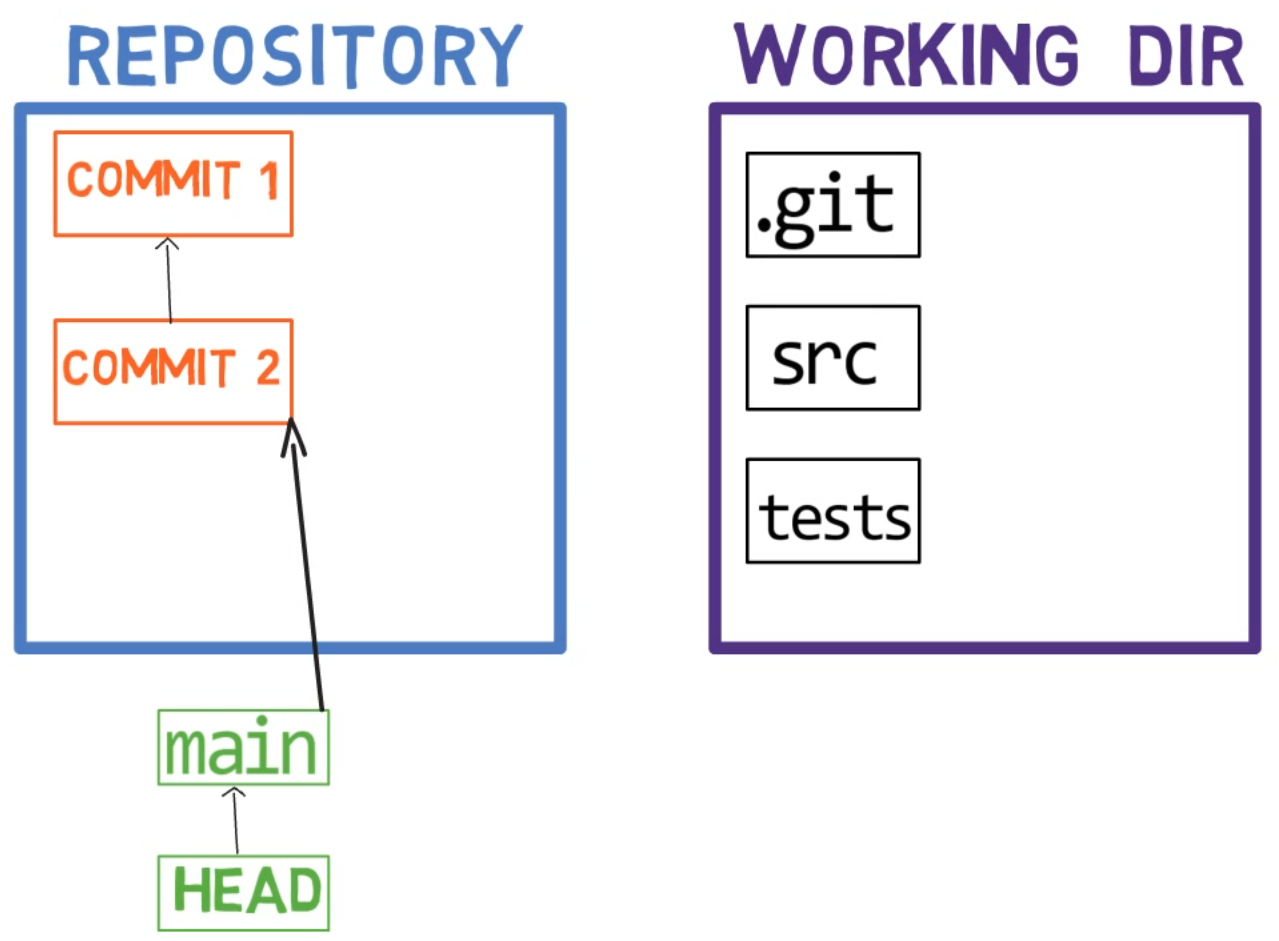 Un répertoire de travail à côté du dépôt
Un répertoire de travail à côté du dépôt
Note concernant les conventions de dessin que j'utilise : J'inclus .git dans le répertoire de travail, pour vous rappeler qu'il s'agit d'un dossier dans le dossier du projet sur le système de fichiers. Le dossier .git contient en fait les objets du dépôt, comme nous le verrons au chapitre 4.
Il existe d'autres systèmes de contrôle de version où les modifications sont validées directement du répertoire de travail vers le dépôt. Dans Git, ce n'est pas le cas. Au lieu de cela, les modifications sont d'abord enregistrées dans quelque chose appelé l'index, ou la zone de transit (staging area).
Ces deux termes font référence à la même chose et sont souvent utilisés dans la documentation de Git. J'utiliserai ces termes de manière interchangeable tout au long de ce livre, car vous devriez vous sentir à l'aise avec les deux.
Vous pouvez penser à l'ajout de modifications à l'index comme un moyen de "confirmer" vos modifications, une par une, avant de créer un commit (qui enregistre toutes vos modifications approuvées en une seule fois).
Lorsque vous faites un checkout d'une branche, Git peuple l'index et le répertoire de travail avec le contenu des fichiers tels qu'ils existent dans le commit vers lequel pointe cette branche. Lorsque vous utilisez git commit, Git crée un nouvel objet commit basé sur l'état de l'index.
 Les trois "états" - répertoire de travail, index et dépôt
Les trois "états" - répertoire de travail, index et dépôt
L'utilisation de l'index vous permet de préparer soigneusement chaque commit. Par exemple, vous pouvez avoir deux fichiers avec des modifications dans votre répertoire de travail :
 Le répertoire de travail comprend deux fichiers avec des modifications
Le répertoire de travail comprend deux fichiers avec des modifications
Par exemple, supposons que ces deux fichiers soient 1.txt et 2.txt. Il est possible de n'ajouter qu'un seul d'entre eux (par exemple, 1.txt) à l'index, en utilisant git add 1.txt :
 L'état après la mise en transit de
L'état après la mise en transit de 1.txt
En conséquence, l'état de l'index correspond à l'état de HEAD (dans ce cas, "Commit 2"), à l'exception du fichier 1.txt, qui correspond à l'état de 1.txt dans le répertoire de travail. Puisque vous n'avez pas mis en transit 2.txt, l'index n'inclut pas la version mise à jour de 2.txt. Donc l'état de 2.txt dans l'index correspond à l'état de 2.txt dans "Commit 2".
En coulisses - une fois que vous mettez en transit (stage) une version d'un fichier, Git crée un objet blob avec le contenu du fichier. Cet objet blob est ensuite ajouté à l'index. Tant que vous modifiez uniquement le fichier sur le répertoire de travail, sans le mettre en transit, les modifications que vous apportez ne sont pas enregistrées dans les objets blob.
Lorsque vous considérez la figure précédente, notez que je ne dessine pas la version mise en transit du fichier comme faisant partie du "dépôt", car dans cette représentation, le "dépôt" fait référence à un arbre de commits et à leurs références, et ce blob n'a fait partie d'aucun commit.
Maintenant, vous pouvez utiliser git commit pour enregistrer la modification de 1.txt uniquement :
 L'état après l'utilisation de
L'état après l'utilisation de git commit
L'utilisation de git commit effectue deux opérations principales :
- Elle crée un nouvel objet commit. Cet objet commit reflète l'état de l'index lorsque vous avez exécuté la commande
git commit. - Elle met à jour la branche active pour pointer vers le commit nouvellement créé. Dans cet exemple,
mainpointe maintenant vers "Commit 3", le nouvel objet commit.
Comment créer un repo — La méthode conventionnelle
Assurons-nous que vous compreniez comment les termes que nous avons introduits se rapportent au processus de création d'un nouveau dépôt. Il s'agit d'une vue d'ensemble rapide de haut niveau, avant de plonger beaucoup plus profondément dans ce processus.
Initialisez un nouveau dépôt en utilisant git init my_repo, puis changez votre répertoire pour celui du dépôt en utilisant cd my_repo :

git init
En utilisant tree -f .git, vous pouvez voir que l'exécution de git init my_repo a entraîné la création de pas mal de sous-répertoires à l'intérieur de .git. (Le drapeau -f inclut les fichiers dans la sortie de tree).
Note : si vous utilisez Windows, exécutez tree /f .git.
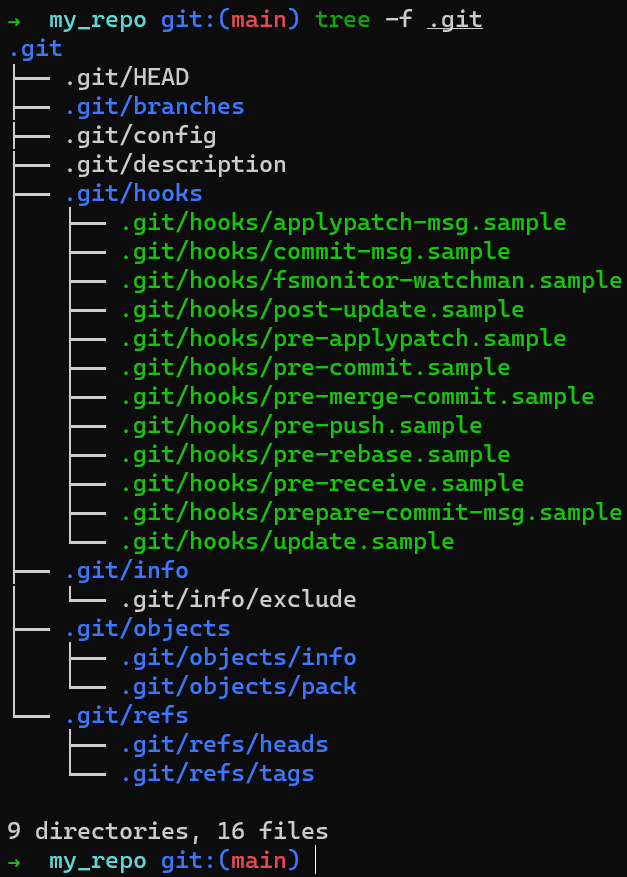 La sortie de
La sortie de tree -f .git après avoir utilisé git init
Créez un fichier à l'intérieur du répertoire my_repo :
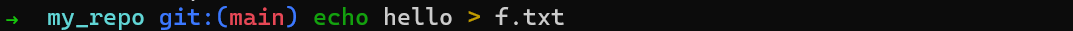 Création de
Création de f.txt
Ce fichier se trouve dans votre répertoire de travail. Si vous exécutez git status, vous verrez que ce fichier n'est pas suivi (untracked) :
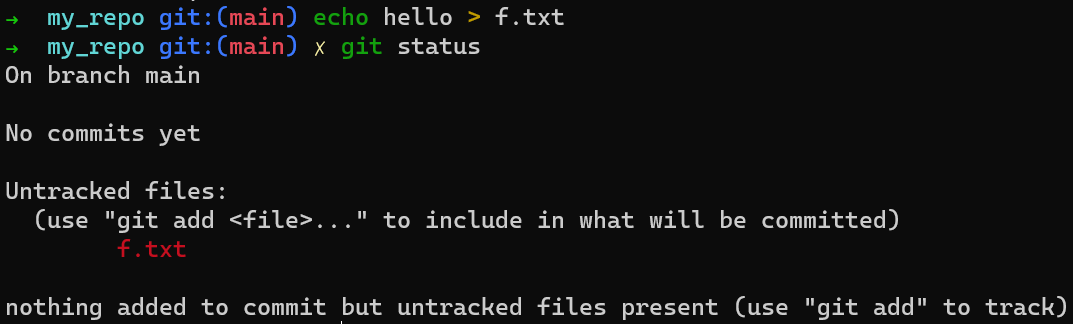 Le résultat de
Le résultat de git status
Les fichiers dans votre répertoire de travail peuvent être dans l'un des deux états : suivis (tracked) ou non suivis (untracked).
Les fichiers suivis sont des fichiers que Git "connaît". Ils étaient soit dans le dernier commit, soit ils sont mis en transit maintenant (c'est-à-dire qu'ils sont dans la zone de transit).
Les fichiers non suivis sont tout le reste — tous les fichiers de votre répertoire de travail qui n'étaient pas dans votre dernier commit et qui ne sont pas dans votre zone de transit.
Le nouveau fichier (f.txt) est actuellement non suivi, car vous ne l'avez pas ajouté à la zone de transit et il n'a pas été inclus dans un commit précédent.

f.txt est dans le répertoire de travail (et non suivi)
Vous pouvez maintenant ajouter ce fichier à la zone de transit (aussi appelé stager ce fichier) en utilisant git add f.txt. Vous pouvez vérifier qu'il a été mis en transit en exécutant git status :
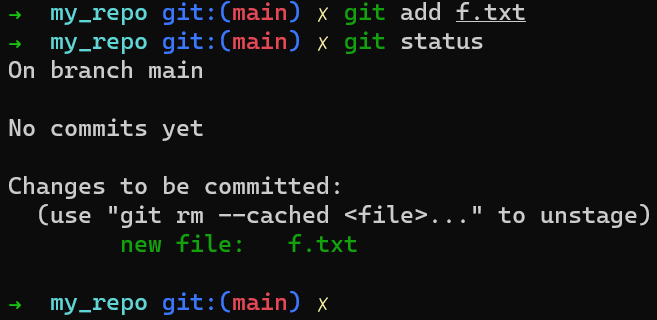 Ajout du nouveau fichier à la zone de transit
Ajout du nouveau fichier à la zone de transit
Donc maintenant, l'état de l'index correspond à celui du répertoire de travail :
 L'état après l'ajout du nouveau fichier
L'état après l'ajout du nouveau fichier
Vous pouvez maintenant créer un commit en utilisant git commit :
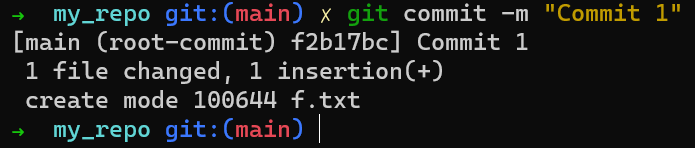 Validation d'un commit initial
Validation d'un commit initial
Si vous exécutez à nouveau git status, vous verrez que le statut est propre (clean) - c'est-à-dire que l'état de HEAD (qui pointe vers votre commit initial) est égal à l'état de l'index, et aussi à l'état du répertoire de travail. En utilisant git log, vous verrez en effet que HEAD pointe vers main qui à son tour pointe vers votre nouveau commit :
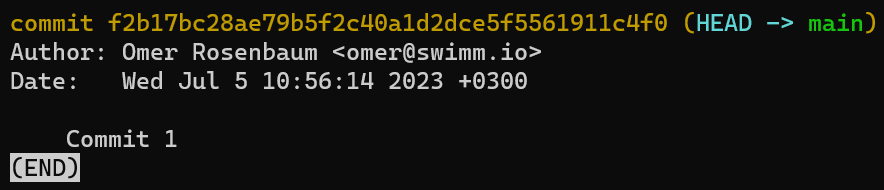 La sortie de
La sortie de git log après l'introduction du premier commit
Quelque chose a-t-il changé dans le répertoire .git ? Exécutez tree -f .git pour vérifier :
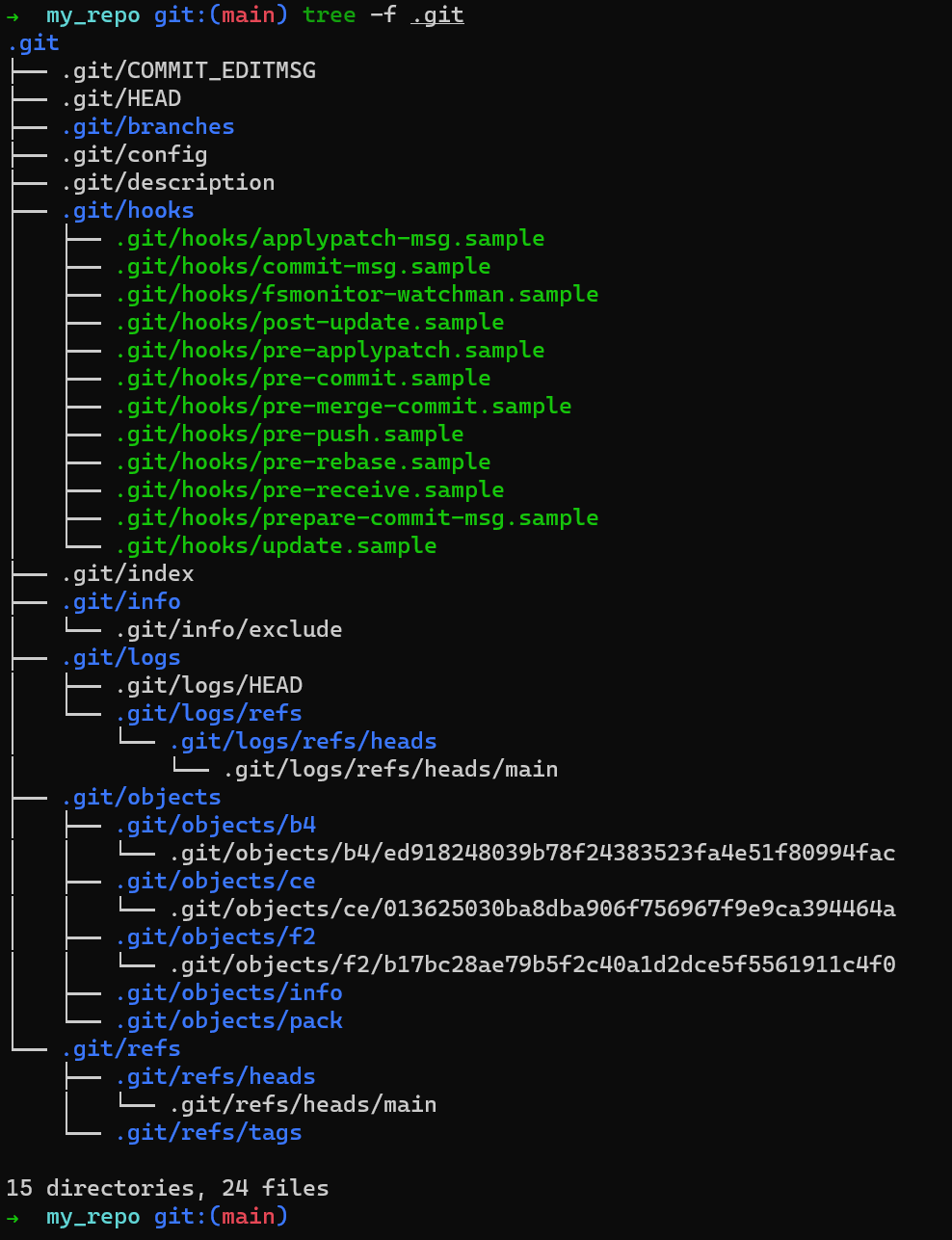 Beaucoup de choses ont changé dans
Beaucoup de choses ont changé dans .git
Apparemment, pas mal de choses ont changé. Il est temps de plonger plus profondément dans la structure de .git et de comprendre ce qui se passe sous le capot lorsque vous exécutez git init, git add ou git commit. C'est exactement ce que le prochain chapitre couvrira.
Récapitulatif - Comment enregistrer des changements dans Git
Vous avez appris les trois "états" différents du système de fichiers que Git maintient :
- Répertoire de travail (ou arbre de travail) - tout répertoire de votre système de fichiers auquel un dépôt est associé.
- Index, ou Zone de transit - un terrain de jeu pour le prochain commit.
- Dépôt (en abrégé : "repo") - une collection de commits, chacun étant un instantané de l'arbre de travail.
Lorsque vous introduisez des changements dans Git, vous suivez presque toujours cet ordre :
- Vous modifiez d'abord le répertoire de travail
- Ensuite, vous mettez en transit ces modifications (ou certaines d'entre elles) dans l'index
- Et enfin, vous validez ces modifications (commit) - mettant ainsi à jour le dépôt avec un nouveau commit. L'état de ce nouveau commit correspond à l'état de l'index.
Prêt à plonger plus profondément ?
Chapitre 4 - Comment créer un repo en partant de zéro
Jusqu'à présent, nous avons couvert quelques principes fondamentaux de Git, et maintenant vous devriez être prêt à vraiment Git going (je ne semble pas me lasser de ce jeu de mots).
Afin de comprendre en profondeur comment Git fonctionne, vous allez créer un dépôt, mais cette fois-ci — vous allez le construire à partir de zéro. Comme dans les autres chapitres, je vous encourage à essayer les commandes en parallèle de ce chapitre.
Comment configurer .git
Créez un nouveau répertoire et exécutez git status à l'intérieur :

git status dans un nouveau répertoire
D'accord, donc Git semble mécontent car vous n'avez pas encore de dossier .git. La chose naturelle à faire serait de créer ce répertoire et de réessayer :
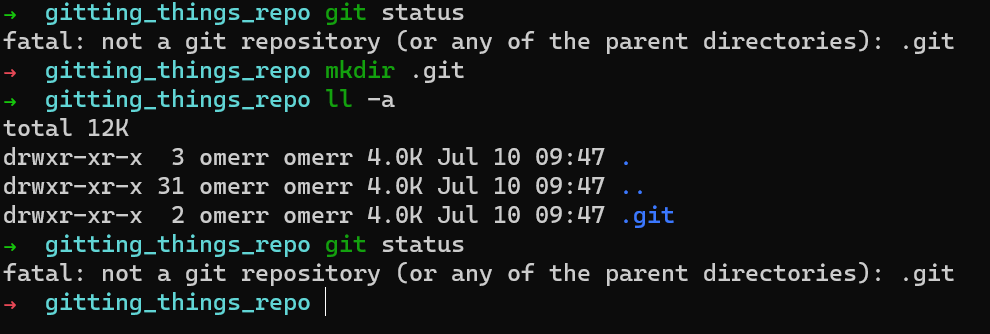
git status après avoir créé .git
Apparemment, créer un répertoire .git ne suffit tout simplement pas. Vous devez ajouter du contenu à ce répertoire.
Un dépôt Git a deux composants principaux :
- Une collection d'objets — blobs, arbres et commits.
- Un système de nommage de ces objets — appelé références.
Un dépôt peut également contenir d'autres choses, comme des hooks, mais à tout le moins — il doit inclure des objets et des références.
Créez un répertoire pour les objets à .git/objects, et un répertoire pour les références (en abrégé : "refs") à .git/refs (sur les systèmes Windows — .git\objects et .git\refs, respectivement).
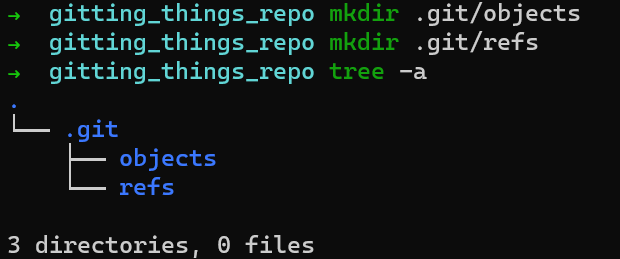 Considération de l'arborescence des répertoires
Considération de l'arborescence des répertoires
Un type de référence est les branches. En interne, Git appelle les branches par le nom heads. Créez un répertoire pour les branches — .git/refs/heads.
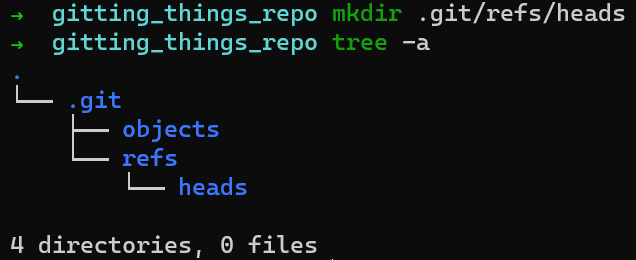 L'arborescence des répertoires
L'arborescence des répertoires
Cela ne change toujours pas le résultat de git status :
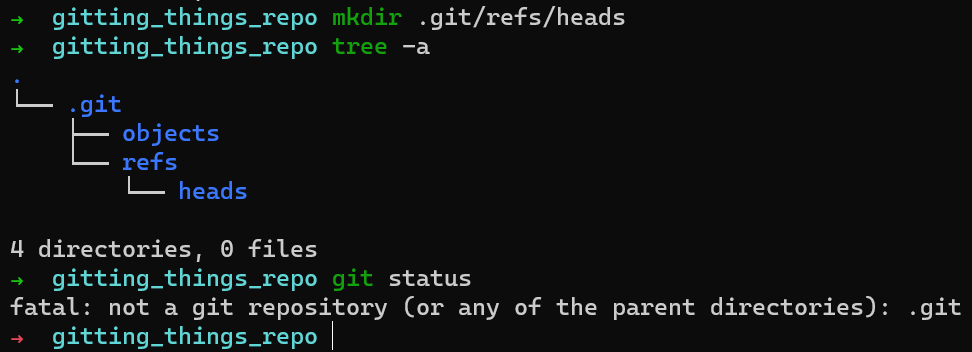
git status après avoir créé .git/refs/heads
Comment Git sait-il par où commencer lorsqu'il cherche un commit dans le dépôt ? Comme je l'ai expliqué plus tôt, il cherche HEAD, qui pointe vers la branche active actuelle (ou le commit, dans certains cas).
Donc, vous devez créer HEAD, qui n'est qu'un fichier résidant à .git/HEAD. Vous pouvez appliquer ce qui suit :
Sur UNIX :
echo "ref: refs/heads/main" > .git/HEAD
Sur Windows :
echo ref: refs/heads/main > .git\HEAD
Vous savez maintenant comment HEAD est implémenté — c'est simplement un fichier, et son contenu décrit ce vers quoi il pointe.
Suite à la commande ci-dessus, git status semble changer d'avis :
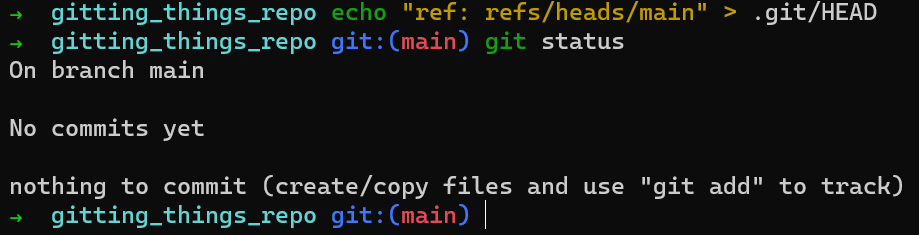
HEAD est juste un fichier
Remarquez que Git "croit" que vous êtes sur une branche appelée main, même si vous n'avez pas créé cette branche. main est juste un nom. Vous pouvez aussi faire croire à Git que vous êtes sur une branche appelée banana si vous le souhaitez :
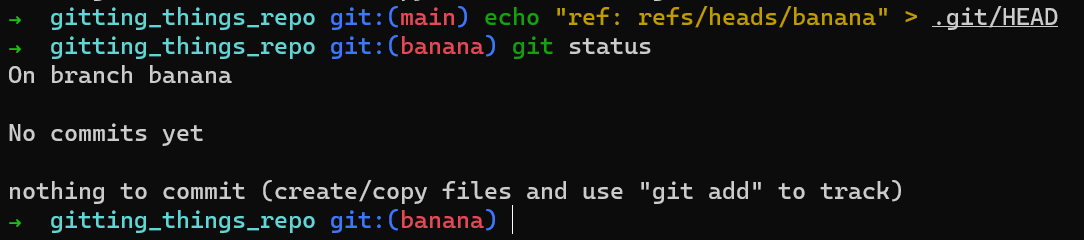 Création d'une branche nommée
Création d'une branche nommée banana
Revenez à main, car vous continuerez à travailler depuis (principalement) là tout au long de ce chapitre, juste pour adhérer à la convention habituelle :
echo "ref: refs/heads/main" > .git/HEAD
Maintenant que votre répertoire .git est prêt, vous pouvez travailler pour faire un commit (encore une fois, sans utiliser git add ou git commit).
Commandes de plomberie vs porcelaine dans Git
À ce stade, il serait utile de faire une distinction entre deux types de commandes Git : plomberie (plumbing) et porcelaine (porcelain). L'application des termes vient curieusement des toilettes, traditionnellement faites de porcelaine, et de l'infrastructure de plomberie (tuyaux et drains).
La couche de porcelaine fournit une interface conviviale pour la plomberie. La plupart des gens ne s'occupent que de la porcelaine. Pourtant, quand les choses tournent (terriblement) mal, et que quelqu'un veut comprendre pourquoi, il devra se retrousser les manches et s'occuper de la plomberie.
Git utilise cette terminologie comme une analogie pour séparer les commandes de bas niveau que les utilisateurs n'ont généralement pas besoin d'utiliser directement (commandes de "plomberie") des commandes de haut niveau plus conviviales (commandes de "porcelaine").
Jusqu'à présent, vous avez traité des commandes de porcelaine — git init, git add ou git commit. Il est temps d'aller plus loin et de vous familiariser avec certaines commandes de plomberie.
Comment créer des objets dans Git
Commencez par créer un objet et écrivez-le dans la base de données d'objets de Git, résidant dans .git/objects. Pour connaître la valeur de hachage SHA-1 d'un blob, vous pouvez utiliser git hash-object (oui, une commande de plomberie), de la manière suivante :
Sur UNIX :
echo "Git is awesome" | git hash-object --stdin
Sur Windows :
> echo Git is awesome | git hash-object --stdin
En utilisant --stdin, vous demandez à git hash-object de prendre son entrée depuis l'entrée standard. Cela vous fournira la valeur de hachage pertinente :
 Obtention du SHA-1 d'un blob
Obtention du SHA-1 d'un blob
Afin d'écrire réellement ce blob dans la base de données d'objets de Git, vous pouvez ajouter l'option -w pour git hash-object. Ensuite, vous vérifiez le contenu du dossier .git, et voyez qu'il a changé :
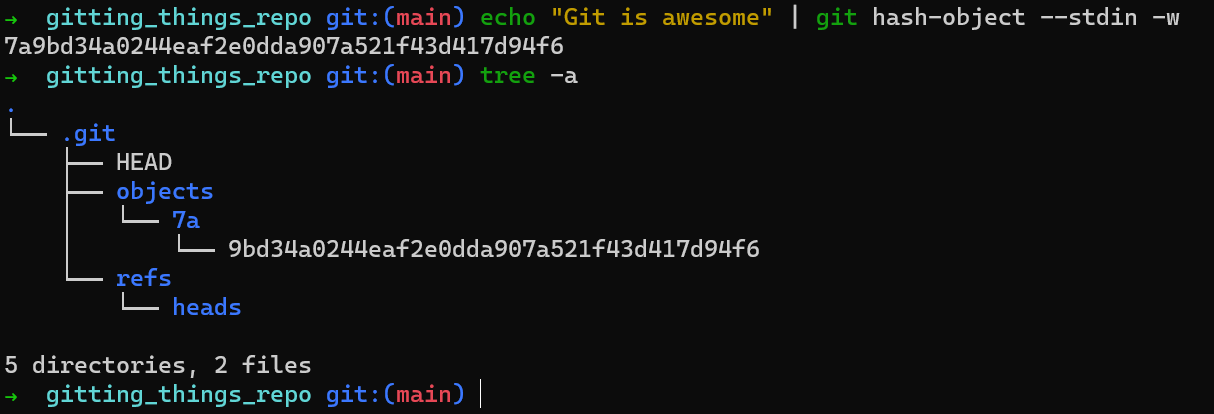 Écriture d'un blob dans la base de données d'objets
Écriture d'un blob dans la base de données d'objets
Vous pouvez voir que le hachage de votre blob est 7a9bd34a0244eaf2e0dda907a521f43d417d94f6. Vous pouvez également voir qu'un répertoire a été créé sous .git/objects, un répertoire nommé 7a, et à l'intérieur de celui-ci, un fichier du nom de 9bd34a0244eaf2e0dda907a521f43d417d94f6.
Ce que Git a fait ici, c'est prendre les deux premiers caractères du hachage SHA-1 et les utiliser comme nom d'un répertoire. Les caractères restants sont utilisés comme nom de fichier pour le fichier qui contient réellement le blob.
Pourquoi cela ? Considérez un dépôt assez volumineux, un qui a 400 000 objets (blobs, arbres et commits) dans sa base de données. Rechercher un hachage dans cette liste de 400 000 hachages pourrait prendre un certain temps. Ainsi, Git divise simplement ce problème par 256.
Pour rechercher le hachage ci-dessus, Git chercherait d'abord le répertoire nommé 7a à l'intérieur du répertoire .git/objects, qui peut avoir jusqu'à 256 répertoires (de 00 à FF). Ensuite, il cherchera dans ce répertoire, réduisant la recherche au fur et à mesure.
Retour au processus de génération d'un commit. Vous venez de créer un objet. Quel est le type de cet objet ? Vous pouvez utiliser une autre commande de plomberie, git cat-file -t (-t signifie "type"), pour vérifier cela :
 _L'utilisation de
_L'utilisation de git cat-file -t <object_sha> révèle le type de l'objet Git_
Sans surprise, cet objet est un blob. Vous pouvez également utiliser git cat-file -p (-p signifie "pretty-print" ou impression jolie) pour voir son contenu :

git cat-file -p
Ce processus de création d'un objet blob sous .git/objects se produit généralement lorsque vous ajoutez quelque chose à la zone de transit — c'est-à-dire lorsque vous utilisez git add. Les blobs ne sont donc pas créés chaque fois que vous enregistrez un fichier sur le système de fichiers (le répertoire de travail), mais seulement lorsque vous le mettez en transit.
Rappelez-vous que Git crée un blob du fichier entier qui est mis en transit. Même si un seul caractère est modifié ou ajouté, le fichier a un nouveau blob avec un nouveau hachage (comme dans l'exemple du chapitre 1 où vous avez ajouté ! à la fin d'une ligne).
Y aura-t-il un changement dans git status ?
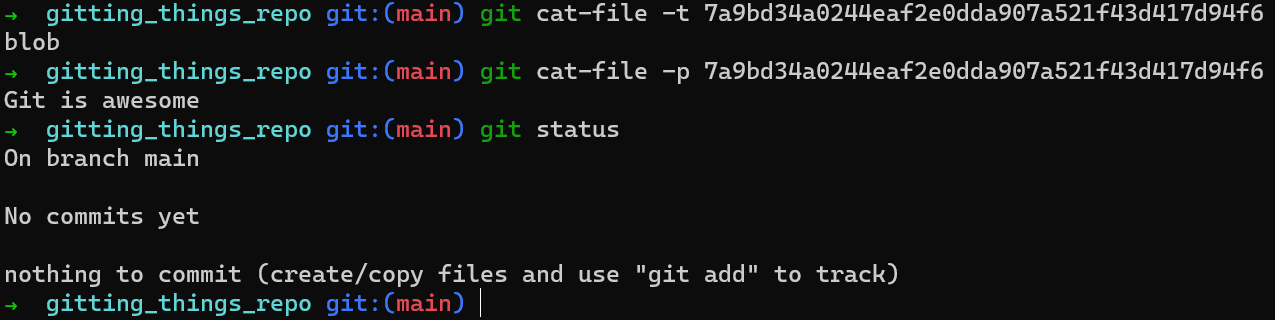
git status après la création d'un objet blob
Apparemment, non. Ajouter un objet blob à la base de données interne de Git ne change pas le statut, car Git ne connaît aucun fichier suivi (ou non suivi) à ce stade.
Vous devez suivre ce fichier — l'ajouter à la zone de transit. Pour ce faire, vous pouvez utiliser une autre commande de plomberie, git update-index, comme ceci :
git update-index --add --cacheinfo 100644 <blob-hash> <filename>
Note : Le cacheinfo est un mode de fichier de 16 bits tel que stocké par Git, suivant la disposition des types et modes POSIX. Ce n'est pas dans le cadre de ce livre, car ce n'est vraiment pas important pour vous pour "Git things done".
L'exécution de la commande ci-dessus entraînera un changement dans le contenu de .git :
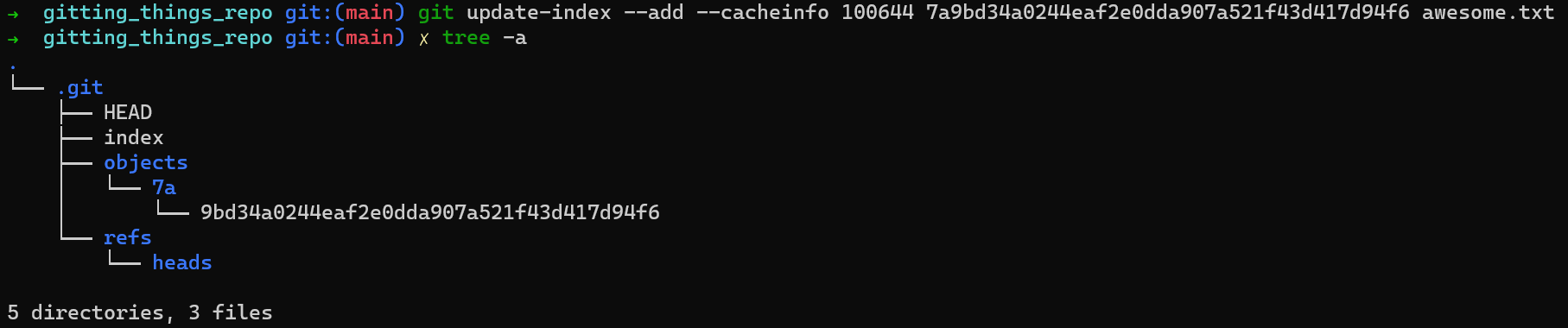 L'état de
L'état de .git après la mise à jour de l'index
Pouvez-vous repérer le changement ? Un nouveau fichier du nom de index a été créé. C'est ça — le fameux index (ou zone de transit), est essentiellement un fichier qui réside dans .git/index.
Donc maintenant que votre blob a été ajouté à l'index, vous attendez-vous à ce que git status soit différent ?
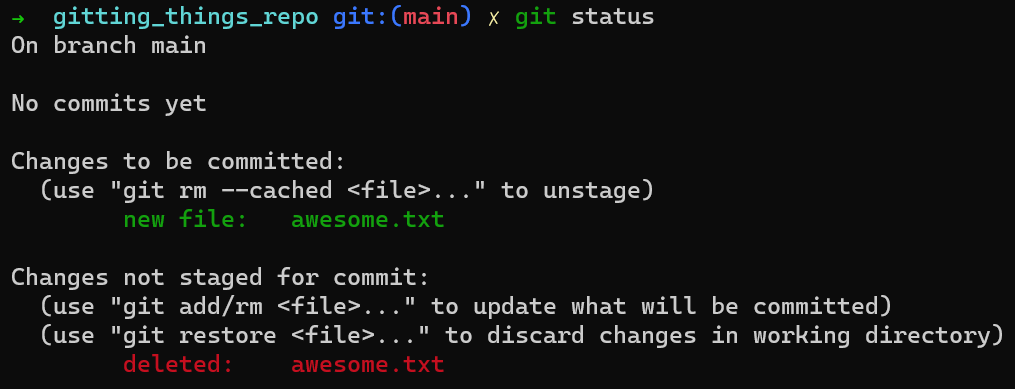
git status après avoir utilisé git update-index
C'est intéressant ! Deux choses se sont produites ici.
Premièrement, vous pouvez voir que awesome.txt apparaît en vert, dans la zone "Changes to be committed" (Changements à valider). C'est parce que l'index inclut maintenant awesome.txt, en attente d'être validé.
Deuxièmement, nous pouvons voir que awesome.txt apparaît en rouge — parce que Git croit que le fichier awesome.txt a été supprimé, et le fait que le fichier a été supprimé n'est pas mis en transit.
(Note : Vous avez peut-être remarqué que je fais parfois référence à Git avec des mots tels que "croit", "pense" ou "veut". Comme je l'ai expliqué dans l'introduction de ce livre - pour que nous puissions prendre plaisir à jouer avec Git, et à lire (et écrire) ce livre, j'ai l'impression que faire référence à Git comme étant plus que du simple code rend le tout beaucoup plus agréable.)
Cela se produit car vous avez ajouté le blob avec le contenu Git is awesome à la base de données des objets, et mis à jour l'index indiquant que le fichier awesome.txt contient le contenu de ce blob, mais vous n'avez jamais réellement créé ce fichier sur le disque.
Vous pouvez facilement résoudre ce problème en prenant le contenu du blob et en l'écrivant sur notre système de fichiers, dans un fichier appelé awesome.txt :
echo "Git is awesome" > awesome.txt
En conséquence, il n'apparaîtra plus en rouge par git status :
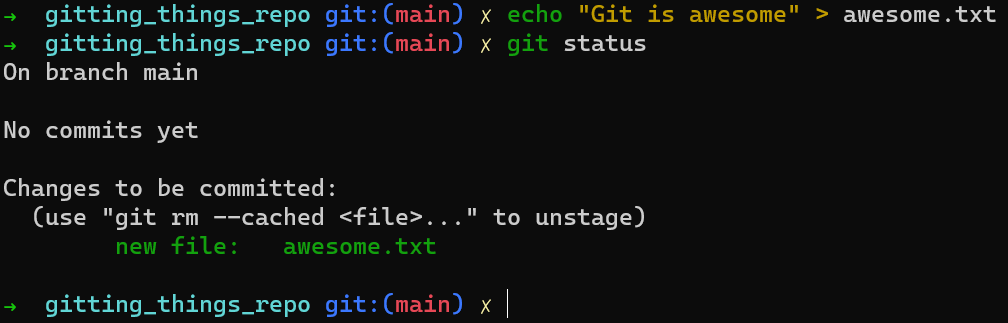
git status après avoir créé awesome.txt sur le disque
Il est donc maintenant temps de créer un objet commit à partir de votre zone de transit. Comme expliqué au chapitre 1, un objet commit a une référence à un arbre, vous devez donc créer un arbre.
Vous pouvez y parvenir en utilisant la commande git write-tree, qui enregistre le contenu de l'index dans un objet arbre. Bien sûr, vous pouvez utiliser git cat-file -t pour voir que c'est bien un arbre :
 Création d'un objet arbre avec le contenu de l'index
Création d'un objet arbre avec le contenu de l'index
Et vous pouvez utiliser git cat-file -p pour voir son contenu :

git cat-file -p pour voir le contenu de l'arbre
Super, vous avez donc créé un arbre, et maintenant vous devez créer un objet commit qui référence cet arbre. Pour ce faire, vous pouvez utiliser la commande :
git commit-tree <tree-hash> -m <commit message>
 Validation en utilisant l'objet arbre
Validation en utilisant l'objet arbre
Vous devriez maintenant vous sentir à l'aise avec les commandes utilisées pour vérifier le type de l'objet créé et imprimer son contenu :
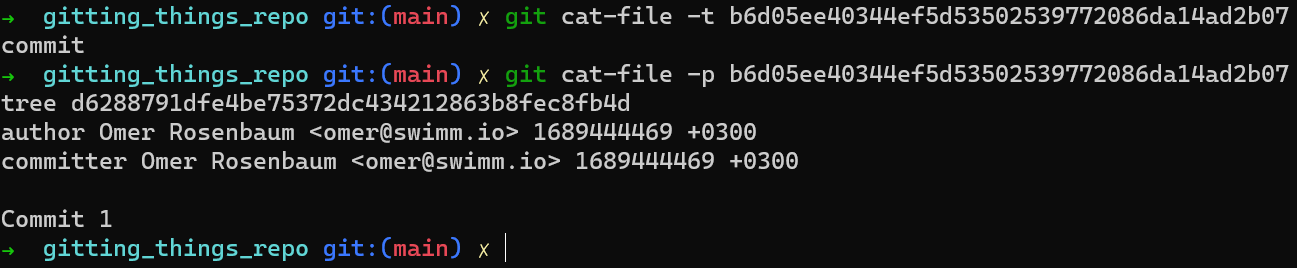 Création d'un objet commit
Création d'un objet commit
Notez que cet objet commit n'a pas de parent, car c'est le premier commit. Lorsque vous ajouterez un autre commit, vous voudrez probablement déclarer son parent — ne vous inquiétez pas, vous le ferez plus tard.
Le dernier hachage que nous avons obtenu — b6d05ee40344ef5d53502539772086da14ad2b07 – est un hachage de commit. Vous devriez en fait être habitué à utiliser ces hachages — vous les regardez probablement tout le temps (lorsque vous utilisez git log, par exemple). Notez que cet objet commit pointe vers un objet arbre, avec son propre hachage, que vous spécifiez rarement explicitement.
Quelque chose changera-t-il dans git status ?
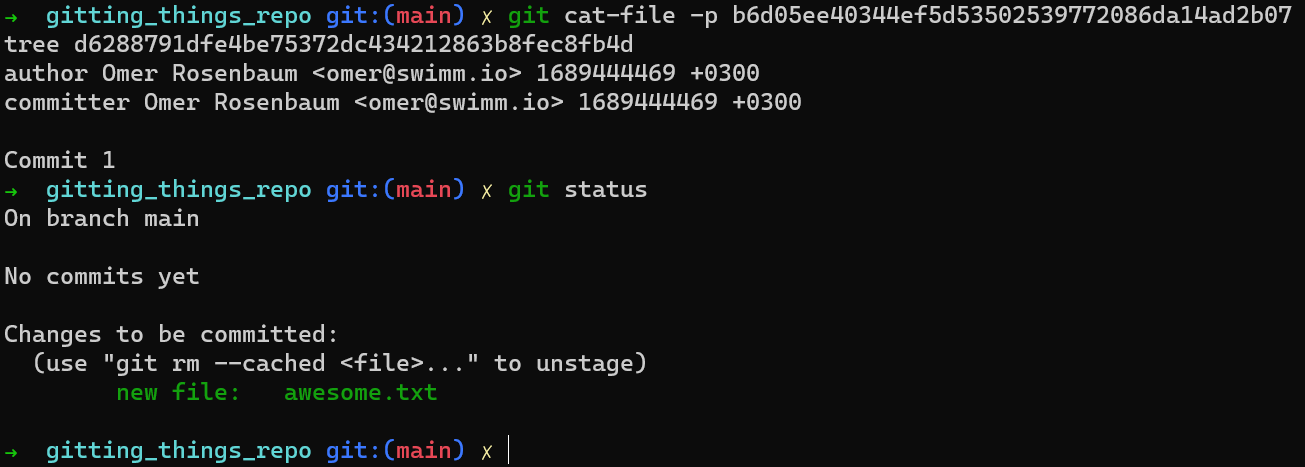
git status après la création d'un objet commit
Non, rien n'a changé. Pourquoi cela ?
Eh bien, pour savoir que votre fichier a été validé (committed), Git doit connaître le dernier commit. Comment Git fait-il cela ? Il va à HEAD :
 Regarder le contenu de
Regarder le contenu de HEAD
HEAD pointe vers main, mais qu'est-ce que main ? Vous ne l'avez pas vraiment encore créé.
Comme nous l'avons expliqué plus tôt au chapitre 2, une branche est simplement une référence nommée à un commit. Et dans ce cas, nous aimerions que main fasse référence à l'objet commit avec le hachage b6d05ee40344ef5d53502539772086da14ad2b07.
Vous pouvez y parvenir en créant un fichier à .git/refs/heads/main, avec le contenu de ce hachage, comme ceci :
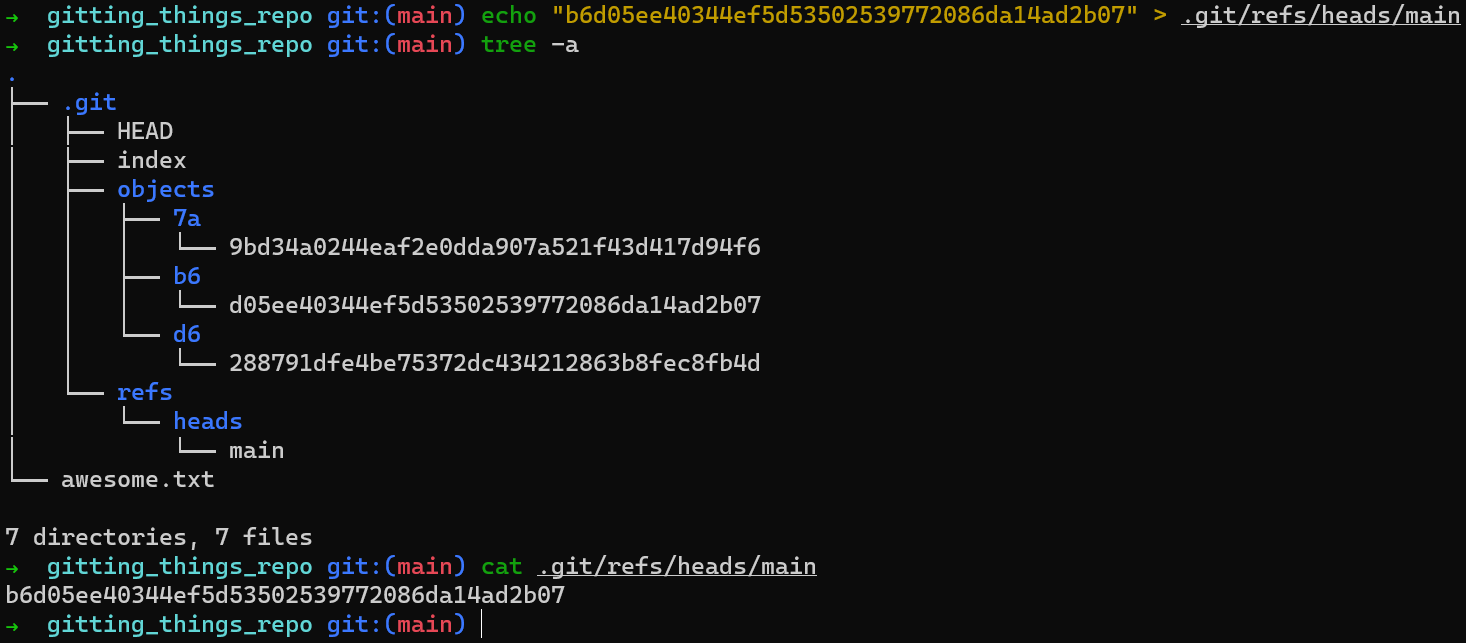 Création de
Création de main
En somme, une branche est juste un fichier à l'intérieur de .git/refs/heads, contenant un hachage du commit auquel il fait référence.
Maintenant, enfin, git status et git log semblent apprécier nos efforts :

git status

git log
Vous avez réussi à créer un commit sans utiliser de commandes de porcelaine ! C'est pas cool ça ?
Récapitulatif - Comment créer un repo en partant de zéro
Dans ce chapitre, vous avez plongé sans crainte dans Git. Vous avez arrêté d'utiliser des commandes de porcelaine et êtes passé aux commandes de plomberie.
En utilisant echo et des commandes de bas niveau telles que git hash-object, vous avez pu créer un blob, l'ajouter à l'index, créer un arbre de l'index et créer un objet commit pointant vers cet arbre.
Vous avez également appris que HEAD est un fichier, situé dans .git/HEAD. Les branches sont également des fichiers, situés sous .git/refs/heads. Lorsque vous comprenez comment Git fonctionne, ces notions abstraites de HEAD ou de "branches" deviennent très tangibles.
Le prochain chapitre approfondira votre compréhension du fonctionnement des branches sous le capot.
Chapitre 5 - Comment travailler avec les branches dans Git — Sous le capot
Dans le chapitre précédent, vous avez créé un dépôt et un commit sans utiliser git init, git add ou git commit. Dans ce chapitre, nous allons créer et basculer entre les branches sans utiliser de commandes de porcelaine (git branch, git switch ou git checkout).
Il est parfaitement compréhensible que vous soyez excité, je le suis aussi !
En continuant du chapitre précédent - vous n'avez qu'une seule branche, nommée main. Pour en créer une autre avec le nom test (comme l'équivalent de git branch test), vous devrez créer un fichier nommé test dans .git/refs/heads, et le contenu de ce fichier serait le hachage du même commit que celui vers lequel pointe la branche main.
 Création de la branche
Création de la branche test
Si vous utilisez git log, vous pouvez voir que c'est bien le cas — main et test pointent tous deux vers ce commit :

git log après avoir créé la branche test
(Note : si vous exécutez cette commande et ne voyez pas de sortie valide, vous avez peut-être écrit autre chose que le hachage du commit dans .git/refs/heads/test.)
Ensuite, passez à notre branche nouvellement créée (l'équivalent de git checkout test). Comment feriez-vous cela ? Essayez de répondre par vous-même avant de passer au paragraphe suivant.
Pour changer la branche active, vous devez changer HEAD pour pointer vers votre nouvelle branche :
 Passer à la branche
Passer à la branche test en changeant HEAD
Comme vous pouvez le voir, git status confirme que HEAD pointe maintenant vers test, qui est, par conséquent, la branche active.
Vous pouvez maintenant utiliser les commandes que vous avez déjà utilisées dans le chapitre précédent pour créer un autre fichier et l'ajouter à l'index :
 Écriture et mise en transit d'un autre fichier
Écriture et mise en transit d'un autre fichier
Suite aux commandes ci-dessus, vous :
- Créez un blob avec le contenu de
Another File(en utilisantgit hash-object). - L'ajoutez à l'index sous le nom
another_file.txt(en utilisantgit update-index). - Créez un fichier correspondant sur le disque avec le contenu du blob (en utilisant
git cat-file -p). - Créez un objet arbre représentant l'index (en utilisant
git write-tree).
Il est maintenant temps de créer un commit référençant cet arbre. Cette fois, vous devez également spécifier le parent de ce commit — qui serait le commit précédent. Vous spécifiez le parent en utilisant l'option -p de git commit-tree :
 Création d'un autre objet commit
Création d'un autre objet commit
Nous venons de créer un commit, avec un arbre ainsi qu'un parent, comme vous pouvez le voir :
 Observation du nouvel objet commit
Observation du nouvel objet commit
(Note : la valeur SHA-1 de votre objet commit sera différente de celle indiquée dans la capture d'écran ci-dessus, car elle inclut l'horodatage du commit, et aussi les détails de l'auteur - qui seraient différents sur votre machine.)
Est-ce que git log nous montrera le nouveau commit ?

git log après avoir créé "Commit 2"
Comme vous pouvez le voir, git log ne montre rien de nouveau. Pourquoi cela ?
Rappelez-vous que git log trace les branches pour trouver les commits pertinents à afficher. Il nous montre maintenant test et le commit vers lequel il pointe, et il montre aussi main qui pointe vers le même commit.
C'est exact — vous devez changer test pour pointer vers le nouvel objet commit. Vous pouvez le faire en changeant le contenu de .git/refs/heads/test :
echo 22267a945af8fde78b62ee7f705bbecfdd276b3d > .git/refs/heads/test
Et maintenant si vous exécutez git log :
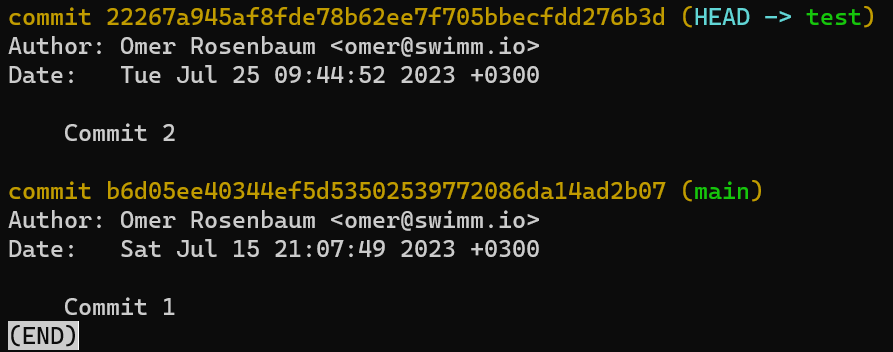
git log après la mise à jour de la branche test
Ça a marché !
git log va à HEAD, qui dit à Git d'aller à la branche test, qui pointe vers le commit 222..3d, qui renvoie à son commit parent b6d..07.
N'hésitez pas à admirer la beauté, I Git you. 😊
En inspectant le dossier de votre dépôt, vous pouvez voir que vous avez six objets différents sous le dossier .git/objects - ce sont les deux blobs que vous avez créés (un pour awesome.txt et un pour file.txt), deux objets commit ("Commit 1" et "Commit 2"), et les objets arbre - chacun pointé par l'un des objets commit.
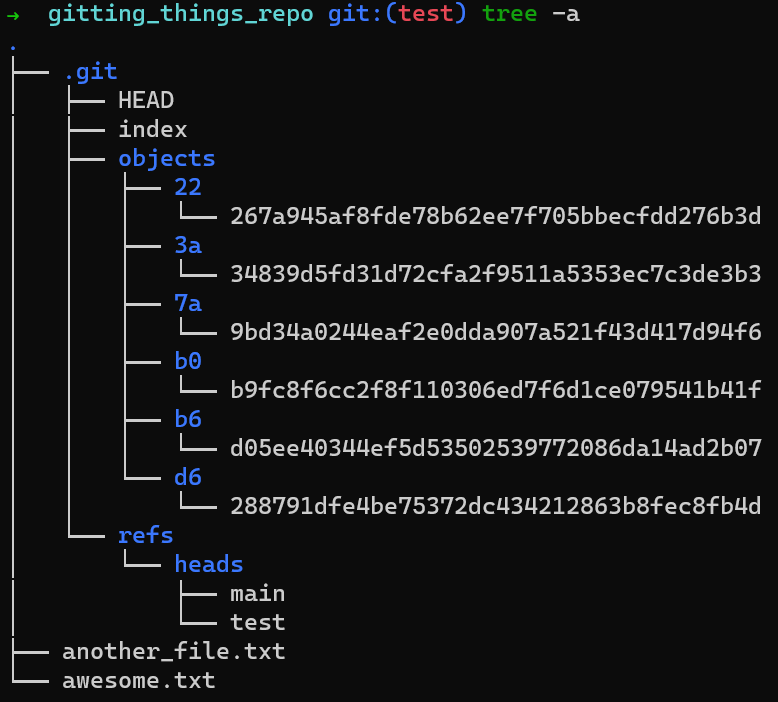 La liste de l'arbre après la création de "Commit 2"
La liste de l'arbre après la création de "Commit 2"
Vous avez également .git/HEAD qui pointe vers la branche active ou le commit, et deux branches - dans .git/refs/heads.
Récapitulatif - Comment travailler avec les branches dans Git — Sous le capot
Dans ce chapitre, vous avez compris comment les branches fonctionnent réellement dans Git.
Les principales choses que nous avons couvertes :
- Une branche est un fichier sous
.git/refs/heads, où le contenu du fichier est une valeur SHA-1 d'un commit. - Pour créer une nouvelle branche, Git crée simplement un nouveau fichier sous
.git/refs/headsavec le nom de la branche - par exemple,.git/refs/heads/my_branchpour la branchemy_branch. - Pour changer de branche active, Git modifie le contenu de
.git/HEADpour faire référence à la nouvelle branche active..git/HEADpeut également pointer directement vers un objet commit. - Lors de la validation avec
git commit, Git crée un objet commit, et déplace également la branche actuelle (c'est-à-dire le contenu du fichier sous.git/refs/heads) pour pointer vers l'objet commit nouvellement créé.
Partie 1 - Résumé
Cette partie vous a présenté les rouages internes de Git. Nous avons commencé par couvrir les objets de base — blobs, arbres et commits.
Vous avez appris qu'un blob contient le contenu d'un fichier. Un arbre est une liste de répertoire, contenant des blobs et/ou des sous-arbres. Un commit est un instantané de notre répertoire de travail, avec certaines métadonnées telles que l'heure ou le message de commit.
Vous avez appris à propos des branches, voyant qu'elles ne sont rien d'autre qu'une référence nommée à un commit.
Vous avez appris le processus d'enregistrement des changements dans Git, et qu'il implique le répertoire de travail, un répertoire auquel un dépôt est associé, la zone de transit (index) qui contient l'arbre pour le prochain commit, et le dépôt, qui est une collection de commits et de références.
Nous avons clarifié comment ces termes se rapportent aux commandes Git que nous connaissons en créant un nouveau dépôt et en validant un fichier en utilisant les bien connus git init, git add et git commit.
Ensuite, vous avez créé un nouveau dépôt à partir de zéro, en utilisant echo et des commandes de bas niveau telles que git hash-object. Vous avez créé un blob, l'avez ajouté à l'index, avez créé un objet arbre représentant l'index, et avez même créé un objet commit pointant vers cet arbre.
Vous avez également pu créer et basculer entre les branches en modifiant directement les fichiers. Bravo à ceux d'entre vous qui ont essayé cela par eux-mêmes !
Dans l'ensemble, après avoir suivi cette partie, vous devriez sentir que vous avez approfondi votre compréhension de ce qui se passe sous le capot lorsque vous travaillez avec Git.
La prochaine partie explorera différentes stratégies pour intégrer les changements lorsque l'on travaille dans différentes branches dans Git - spécifiquement, merge et rebase.
Partie 2 - Brancher et intégrer les changements
Chapitre 6 - Diffs et Patches
Dans la partie 1, vous avez appris comment Git fonctionne sous le capot, les différents objets Git, et comment créer un repo à partir de zéro.
Lorsque les équipes travaillent avec Git, elles introduisent des séquences de changements, généralement dans des branches, puis elles doivent combiner différents historiques de changements ensemble. Pour vraiment comprendre comment cela est réalisé, vous devriez apprendre comment Git traite les diffs et les patches. Vous appliquerez ensuite vos connaissances pour comprendre le processus de merge (fusion) et de rebase (rebasage).
De nombreux processus intéressants dans Git comme la fusion, le rebasage ou même la validation sont basés sur les diffs et les patches. Les développeurs travaillent tout le temps avec des diffs, que ce soit en utilisant Git directement ou en s'appuyant sur la vue diff de l'IDE. Dans ce chapitre, vous apprendrez ce que sont les diffs et les patches Git, leur structure et comment appliquer des patches.
Pour rappel du chapitre sur les objets Git, un commit est un instantané de l'arbre de travail à un certain moment, en plus de certaines métadonnées.
Pourtant, il est vraiment difficile de donner un sens aux commits individuels en regardant l'arbre de travail entier. Il est plutôt plus utile de regarder en quoi un commit est différent de son commit parent, c'est-à-dire le diff entre ces commits.
Alors, qu'est-ce que je veux dire quand je dis "diff" ? Commençons par un peu d'histoire.
Histoire de Git Diff
Le diff de Git est basé sur l'utilitaire diff sur les systèmes UNIX. diff a été développé au début des années 1970 sur le système d'exploitation Unix. La première version publiée a été livrée avec la cinquième édition d'Unix en 1974.
git diff est une commande qui prend deux entrées et calcule la différence entre elles. Les entrées peuvent être des commits, mais aussi des fichiers, et même des fichiers qui n'ont jamais été introduits dans le dépôt.
 Git diff prend deux entrées, qui peuvent être des commits ou des fichiers
Git diff prend deux entrées, qui peuvent être des commits ou des fichiers
Ceci est important - git diff calcule la différence entre deux chaînes, qui se trouvent la plupart du temps être constituées de code, mais pas nécessairement.
Il est temps de mettre la main à la pâte
Comme toujours, vous êtes encouragé à exécuter les commandes vous-même pendant la lecture de ce chapitre. Sauf indication contraire, j'utiliserai le dépôt suivant :
https://github.com/Omerr/gitting_things_repo.git
Vous pouvez le cloner localement et avoir le même point de départ que celui que j'utilise pour ce chapitre.
Considérez ce court fichier texte sur ma machine, appelé file.txt, qui se compose de 6 lignes :
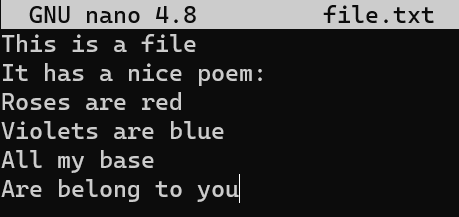
file.txt se compose de six lignes
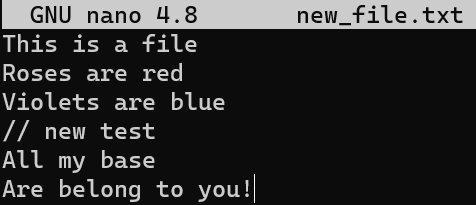
Maintenant, modifiez un peu ce fichier. Supprimez la deuxième ligne et insérez une nouvelle ligne comme quatrième ligne. Ajoutez un point d'exclamation (!) à la fin de la dernière ligne, de sorte que vous obteniez ce résultat :
 Après avoir modifié
Après avoir modifié file.txt, nous obtenons six lignes différentes
Enregistrez ce fichier avec un nouveau nom, new_file.txt.
Maintenant, vous pouvez exécuter git diff pour calculer la différence entre les fichiers comme ceci :
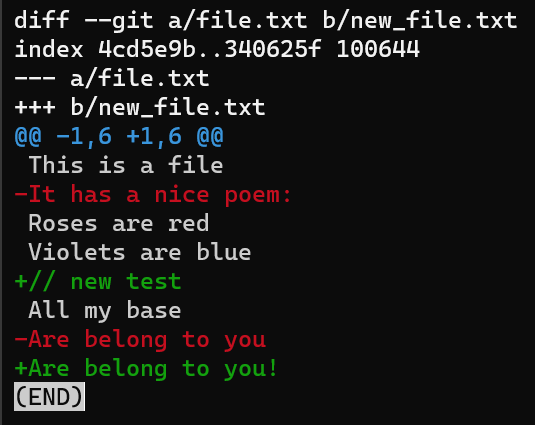
git diff --no-index file.txt new_file.txt
(J'expliquerai l'option --no-index de cette commande plus tard. Pour l'instant, il suffit de comprendre qu'elle nous permet de comparer deux fichiers qui ne font pas partie d'un dépôt Git.)
 _La sortie de
_La sortie de git diff --no-index file.txt new_file.txt_
La sortie de git diff montre pas mal de choses.
Concentrez-vous sur la partie commençant par This is a file. Vous pouvez voir que la ligne ajoutée (// new test) est précédée d'un signe +. La ligne supprimée est précédée d'un signe -.
Fait intéressant, remarquez que Git considère une ligne modifiée comme une séquence de deux changements - effacer une ligne et ajouter une nouvelle ligne à la place. Donc, le patch inclut la suppression de la dernière ligne et l'ajout d'une nouvelle ligne qui est égale à cette ligne, avec l'ajout d'un !.
 Les lignes d'ajout sont précédées par
Les lignes d'ajout sont précédées par +, les lignes de suppression par -, et les lignes de modification sont des séquences de suppressions et d'ajouts
Il serait maintenant temps de discuter des termes "patch" et "diff". Ces deux termes sont souvent utilisés de manière interchangeable, bien qu'il y ait une distinction, du moins historiquement.
Un diff montre les différences entre deux fichiers, ou instantanés, et peut être assez minimaliste en le faisant. Un patch est une extension d'un diff, augmentée d'informations supplémentaires telles que des lignes de contexte et des noms de fichiers, ce qui lui permet d'être appliqué plus largement. C'est un document texte qui décrit comment modifier un fichier ou une base de code existante.
De nos jours, le programme Unix diff, et git diff, peuvent produire des patches de divers types.
Un patch est une représentation compacte des différences entre deux fichiers. Il décrit comment transformer un fichier en un autre.
En d'autres termes, si vous appliquez les "instructions" produites par git diff sur file.txt - c'est-à-dire supprimer la deuxième ligne, insérer // new test comme quatrième ligne, supprimer la dernière ligne et ajouter à la place une ligne avec le même contenu et un ! - vous obtiendrez le contenu de new_file.txt.
Une autre chose importante à noter est qu'un patch est asymétrique : le patch de file.txt vers new_file.txt n'est pas le même que le patch pour l'autre direction. Générer un patch entre new_file.txt et file.txt, dans cet ordre, signifierait exactement les instructions opposées qu'auparavant - ajouter la deuxième ligne au lieu de la supprimer, et ainsi de suite.
