

Article original : Exploring a powerful SQL pattern: ARRAY_AGG, STRUCT and UNNEST
Par Lak Lakshmanan
Il peut être extrêmement rentable (à la fois en termes de stockage et en termes de temps de requête) d'utiliser des champs imbriqués plutôt que d'aplatir toutes vos données. Les champs imbriqués et répétitifs sont très puissants, mais le SQL requis pour les interroger semble un peu inhabituel. Il vaut donc la peine de passer un peu de temps avec STRUCT, UNNEST et ARRAY_AGG. L'utilisation de ces trois en combinaison rend également certains types de requêtes beaucoup plus faciles à écrire.

Tâche
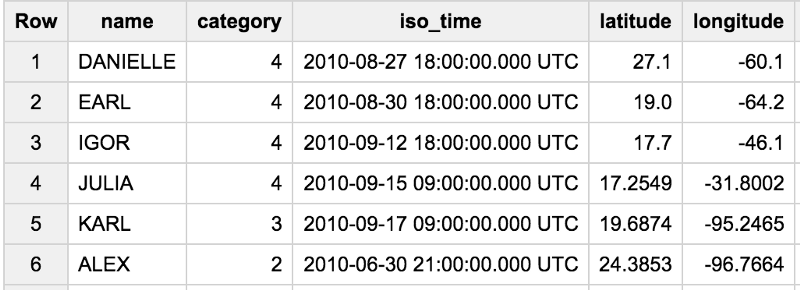
Prenons une table BigQuery de cyclones tropicaux. Voici un aperçu de la table :

La tâche consiste à trouver la valeur maximale de usa_sshs (plus connue sous le nom de « catégorie ») atteinte par chaque ouragan nord-américain (basin=NA) de la saison 2010 et l'heure à laquelle la catégorie a été atteinte pour la première fois. Je veux pouvoir dire quelque chose comme « L'ouragan Danielle a atteint la catégorie 4 à 18:00 UTC le 2010–08–27 lorsqu'il se trouvait à (27,1, -60,1) ».
Voici la requête solution. Dans cet article, je vais la construire pièce par pièce.
Où est l'ouragan ?
Ma première étape a été de créer un historique des emplacements des ouragans. Essentiellement, je veux obtenir :
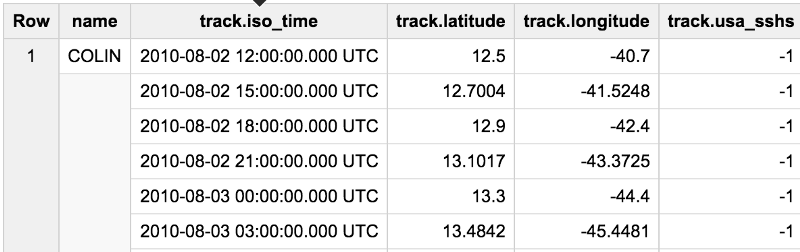
Nous pouvons filtrer par bassin et par saison :
#standardsqlWITH hurricanes AS (SELECT NAME, iso_time, latitude, longitude, usa_sshsFROM `bigquery-public-data.noaa_hurricanes.hurricanes`WHERE season = '2010' AND basin = 'NA')SELECT * from hurricanes LIMIT 5
Mais cela nous donne un mélange de lignes qui répondent aux critères nécessaires. Ce dont nous avons besoin, c'est d'obtenir une liste ordonnée d'emplacements pour chaque ouragan. Ajouter simplement un GROUP BY à la requête ci-dessus ne fonctionnera pas. (Pourquoi ? Essayez !)
Cette requête, cependant, fonctionne :
#standardsqlWITH hurricanes AS (SELECT MIN(NAME) AS name, ARRAY_AGG(STRUCT(iso_time, latitude, longitude, usa_sshs) ORDER BY iso_time ASC) AS trackFROM `bigquery-public-data.noaa_hurricanes.hurricanes`WHERE season = '2010' AND basin = 'NA'GROUP BY sid)
SELECT * from hurricanes LIMIT 5
Décortiquons la requête :
- Nous regroupons par identifiant de tempête, mais lorsque nous regroupons, nous obtenons un ensemble de lignes. Souvent, ce que nous ferions, c'est une agrégation telle que
SUM()ouAVG()des lignes du groupe pour obtenir une seule valeur par ligne de l'ensemble de résultats. - Pour conserver toutes les lignes du groupe, utilisez
ARRAY_AGG(). Dans ce tableau, nous ne voulons pas qu'un seul champ, nous en voulons quatre. Je fais donc de ces quatre champs (temps, lat, lon, force de l'ouragan) une structure. La structure me permet de conserver la relation élément par élément entre ces quatre colonnes. - Ordonner le tableau par temps.
Catégorie maximale
Maintenant que nous avons l'historique de chaque ouragan, déterminons la catégorie maximale atteinte par l'ouragan. Ce que nous voulons, c'est :

Voici le WITH supplémentaire :
WITH hurricanes AS ( ...),
cat_hurricane AS (SELECT name,track, (SELECT MAX(usa_sshs) FROM UNNEST(track)) AS categoryfrom hurricanesORDER BY category DESC)
SELECT * from cat_hurricane
La sélection du nom dans la table des ouragans est assez évidente. Ce n'est qu'une colonne. Mais que fait la sélection de track ? Parce que track est un tableau, vous obtenez le tableau entier.
Pour obtenir une seule ligne du tableau de suivi, nous devons passer par UNNEST(). Lorsque vous appelez UNNEST(track), cela crée une table, donc UNNEST() ne peut être utilisé que dans la clause FROM de BigQuery. Une fois que vous comprenez que UNNEST(track) crée une table avec quatre colonnes (les quatre colonnes de la STRUCT), vous voyez que MAX(usa_sshs) calcule simplement la force maximale atteinte par chaque ouragan.
Heure à laquelle la catégorie maximale est atteinte
Comment trouver l'heure à laquelle la catégorie maximale est atteinte ? Essentiellement, trouver toutes les lignes dans la table UNNEST(track) pour lesquelles la colonne usa_sshs est la catégorie maximale et limiter à 1, pour obtenir la première ligne à laquelle la catégorie est atteinte :
SELECT name, category, (SELECT AS STRUCT iso_time, latitude, longitude FROM UNNEST(track) WHERE usa_sshs = category ORDER BY iso_time LIMIT 1).*FROM cat_hurricaneORDER BY category DESC, name ASC
Voici la requête complète. N'hésitez pas à essayer quelques variantes pour comprendre ce qui se passe :
- Pourquoi ai-je le
.*? Essayez la requête pour voir ce qui se passe si je n'inclus pas le.*? (Indice : cela a à voir avec le nom de la colonne). - Que se passe-t-il si je ne fais pas le
AS STRUCTci-dessus ? - Que se passe-t-il si je ne fais pas le
LIMIT 1?