 Un patch consiste en des instructions asymétriques pour passer d'un fichier à un autre
Un patch consiste en des instructions asymétriques pour passer d'un fichier à un autre
Essayez :
git diff --no-index new_file.txt file.txt
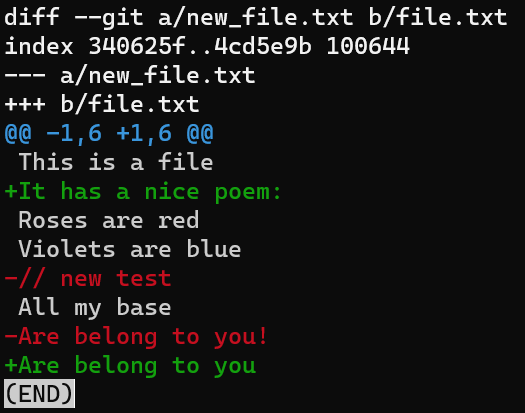 L'exécution de git diff dans la direction inverse donne les instructions inverses - ajouter une ligne au lieu de la supprimer, et ainsi de suite
L'exécution de git diff dans la direction inverse donne les instructions inverses - ajouter une ligne au lieu de la supprimer, et ainsi de suite
Le format de patch utilise le contexte, ainsi que les numéros de ligne, pour localiser les régions de fichier divergentes. Cela permet d'appliquer un patch à une version quelque peu antérieure ou postérieure du premier fichier par rapport à celle dont il est dérivé, tant que le programme d'application peut toujours localiser le contexte du changement. Nous verrons exactement comment ceux-ci sont utilisés.
La structure d'un Diff
Il est temps de plonger plus profondément.
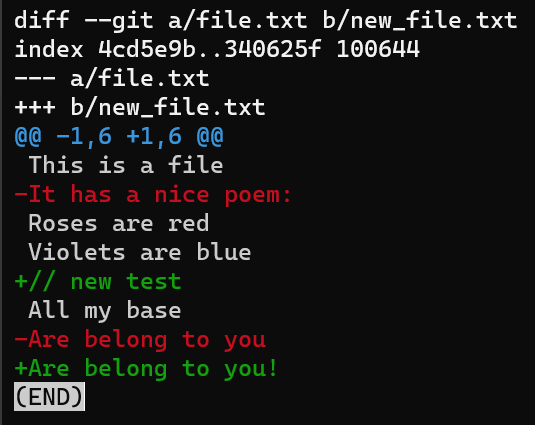
Générez à nouveau un diff de file.txt à new_file.txt, et considérez la sortie plus attentivement :
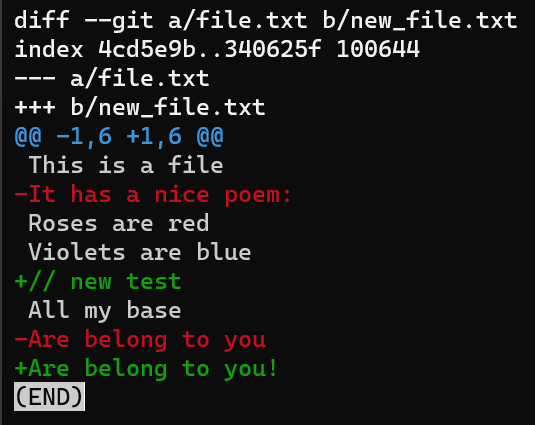
git diff --no-index file.txt new_file.txt
 _La sortie de
_La sortie de git diff --no-index file.txt new_file.txt_
La première ligne introduit les fichiers comparés. Git donne toujours à un fichier le nom a, et à l'autre le nom b. Donc dans ce cas file.txt est appelé a, tandis que new_file.txt est appelé b.
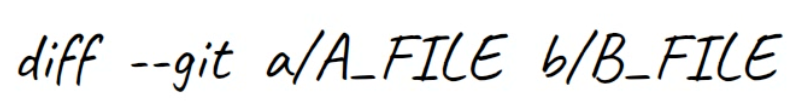 La première ligne de la sortie de
La première ligne de la sortie de diff introduit les fichiers comparés
Ensuite, la deuxième ligne, commençant par index, inclut les SHA des blobs de ces fichiers. Donc, même si dans notre cas ils ne sont même pas stockés dans un repo Git, Git montre leurs valeurs SHA-1 correspondantes.
La troisième valeur de cette ligne, 100644, représente les "bits de mode", indiquant qu'il s'agit d'un fichier "régulier" : non exécutable et pas un lien symbolique.
L'utilisation de deux points (..) ici entre les SHA des blobs est juste comme séparateur (contrairement à d'autres cas où il est utilisé dans Git).
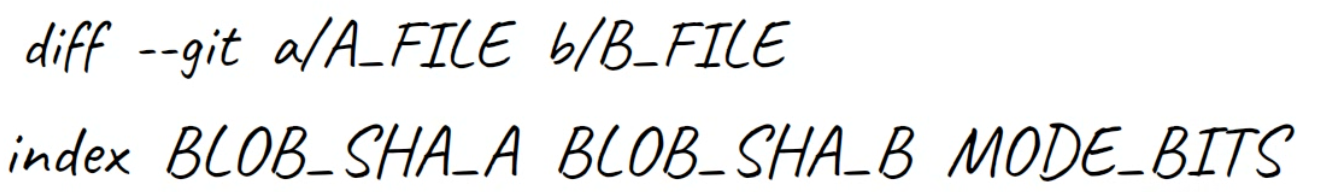 La deuxième ligne de la sortie de
La deuxième ligne de la sortie de diff inclut les SHA des blobs des fichiers comparés, ainsi que les bits de mode
D'autres lignes d'en-tête pourraient indiquer les anciens et nouveaux bits de mode s'ils ont changé, les anciens et nouveaux noms de fichiers si les fichiers ont été renommés, et ainsi de suite.
Les SHA des blobs (également appelés "IDs de blob") sont utiles si ce patch est appliqué ultérieurement par Git au même projet et qu'il y a des conflits lors de son application. Vous comprendrez mieux ce que cela signifie lorsque vous découvrirez les fusions dans le prochain chapitre.
Après les IDs de blob, nous avons deux lignes : l'une commençant par des signes -, et l'autre commençant par des signes +. C'est l'en-tête traditionnel "unified diff" (diff unifié), montrant à nouveau les fichiers comparés et la direction des changements : les signes - montrent les lignes dans la version A qui sont manquantes dans la version B, et les signes + montrent les lignes manquantes dans la version A mais présentes dans B.
Si le patch concernait l'ajout ou la suppression de ce fichier dans son intégralité, alors l'un d'eux serait /dev/null pour signaler cela.
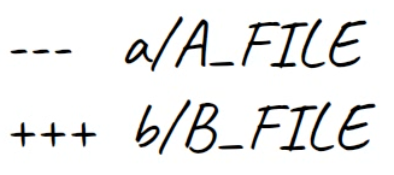 Les signes
Les signes - montrent les lignes de la version A mais manquantes dans la version B ; et les signes +, les lignes manquantes dans la version A mais présentes dans B
Considérez le cas où vous supprimez un fichier :
rm awesome.txt
Et ensuite utilisez git diff :
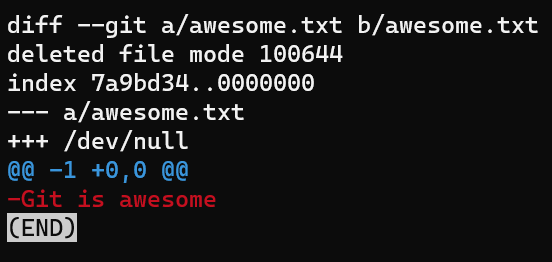 Sortie de
Sortie de git diff pour un fichier supprimé
La version A, représentant l'état de l'index, est actuellement awesome.txt, comparée au répertoire de travail où ce fichier n'existe pas, donc c'est /dev/null. Toutes les lignes sont précédées de signes - car elles n'existent que dans la version A.
Pour l'instant, annulez la suppression (plus d'informations sur l'annulation des changements dans la Partie 3) :
git restore awesome.txt
Revenons au diff avec lequel nous avons commencé :
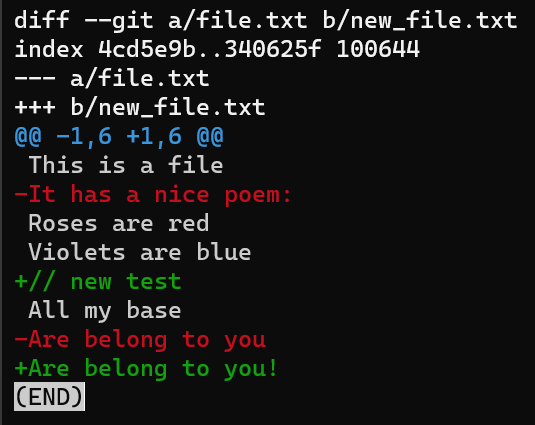 _La sortie de
_La sortie de git diff --no-index file.txt new_file.txt_
Après cet en-tête de diff unifié, nous arrivons à la partie principale du diff, constituée de "sections de différence", également appelées "hunks" ou "chunks" (morceaux) dans Git. Notez que ces termes sont utilisés de manière interchangeable, et vous pouvez tomber sur l'un ou l'autre dans la documentation et les tutoriels de Git, ainsi que dans le code source de Git.
Chaque morceau commence par une seule ligne, commençant par deux signes @. Ces signes sont suivis d'au plus quatre nombres, puis d'un en-tête pour le morceau - qui est une supposition éclairée par Git. Généralement, cela inclura le début d'une fonction ou d'une classe, lorsque c'est possible.
Dans cet exemple, cela n'inclut rien car il s'agit d'un fichier texte, alors considérez un autre exemple un instant :
git diff --no-index example.py example_changed.py
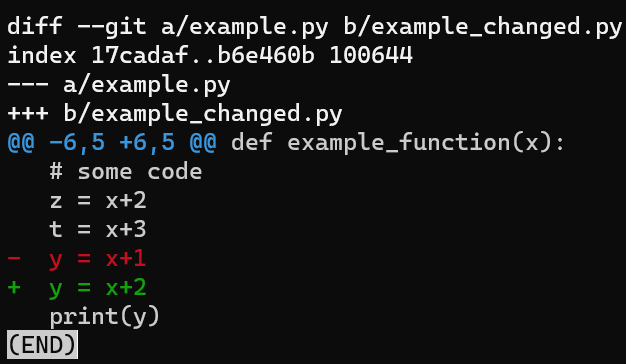 Lorsque c'est possible, Git inclut un en-tête pour chaque morceau, par exemple une définition de fonction ou de classe
Lorsque c'est possible, Git inclut un en-tête pour chaque morceau, par exemple une définition de fonction ou de classe
Dans l'image ci-dessus, l'en-tête du morceau inclut le début de la fonction qui inclut les lignes modifiées - def example_function(x).
Revenons donc à notre exemple précédent :
 Retour au diff précédent
Retour au diff précédent
Après les deux signes @, vous trouverez quatre nombres :
Les premiers nombres sont précédés d'un signe - car ils font référence au fichier A. Le premier nombre représente le numéro de ligne correspondant à la première ligne dans fichier A à laquelle ce morceau fait référence. Dans l'exemple ci-dessus, c'est 1, ce qui signifie que la ligne This is a file correspond au numéro de ligne 1 dans la version fichier A.
Ce nombre est suivi d'une virgule (,), puis du nombre de lignes que ce morceau comporte dans fichier A. Ce nombre inclut toutes les lignes de contexte (les lignes précédées d'un espace dans le diff), ou les lignes marquées d'un signe -, car elles font partie de fichier A, mais pas les lignes marquées d'un signe +, car elles n'existent pas dans fichier A.
Dans notre exemple, ce nombre est 6, comptant la ligne de contexte This is a file, la ligne - It has a nice poem:, puis les trois lignes de contexte, et enfin Are belong to you.
Comme vous pouvez le voir, les lignes commençant par un caractère espace sont des lignes de contexte, ce qui signifie qu'elles apparaissent telles qu'affichées à la fois dans fichier A et fichier B.
Ensuite, nous avons un signe + pour marquer les deux nombres qui font référence au fichier B. D'abord, il y a le numéro de ligne correspondant à la première ligne dans fichier B, suivi du nombre de lignes que ce morceau comporte dans fichier B.
Ce nombre inclut toutes les lignes de contexte, ainsi que les lignes marquées du signe +, car elles font partie de fichier B, mais pas les lignes marquées d'un signe -.
Ces quatre nombres sont suivis de deux signes @ supplémentaires.
Après l'en-tête du morceau, nous obtenons les lignes réelles - soit contextes, -, ou +.
Typiquement et par défaut, un morceau commence et se termine par trois lignes de contexte. Par exemple, si vous modifiez les lignes 4-5 dans un fichier de dix lignes :
- Ligne 1 - ligne de contexte (avant les lignes modifiées)
- Ligne 2 - ligne de contexte (avant les lignes modifiées)
- Ligne 3 - ligne de contexte (avant les lignes modifiées)
- Ligne 4 - ligne modifiée
- Ligne 5 - une autre ligne modifiée
- Ligne 6 - ligne de contexte (après les lignes modifiées)
- Ligne 7 - ligne de contexte (après les lignes modifiées)
- Ligne 8 - ligne de contexte (après les lignes modifiées)
- Ligne 9 - cette ligne ne fera pas partie du morceau
Donc par défaut, changer les lignes 4-5 résulte en un morceau composé des lignes 1-8, c'est-à-dire trois lignes avant et trois lignes après les lignes modifiées.
Si ce fichier n'a pas neuf lignes, mais plutôt six lignes - alors le morceau ne contiendra qu'une seule ligne de contexte après les lignes modifiées, et non trois. De même, si vous changez la deuxième ligne d'un fichier, alors il n'y aura qu'une seule ligne de contexte avant les lignes modifiées.
 Le format de patch par
Le format de patch par git diff
Comment produire des Diffs
Le dernier exemple que nous avons considéré montre un diff entre deux fichiers. Un seul fichier patch peut contenir les différences pour n'importe quel nombre de fichiers, et git diff produit des diffs pour tous les fichiers modifiés dans le dépôt en un seul patch.
Souvent, vous verrez la sortie de git diff montrant deux versions du même fichier et la différence entre elles.
Pour démontrer, considérez l'état dans une autre branche appelée diffs :
git checkout diffs
Encore une fois, je vous encourage à exécuter les commandes avec moi - assurez-vous de cloner le dépôt depuis :
https://github.com/Omerr/gitting_things_repo.git
À l'état actuel, le répertoire actif est un dépôt Git, avec un statut propre :

git status
Prenez un fichier existant, my_file.py :
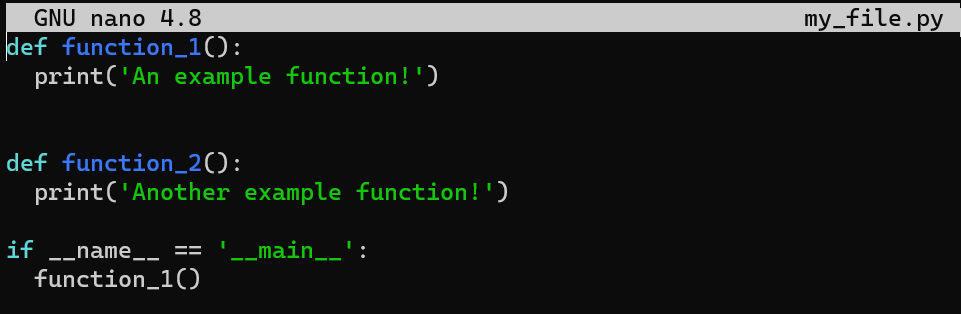 _Un exemple de fichier -
_Un exemple de fichier - my_file.py_
Et changez la deuxième ligne de print('An example function!') à print('An example function! And it has been changed!') :
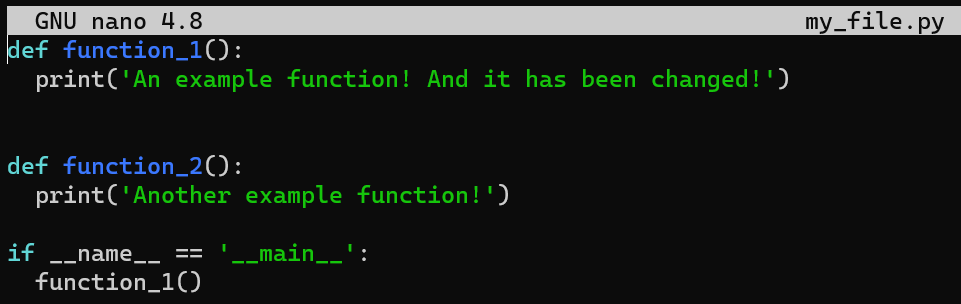 _Le contenu de
_Le contenu de my_file.py après modification de la deuxième ligne_
Enregistrez vos modifications, mais ne les mettez pas en transit (stage) et ne les validez pas (commit). Ensuite, exécutez git diff :
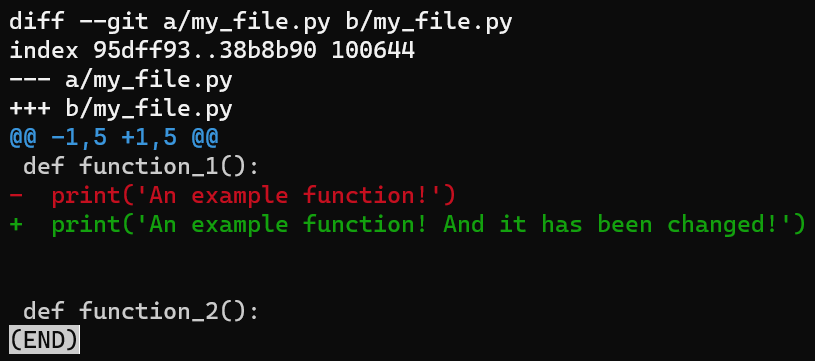 _La sortie de
_La sortie de git diff pour my_file.py après l'avoir modifié_
La sortie de git diff montre la différence entre la version de my_file.py dans la zone de transit, qui dans ce cas est la même que le dernier commit (HEAD), et la version dans le répertoire de travail.
J'ai couvert les termes "répertoire de travail", "zone de transit" et "commit" dans le chapitre sur les objets Git, donc consultez-le au cas où vous voudriez vous rafraîchir la mémoire. Pour rappel, les termes "zone de transit" et "index" sont interchangeables, et les deux sont largement utilisés.
 À cet état, le statut du répertoire de travail est différent du statut de l'index. Le statut de l'index est le même que celui de
À cet état, le statut du répertoire de travail est différent du statut de l'index. Le statut de l'index est le même que celui de HEAD
Pour voir la différence entre le répertoire de travail et la zone de transit, utilisez git diff, sans aucun drapeau supplémentaire.
 Sans options,
Sans options, git diff montre la différence entre la zone de transit et le répertoire de travail
Comme vous pouvez le voir, git diff liste ici à la fois fichier A et fichier B pointant vers my_file.py. Fichier A fait ici référence à la version de my_file.py dans la zone de transit, tandis que fichier B fait référence à sa version dans le répertoire de travail.
Notez que si vous modifiez my_file.py dans un éditeur de texte, et ne sauvegardez pas le fichier, alors git diff ne sera pas au courant des modifications que vous avez apportées. C'est parce qu'elles n'ont pas été enregistrées dans le répertoire de travail.
Nous pouvons fournir quelques options à git diff pour obtenir le diff entre le répertoire de travail et un commit spécifique, ou entre la zone de transit et le dernier commit, ou entre deux commits, et ainsi de suite.
Commencez par créer un nouveau fichier, new_file.txt, et enregistrez-le :
 _Un nouveau fichier simple enregistré sous
_Un nouveau fichier simple enregistré sous new_file.txt_
Actuellement le fichier est dans le répertoire de travail, et il est en fait non suivi (untracked) dans Git.
 Un nouveau fichier non suivi
Un nouveau fichier non suivi
Maintenant mettez en transit et validez ce fichier :
git add new_file.txt
git commit -m "Commit 3"
Maintenant, l'état de HEAD est le même que l'état de la zone de transit, ainsi que de l'arbre de travail :
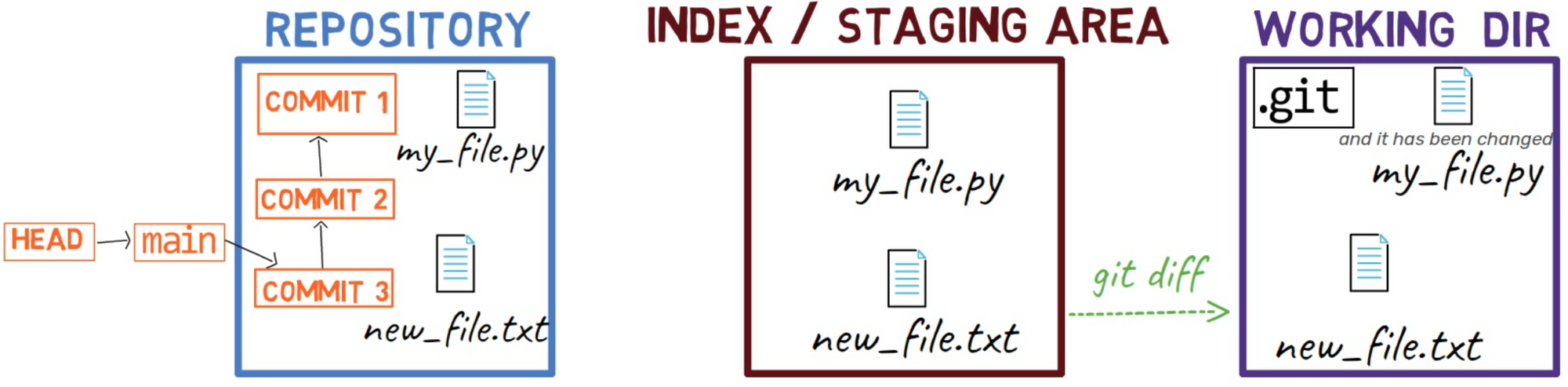 L'état de
L'état de HEAD est le même que l'index et le répertoire de travail
Ensuite, éditez new_file.txt en ajoutant une nouvelle ligne au début et une autre nouvelle ligne à la fin :
 _Modification de
_Modification de new_file.txt en ajoutant une ligne au début et une autre à la fin_
En conséquence, l'état est le suivant :
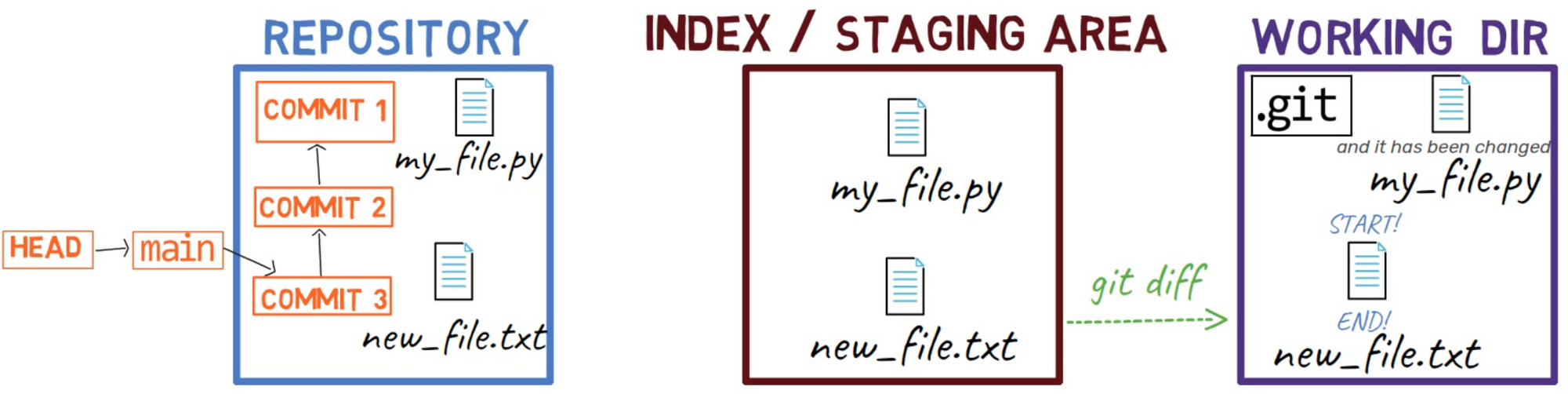 Après sauvegarde, l'état dans le répertoire de travail est différent de celui de l'index ou de
Après sauvegarde, l'état dans le répertoire de travail est différent de celui de l'index ou de HEAD
Une astuce sympa serait d'utiliser git add -p, qui vous permet de diviser les modifications même à l'intérieur d'un fichier, et de considérer celles que vous aimeriez mettre en transit.
Dans ce cas, ajoutez la première ligne à l'index, mais pas la dernière ligne. Pour faire cela, vous pouvez diviser le morceau en utilisant s, puis accepter de mettre en transit le premier morceau (en utilisant y), et pas la deuxième partie (en utilisant n).
Si vous n'êtes pas sûr de ce que chaque lettre signifie, vous pouvez toujours utiliser un ? et Git vous le dira.
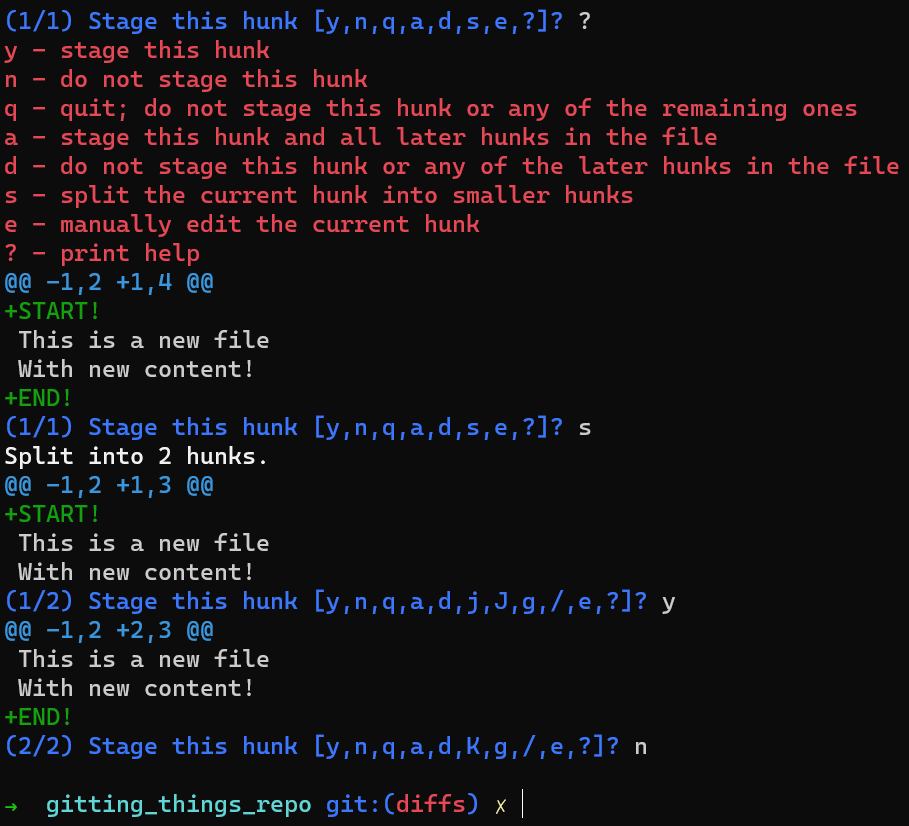 En utilisant
En utilisant git add -p, vous pouvez mettre en transit seulement le premier changement
Donc maintenant l'état dans HEAD est sans aucune de ces nouvelles lignes. Dans la zone de transit vous avez la première ligne mais pas la dernière ligne, et dans le répertoire de travail vous avez les deux nouvelles lignes.
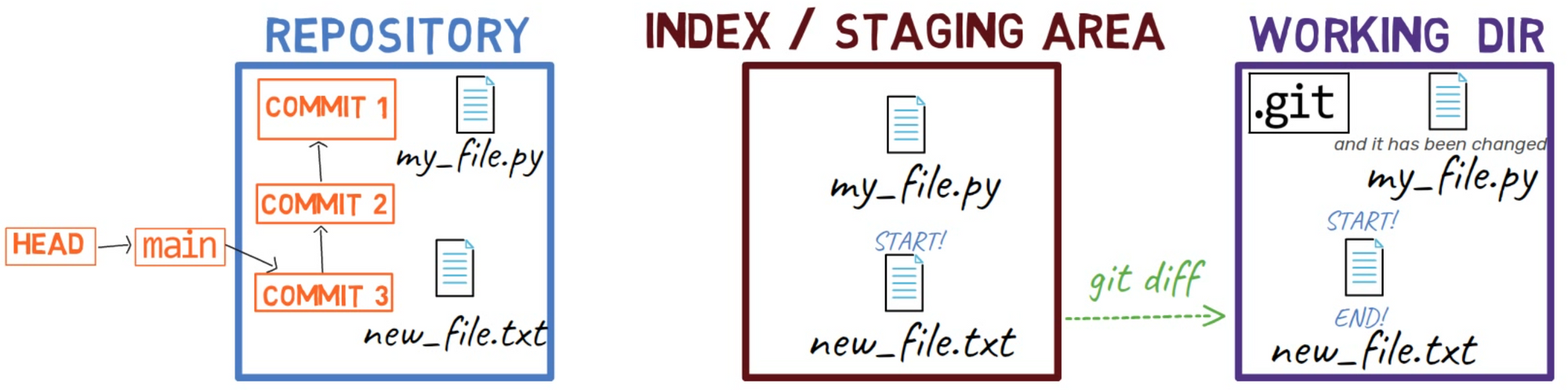 L'état après la mise en transit de la première ligne seulement
L'état après la mise en transit de la première ligne seulement
Si vous utilisez git diff, que se passera-t-il ?
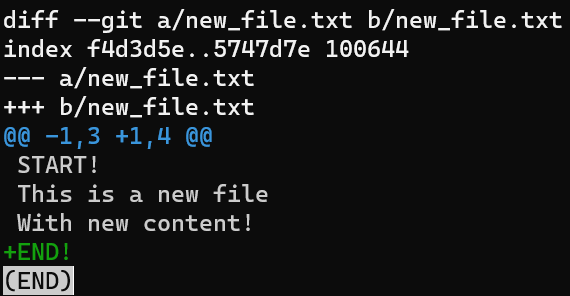
git diff montre la différence entre l'index et le répertoire de travail
Eh bien, comme indiqué précédemment, vous obtenez le diff entre la zone de transit et l'arbre de travail.
Que se passe-t-il si vous voulez obtenir le diff entre HEAD et la zone de transit ? Pour cela, vous pouvez utiliser git diff --cached :
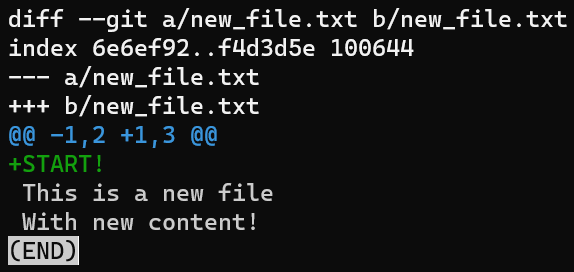
git diff --cached montre la différence entre HEAD et l'index
Et si vous voulez la différence entre HEAD et l'arbre de travail ? Pour cela vous pouvez exécuter git diff HEAD :
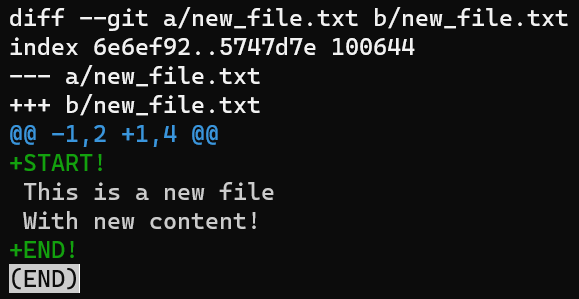
git diff HEAD montre la différence entre HEAD et le répertoire de travail
Pour résumer les différentes options pour git diff que nous avons vues jusqu'à présent, voici un diagramme :
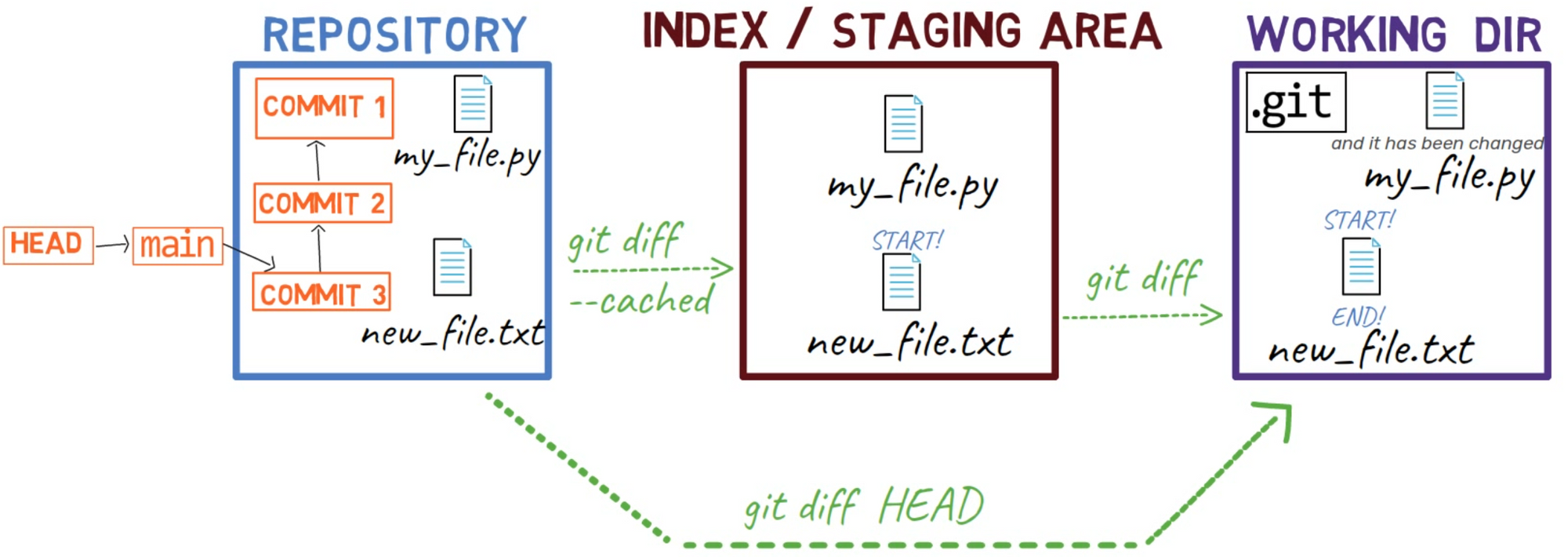 Différentes options pour
Différentes options pour git diff
Pour rappel, au début de ce chapitre vous avez utilisé git diff --no-index. Avec l'option --no-index, vous pouvez comparer deux fichiers qui ne font pas partie du dépôt - ou de toute zone de transit.
Maintenant, validez les changements que vous avez dans la zone de transit :
git commit -m "Commit 4"
Pour observer le diff entre ce commit et son commit parent, vous pouvez exécuter la commande suivante :
git diff HEAD~1 HEAD
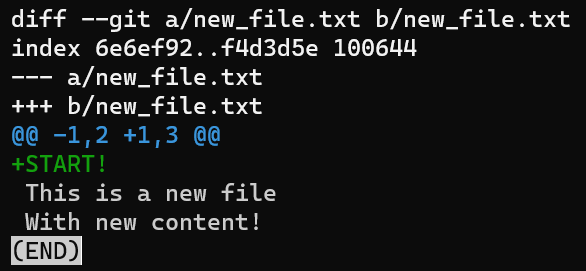 La sortie de
La sortie de git diff HEAD~1 HEAD
Au passage, vous pouvez omettre le 1 ci-dessus et écrire HEAD~, et obtenir le même résultat. Utiliser 1 est la manière explicite de dire que vous faites référence au premier parent du commit.
Notez que d'écrire le commit parent ici, HEAD~1, en premier résulte en un diff montrant comment aller du commit parent vers le commit actuel. Bien sûr, je pourrais aussi générer le diff inverse en écrivant :
git diff HEAD HEAD~1
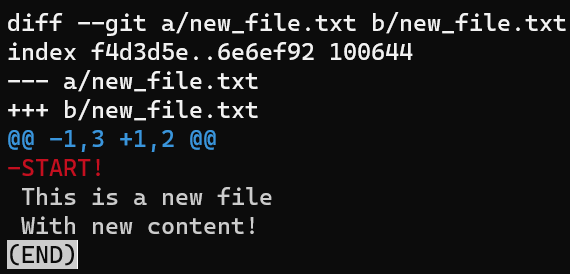 La sortie de
La sortie de git diff HEAD HEAD~1 génère le patch inverse
Pour résumer toutes les différentes options pour git diff que nous avons couvertes dans cette section, voir ce diagramme :
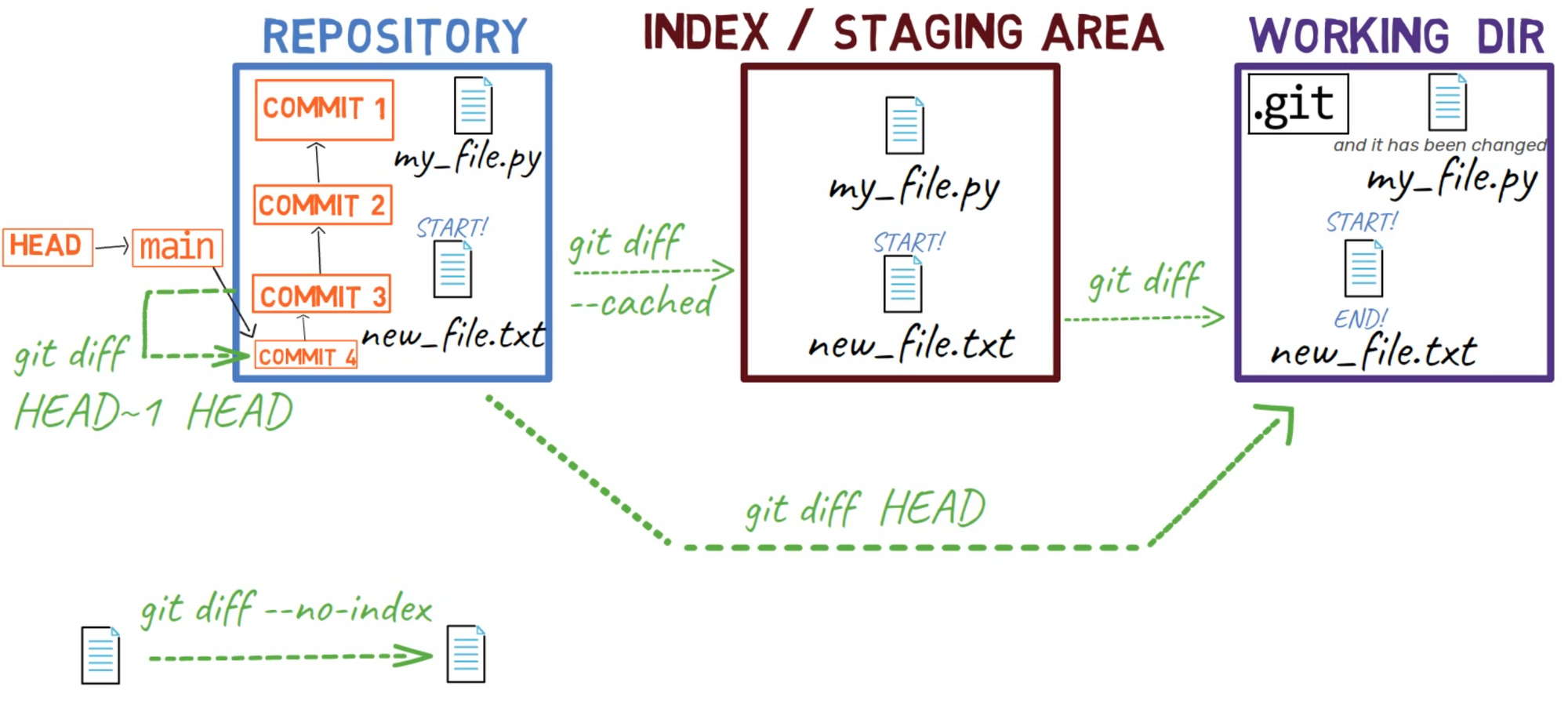 Les différentes options pour
Les différentes options pour git diff
Une manière courte de voir le diff entre un commit et son parent est d'utiliser git show, par exemple :
git show HEAD
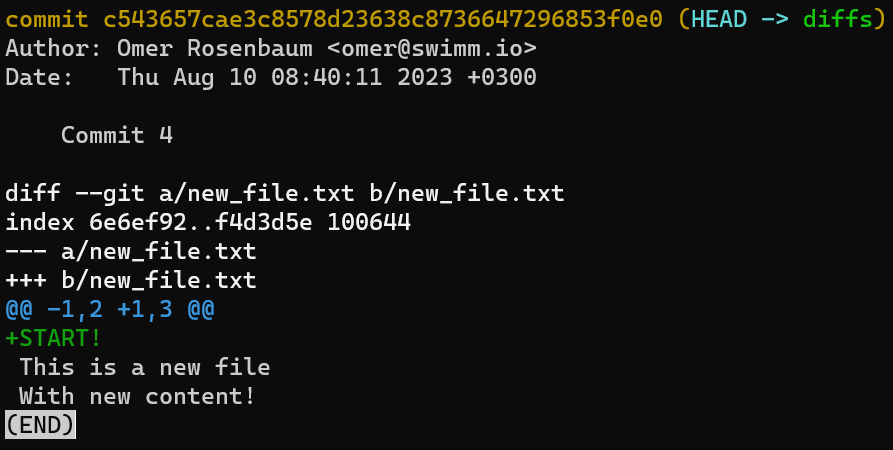
git show HEAD
C'est la même chose que d'écrire :
git diff HEAD~ HEAD
Nous pouvons maintenant mettre à jour notre diagramme :
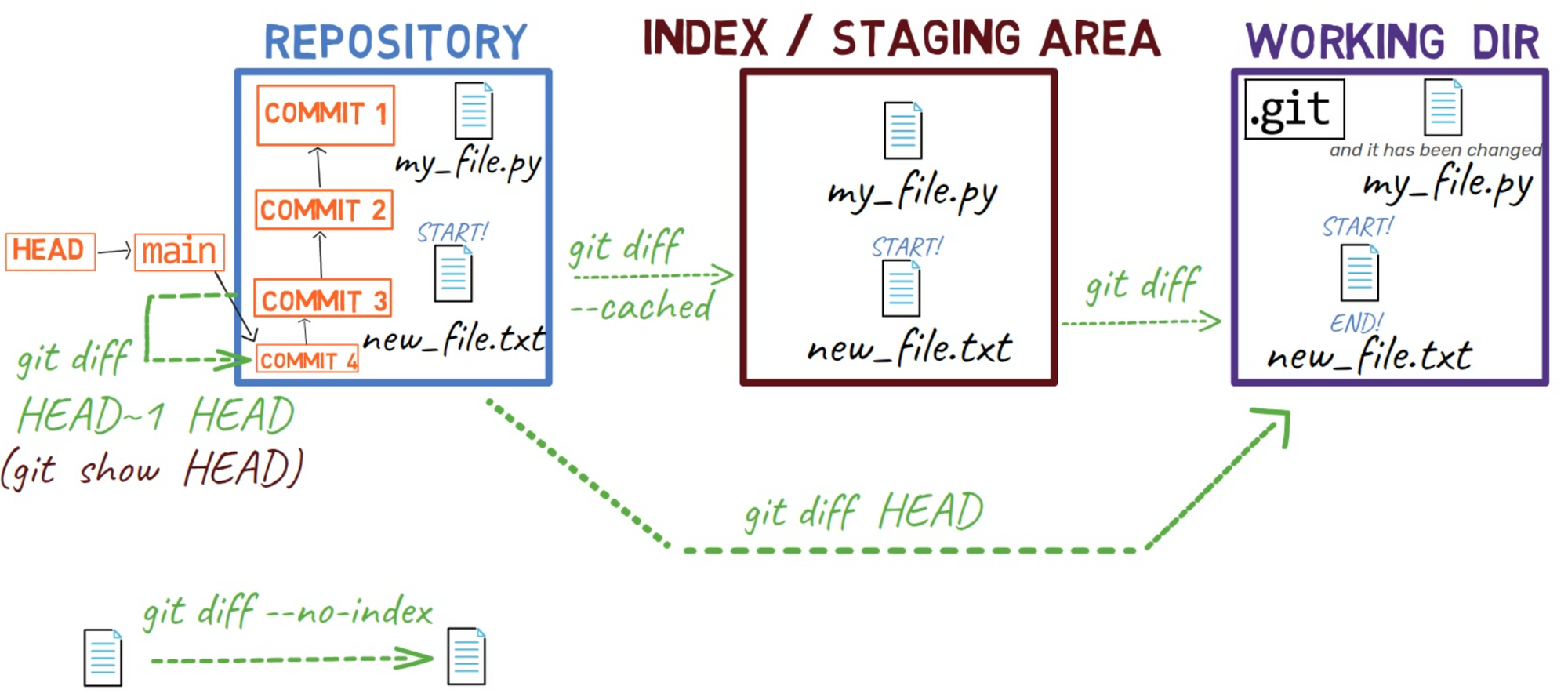
git diff HEAD~ HEAD est utilisé pour montrer la différence entre les commits
Vous pouvez revenir à ce diagramme comme référence si nécessaire.
Pour rappel, les commits Git sont des instantanés - de l'ensemble du répertoire de travail du dépôt, à un certain moment. Pourtant, il n'est parfois pas utile de considérer un commit comme un instantané entier, mais plutôt par les changements que ce commit spécifique a introduits. En d'autres termes, par le diff entre un commit parent et le commit suivant.
Comme vous l'avez appris dans le chapitre sur les objets Git, Git stocke les instantanés entiers. Le diff est généré dynamiquement à partir des données de l'instantané - en comparant les arbres racines du commit et de son parent.
Bien sûr, Git peut comparer n'importe quels deux instantanés dans le temps, pas seulement des commits adjacents, et aussi générer un diff de fichiers non inclus dans un dépôt.
Comment appliquer des Patches
En utilisant git diff, vous pouvez voir un patch que Git génère, et vous pouvez ensuite appliquer ce patch en utilisant git apply.
Note Historique
En fait, le partage de patches était le principal moyen de partager du code aux débuts de l'open source. Mais maintenant - pratiquement tous les projets sont passés au partage de commits Git directement via des pull requests (appelées "merge requests" sur certaines plateformes).
Le plus gros problème avec l'utilisation des patches est qu'il est difficile d'appliquer un patch lorsque votre répertoire de travail ne correspond pas au commit précédent de l'expéditeur. Perdre l'historique des commits rend difficile la résolution des conflits. Vous comprendrez mieux cela en plongeant plus profondément dans le processus de git apply, en particulier dans le prochain chapitre où nous couvrons les fusions.
Un Patch Simple
Que signifie appliquer un patch ? Il est temps d'essayer !
Prenez la sortie de git diff :
git diff HEAD~1 HEAD
Et stockez-la dans un fichier :
git diff HEAD~1 HEAD > my_patch.patch
Utilisez reset pour annuler le dernier commit :
git reset --hard HEAD~1
Ne vous inquiétez pas pour la dernière commande - je l'expliquerai en détail dans la Partie 3, où nous discutons de l'annulation des changements. En bref, cela nous permet de "réinitialiser" l'état de l'endroit où HEAD pointe, ainsi que l'état de l'index et du répertoire de travail. Dans l'exemple ci-dessus, ils sont tous réglés à l'état de HEAD~1, ou "Commit 3" dans le diagramme.
Donc après avoir exécuté la commande reset, le contenu du fichier est le suivant (l'état de "Commit 3") :
nano new_file.txt
 _
_new_file.txt_
Et vous allez appliquer ce patch que vous venez de sauvegarder :
nano my_patch.patch
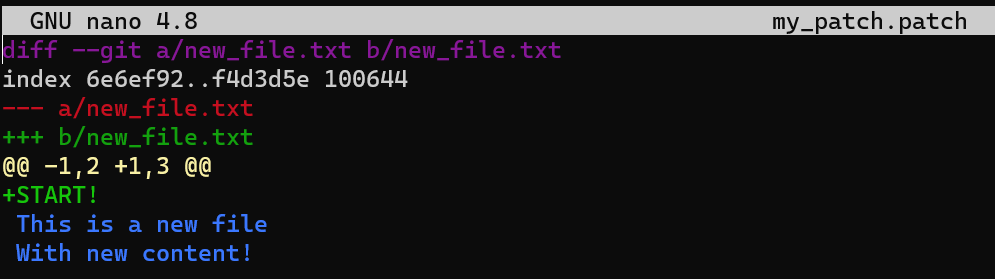 Le patch que vous êtes sur le point d'appliquer, tel que généré par git diff
Le patch que vous êtes sur le point d'appliquer, tel que généré par git diff
Ce patch dit à Git de trouver les lignes :
This is a new file
With new content!
Ces lignes étaient le numéro de ligne 1 et le numéro de ligne 2 dans new_file.txt, et d'ajouter une ligne avec le contenu START! juste au-dessus d'elles.
Exécutez cette commande pour appliquer le patch :
git apply my_patch.patch
Et en conséquence, vous obtenez cette version de votre fichier, tout comme le commit que vous avez créé auparavant :
nano new_file.txt
 _Le contenu de
_Le contenu de new_file.txt après l'application du patch_
Comprendre les lignes de contexte
Pour comprendre l'importance des lignes de contexte, considérez un scénario plus avancé. Que se passe-t-il si les numéros de ligne ont changé depuis que vous avez créé le fichier patch ?
Pour tester, commencez par créer un autre fichier :
nano test.text
 Création d'un autre fichier -
Création d'un autre fichier - test.txt
Mettez en transit et validez ce fichier :
git add test.txt
git commit -m "Test file"
Maintenant, changez ce fichier en ajoutant une nouvelle ligne, et aussi en effaçant la ligne avant la dernière :
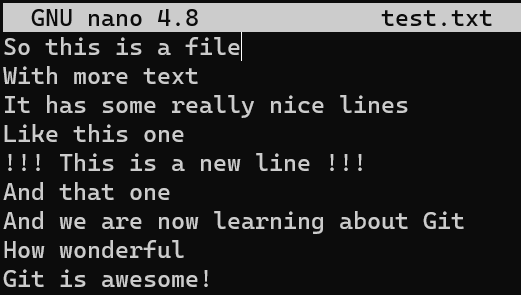 Changements à
Changements à test.txt
Observez la différence entre la version originale du fichier et la version incluant vos modifications :
git diff -- test.txt
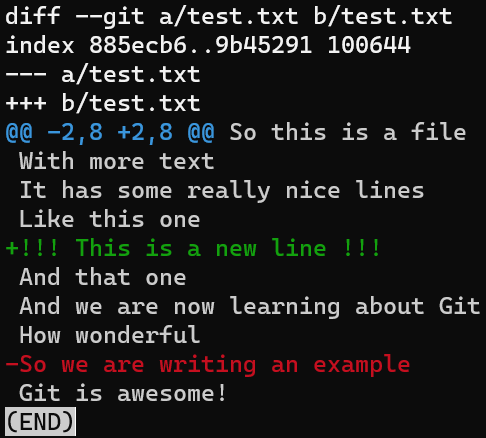 La sortie pour
La sortie pour git diff -- test.txt
(L'utilisation de -- test.txt indique à Git d'exécuter la commande diff, en prenant en considération uniquement test.txt, pour que vous n'obteniez pas le diff pour d'autres fichiers.)
Stockez ce diff dans un fichier patch :
git diff -- test.txt > new_patch.patch
Maintenant, réinitialisez votre état à celui avant l'introduction des changements :
git reset --hard
Si vous deviez appliquer new_patch.patch maintenant, cela fonctionnerait simplement.
Considérons maintenant un cas plus intéressant. Modifiez test.txt à nouveau en ajoutant une nouvelle ligne au début :
 Ajout d'une nouvelle ligne au début de
Ajout d'une nouvelle ligne au début de test.txt
En conséquence, les numéros de ligne sont différents de la version originale où le patch a été créé. Considérez le patch que vous avez créé auparavant :
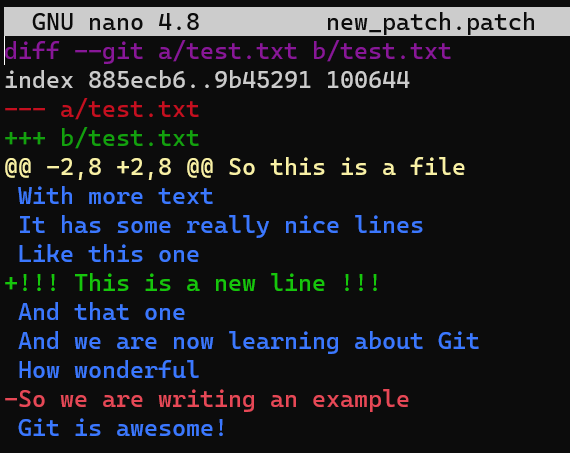 _
_new_patch.patch_
Il suppose que la ligne With more text est la deuxième ligne dans test.txt, ce qui n'est plus le cas. Alors... est-ce que git apply fonctionnera ?
git apply new_patch.patch
Ça a marché !
Par défaut, Git cherche 3 lignes de contexte avant et après chaque changement introduit dans le patch - comme vous pouvez le voir, elles sont incluses dans le fichier patch. Si vous prenez trois lignes avant et après la ligne ajoutée, et trois lignes avant et après la ligne supprimée (en fait une seule ligne après, car aucune autre ligne n'existe) - vous arrivez au fichier patch. Si toutes ces lignes existent - alors l'application du patch fonctionne, même si les numéros de ligne ont changé.
Réinitialisez l'état à nouveau :
git reset --hard
Que se passe-t-il si vous changez l'une des lignes de contexte ? Essayez en changeant la ligne With more text en With more text! :
 Changement de la ligne
Changement de la ligne With more text en With more text!
Et maintenant :
git apply new_patch.patch

git apply n'applique pas le patch
Eh bien, non. Le patch ne s'applique pas. Si vous n'êtes pas sûr pourquoi, ou voulez juste mieux comprendre le processus que Git effectue, vous pouvez ajouter le drapeau --verbose à git apply, comme ceci :
git apply --verbose new_patch.patch
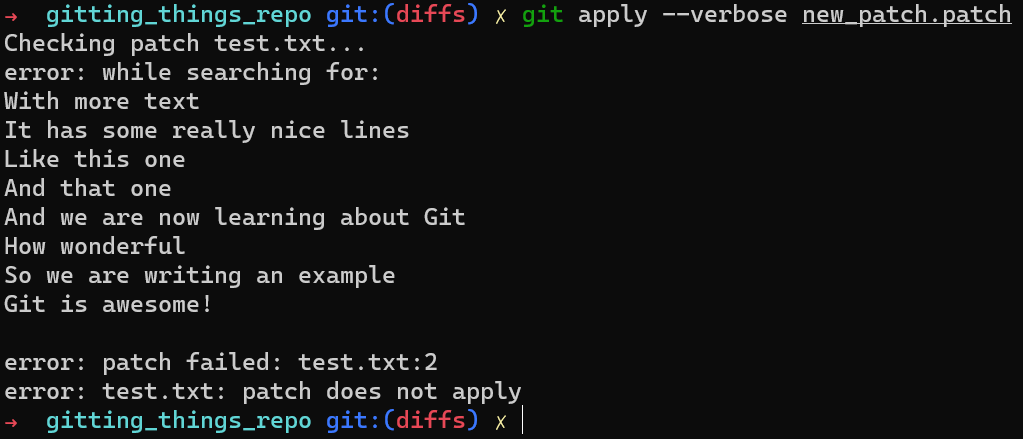
git apply --verbose montre le processus que Git prend pour appliquer le patch
Il semble que Git ait cherché des lignes du fichier, y compris la ligne "With more text", juste avant la ligne "It has some really nice lines". Cette séquence de lignes n'existe plus dans le fichier. Comme Git ne peut pas trouver cette séquence, il ne peut pas appliquer le patch.
Comme mentionné précédemment, par défaut, Git cherche 3 lignes de contexte avant et après chaque changement introduit dans le patch. Si les trois lignes environnantes n'existent pas, Git ne peut pas appliquer le patch.
Vous pouvez demander à Git de compter sur moins de lignes de contexte, en utilisant l'argument -C. Par exemple, pour demander à Git de chercher 1 ligne de contexte environnant, exécutez la commande suivante :
git apply -C1 new_patch.patch
Le patch s'applique !
 _
_git apply -C1 new_patch.patch_
Pourquoi cela ? Considérez le patch à nouveau :
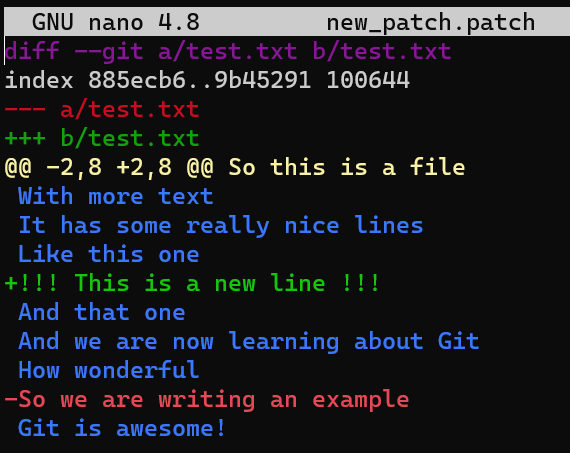 _
_new_patch.patch_
Lors de l'application du patch avec l'option -C1, Git recherche les lignes :
Like this one
And that one
afin d'ajouter la ligne !!!This is the new line!!! entre ces deux lignes. Ces lignes existent (et, surtout, elles apparaissent l'une juste après l'autre). En conséquence, Git peut réussir à ajouter la ligne entre elles, même si les numéros de ligne ont changé.
De même, Git chercherait les lignes :
How wonderful
So we are writing an example
Git is awesoome!
Comme Git peut trouver ces lignes, Git peut effacer celle du milieu.
Si nous changions l'une de ces lignes, disons, changé "How wonderful" en "How very wondeful", alors Git ne serait pas capable de trouver la chaîne ci-dessus, et ainsi le patch ne s'appliquerait pas.
Récapitulatif - Git Diff et Patch
Dans ce chapitre, vous avez appris ce qu'est un diff, et la différence entre un diff et un patch. Vous avez appris comment générer divers patches en utilisant différentes options pour git diff. Vous avez également appris à quoi ressemble la sortie de git diff et comment elle est construite. Finalement, vous avez appris comment les patches sont appliqués, et spécifiquement l'importance du contexte.
Comprendre les diffs est une étape majeure pour comprendre de nombreux autres processus au sein de Git - par exemple, la fusion (merging) ou le rebasage (rebasing), que nous explorerons dans les prochains chapitres.
Chapitre 7 - Comprendre Git Merge
En lisant ce chapitre, vous allez vraiment comprendre git merge, l'une des opérations les plus courantes que vous effectuerez dans vos dépôts Git.
Qu'est-ce qu'une fusion (merge) dans Git ?
La fusion est le processus consistant à combiner les changements récents de plusieurs branches en un seul nouveau commit. Ce commit pointe vers ces branches.
D'une certaine manière, la fusion est le complément du branchement (branching) dans le contrôle de version : une branche vous permet de travailler simultanément avec d'autres sur un ensemble particulier de fichiers, tandis qu'une fusion vous permet de combiner plus tard des travaux séparés sur des branches qui ont divergé d'un commit ancêtre commun.
OK, prenons cela petit à petit.
Rappelez-vous que dans Git, une branche n'est qu'un nom pointant vers un seul commit. Quand nous pensons aux commits comme étant "sur" une branche spécifique, ils sont en fait accessibles via la chaîne parente à partir du commit vers lequel la branche pointe.
C'est-à-dire, si vous considérez ce graphique de commit :
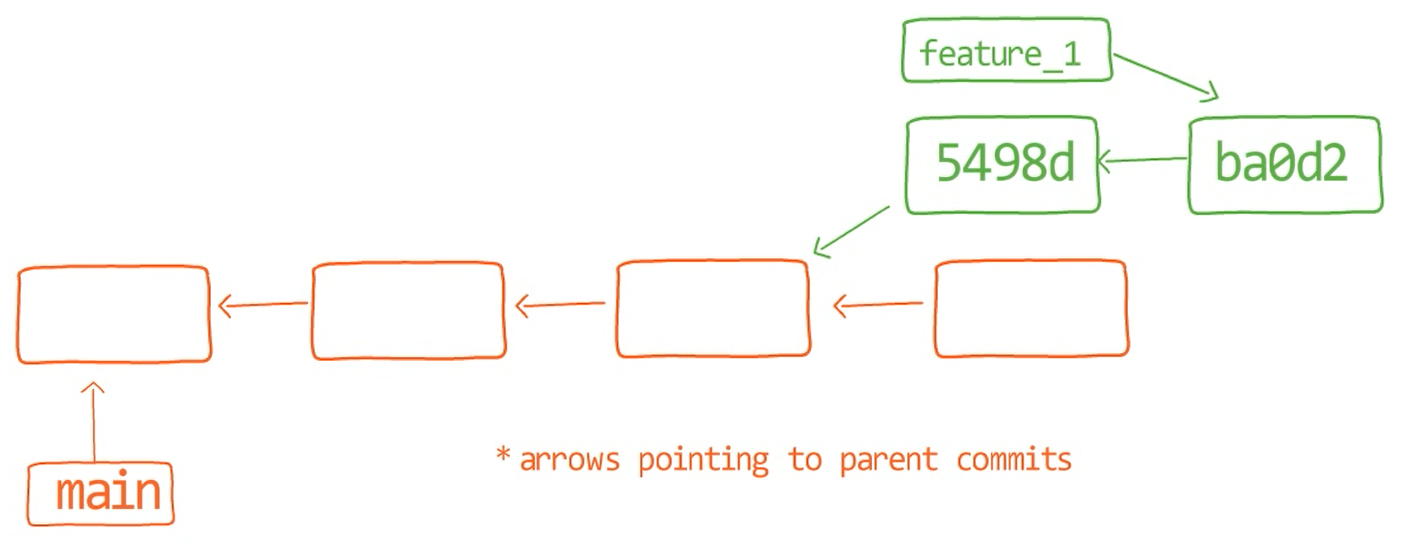 _Graphique de commit avec
_Graphique de commit avec feature_1_
Vous voyez la branche feature_1, qui pointe vers un commit avec la valeur SHA-1 de ba0d2. Comme dans les chapitres précédents, je n'écris que les 5 premiers chiffres de la valeur SHA-1 par souci de brièveté.
Remarquez que le commit 54a9d est également "sur" cette branche, car c'est le commit parent de ba0d2. Donc si vous commencez à partir du pointeur de feature_1, vous arrivez à ba0d2, qui pointe ensuite vers 54a9d. Vous pouvez continuer sur la chaîne des parents, et tous ces commits accessibles sont considérés comme étant "sur" feature_1.
Lorsque vous fusionnez avec Git, vous fusionnez des commits. Presque toujours, nous fusionnons deux commits en nous référant à eux par les noms de branche qui pointent vers eux. C'est pourquoi nous disons que nous "fusionnons des branches" - bien qu'en coulisses, nous fusionnons en fait des commits.
Il est temps de mettre la main à la pâte
Pour ce chapitre, j'utiliserai le dépôt suivant :
https://github.com/Omerr/gitting_things_merge.git
Comme dans les chapitres précédents, je vous encourage à le cloner localement et à avoir le même point de départ que celui que j'utilise pour ce chapitre.
OK, disons que j'ai ce dépôt simple ici, avec une branche appelée main, et quelques commits avec les messages de commit "Commit 1", "Commit 2" et "Commit 3" :
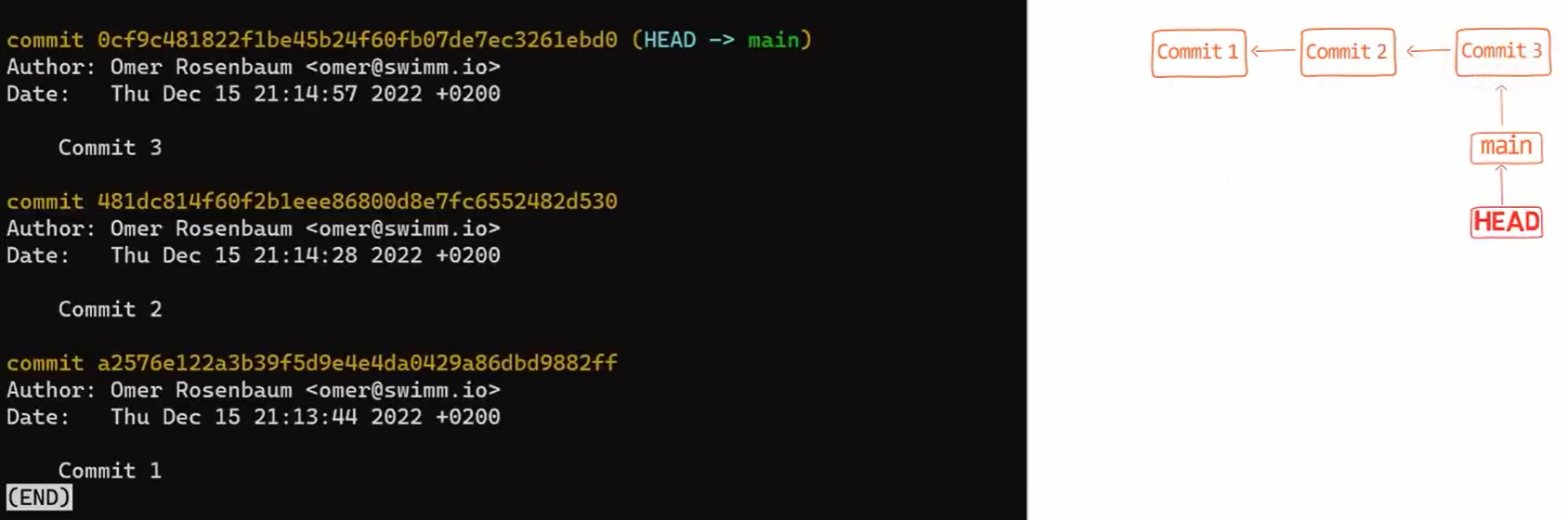 Un dépôt simple avec trois commits
Un dépôt simple avec trois commits
Ensuite, créez une branche de fonctionnalité en tapant git branch new_feature :
 Création d'une nouvelle branche avec
Création d'une nouvelle branche avec git branch
Et changez HEAD pour pointer vers cette nouvelle branche, en utilisant git checkout new_feature (ou git switch new_feature). Vous pouvez regarder le résultat en utilisant git log :
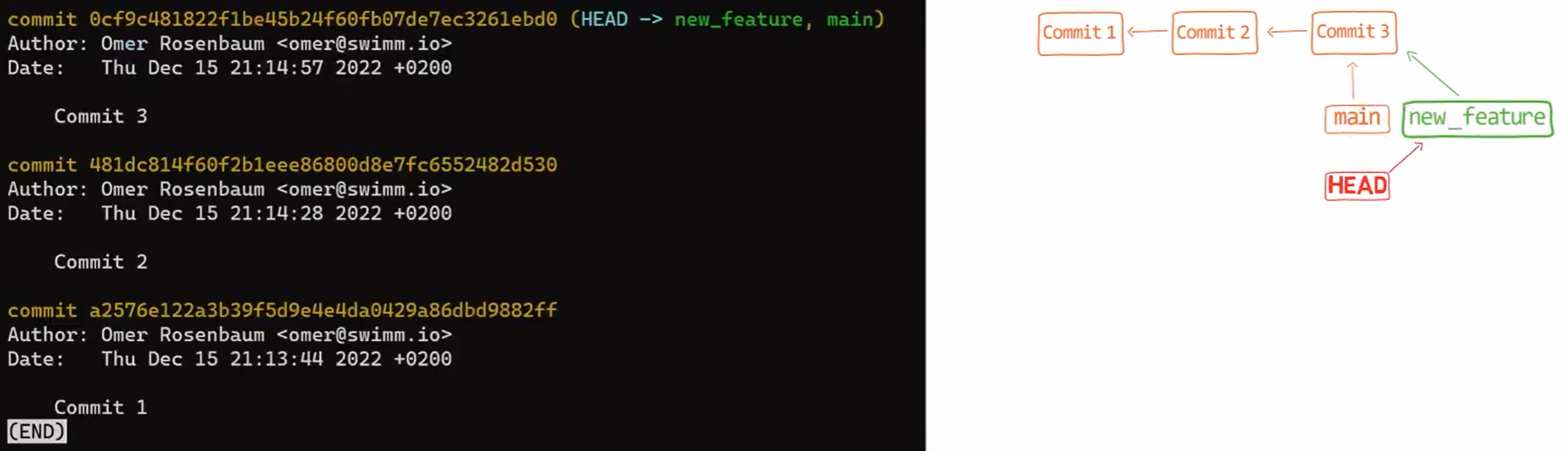 _La sortie de
_La sortie de git log après avoir utilisé git checkout new_feature_
Pour rappel, vous pourriez aussi écrire git checkout -b new_feature, qui créerait à la fois une nouvelle branche et changerait HEAD pour pointer vers cette nouvelle branche.
Si vous avez besoin d'un rappel sur les branches et comment elles sont implémentées sous le capot, veuillez consulter le chapitre 2. Oui, check out. Jeu de mots intentionnel 😇
Maintenant, sur la branche new_feature, implémentez une nouvelle fonctionnalité. Dans cet exemple, je vais éditer un fichier existant qui ressemble à ceci avant l'édition :
code.py avant de l'éditer
Et je vais maintenant l'éditer pour inclure une nouvelle fonction :
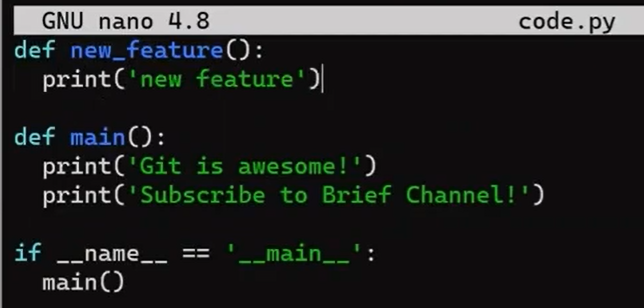 _Implémentation de
_Implémentation de new_feature_
Et heureusement, ce n'est pas un livre de programmation, donc cette fonction est légitime 😇
Ensuite, mettez en transit et validez ce changement :
git add code.py
git commit -m "Commit 4"
En regardant l'historique, vous avez la branche new_feature, pointant maintenant vers "Commit 4", qui pointe vers son parent, "Commit 3". La branche main pointe également vers "Commit 3".
 L'historique après la validation de "Commit 4"
L'historique après la validation de "Commit 4"
Il est temps de fusionner la nouvelle fonctionnalité ! C'est-à-dire, fusionner ces deux branches, main et new_feature. Ou, dans le jargon de Git, fusionner new_feature dans main. Cela signifie fusionner "Commit 4" et "Commit 3". C'est assez trivial, car après tout, "Commit 3" est un ancêtre de "Commit 4".
Faites un checkout de la branche main (avec git checkout main), et effectuez la fusion en utilisant git merge new_feature :
 _Fusion de
_Fusion de new_feature dans main_
Puisque new_feature n'a jamais vraiment divergé de main, Git a pu simplement effectuer une fusion en avance rapide (fast-forward merge). Alors que s'est-il passé ici ? Considérez l'historique :
 Le résultat d'une fusion en avance rapide
Le résultat d'une fusion en avance rapide
Même si vous avez utilisé git merge, il n'y a eu aucune fusion réelle ici. En fait, Git a fait quelque chose de très simple - il a réinitialisé (reset) la branche main pour pointer vers le même commit que la branche new_feature.
Au cas où vous ne voudriez pas que cela se produise, mais que vous vouliez plutôt que Git effectue réellement une fusion, vous pourriez soit changer la configuration de Git, soit exécuter la commande de fusion avec le drapeau --no-ff.
D'abord, annulez le dernier commit :
git reset --hard HEAD~1
Rappel : si cette façon d'utiliser reset n'est pas claire pour vous, ne vous inquiétez pas - nous la couvrirons en détail dans la Partie 3. Elle n'est pas cruciale pour cette introduction à la fusion, cependant. Pour l'instant, il est important de comprendre que cela annule essentiellement l'opération de fusion.
Juste pour clarifier, maintenant si vous faisiez un checkout de new_feature à nouveau :
git checkout new_feature
L'historique ressemblerait exactement à avant la fusion :
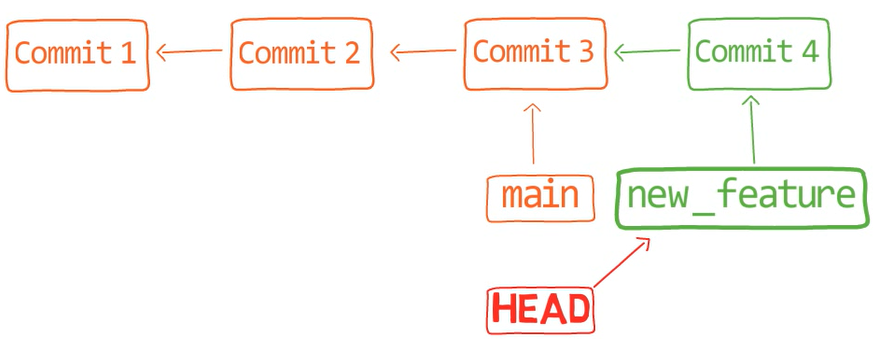 L'historique après l'utilisation de
L'historique après l'utilisation de git reset --hard HEAD~1
Ensuite, effectuez la fusion avec le drapeau --no-fast-forward (--no-ff en abrégé) :
git checkout main
git merge new_feature --no-ff
Maintenant, si nous regardons l'historique en utilisant git lol :
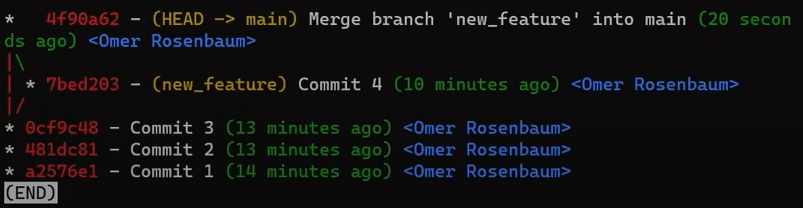 Historique après fusion avec le drapeau
Historique après fusion avec le drapeau --no-ff
(Rappel : git lol est un alias que j'ai ajouté à Git pour voir visiblement l'historique de manière graphique. Vous pouvez le trouver, avec les autres composants de ma configuration, à la partie Ma configuration du chapitre Introduction.)
En considérant cet historique, vous pouvez voir que Git a créé un nouveau commit, un commit de fusion.
Si vous considérez ce commit d'un peu plus près :
git log -n1
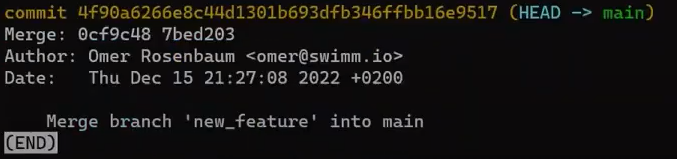 Le commit de fusion a deux parents
Le commit de fusion a deux parents
Vous verrez que ce commit a en fait deux parents - "Commit 4", qui était le commit vers lequel new_feature pointait lorsque vous avez exécuté git merge, et "Commit 3", qui était le commit vers lequel main pointait.
Un commit de fusion a deux parents : les deux commits qu'il a fusionnés.
Le commit de fusion nous montre assez bien le concept de fusion. Git prend deux commits, généralement référencés par deux branches différentes, et les fusionne ensemble.
Après la fusion, comme vous avez commencé le processus à partir de main, vous êtes toujours sur main, et l'historique de new_feature a été fusionné dans cette branche. Puisque vous avez commencé avec main, alors "Commit 3", vers lequel main pointait, est le premier parent du commit de fusion, tandis que "Commit 4", que vous avez fusionné dans main, est le second parent du commit de fusion.
Remarquez que vous avez commencé sur main quand il pointait vers "Commit 3", et Git a fait beaucoup de chemin pour vous. Il a changé l'arbre de travail, l'index, et aussi HEAD et a créé un nouvel objet commit. Au moins quand vous utilisez git merge sans le drapeau --no-commit et quand ce n'est pas une fusion en avance rapide, Git fait tout cela.
C'était un cas super simple, où les branches que vous avez fusionnées n'avaient pas divergé du tout. Nous considérerons bientôt des cas plus intéressants.
Au passage, vous pouvez utiliser git merge pour fusionner plus de deux commits - en fait, n'importe quel nombre de commits. C'est rarement fait, et pour adhérer au principe de praticité de ce livre, je n'entrerai pas là-dedans.
Une autre façon de penser à git merge est de joindre deux ou plusieurs historiques de développement ensemble. C'est-à-dire, quand vous fusionnez, vous incorporez des changements des commits nommés, depuis le moment où leurs historiques ont divergé de la branche actuelle, dans la branche actuelle. J'ai utilisé le terme "branche" ici, mais j'insiste à nouveau là-dessus - nous fusionnons en fait des commits.
Il est temps pour un cas plus avancé
Il est temps de considérer un cas plus avancé, qui est probablement le cas le plus courant où nous utilisons git merge explicitement - où vous devez fusionner des branches qui ont divergé l'une de l'autre.
Supposons que nous ayons deux personnes travaillant sur ce repo maintenant, John et Paul.
John a créé une branche :
git checkout -b john_branch
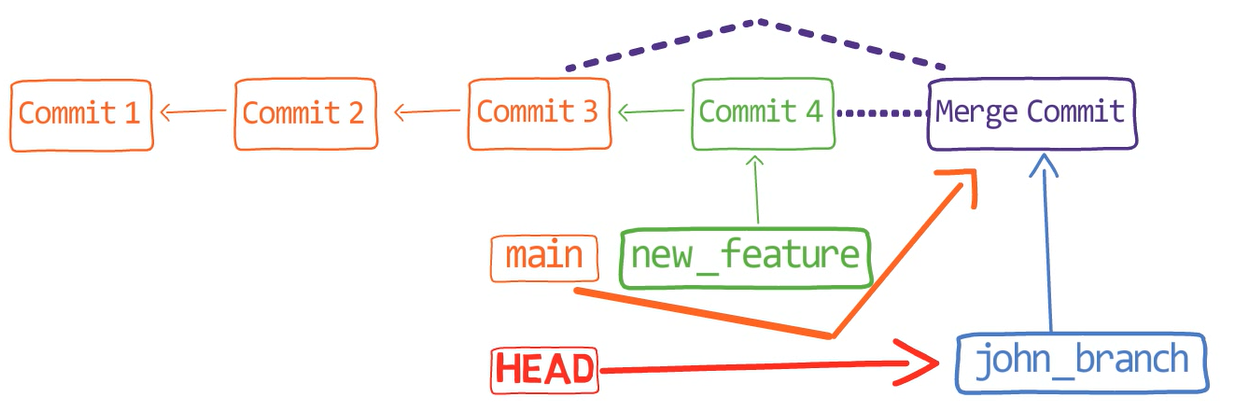 _Une nouvelle branche,
_Une nouvelle branche, john_branch_
Et John a écrit une nouvelle chanson dans un nouveau fichier, lucy_in_the_sky_with_diamonds.md. Eh bien, je crois que John Lennon n'écrivait pas vraiment au format Markdown, ou n'utilisait pas Git d'ailleurs, mais faisons semblant qu'il l'a fait pour cette explication.
git add lucy_in_the_sky_with_diamonds.md
git commit -m "Commit 5"
Pendant que John travaillait sur cette chanson, Paul écrivait aussi, sur une autre branche. Paul avait commencé à partir de main :
git checkout main
Et a créé sa propre branche :
git checkout -b paul_branch
Et Paul a écrit sa chanson dans un fichier appelé penny_lane.md. Paul a mis en transit et validé ce fichier :
git add penny_lane.md
git commit -m "Commit 6"
Donc maintenant notre historique ressemble à ceci - où nous avons deux branches différentes, partant de main, avec des historiques différents :
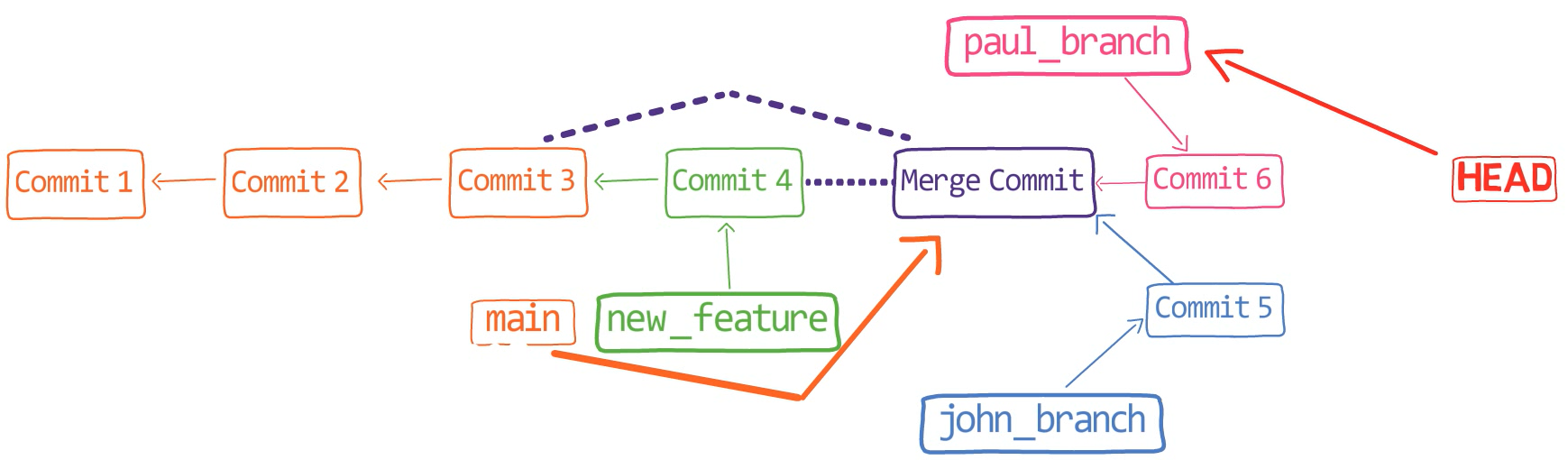 L'historique après que John et Paul ont validé
L'historique après que John et Paul ont validé
John est content de sa branche (c'est-à-dire de sa chanson), alors il décide de la fusionner dans la branche main :
git checkout main
git merge john_branch
En fait, c'est une fusion en avance rapide, comme nous l'avons appris auparavant. Vous pouvez valider cela en regardant l'historique (en utilisant git lol, par exemple) :
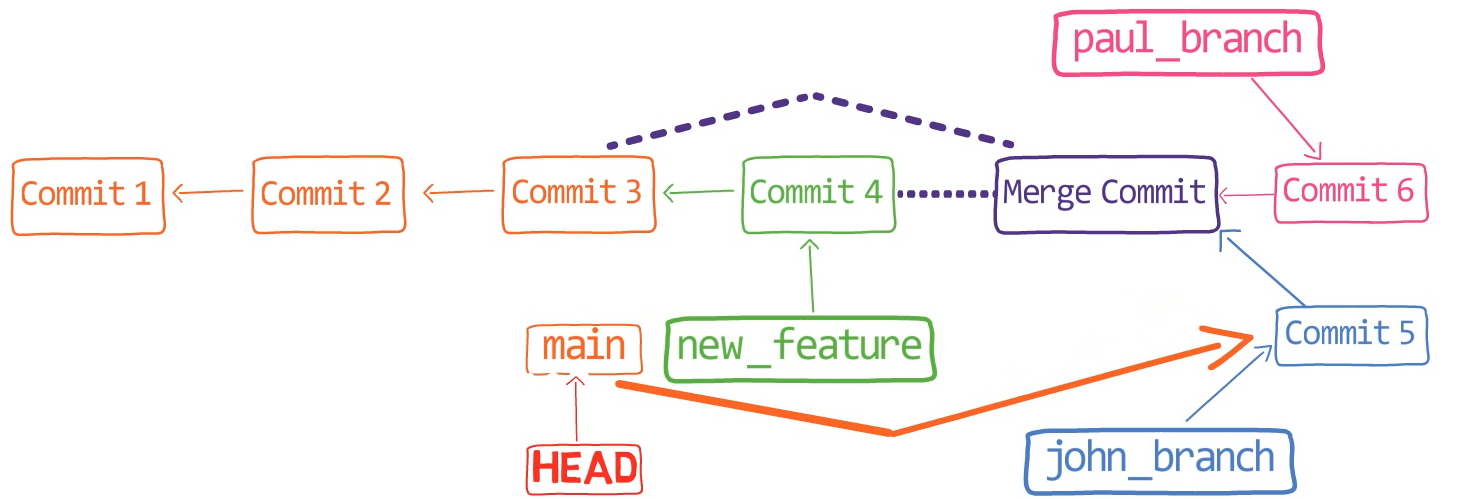 _Fusionner
_Fusionner john_branch dans main résulte en une fusion en avance rapide_
À ce stade, Paul veut aussi fusionner sa branche dans main, mais maintenant une fusion en avance rapide n'est plus pertinente - il y a deux historiques différents ici : l'historique de main et celui de paul_branch. Ce n'est pas que paul_branch ajoute seulement des commits par-dessus la branche main ou vice versa.
Maintenant les choses deviennent intéressantes. 😎😎
D'abord, laissez Git faire le gros du travail pour vous. Après cela, nous comprendrons ce qui se passe réellement sous le capot.
git merge paul_branch
Considérez l'historique maintenant :
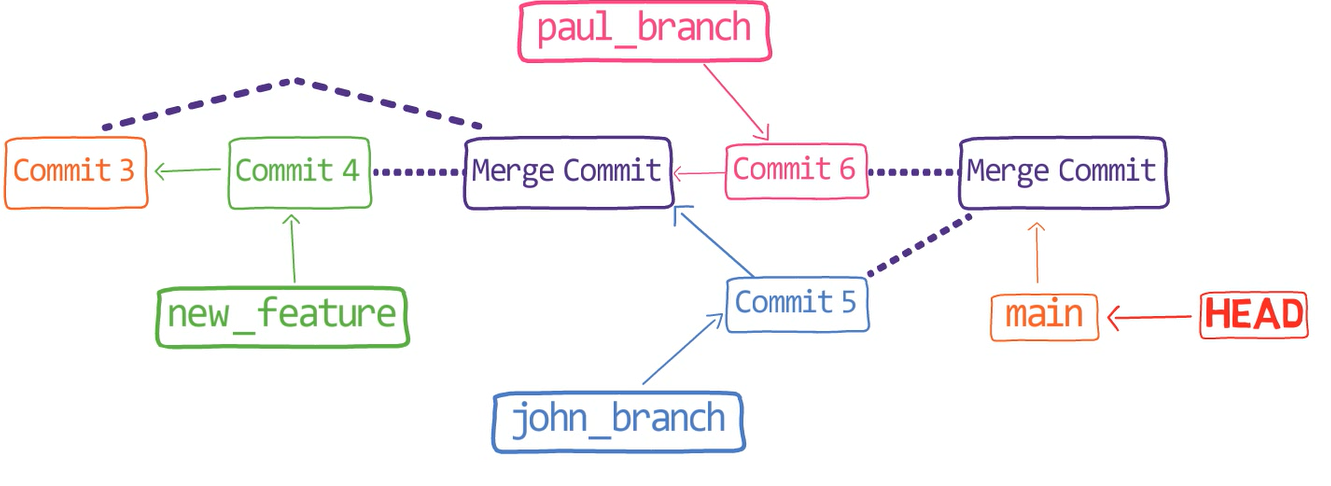 _Quand vous fusionnez
_Quand vous fusionnez paul_branch, vous obtenez un nouveau commit de fusion_
Ce que vous avez est un nouveau commit, avec deux parents - "Commit 5" et "Commit 6".
Dans le répertoire de travail, vous pouvez voir que la chanson de John ainsi que la chanson de Paul sont là (si vous utilisez ls, vous verrez les deux fichiers dans le répertoire de travail).
Sympa, Git a vraiment fusionné les changements pour vous. Mais comment cela se produit-il ?
Annulez ce dernier commit :
git reset --hard HEAD~
Comment effectuer une fusion à trois voies (Three-way Merge) dans Git
Il est temps de comprendre ce qui se passe réellement sous le capot. 😎
Ce que Git a fait ici est qu'il a appelé une fusion à 3 voies. En décrivant le processus d'une fusion à 3 voies, j'utiliserai le terme "branche" pour simplifier, mais vous devez vous rappeler que vous pourriez aussi fusionner deux (ou plusieurs) commits qui ne sont pas référencés par une branche.
Le processus de fusion à 3 voies comprend ces étapes :
Premièrement, Git localise l'ancêtre commun des deux branches. C'est-à-dire le commit commun à partir duquel les branches fusionnées ont divergé le plus récemment. Techniquement, c'est en fait le premier commit qui est accessible depuis les deux branches. Ce commit est alors appelé la base de fusion (merge base).
Deuxièmement, Git calcule deux diffs - un diff de la base de fusion à la première branche, et un autre diff de la base de fusion à la seconde branche. Git génère des patches basés sur ces diffs.
Troisièmement, Git applique les deux patches à la base de fusion en utilisant un algorithme de fusion à 3 voies. Le résultat est l'état du nouveau commit de fusion.
 Les trois étapes de l'algorithme de fusion à 3 voies : (1) localiser l'ancêtre commun (2) calculer les diffs de la base de fusion à la première branche, et de la base de fusion à la seconde branche (3) appliquer les deux patches ensemble
Les trois étapes de l'algorithme de fusion à 3 voies : (1) localiser l'ancêtre commun (2) calculer les diffs de la base de fusion à la première branche, et de la base de fusion à la seconde branche (3) appliquer les deux patches ensemble
Donc, revenons à notre exemple.
Dans la première étape, Git regarde à partir des deux branches - main et paul_branch - et traverse l'historique pour trouver le premier commit qui est accessible depuis les deux. Dans ce cas, ce serait… quel commit ?
Correct, le commit de fusion (celui avec "Commit 3" et "Commit 4" comme parents).
Si vous n'êtes pas sûr, vous pouvez toujours demander directement à Git :
git merge-base main paul_branch
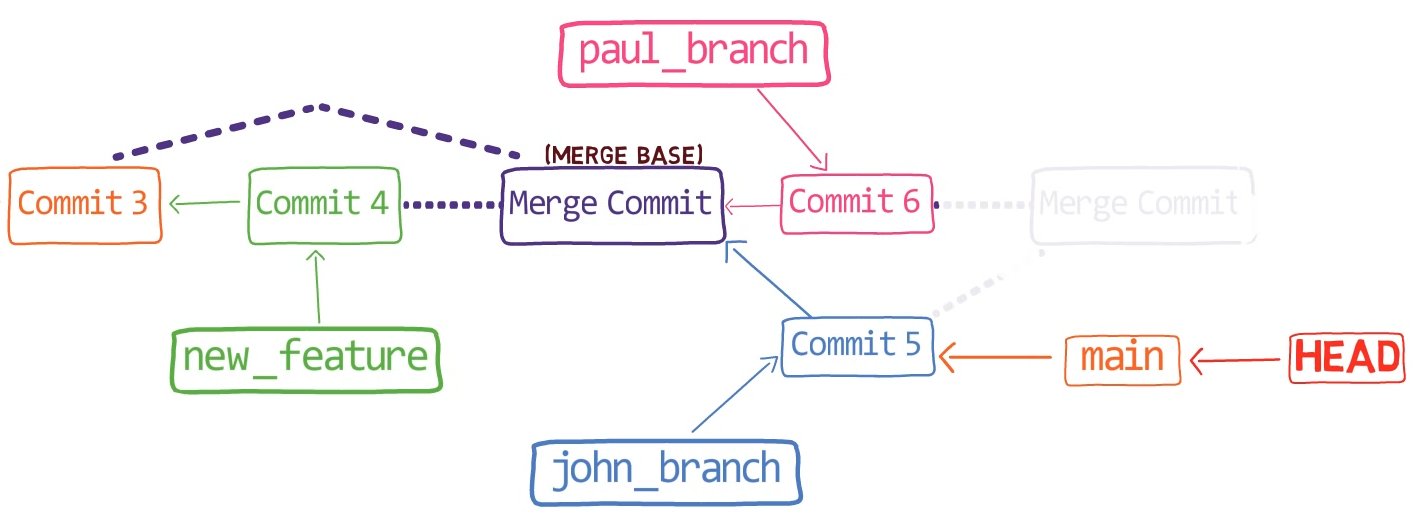 La base de fusion est le commit de fusion avec "Commit 3" et "Commit 4" comme parents. Note : la fusion du commit précédent est floutée car elle n'est pas accessible via l'historique actuel suite à la commande
La base de fusion est le commit de fusion avec "Commit 3" et "Commit 4" comme parents. Note : la fusion du commit précédent est floutée car elle n'est pas accessible via l'historique actuel suite à la commande reset
Au passage, c'est le cas le plus courant et le plus simple, où nous avons un seul choix évident pour la base de fusion. Dans des cas plus compliqués, il peut y avoir plusieurs possibilités pour une base de fusion, mais ce n'est pas notre objectif.
Dans la deuxième étape, Git calcule les diffs. Donc il calcule d'abord le diff entre le commit de fusion et "Commit 5" :
git diff 4f90a62 4683aef
(Les valeurs SHA-1 seront différentes sur votre machine.)
 Le diff entre le commit de fusion et "Commit 5"
Le diff entre le commit de fusion et "Commit 5"
Si vous ne vous sentez pas à l'aise avec la sortie de git diff, vous pouvez lire le chapitre précédent où je l'ai décrite en détail.
Vous pouvez stocker ce diff dans un fichier :
git diff 4f90a62 4683aef > john_branch_diff.patch
Ensuite, Git calcule le diff entre le commit de fusion et "Commit 6" :
git diff 4f90a62 c5e4951
 Le diff entre le commit de fusion et "Commit 6"
Le diff entre le commit de fusion et "Commit 6"
Écrivez celui-ci aussi dans un fichier :
git diff 4f90a62 c5e4951 > paul_branch_diff.patch
Maintenant Git applique ces patches sur la base de fusion.
D'abord, essayez cela directement - appliquez simplement les patches (je vais vous guider dans un instant). Ce n'est pas ce que Git fait réellement sous le capot, mais cela vous aidera à mieux comprendre pourquoi Git doit faire quelque chose de différent.
Faites un checkout de la base de fusion d'abord, c'est-à-dire le commit de fusion :
git checkout 4f90a62
Et appliquez le patch de John d'abord (pour rappel, c'est le patch montré dans l'image avec la légende "Le diff entre le commit de fusion et "Commit 5"") :
git apply --index john_branch_diff.patch
Remarquez que pour l'instant il n'y a pas de commit de fusion. git apply met à jour le répertoire de travail ainsi que l'index, car nous avons utilisé le drapeau --index.
Vous pouvez observer le statut en utilisant git status :
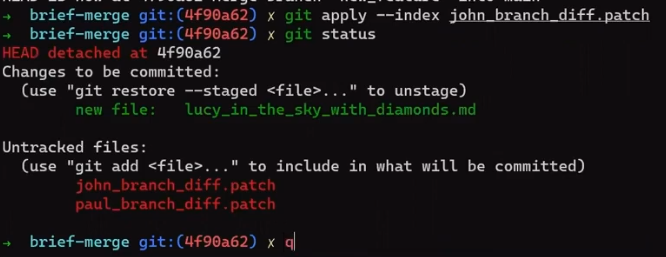 Application du patch de John sur le commit de fusion
Application du patch de John sur le commit de fusion
Donc maintenant la nouvelle chanson de John est incorporée dans l'index. Appliquez l'autre patch :
git apply --index paul_branch_diff.patch
En conséquence, l'index contient des changements des deux branches.
Il est maintenant temps de valider votre fusion. Puisque la commande de porcelaine git commit génère toujours un commit avec un seul parent, vous auriez besoin de la commande de plomberie sous-jacente - git commit-tree.
Si vous avez besoin d'un rappel sur les commandes de porcelaine vs plomberie, consultez le chapitre 4 où j'ai expliqué ces termes et créé un repo entier à partir de zéro.
Rappelez-vous que chaque objet commit Git pointe vers un seul arbre. Vous devez donc enregistrer le contenu de l'index dans un arbre :
git write-tree
Maintenant vous obtenez la valeur SHA-1 de l'arbre créé, et vous pouvez créer un objet commit en utilisant git commit-tree :
git commit-tree <TREE_SHA> -p <COMMIT_5> -p <COMMIT_6> -m "Merge commit!"
 Création d'un commit de fusion
Création d'un commit de fusion
Super, vous avez donc créé un objet commit !
Rappelez-vous que git merge change aussi HEAD pour pointer vers le nouvel objet commit de fusion. Vous pouvez donc simplement faire de même :
git reset --hard db315a
Si vous regardez l'historique maintenant :
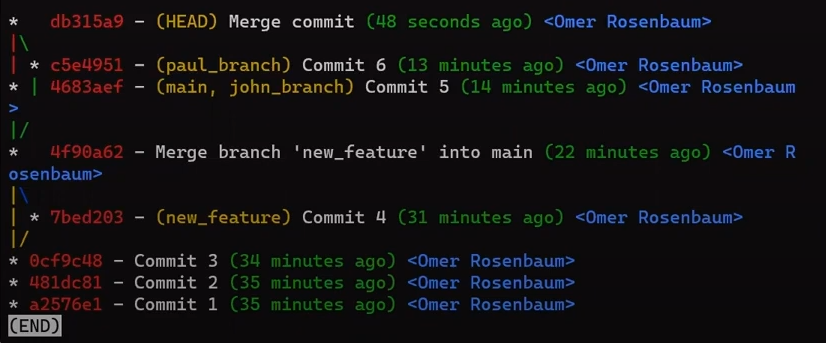 L'historique après la création d'un commit de fusion et la réinitialisation de
L'historique après la création d'un commit de fusion et la réinitialisation de HEAD
(Note : dans cet état, HEAD est "détaché" - c'est-à-dire qu'il pointe directement vers un objet commit plutôt que vers une référence nommée. gg ne montre pas HEAD quand il est "détaché", alors ne soyez pas confus si vous ne pouvez pas voir HEAD dans la sortie de gg.)
C'est presque ce que nous voulions. Rappelez-vous que lorsque vous avez exécuté git merge, le résultat était HEAD pointant vers main qui pointait vers le commit nouvellement créé (comme indiqué dans l'image avec la légende "Quand vous fusionnez paul_branch, vous obtenez un nouveau commit de fusion". Que devriez-vous faire alors ?
Eh bien, ce que vous voulez, c'est modifier main, donc vous pouvez simplement le pointer vers le nouveau commit :
git checkout main
git reset --hard db315a
Et maintenant vous avez le même résultat que lorsque vous avez exécuté git merge : main pointe vers le nouveau commit, qui a "Commit 5" et "Commit 6" comme parents. Vous pouvez utiliser git lol pour vérifier cela.
C'est donc exactement le même résultat que la fusion faite par Git, à l'exception de l'horodatage et donc de la valeur SHA-1, bien sûr.
Dans l'ensemble, vous avez réussi à fusionner à la fois le contenu des deux commits - c'est-à-dire l'état des fichiers, et aussi l'historique de ces commits - en créant un commit de fusion qui pointe vers les deux historiques.
Dans ce cas simple, vous pourriez en fait juste appliquer les patches en utilisant git apply, et tout fonctionne plutôt bien.
Récapitulatif rapide d'une fusion à trois voies
Donc pour récapituler rapidement, lors d'une fusion à trois voies, Git :
- Premièrement, localise la base de fusion - l'ancêtre commun des deux branches. C'est-à-dire le premier commit qui est accessible depuis les deux branches.
- Deuxièmement, Git calcule deux diffs - un diff de la base de fusion à la première branche, et un autre diff de la base de fusion à la seconde branche.
- Troisièmement, Git applique les deux patches à la base de fusion, en utilisant un algorithme de fusion à 3 voies. Je n'ai pas encore expliqué la fusion à 3 voies, mais je développerai cela plus tard. Le résultat est l'état du nouveau commit de fusion.
Vous pouvez aussi comprendre pourquoi cela s'appelle une "fusion à 3 voies" : Git fusionne trois états différents - celui de la première branche, celui de la seconde branche et leur ancêtre commun. Dans notre exemple précédent, main, paul_branch et le commit de fusion (avec "Commit 3" et "Commit 4" comme parents), respectivement.
C'est différent, disons, des exemples d'avance rapide que nous avons vus auparavant. Les exemples d'avance rapide sont en fait un cas de fusion à deux voies, car Git compare seulement deux états - par exemple, où main pointait, et où john_branch pointait.
Pour aller plus loin
Pourtant, c'était un cas simple de fusion à 3 voies. John et Paul ont créé des chansons différentes, donc chacun d'eux a touché un fichier différent. C'était assez simple d'exécuter la fusion.
Qu'en est-il des cas plus intéressants ?
Supposons que maintenant John et Paul sont co-auteurs d'une nouvelle chanson.
Donc, John a fait un checkout de la branche main et a commencé à écrire la chanson :
git checkout main
 La nouvelle chanson de John
La nouvelle chanson de John
Il l'a mise en transit et validée ("Commit 7") :
git add a_day_in_the_life.md
git commit -m "Commit 7"
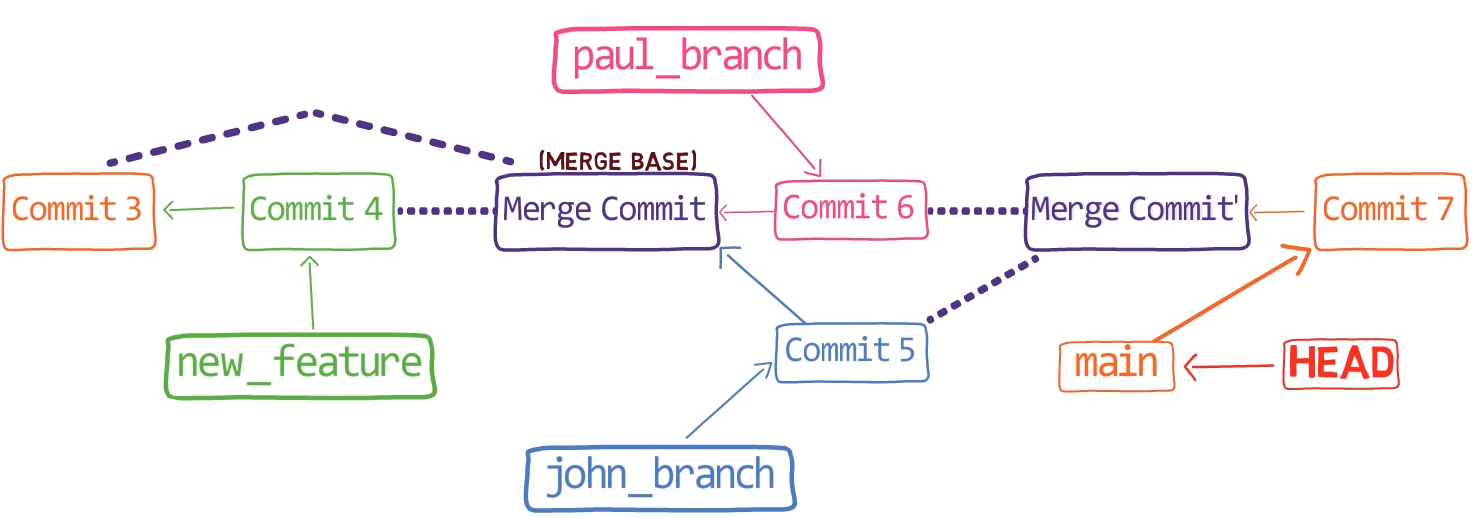 La nouvelle chanson de John est validée
La nouvelle chanson de John est validée
Maintenant, Paul branche :
git checkout -b paul_branch_2
Et édite la chanson, ajoutant un autre couplet :
 Paul a ajouté un nouveau couplet
Paul a ajouté un nouveau couplet
Bien sûr, la chanson originale n'inclut pas le titre "Paul's Verse", mais je l'ai ajouté ici pour la clarté.
Paul met en transit et valide les changements :
git add a_day_in_the_life.md
git commit -m "Commit 8"
 L'historique après l'introduction de "Commit 8"
L'historique après l'introduction de "Commit 8"
John branche aussi depuis main et ajoute deux lignes supplémentaires à la fin :
git checkout main
git checkout -b john_branch_2
 John a ajouté les deux dernières lignes
John a ajouté les deux dernières lignes
John met en transit et valide aussi ses changements ("Commit 9") :
git add a_day_in_the_life.md
git commit -m "Commit 9"
Voici l'historique résultant :
 L'historique après le dernier commit de John
L'historique après le dernier commit de John
Donc, Paul et John ont tous deux modifié le même fichier sur des branches différentes. Git réussira-t-il à les fusionner ?
Disons maintenant que nous ne passons pas par main, mais John va essayer de fusionner la nouvelle branche de Paul dans sa branche :
git merge paul_branch_2
Attendez ! N'exécutez pas cette commande ! Pourquoi laisseriez-vous Git faire tout le travail difficile ? Vous essayez de comprendre le processus ici.
Donc, d'abord, Git doit trouver la base de fusion. Pouvez-vous voir quel commit ce serait ?
Correct, ce serait le dernier commit sur la branche main, où les deux ont divergé - c'est-à-dire "Commit 7".
Vous pouvez vérifier cela en utilisant :
git merge-base john_branch_2 paul_branch_2
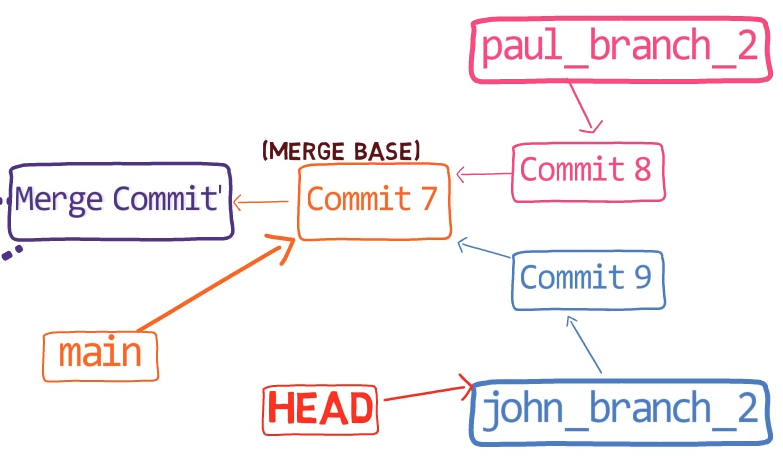 "Commit 7" est la base de fusion
"Commit 7" est la base de fusion
Faites un checkout de la base de fusion pour que vous puissiez plus tard appliquer les patches que vous créerez :
git checkout main
Super, maintenant Git devrait calculer les diffs et générer les patches. Vous pouvez observer les diffs directement :
git diff main paul_branch_2
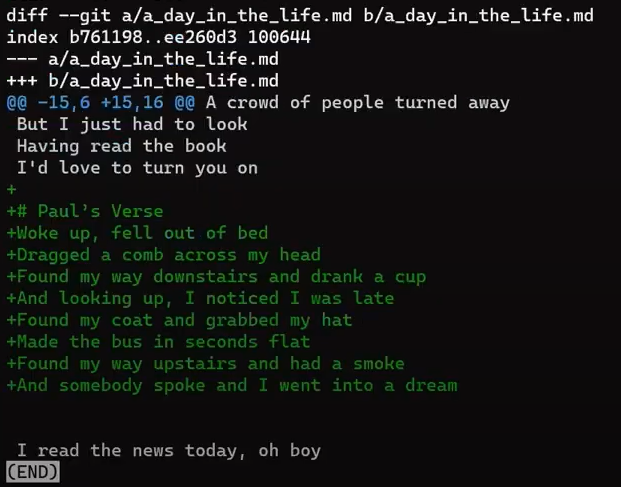 _La sortie de
_La sortie de git diff main paul_branch_2_
L'application de ce patch réussira-t-elle ? Eh bien, pas de problème, Git a toutes les lignes de contexte en place.
Passez à la base de fusion (qui est "Commit 7", aussi référencée par main), et demandez à Git d'appliquer ce patch :
git checkout main
git diff main paul_branch_2 > paul_branch_2.patch
git apply --index paul_branch_2.patch
Et cela a fonctionné, aucun problème du tout.
Maintenant, calculez le diff entre la nouvelle branche de John et la base de fusion. Remarquez que vous n'avez pas validé les changements appliqués, donc john_branch_2 pointe toujours vers le même commit qu'avant, "Commit 9" :
git diff main john_branch_2
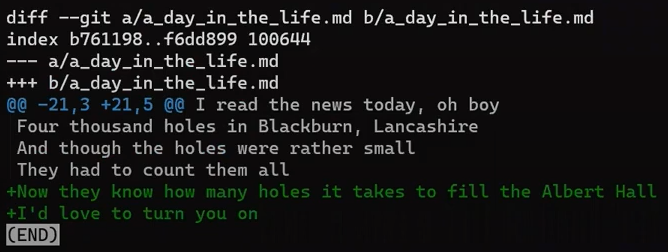 _La sortie de
_La sortie de git diff main john_branch_2_
L'application de ce diff fonctionnera-t-elle ?
Eh bien, en effet, oui. Remarquez que même si les numéros de ligne ont changé sur la version actuelle du fichier, grâce aux lignes de contexte Git est capable de localiser où il doit ajouter ces lignes…
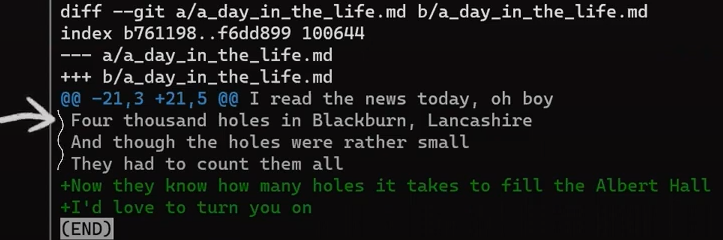 Git peut compter sur les lignes de contexte
Git peut compter sur les lignes de contexte
Sauvegardez ce patch et appliquez-le ensuite :
git diff main john_branch_2 > john_branch_2.patch
git apply --index john_branch_2.patch
Observez le fichier résultat :
 Le résultat après l'application du patch de Paul
Le résultat après l'application du patch de Paul
Cool, exactement ce que nous voulions.
Vous pouvez maintenant créer l'arbre et le commit pertinent :
git write-tree
N'oubliez pas de spécifier les deux parents :
git commit-tree <TREE-ID> -p paul_branch_2 -p john_branch_2 -m "Merging new changes"
Voyez comment j'ai utilisé les noms de branche ici ? Après tout, ce sont juste des pointeurs vers les commits que nous voulons.
Cool, regardez le journal du nouveau commit :
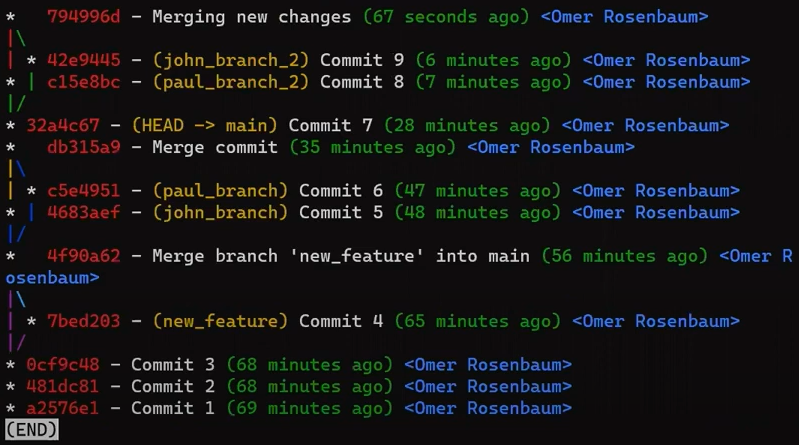 _
_git lol <SHA_OF_THE_MERGE_COMMIT> après la création du commit de fusion_
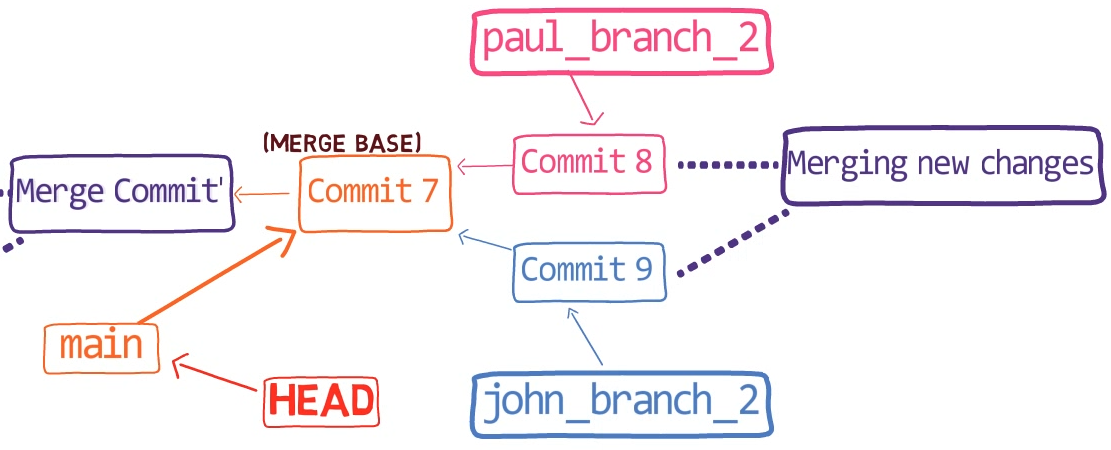 L'historique après la création du commit de fusion
L'historique après la création du commit de fusion
Exactement ce que nous voulions.
Vous pouvez aussi laisser Git effectuer le travail pour vous. Vous pouvez faire un checkout de john_branch_2, que vous n'avez pas déplacé - donc il pointe toujours vers le même commit qu'avant la fusion. Donc tout ce que vous avez à faire est d'exécuter :
git checkout john_branch_2
git merge paul_branch_2
Observez l'historique résultant :
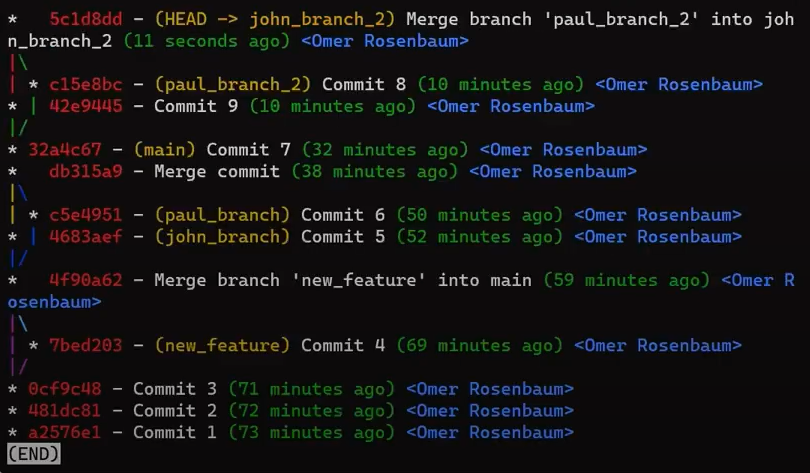
git lol après avoir laissé Git effectuer la fusion
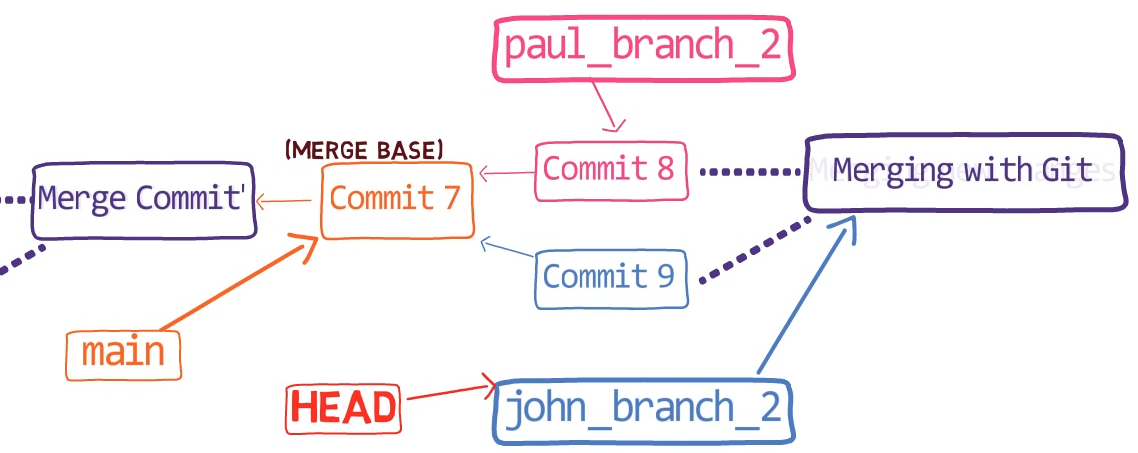 Une visualisation de l'historique après avoir laissé Git effectuer la fusion
Une visualisation de l'historique après avoir laissé Git effectuer la fusion
Tout comme avant, vous avez un commit de fusion pointant vers "Commit 8" et "Commit 9" comme ses parents. "Commit 9" est le premier parent puisque vous avez fusionné dedans.
Mais c'était encore assez simple… John et Paul ont travaillé sur le même fichier, mais sur des parties très différentes. Vous pourriez aussi appliquer directement les changements de Paul à la branche de John. Si vous revenez à la branche de John avant la fusion :
git reset --hard HEAD~
Et maintenant appliquez les changements de Paul :
git apply --index paul_branch_2.patch
Vous obtiendrez le même résultat.
Mais que se passe-t-il lorsque les deux branches incluent des changements sur les mêmes fichiers, aux mêmes endroits ?
Cas de fusion Git plus avancés
Que se passerait-il si John et Paul devaient coordonner une nouvelle chanson et travailler dessus ensemble ?
Dans ce cas, John crée la première version de cette chanson dans la branche principale :
git checkout main
nano everyone.md
 Le contenu de
Le contenu de everyone.md avant le premier commit
Au passage, ce texte est en effet tiré de la version que John Lennon a enregistrée pour une démo en 1968. Mais ce n'est pas un livre sur les Beatles. Si vous êtes curieux du processus que les Beatles ont suivi en écrivant cette chanson, vous pouvez suivre les liens à la fin de ce chapitre.
git add everyone.md
git commit -m "Commit 10"
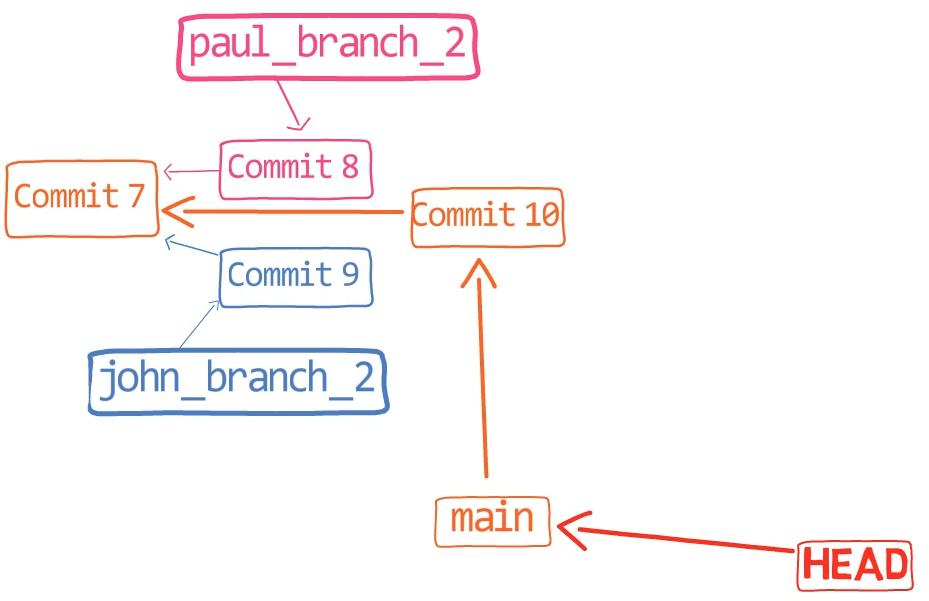 Introduction de "Commit 10"
Introduction de "Commit 10"
Maintenant John et Paul se séparent. Paul crée un nouveau couplet au début :
git checkout -b paul_branch_3
nano everyone.md
 Paul a ajouté un nouveau couplet au début
Paul a ajouté un nouveau couplet au début
Aussi, en parlant à John, ils ont décidé de changer le mot "feet" en "foot", alors Paul ajoute aussi ce changement.
Et Paul ajoute et valide ses changements dans le repo :
git add everyone.md
git commit -m "Commit 11"
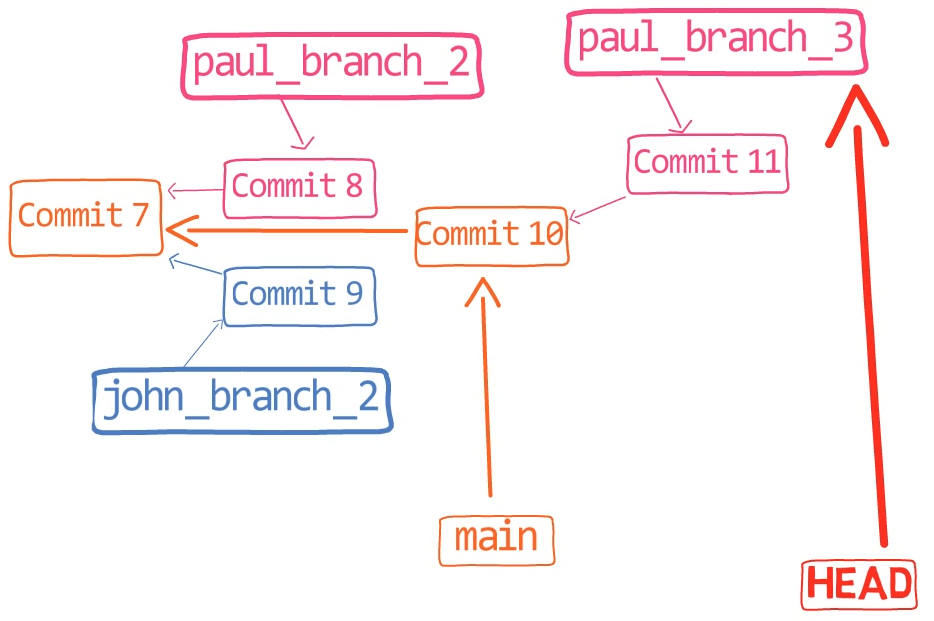 L'historique après l'introduction de "Commit 11"
L'historique après l'introduction de "Commit 11"
Vous pouvez observer les changements de Paul, en comparant l'état de cette branche à l'état de la branche main :
git diff main
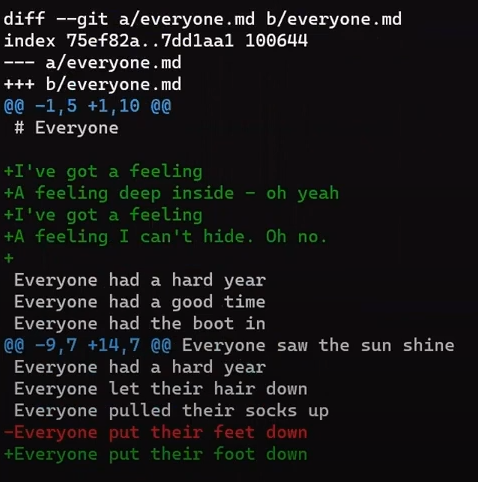 La sortie de
La sortie de git diff main depuis la branche de Paul
Stockez ce diff dans un fichier patch :
git diff main > paul_3.patch
Maintenant retour à main…
git checkout main
John décide de faire un autre changement, dans sa propre nouvelle branche :
git checkout -b john_branch_3
Et il remplace la ligne "Everyone had the boot in" par la ligne "Everyone had a wet dream". De plus, John a changé le mot "feet" en "foot", suite à sa discussion avec Paul.
Observez le diff :
git diff main
 La sortie de
La sortie de git diff main depuis la branche de John
Stockez cette sortie aussi :
git diff main > john_3.patch
Maintenant, mettez en transit et validez :
git add everyone.md
git commit -m "Commit 12"
Cela devrait être votre historique actuel :
 L'historique après l'introduction de "Commit 12"
L'historique après l'introduction de "Commit 12"
Notez que j'ai supprimé john_branch_2 et paul_branch_2 pour simplifier. Bien sûr, vous pouvez les effacer de Git en utilisant git branch -D <branch_name>. En conséquence, ces noms de branche n'apparaîtront pas dans la sortie de git log ou d'autres commandes similaires.
Cela s'applique aussi aux commits qui ne sont plus accessibles depuis aucune référence nommée, tels que "Commit 8" ou "Commit 9". Puisqu'ils ne sont pas accessibles depuis une référence nommée via la chaîne des parents, ils ne seront pas inclus dans la sortie de commandes telles que git log.
Retour à notre histoire - Paul a dit à John qu'il avait ajouté un nouveau couplet, donc John aimerait fusionner les changements de Paul.
John peut-il simplement appliquer le patch de Paul ?
Considérez le patch à nouveau :
git diff main paul_branch_3
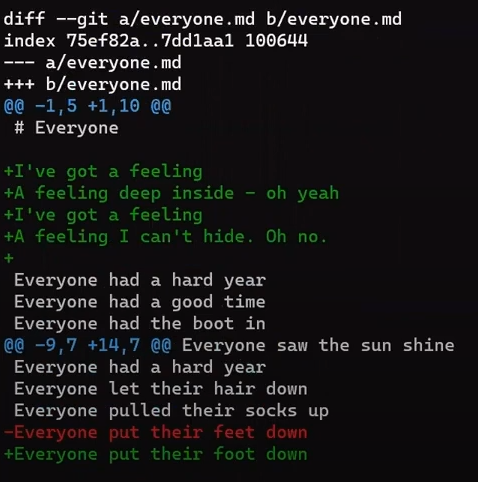 _La sortie de
_La sortie de git diff main paul_branch_3_
Comme vous pouvez le voir, ce diff s'appuie sur la ligne "Everyone had the boot in", mais cette ligne n'existe plus sur la branche de John. En conséquence, vous pourriez vous attendre à ce que l'application du patch échoue. Allez-y, essayez :
git apply paul_3.patch
 L'application du patch a échoué
L'application du patch a échoué
En effet, vous pouvez voir que cela a échoué.
Mais devrait-il vraiment échouer ?
Comme expliqué plus tôt, git merge utilise un algorithme de fusion à 3 voies, et cela peut s'avérer utile ici. Quelle serait la première étape de cet algorithme ?
Eh bien, d'abord, Git trouverait la base de fusion - c'est-à-dire l'ancêtre commun de la branche de Paul et de la branche de John. Considérez l'historique :
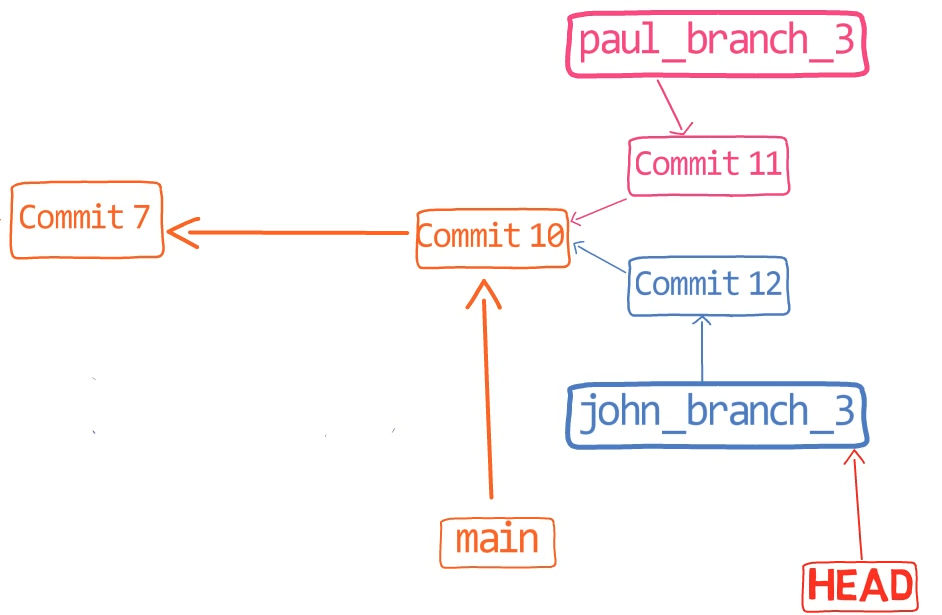 L'historique après l'introduction de "Commit 12"
L'historique après l'introduction de "Commit 12"
Donc l'ancêtre commun de "Commit 11" et "Commit 12" est "Commit 10". Vous pouvez vérifier cela en exécutant la commande :
git merge-base john_branch_3 paul_branch_3
Maintenant, nous pouvons prendre les patches que nous avons générés à partir des diffs sur les deux branches, et les appliquer à main. Est-ce que cela fonctionnerait ?
D'abord, essayez d'appliquer le patch de John, puis le patch de Paul.
Considérez le diff :
git diff main john_branch_3
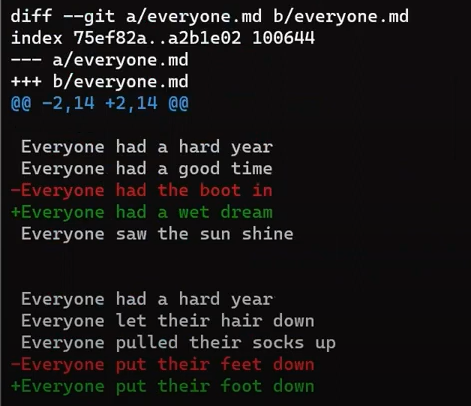 _La sortie de
_La sortie de git diff main john_branch_3_
Nous pouvons le stocker dans un fichier :
git diff main john_branch_3 > john_3.patch
Et appliquer ce patch sur main :
git checkout main
git apply john_3.patch
Considérons le résultat :
nano everyone.md
 Le contenu de
Le contenu de everyone.md après l'application du patch de John
La ligne a changé comme prévu. Sympa 😎
Maintenant, Git peut-il appliquer le patch de Paul ? Pour vous rappeler, voici le patch :
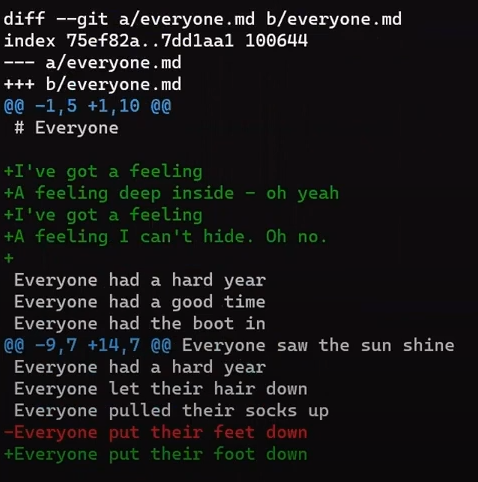 Le contenu du patch de Paul
Le contenu du patch de Paul
Eh bien, Git ne peut pas appliquer ce patch, car ce patch suppose que la ligne "Everyone had the boot in" existe. Essayer de l'appliquer risque d'échouer :
git apply -v paul_3.branch
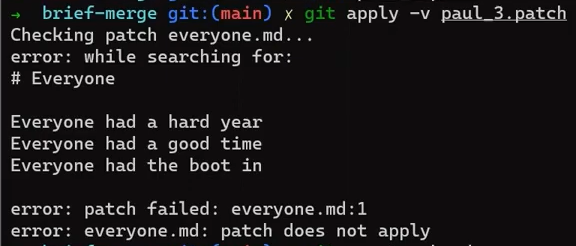 L'application du patch de Paul a échoué
L'application du patch de Paul a échoué
Ce que vous avez essayé de faire maintenant, appliquer le patch de Paul sur la branche main après avoir appliqué le patch de John, est la même chose qu'être sur john_branch_3, et tenter d'appliquer le patch. C'est-à-dire, exécuter :
git apply paul_3.patch
Que se passerait-il si nous essayions dans l'autre sens ?
D'abord, nettoyez l'état :
git reset --hard
Et commencez à partir de la branche de Paul :
git checkout paul_branch_3
Pouvons-nous appliquer le patch de John ? Pour rappel, voici le statut de everyone.md sur cette branche :
 _Le contenu de
_Le contenu de everyone.md sur paul_branch_3_
Et voici le patch de John :
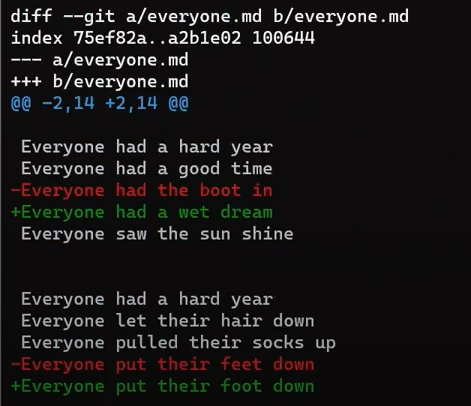 Le contenu du patch de John
Le contenu du patch de John
L'application du patch de John fonctionnerait-elle ?
Essayez de répondre vous-même avant de continuer à lire.
Vous pouvez essayer :
git apply john_3.patch
 Git échoue à appliquer le patch de John
Git échoue à appliquer le patch de John
Eh bien, non ! Encore une fois, si vous n'êtes pas sûr de ce qui s'est passé, vous pouvez toujours demander à git apply d'être un peu plus verbeux :
git apply -v john_3.patch
 Vous pouvez obtenir plus d'informations en utilisant le drapeau
Vous pouvez obtenir plus d'informations en utilisant le drapeau -v
Git cherche "Everyone put the feet down", mais Paul a déjà changé cette ligne pour qu'elle soit constituée du mot "foot" au lieu de "feet". En conséquence, l'application de ce patch échoue.
Remarquez que changer le nombre de lignes de contexte ici (c'est-à-dire, utiliser git apply avec le drapeau -C, comme discuté au chapitre précédent) est non pertinent - Git est incapable de localiser la ligne réelle que le patch essaie d'effacer.
Mais en fait, Git peut faire fonctionner cela, si vous ajoutez simplement un drapeau à apply, lui disant d'effectuer une fusion à 3 voies sous le capot :
git apply -3 john_3.patch
 L'application avec le drapeau
L'application avec le drapeau -3 réussit
Et considérez le résultat :
 Le contenu de
Le contenu de everyone.md après la fusion
Exactement ce que nous voulions ! Vous avez le couplet de Paul, et les deux changements de John !
Alors, comment Git a-t-il pu accomplir cela ?
Eh bien, comme je l'ai mentionné, Git a vraiment fait une fusion à 3 voies, et avec cet exemple, ce sera un bon moment pour plonger dans ce que cela signifie réellement.
Comment fonctionne l'algorithme de fusion à 3 voies de Git
Revenez à l'état avant l'application de ce patch :
git reset --hard
Vous avez maintenant trois versions : la base de fusion, qui est "Commit 10", la branche de Paul et la branche de John. En termes généraux, nous pouvons dire que ce sont base de fusion, commit A et commit B. Notez que la base de fusion est par définition un ancêtre à la fois de commit A et commit B.
Pour effectuer la fusion, Git regarde le diff entre les trois versions différentes du fichier en question sur ces trois révisions. Dans votre cas, c'est le fichier everyone.md, et les révisions sont "Commit 10", la branche de Paul - c'est-à-dire "Commit 11", et la branche de John, c'est-à-dire "Commit 12".
Git prend la décision de fusion basée sur le statut de chaque ligne dans chacune de ces versions.
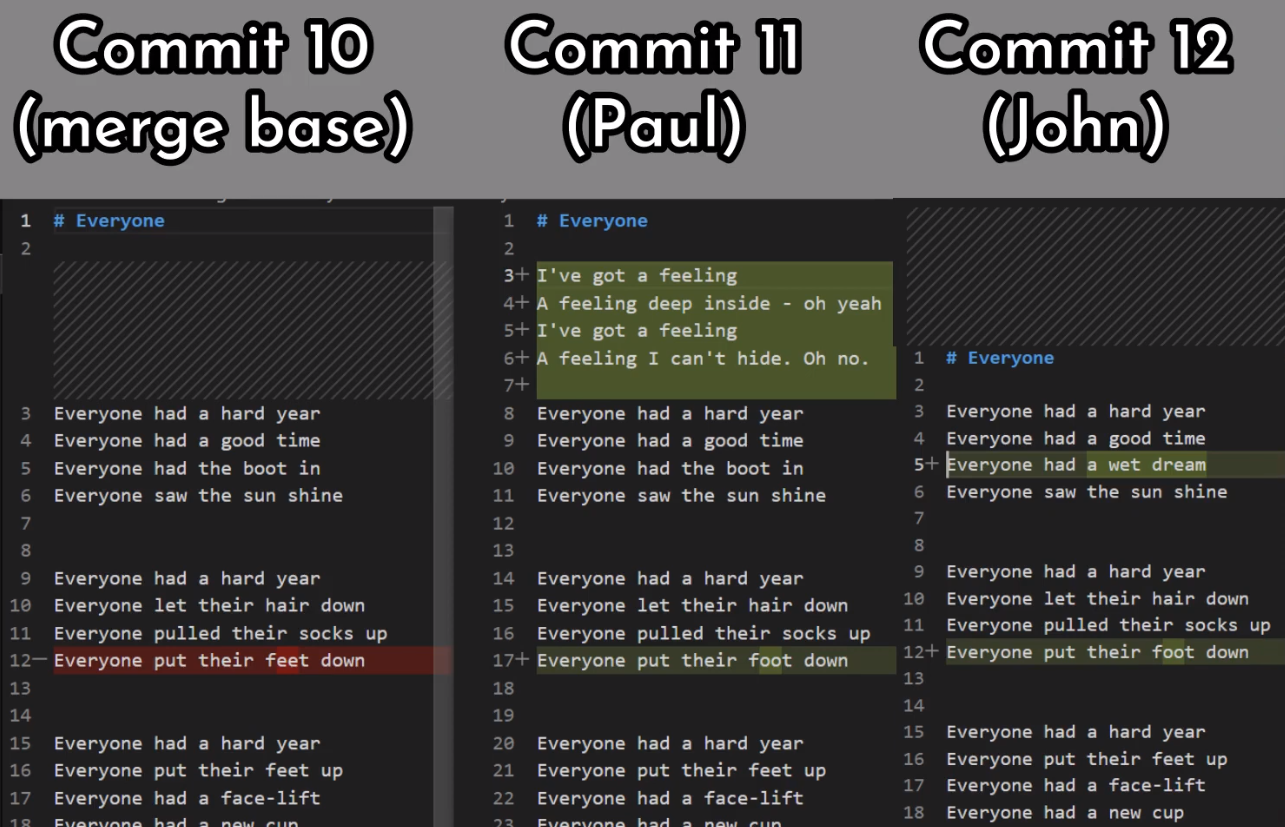 Les trois versions considérées pour la fusion à 3 voies
Les trois versions considérées pour la fusion à 3 voies
Au cas où les trois versions ne correspondraient pas, c'est un conflit. Git peut résoudre bon nombre de ces conflits automatiquement, comme nous allons le voir maintenant.
Considérons des lignes spécifiques.
Les premières lignes ici n'existent que sur la branche de Paul :
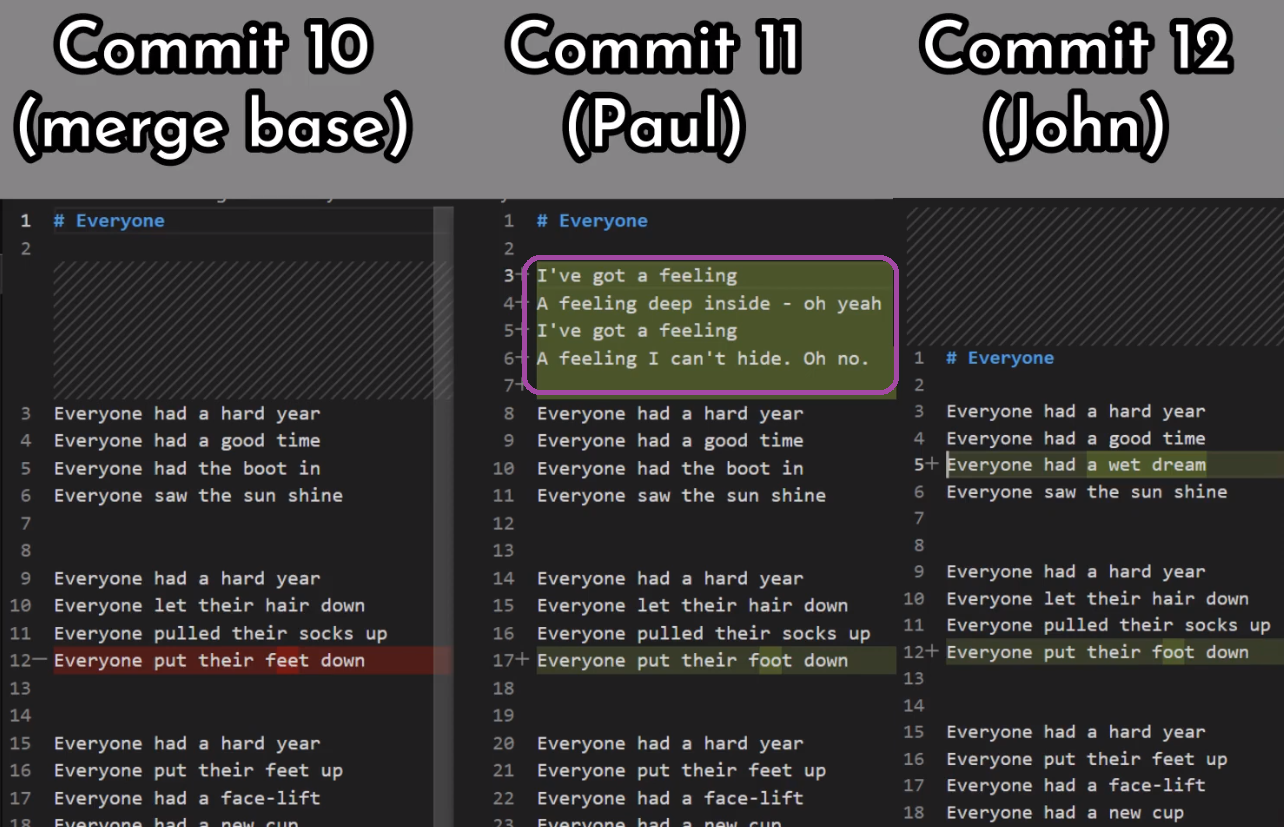 Lignes qui n'apparaissent que sur la branche de Paul
Lignes qui n'apparaissent que sur la branche de Paul
Cela signifie que l'état de la branche de John est égal à l'état de la base de fusion. Donc la fusion à 3 voies va avec la version de Paul.
En général, si l'état de la base de fusion est le même que A, l'algorithme va avec B. La raison est que puisque la base de fusion est l'ancêtre à la fois de A et B, Git suppose que cette ligne n'a pas changé dans A, et qu'elle a changé dans B, qui est la version la plus récente pour cette ligne, et devrait donc être prise en compte.
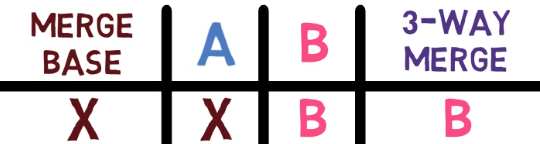 Si l'état de la base de fusion est le même que
Si l'état de la base de fusion est le même que A, et que cet état est différent de B, l'algorithme va avec B
Ensuite, vous pouvez voir des lignes où les trois versions sont d'accord - elles existent sur la base de fusion, A et B, avec des données égales.
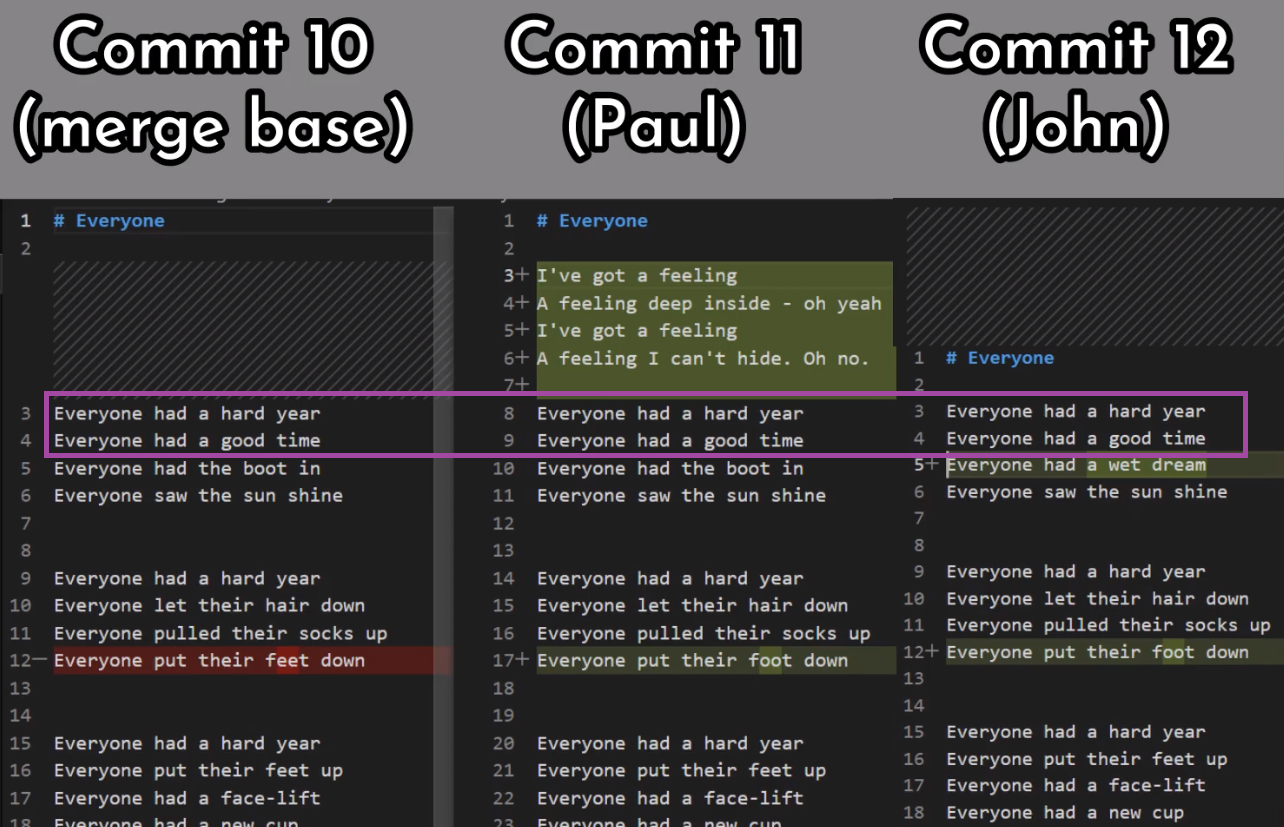 Lignes où les trois versions sont d'accord
Lignes où les trois versions sont d'accord
Dans ce cas, l'algorithme a un choix trivial - prendre simplement cette version.
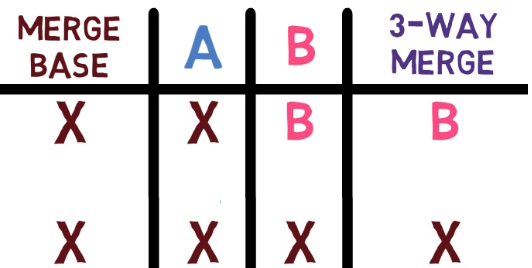 Au cas où les trois versions sont d'accord, l'algorithme va avec cette version unique
Au cas où les trois versions sont d'accord, l'algorithme va avec cette version unique
Dans un exemple précédent, nous avons vu que si la base de fusion et A sont d'accord, et que la version de B est différente, l'algorithme choisit B. Cela fonctionne aussi dans l'autre sens - par exemple, ici vous avez une ligne qui existe sur la branche de John, différente de celle sur la base de fusion et la branche de Paul.
 Une ligne où la version de Paul correspond à la version de la base de fusion, et John a une version différente
Une ligne où la version de Paul correspond à la version de la base de fusion, et John a une version différente
Par conséquent, la version de John est choisie.
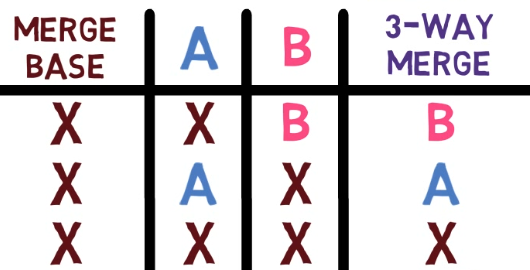 Si l'état de la base de fusion est le même que
Si l'état de la base de fusion est le même que B, et que cet état est différent de A, l'algorithme va avec A
Maintenant considérez un autre cas, où A et B sont d'accord sur une ligne, mais la valeur sur laquelle ils sont d'accord est différente de la base de fusion : John et Paul ont tous deux accepté de changer la ligne "Everyone put their feet down" en "Everyone put their foot down" :
 Une ligne où la version de Paul correspond à la version de John ; pourtant la base de fusion a une version différente
Une ligne où la version de Paul correspond à la version de John ; pourtant la base de fusion a une version différente
Dans ce cas, l'algorithme choisit la version sur A et B.
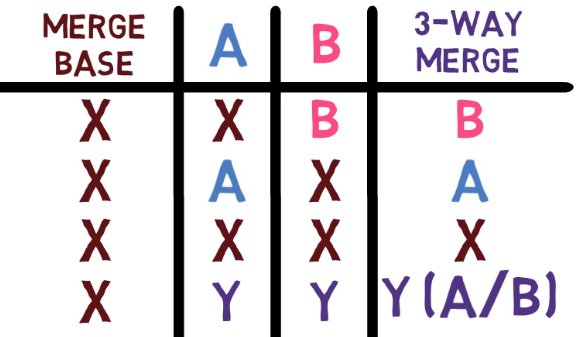 Au cas où
Au cas où A et B sont d'accord sur une version qui est différente de la version de la base de fusion, l'algorithme choisit la version sur A et B
Remarquez que ce n'est pas un vote démocratique. Dans le cas précédent, l'algorithme a choisi la version minoritaire, car elle ressemblait à la version la plus récente de cette ligne. Dans ce cas, il se trouve qu'il choisit la majorité - mais seulement parce que A et B sont les révisions qui sont d'accord sur la nouvelle version.
La même chose se produirait si nous utilisions git merge :
git merge john_branch_3
Sans spécifier d'options, git merge utilisera par défaut une fusion à 3 voies.
 Par défaut,
Par défaut, git merge utilise un algorithme de fusion à 3 voies
Le statut de everyone.md après l'exécution de git merge john_branch serait le même que le résultat que vous avez obtenu en appliquant les patches avec git apply -3.
Si vous considérez l'historique :
 L'historique de Git après avoir effectué la fusion
L'historique de Git après avoir effectué la fusion
Vous verrez que le commit de fusion a bien deux parents : le premier est "Commit 11", c'est-à-dire là où pointait paul_branch_3 avant la fusion. Le second est "Commit 12", là où john_branch_3 pointait, et pointe toujours maintenant.
Que se passera-t-il si vous fusionnez maintenant depuis main ? C'est-à-dire, passer à la branche main, qui pointe vers "Commit 10" :
git checkout main
Et ensuite fusionner la branche de Paul ?
git merge paul_branch_3
En effet, nous obtenons une fusion en avance rapide - car avant d'exécuter cette commande, main était un ancêtre de paul_branch_3.
 Une fusion en avance rapide
Une fusion en avance rapide
Donc, c'est une fusion à 3 voies. En général, si toutes les versions sont d'accord sur une ligne, alors cette ligne est utilisée. Si A et la base de fusion correspondent, et que B a une autre version, B est pris. Dans le cas contraire, où la base de fusion et B correspondent, la version A est sélectionnée. Si A et B correspondent, cette version est prise, que la base de fusion soit d'accord ou non.
Cette description laisse cependant une question ouverte : Que se passe-t-il dans les cas où les trois versions sont en désaccord ?
Eh bien, c'est un conflit que Git ne résout pas automatiquement. Dans ces cas, Git demande l'aide d'un humain.
Comment résoudre les conflits de fusion
En suivant jusqu'ici, vous devriez comprendre les bases de la commande git merge, et comment Git peut résoudre automatiquement certains conflits. Vous comprenez également quels cas sont résolus automatiquement.
Ensuite, considérons un cas plus avancé.
Disons que Paul et John continuent de travailler sur cette chanson.
Paul crée une nouvelle branche :
git checkout -b paul_branch_4
Et il décide d'ajouter quelques "Yeah" à la chanson, alors il change ce couplet comme suit :
 Les ajouts de Paul
Les ajouts de Paul
Donc Paul met en transit et valide ces changements :
git add everyone.md
git commit -m "Commit 13"
Paul crée également une autre chanson, let_it_be.md et l'ajoute au repo :
git add let_it_be.md
git commit -m "Commit 14"
Voici l'historique :
 L'historique après que Paul a introduit "Commit 14"
L'historique après que Paul a introduit "Commit 14"
De retour à main :
git checkout main
John branche aussi :
git checkout -b john_branch_4
Et John travaille aussi sur la chanson "Everyone had a hard year", qui s'appellera plus tard "I've got a feeling" (encore une fois, ce n'est pas un livre sur les Beatles, donc je ne m'étendrai pas là-dessus. Voir les liens supplémentaires si vous êtes curieux).
John décide de changer toutes les occurrences de "Everyone" en "Everybody" :
 John change toutes les occurrences de "Everyone" en "Everybody"
John change toutes les occurrences de "Everyone" en "Everybody"
Il met en transit et valide cette chanson dans le repo :
git add everyone.md
git commit -m "Commit 15"
Sympa. Maintenant John crée aussi une autre chanson, across_the_universe.md. Il l'ajoute aussi au repo :
git add across_the_universe.md
git commit -m "Commit 16"
Observez l'historique à nouveau :
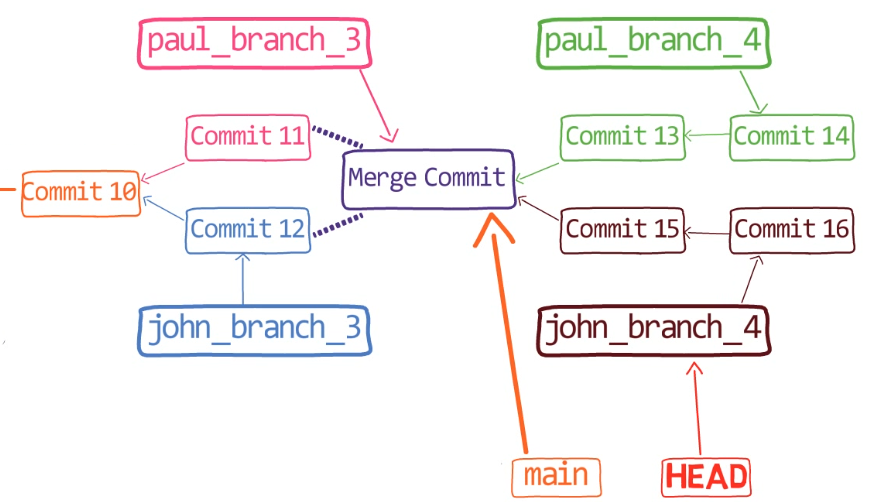 L'historique après que John a introduit "Commit 16"
L'historique après que John a introduit "Commit 16"
Vous pouvez voir que l'historique diverge de main, vers deux branches différentes - paul_branch_4, et john_branch_4.
À ce stade, John aimerait fusionner les changements introduits par Paul.
Que va-t-il se passer ici ?
Rappelez-vous les changements introduits par Paul :
git diff main paul_branch_4
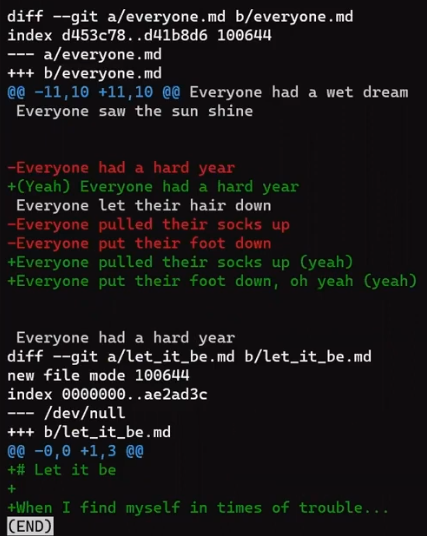 _La sortie de
_La sortie de git diff main paul_branch_4_
Qu'en pensez-vous ? La fusion fonctionnera-t-elle ?
Essayez :
git merge paul_branch_4
 Un conflit de fusion
Un conflit de fusion
Nous avons un conflit !
Git ne peut pas fusionner ces branches tout seul. Vous pouvez avoir un aperçu de l'état de fusion, en utilisant git status :
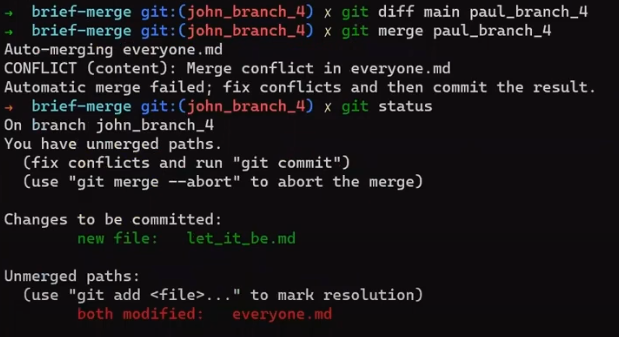 La sortie de
La sortie de git status juste après l'opération de fusion
Les changements que Git n'a eu aucun problème à résoudre sont mis en transit pour validation. Et il y a une section séparée pour "unmerged paths" (chemins non fusionnés) - ce sont des fichiers avec des conflits que Git n'a pas pu résoudre tout seul.
Il est temps de comprendre pourquoi et quand ces conflits se produisent, comment les résoudre, et aussi comment Git les gère sous le capot.
Très bien alors ! J'espère que vous êtes au moins aussi excité que moi. 😇
Rappelons ce que nous savons sur les fusions à 3 voies :
Premièrement, Git cherchera la base de fusion - l'ancêtre commun de john_branch_4 et paul_branch_4. Quel commit ce serait ?
Ce serait la pointe de la branche main, le commit dans lequel nous avons fusionné john_branch_3 dans paul_branch_3.
Encore une fois, si vous n'êtes pas sûr, vous pouvez vérifier cela en exécutant :
git merge-base john_branch_4 paul_branch_4
Et à l'état actuel, git status sait quels fichiers sont mis en transit et lesquels ne le sont pas.
Considérez le processus pour chaque fichier, qui est le même que l'algorithme de fusion à 3 voies que nous avons considéré par ligne, mais au niveau d'un fichier :
across_the_universe.md existe sur la branche de John, mais n'existe pas sur la base de fusion ou sur la branche de Paul. Donc Git choisit d'inclure ce fichier. Puisque vous êtes déjà sur la branche de John et que ce fichier est inclus dans la pointe de cette branche, il n'est pas mentionné par git status.
let_it_be.md existe sur la branche de Paul, mais n'existe pas sur la base de fusion ou la branche de John. Donc git merge "choisit" de l'inclure.
Qu'en est-il de everyone.md ? Eh bien, ici nous avons trois états différents de ce fichier : son état sur la base de fusion, son état sur la branche de John, et son état sur la branche de Paul. Lors de l'exécution d'une fusion, Git stocke toutes ces versions dans l'index.
Observons cela en regardant directement l'index avec la commande git ls-files :
git ls-files -s --abbrev
 La sortie de
La sortie de git ls-files -s --abbrev après l'opération de fusion
Vous pouvez voir que everyone.md a trois entrées différentes. Git attribue à chaque version un numéro qui représente le "stage" (stade) du fichier, et c'est une propriété distincte d'une entrée d'index, aux côtés du nom du fichier et des bits de mode.
Quand il n'y a pas de conflit de fusion concernant un fichier, son "stage" est 0. C'est bien l'état pour across_the_universe.md, et pour let_it_be.md.
Sur un état de conflit, nous avons :
- Stage
1- qui est la base de fusion. - Stage
2- qui est "votre" version. C'est-à-dire, la version du fichier sur la branche dans laquelle vous fusionnez (into). Dans notre exemple, ce seraitjohn_branch_4. - Stage
3- qui est "leur" version, aussi appeléeMERGE_HEAD. C'est-à-dire, la version sur la branche que vous fusionnez (dans la branche actuelle). Dans notre exemple, c'estpaul_branch_4.
Pour observer le contenu du fichier dans un stade spécifique, vous pouvez utiliser une commande que j'ai introduite dans un post précédent, git cat-file, et fournir le SHA du blob :
git cat-file -p <BLOB_SHA_FOR_STAGE_2>
 Utiliser
Utiliser git cat-file pour présenter le contenu du fichier sur la branche de John, directement depuis son état dans l'index
Et en effet, c'est le contenu que nous attendions - de la branche de John, où les lignes commencent par "Everybody" plutôt que "Everyone".
Une astuce sympa qui vous permet de voir le contenu rapidement sans fournir la valeur SHA-1 du blob, est d'utiliser git show, comme ceci :
git show :<STAGE>:everyone.md
Par exemple, pour obtenir le contenu de la même version qu'avec git cat-file -p , vous pouvez écrire git show :2:everyone.md.
Git enregistre les trois états des trois commits dans l'index de cette manière au début de la fusion. Il suit ensuite l'algorithme de fusion à trois voies pour résoudre rapidement les cas simples :
Au cas où les trois stades correspondent, alors la sélection est triviale.
Si un côté a fait un changement alors que l'autre n'a rien fait - c'est-à-dire, le stage 1 correspond au stage 2 - alors nous choisissons le stage 3, ou vice versa. C'est exactement ce qui s'est passé avec let_it_be.md et across_the_universe.md.
En cas de suppression sur la branche entrante, par exemple, et étant donné qu'il n'y a eu aucun changement sur la branche actuelle, alors nous verrions que le stage 1 correspond au stage 2, mais il n'y a pas de stage 3. Dans ce cas, git merge supprime le fichier pour la version fusionnée.
Ce qui est vraiment cool ici, c'est que pour la correspondance, Git n'a pas besoin des fichiers réels. Il peut plutôt se fier aux valeurs SHA-1 des blobs correspondants. De cette façon, Git peut facilement détecter l'état dans lequel se trouve un fichier.
 Git effectue le même algorithme de fusion à 3 voies au niveau des fichiers
Git effectue le même algorithme de fusion à 3 voies au niveau des fichiers
Pour everyone.md vous avez ce cas spécial - où stage 1, stage 2 et stage 3 sont tous différents les uns des autres. C'est-à-dire qu'ils ont des SHAs de blob différents. Il est temps d'aller plus loin et de comprendre le conflit de fusion. 😊
Une façon de faire cela serait d'utiliser simplement git diff. Dans un chapitre précédent, nous avons examiné git diff en détail, et vu qu'il montre les différences entre diverses combinaisons de l'arbre de travail, de l'index ou des commits.
Mais git diff a aussi un mode spécial pour aider avec les conflits de fusion :
git diff
 La sortie de
La sortie de git diff pendant un conflit de fusion
Cette sortie peut être déroutante au début, mais une fois que vous y êtes habitué, c'est assez clair. Commençons par la comprendre, puis voyons comment vous pouvez résoudre les conflits avec d'autres outils plus visuels.
La section en conflit est séparée par les marques "égal" (====), et marquée avec les branches correspondantes. Dans ce contexte, "ours" (la nôtre) est la branche actuelle. Dans cet exemple, ce serait john_branch_4, la branche vers laquelle HEAD pointait lorsque nous avons lancé la commande git merge. "Theirs" (la leur) est le MERGE_HEAD, la branche que nous fusionnons - dans ce cas, paul_branch_4.
Donc git diff sans aucun drapeau spécial montre les changements entre l'arbre de travail et l'index - qui dans ce cas sont les conflits encore à résoudre. La sortie n'inclut pas les changements mis en transit, ce qui est très pratique pour résoudre le conflit.
Il est temps de résoudre cela manuellement. Fun !
Alors, pourquoi est-ce un conflit ?
Pour Git, Paul et John ont fait des changements différents à la même ligne, pour quelques lignes. John l'a changée en une chose, et Paul l'a changée en une autre chose. Git ne peut pas décider laquelle est correcte.
Ce n'est pas le cas pour les dernières lignes, comme la ligne qui était "Everyone had a hard year" sur la base de fusion. Paul n'a pas changé cette ligne, ni les lignes l'entourant, donc sa version sur paul_branch_4, ou "theirs" dans notre cas, est d'accord avec merge_base. Pourtant la version de John, "ours", est différente. Ainsi git merge peut facilement décider de prendre cette version.
Mais qu'en est-il des lignes en conflit ?
Dans ce cas, je sais ce que je veux, et c'est en fait une combinaison de ces lignes. Je veux que les lignes commencent par "Everybody", suivant le changement de John, mais aussi inclure les "yeah"s de Paul. Alors allez-y et créez la version désirée en éditant everyone.md :
nano everyone.md
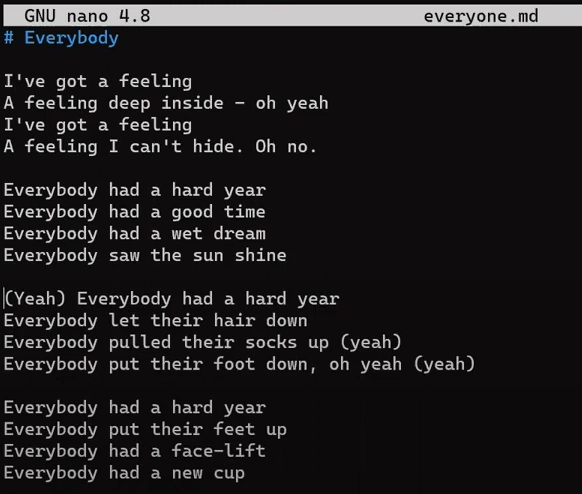 Édition manuelle du fichier pour atteindre l'état désiré
Édition manuelle du fichier pour atteindre l'état désiré
Pour comparer le fichier résultat à ce que vous aviez dans la branche avant la fusion, vous pouvez exécuter :
git diff --ours
De même, si vous souhaitez voir en quoi le résultat de la fusion diffère de la branche que vous avez fusionnée dans notre branche, vous pouvez exécuter :
git diff --theirs
Vous pouvez même voir en quoi le résultat est différent des deux côtés en utilisant :
git diff --base
Maintenant vous pouvez mettre en transit la version corrigée :
git add everyone.md
Après la mise en transit, si vous regardez git status, vous ne verrez aucun conflit :
 Après avoir mis en transit la version corrigée
Après avoir mis en transit la version corrigée everyone.md, il n'y a plus de conflits
Vous pouvez maintenant simplement utiliser git commit, et Git vous présentera un message de commit contenant des détails sur la fusion. Vous pouvez le modifier si vous le souhaitez, ou le laisser tel quel. Quel que soit le message de commit, Git créera un "commit de fusion" - c'est-à-dire un commit avec plus d'un parent.
Pour valider cela, considérez l'historique :
 L'historique après avoir terminé l'opération de fusion
L'historique après avoir terminé l'opération de fusion
john_branch_4 pointe maintenant vers le nouveau commit de fusion. La branche entrante, "theirs", dans ce cas, paul_branch_4, reste là où elle était.
Comment utiliser VS Code pour résoudre les conflits
Vous allez maintenant voir comment résoudre le même conflit en utilisant un outil graphique. Pour cet exemple, j'utilise VS Code, qui est un éditeur de code gratuit et populaire. Il existe de nombreux autres outils, mais le processus est similaire, donc je montrerai juste VS Code comme exemple.
D'abord, revenez à l'état avant la fusion :
git reset --hard HEAD~
Et essayez de fusionner à nouveau :
git merge paul_branch_4
Vous devriez être de retour au même statut :
 De retour au statut conflictuel
De retour au statut conflictuel
Voyons comment cela apparaît sur VS Code :
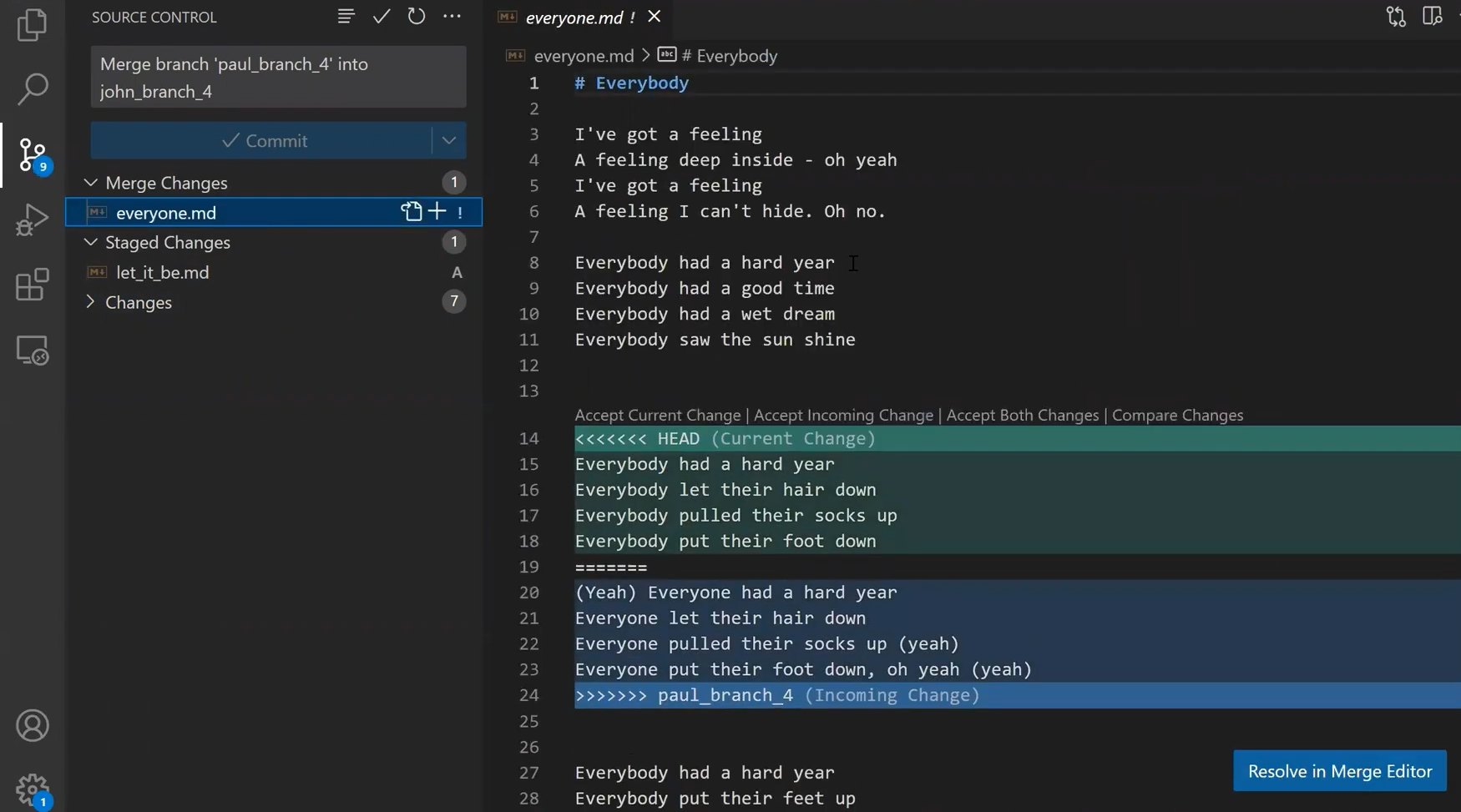 Résolution de conflit avec VS Code
Résolution de conflit avec VS Code
VS Code marque les différentes versions avec "Current Change" - qui est la version "ours", le HEAD actuel, et "Incoming Change" pour la branche que nous fusionnons dans la branche active. Vous pouvez accepter l'un des changements (ou les deux) en cliquant sur l'une des options.
Si vous avez cliqué sur Resolve in Merge editor, vous obtiendrez une vue plus visuelle de l'état. VS Code montre le statut de chaque ligne :
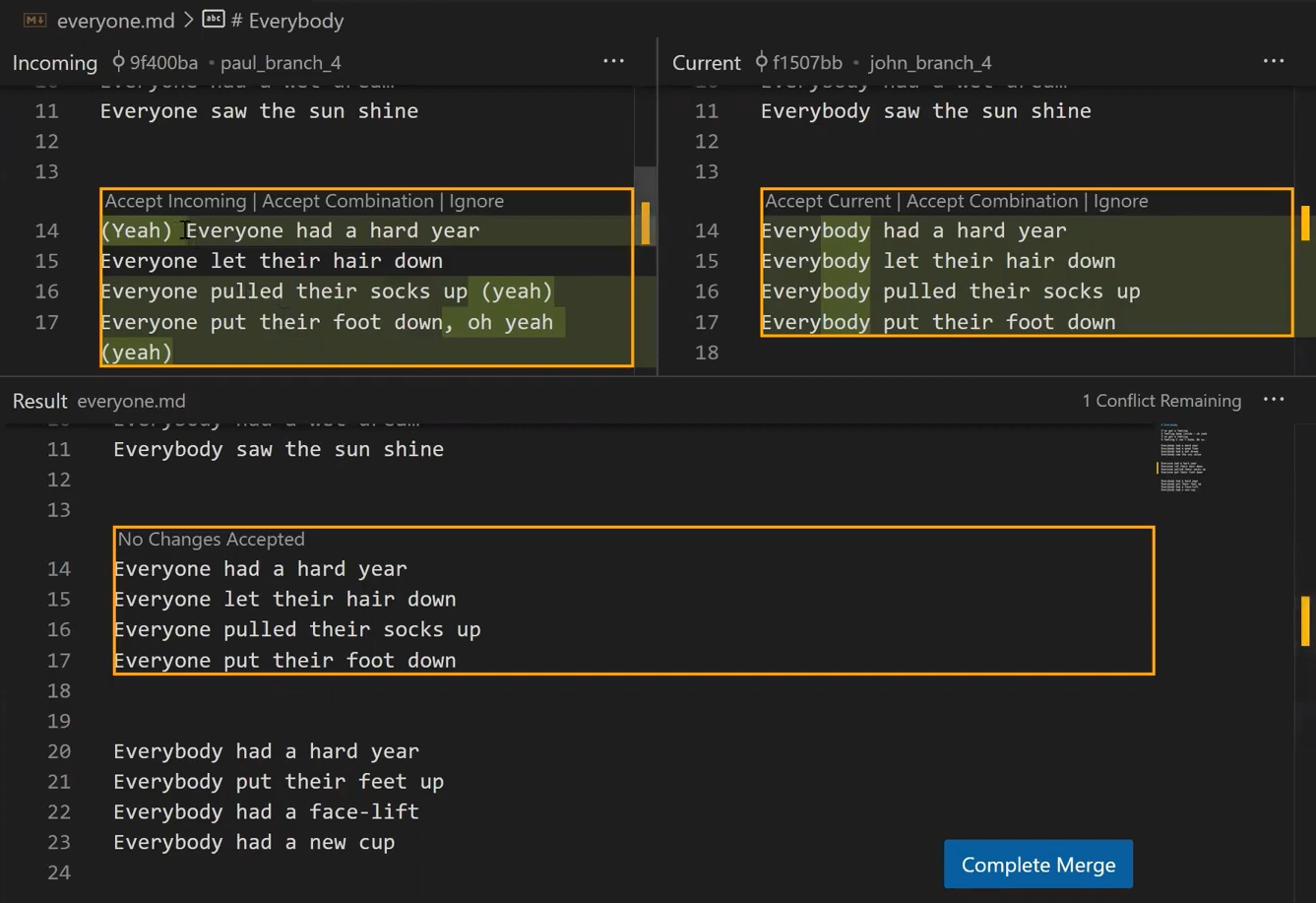 Éditeur de fusion de VS Code
Éditeur de fusion de VS Code
Si vous regardez de près, vous verrez que VS Code montre les changements à l'intérieur des mots - par exemple, montrant que "Everyone" a été changé en "Everybody", marquant les parties modifiées.
Vous pouvez accepter l'une ou l'autre version, ou vous pouvez accepter une combinaison. Dans ce cas, si vous cliquez sur "Accept Combination", vous obtenez ce résultat :
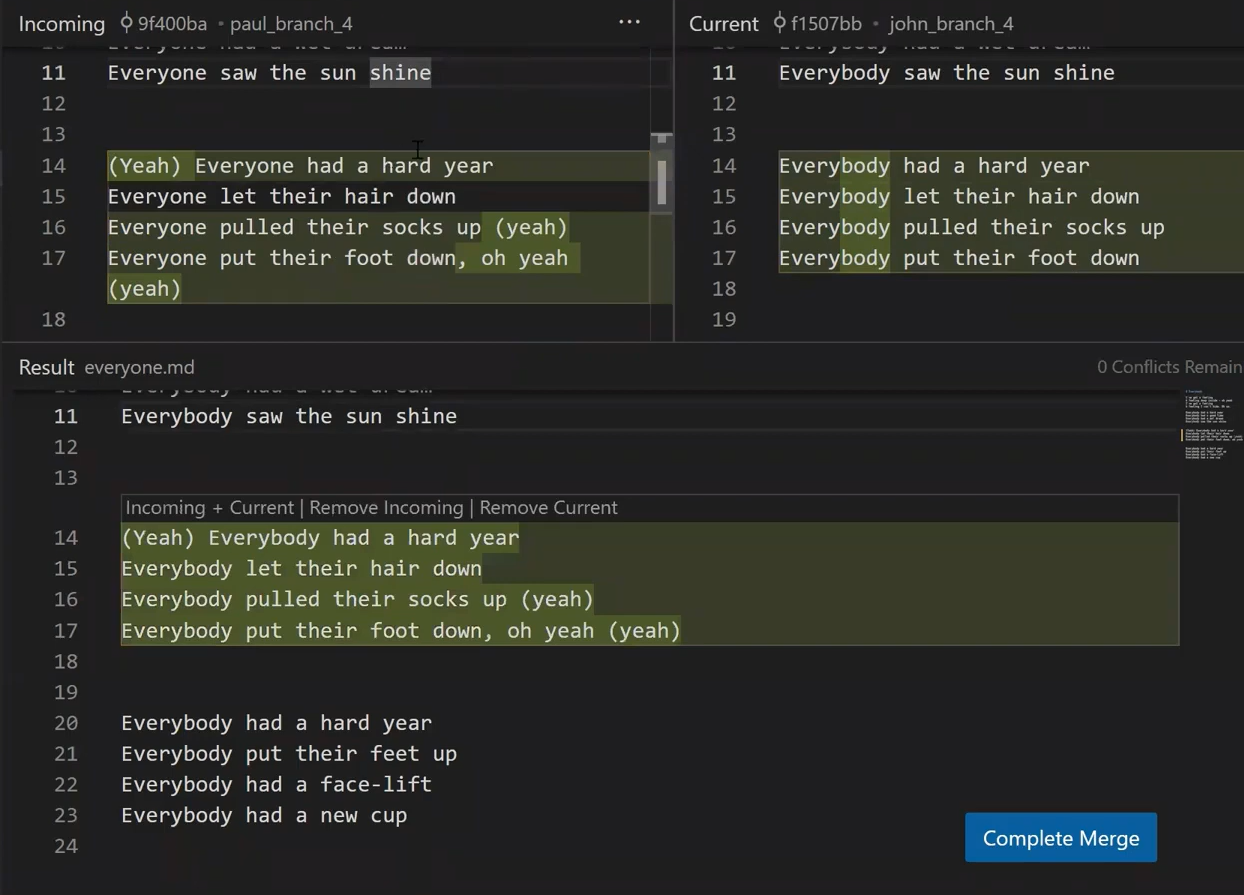 Éditeur de fusion de VS Code après avoir cliqué sur "Accept Combination"
Éditeur de fusion de VS Code après avoir cliqué sur "Accept Combination"
VS Code a fait un très bon travail ! Le même algorithme de fusion à trois voies a été implémenté ici et utilisé au niveau du mot plutôt qu'au niveau de la ligne. Donc VS Code a pu réellement résoudre ce conflit d'une manière assez impressionnante. Bien sûr, vous pouvez modifier la suggestion de VS Code, mais cela a fourni un très bon départ.
Un outil plus puissant
Eh bien, c'était la première fois dans ce livre que j'utilisais un outil avec une interface utilisateur graphique. En effet, les interfaces graphiques peuvent être pratiques pour comprendre ce qui se passe lorsque vous résolvez des conflits de fusion.
Cependant, comme dans de nombreux autres cas, quand nous avons besoin de vraiment comprendre ce qui se passe, la ligne de commande devient utile. Alors, revenons à la ligne de commande et apprenons un outil qui peut s'avérer utile dans des cas plus compliqués.
Encore une fois, revenez à l'état avant la fusion :
git reset --hard HEAD~
Et fusionnez :
git merge paul_branch_4
Et disons, vous n'êtes pas exactement sûr de ce qui s'est passé. Pourquoi y a-t-il un conflit ? Une commande très utile serait :
git log -p --merge
Pour rappel, git log montre l'historique des commits qui sont accessibles depuis HEAD. Ajouter -p indique à git log de montrer les commits avec les diffs qu'ils ont introduits. L'option --merge fait en sorte que la commande montre tous les commits contenant des changements pertinents pour tous les fichiers non fusionnés, sur l'une ou l'autre branche, avec leurs diffs.
Cela peut vous aider à identifier les changements dans l'historique qui ont conduit aux conflits. Donc dans cet exemple, vous verriez :
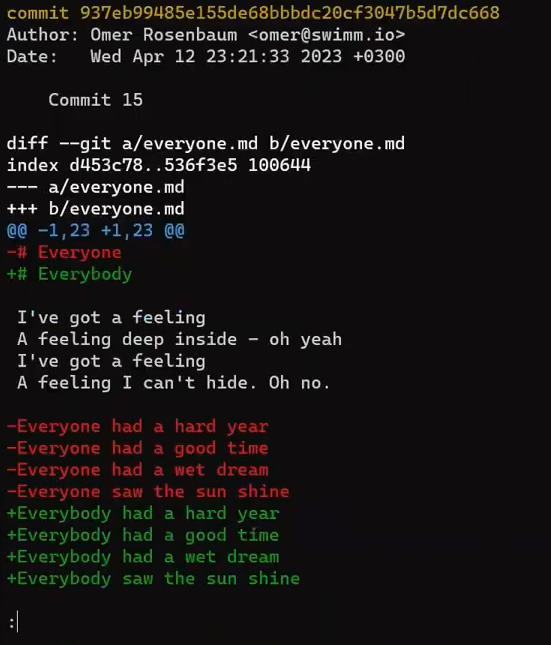 La sortie de
La sortie de git log -p --merge
Le premier commit que nous voyons est "Commit 15", car dans ce commit John a modifié everyone.md, un fichier qui a encore des conflits. Ensuite, Git montre "Commit 13", où Paul a changé everyone.md :
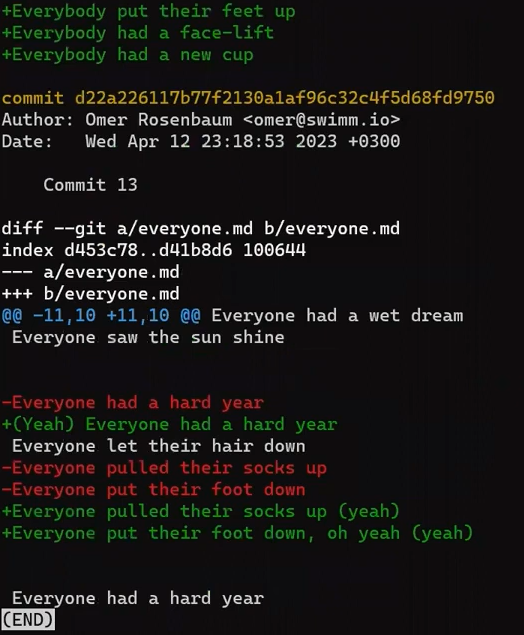 La sortie de
La sortie de git log -p --merge - suite
Remarquez que git log --merge n'a pas mentionné les commits précédents qui ont changé everyone.md avant "Commit 13", car ils n'affectaient pas le conflit actuel.
De cette façon, git log vous dit tout ce que vous devez savoir pour comprendre le processus qui vous a mis dans l'état conflictuel actuel. Cool ! 😎
En utilisant la ligne de commande, vous pouvez aussi demander à Git de prendre seulement un côté des changements - soit "ours" soit "theirs", même pour un fichier spécifique.
Vous pouvez aussi instruire Git de prendre certaines parties des diffs d'un fichier et une autre d'un autre fichier. Je fournirai des liens qui décrivent comment faire cela dans les ressources supplémentaires de ce chapitre dans l'annexe.
Pour la plupart, vous pouvez accomplir cela assez facilement, soit manuellement soit depuis l'interface utilisateur de votre IDE favori.
Pour l'instant, il est temps de faire un récapitulatif.
Récapitulatif - Comprendre Git Merge
Dans ce chapitre, vous avez eu un aperçu complet de la fusion avec Git. Vous avez appris que la fusion est le processus consistant à combiner les changements récents de plusieurs branches en un seul nouveau commit. Le nouveau commit a deux parents - ces commits qui avaient été les pointes des branches qui ont été fusionnées.
Nous avons considéré une fusion simple, en avance rapide, qui est possible lorsqu'une branche a divergé de la branche de base, et a ensuite juste ajouté des commits par-dessus la branche de base.
Nous avons ensuite considéré les fusions à trois voies, et expliqué le processus en trois étapes :
- Premièrement, Git localise la base de fusion. Pour rappel, c'est le premier commit qui est accessible depuis les deux branches.
- Deuxièmement, Git calcule deux diffs - un diff de la base de fusion à la première branche, et un autre diff de la base de fusion à la seconde branche. Git génère des patches basés sur ces diffs.
- Troisièmement et dernièrement, Git applique les deux patches à la base de fusion, en utilisant un algorithme de fusion à 3 voies. Le résultat est l'état du nouveau commit de fusion.
Nous avons plongé plus profondément dans le processus d'une fusion à 3 voies, que ce soit au niveau fichier ou au niveau morceau. Nous avons considéré quand Git est capable de compter sur une fusion à 3 voies pour résoudre automatiquement les conflits, et quand il ne peut tout simplement pas.
Vous avez vu la sortie de git diff quand nous sommes dans un état conflictuel, et comment résoudre les conflits soit manuellement soit avec VS Code.
Il y a beaucoup plus à dire sur les fusions - différentes stratégies de fusion, fusions récursives, et ainsi de suite. Pourtant, je crois que ce chapitre a couvert tout ce qui est nécessaire pour que vous ayez une compréhension robuste de ce qu'est la fusion, et de ce qui se passe sous le capot dans la grande majorité des cas.
Ressources liées aux Beatles
- https://www.the-paulmccartney-project.com/song/ive-got-a-feeling/
- https://www.cheatsheet.com/entertainment/did-john-lennon-or-paul-mccartney-write-the-classic-a-day-in-the-life.html/
- http://lifeofthebeatles.blogspot.com/2009/06/ive-got-feeling-lyrics.html
Chapitre 8 - Comprendre Git Rebase
L'un des outils les plus puissants qu'un développeur puisse avoir dans sa boîte à outils est git rebase. Pourtant, il est connu pour être complexe et mal compris.
La vérité est que si vous comprenez ce qu'il fait réellement, git rebase est un outil très élégant et simple pour réaliser tant de choses différentes dans Git.
Dans les chapitres précédents de cette partie, vous avez appris ce que sont les diffs Git, ce qu'est une fusion et comment Git résout les conflits de fusion. Dans ce chapitre, vous comprendrez ce qu'est Git rebase, pourquoi il est différent de merge et comment rebaser avec confiance.
Court résumé - Qu'est-ce que Git Merge ?
Sous le capot, git rebase et git merge sont des choses très, très différentes. Alors pourquoi les gens les comparent-ils tout le temps ?
La raison est leur utilisation. Lorsque nous travaillons avec Git, nous travaillons généralement dans différentes branches et introduisons des changements dans ces branches.
Dans le chapitre précédent, nous avons considéré l'exemple où John et Paul (des Beatles) co-écrivaient une nouvelle chanson. Ils ont commencé à partir de la branche main, puis chacun a divergé, modifié les paroles et validé ses changements.
Ensuite, les deux voulaient intégrer leurs changements, ce qui est quelque chose qui arrive très fréquemment lorsque l'on travaille avec Git.
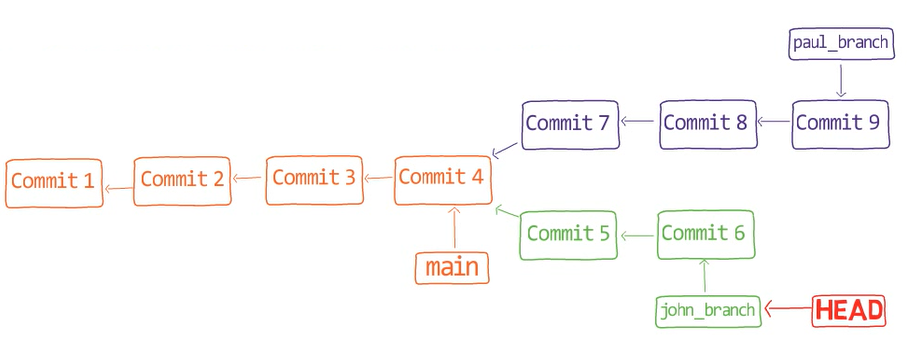 _Un historique divergent -
_Un historique divergent - paul_branch et john_branch ont divergé de main_
Il y a deux façons principales d'intégrer des changements introduits dans différentes branches dans Git, ou en d'autres termes, différents commits et historiques de commit. Ce sont merge et rebase.
Dans le chapitre précédent, nous avons appris à bien connaître git merge. Nous avons vu que lors de l'exécution d'une fusion, nous créons un commit de fusion - où le contenu de ce commit est une combinaison des deux branches, et il a aussi deux parents, un dans chaque branche.
Donc, disons que vous êtes sur la branche john_branch (en supposant l'historique représenté dans le dessin ci-dessus), et que vous exécutez git merge paul_branch. Vous arriverez à cet état - où sur john_branch, il y a un nouveau commit avec deux parents. Le premier sera le commit sur la branche john_branch où HEAD pointait vers un état avant d'effectuer la fusion - dans ce cas, "Commit 6". Le second sera le commit pointé par paul_branch, "Commit 9".
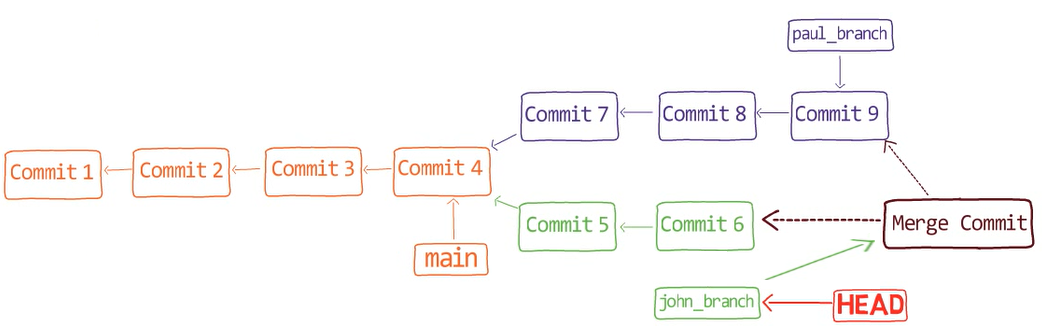 _Le résultat de l'exécution de
_Le résultat de l'exécution de git merge paul_branch : un nouveau Commit de Fusion avec deux parents_
Regardez à nouveau le graphique d'historique : vous avez créé un historique divergent. Vous pouvez en fait voir où il s'est ramifié et où il a fusionné à nouveau.
Donc, lorsque vous utilisez git merge, vous ne réécrivez pas l'historique - mais plutôt, vous ajoutez un commit à l'historique existant. Et spécifiquement, un commit qui crée un historique divergent.
En quoi git rebase est-il différent de git merge ?
Lorsque vous utilisez git rebase, quelque chose de différent se produit.
Commençons par une vue d'ensemble : si vous êtes sur paul_branch, et utilisez git rebase john_branch, Git va à l'ancêtre commun de la branche de John et de la branche de Paul. Ensuite, il prend les patches introduits dans les commits sur la branche de Paul, et applique ces changements à la branche de John.
Donc ici, vous utilisez rebase pour prendre les changements qui ont été validés sur une branche - la branche de Paul - et les rejouer sur une branche différente, john_branch.
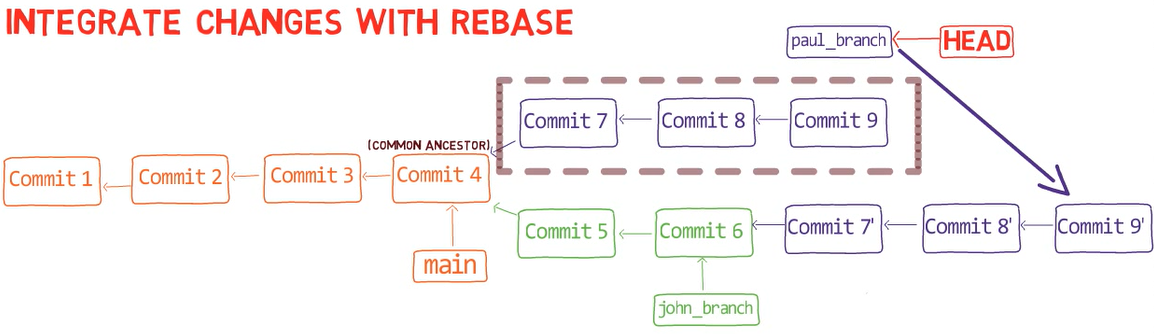 _Le résultat de l'exécution de
_Le résultat de l'exécution de git rebase john_branch : les commits sur paul_branch ont été "rejoués" par-dessus john_branch_
Attendez, qu'est-ce que cela signifie ?
Nous allons maintenant prendre cela petit à petit pour nous assurer que vous comprenez bien ce qui se passe sous le capot 😎
cherry-pick comme base pour Rebase
Il est utile de penser au rebase comme l'exécution de git cherry-pick - une commande qui prend un commit, calcule le patch que ce commit introduit en calculant la différence entre le commit parent et le commit lui-même, et ensuite le cherry-pick "rejoue" cette différence.
Faisons cela manuellement.
Si nous regardons la différence introduite par "Commit 5" en effectuant git diff main <SHA_OF_COMMIT_5> :
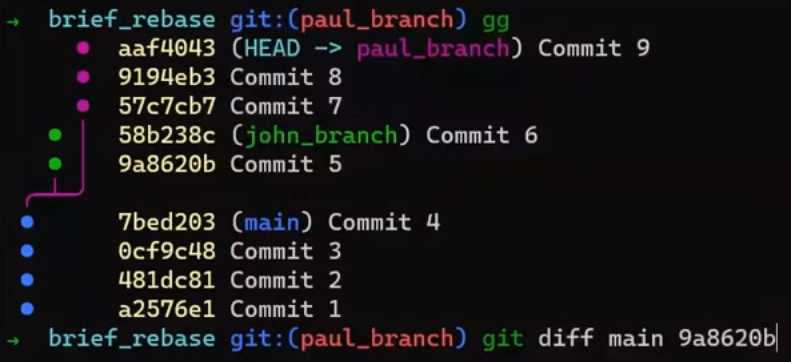 Exécution de
Exécution de git diff pour observer le patch introduit par "Commit 5"
Comme toujours, vous êtes encouragé à exécuter les commandes vous-même pendant la lecture de ce chapitre. Sauf indication contraire, j'utiliserai le dépôt suivant :
https://github.com/Omerr/rebase_playground.git
Je vous recommande de le cloner localement et d'avoir le même point de départ que celui que j'utilise pour ce chapitre.
Vous pouvez voir que dans ce commit, John a commencé à travailler sur une chanson appelée "Lucy in the Sky with Diamonds" :
 La sortie de
La sortie de git diff - le patch introduit par "Commit 5"
Pour rappel, vous pouvez également utiliser la commande git show pour obtenir la même sortie :
git show <SHA_OF_COMMIT_5>
Maintenant, si vous faites un cherry-pick de ce commit, vous introduirez ce changement spécifiquement, sur la branche active. Passez d'abord à main :
git checkout main (ou git switch main)
Et créez une autre branche :
git checkout -b my_branch (ou git switch -c my_branch)
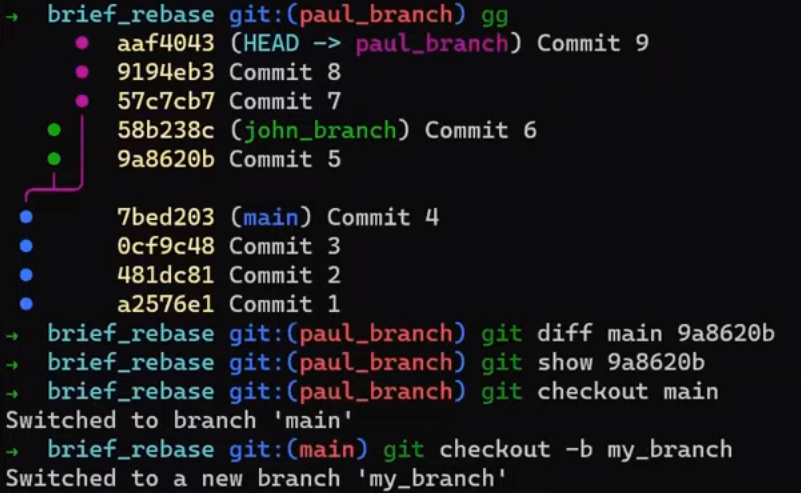 _Création de
_Création de my_branch qui branche depuis main_
Ensuite, faites un cherry-pick de "Commit 5" :
git cherry-pick <SHA_OF_COMMIT_5>
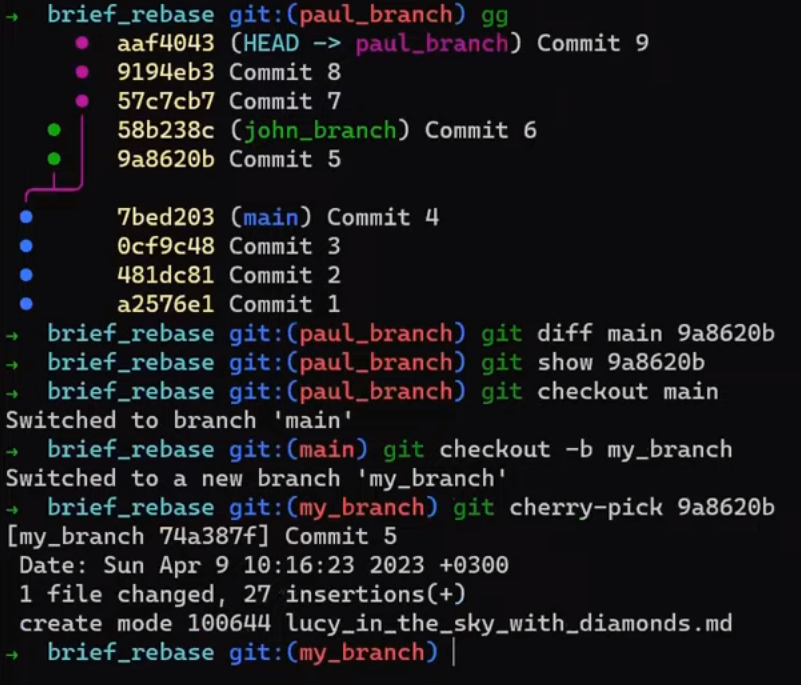 Utiliser
Utiliser cherry-pick pour appliquer les changements introduits dans "Commit 5" sur main
Considérez le journal (sortie de git lol) :
 La sortie de
La sortie de git lol
Il semble que vous ayez copié-collé "Commit 5". Rappelez-vous que même s'il a le même message de commit, et introduit les mêmes changements, et pointe même vers le même objet arbre que le "Commit 5" original dans ce cas - c'est toujours un objet commit différent, car il a été créé avec un horodatage différent.
En regardant les changements, en utilisant git show HEAD :
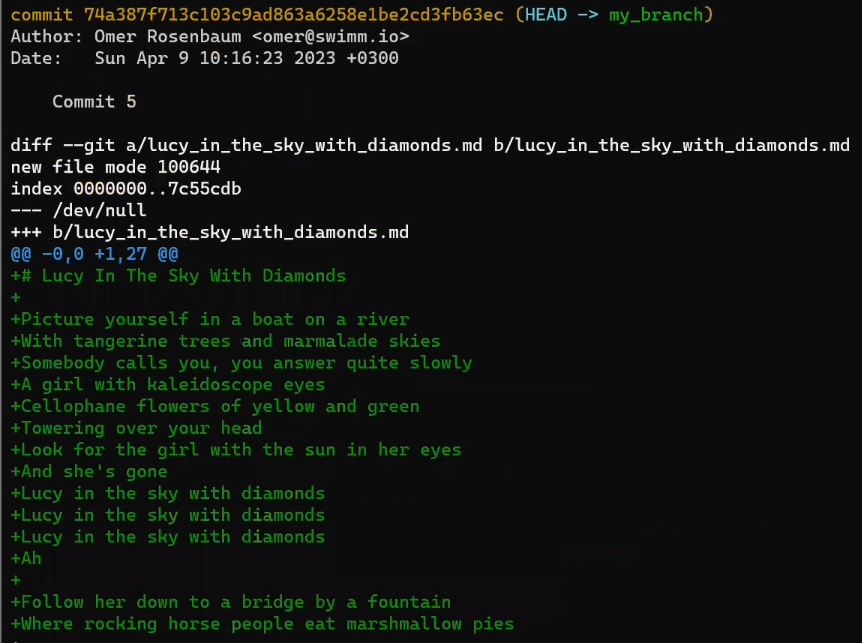 La sortie de
La sortie de git show HEAD
Ce sont les mêmes que ceux de "Commit 5".
Et bien sûr, si vous regardez le fichier (disons, en utilisant nano lucy_in_the_sky_with_diamonds.md), il sera dans le même état qu'il l'a été après le "Commit 5" original.
Cool ! 😎
Vous pouvez maintenant supprimer la nouvelle branche pour qu'elle n'apparaisse pas dans votre historique à chaque fois :
git checkout main
git branch -D my_branch
Au-delà de cherry-pick - Comment utiliser git rebase
Vous pouvez voir git rebase comme un moyen d'effectuer plusieurs cherry-picks l'un après l'autre - c'est-à-dire, de "rejouer" plusieurs commits. Ce n'est pas la seule chose que vous pouvez faire avec rebase, mais c'est un bon point de départ pour notre explication.
Il est temps de jouer avec git rebase !
Avant, vous avez fusionné paul_branch dans john_branch. Que se passerait-il si vous rebasiez paul_branch au-dessus de john_branch ? Vous obtiendriez un historique très différent.
En substance, il semblerait que nous ayons pris les changements introduits dans les commits sur paul_branch, et les ayons rejoués sur john_branch. Le résultat serait un historique linéaire.
Pour comprendre le processus, je fournirai la vue d'ensemble, puis je plongerai plus profondément dans chaque étape. Le processus de rebasage d'une branche au-dessus d'une autre branche est le suivant :
- Trouver l'ancêtre commun.
- Identifier les commits à "rejouer".
- Pour chaque commit
X, calculerdiff(parent(X), X), et le stocker comme unpatch(X). - Déplacer
HEADvers la nouvelle base. - Appliquer les patches générés dans l'ordre sur la branche cible. À chaque fois, créer un nouvel objet commit avec le nouvel état.
Le processus de création de nouveaux commits avec les mêmes ensembles de changements que ceux existants est également appelé "replaying" (rejeu) de ces commits, un terme que nous avons déjà utilisé.
Il est temps de mettre la main à la pâte avec Rebase
Avant d'exécuter la commande suivante, assurez-vous d'avoir john_branch localement, donc exécutez :
git checkout john_branch
Commencez à partir de la branche de Paul :
git checkout paul_branch
Voici l'historique :
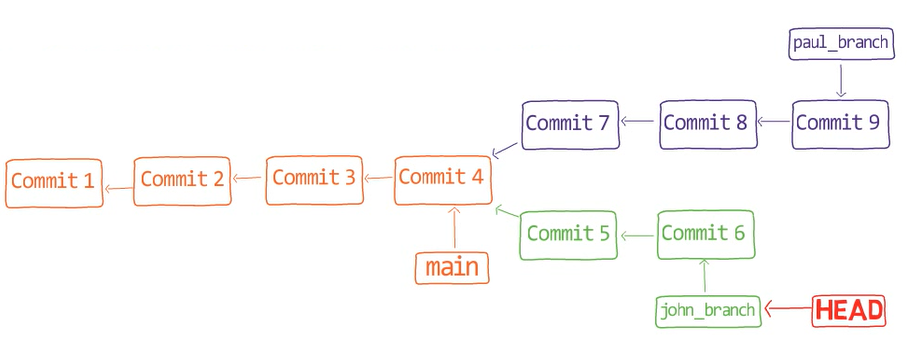 Historique des commits avant d'effectuer
Historique des commits avant d'effectuer git rebase
Et maintenant, la partie excitante :
git rebase john_branch
Et observez l'historique :
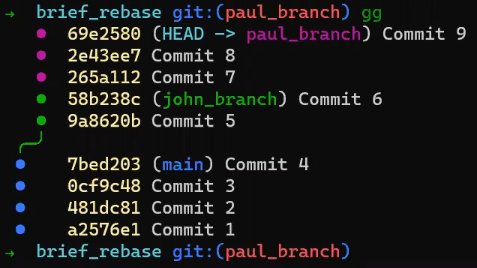 L'historique après le rebasage
L'historique après le rebasage
Avec git merge vous avez ajouté à l'historique, tandis qu'avec git rebase vous réécrivez l'historique. Vous créez de nouveaux objets commit. De plus, le résultat est un graphique d'historique linéaire - plutôt qu'un graphique divergent.
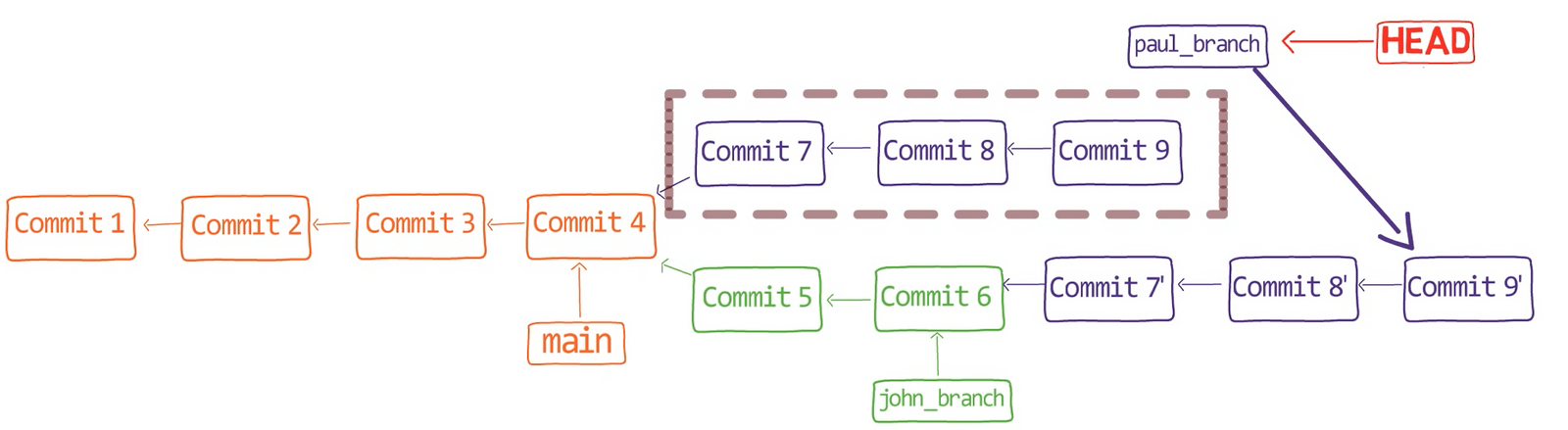 L'historique après le rebasage
L'historique après le rebasage
En substance, vous avez "copié" les commits qui étaient sur paul_branch et qui ont été introduits après "Commit 4", et les avez "collés" au-dessus de john_branch.
La commande s'appelle "rebase" (rebaser), car elle change le commit de base de la branche depuis laquelle elle est exécutée. C'est-à-dire, dans votre cas, avant d'exécuter git rebase, la base de paul_branch était "Commit 4" - car c'est là que la branche est "née" (de main). Avec rebase, vous avez demandé à Git de lui donner une autre base - c'est-à-dire, faire comme si elle était née de "Commit 6".
Pour faire cela, Git a pris ce qui était le "Commit 7", et a "rejoué" les changements introduits dans ce commit sur le "Commit 6". Ensuite, il a créé un nouvel objet commit. Cet objet diffère du "Commit 7" original sur trois aspects :
- Il a un horodatage différent.
- Il a un commit parent différent - "Commit 6", plutôt que "Commit 4".
- L'objet arbre vers lequel il pointe est différent - car les changements ont été introduits dans l'arbre pointé par "Commit 6", et non l'arbre pointé par "Commit 4".
Remarquez le dernier commit ici, "Commit 9'". L'instantané qu'il représente (c'est-à-dire l'arbre vers lequel il pointe) est exactement le même arbre que vous obtiendriez en fusionnant les deux branches. L'état des fichiers dans votre dépôt Git serait le même que si vous utilisiez git merge. C'est seulement l'historique qui est différent, et les objets commit bien sûr.
Maintenant, vous pouvez simplement utiliser :
git checkout main
git merge paul_branch
Hm.... Que se passerait-il si vous exécutiez cette dernière commande ? Considérez à nouveau l'historique des commits, après avoir fait un checkout de main :
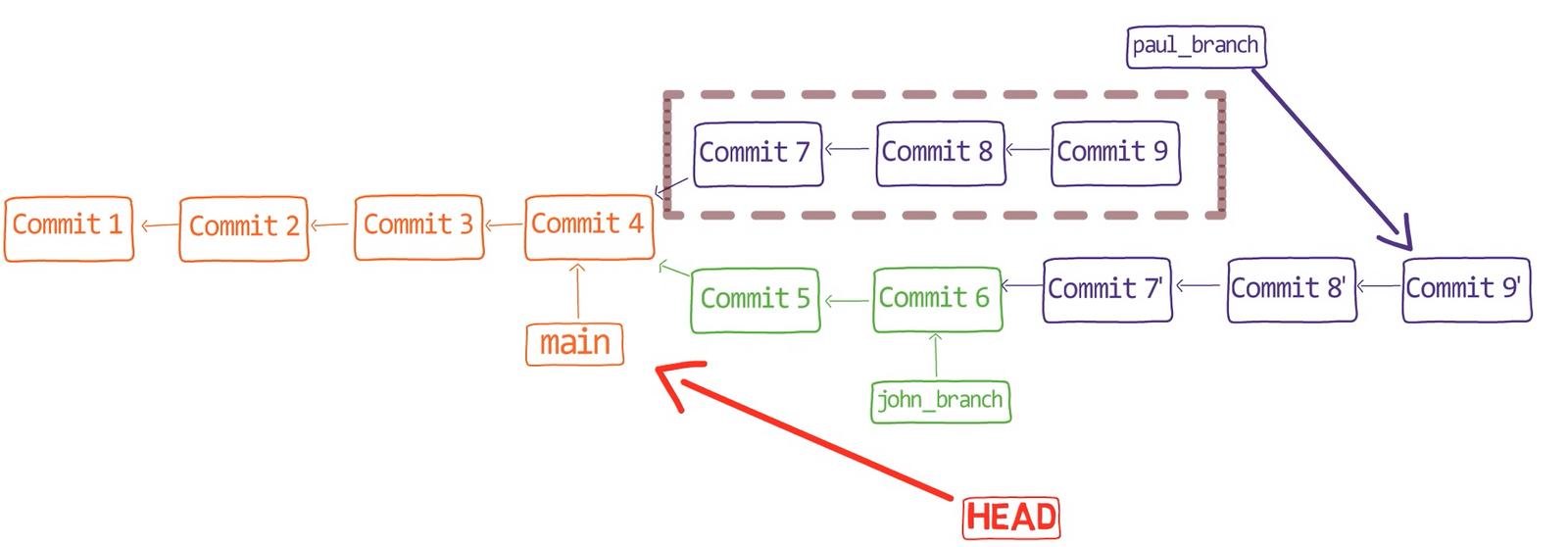 L'historique après le rebasage et le checkout de
L'historique après le rebasage et le checkout de main
Qu'est-ce que cela signifierait de fusionner main et paul_branch ?
En effet, Git peut simplement effectuer une fusion en avance rapide, car l'historique est complètement linéaire (si vous avez besoin d'un rappel sur les fusions en avance rapide, consultez le chapitre précédent). En conséquence, main et paul_branch pointent maintenant vers le même commit :
 Le résultat d'une fusion en avance rapide
Le résultat d'une fusion en avance rapide
Rebasage avancé dans Git
Maintenant que vous comprenez les bases du rebase, il est temps de considérer des cas plus avancés, où des options et arguments supplémentaires pour la commande rebase seront utiles.
Dans l'exemple précédent, lorsque vous n'avez utilisé que rebase (sans options supplémentaires), Git a rejoué tous les commits depuis l'ancêtre commun jusqu'à la pointe de la branche actuelle.
Mais rebase est un super-pouvoir. C'est une commande toute-puissante capable de… eh bien, réécrire l'historique. Et cela peut être utile si vous voulez modifier l'historique pour vous l'approprier.
Annulez la dernière fusion en faisant pointer main vers "Commit 4" à nouveau :
git reset --hard <ORIGINAL_COMMIT 4>
 "Annulation" de la dernière opération de fusion
"Annulation" de la dernière opération de fusion
Et annulez le rebasage en utilisant :
git checkout paul_branch
git reset --hard <ORIGINAL_COMMIT 9>
 "Annulation" de l'opération de rebasage
"Annulation" de l'opération de rebasage
Remarquez que vous êtes revenu exactement au même historique que vous aviez :
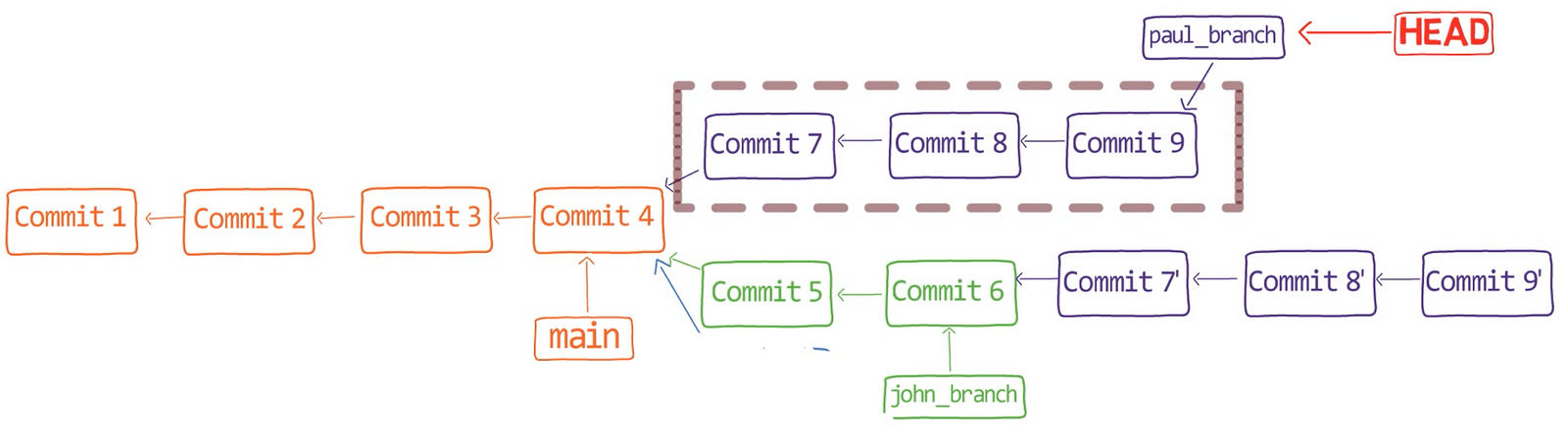 Visualisation de l'historique après avoir "annulé" l'opération de rebasage
Visualisation de l'historique après avoir "annulé" l'opération de rebasage
Pour être clair, "Commit 9" ne disparaît pas simplement quand il n'est pas accessible depuis le HEAD actuel. Il est plutôt toujours stocké dans la base de données d'objets. Et comme vous avez utilisé git reset maintenant pour changer HEAD pour pointer vers ce commit, vous avez pu le récupérer, ainsi que ses commits parents puisqu'ils sont aussi stockés dans la base de données. Plutôt cool, hein ? 😎
Vous en apprendrez plus sur git reset dans la prochaine partie, où nous discutons de l'annulation des changements dans Git.
Affichez les changements que Paul a introduits :
git show HEAD
git show HEAD montre le patch introduit par "Commit 9"
Continuez à remonter dans le graphique des commits :
git show HEAD~
git show HEAD~ (idem que git show HEAD~1) montre le patch introduit par "Commit 8"
Et un commit plus loin :
git show HEAD~2
git show HEAD~2 montre le patch introduit par "Commit 7"
Peut-être que Paul ne veut pas de ce genre d'historique. Il veut plutôt faire comme s'il avait introduit les changements de "Commit 7" et "Commit 8" en un seul commit.
Pour cela, vous pouvez utiliser un rebase interactif. Pour faire cela, nous ajoutons l'option -i (ou --interactive) à la commande rebase :
git rebase -i <SHA_OF_COMMIT_4>
Ou, puisque main pointe vers "Commit 4", nous pouvons exécuter :
git rebase -i main
En exécutant cette commande, vous dites à Git d'utiliser une nouvelle base, "Commit 4". Vous demandez donc à Git de revenir à tous les commits qui ont été introduits après "Commit 4" et qui sont accessibles depuis le HEAD actuel, et de rejouer ces commits.
Pour chaque commit rejoué, Git nous demande ce que nous aimerions en faire :
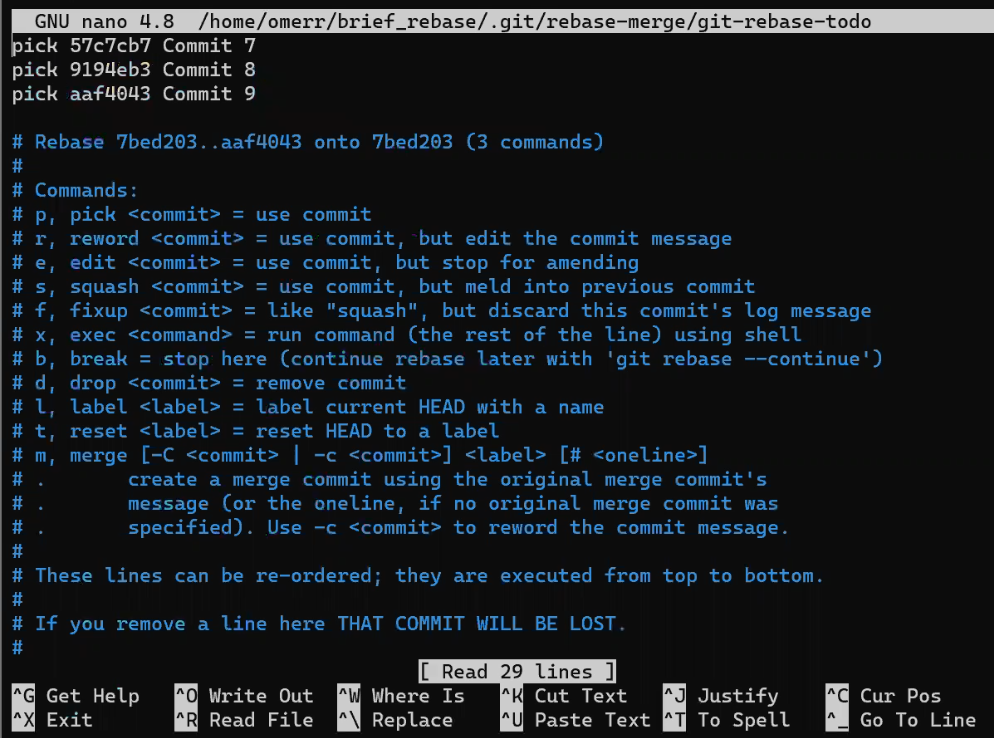
git rebase -i main vous invite à sélectionner quoi faire avec chaque commit
Dans ce contexte, il est utile de penser à un commit comme à un patch. C'est-à-dire "Commit 7", comme dans "le patch que "Commit 7" a introduit par-dessus son parent".
Une option est d'utiliser pick. C'est le comportement par défaut, qui dit à Git de rejouer les changements introduits dans ce commit. Dans ce cas, si vous le laissez tel quel - et faites pick (choisir) pour tous les commits - vous obtiendrez le même historique, et Git ne créera même pas de nouveaux objets commit.
Une autre option est squash. Un commit squashé (écrasé) aura son contenu "plié" dans le contenu du commit qui le précède. Donc dans notre cas, Paul aimerait squasher "Commit 8" dans "Commit 7" :
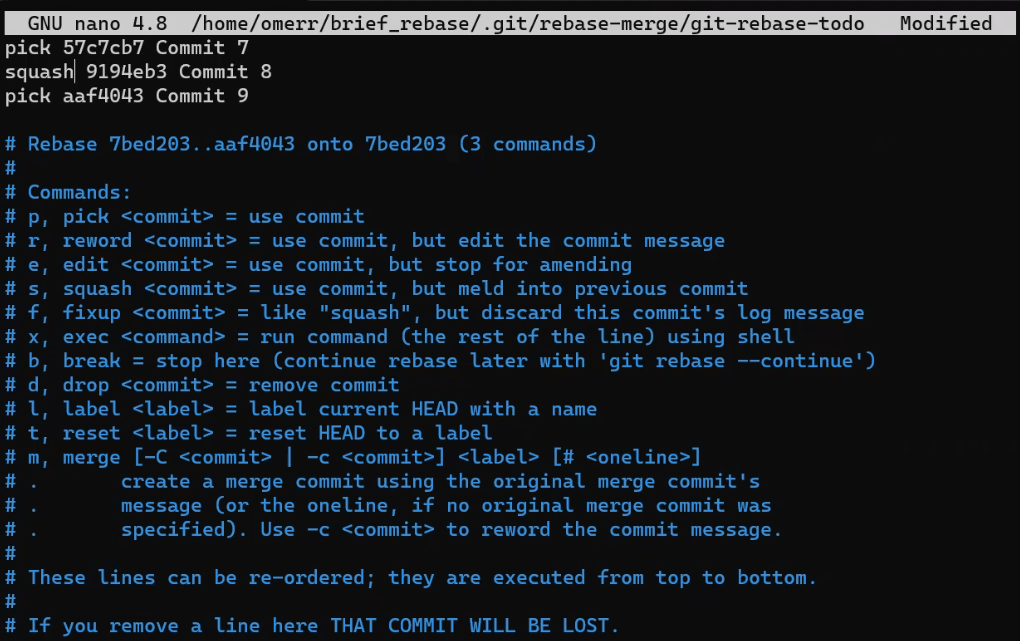 Squasher "Commit 8" dans "Commit 7"
Squasher "Commit 8" dans "Commit 7"
Comme vous pouvez le voir, git rebase -i fournit des options supplémentaires, mais nous n'entrerons pas dans le détail de toutes dans ce chapitre. Si vous laissez le rebase s'exécuter, vous serez invité à sélectionner un message de commit pour le commit nouvellement créé (c'est-à-dire celui qui a introduit les changements à la fois de "Commit 7" et "Commit 8") :
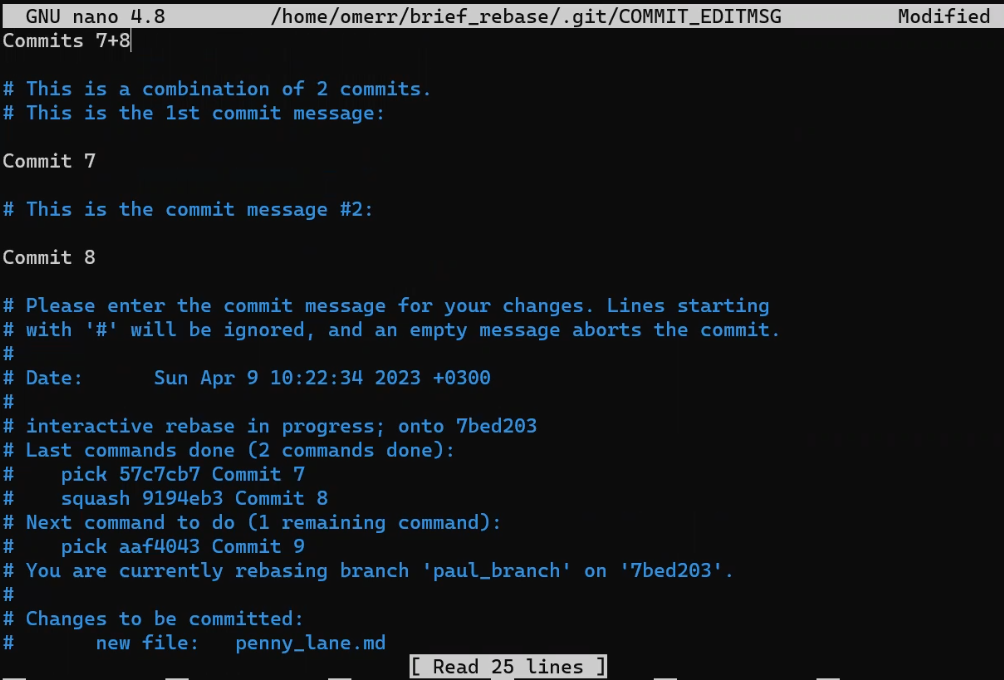 Fournir le message de commit : Commits 7+8
Fournir le message de commit : Commits 7+8
Et regardez l'historique :
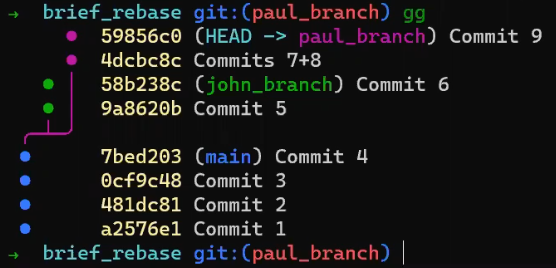 L'historique après le rebase interactif
L'historique après le rebase interactif
Exactement comme nous le voulions ! Sur paul_branch, nous avons "Commit 9" (bien sûr, c'est un objet différent du "Commit 9" original). Cet objet pointe vers "Commits 7+8", qui est un seul commit introduisant les changements à la fois du "Commit 7" original et du "Commit 8" original. Le parent de ce commit est "Commit 4", là où main pointe.
Oh wow, c'est pas cool ça ? 😎
git rebase vous accorde un contrôle illimité sur la forme de n'importe quelle branche. Vous pouvez l'utiliser pour réorganiser des commits, ou pour supprimer des changements incorrects, ou modifier un changement rétrospectivement. Alternativement, vous pourriez peut-être déplacer la base de votre branche sur un autre commit, n'importe quel commit que vous souhaitez.
Comment utiliser l'option --onto de git rebase
Considérons un exemple de plus. Revenez à main :
git checkout main
Et supprimez les pointeurs vers paul_branch et john_branch pour ne plus les voir dans le graphique des commits :
git branch -D paul_branch
git branch -D john_branch
Ensuite, branchez depuis main vers une nouvelle branche :
git checkout -b new_branch
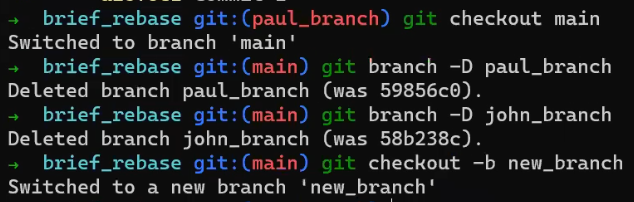 _Création de
_Création de new_branch qui diverge de main_
Voici l'historique propre que vous devriez avoir :
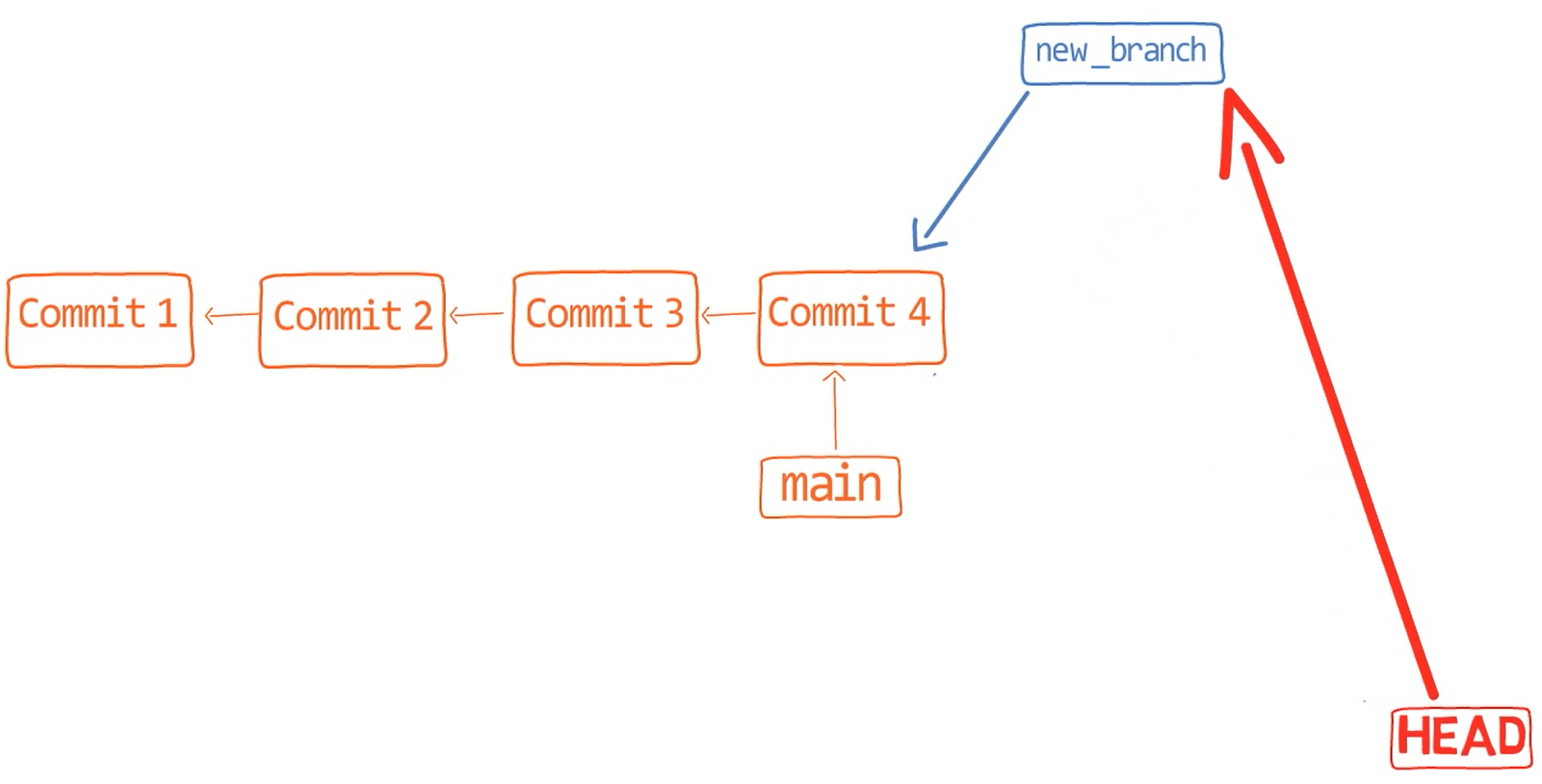 _Un historique propre avec
_Un historique propre avec new_branch qui diverge de main_
Maintenant, changez le fichier code.py (par exemple, ajoutez une nouvelle fonction) et validez vos changements :
nano code.py
 _Ajout de la fonction
_Ajout de la fonction new_branch à code.py_
git add code.py
git commit -m "Commit 10"
Revenez à main :
git checkout main
Et introduisez un autre changement - ajouter une docstring au début du fichier :
 Ajout d'une docstring au début du fichier
Ajout d'une docstring au début du fichier
Il est temps de mettre en transit et de valider ces changements :
git add code.py
git commit -m "Commit 11"
Et encore un autre changement, peut-être ajouter @Author à la docstring :
 Ajout de
Ajout de @Author à la docstring
Validez ce changement également :
git add code.py
git commit -m "Commit 12"
Oh attendez, maintenant je réalise que je voulais que vous fassiez les changements introduits dans "Commit 11" comme partie de new_branch. Argh. Que pouvez-vous faire ?
Considérez l'historique :
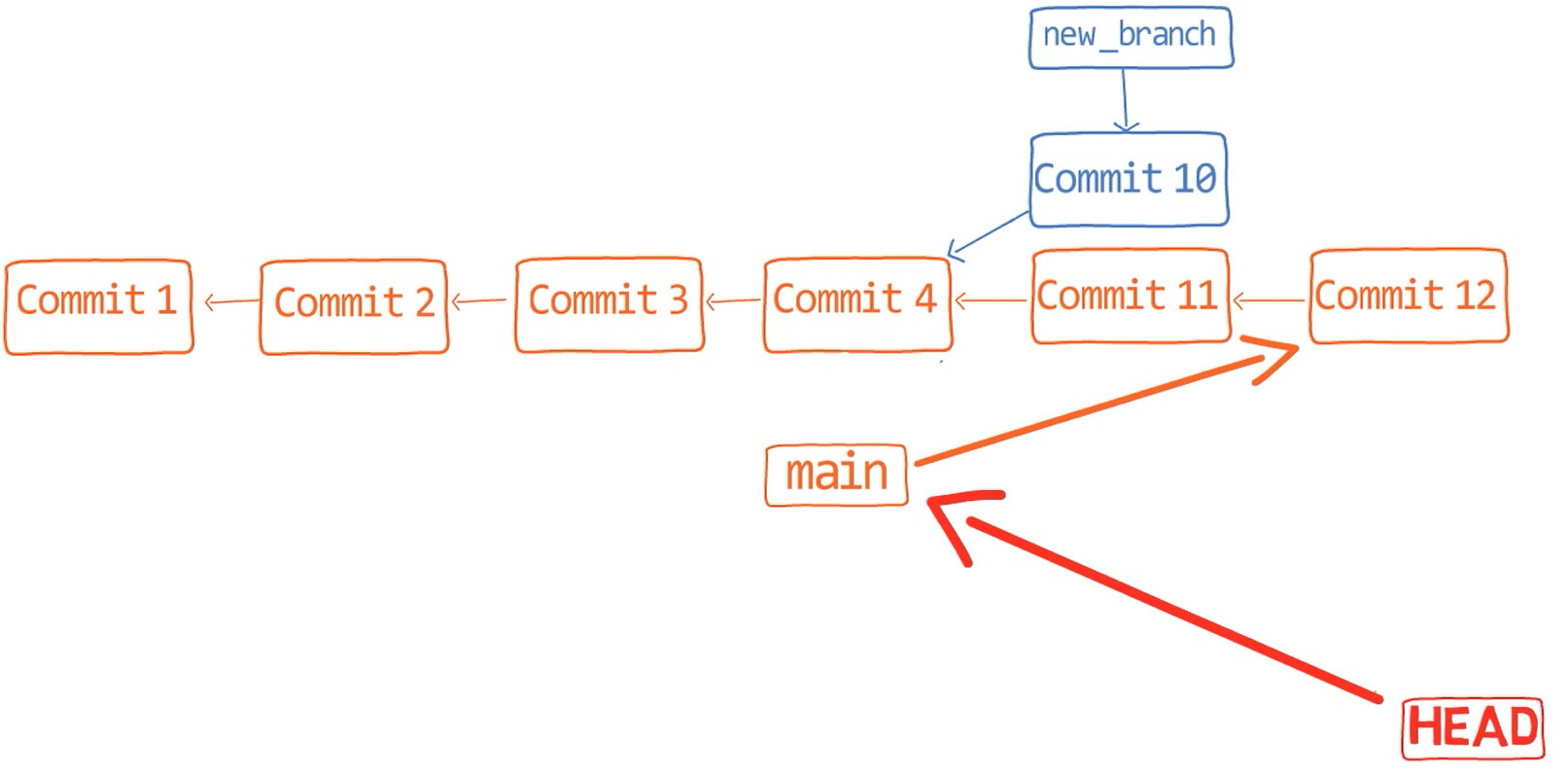 L'historique après l'introduction de "Commit 12"
L'historique après l'introduction de "Commit 12"
Au lieu d'avoir "Commit 11" résidant uniquement sur la branche main, je veux qu'il soit sur à la fois la branche main ainsi que new_branch. Visuellement, je voudrais le déplacer vers le bas du graphique ici :
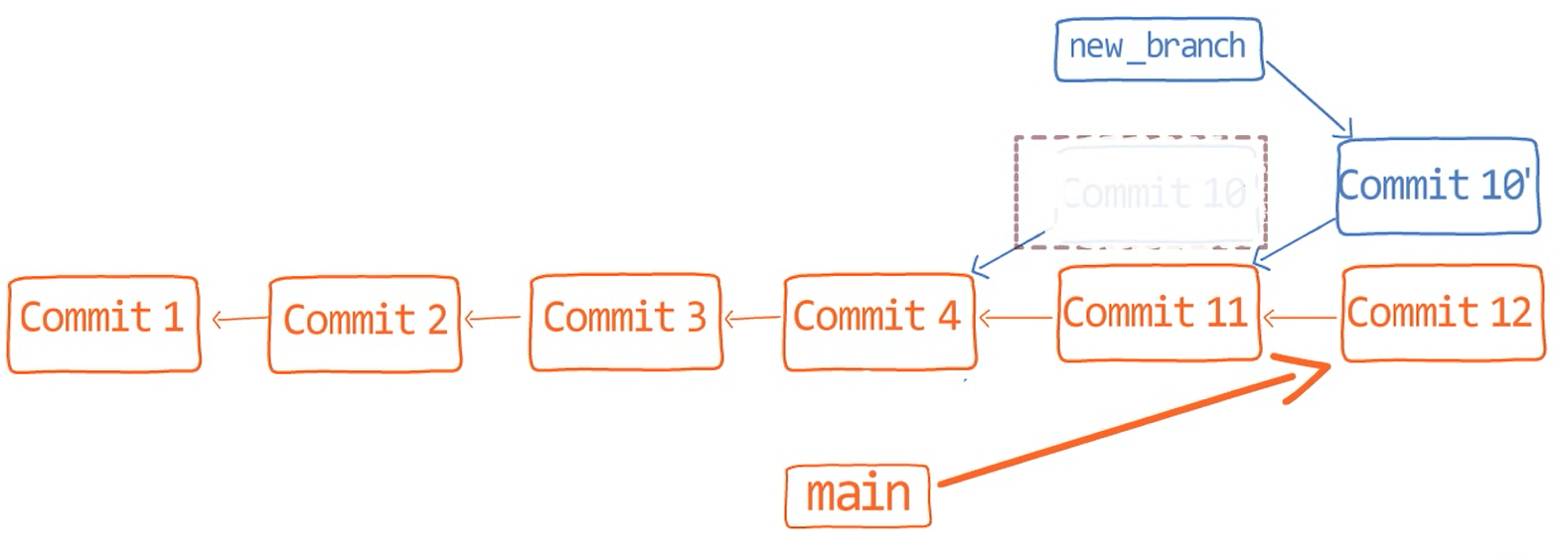 Visuellement, je veux que vous "poussiez vers le bas" "Commit 10"
Visuellement, je veux que vous "poussiez vers le bas" "Commit 10"
Voyez-vous où je veux en venir ? 😇
Eh bien, rebase vous permet essentiellement de rejouer les changements introduits dans new_branch, ceux introduits dans "Commit 10", comme s'ils avaient été initialement menés sur "Commit 11", plutôt que "Commit 4".
Pour faire cela, vous pouvez utiliser d'autres arguments de git rebase. Spécifiquement, vous pouvez utiliser git rebase --onto, qui prend optionnellement trois paramètres :
git rebase --onto <new_parent> <old_parent> <until>
C'est-à-dire que vous prenez tous les commits entre old_parent et until, et vous les "coupez" et "collez" sur (onto) new_parent.
Dans ce cas, vous diriez à Git que vous voulez prendre tout l'historique introduit entre l'ancêtre commun de main et new_branch, qui est "Commit 4", et avoir comme nouvelle base pour cet historique "Commit 11". Pour faire cela, utilisez :
git rebase --onto <SHA_OF_COMMIT_11> main new_branch
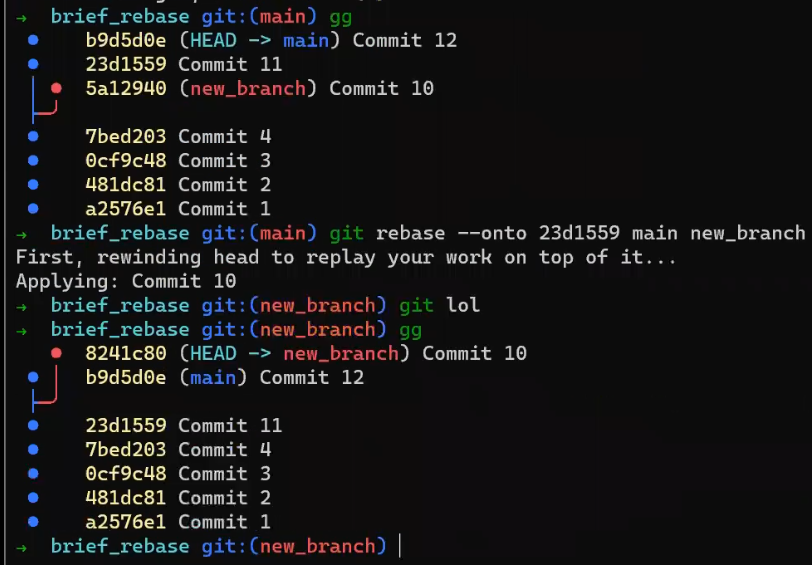 L'historique avant et après le rebase, "Commit 10" a été "poussé"
L'historique avant et après le rebase, "Commit 10" a été "poussé"
Et regardez notre bel historique ! 😍
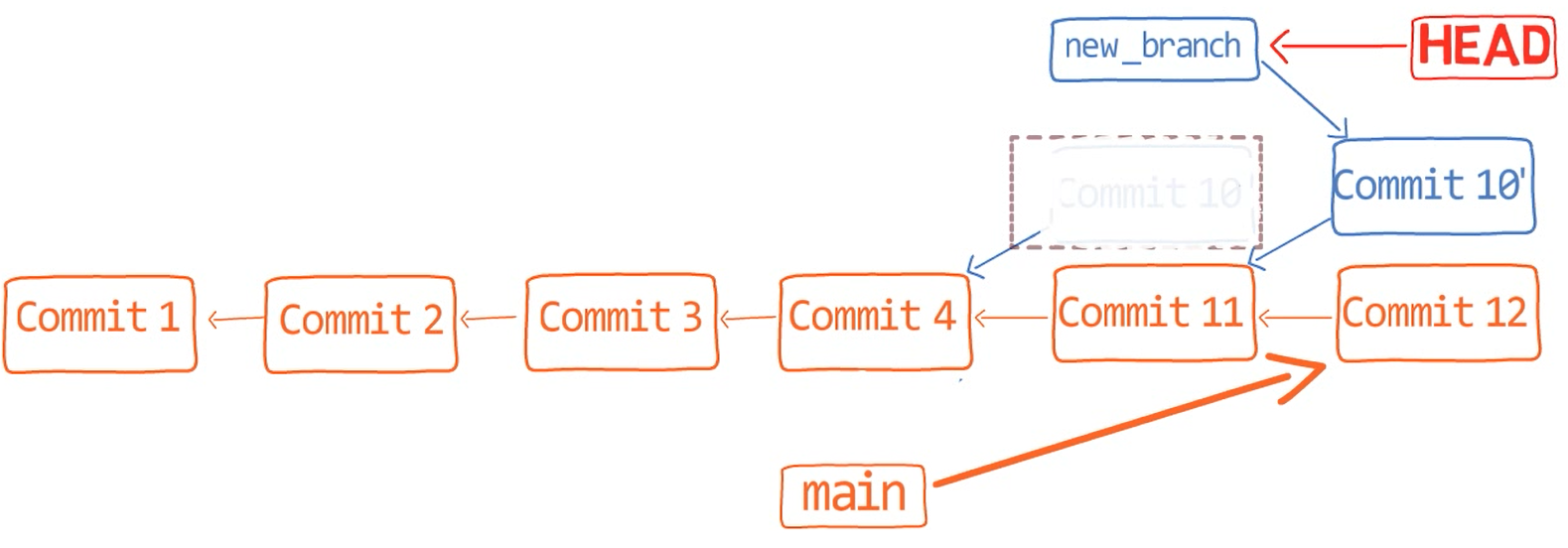 L'historique avant et après le rebase, "Commit 10" a été "poussé"
L'historique avant et après le rebase, "Commit 10" a été "poussé"
Considérons un autre cas.
Disons que j'ai commencé à travailler sur une nouvelle fonctionnalité, et par erreur j'ai commencé à travailler depuis feature_branch_1, plutôt que depuis main.
Donc pour émuler cela, créez feature_branch_1 :
git checkout main
git checkout -b feature_branch_1
Et effacez new_branch pour ne plus la voir dans le graphique :
git branch -D new_branch
Créez un fichier Python simple appelé 1.py :
 Un nouveau fichier,
Un nouveau fichier, 1.py, avec print('Hello world!')
Mettez en transit et validez ce fichier :
git add 1.py
git commit -m "Commit 13"
Maintenant branchez depuis feature_branch_1 (c'est l'erreur que vous corrigerez plus tard) :
git checkout -b feature_branch_2
Et créez un autre fichier, 2.py :
 Création de
Création de 2.py
Mettez en transit et validez ce fichier également :
git add 2.py
git commit -m "Commit 14"
Et introduisez un peu plus de code à 2.py :
 Modification de
Modification de 2.py
Mettez en transit et validez ces changements aussi :
git add 2.py
git commit -m "Commit 15"
Jusqu'ici vous devriez avoir cet historique :
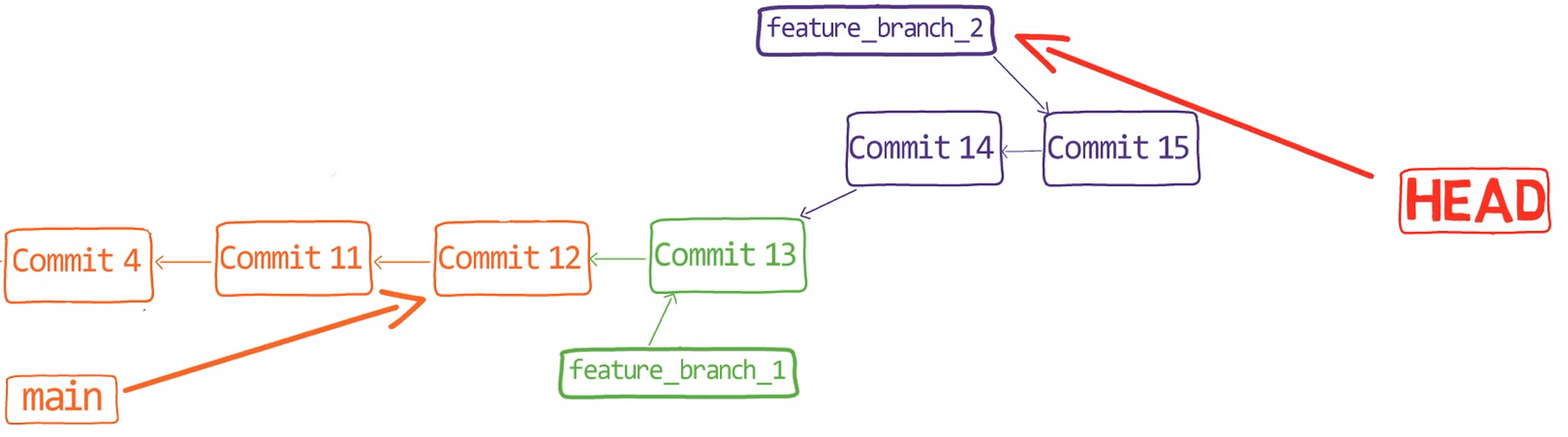 L'historique après l'introduction de "Commit 15"
L'historique après l'introduction de "Commit 15"
Revenez à feature_branch_1 et éditez 1.py :
git checkout feature_branch_1
 Modification de
Modification de 1.py
Maintenant mettez en transit et validez :
git add 1.py
git commit -m "Commit 16"
Votre historique devrait ressembler à ceci :
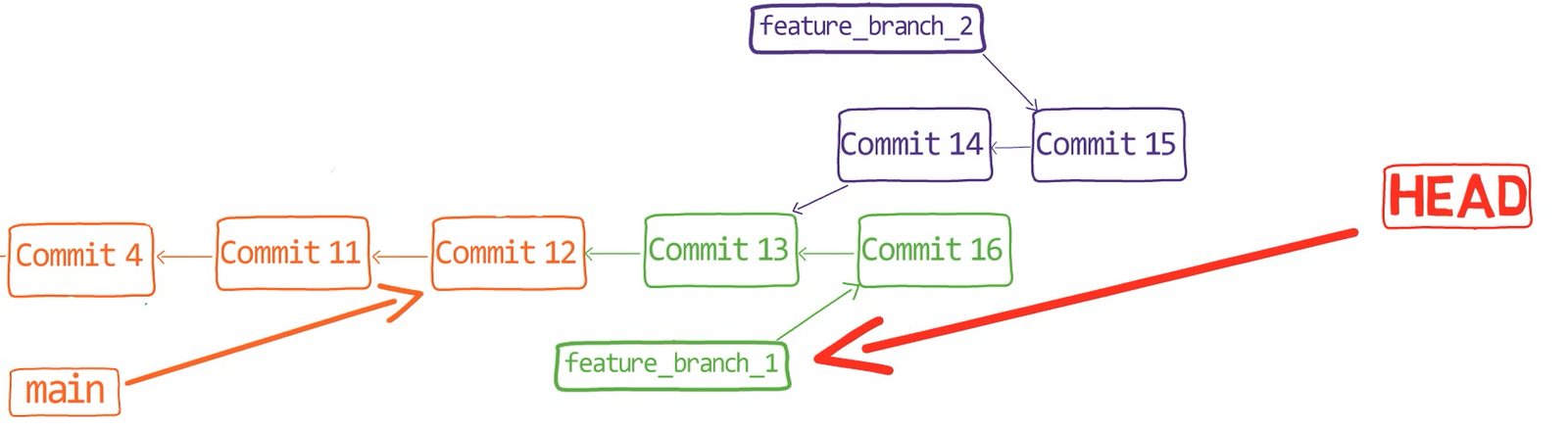 L'historique après l'introduction de "Commit 16"
L'historique après l'introduction de "Commit 16"
Disons maintenant que vous réalisez que vous avez fait une erreur. Vous vouliez en fait que feature_branch_2 naisse de la branche main, plutôt que de feature_branch_1.
Comment pouvez-vous réaliser cela ?
Essayez d'y réfléchir étant donné le graphique d'historique et ce que vous avez appris sur le drapeau --onto pour la commande rebase.
Eh bien, vous voulez "remplacer" le parent de votre premier commit sur feature_branch_2, qui est "Commit 14", pour qu'il soit au-dessus de la branche main - dans ce cas, "Commit 12" - plutôt qu'au début de feature_branch_1 - dans ce cas, "Commit 13". Donc encore une fois, vous allez créer une nouvelle base, cette fois pour le premier commit sur feature_branch_2.
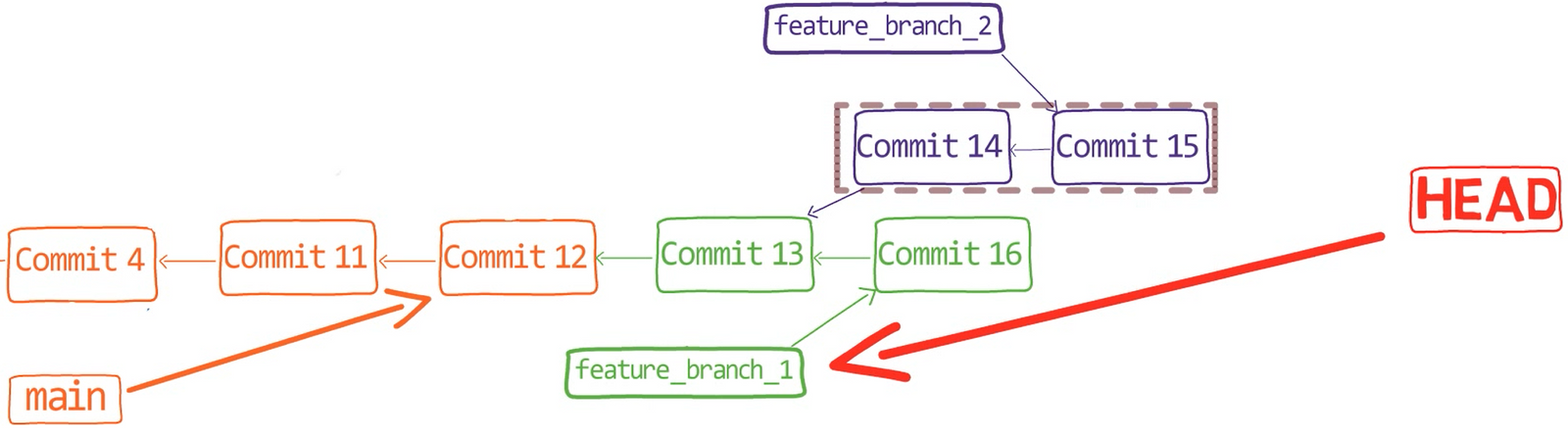 Vous voulez déplacer "Commit 14" et "Commit 15"
Vous voulez déplacer "Commit 14" et "Commit 15"
Comment feriez-vous cela ?
D'abord, passez à feature_branch_2 :
git checkout feature_branch_2
Et maintenant vous pouvez utiliser :
git rebase --onto main <SHA_OF_COMMIT_13>
Cela dit à Git de prendre l'historique avec "Commit 13" comme base, et de changer cette base pour être "Commit 12" (pointé par main) à la place.
En conséquence, vous avez feature_branch_2 basé sur main plutôt que feature_branch_1 :
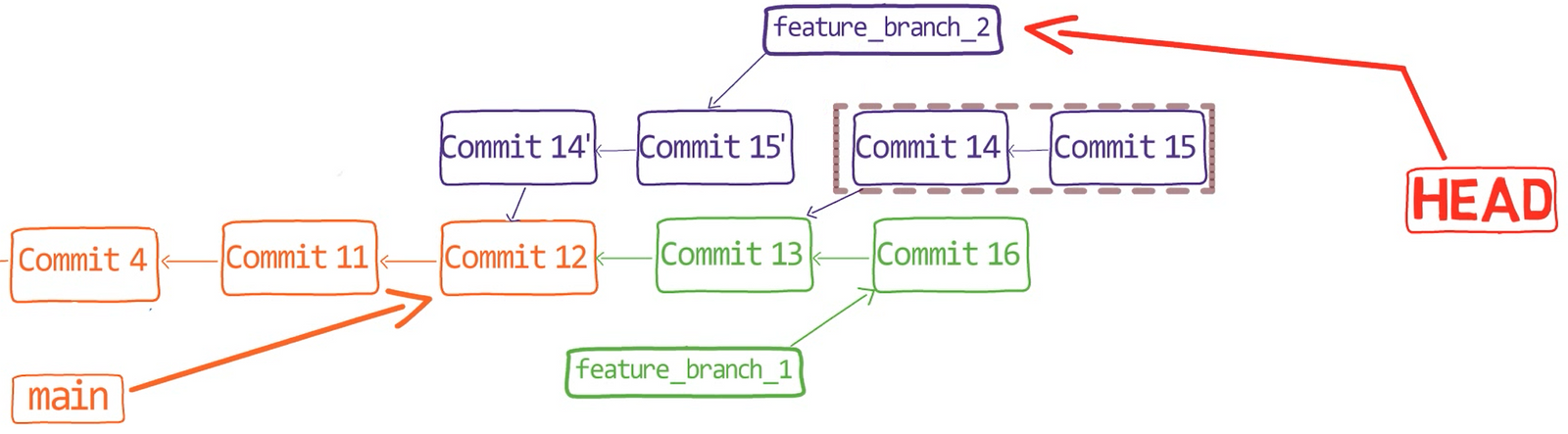 L'historique des commits après avoir effectué le rebase
L'historique des commits après avoir effectué le rebase
La syntaxe de la commande est :
git rebase --onto <new_parent> <old_parent>
Comment rebaser sur une seule branche
Vous pouvez également utiliser git rebase tout en regardant l'historique d'une seule branche.
Voyons si vous pouvez m'aider ici.
Disons que j'ai travaillé depuis feature_branch_2, et spécifiquement édité le fichier code.py. J'ai commencé par changer toutes les chaînes pour qu'elles soient entourées de guillemets doubles plutôt que de guillemets simples :
 Changement de
Changement de ' en " dans code.py
Ensuite, j'ai mis en transit et validé :
git add code.py
git commit -m "Commit 17"
J'ai ensuite décidé d'ajouter une nouvelle fonction au début du fichier :
 _Ajout de la fonction
_Ajout de la fonction another_feature_
Encore une fois, j'ai mis en transit et validé :
git add code.py
git commit -m "Commit 18"
Et maintenant j'ai réalisé que j'avais en fait oublié de changer les guillemets simples en guillemets doubles entourant __main__ (comme vous l'avez peut-être remarqué), donc j'ai fait cela aussi :
 Changement de
Changement de '__main__' en "__main__"
Bien sûr, j'ai mis en transit et validé ce changement :
git add code.py
git commit -m "Commit 19"
Maintenant, considérez l'historique :
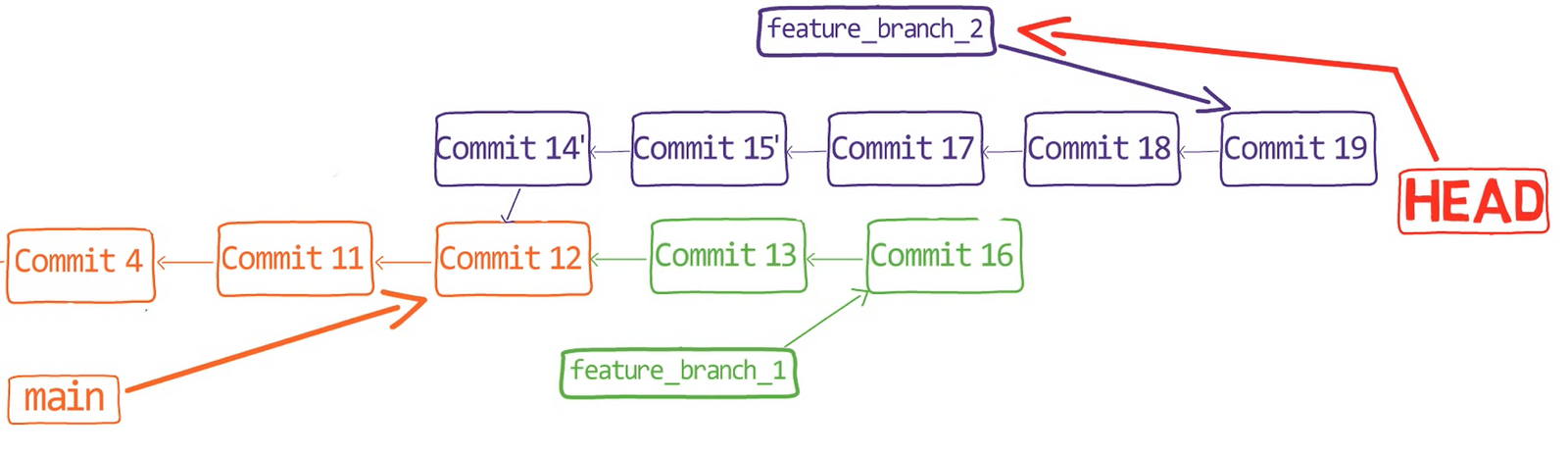 L'historique des commits après l'introduction de "Commit 19"
L'historique des commits après l'introduction de "Commit 19"
Ce n'est pas vraiment beau, n'est-ce pas ? Je veux dire, j'ai deux commits qui sont liés l'un à l'autre, "Commit 17" et "Commit 19" (transformant les ' en "), mais ils sont séparés par le "Commit 18" non lié (où j'ai ajouté une nouvelle fonction). Que pouvons-nous faire ? Pouvez-vous m'aider ?
Intuitivement, je veux éditer l'historique ici :
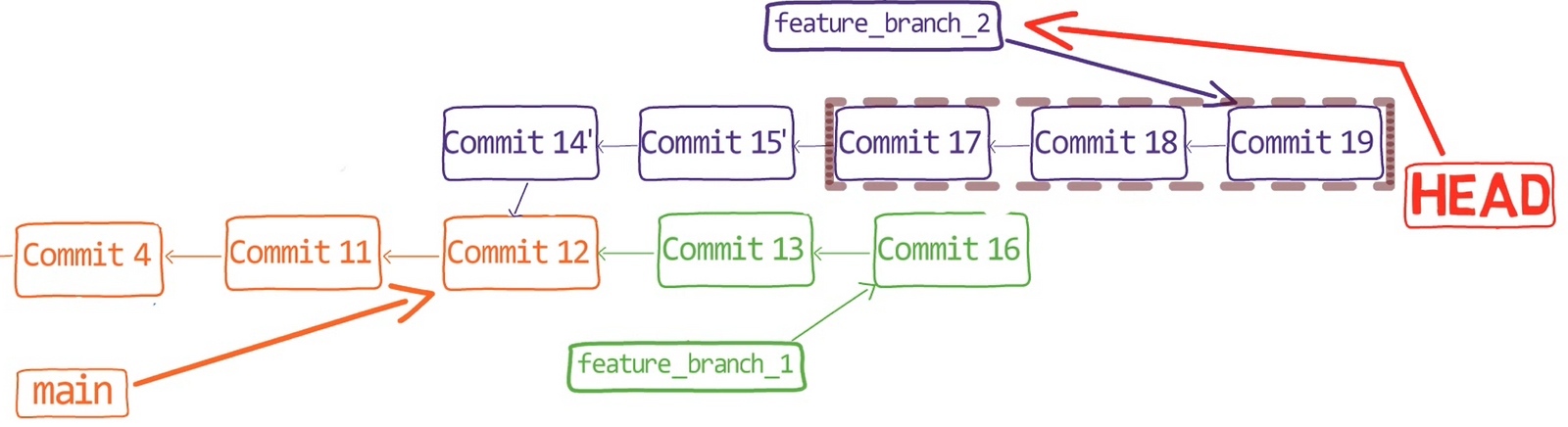 Ce sont les commits que je veux éditer
Ce sont les commits que je veux éditer
Alors, que feriez-vous ?
Vous avez raison !
Je peux rebase (rebaser) l'historique de "Commit 17" à "Commit 19", au-dessus de "Commit 15". Pour faire cela :
git rebase --interactive --onto <SHA_OF_COMMIT_15> <SHA_OF_COMMIT_15>
Remarquez que j'ai spécifié "Commit 15" comme le début de la plage de commits, excluant ce commit. Et je n'ai pas eu besoin de spécifier explicitement HEAD comme dernier paramètre.
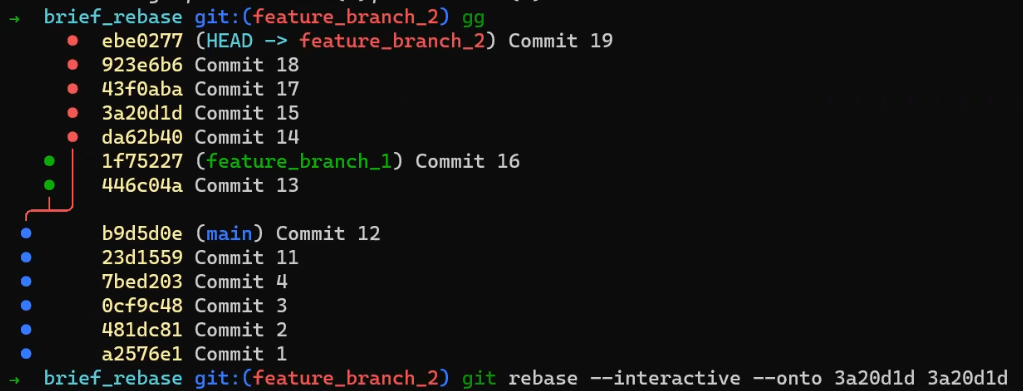 Utilisation de
Utilisation de rebase --onto sur une seule branche
(Note : Si vous suivez les étapes ci-dessus avec mon dépôt et obtenez un conflit de fusion, vous avez peut-être une configuration différente de celle de ma machine en ce qui concerne les caractères d'espacement aux fins de ligne. Dans ce cas, vous pouvez ajouter l'option --ignore-whitespace à la commande rebase, ce qui donne la commande suivante : git rebase --ignore-whitespace --interactive --onto <SHA_OF_COMMIT_15> <SHA_OF_COMMIT_15>. Si vous êtes curieux d'en savoir plus sur ce problème, recherchez autocrlf.)
Après avoir suivi vos conseils et exécuté la commande rebase (merci ! 😇), j'obtiens l'écran suivant :
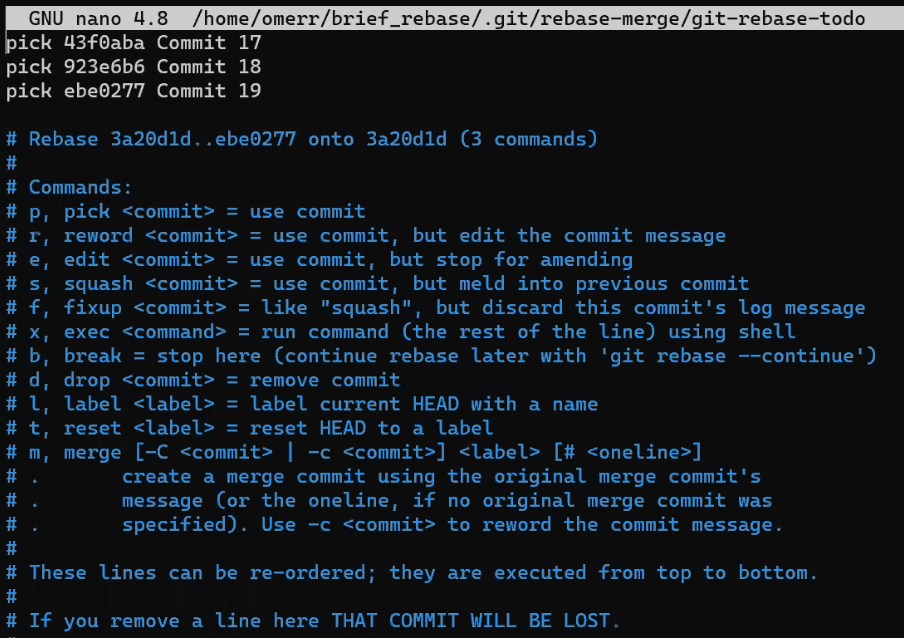 Rebase interactif
Rebase interactif
Alors, que ferais-je ? Je veux mettre "Commit 19" avant "Commit 18", pour qu'il vienne juste après "Commit 17". Je peux aller plus loin et les squash (écraser) ensemble, comme ceci :
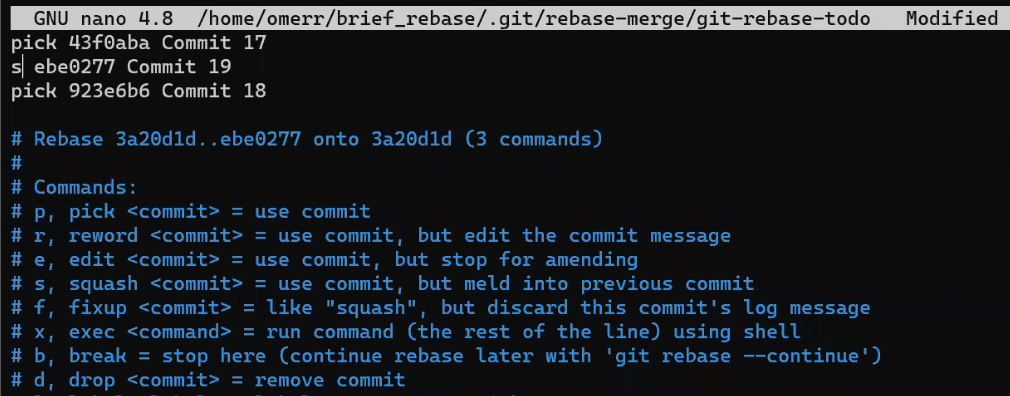 Rebase interactif - changer l'ordre des commits et squasher
Rebase interactif - changer l'ordre des commits et squasher
Maintenant, quand je suis invité à fournir un message de commit, je peux fournir le message "Commit 17+19" :
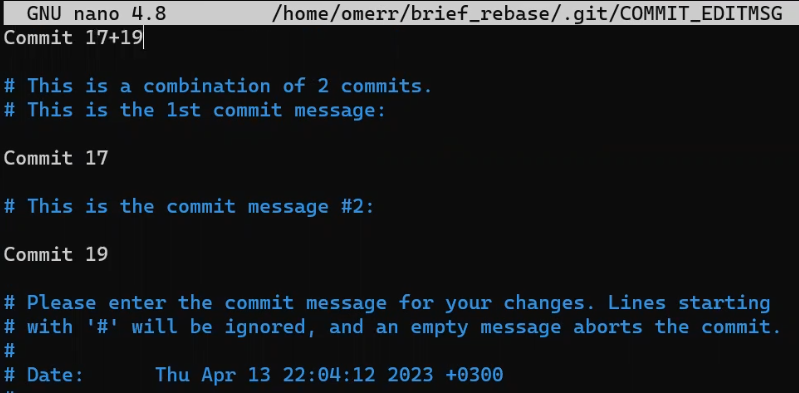 Fournir un message de commit
Fournir un message de commit
Et maintenant, voyez notre bel historique :
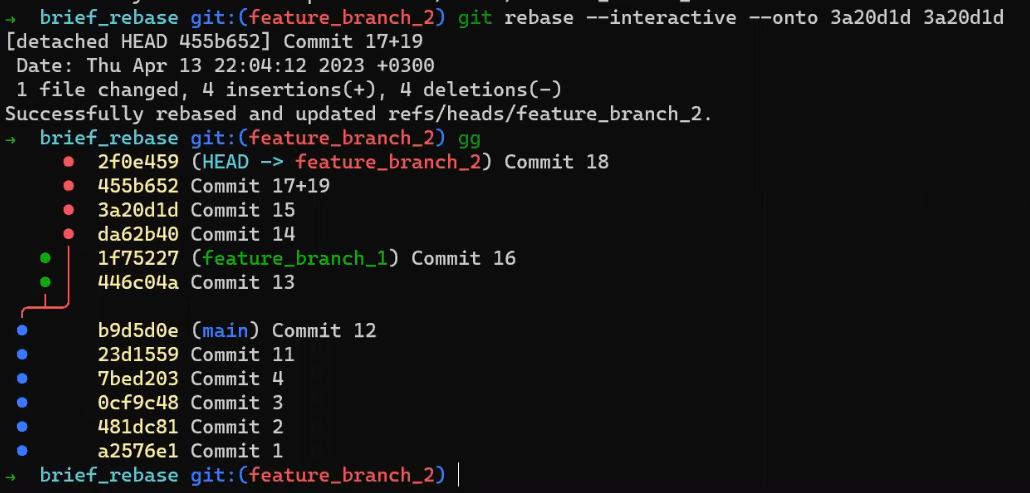 L'historique résultant
L'historique résultant
Merci encore !
Plus de cas d'utilisation de Rebase + Plus de pratique
À présent, j'espère que vous vous sentez à l'aise avec la syntaxe de rebase. La meilleure façon de vraiment le comprendre est de considérer divers cas et de trouver comment les résoudre vous-même.
Avec les cas d'utilisation à venir, je vous suggère fortement d'arrêter de lire après que j'ai introduit chaque cas d'utilisation, puis d'essayer de le résoudre par vous-même.
Comment exclure des commits
Disons que vous avez cet historique sur un autre repo :
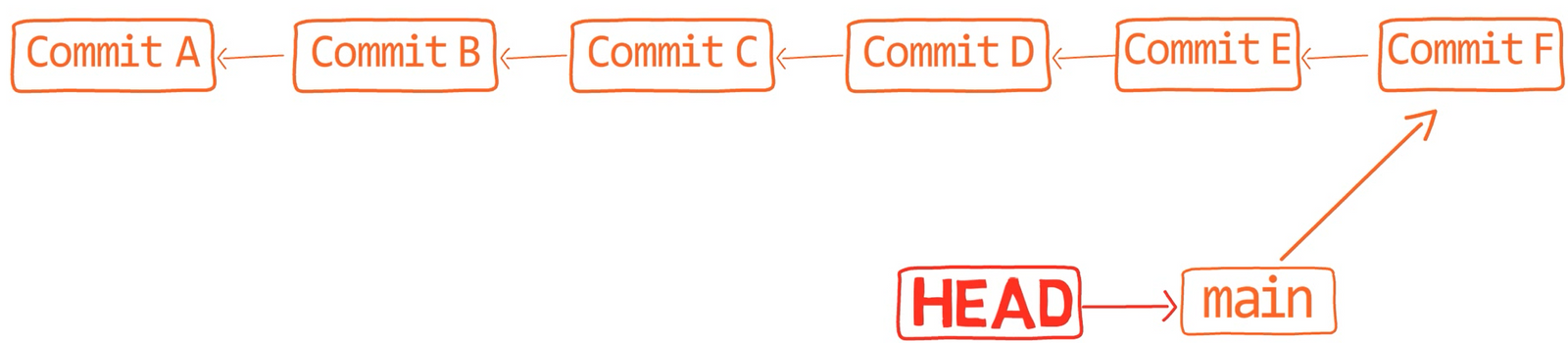 Un autre historique de commit
Un autre historique de commit
Avant de jouer avec, stockez un tag vers "Commit F" pour pouvoir y revenir plus tard :
git tag original_commit_f
(Un tag est une référence nommée à un commit, tout comme une branche - mais il ne change pas lorsque vous ajoutez des commits supplémentaires. C'est comme une référence nommée constante.)
Maintenant, vous ne voulez en fait pas que les changements dans "Commit C" et "Commit D" soient inclus. Vous pourriez utiliser un rebase interactif comme avant et supprimer leurs changements. Ou, vous pourriez utiliser git rebase --onto à nouveau. Comment utiliseriez-vous --onto afin de "supprimer" ces deux commits ?
Vous pouvez rebaser HEAD au-dessus de "Commit B", où l'ancien parent était en fait "Commit D", et maintenant cela devrait être "Commit B". Considérez à nouveau l'historique :
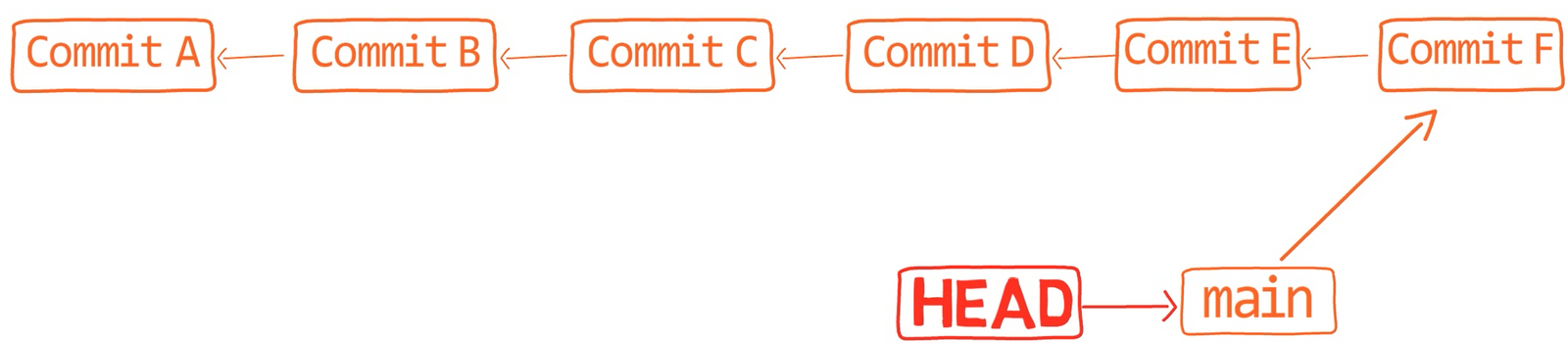 L'historique à nouveau
L'historique à nouveau
Rebaser pour que "Commit B" soit la base de "Commit E" signifie "déplacer" à la fois "Commit E" et "Commit F", et leur donner une autre base - "Commit B". Pouvez-vous trouver la commande vous-même ?
git rebase --onto <SHA_OF_COMMIT_B> <SHA_OF_COMMIT_D> HEAD
Remarquez que l'utilisation de la syntaxe ci-dessus (exactement telle que fournie) ne déplacerait pas main pour pointer vers le nouveau commit, donc le résultat est un HEAD "détaché". Si vous utilisez gg ou un autre outil qui affiche l'historique accessible depuis les branches, cela pourrait vous dérouter :
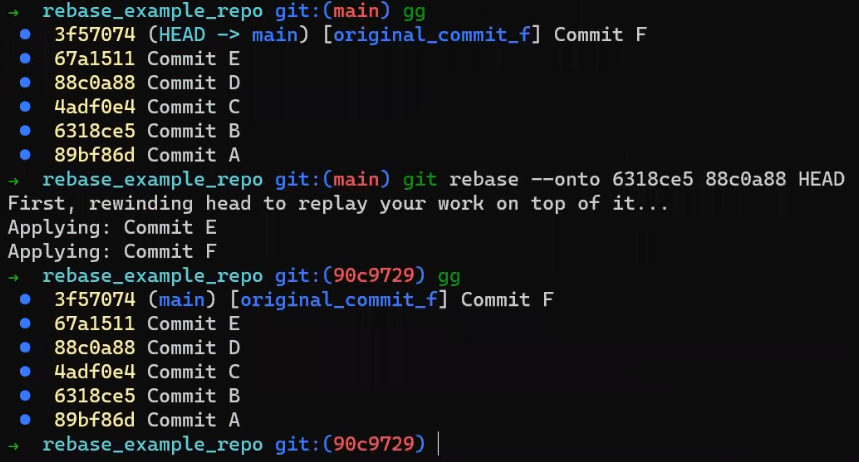 Rebaser avec
Rebaser avec --onto résulte en un HEAD détaché
Mais si vous utilisez simplement git log (ou mon alias git lol), vous verrez l'historique désiré :
 L'historique résultant
L'historique résultant
Je ne sais pas pour vous, mais ce genre de choses me rend vraiment heureux. 😊😇
Au fait, vous pourriez omettre HEAD de la commande précédente car c'est la valeur par défaut pour le troisième paramètre. Donc juste utiliser :
git rebase --onto <SHA_OF_COMMIT_B> <SHA_OF_COMMIT_D>
Aurait le même effet. Le dernier paramètre dit en fait à Git où se trouve la fin de la séquence actuelle de commits à rebaser. Donc la syntaxe de git rebase --onto avec trois arguments est :
git rebase --onto <new_parent> <old_parent> <until>
Comment déplacer des commits entre branches
Disons donc que nous revenons au même historique qu'avant :
git checkout original_commit_f
Et maintenant je veux seulement que "Commit E" soit sur une branche basée sur "Commit B". C'est-à-dire que je veux avoir une nouvelle branche, branchée depuis "Commit B", avec seulement "Commit E".
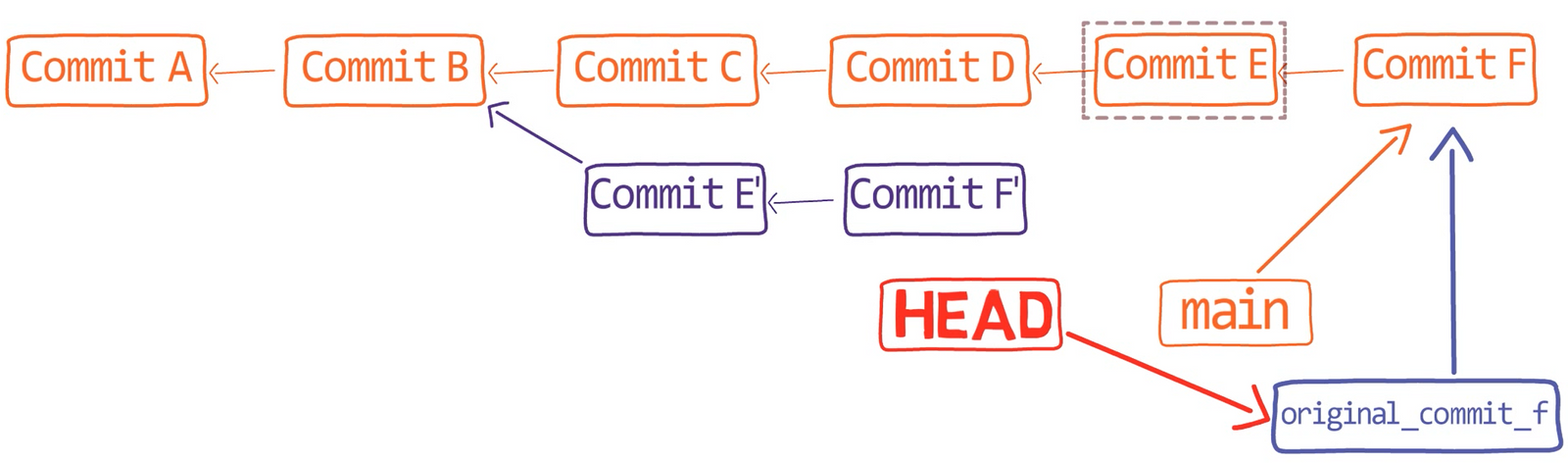 L'historique actuel, en considérant "Commit E"
L'historique actuel, en considérant "Commit E"
Alors, qu'est-ce que cela signifie en termes de rebase ? Considérez l'image ci-dessus. Quel commit (ou commits) dois-je rebaser, et quel commit serait la nouvelle base ?
Je sais que je peux compter sur vous ici 😉
Ce que je veux, c'est prendre "Commit E", et ce commit seulement, et changer sa base pour être "Commit B". En d'autres termes, rejouer les changements introduits dans "Commit E" sur "Commit B".
Pouvez-vous appliquer cette logique à la syntaxe de git rebase ?
La voici (cette fois j'écris <COMMIT_X> au lieu de <SHA_OF_COMMIT_X>, par souci de brièveté) :
git rebase --onto <COMMIT_B> <COMMIT_D> <COMMIT_E>
Maintenant l'historique ressemble à ceci :
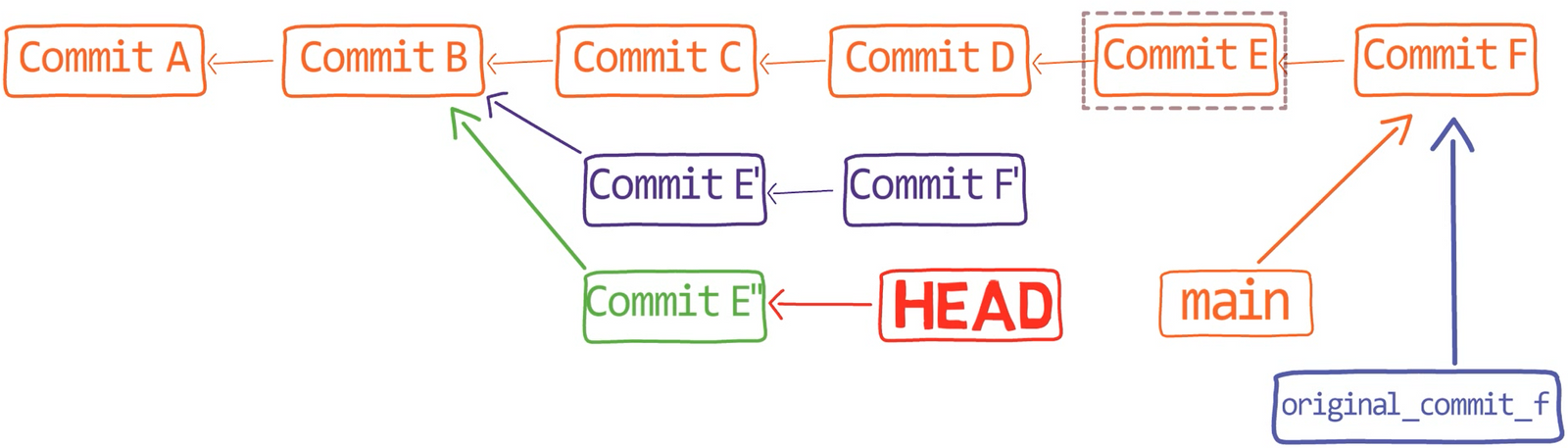 L'historique après rebase
L'historique après rebase
Remarquez que rebase a déplacé HEAD, mais aucune autre référence nommée (telle qu'une branche ou un tag). En d'autres termes, vous êtes dans un état HEAD détaché. Donc ici aussi, utiliser gg ou un autre outil qui affiche l'historique accessible depuis les branches et les tags pourrait vous dérouter. Vous pouvez utiliser git log (ou mon alias git lol) pour afficher l'historique accessible depuis HEAD.
Génial !
Une note sur les conflits
Notez que lors de l'exécution d'un rebase, vous pouvez rencontrer des conflits tout comme lors d'une fusion. Vous pouvez avoir des conflits parce que, lors du rebasage, vous essayez d'appliquer des patches sur une base différente, peut-être là où les patches ne s'appliquent pas.
Par exemple, considérez à nouveau le dépôt précédent, et spécifiquement, considérez le changement introduit dans "Commit 12", pointé par main :
git show main
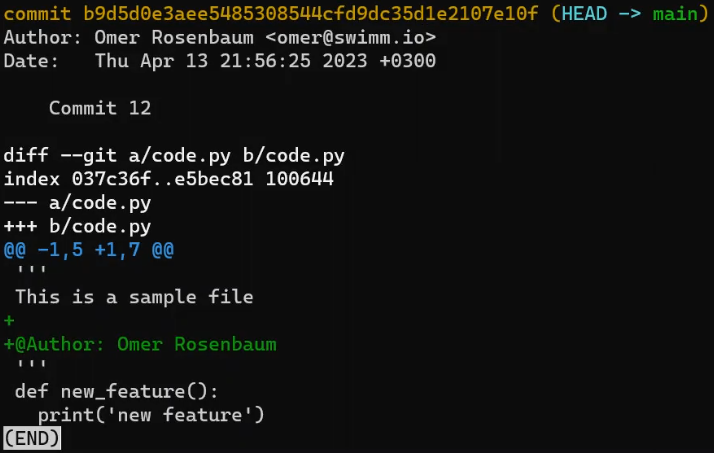 Le patch introduit dans "Commit 12"
Le patch introduit dans "Commit 12"
J'ai déjà couvert le format de git diff en détail au chapitre 6, mais pour rappel rapide, ce commit demande à Git d'ajouter une ligne après les deux lignes de contexte :
This is a sample file
Et avant ces trois lignes de contexte :
```patch
def new_feature(): print('new feature')
Disons que vous essayez de rebaser "Commit 12" sur un autre commit. Si, pour une raison quelconque, ces lignes de contexte n'existent pas comme elles le font dans le patch sur le commit sur lequel vous rebasez, alors vous aurez un conflit.
### Prendre du recul pour une vue d'ensemble
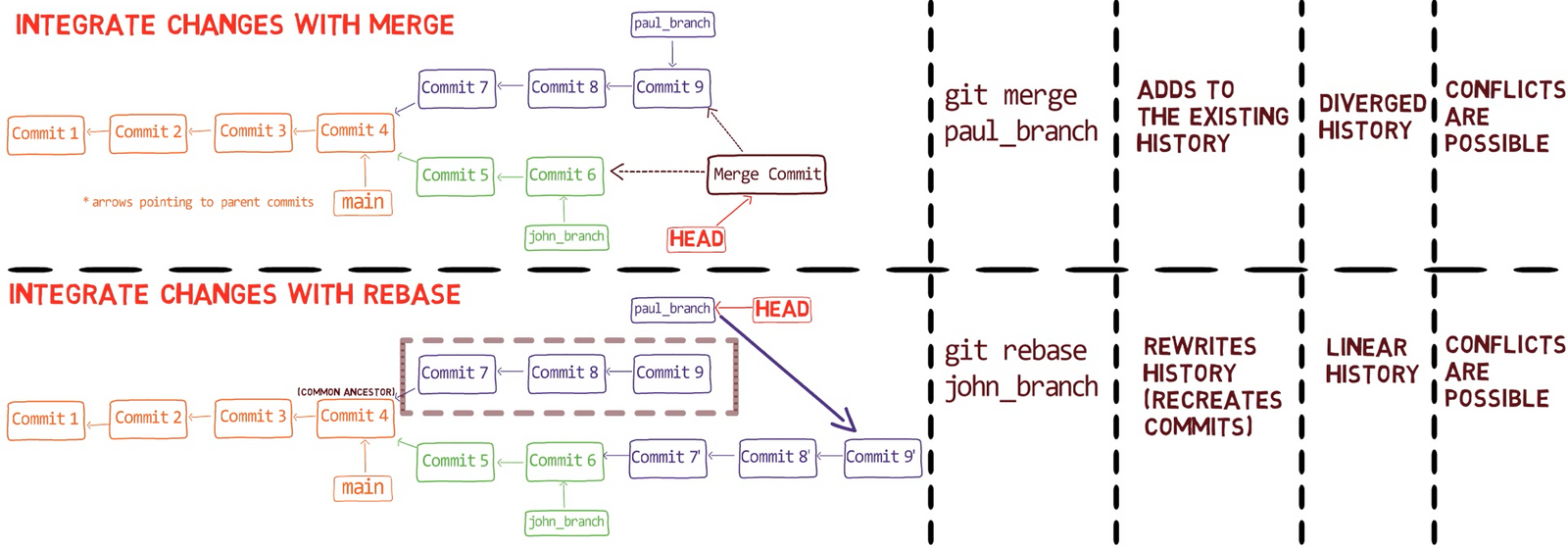
_Comparaison entre rebase et merge_
Au début de ce chapitre, j'ai commencé par mentionner la similitude entre `git merge` et `git rebase` : les deux sont utilisés pour intégrer des changements introduits dans différents historiques.
Mais, comme vous le savez maintenant, ils sont très différents dans leur fonctionnement. Alors que la fusion résulte en un historique _divergent_, le rebasage résulte en un historique _linéaire_. Les conflits sont possibles dans les deux cas. Et il y a une colonne de plus décrite dans le tableau ci-dessus qui nécessite une attention particulière.
Maintenant que vous savez ce qu'est "Git rebase", et comment utiliser le rebase interactif ou rebase `--onto`, comme j'espère que vous en conviendrez, `git rebase` est un outil super puissant. Pourtant, il a un énorme inconvénient comparé à la fusion.
**Git rebase change l'historique.**
Cela signifie que vous ne devriez **pas** rebaser des commits qui existent en dehors de votre copie locale du dépôt, et sur lesquels d'autres personnes pourraient avoir basé leurs commits.
En d'autres termes, si les seuls commits en question sont ceux que vous avez créés localement - allez-y, utilisez rebase, faites-vous plaisir.
Mais si les commits ont été poussés (pushed), cela peut mener à un énorme problème - car quelqu'un d'autre peut compter sur ces commits que vous écrasez plus tard, et alors vous et eux aurez des versions différentes du dépôt.
C'est différent de `merge` qui, comme nous l'avons vu, ne modifie pas l'historique.
Par exemple, considérez le dernier cas où nous avons rebasé et abouti à cet historique :
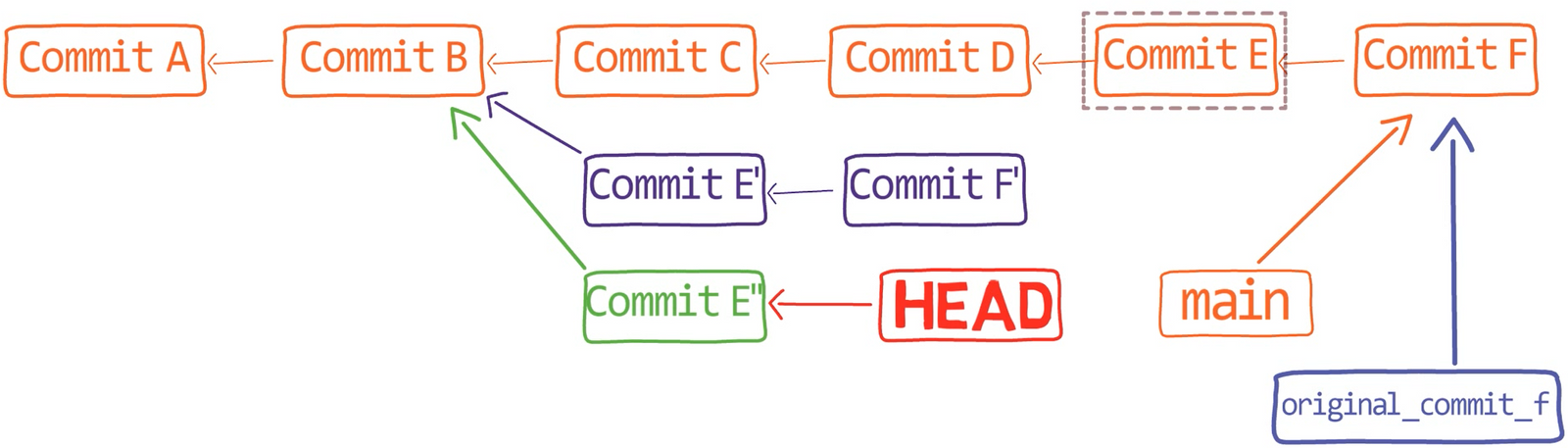
_L'historique après rebase_
Maintenant, supposons que j'ai déjà poussé cette branche vers le dépôt distant. Et après que j'ai poussé la branche, un autre développeur l'a tirée (pulled) et a branché à partir de "Commit C". L'autre développeur ne savait pas que pendant ce temps, je rebasais localement ma branche, et que je la pousserais plus tard à nouveau.
Cela résulte en une incohérence : l'autre développeur travaille à partir d'un commit qui n'est plus disponible sur ma copie du dépôt.
Je ne m'étendrai pas sur ce que cela provoque exactement dans ce livre, car mon message principal est que vous devriez absolument éviter de tels cas. Si vous êtes intéressé par ce qui se passerait réellement, je laisserai un lien vers une ressource utile dans les [références supplémentaires](#heading-references-supplementaires-par-partie). Pour l'instant, résumons ce que nous avons couvert.
### Récapitulatif - Comprendre Git Rebase
Dans ce chapitre, vous avez appris ce qu'est `git rebase`, un outil super-puissant pour réécrire l'historique dans Git. Vous avez considéré quelques cas d'utilisation où git rebase peut être utile, et comment l'utiliser avec un, deux ou trois paramètres, avec et sans l'option `--onto`.
J'espère avoir pu vous convaincre que `git rebase` est puissant - mais aussi qu'il est assez simple une fois que vous avez saisi l'essentiel. C'est un outil que vous pouvez utiliser pour "copier-coller" des commits (ou, plus précisément, des patches). Et c'est un outil utile à avoir dans votre manche. En essence, `git rebase` prend les patches introduits par des commits, et les rejoue sur un autre commit. Comme décrit dans ce chapitre, cela est utile dans de nombreux scénarios différents.
## Partie 2 - Résumé
Dans cette partie, vous avez appris à brancher et à intégrer des changements dans Git.
Vous avez appris ce qu'est un **diff**, et la différence entre un diff et un **patch**. Vous avez également appris comment la sortie de `git diff` est construite.
Comprendre les diffs est une étape majeure pour comprendre de nombreux autres processus au sein de Git tels que la fusion ou le rebasage.
Ensuite, vous avez eu un aperçu complet de la fusion avec Git. Vous avez appris que la **fusion** est le processus consistant à **combiner les changements récents de plusieurs branches en un seul nouveau commit**. Le nouveau commit a plusieurs parents - ces commits qui avaient été les pointes des branches qui ont été fusionnées. Dans la plupart des cas, la fusion combine les changements de deux branches, et le commit de fusion résultant a alors deux parents - un de chaque branche.
Nous avons considéré une fusion simple, en avance rapide, qui est possible lorsqu'une branche a divergé de la branche de base, et a ensuite juste ajouté des commits par-dessus la branche de base.
Nous avons ensuite considéré les fusions à trois voies, et expliqué le processus en trois étapes :
* Premièrement, Git localise la base de fusion. Pour rappel, c'est le premier commit qui est accessible depuis les deux branches.
* Deuxièmement, Git calcule deux diffs - un diff de la base de fusion à la _première_ branche, et un autre diff de la base de fusion à la _seconde_ branche. Git génère des patches basés sur ces diffs.
* Troisièmement et dernièrement, Git applique les deux patches à la base de fusion, en utilisant un algorithme de fusion à 3 voies. Le résultat est l'état du nouveau commit de fusion.
Vous avez vu la sortie de `git diff` quand nous sommes dans un état conflictuel, et comment résoudre les conflits soit manuellement soit avec VS Code.
Finalement, vous avez découvert Git rebase. Vous avez vu que `git rebase` est puissant - mais aussi qu'il est assez simple une fois que vous comprenez ce qu'il fait. C'est un outil pour "copier-coller" des commits (ou, plus précisément, des patches).
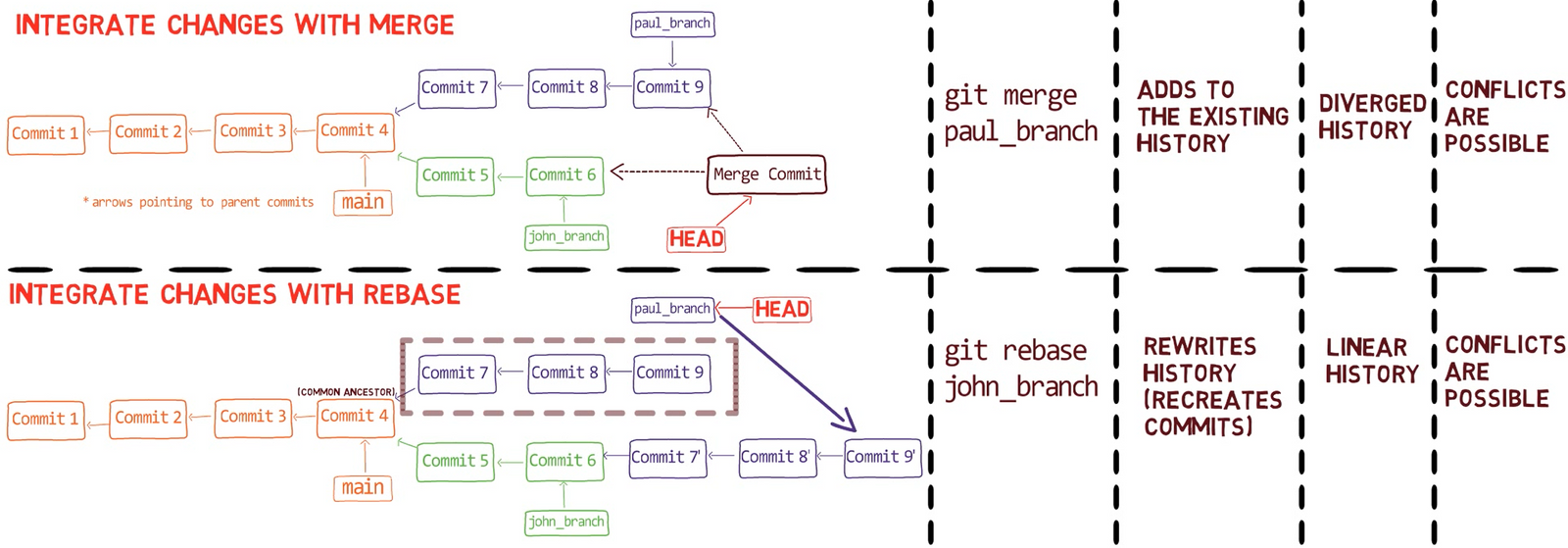
_Comparaison entre rebase et merge_
`git merge` et `git rebase` sont tous deux utilisés pour intégrer des changements introduits dans différents historiques.
Pourtant, ils diffèrent dans leur fonctionnement. Alors que la fusion résulte en un historique _divergent_, le rebasage résulte en un historique _linéaire_. `git rebase` _change_ l'historique, tandis que `git merge` ajoute à l'historique existant.
Avec cette compréhension approfondie des diffs, des patches, de la fusion et du rebasage, vous devriez vous sentir confiant pour introduire des changements dans un dépôt git.
La prochaine partie se concentrera sur ce qui se passe quand les choses tournent mal - comment vous pouvez changer l'historique (avec ou sans `git rebase`), ou trouver des commits "perdus".
# Partie 3 - Annuler des changements
Êtes-vous déjà arrivé à un point où vous avez dit : "Ouh là, qu'est-ce que je viens de faire ?" Je suppose que oui, tout comme à peu près tous ceux qui utilisent Git.
Peut-être avez-vous validé (commit) sur la mauvaise branche. Peut-être avez-vous perdu du code que vous aviez écrit. Peut-être avez-vous validé quelque chose que vous ne vouliez pas.
Cette partie vous donnera les outils pour réécrire l'historique avec confiance, "annulant" ainsi toutes sortes de changements dans Git.
Tout comme les autres parties du livre, cette partie sera pratique mais approfondie - donc au lieu de vous fournir une liste de choses à faire quand les choses tournent mal, nous comprendrons les mécanismes sous-jacents, afin que vous vous sentiez confiant chaque fois que vous arrivez au moment "ouh là". En fait, vous trouverez ces moments comme des opportunités pour un défi intéressant, plutôt qu'un scénario redoutable.
## Chapitre 9 - Git Reset
Notre voyage commence avec une commande puissante qui peut être utilisée pour annuler de nombreuses actions différentes avec Git - `git reset`.
### Un court rappel - Enregistrer des changements
Au [chapitre 3](#heading-chapitre-3-comment-enregistrer-des-changements-dans-git), vous avez appris comment enregistrer des changements dans Git. Si vous vous souvenez de tout de cette partie, n'hésitez pas à passer à la section suivante.
Il est très utile de penser à Git comme un système pour enregistrer des instantanés d'un système de fichiers dans le temps. Considérant un dépôt Git, il a trois "états" ou "arbres" :
1. Le **répertoire de travail**, un répertoire auquel un dépôt est associé.
2. La **zone de transit (index)** qui contient l'arbre pour le prochain commit.
3. Le **dépôt**, qui est une collection de commits et de références.

_Les trois "arbres" d'un dépôt Git_
Note concernant les conventions de dessin que j'utilise : J'inclus `.git` dans le répertoire de travail, pour vous rappeler qu'il s'agit d'un dossier dans le dossier du projet sur le système de fichiers. Le dossier `.git` contient en fait les objets et les références du dépôt, comme expliqué au [chapitre 4](#heading-chapitre-4-comment-creer-un-repo-en-partant-de-zero).
#### Démonstration pratique
Utilisez `git init` pour initialiser un nouveau dépôt. Écrivez du texte dans un fichier appelé `1.txt` :
```bash
mkdir my_repo
cd my_repo
git init
echo Hello world > 1.txt
Parmi les trois états d'arbres décrits ci-dessus, où est 1.txt maintenant ?
Dans l'arbre de travail, car il n'a pas encore été introduit dans l'index.
 Le fichier
Le fichier 1.txt fait maintenant partie du répertoire de travail uniquement
Afin de le mettre en transit (stage), de l'ajouter à l'index, utilisez :
git add 1.txt
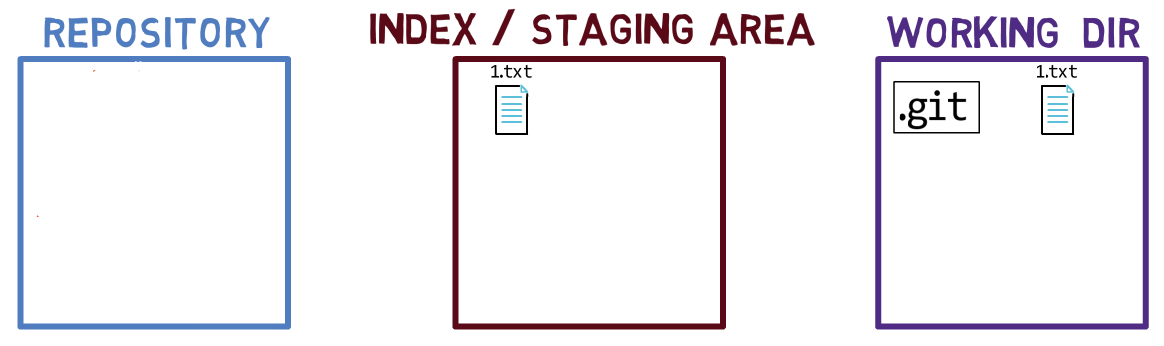 Utiliser
Utiliser git add met en transit le fichier donc il est maintenant aussi dans l'index
Remarquez qu'une fois que vous mettez en transit 1.txt, Git crée un objet blob avec le contenu de ce fichier, et l'ajoute à la base de données d'objets interne (dans le dossier .git), comme couvert dans le chapitre 3 et le chapitre 4. Je ne le dessine pas comme faisant partie du "dépôt" car dans cette représentation, le "dépôt" fait référence à un arbre de commits et à leurs références, et ce blob n'a fait partie d'aucun commit.
Maintenant, utilisez git commit pour valider vos changements dans le dépôt :
git commit -m "Commit 1"
 Utiliser
Utiliser git commit crée un objet commit dans le dépôt
Vous avez créé un nouvel objet commit, qui inclut un pointeur vers un arbre décrivant l'ensemble de l'arbre de travail. Dans ce cas, cet arbre consiste uniquement en 1.txt dans le dossier racine. En plus d'un pointeur vers l'arbre, l'objet commit inclut des métadonnées, telles que des horodatages et des informations sur l'auteur.
En considérant les diagrammes, remarquez que nous n'avons qu'une seule copie du fichier 1.txt sur le disque, et un objet blob correspondant dans la base de données d'objets de Git. L'arbre "dépôt" montre maintenant ce fichier comme faisant partie du commit actif - c'est-à-dire que l'objet commit "Commit 1" pointe vers un arbre qui pointe vers le blob avec le contenu de 1.txt, le même blob vers lequel l'index pointe.
Pour plus d'informations sur les objets dans Git (tels que les commits et les arbres), référez-vous au chapitre 1.
Ensuite, créez un nouveau fichier, et ajoutez-le à l'index, comme avant :
echo second file > 2.txt
git add 2.txt
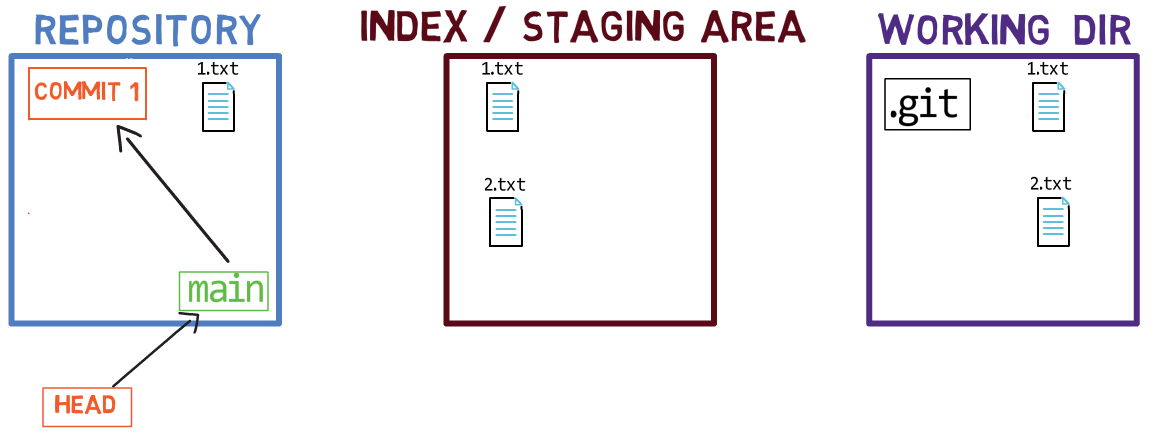 Le fichier
Le fichier 2.txt est dans le répertoire de travail et l'index après l'avoir mis en transit avec git add
Ensuite, validez :
git commit -m "Commit 2"
Il est important de noter que git commit fait deux choses :
Premièrement, il crée un objet commit, donc il y a un objet dans la base de données d'objets interne de Git avec une valeur SHA-1 correspondante. Ce nouvel objet commit pointe également vers le commit parent. C'est le commit vers lequel HEAD pointait lorsque vous avez écrit la commande git commit.
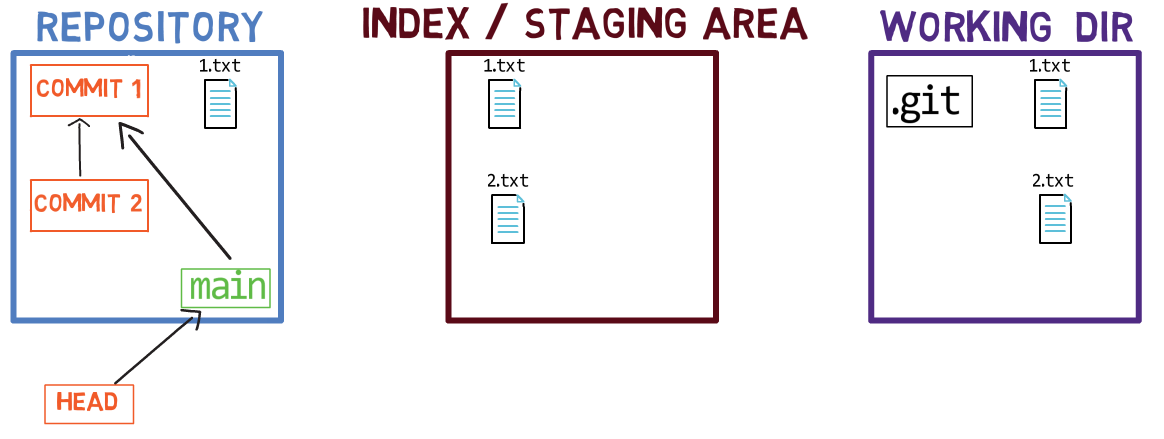 Un nouvel objet commit a été créé, au début —
Un nouvel objet commit a été créé, au début — main pointe toujours vers le commit précédent
Deuxièmement, git commit déplace le pointeur de la branche active — dans notre cas, ce serait main, pour pointer vers l'objet commit nouvellement créé.
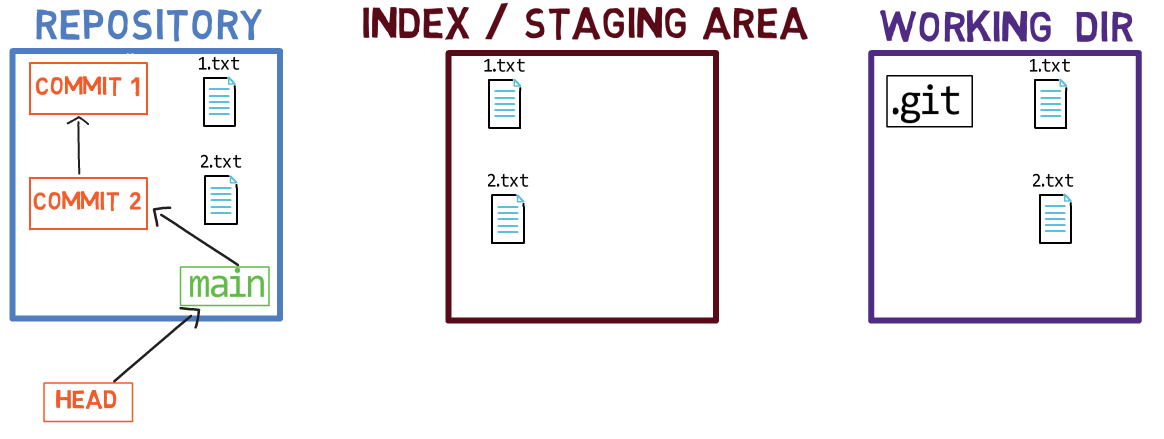
git commit met aussi à jour la branche active pour pointer vers l'objet commit nouvellement créé
Introduction à git reset
Vous allez maintenant apprendre comment inverser le processus d'introduction d'un commit. Pour cela, vous allez découvrir la commande git reset.
git reset --soft
La toute dernière étape que vous avez faite avant était de git commit, ce qui signifie en fait deux choses — Git a créé un objet commit et a déplacé main, la branche active. Pour annuler cette étape, utilisez la commande suivante :
git reset --soft HEAD~1
La syntaxe HEAD~1 fait référence au premier parent de HEAD. Considérez un cas où j'avais plus d'un commit dans le graphe de commit, disons "Commit 3" pointant vers "Commit 2", qui pointe à son tour vers "Commit 1". Et considérez que HEAD pointait vers "Commit 3". Vous pourriez utiliser HEAD~1 pour faire référence à "Commit 2", et HEAD~2 ferait référence à "Commit 1".
Donc, revenons à la commande : git reset --soft HEAD~1
Cette commande demande à Git de changer ce vers quoi HEAD pointe. (Note : Dans les diagrammes ci-dessous, j'utilise *HEAD pour "ce vers quoi HEAD pointe"). Dans notre exemple, HEAD pointe vers main. Donc Git changera seulement le pointeur de main pour pointer vers HEAD~1. C'est-à-dire que main pointera vers "Commit 1".
Cependant, cette commande n'a pas affecté l'état de l'index ou de l'arbre de travail. Donc si vous utilisez git status vous verrez que 2.txt est mis en transit, tout comme avant que vous exécutiez git commit :
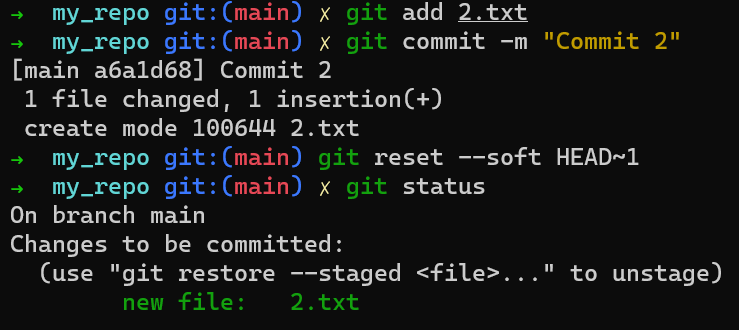
git status montre que 2.txt est dans l'index, mais pas dans le commit actif
L'état est maintenant :
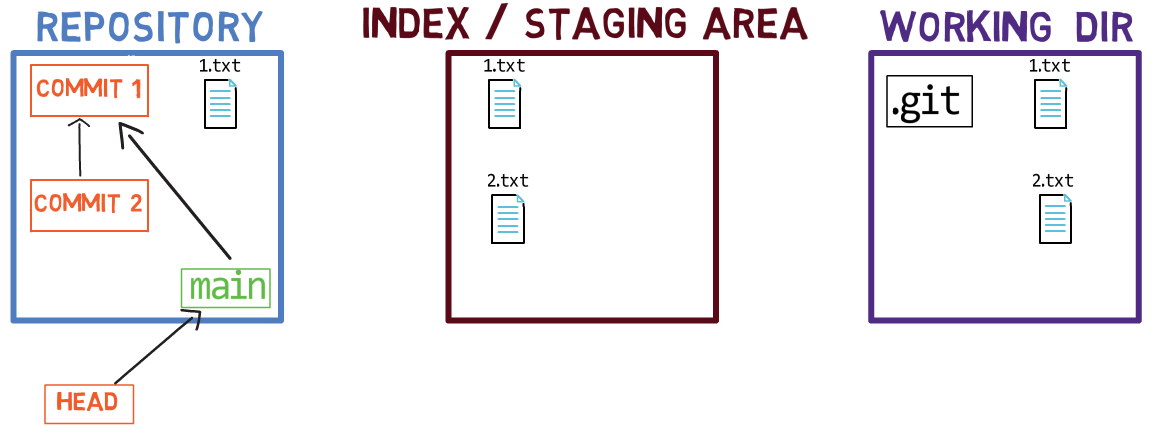 Réinitialisation de
Réinitialisation de main à "Commit 1"
(Note : J'ai retiré 2.txt du "dépôt" dans le diagramme car il ne fait pas partie du commit actif - c'est-à-dire que l'arbre pointé par "Commit 1" ne référence pas ce fichier. Cependant, il n'a pas été retiré du système de fichiers - car il existe toujours dans l'arbre de travail et l'index.)
Qu'en est-il de git log ? Il partira de HEAD, ira à main, et ensuite à "Commit 1" :
 La sortie de
La sortie de git log
Remarquez que cela signifie que "Commit 2" n'est plus accessible depuis notre historique.
Cela signifie-t-il que l'objet commit de "Commit 2" est supprimé ?
Non, il n'est pas supprimé. Il réside toujours dans la base de données interne d'objets de Git.
Si vous poussez l'historique actuel maintenant, en utilisant git push, Git ne poussera pas "Commit 2" vers le serveur distant (car il n'est pas accessible depuis le HEAD actuel), mais l'objet commit existe toujours sur votre copie locale du dépôt.
Maintenant, validez à nouveau - et utilisez le message de commit de "Commit 2.1" pour différencier ce nouvel objet du "Commit 2" original :
git commit -m "Commit 2.1"
Voici l'état résultant :
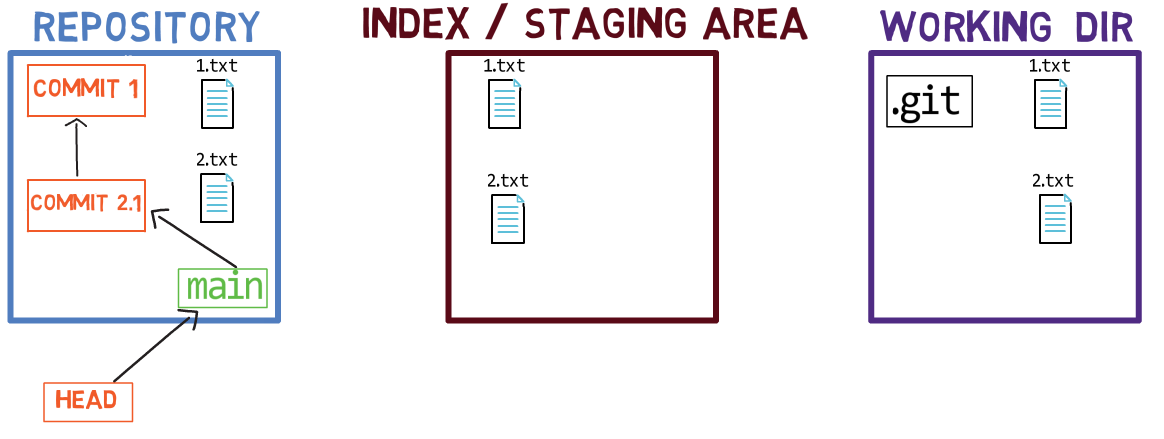 Création d'un nouveau commit
Création d'un nouveau commit
J'ai omis "Commit 2" car il n'est pas accessible depuis HEAD, même si son objet existe dans la base de données interne d'objets de Git.
Pourquoi "Commit 2" et "Commit 2.1" sont-ils différents ? Même si nous avons utilisé le même message de commit, et même s'ils pointent vers le même objet arbre (du dossier racine consistant en 1.txt et 2.txt), ils ont toujours des horodatages différents, car ils ont été créés à des moments différents. "Commit 2" et "Commit 2.1" pointent tous deux vers "Commit 1", mais seul "Commit 2.1" est accessible depuis HEAD.
git reset --mixed
Il est temps d'annuler encore plus loin. Cette fois, utilisez :
git reset --mixed HEAD~1
(Note : --mixed est l'option par défaut pour git reset.)
Cette commande commence de la même manière que git reset --soft HEAD~1. C'est-à-dire que la commande prend le pointeur de ce vers quoi HEAD pointe maintenant, qui est la branche main, et le règle à HEAD~1, dans notre exemple - "Commit 1".
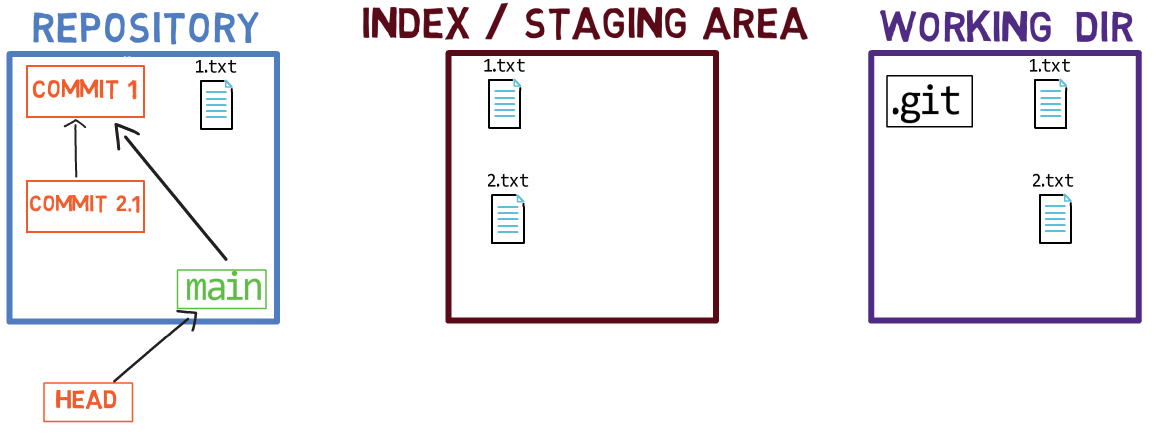 La première étape de
La première étape de git reset --mixed est la même que git reset --soft
Ensuite, Git va plus loin, annulant effectivement les changements que nous avons faits à l'index. C'est-à-dire changer l'index pour qu'il corresponde au HEAD actuel, le nouveau HEAD après l'avoir réglé dans la première étape.
Si nous avons exécuté git reset --mixed HEAD~1, alors HEAD (main) serait réglé à HEAD~1 ("Commit 1"), et ensuite Git ferait correspondre l'index à l'état de "Commit 1" - dans ce cas, cela signifie que 2.txt ne ferait plus partie de l'index.
 La deuxième étape de
La deuxième étape de git reset --mixed est de faire correspondre l'index avec le nouveau HEAD
Il est temps de créer un nouveau commit avec l'état du "Commit 2" original. Cette fois vous devez mettre en transit 2.txt à nouveau avant de le créer :
git add 2.txt
git commit -m "Commit 2.2"
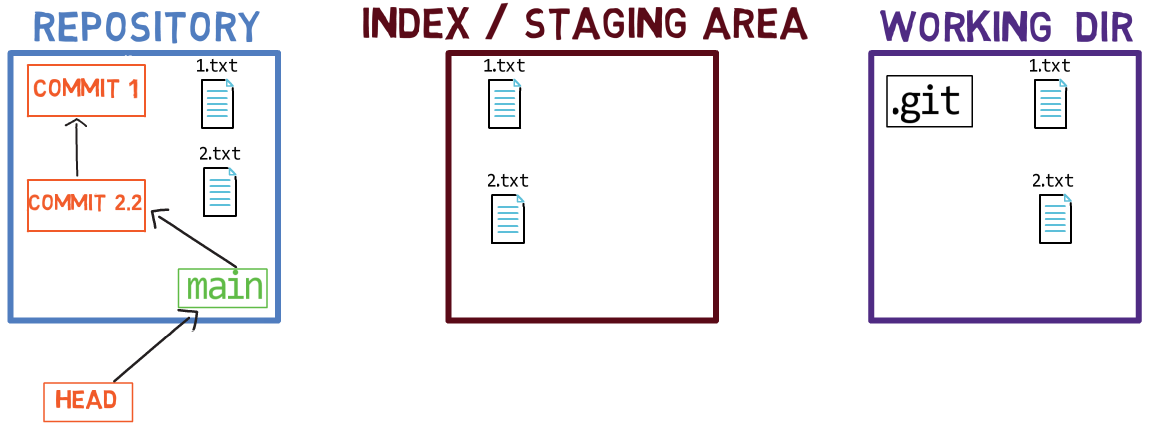 Création de "Commit 2.2"
Création de "Commit 2.2"
De même que pour "Commit 2.1", je "nomme" ce commit "Commit 2.2" pour le différencier du "Commit 2" original ou de "Commit 2.1" - ces commits résultent dans le même état que le "Commit 2" original, mais ce sont des objets commit différents.
git reset --hard
Allez-y, annulez encore plus !
Cette fois, utilisez l'option --hard, et exécutez :
git reset --hard HEAD~1
Encore une fois, Git commence par l'étape --soft, réglant ce vers quoi HEAD pointe (main), à HEAD~1 ("Commit 1").
 La première étape de
La première étape de git reset --hard est la même que git reset --soft
Ensuite, passant à l'étape --mixed, faisant correspondre l'index avec HEAD. C'est-à-dire que Git annule la mise en transit de 2.txt.
 La deuxième étape de
La deuxième étape de git reset --hard est la même que git reset --mixed
Ensuite vient l'étape --hard, où Git va encore plus loin et fait correspondre le répertoire de travail avec l'état de l'index. Dans ce cas, cela signifie supprimer 2.txt aussi du répertoire de travail.
 La troisième étape de
La troisième étape de git reset --hard fait correspondre l'état du répertoire de travail avec celui de l'index
Donc pour introduire un changement dans Git, vous avez trois étapes : vous changez le répertoire de travail, l'index ou la zone de transit, et ensuite vous validez un nouvel instantané avec ces changements. Pour annuler ces changements :
- Si nous utilisons
git reset --soft, nous annulons l'étape de commit. - Si nous utilisons
git reset --mixed, nous annulons aussi l'étape de mise en transit. - Si nous utilisons
git reset --hard, nous annulons les changements au répertoire de travail.
 Les trois options principales de
Les trois options principales de git reset
Scénarios de la vie réelle
Scénario #1
Donc dans un scénario de la vie réelle, écrivez "I love Git" dans un fichier (love.txt), car nous aimons tous Git 😍. Allez-y, mettez en transit et validez ceci aussi :
echo I love Git > love.txt
git add love.txt
git commit -m "Commit 2.3"
 Création de "Commit 2.3"
Création de "Commit 2.3"
Aussi, sauvegardez un tag pour pouvoir revenir à ce commit plus tard si nécessaire :
git tag scenario-1
Oh, oups !
En fait, je ne voulais pas que vous le validiez.
Ce que je voulais vraiment que vous fassiez, c'est écrire un peu plus de mots d'amour dans ce fichier avant de le valider.
Que pouvez-vous faire ?
Eh bien, une façon de surmonter cela serait d'utiliser git reset --mixed HEAD~1, annulant effectivement à la fois les actions de validation et de mise en transit que vous avez prises :
git reset --mixed HEAD~1
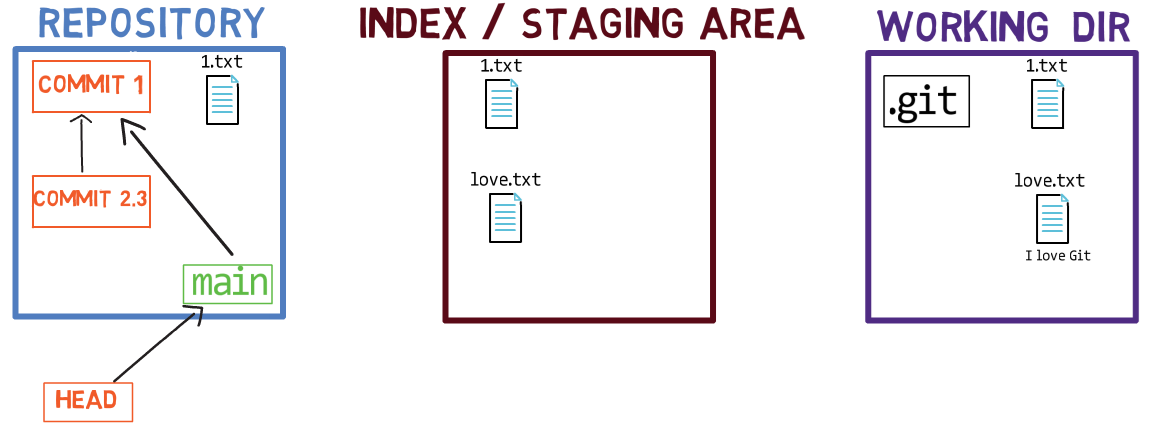 Annulation des étapes de mise en transit et de validation
Annulation des étapes de mise en transit et de validation
Donc main pointe vers "Commit 1" à nouveau, et love.txt ne fait plus partie de l'index. Cependant, le fichier reste dans le répertoire de travail. Vous pouvez maintenant y ajouter plus de contenu :
echo and Gitting Things Done >> love.txt
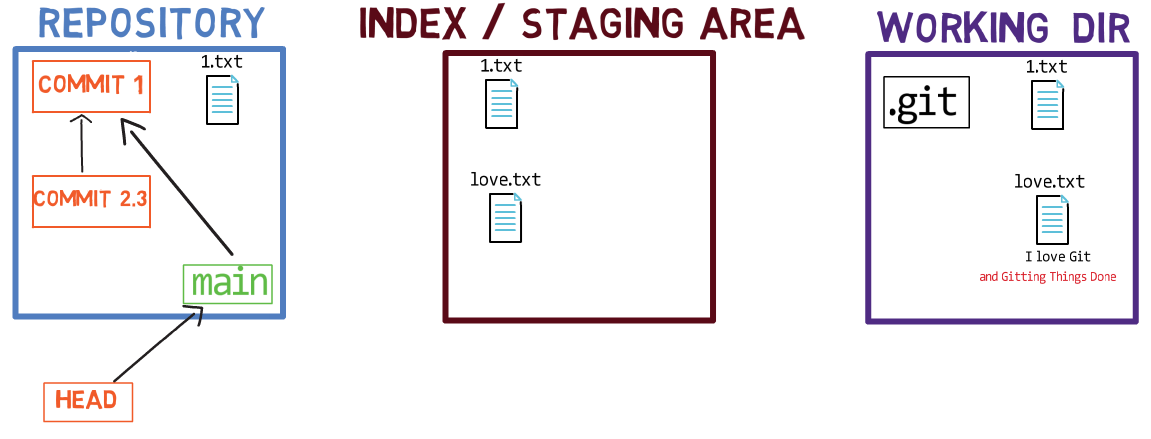 Ajout de plus de paroles d'amour
Ajout de plus de paroles d'amour
Mettez en transit et validez votre fichier :
git add love.txt
git commit -m "Commit 2.4"
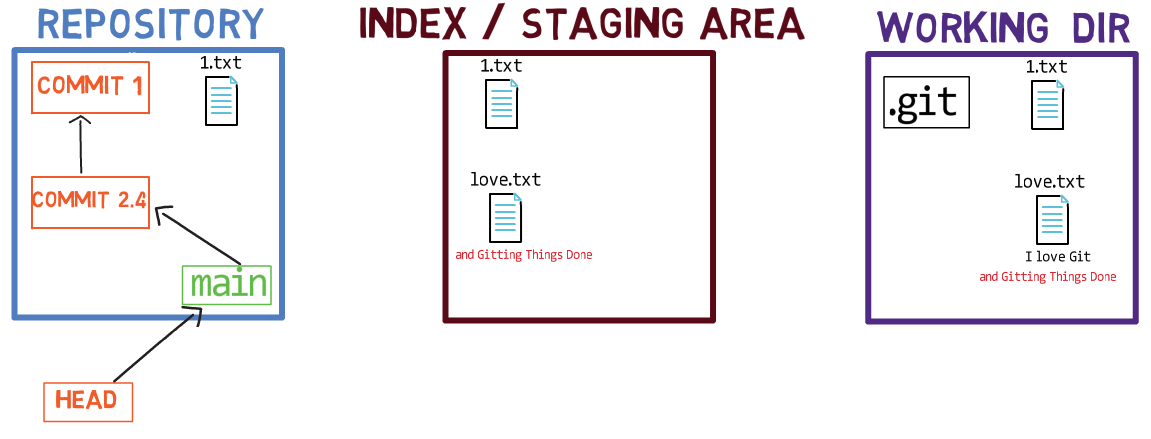 Introduction de "Commit 2.4"
Introduction de "Commit 2.4"
Bien joué !
Vous avez obtenu cet historique clair et agréable de "Commit 2.4" pointant vers "Commit 1".
Vous avez maintenant un nouvel outil dans votre boîte à outils, git reset.
Cet outil est super, super utile, et vous pouvez accomplir presque tout avec. Ce n'est pas toujours l'outil le plus pratique à utiliser, mais il est capable de résoudre presque tous les scénarios de réécriture d'historique si vous l'utilisez avec précaution.
Pour les débutants, je recommande d'utiliser uniquement git reset pour presque toutes les fois où vous voulez annuler dans Git. Une fois que vous vous sentez à l'aise avec, passez à d'autres outils.
Scénario #2
Considérons un autre cas.
Créez un nouveau fichier appelé new.txt ; mettez en transit et validez :
echo this is a new file > new.txt
git add new.txt
git commit -m "Commit 3"
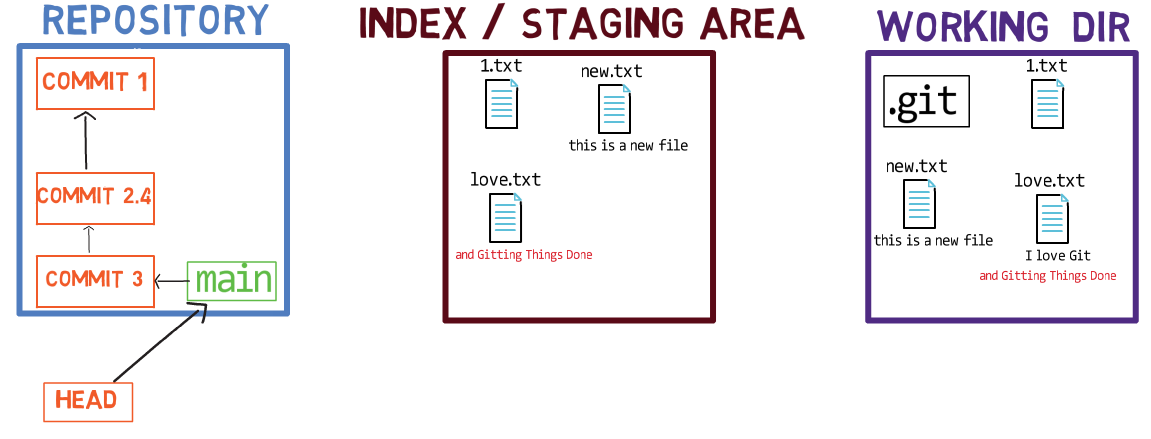 Création de
Création de new.txt et "Commit 3"
(Note : Dans le dessin j'ai omis les fichiers du dépôt pour éviter l'encombrement. Commit 3 inclut 1.txt, love.txt et new.txt à ce stade).
Oups. En fait, c'est une erreur. Vous étiez sur main, et je voulais que vous créiez ce commit sur une branche de fonctionnalité. Ma faute 😇
Il y a deux outils les plus importants que je veux que vous reteniez de ce chapitre. Le second est git reset. Le premier et de loin le plus important est de dessiner au tableau blanc l'état actuel par rapport à l'état dans lequel vous voulez être.
Pour ce scénario, l'état actuel et l'état désiré ressemblent à ceci :
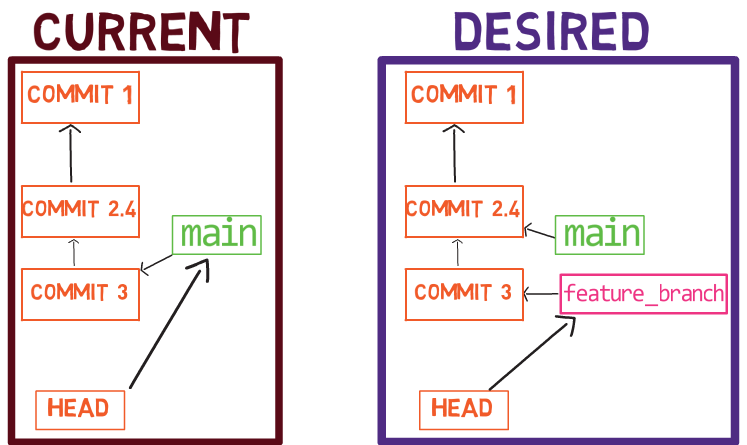 Scénario #2 : états actuel-vs-désiré
Scénario #2 : états actuel-vs-désiré
(Note : Dans les diagrammes suivants, je ferai référence à l'état actuel comme l'état "original" - avant de commencer le processus de réécriture de l'historique.)
Vous remarquerez trois changements :
mainpointe vers "Commit 3" (le bleu) dans l'état actuel, mais vers "Commit 2.4" dans l'état désiré.feature_branchn'existe pas dans l'état actuel, mais il existe et pointe vers "Commit 3" dans l'état désiré.HEADpointe versmaindans l'état actuel, et versfeature_branchdans l'état désiré.
Si vous pouvez dessiner cela et que vous savez utiliser git reset, vous pouvez certainement vous sortir de cette situation.
Donc encore une fois, la chose la plus importante est de respirer un coup et de dessiner cela.
En observant le dessin ci-dessus, comment passez-vous de l'état actuel à l'état désiré ?
Il y a quelques façons différentes bien sûr, mais je présenterai une seule option pour chaque scénario. N'hésitez pas à jouer avec d'autres options également.
Vous pouvez commencer par utiliser git reset --soft HEAD~1. Cela réglerait main pour pointer vers le commit précédent, "Commit 2.4" :
git reset --soft HEAD~1
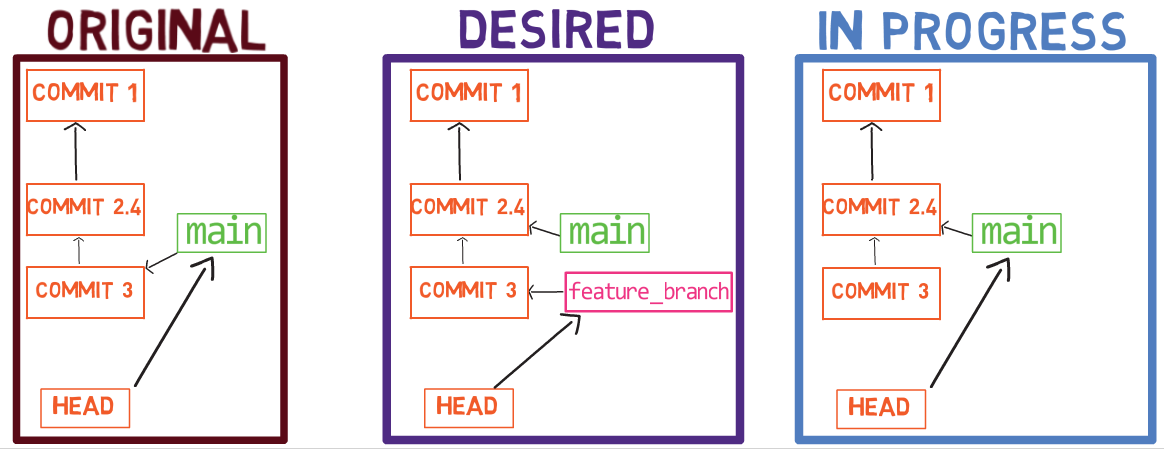 Changement de
Changement de main : "Commit 3" est toujours là, juste pas accessible depuis HEAD
En jetant un coup d'œil au diagramme actuel-vs-désiré à nouveau, vous pouvez voir que vous avez besoin d'une nouvelle branche, n'est-ce pas ? Vous pouvez utiliser git switch -c feature_branch pour cela, ou git checkout -b feature_branch (qui fait la même chose) :
git switch -c feature_branch
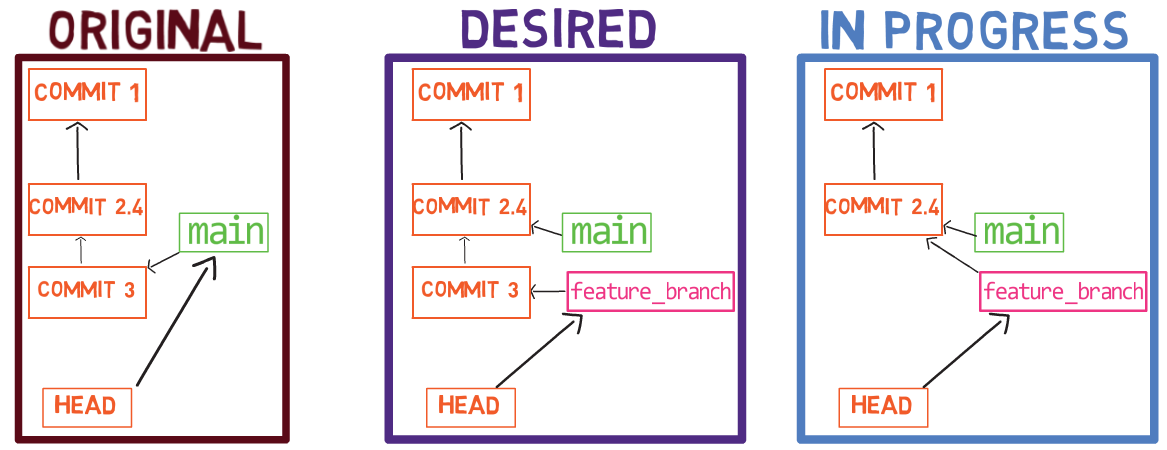 _Création de la branche
_Création de la branche feature_branch_
Cette commande met également à jour HEAD pour pointer vers la nouvelle branche.
Puisque vous avez utilisé git reset --soft, vous n'avez pas changé l'index, donc il a actuellement exactement l'état que vous voulez valider - comme c'est pratique ! Vous pouvez simplement valider sur feature_branch :
git commit -m "Commit 3.1"
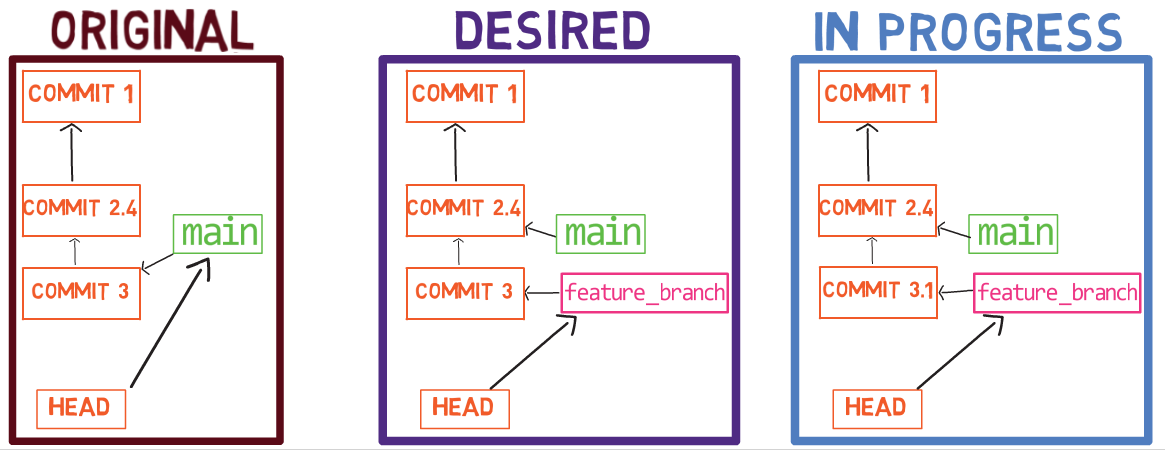 _Validation sur la branche
_Validation sur la branche feature_branch_
Et vous êtes arrivé à l'état désiré.
Scénario #3
Prêt à appliquer vos connaissances à d'autres cas ?
Toujours sur feature_branch, ajoutez quelques changements à love.txt, et créez un nouveau fichier appelé cool.txt. Mettez-les en transit et validez :
echo Some changes >> love.txt
echo Git is cool > cool.txt
git add love.txt
git add cool.txt
git commit -m "Commit 4"
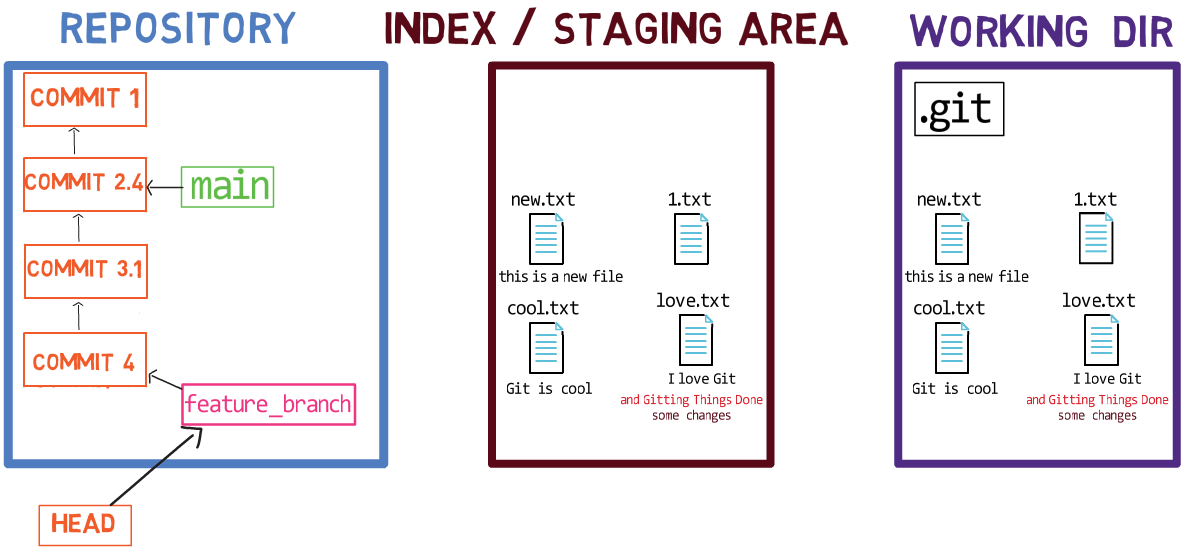 L'historique, ainsi que l'état de l'index et du répertoire de travail après la création de "Commit 4"
L'historique, ainsi que l'état de l'index et du répertoire de travail après la création de "Commit 4"
Oh, oups, en fait je voulais que vous créiez deux commits séparés, un avec chaque changement...
Voulez-vous essayer celui-ci vous-même (avant de lire la suite) ?
Vous pouvez annuler les étapes de validation et de mise en transit :
git reset --mixed HEAD~1
Suite à cette commande, l'index n'inclut plus ces deux changements, mais ils sont tous les deux toujours dans votre système de fichiers :
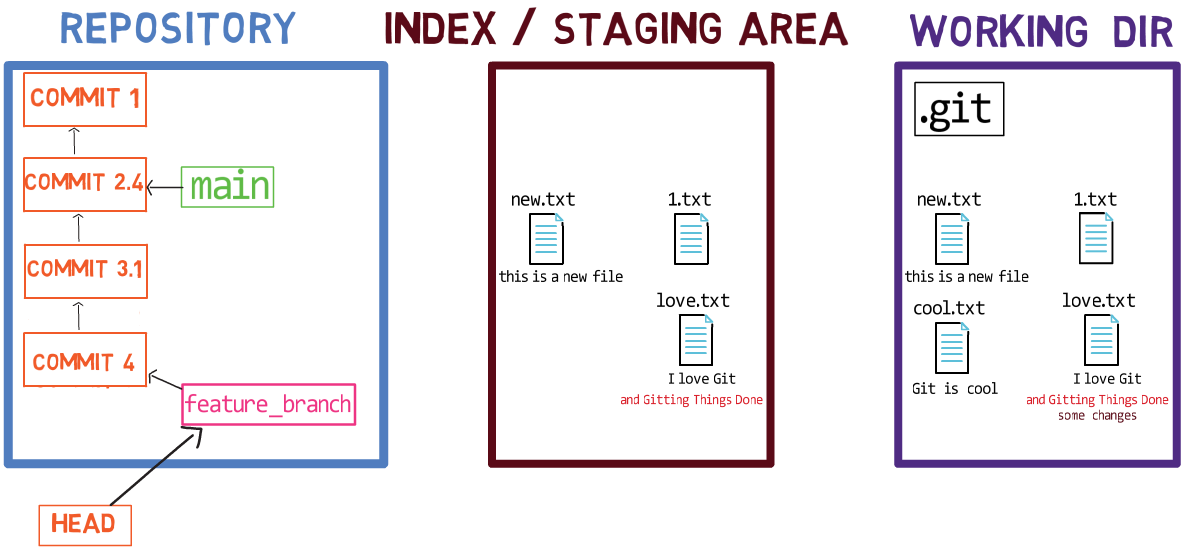 État résultant après l'utilisation de
État résultant après l'utilisation de git reset --mixed HEAD~1
Donc maintenant, si vous mettez en transit seulement love.txt, vous pouvez le valider séparément :
git add love.txt
git commit -m "Love"
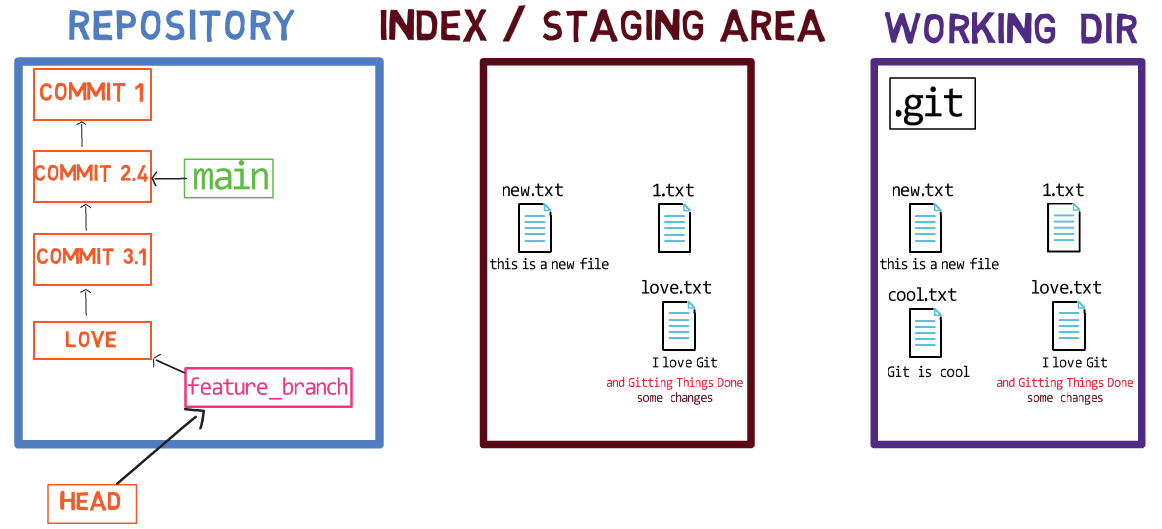 État résultant après la validation des changements de
État résultant après la validation des changements de love.txt
Ensuite, faites de même pour cool.txt :
git add cool.txt
git commit -m "Cool"
 Validation séparée
Validation séparée
Bien !
Scénario #4
Pour nettoyer l'état, passez à main et utilisez reset --hard pour le faire pointer vers "Commit 3.1", tout en réglant l'index et le répertoire de travail à l'état de "Commit 3.1" :
git checkout main
git reset --hard <SHA_OF_COMMIT_3_1>
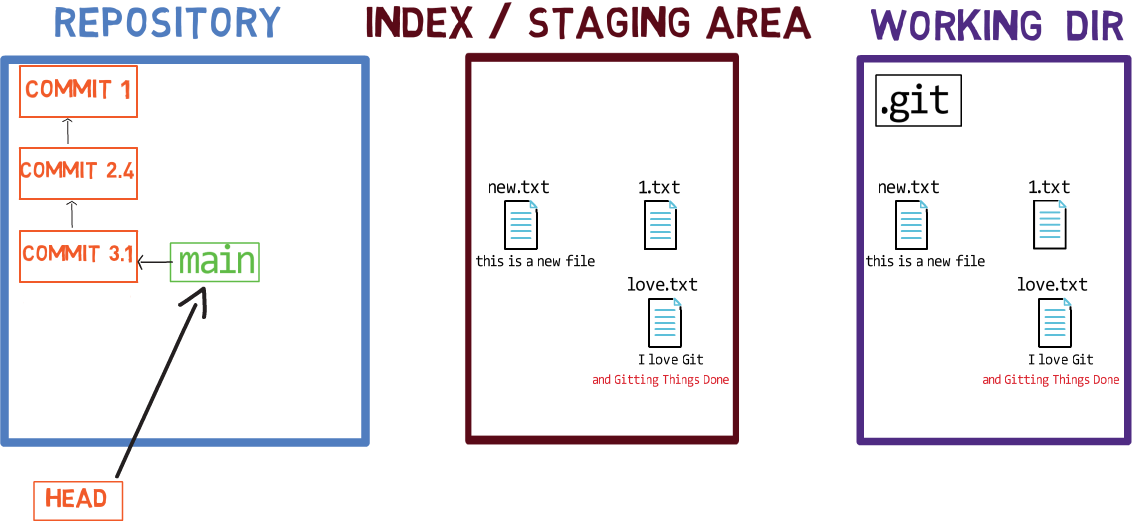 Réinitialisation de
Réinitialisation de main à "Commit 3.1"
Créez un autre fichier (another.txt) avec du texte, et ajoutez du texte à love.txt. Mettez en transit les deux changements, et validez-les :
echo Another file > another.txt
echo More love >> love.txt
git add another.txt
git add love.txt
git commit -m "Commit 4.1"
Cela devrait être le résultat :
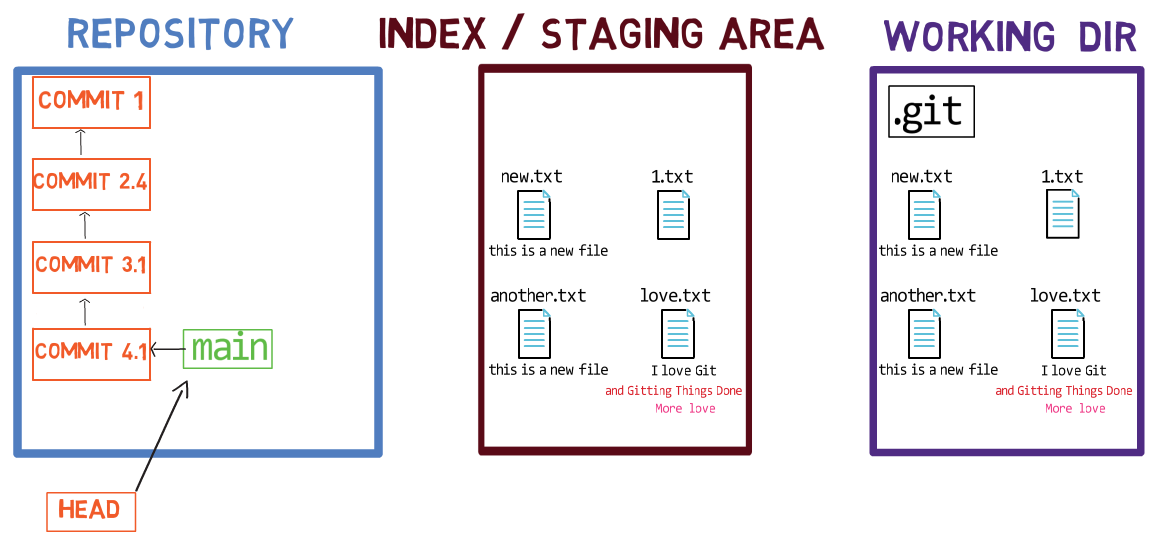 Un nouveau commit
Un nouveau commit
Oups...
Donc cette fois, je voulais que ce soit sur une autre branche, mais pas une nouvelle branche, plutôt - une branche déjà existante.
Alors que pouvez-vous faire ?
Je vais vous donner un indice. La réponse est vraiment courte et vraiment facile. Que faisons-nous en premier ?
Non, pas reset. Nous dessinons. C'est la première chose à faire, car cela rendrait tout le reste tellement plus facile. Donc voici l'état actuel :
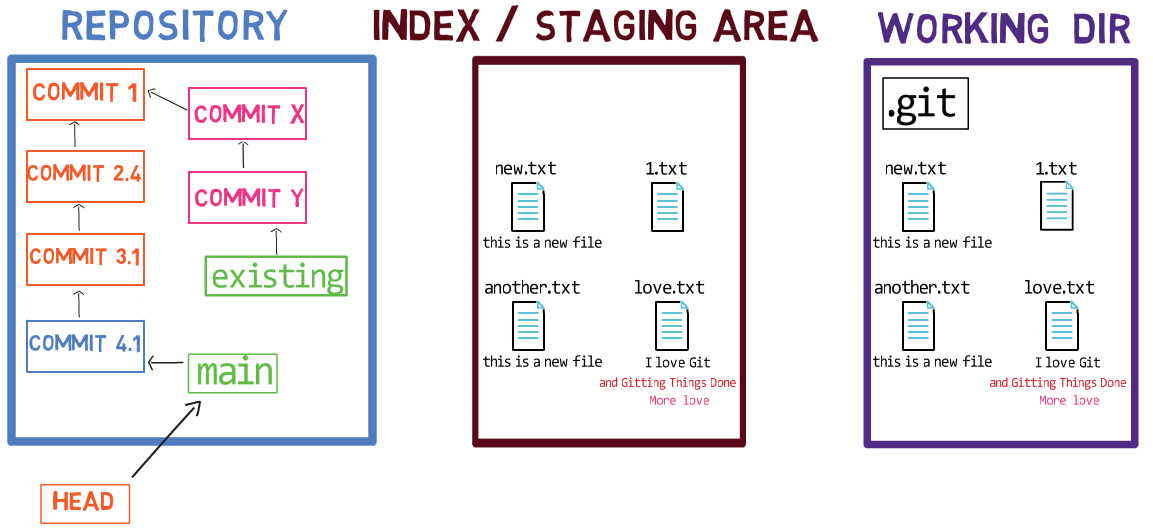 Le nouveau commit sur
Le nouveau commit sur main apparaît en bleu
Et l'état désiré ?
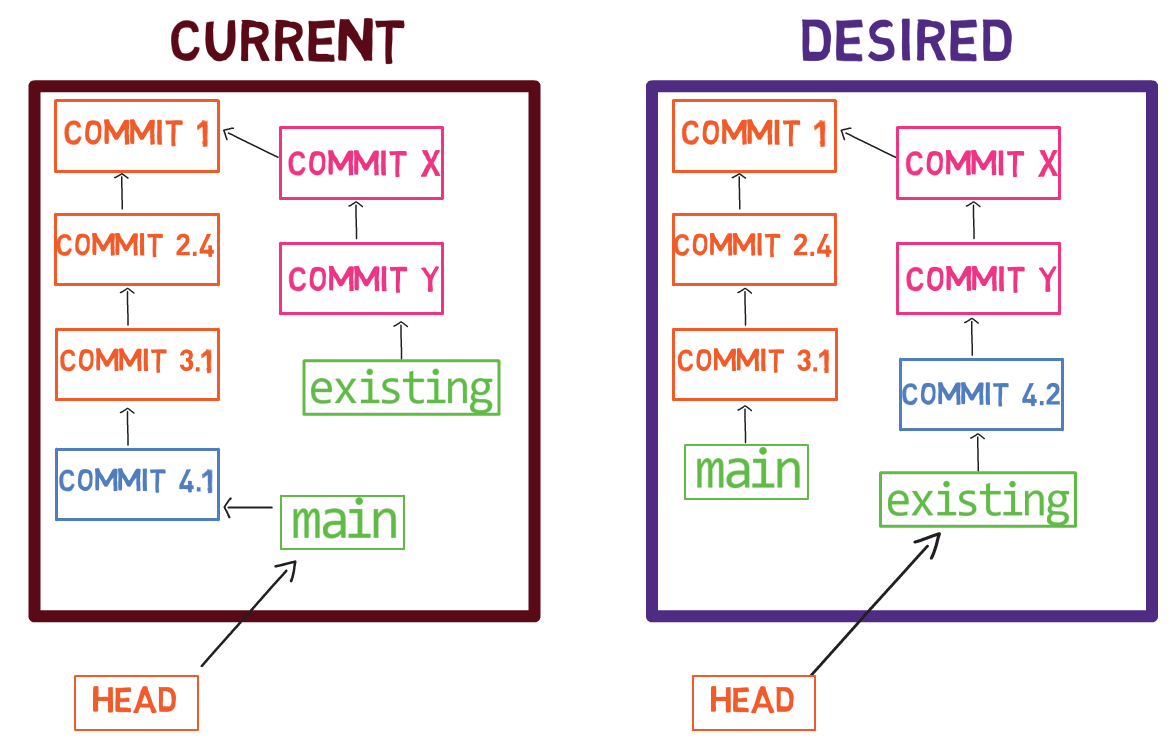 Nous voulons que le commit "bleu" soit sur une autre branche,
Nous voulons que le commit "bleu" soit sur une autre branche, existing
Comment passez-vous de l'état actuel à l'état désiré, qu'est-ce qui serait le plus facile ?
Une façon serait d'utiliser git reset comme vous l'avez fait avant, mais il y a une autre façon que j'aimerais que vous essayiez.
Notez que les commandes suivantes supposent en effet que la branche existing existe sur votre dépôt, pourtant vous ne l'avez pas créée plus tôt. Pour correspondre à un état où cette branche existe réellement, vous pouvez utiliser les commandes suivantes :
git checkout <SHA_OF_COMMIT_1>
git checkout -b existing
echo "Hello" > x.txt
git add x.txt
git commit -m "Commit X"
git checkout <SHA_OF_COMMIT_3_1> -- love.txt
git commit -m "Commit Y"
git checkout main
(La commande git checkout <SHA_OF_COMMIT_3_1> -- love.txt copie le contenu de love.txt de "Commit 3.1" vers l'index et le répertoire de travail, pour que vous puissiez le valider sur la branche existing. Nous avons besoin que l'état de love.txt sur "Commit Y" soit le même que sur "Commit 3.1" pour éviter les conflits.)
Maintenant votre historique devrait correspondre à celui montré dans l'image avec la légende "Nous voulons que le commit "bleu" soit sur une autre branche, existing".
D'abord, déplacez HEAD pour pointer vers la branche existing :
git switch existing
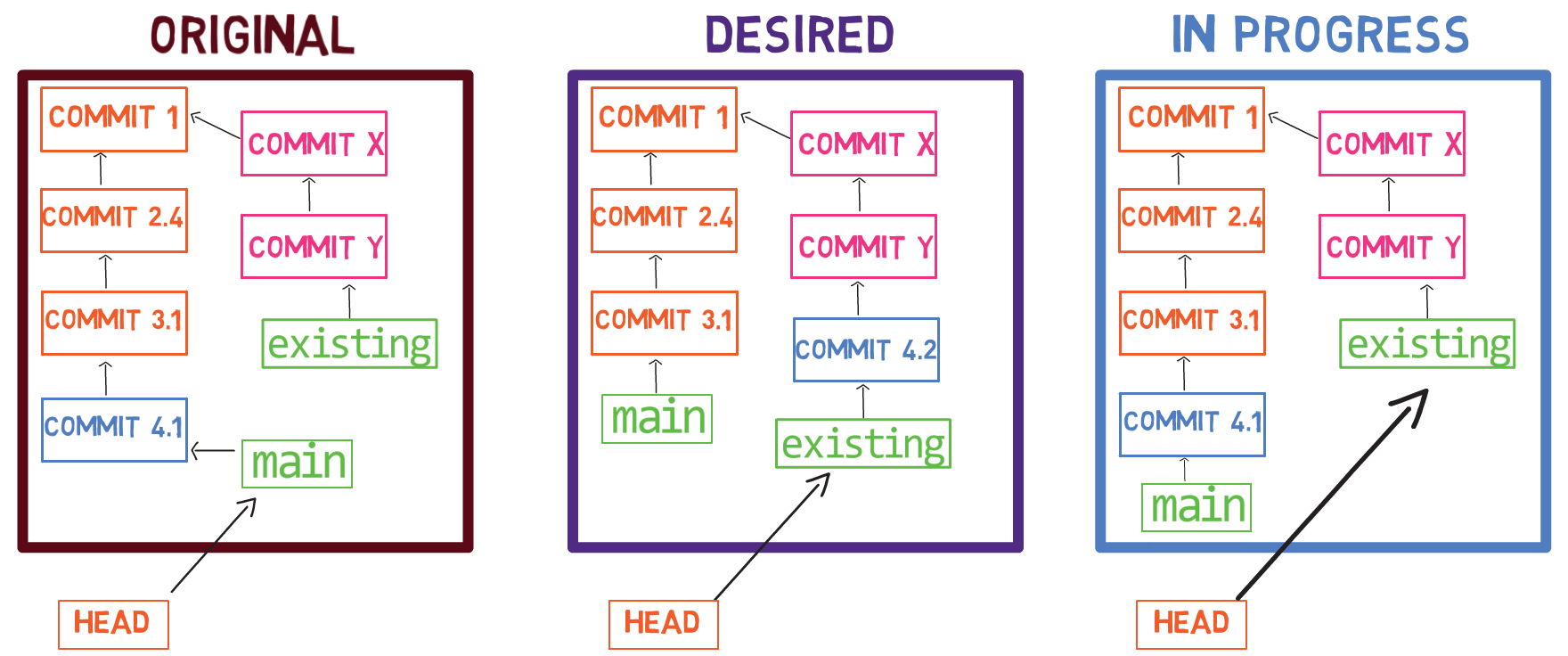 Passer à la branche
Passer à la branche existing
Intuitivement, ce que vous voulez faire, c'est prendre les changements introduits dans "Commit 4.1", et appliquer ces changements ("copier-coller") au-dessus de la branche existing. Et Git a un outil juste pour ça.
Pour demander à Git de prendre les changements introduits entre un commit et son commit parent et juste appliquer ces changements sur la branche active, vous pouvez utiliser git cherry-pick, une commande que nous avons introduite au chapitre 8. Cette commande prend les changements introduits dans la révision spécifiée et les applique à l'état du commit actif. Exécutez :
git cherry-pick <SHA_OF_COMMIT_4_1>
Vous pouvez spécifier l'identifiant SHA-1 du commit désiré, mais vous pouvez aussi utiliser git cherry-pick main, car le commit dont vous appliquez les changements est celui vers lequel main pointe.
git cherry-pick crée également un nouvel objet commit, et met à jour la branche active pour pointer vers ce nouvel objet, donc l'état résultant serait :
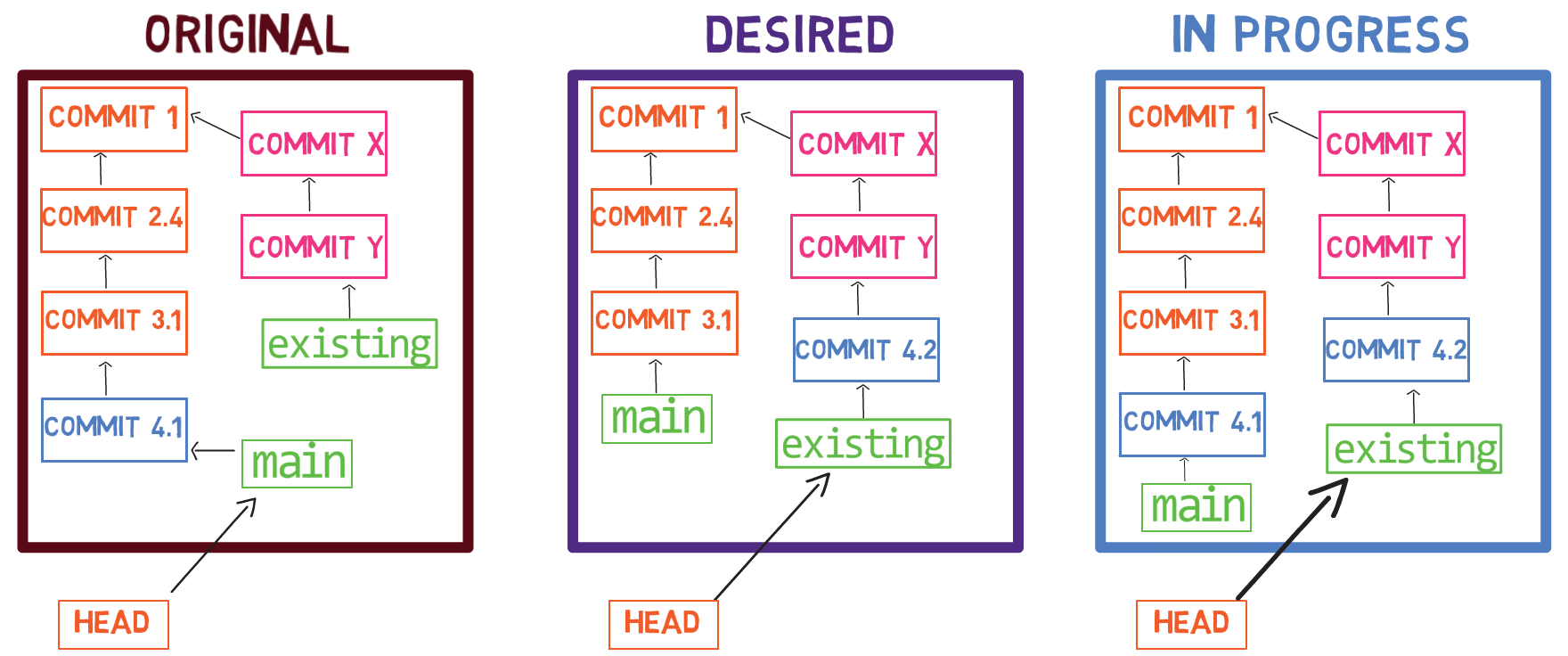 Le résultat après l'utilisation de
Le résultat après l'utilisation de git cherry-pick
Je marque le commit comme "Commit 4.2" car il a un horodatage, un parent et une valeur SHA-1 différents de "Commit 4.1", bien que les changements qu'il introduit soient les mêmes.
Vous avez fait de bons progrès - le commit désiré est maintenant sur la branche existing ! Mais nous ne voulons pas que ces changements existent sur la branche main. git cherry-pick a seulement appliqué les changements à la branche existante. Comment pouvez-vous les supprimer de main ?
Une façon serait de repasser à main, puis de le réinitialiser :
git switch main
git reset --hard HEAD~1
Et le résultat :
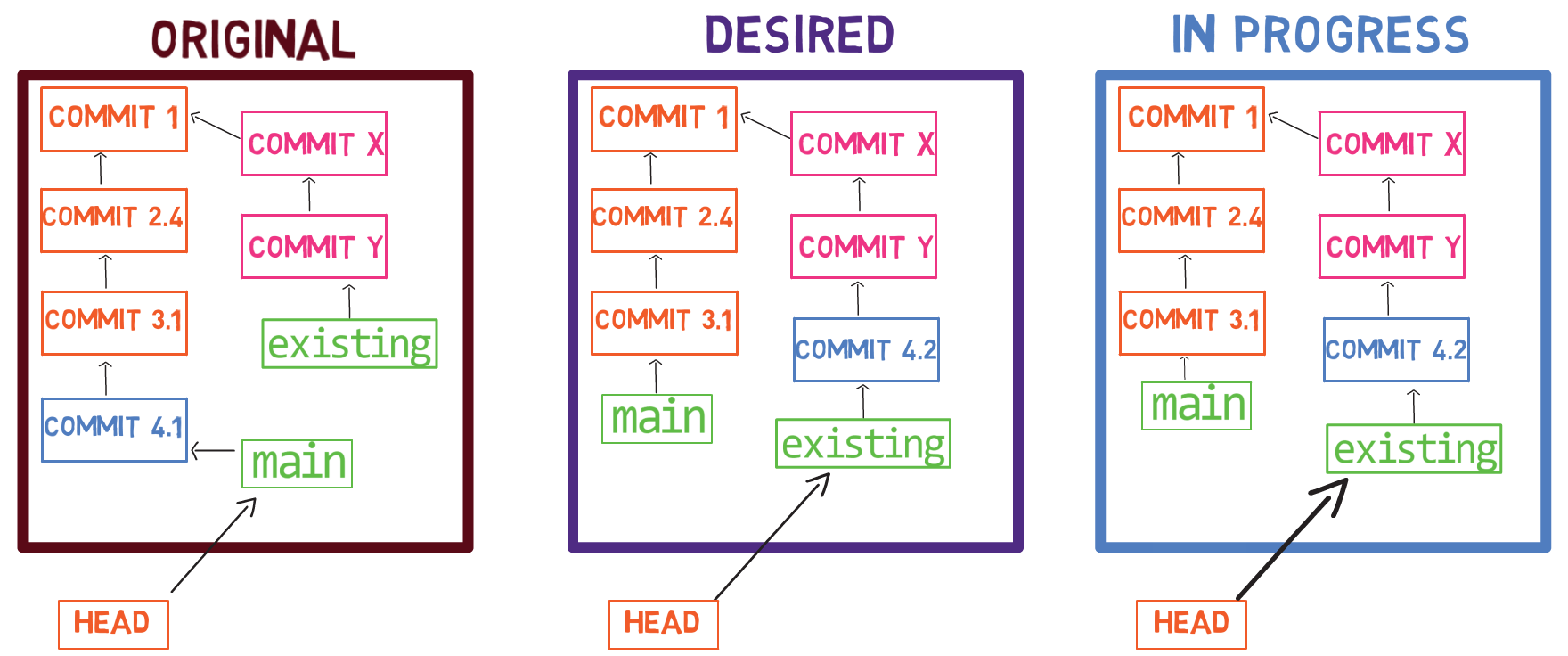 L'état résultant après la réinitialisation de
L'état résultant après la réinitialisation de main
Vous l'avez fait !
Notez que git cherry-pick calcule en fait la différence entre le commit spécifié et son parent, puis applique la différence au commit actif. Cela signifie que parfois, Git ne sera pas capable d'appliquer ces changements en raison d'un conflit.
Aussi, notez que vous pouvez demander à Git de cherry-pick les changements introduits dans n'importe quel commit, pas seulement les commits référencés par une branche.
Récapitulatif - Git Reset
Dans ce chapitre, nous avons appris comment git reset fonctionne, et clarifié ses trois principaux modes de fonctionnement :
git reset --soft <commit>, qui change ce vers quoiHEADpointe - vers<commit>.git reset --mixed <commit>, qui passe par l'étape--soft, et règle aussi l'état de l'index pour correspondre à celui deHEAD.git reset --hard <commit>, qui passe par les étapes--softet--mixed, et ensuite règle l'état du répertoire de travail pour correspondre à celui de l'index.
Vous avez ensuite appliqué vos connaissances sur git reset pour résoudre certains problèmes de la vie réelle qui surviennent lors de l'utilisation de Git.
En comprenant la façon dont Git fonctionne, et en dessinant au tableau blanc l'état actuel versus l'état désiré, vous pouvez aborder avec confiance toutes sortes de scénarios.
Dans les futurs chapitres, nous couvrirons des commandes Git supplémentaires et comment elles peuvent nous aider à résoudre toutes sortes de situations indésirables.
Chapitre 10 - Outils supplémentaires pour annuler des changements
Dans le chapitre précédent, vous avez rencontré git reset. En effet, git reset est un outil super puissant, et je recommande fortement de l'utiliser jusqu'à ce que vous vous sentiez complètement à l'aise avec.
Pourtant, git reset n'est pas le seul outil à notre disposition. Parfois, ce n'est pas l'outil le plus pratique à utiliser. D'autres fois, ce n'est tout simplement pas suffisant. Ce court chapitre aborde quelques outils qui sont utiles pour annuler des changements dans Git.
git commit --amend
Considérez le Scénario #1 du chapitre précédent à nouveau. Pour rappel, vous avez écrit "I love Git" dans un fichier (love.txt), mis en transit et validé ce fichier :
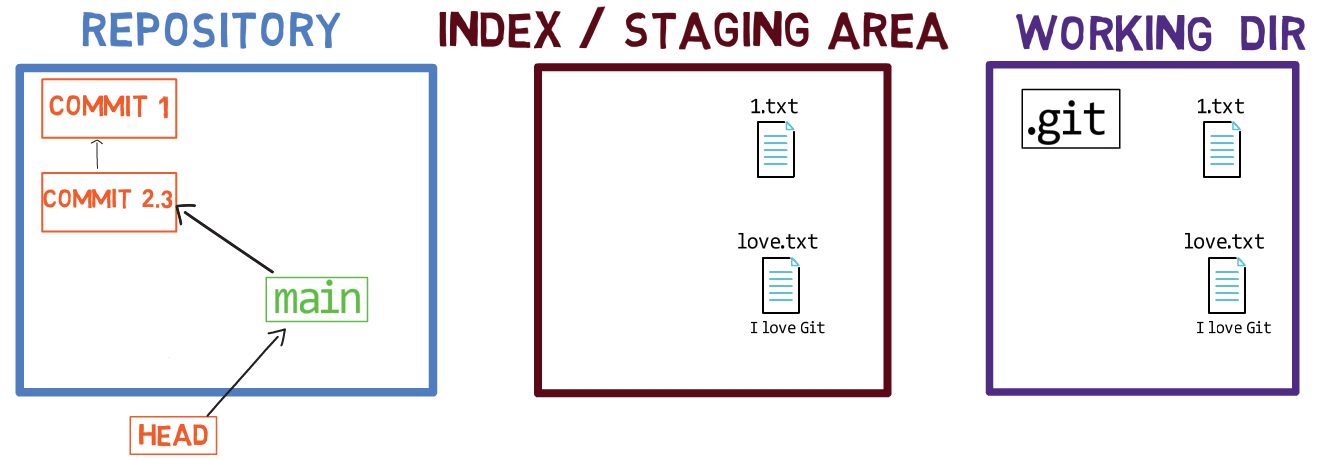 L'état après la création de "Commit 2.3"
L'état après la création de "Commit 2.3"
Et puis j'ai réalisé que je ne voulais pas que vous le validiez à cet état, mais plutôt - écrire un peu plus de mots d'amour dans ce fichier avant de le valider.
Pour correspondre à cet état, faites simplement un checkout du tag que vous avez créé, qui pointe vers "Commit 2.3" :
git checkout scenario-1
Dans le chapitre précédent, lorsque nous avons introduit git reset, vous avez résolu ce problème en utilisant git reset --mixed HEAD~1, annulant effectivement à la fois les actions de validation et de mise en transit que vous avez prises.
Maintenant je voudrais que vous considériez une autre approche. Continuez à travailler à l'état du dernier commit introduit ("Commit 2.3", référencé par le tag "scenario-1"), et faites les changements que vous voulez :
echo And I love this book >> love.txt
Ajoutez ce changement à l'index :
git add love.txt
Maintenant, vous pouvez utiliser git commit avec l'option --amend, qui lui dit d'écraser le commit vers lequel HEAD pointe. En fait, cela créera un autre nouveau commit, pointant vers HEAD~1 ("Commit 1" dans notre exemple), et fera pointer HEAD vers ce commit nouvellement créé. En fournissant l'argument -m vous pouvez spécifier un nouveau message de commit également :
git commit --amend -m "Commit 2.4"
Après avoir exécuté cette commande, HEAD pointe vers main, qui pointe vers "Commit 2.4", qui pointe à son tour vers "Commit 1". Le "Commit 2.3" précédent n'est plus accessible depuis l'historique.
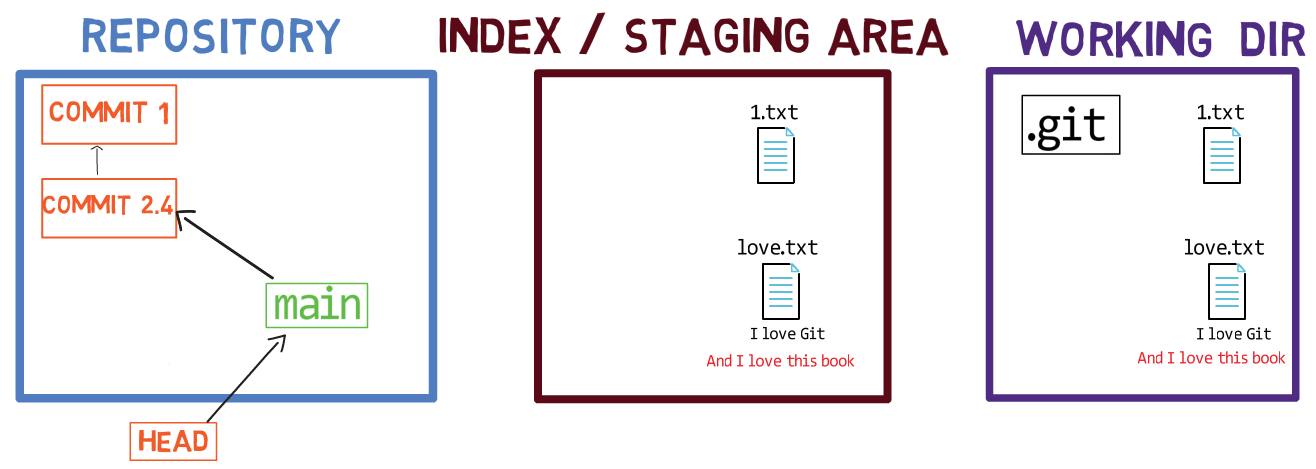 L'état après l'utilisation de
L'état après l'utilisation de git commit --amend (Commit "2.3" est inaccessible et donc non inclus dans le dessin)
Cet outil est utile lorsque vous voulez rapidement écraser le dernier commit que vous avez créé. En effet, vous pourriez utiliser git reset pour accomplir la même chose, mais vous pouvez voir git commit --amend comme un raccourci plus pratique.
git revert
D'accord, donc un autre jour, un autre problème.
Ajoutez le texte suivant à love.txt, mettez en transit et validez comme suit :
echo This is more tezt >> love.txt
git add love.txt
git commit -m "Commit 3"
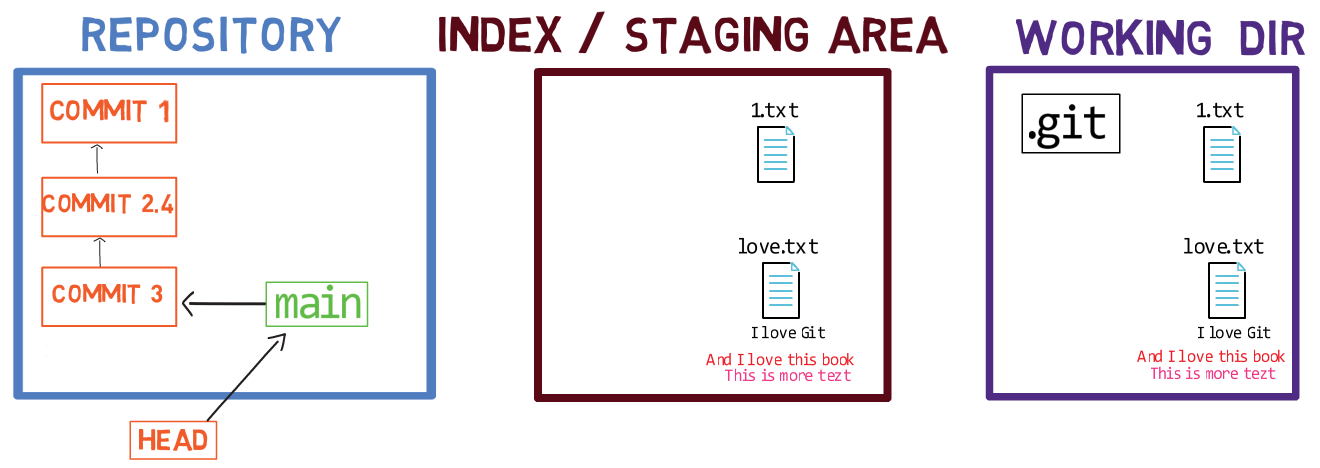 L'état après la validation de "Commit 3"
L'état après la validation de "Commit 3"
Et poussez-le vers le serveur distant :
git push origin HEAD
Euh, oups 😓…
Je viens de remarquer quelque chose. J'avais une coquille là. J'ai écrit "This is more tezt" au lieu de "This is more text". Oups. Alors quel est le gros problème maintenant ? J'ai poussé (push), ce qui signifie que quelqu'un d'autre pourrait avoir déjà tiré (pull) ces changements.
Si j'écrase ces changements en utilisant git reset, nous aurons des historiques différents, et tout pourrait mal tourner. Vous pouvez réécrire votre propre copie du repo autant que vous le souhaitez jusqu'à ce que vous la poussiez.
Une fois que vous poussez le changement, vous devez être certain que personne d'autre n'a récupéré ces changements si vous allez réécrire l'historique.
Alternativement, vous pouvez utiliser un autre outil appelé git revert. Cette commande prend le commit que vous lui fournissez et calcule le diff par rapport à son commit parent, tout comme git cherry-pick, mais cette fois, elle calcule les changements inverses. C'est-à-dire que si dans le commit spécifié vous avez ajouté une ligne, l'inverse supprimerait la ligne, et vice versa.
Dans notre cas, nous inversons "Commit 3", donc l'inverse serait de supprimer la ligne "This is more tezt" de love.txt. Puisque "Commit 3" est référencé par main et HEAD, nous pouvons utiliser n'importe laquelle de ces références nommées dans cette commande :
 Utilisation de
Utilisation de git revert pour annuler les changements
git revert a créé un nouvel objet commit, ce qui signifie que c'est un ajout à l'historique. En utilisant git revert, vous n'avez pas réécrit l'historique. Vous avez admis votre erreur passée, et ce commit est une reconnaissance que vous avez fait une erreur et que vous l'avez maintenant corrigée.
Certains diraient que c'est la façon la plus mature. Certains diraient que ce n'est pas un historique aussi propre que celui que vous obtiendriez si vous utilisiez git reset pour réécrire le commit précédent. Mais c'est un moyen d'éviter de réécrire l'historique.
Vous pouvez maintenant corriger la coquille et valider à nouveau :
echo This is more text >> love.txt
git add love.txt
git commit -m "Commit 3.1"
 L'état résultant après avoir refait les changements
L'état résultant après avoir refait les changements
Vous pouvez utiliser git revert pour inverser un commit autre que HEAD. Disons que vous voulez inverser le parent de HEAD, vous pouvez utiliser :
git revert HEAD~1
Ou vous pourriez fournir le SHA-1 du commit à inverser.
Notez que puisque Git appliquera le patch inverse du patch précédent - cette opération pourrait échouer, car le patch pourrait ne plus s'appliquer et vous pourriez obtenir un conflit.
Git Rebase comme outil pour annuler des choses
Au chapitre 8, vous avez appris Git rebase. Nous l'avons ensuite considéré principalement comme un outil pour combiner des changements introduits dans différentes branches. Pourtant, tant que vous n'avez pas poussé vos changements, utiliser rebase sur votre propre branche peut être un moyen très pratique de réorganiser votre historique de commit.
Pour cela, vous rebaseriez généralement sur une seule branche, et utiliseriez le rebase interactif. Considérez à nouveau cet exemple couvert au chapitre 8, où j'ai travaillé depuis feature_branch_2, et spécifiquement édité le fichier code.py. J'ai commencé par changer toutes les chaînes pour qu'elles soient entourées de guillemets doubles plutôt que de guillemets simples :
 Changement de
Changement de ' en " dans code.py
Ensuite, j'ai mis en transit et validé :
git add code.py
git commit -m "Commit 17"
J'ai ensuite décidé d'ajouter une nouvelle fonction au début du fichier :
 _Ajout de la fonction
_Ajout de la fonction another_feature_
Encore une fois, j'ai mis en transit et validé :
git add code.py
git commit -m "Commit 18"
Et maintenant j'ai réalisé que j'avais en fait oublié de changer les guillemets simples en guillemets doubles entourant le __main__ (comme vous l'avez peut-être remarqué), donc j'ai fait cela aussi :
 Changement de
Changement de '__main__' en "__main__"
Bien sûr, j'ai mis en transit et validé ce changement :
git add code.py
git commit -m "Commit 19"
Maintenant, considérez l'historique :
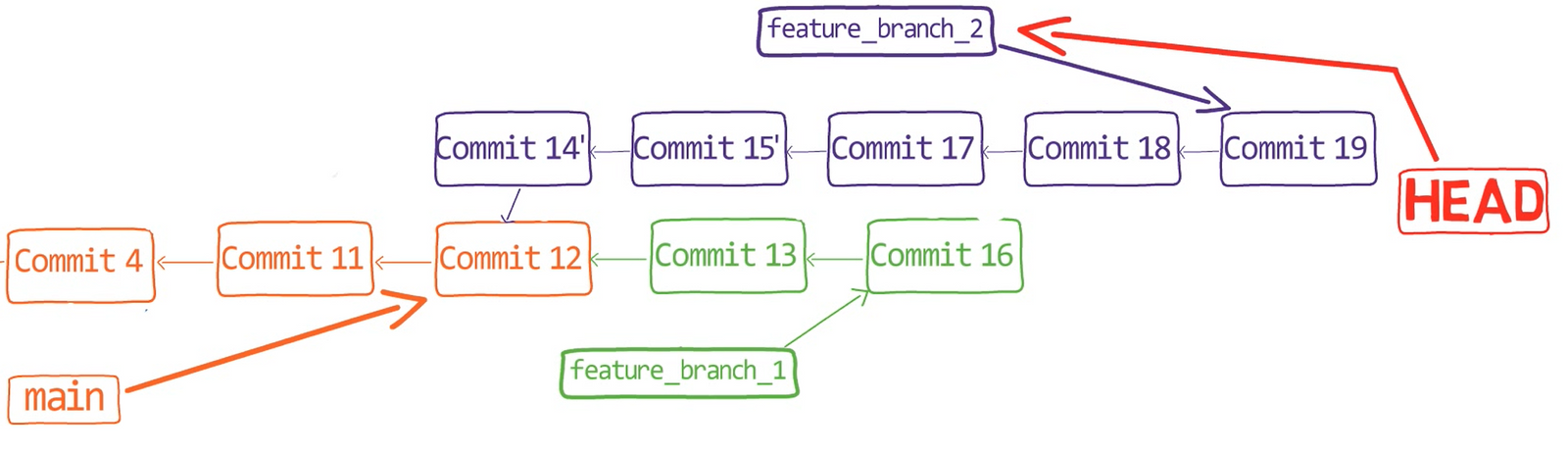 L'historique des commits après l'introduction de "Commit 19"
L'historique des commits après l'introduction de "Commit 19"
Comme expliqué au chapitre 8, je suis arrivé à un état avec deux commits qui sont liés l'un à l'autre, "Commit 17" et "Commit 19" (transformant les ' en "), mais ils sont séparés par le "Commit 18" non lié (où j'ai ajouté une nouvelle fonction).
C'est un cas classique où git rebase serait utile, pour annuler les changements locaux avant de pousser un historique propre.
Intuitivement, je veux éditer l'historique ici :
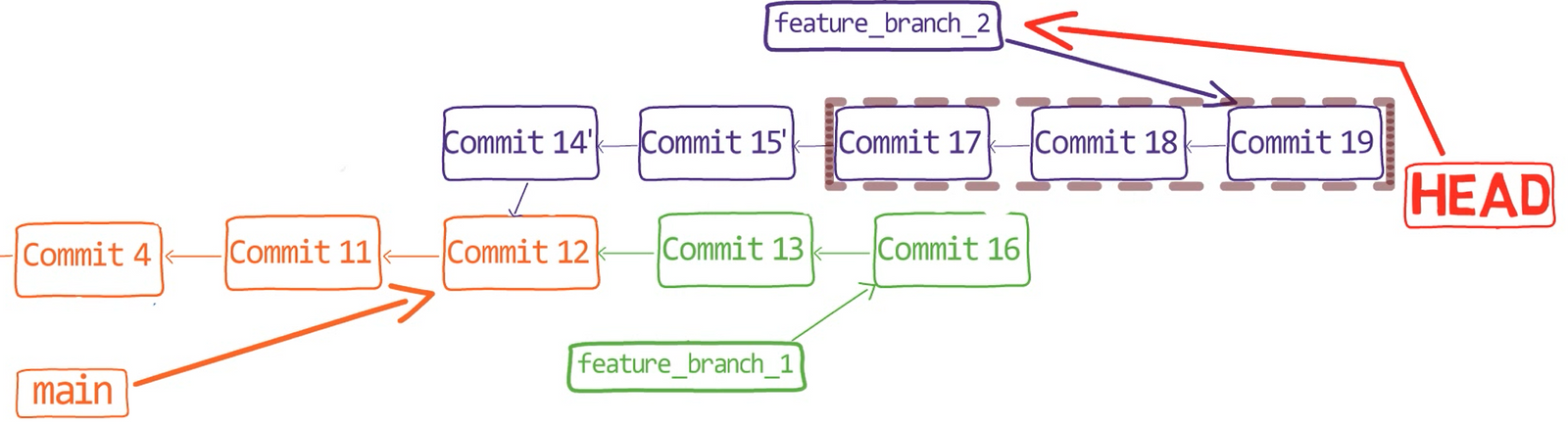 Ce sont les commits que je veux éditer
Ce sont les commits que je veux éditer
Je peux rebase (rebaser) l'historique de "Commit 17" à "Commit 19", au-dessus de "Commit 15". Pour faire cela :
git rebase --interactive --onto <SHA_OF_COMMIT_15> <SHA_OF_COMMIT_15>
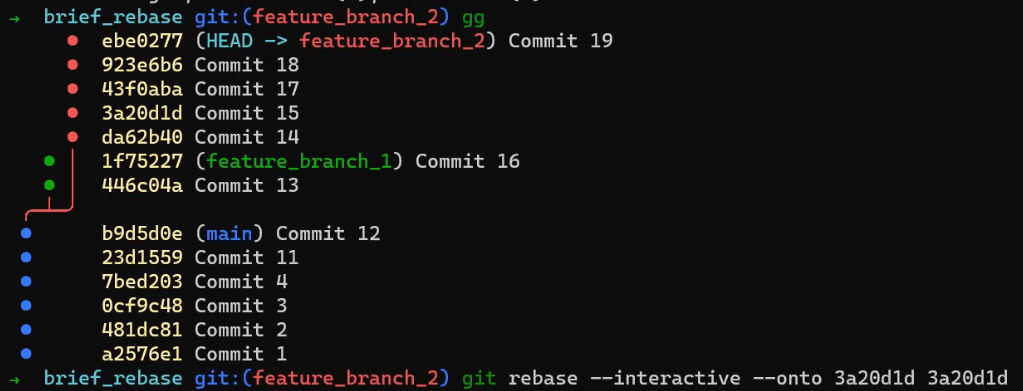 Utilisation de
Utilisation de rebase --onto sur une seule branche
Cela résulte en l'écran suivant :
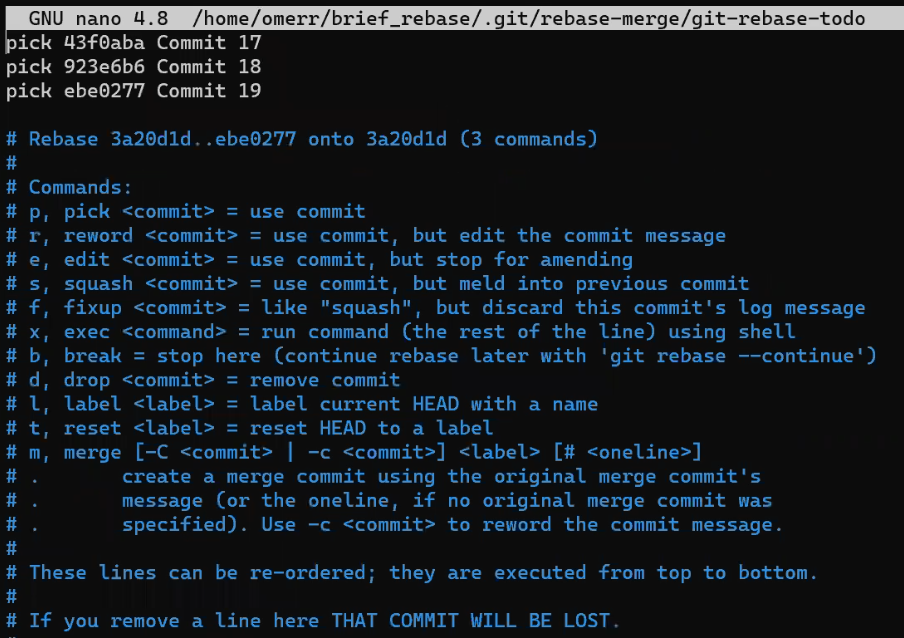 Rebase interactif
Rebase interactif
Alors, que ferais-je ? Je veux mettre "Commit 19" avant "Commit 18", pour qu'il vienne juste après "Commit 17". Je peux aller plus loin et les squash (écraser) ensemble, comme ceci :
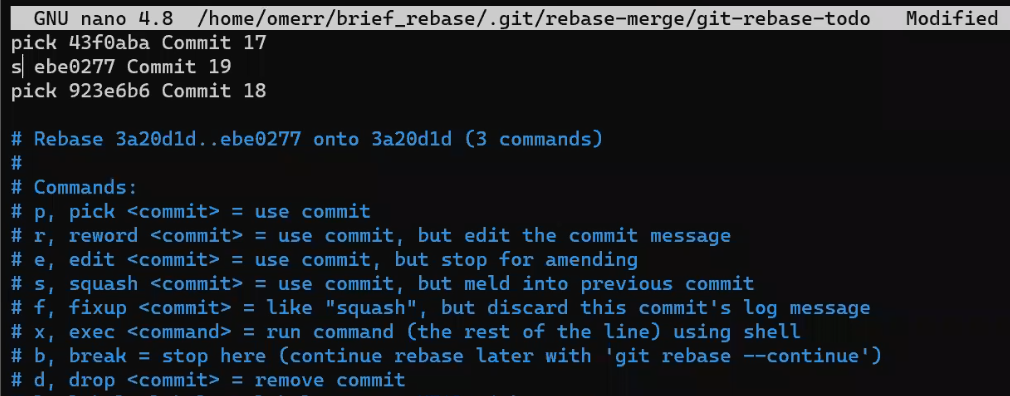 Rebase interactif - changer l'ordre des commits et squasher
Rebase interactif - changer l'ordre des commits et squasher
Maintenant, quand je suis invité à fournir un message de commit, je peux fournir le message "Commit 17+19" :
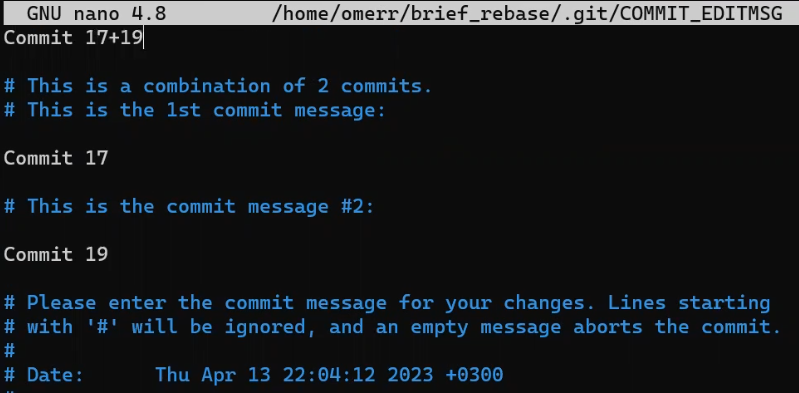 Fournir un message de commit
Fournir un message de commit
Et maintenant, voyez notre bel historique :
 L'historique résultant
L'historique résultant
La syntaxe utilisée ci-dessus, git rebase --interactive --onto <COMMIT X> <COMMIT X> serait la syntaxe la plus couramment utilisée par ceux qui utilisent rebase régulièrement. L'état d'esprit que ces développeurs ont généralement est de créer des commits atomiques tout en travaillant, tout le temps, sans avoir peur de les changer plus tard. Ensuite, avant de pousser leurs changements, ils rebaseraient l'ensemble complet des changements depuis le dernier push, et le réorganiseraient pour que l'historique devienne cohérent.
git reflog
Il est temps de considérer un cas plus surprenant.
Revenez à "Commit 2.4" :
git reset --hard <SHA_OF_COMMIT_2_4>
Faites un peu de travail, écrivez du code, et ajoutez-le à love.txt. Mettez en transit ce changement, et validez-le :
echo lots of work >> love.txt
git add love.txt
git commit -m "Commit 3.2"
(J'utilise "Commit 3.2" pour indiquer que ce n'est pas le même commit que "Commit 3" que nous avons utilisé lors de l'explication de git revert.)
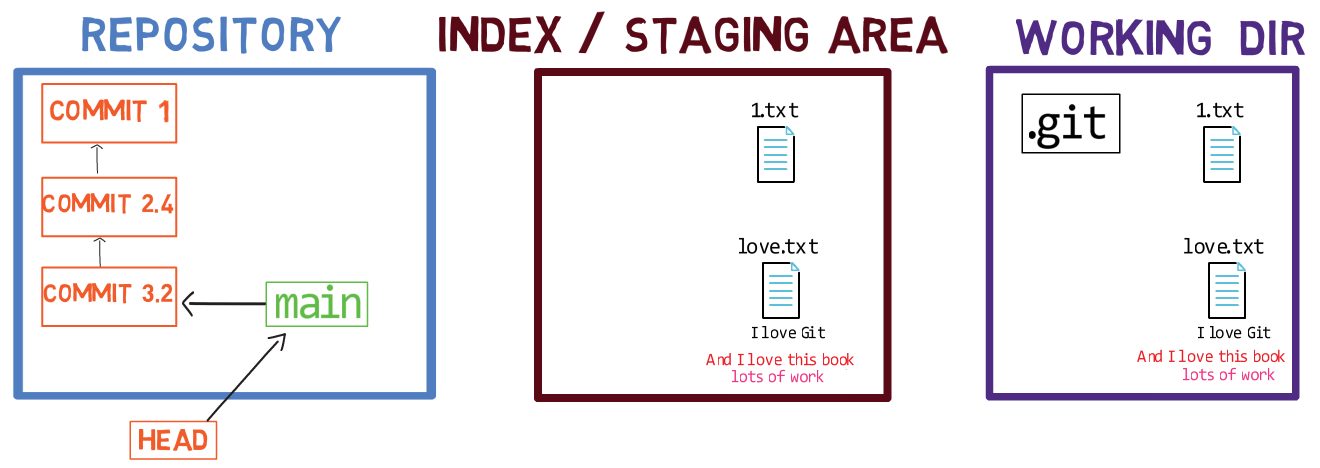 Un autre commit - "Commit 3.2"
Un autre commit - "Commit 3.2"
J'ai fait la même chose sur ma machine, et j'ai utilisé la touche fléchée Haut de mon clavier pour revenir aux commandes précédentes, et puis j'ai appuyé sur Entrée, et… Wow.
Oups.
 Est-ce que je viens de faire
Est-ce que je viens de faire git reset --hard ?
Est-ce que je viens d'utiliser git reset --hard ? 😨
Que s'est-il réellement passé ? Comme vous l'avez appris au chapitre 9, Git a déplacé le pointeur vers HEAD~1, donc le dernier commit, avec tout mon précieux travail, n'est pas accessible depuis l'historique actuel. Git a également supprimé tous les changements de la zone de transit, puis a fait correspondre le répertoire de travail à l'état de la zone de transit.
C'est-à-dire que tout correspond à cet état où mon travail est… parti.
Moment de panique. Je panique.
Mais, vraiment, y a-t-il une raison de paniquer ? Pas vraiment… Nous sommes des gens détendus. Que faisons-nous ? Eh bien, intuitivement, le commit est-il vraiment, vraiment parti ?
Non. Pourquoi pas ? Il existe toujours à l'intérieur de la base de données interne de Git.
Si seulement je savais où c'est, je connaîtrais la valeur SHA-1 qui identifie ce commit, et nous pourrions le restaurer. Je pourrais même annuler l'annulation, et faire un reset pour revenir à ce commit.
En fait, la seule chose dont j'ai vraiment besoin ici est le SHA-1 du commit "supprimé".
Maintenant la question est, comment le trouver ? Est-ce que git log serait utile ?
Eh bien, pas vraiment. git log irait à HEAD, qui pointe vers main, qui pointe vers le commit parent du commit que nous cherchons. Ensuite, git log remonterait à travers la chaîne des parents, qui n'inclut pas le commit avec mon précieux travail.
git log n'aide pas dans ce cas
Heureusement, les gens très intelligents qui ont créé Git ont aussi créé un plan de secours pour nous, et cela s'appelle le reflog.
Pendant que vous travaillez avec Git, chaque fois que vous changez HEAD, ce que vous pouvez faire en utilisant git reset, mais aussi d'autres commandes comme git switch ou git checkout, Git ajoute une entrée au reflog.

git reflog nous montre où était HEAD
Nous avons trouvé notre commit ! C'est celui commençant par 0fb929e.
Nous pouvons aussi nous y référer par son "surnom" - HEAD@{1}. De la même manière que Git utilise HEAD~1 pour accéder au premier parent de HEAD, et HEAD~2 pour faire référence au deuxième parent de HEAD et ainsi de suite, Git utilise HEAD@{1} pour faire référence au premier parent reflog de HEAD, c'est-à-dire là où HEAD pointait à l'étape précédente.
Nous pouvons aussi demander à git rev-parse de nous montrer sa valeur :
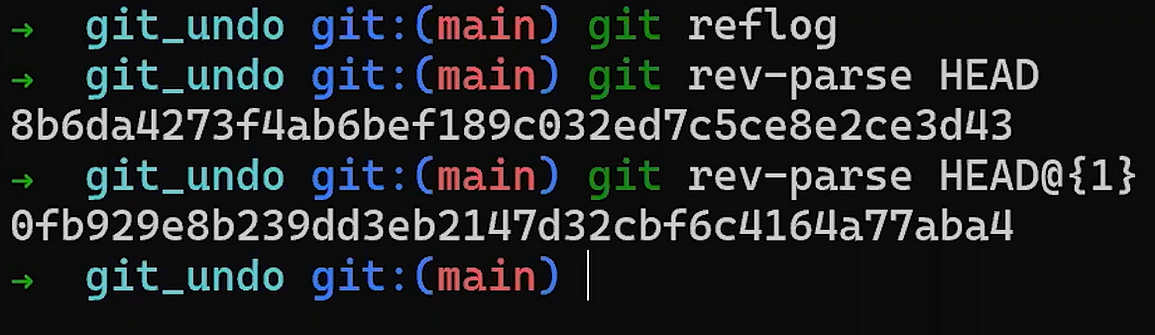 Utilisation de
Utilisation de git rev-parse HEAD@{1}
Note : Au cas où vous utilisez Windows, vous devrez peut-être l'entourer de guillemets - comme ceci :
git rev-parse "HEAD@{1}"
Une autre façon de voir le reflog est d'utiliser git log -g, qui demande à git log de considérer réellement le reflog :
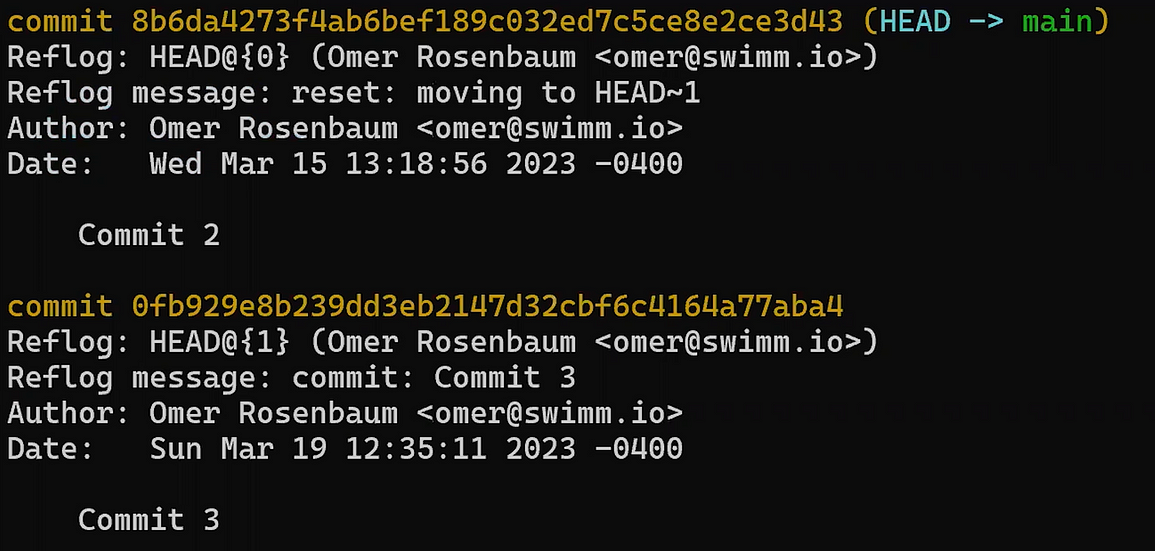 La sortie de
La sortie de git log -g
Vous pouvez voir dans la sortie de git log -g que l'entrée HEAD@{0} du reflog, tout comme HEAD, pointe vers main, qui pointe vers "Commit 2". Mais le parent de cette entrée dans le reflog pointe vers "Commit 3".
Donc pour revenir à "Commit 3", vous pouvez juste utiliser git reset --hard HEAD@{1} (ou la valeur SHA-1 de "Commit 3") :
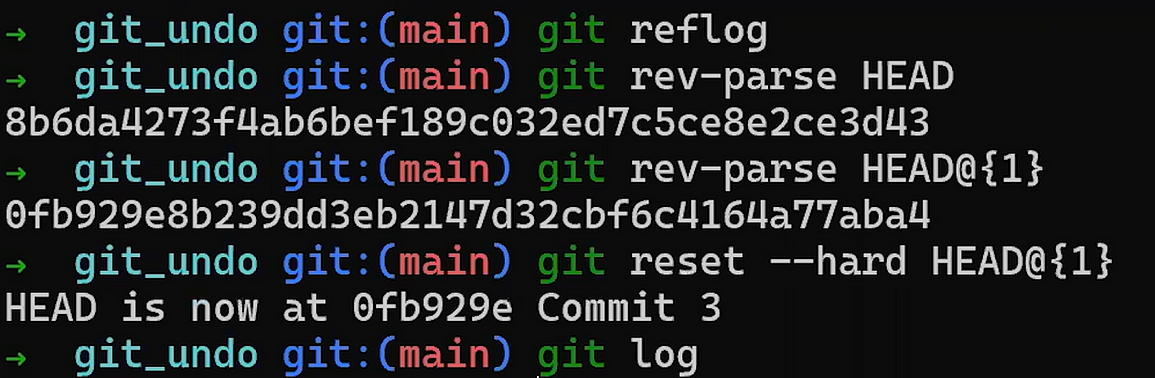
git reset --hard HEAD@{1}
Et maintenant, si vous faites git log :
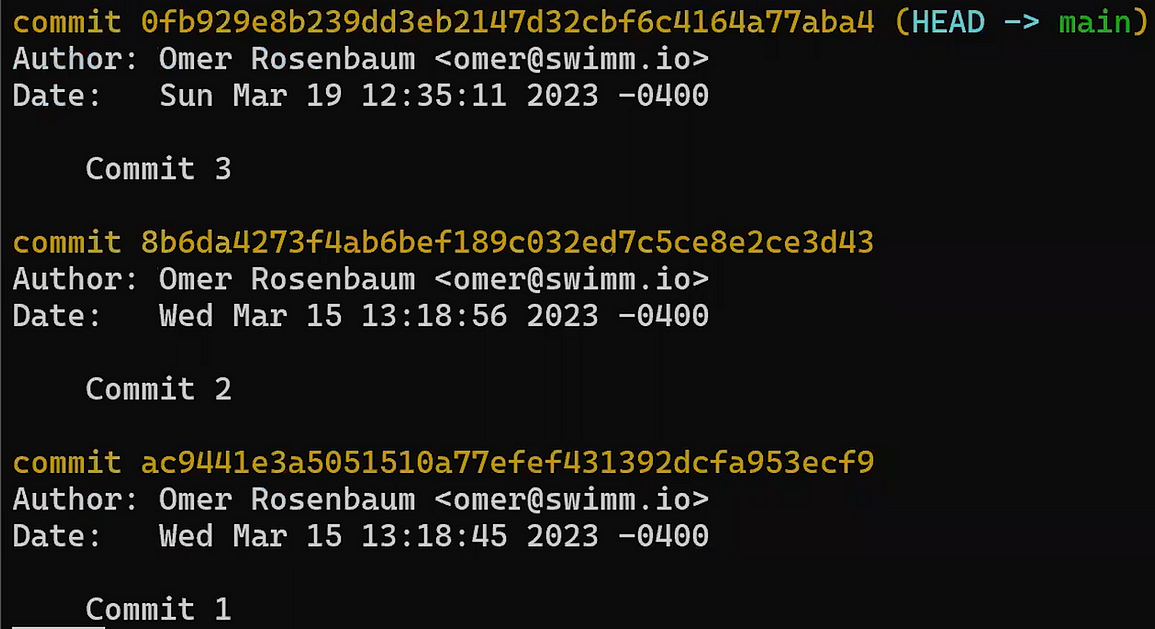 Notre historique est de retour !!!
Notre historique est de retour !!!
Nous avons sauvé la journée !
Que se passerait-il si j'utilisais cette commande à nouveau ? Et exécutais git reset --hard HEAD@{1} ?
Git réglerait HEAD là où HEAD pointait avant le dernier reset, ce qui signifie à "Commit 2". Nous pouvons continuer toute la journée :
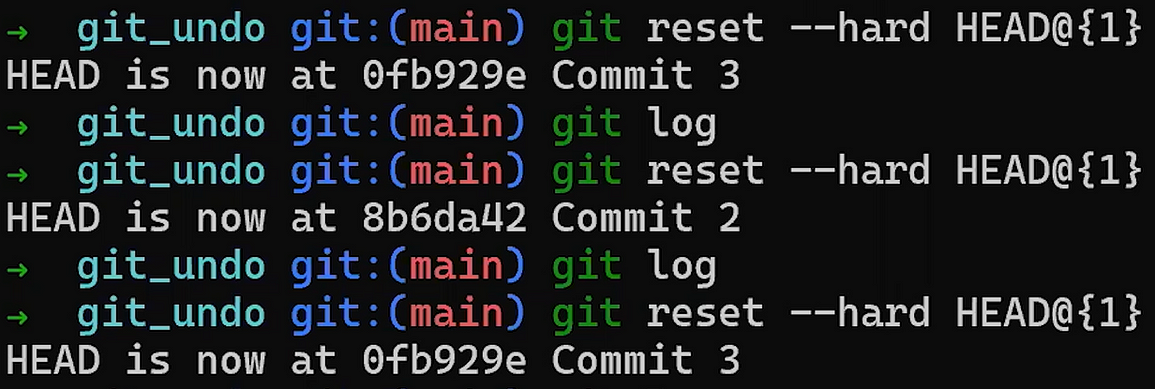
git reset --hard encore
Récapitulatif - Outils supplémentaires pour annuler des changements
Dans le chapitre précédent, vous avez appris comment utiliser git reset pour annuler des changements.
Dans ce chapitre, vous avez étendu votre boîte à outils pour annuler des changements dans Git avec quelques nouvelles commandes :
git commit --amend- qui "écrase" le dernier commit avec l'état de l'index. Surtout utile lorsque vous venez de valider quelque chose et voulez modifier ce dernier commit.git revert- qui crée un nouveau commit, qui inverse un commit passé en ajoutant un nouveau commit à l'historique avec les changements inversés. Utile surtout lorsque le commit "défectueux" a déjà été poussé vers le dépôt distant.git rebase- que vous connaissez déjà du chapitre 8, et qui est utile pour réécrire l'historique de plusieurs commits, surtout avant de les pousser.git reflog(etgit log -g) - qui suit tous les changements deHEAD, afin que vous puissiez trouver la valeur SHA-1 d'un commit auquel vous devez revenir.
L'outil le plus important, encore plus important que les outils que je viens de lister, est de dessiner au tableau blanc la situation actuelle vs la situation désirée. Croyez-moi là-dessus, cela rendra chaque situation moins intimidante et la solution plus claire.
Il y a des outils supplémentaires qui vous permettent d'inverser des changements dans Git (je fournirai des liens dans l'annexe), mais la collection d'outils couverte ici devrait vous préparer à aborder n'importe quel défi avec confiance.
Chapitre 11 - Exercices
Ce chapitre comprend quelques exercices pour approfondir votre compréhension des outils que vous avez appris dans la Partie 3. La version complète de ce livre comprend également des solutions détaillées pour chacun.
Les exercices se trouvent sur ce dépôt :
https://github.com/Omerr/undo-exercises.git
Chaque exercice existe sur une branche avec le nom exercise_XX, donc l'Exercice 1 se trouve sur la branche exercise_01, l'Exercice 2 se trouve sur la branche exercise_02 et ainsi de suite.
Note : Comme expliqué dans les chapitres précédents, si vous travaillez avec des commits qui peuvent être trouvés sur un serveur distant (ce qui est le cas ici, car vous utilisez mon dépôt "undo-exercises"), vous devriez probablement utiliser git revert au lieu de git reset. De même que git rebase, la commande git reset réécrit également l'historique - et vous devriez donc vous abstenir de l'utiliser sur des commits sur lesquels d'autres pourraient avoir compté.
Pour les besoins de ces exercices, vous pouvez supposer que personne d'autre n'a cloné ou tiré le code du dépôt distant. Rappelez-vous simplement - dans la vraie vie, vous devriez probablement utiliser git revert au lieu de commandes qui réécrivent l'historique dans de tels cas.
Exercice 1
Sur la branche exercise_01, considérez le fichier hello.txt :
 Le fichier
Le fichier hello.txt
Ce fichier contient une coquille (dans le dernier caractère). Trouvez le commit qui a introduit cette coquille.
Exercice (1a)
Supprimez ce commit de l'historique accessible en utilisant git reset (avec les bons arguments), corrigez la coquille et validez à nouveau. Considérez votre historique.
Revenez à l'état précédent.
Exercice (1b)
Supprimez le commit défectueux en utilisant git commit --amend, et arrivez au même état de l'historique qu'à la fin de l'exercice (1a).
Revenez à l'état précédent.
Exercice (1c)
revert le commit défectueux en utilisant git revert et corrigez la coquille. Considérez votre historique.
Revenez à l'état précédent.
Exercice (1d)
En utilisant git rebase, arrivez au même état qu'à la fin de l'exercice (1a).
Exercice 2
Passez à exercise_02, et considérez le contenu de exercise_02.txt :
 _Le contenu de
_Le contenu de exercise_02.txt_
Un fichier simple, avec un caractère à chaque ligne.
Considérez l'historique (en utilisant git lol) :
git lol
Oh là là. Chaque caractère a été introduit dans un commit séparé. Cela n'a aucun sens !
Utilisez les outils que vous avez acquis pour créer un historique où la création de exercise_02.txt est entièrement faite en un seul commit.
Exercice 3
Considérez l'historique sur la branche exercise_03 :
 _L'historique sur
_L'historique sur exercise_03_
Cela ressemble à un désordre. Vous remarquerez que :
- L'ordre est biaisé. Nous avons besoin que "Commit 1" soit le commit le plus ancien sur cette branche, et ait "Initial Commit" comme parent, suivi de "Commit 2" et ainsi de suite.
- Nous ne devrions pas avoir "Commit 2a" et "Commit 2b", ou "Commit 4a" et "Commit 4b" - ces deux paires doivent être combinées en un seul commit chacune - "Commit 2" et "Commit 4".
- Il y a une coquille sur le message de commit de "Commit 1", il ne devrait pas avoir 3
m.
Corrigez ces problèmes, mais appuyez-vous sur les changements de chaque commit original. L'historique résultant devrait ressembler à ceci :
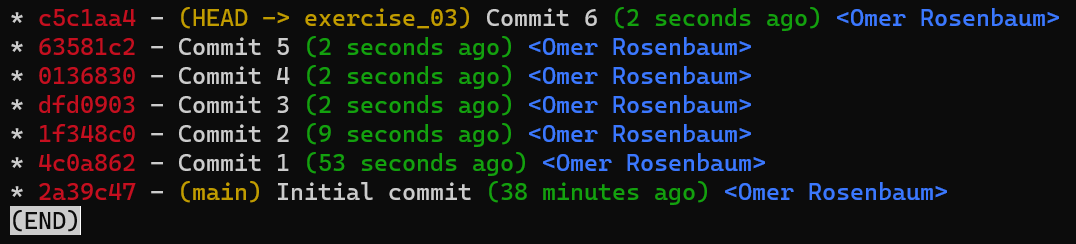 L'historique désiré
L'historique désiré
Exercice 4
Cet exercice consiste en fait en trois branches : exercise_04, exercise_04_a, et exercise_04_b.
Pour voir l'historique de ces branches sans les autres, utilisez la syntaxe suivante :
git lol --branches="exercise_04*"
Le résultat est :
 _La sortie de
_La sortie de git lol --branches="exercise_04*"_
Votre objectif est de rendre exercise_04_b indépendante de exercise_04_a. C'est-à-dire, arriver à cet historique :
 L'historique désiré
L'historique désiré
Bonne chance !
Partie 4 - Outils Git incroyables et utiles
Git a beaucoup de commandes, et ces commandes ont tellement d'options et d'arguments. Je pourrais essayer de toutes les couvrir (bien qu'elles changent avec le temps), mais je ne vois pas l'intérêt. Vous devriez probablement connaître très bien un sous-ensemble de ces commandes, celles que vous utilisez régulièrement. Ensuite, vous pouvez toujours rechercher une commande spécifique pour effectuer une tâche donnée.
Cette partie s'appuie sur les bases que vous avez acquises dans les parties précédentes, et couvre des commandes et options spécifiques que vous pourriez trouver utiles. Étant donné votre compréhension du fonctionnement de Git, avoir ces petits outils peut faire de vous un vrai pro pour Gitting things done.
Chapitre 12 - Git Log
Vous avez utilisé git log de nombreuses fois à travers différents chapitres, et vous l'aviez probablement utilisé de nombreuses fois avant de lire ce livre.
La plupart des développeurs utilisent git log, peu l'utilisent efficacement. Dans ce chapitre, vous apprendrez des ajustements utiles pour tirer le meilleur parti de git log. Une fois que vous vous sentirez à l'aise avec les différentes options de cette commande, cela changera la donne dans votre travail quotidien avec Git.
En y réfléchissant, git log englobe l'essence de tout système de contrôle de version - c'est-à-dire, enregistrer les changements dans les versions. Vous enregistrez les versions pour pouvoir considérer l'historique de votre projet - peut-être inverser ou appliquer des changements spécifiques, préférer passer à un autre point dans le temps et tester des choses là-bas. Peut-être aimeriez-vous savoir qui a contribué à un certain morceau de code ou quand ils l'ont fait.
Bien que git préserve ces informations en utilisant des objets commit, qui pointent également vers leurs commits parents, et des références aux objets commit (telles que les branches ou HEAD), ce stockage de versions n'est pas suffisant. Sans être capable de trouver le commit pertinent que vous aimeriez considérer, ou de rassembler les informations pertinentes à son sujet, avoir ces données stockées est assez inutile.
Vous pouvez penser à vos objets commit comme à différents livres qui s'empilent dans une énorme pile, ou dans une bibliothèque, remplissant de longues étagères. Les informations dont vous pourriez avoir besoin sont dans ces livres, mais si vous n'avez pas d'index - un moyen de savoir dans quel livre l'information que vous cherchez se trouve, ou où ce livre est situé dans la bibliothèque - vous ne seriez pas capable d'en faire grand usage. git log est cette indexation de votre bibliothèque - c'est un moyen de trouver les commits pertinents et les informations à leur sujet.
Les arguments utiles pour git log que vous apprendrez dans ce chapitre formatent la façon dont les commits sont affichés dans le journal, ou filtrent des commits spécifiques.
git lol, un alias que j'ai utilisé tout au long du livre, utilise certaines de ces options, comme je le démontrerai. N'hésitez pas à modifier cet alias (ou à en créer un autre à partir de zéro) après avoir lu ce chapitre.
Comme dans les autres chapitres, le but n'est pas de fournir une référence complète, donc je ne fournirai pas toutes les différentes options de git log. Je me concentrerai sur les options que je pense que vous trouverez utiles.
Filtrer les Commits
Considérez la sortie par défaut de git log :
 La sortie de
La sortie de git log sans options supplémentaires
Le journal commence à HEAD, et suit la chaîne des parents.
Commits (Non) Accessibles Depuis...
Lorsque vous écrivez git log <revision>, git log inclura toutes les entrées accessibles depuis <revision>. Par "accessible", je fais référence à accessible en suivant la chaîne des parents. Donc exécuter git log sans aucun argument est équivalent à exécuter git log HEAD.
Vous pouvez spécifier plusieurs révisions pour git log - si vous écrivez git log branch_1 branch_2, vous demandez à git log d'inclure chaque commit qui est accessible depuis branch_1 ou branch_2 (ou les deux).
git log exclura tous les commits qui sont accessibles depuis des révisions précédées d'un ^.
Par exemple, la commande suivante :
git log branch_1 ^branch_2
demande à git log d'inclure chaque commit qui est accessible depuis branch_1, mais pas ceux accessibles depuis branch_2.
Considérez l'historique quand j'utilise git log feature_branch_1 sur ce repo :
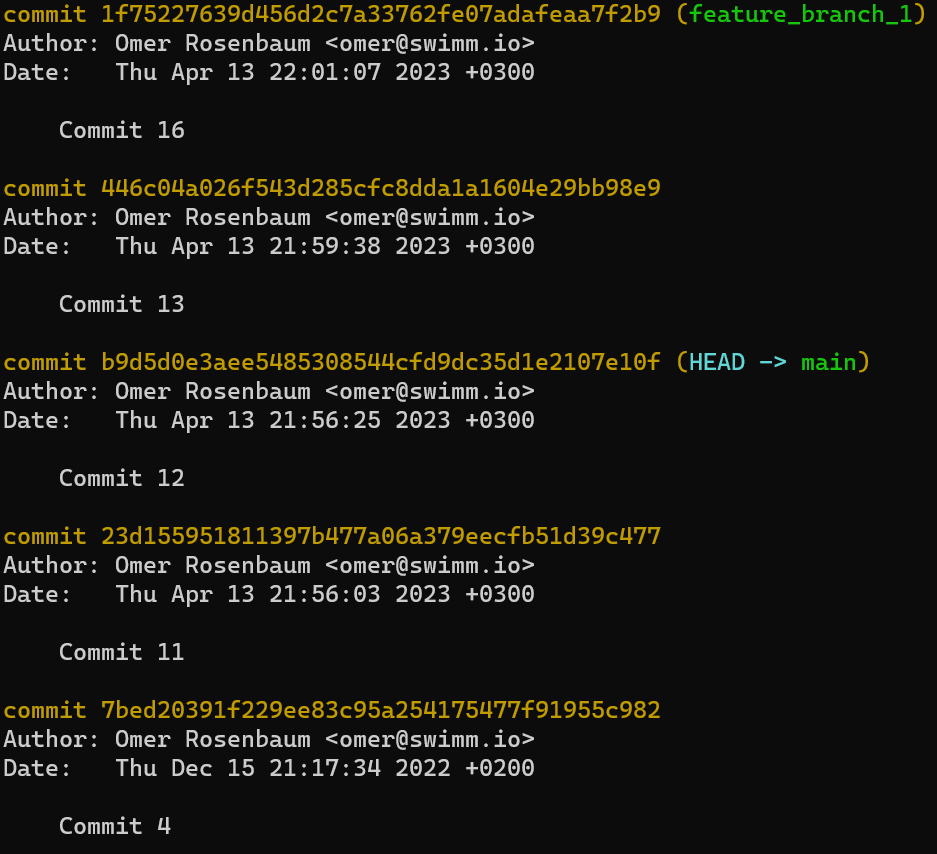 _
_git log feature_branch_1_
L'historique inclut tous les commits accessibles par feature_branch_1. Puisque cette branche "a bifurqué" de main (c'est-à-dire que "Commit 12", vers lequel main pointe, est accessible depuis la chaîne des parents) - le journal inclut également les commits accessibles depuis main.
Que se passerait-il si j'exécutais cette commande ?
git log feature_branch_1 ^main
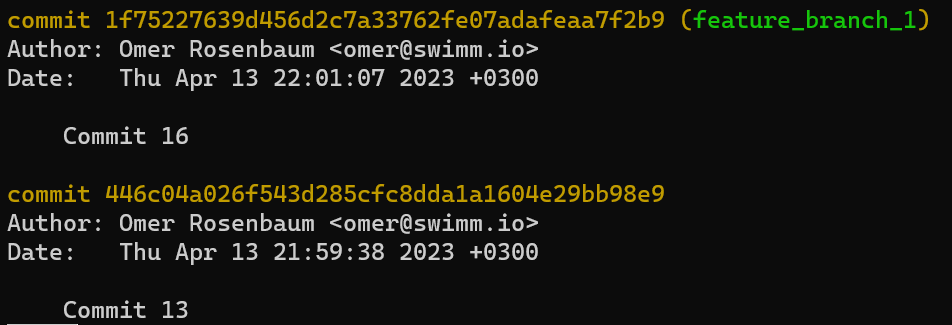 _
_git log feature_branch_1 ^main_
En effet, git log ne sort que "Commit 13" et "Commit 16", qui sont accessibles depuis feature_branch_1 mais pas depuis main.
git log --all
Pour suivre les commits qui sont accessibles depuis n'importe quelle référence nommée ou (toute ref dans refs/) ou HEAD.
Par Auteur
Si vous savez que vous cherchez un commit qu'une personne spécifique a créé, vous pouvez filtrer ces commits en utilisant le nom ou l'email de cet utilisateur, comme ceci :
git log --author="Name"
Vous pouvez utiliser des expressions régulières pour rechercher des noms d'auteur qui correspondent à un motif spécifique, par exemple :
git log --author="John\|Jane"
filtrera les commits créés par John ou Jane.
Par Date
Lorsque vous savez que le changement que vous cherchez a été validé dans un laps de temps spécifique, vous pouvez utiliser --before ou --after pour filtrer les commits de ce laps de temps.
Par exemple, pour obtenir tous les commits introduits après le 12 avril 2023 (inclus), utilisez :
git log --after="2023-04-12"
Par Chemins
Vous pouvez demander à git log de ne montrer que les commits où des changements à des fichiers dans des chemins spécifiques ont été introduits. Remarquez que cela ne signifie pas tout commit qui pointe vers un arbre qui inclut les fichiers en question, mais plutôt que si nous calculons la différence entre le commit en question et son parent, nous verrions qu'au moins l'un des chemins a été modifié.
Par exemple, vous pouvez utiliser :
git log --all -- 1.py
pour trouver tous les commits qui sont accessibles depuis n'importe quel pointeur nommé, ou HEAD, et introduisent un changement à 1.py. Vous pouvez spécifier plusieurs chemins :
git log --all -- 1.py 2.py
La commande précédente fera en sorte que git log inclue les commits accessibles qui ont introduit un changement à 1.py ou 2.py (ou les deux).
Vous pouvez aussi utiliser un motif glob, par exemple :
git log -- *.py
inclura les commits accessibles depuis HEAD qui incluent un changement à tout fichier dans le répertoire racine dont le nom se termine par .py. Pour chercher tout fichier dont le nom se termine par .py, vous pouvez utiliser :
git log -- **/*.py
Par Message de Commit
Si vous connaissez le message de commit (ou des parties de celui-ci) du commit que vous recherchez, vous pouvez utiliser l'option --grep pour "git log", par exemple :
git log --grep="Commit 12"
renvoie le commit avec le message "Commit 12".
Par Contenu de Diff
Celui-ci est super utile, et il m'a sauvé un nombre incalculable de fois. En utilisant git log -S, vous pouvez rechercher des commits qui introduisent ou suppriment une ligne particulière de code source.
Cela s'avère utile, par exemple, lorsque vous savez que vous avez créé quelque chose dans le repo, mais vous ne savez pas où c'est maintenant. Vous ne pouvez le trouver nulle part sur votre système de fichiers (ce n'est pas dans HEAD), et vous savez qu'il doit être là - tapi quelque part dans cette bibliothèque (tas de commits) que vous avez.
Disons que je me souviens avoir écrit une ligne avec le texte Git is awesome, mais je ne peux pas la trouver maintenant. Je pourrais exécuter :
git log --all -S"Git is awesome"
Remarquez que j'ai utilisé --all pour éviter de me restreindre aux commits accessibles depuis HEAD.
Vous pouvez aussi rechercher une expression régulière, en utilisant -G :
git log --all -G"Git .* awesome"
Formater le Journal
Considérez la sortie par défaut de git log à nouveau :
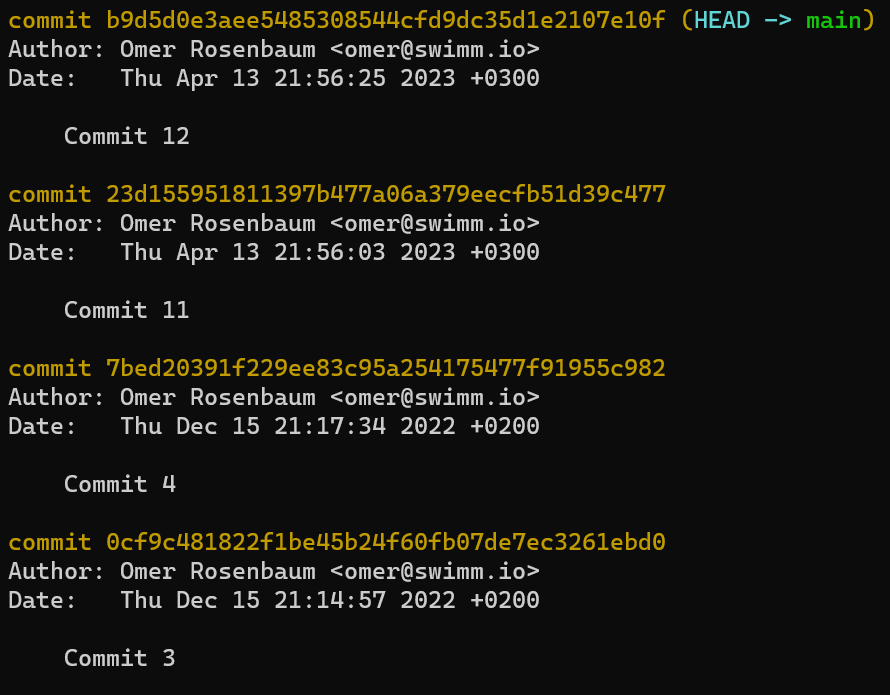 La sortie de
La sortie de git log sans options supplémentaires
Le journal commence à HEAD, et suit la chaîne des parents.
Chaque entrée de journal commence par une ligne commençant par commit et ensuite le SHA-1 du commit, peut-être suivi de pointeurs supplémentaires qui pointent vers ce commit.
Elle est ensuite suivie par l'auteur, la date et le message de commit.
--oneline
La principale difficulté avec la sortie par défaut de git log est qu'il est difficile de comprendre un historique avec plus de quelques commits, car vous ne les voyez tout simplement pas tous.
Dans la sortie de git log montrée avant, seuls quatre objets commit sont apparus sur mon écran. Utiliser git log --oneline fournit une vue plus concise, montrant le SHA-1 du commit, à côté de son message, et des références nommées si pertinent :
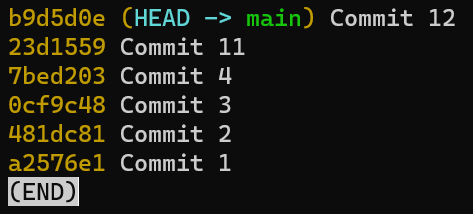 La sortie de
La sortie de git log --oneline
Si vous souhaitez omettre les références nommées, vous pouvez ajouter l'option --no-decorate :
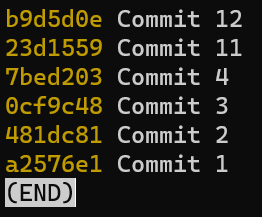 La sortie de
La sortie de git log --oneline --no-decorate
Pour demander explicitement à git log de montrer les décorations, vous pouvez utiliser git log --decorate.
--graph
git log --oneline montre une représentation compacte. C'est génial quand nous avons un historique linéaire, peut-être sur une seule branche. Mais que se passe-t-il quand nous avons plusieurs branches, qui peuvent diverger les unes des autres ?
Considérez la sortie de la commande suivante sur mon dépôt :
git log --oneline feature_branch_1 feature_branch_2
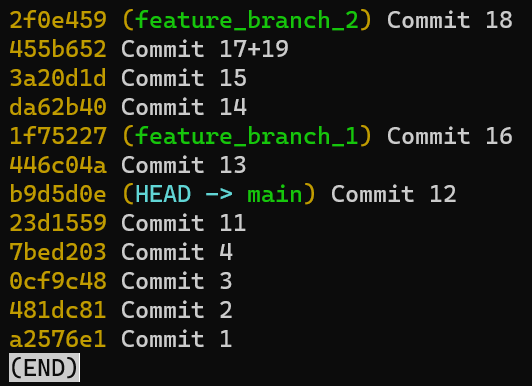 _La sortie de
_La sortie de git log --oneline feature_branch_1 feature_branch_2_
git log sort tout commit accessible par feature_branch_1, feature_branch_2, ou les deux. Mais à quoi ressemble l'historique ? Est-ce que feature_branch_2 a divergé de feature_branch_1 ? Ou a-t-il divergé de main ? Il est impossible de le dire à partir de cette vue.
C'est là que --graph s'avère utile, dessinant un graphique ASCII représentant la structure de branche de l'historique des commits. Si nous ajoutons cette option à la commande précédente :
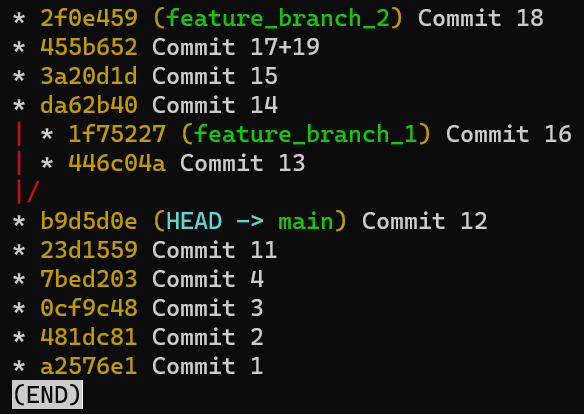 _La sortie de
_La sortie de git log --oneline --graph feature_branch_1 feature_branch_2_
Vous pouvez réellement voir que feature_branch_1 a branché depuis main (car "Commit 12", main, est le parent de "Commit 13"), et aussi que feature_branch_2 a branché depuis main (car le parent de "Commit 14" est aussi "Commit 12").
Le symbole * nous dit sur quelle branche un certain commit se trouve, donc vous pouvez savoir avec certitude que "Commit 13" est sur feature_branch_1, et pas feature_branch_2.
--pretty=format
Le résultat ci-dessus est déjà très utile ! Pourtant, il manque quelques choses. Nous ne connaissons pas l'auteur ou l'heure du commit. Ces deux détails d'information étaient inclus dans la sortie par défaut de git log qui était très longue. Peut-être pouvons-nous les ajouter de manière plus compacte ?
En utilisant --pretty=format:, vous pouvez afficher les informations de chaque commit de diverses manières en utilisant des espaces réservés de style printf.
Dans la commande suivante, les espaces réservés %s, %an et %cd sont remplacés par le sujet (message) du commit, le nom de l'auteur et la date du commit, respectivement.
git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s (%an) [%cd]"
La sortie ressemble à ceci :
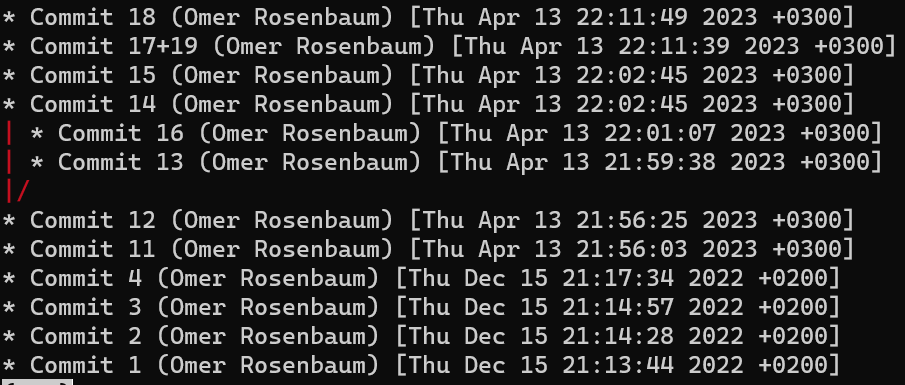 _
_git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s (%an) [%cd]_
C'est utile, mais pas vraiment génial à regarder. Nous pouvons ensuite utiliser d'autres astuces de formatage, spécifiquement %C(color) qui changera la couleur en color, jusqu'à atteindre un %Creset qui réinitialise la couleur. Pour rendre le nom de l'auteur jaune, vous pouvez utiliser :
git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s %C(yellow)(%an)%Creset [%cd]"
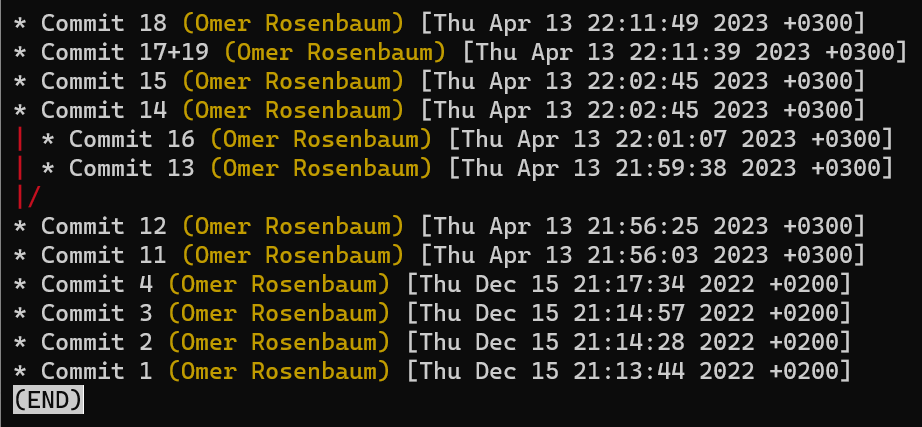 _
_git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s %C(yellow)(%an)%Creset [%cd]"_
Pour certaines couleurs, comme red ou green, il est inutile d'inclure les parenthèses, donc Cred suffit.
Comment git lol est-il structuré ?
Quand j'exécute git lol, cela exécute en fait ce qui suit :
git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit
Pouvez-vous prendre cela petit à petit ?
Vous connaissez déjà --graph, qui fait en sorte que la sortie inclut un graphique ASCII.
--abbrev-commit utilise un préfixe court du SHA-1 complet du commit (dans ma configuration, les sept premiers caractères).
Le reste est juste de la coloration de divers détails sur le commit :
git lol --all
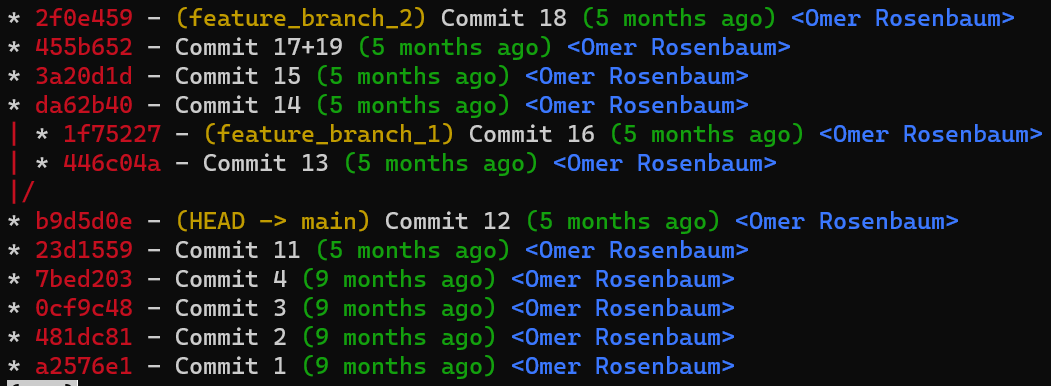
git lol --all
J'aime cette sortie car je la trouve claire. Elle me donne les informations dont j'ai besoin, avec suffisamment de coloration pour que chaque détail ressorte sans me faire mal aux yeux. Mais si vous préférez d'autres informations, d'autres couleurs, un ordre différent, ou toute autre chose - allez-y et ajustez-le à votre goût.
Définir un alias
Comme vous le savez, j'ai défini git lol comme un alias - c'est-à-dire, quand j'exécute git lol, cela exécute la longue commande que j'ai fournie précédemment.
Comment pouvez-vous créer un alias dans Git ?
Le moyen le plus simple est d'utiliser git alias, comme ceci :
git config --global alias.co checkout
Cette commande définit co comme un alias pour la commande checkout, vous pouvez donc utiliser git co main au lieu de git checkout main.
Pour définir git lol comme un alias, vous pouvez utiliser :
git config --global alias.lol 'log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit'
Chapitre 13 - Git Bisect
Oups.
J'ai un bug.
Oui, cela arrive parfois, à nous tous. Quelque chose dans mon système est cassé, et je ne peux pas dire pourquoi. Je débogue depuis un moment, mais la solution n'est pas claire.
Je peux dire qu'il y a deux semaines, cela ne se produisait pas. Heureusement pour moi, j'utilise Git (évidemment, je sais...), donc je peux remonter le temps et tester une version passée de mon code. En effet, dans cette version - tout fonctionnait bien.
Mais... J'ai fait de nombreux changements au cours de ces deux semaines. Hélas, pas seulement moi - toute mon équipe a contribué des commits qui ajoutent, suppriment ou modifient des parties de la base de code. Par où commencer ? Dois-je passer en revue chaque changement introduit au cours de ces deux semaines ?
Entrez - git bisect.
Le but de git bisect est de vous aider à trouver le commit où un bug a été introduit, de manière efficace.
Comment fonctionne git bisect ?
git bisect vous demande d'abord de marquer un commit comme "bad" (mauvais, où le bug se produit), et un autre commit comme "good" (bon, sans le bug). Ensuite, il fait un checkout d'un commit à mi-chemin entre ces deux commits, et vous demande ensuite d'identifier le commit comme "good" ou "bad". Ce processus est répété jusqu'à ce que vous trouviez le premier commit "bad".
La clé ici est l'utilisation de la recherche binaire - en regardant le point médian et en décidant s'il s'agit du nouveau sommet ou du nouveau bas de la liste des commits, vous pouvez trouver le bon commit efficacement. Même si vous avez 10 000 commits à parcourir, cela ne prend qu'un maximum de 13 étapes pour trouver le premier commit qui a introduit le bug.
Exemple git bisect
Pour cet exemple, j'utiliserai le dépôt sur https://github.com/Omerr/bisect-exercise.git. Pour le créer, j'ai adapté le dépôt open source https://github.com/bast/git-bisect-exercise (selon sa licence).
Dans ce dépôt, nous avons un seul fichier python qui est utilisé pour calculer la valeur de pi (qui est approximativement 3.14). Si vous exécutez python3 get_pi.py sur main, cependant, vous obtiendrez un mauvais résultat :
 Un mauvais résultat, nous avons un bug
Un mauvais résultat, nous avons un bug
Cette branche consiste en plus de 500 commits.
Trouvez le premier commit sur cette branche en utilisant :
git log --oneline | tail -n 1

git log --oneline | tail -n 1
Si vous faites un checkout vers ce commit et exécutez python3 get_pi.py à nouveau, le résultat est correct :
 Depuis le premier commit, le résultat est valide
Depuis le premier commit, le résultat est valide
Donc quelque part entre HEAD et le commit f0ea950, un changement a été introduit qui a abouti à cette mauvaise sortie.
Pour le trouver en utilisant git bisect, démarrez (start) le processus bisect, et marquez ce commit comme "good" :
git bisect start
git bisect good
Par défaut, git bisect good prendrait HEAD comme le "bon" commit. Pour marquer main comme "bad", vous pouvez utiliser git bisect bad main :

git bisect bad main
git bisect a fait un checkout du commit numéro 251, le "point médian" de la branche main. Est-ce que l'état dans ce commit produit la bonne ou la mauvaise sortie ?
 Essayer à nouveau...
Essayer à nouveau...
Nous obtenons toujours la mauvaise sortie, ce qui signifie que nous pouvons écarter les commits 252 à 500 (et les commits supplémentaires après cela), et restreindre notre recherche aux commits 2 à 251. Marquez ceci comme bad :
 Marquer comme
Marquer comme bad
git bisect a fait un checkout du commit "médian" (numéro 126), et en exécutant le code à nouveau, on obtient la bonne réponse ! Cela signifie que ce commit est "good", et que le premier commit "bad" est quelque part entre 127 et 251. Marquez-le comme "good" :
 Marquer comme
Marquer comme good
Sympa, git bisect nous emmène au commit 188, car c'est le commit "médian" entre 127 et 251. En exécutant le code à nouveau, vous pouvez voir que le résultat est faux, donc c'est en fait un commit "bad", ce qui signifie que le premier commit défectueux est quelque part entre 127 et 188. Comme vous pouvez le voir, git bisect réduit l'espace de recherche de moitié à chaque itération.
Allez, maintenant c'est à votre tour - continuez à partir d'ici ! Testez le résultat de python3 get_pi.py et utilisez git bisect good ou git bisect bad pour marquer le commit en conséquence. Quel est le commit défectueux ?
Lorsque vous avez terminé, utilisez git bisect reset pour arrêter le processus bisect.
git bisect automatique
Dans l'exemple précédent, vous pouviez simplement exécuter python3 get_pi.py et vérifier le résultat. D'autres fois, le processus de validation de savoir si un certain commit est "good" ou "bad" peut être délicat, sujet aux erreurs, ou simplement chronophage.
Il est possible d'automatiser le processus de git bisect en créant du code qui serait exécuté à chaque itération, retournant 0 quand le commit actuel est "good", et une valeur entre 1-127 (inclus), sauf 125, s'il doit être considéré comme "bad".
La syntaxe est :
git bisect run my_script arguments
Comme ce livre n'est pas sur la programmation et ne suppose pas que vous connaissiez un langage de programmation spécifique, je ne montrerai pas d'exemple d'implémentation de my_script. Le fichier README.md dans le dépôt utilisé dans ce chapitre (https://github.com/Omerr/bisect-exercise.git) inclut un exemple de script que vous pouvez exécuter avec git bisect run pour trouver automatiquement le commit défectueux pour l'exemple précédent.
Chapitre 14 - Autres commandes utiles
Ce chapitre met en évidence quelques commandes qui ont déjà été mentionnées dans les chapitres précédents. Je les mets ici ensemble pour que vous puissiez y revenir comme référence en cas de besoin.
git cherry-pick
Introduite au chapitre 8, cette commande prend un commit donné, calcule le patch que ce commit introduit en calculant la différence entre le commit parent et le commit lui-même, et ensuite cherry-pick "rejoue" cette différence. C'est comme "copier-coller" un commit, c'est-à-dire le diff que ce commit a introduit.
Au chapitre 8, nous avons considéré la différence introduite par "Commit 5" (en utilisant git diff main <SHA_OF_COMMIT_5>) :
 Exécution de
Exécution de git diff pour observer le patch introduit par "Commit 5"
Vous pouvez voir que dans ce commit, John a commencé à travailler sur une chanson appelée "Lucy in the Sky with Diamonds" :
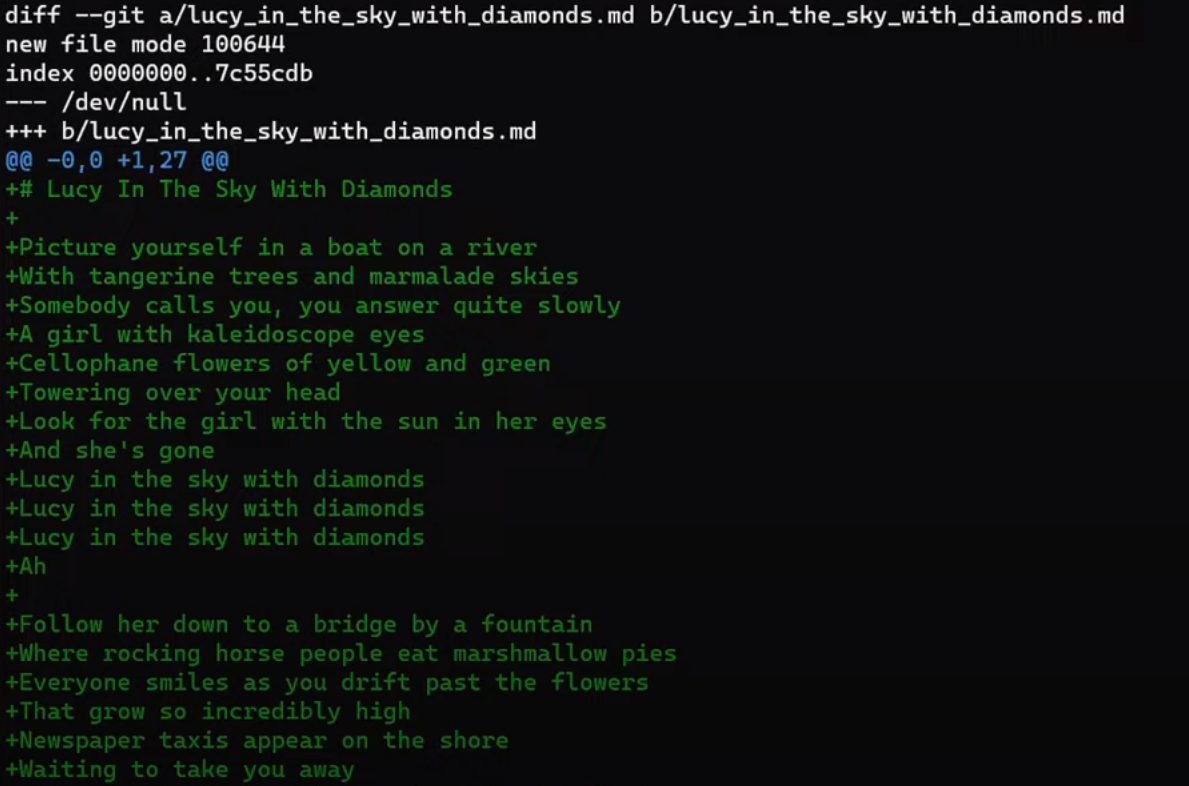 La sortie de
La sortie de git diff - le patch introduit par "Commit 5"
Pour rappel, vous pouvez également utiliser la commande git show pour obtenir la même sortie :
git show <SHA_OF_COMMIT_5>
Maintenant, si vous faites un cherry-pick de ce commit, vous introduirez ce changement spécifiquement, sur la branche active. Vous pouvez passer à la branche main :
git checkout main (ou git switch main)
Et créer une autre branche :
git checkout -b my_branch (ou git switch -c my_branch)
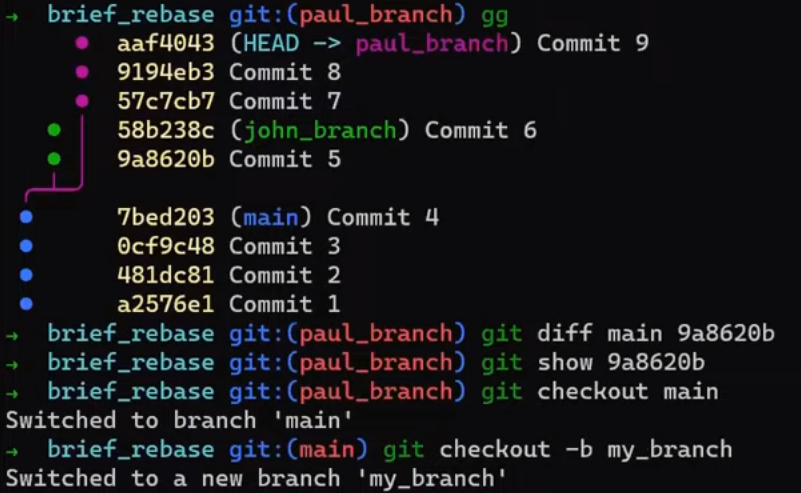 _Création de
_Création de my_branch qui branche depuis main_
Ensuite, faites un cherry-pick de "Commit 5" :
git cherry-pick <SHA_OF_COMMIT_5>
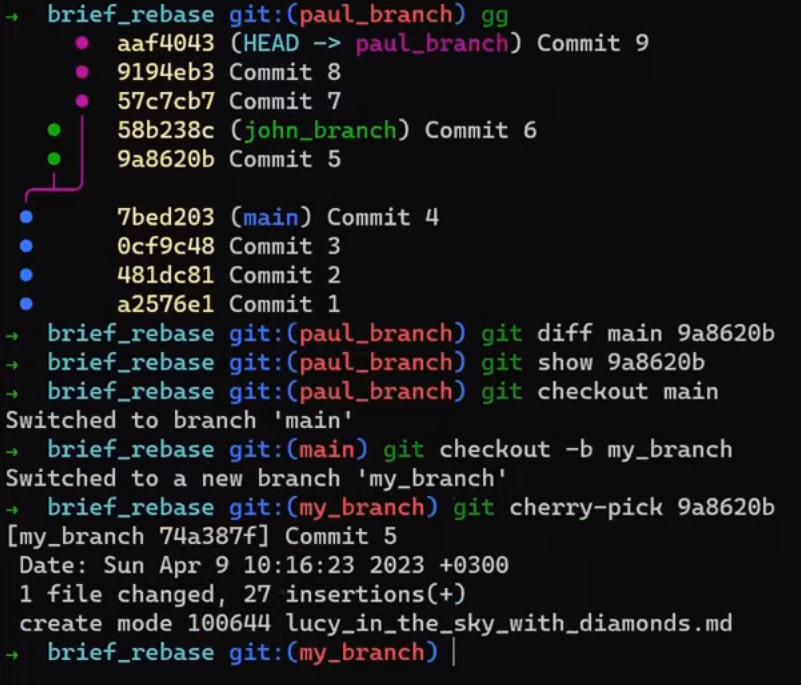 Utiliser
Utiliser cherry-pick pour appliquer les changements introduits dans "Commit 5" sur main
Considérez le journal (sortie de git lol) :
 La sortie de
La sortie de git lol
Il semble que vous ayez copié-collé "Commit 5". Rappelez-vous que même s'il a le même message de commit, et introduit les mêmes changements, et pointe même vers le même objet arbre que le "Commit 5" original dans ce cas - c'est toujours un objet commit différent, car il a été créé avec un horodatage différent.
En regardant les changements, en utilisant git show HEAD :
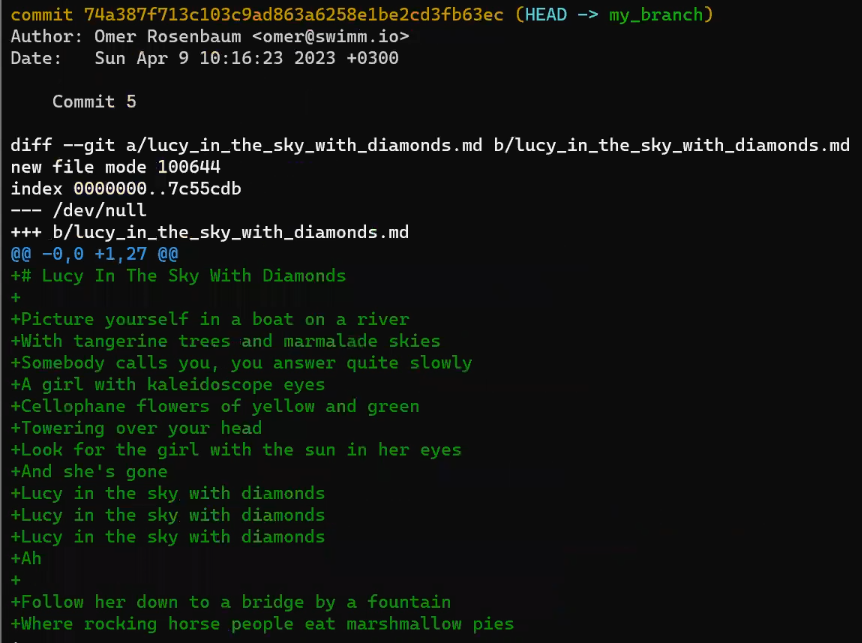 La sortie de
La sortie de git show HEAD
Ils sont les mêmes que ceux de "Commit 5".
git revert
git revert est essentiellement l'inverse de git cherry-pick, introduit au chapitre 10. Cette commande prend le commit que vous lui fournissez et calcule le diff par rapport à son commit parent, tout comme git cherry-pick, mais cette fois, elle calcule les changements inverses. C'est-à-dire que si dans le commit spécifié vous avez ajouté une ligne, l'inverse supprimerait la ligne, et vice versa.
git add -p
Mettre en transit des changements est une partie intégrante de l'introduction de changements dans Git. Parfois, vous souhaitez mettre en transit tous les changements ensemble (avec git add .), ou peut-être mettre en transit tous les changements d'un fichier spécifique (en utilisant git add <file_path>). Pourtant, il y a des moments où il serait pratique de ne mettre en transit que certaines parties des fichiers modifiés.
Au chapitre 6, nous avons introduit git add -p. Cette commande vous permet de mettre en transit certaines parties de fichiers, en les divisant en morceaux (p signifie patch). Par exemple, disons que vous avez ce fichier, my_file.py :
 _
_my_file.py_
Vous modifiez ensuite ce fichier - en changeant du texte dans function_1, et aussi en ajoutant une nouvelle fonction, function_5 :
 _
_my_file.py après les changements_
Si vous utilisiez git add my_file.py à ce stade, vous mettriez en transit ces deux changements ensemble. Au cas où vous voudriez les séparer dans des commits différents, vous pourriez utiliser git add -p, qui divise ces deux changements et vous interroge sur chacun d'eux comme un morceau autonome :
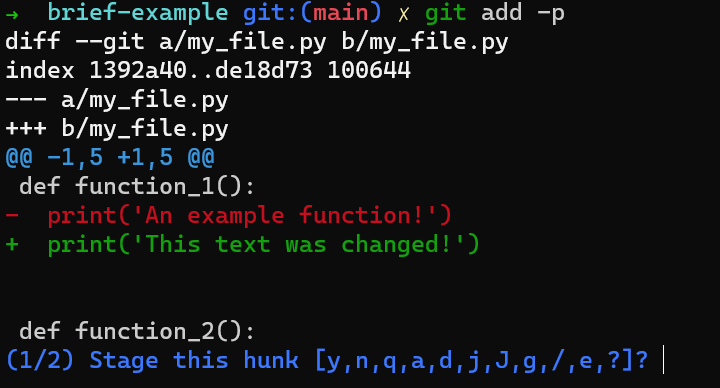
git add -p
En tapant ?, vous pouvez voir ce que les différentes options signifient :
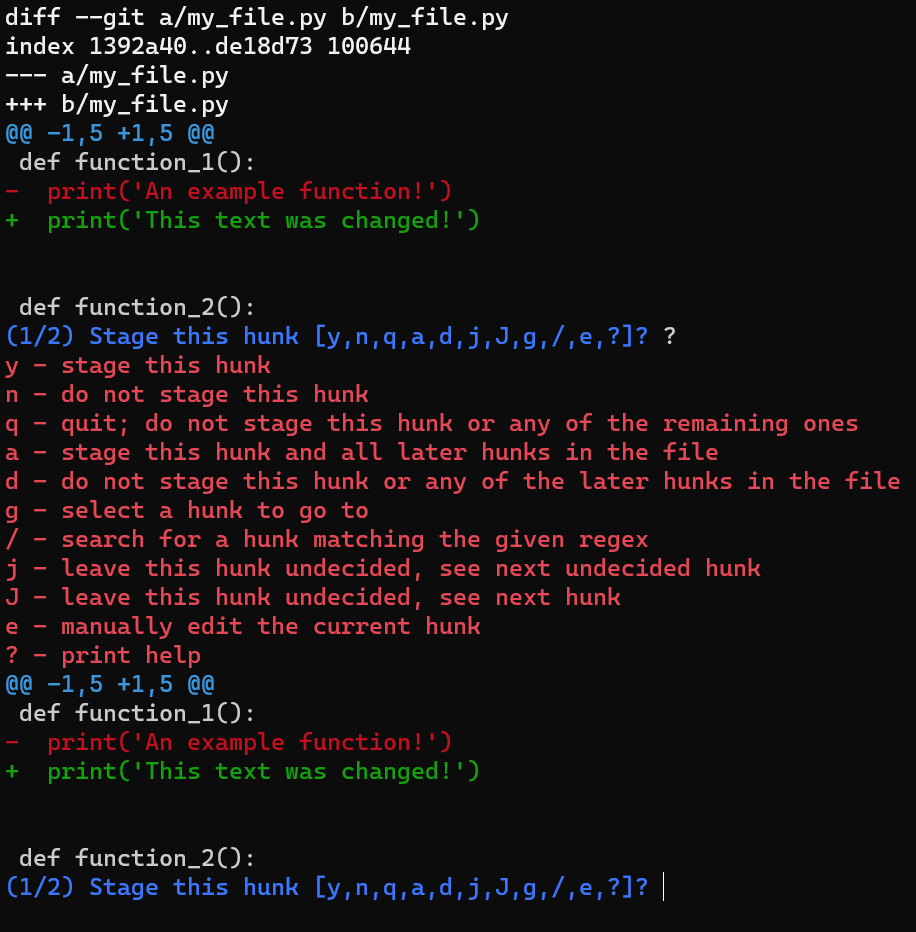 Utiliser un
Utiliser un ? pour obtenir une description des différentes options
Dans ce cas, disons que nous voulons seulement mettre en transit le changement introduisant function_5. Nous ne voulons pas mettre en transit le changement de function_1, donc nous sélectionnons n :
 _Ne pas mettre en transit le changement de
_Ne pas mettre en transit le changement de function_1_
Ensuite, nous sommes invités pour le deuxième changement - celui introduisant function_5. Nous voulons mettre en transit ce morceau en effet, pour ce faire nous pouvons taper y.
Résumé
Eh bien, c'était FUN !
Pouvez-vous croire à quel point vous avez appris ?
Dans la Partie 1, vous avez appris à propos des — blobs, arbres et commits.
Vous avez ensuite appris à propos des branches, voyant qu'elles ne sont rien d'autre qu'une référence nommée à un commit.
Vous avez appris le processus d'enregistrement des changements dans Git, et qu'il implique le répertoire de travail, la zone de transit (index) et le dépôt.
Ensuite - vous avez créé un nouveau dépôt à partir de zéro, en utilisant echo et des commandes de bas niveau telles que git hash-object. Vous avez créé un blob, un arbre et un objet commit pointant vers cet arbre.
Dans la Partie 2, vous avez appris à brancher et à intégrer des changements dans Git.
Vous avez appris ce qu'est un diff, et la différence entre un diff et un patch. Vous avez également appris comment la sortie de git diff est construite.
Ensuite, vous avez eu un aperçu complet de la fusion avec Git, en comprenant spécifiquement l'algorithme de fusion à trois voies. Vous avez compris quand les conflits de fusion se produisent, quand Git peut les résoudre automatiquement, et comment les résoudre manuellement si nécessaire.
Vous avez vu que git rebase est puissant - mais aussi qu'il est assez simple une fois que vous comprenez ce qu'il fait. Vous avez compris les différences entre la fusion et le rebasage, et quand vous devriez utiliser chacun.
Dans la Partie 3, vous avez appris comment annuler des changements dans Git - surtout quand les choses tournent mal. Vous avez appris comment utiliser un tas d'outils, comme git reset, git commit --amend, git revert, git reflog (et git log -g).
L'outil le plus important, encore plus important que les outils que je viens de lister, est de dessiner au tableau blanc la situation actuelle vs la situation désirée. Croyez-moi là-dessus, cela rendra chaque situation moins intimidante et la solution plus claire.
Dans la Partie 4, vous avez acquis des outils puissants supplémentaires, comme différentes options de git log, git bisect, git cherry-pick, git revert et git add -p.
Wow, vous devriez être fier de vous !
Un message de moi à vous
En effet, c'était amusant, mais toutes les choses ont une fin. Vous avez fini de lire ce livre, mais cela ne signifie pas que votre voyage d'apprentissage se termine ici.
Ce que vous avez acquis, plus que tout outil spécifique, c'est l'intuition et la compréhension de la façon dont Git fonctionne, et comment penser aux diverses opérations dans Git. Continuez à rechercher, lire et utiliser Git. Je suis sûr que vous serez capable de m'apprendre quelque chose de nouveau, et par tous les moyens - s'il vous plaît faites-le.
Si vous avez aimé ce livre, partagez-le avec plus de gens.
Si vous voulez lire plus de mes articles et manuels Git, les voici :
- The Git Rebase Handbook
- The Git Merge Handbook
- The Git Diff and Patch Handbook
- Git Internals - Objects, Branches, and How to Create a Repo
- Git Reset Command Explained
Remerciements
Beaucoup de gens ont aidé à rendre ce livre le meilleur possible. Parmi eux, j'ai eu la chance d'avoir de nombreux lecteurs bêta qui m'ont fourni des retours afin que je puisse améliorer le livre. Spécifiquement, je voudrais remercier Jason S. Shapiro, Anna Łapińska, C. Bruce Hilbert et Jonathon McKitrick pour leurs examens approfondis.
Abbey Rennemeyer a été une éditrice merveilleuse. Après qu'elle a examiné mes posts pour freeCodeCamp pendant plus de trois ans, il était clair que je voulais lui demander d'être l'éditrice de ce livre également. Elle m'a aidé à améliorer le livre de nombreuses façons, et je suis reconnaissant de son aide.
Quincy Larson a fondé la communauté incroyable de freeCodeCamp, m'a motivé à travers des e-mails et des discussions en face à face. Je le remercie d'avoir lancé cette communauté incroyable et pour son amitié.
Estefania Cassingena Navone a conçu la couverture de ce livre. Je suis reconnaissant pour son travail professionnel et sa patience avec mon perfectionnisme et mes demandes.
Le site web de Daphne Gray-Grant, "Publication Coach", m'a fourni des conseils inspirants ainsi que techniques qui m'ont grandement aidé dans mon processus d'écriture.
Si vous souhaitez soutenir ce livre
Si vous souhaitez soutenir ce livre, vous êtes invité à acheter la version papier, une version E-Book, ou à m'offrir un café. Merci !
Me contacter
Ce livre a été créé pour vous aider, vous et des gens comme vous, à apprendre, comprendre Git et appliquer leurs connaissances dans la vie réelle.
Dès le début, j'ai demandé des retours et j'ai eu la chance d'en recevoir de personnes formidables (mentionnées dans les Remerciements) pour m'assurer que le livre atteignait ces objectifs. Si vous avez aimé quelque chose dans ce livre, si vous avez senti qu'il manquait quelque chose ou avait besoin d'amélioration - j'aimerais beaucoup vous entendre. N'hésitez pas à me contacter à gitting.things@gmail.com.
Merci d'apprendre et de me permettre de faire partie de votre voyage.
- Omer Rosenbaum
Annexes
Références supplémentaires - Par Partie
(Note - ceci est une liste courte. Vous pouvez trouver une liste plus longue de références sur la version E-Book ou imprimée.)
Partie 1
- Playlist YouTube Git Internals - par Brief : https://www.youtube.com/playlist?list=PL9lx0DXCC4BNUby5H58y6s2TQVLadV8v7
- Conférence de Tim Berglund — "Git From the Bits Up" : https://www.youtube.com/watch?v=MYP56QJpDr4
- Git for the confused : https://www.gelato.unsw.edu.au/archives/git/0512/13748.html
Partie 2
Diffs et Patches
Algorithmes Git Diffs :
L'algorithme de diff le plus par défaut dans Git est Myers :
- https://www.nathaniel.ai/myers-diff/
- https://blog.jcoglan.com/2017/02/12/the-myers-diff-algorithm-part-1/
- https://blog.robertelder.org/diff-algorithm/
Git Merge
- https://git-scm.com/book/en/v2/Git-Tools-Advanced-Merging
- https://blog.plasticscm.com/2010/11/live-to-merge-merge-to-live.html
Git Rebase
- https://jwiegley.github.io/git-from-the-bottom-up/1-Repository/7-branching-and-the-power-of-rebase.html
- https://git-scm.com/book/en/v2/Git-Branching-Rebasing
Ressources liées aux Beatles
- https://www.the-paulmccartney-project.com/song/ive-got-a-feeling/
- https://www.cheatsheet.com/entertainment/did-john-lennon-or-paul-mccartney-write-the-classic-a-day-in-the-life.html/
- http://lifeofthebeatles.blogspot.com/2009/06/ive-got-feeling-lyrics.html
Partie 3
- https://git-scm.com/book/en/v2/Git-Tools-Reset-Demystified
- https://www.edureka.co/blog/common-git-mistakes/
À propos de l'auteur
Omer Rosenbaum est le Chief Technology Officer de Swimm. Il est l'auteur de la chaîne YouTube Brief. Il est également un expert en formation cyber et fondateur de la Checkpoint Security Academy. Il est l'auteur de Computer Networks (en hébreu). Vous pouvez le trouver sur Twitter.