

Article original : Entering into the World of Concurrency with Python
Dans ce tutoriel, nous allons explorer la concurrency en Python. Nous discuterons des threads et des processus et de leurs similitudes et différences. Vous apprendrez également le multi-threading, le multi-processing, la programmation asynchrone et la concurrency en général en Python.
De nombreux tutoriels discutent de ces concepts, mais ils peuvent être difficiles à comprendre en raison du manque d'exemples clairs. Je vais vous guider à travers les concepts et plonger dans le monde de la concurrency en Python, en fournissant des explications simples pour une meilleure compréhension.
Prérequis
Vous devriez être familier avec la programmation Python et avoir une compréhension de base du multi-threading.
Bien que j'aie fourni des exemples de code non multi-threading pour aider ceux qui ne sont pas familiers avec ces concepts, si vous avez déjà des connaissances dans ces domaines, vous serez en mesure d'approfondir votre compréhension.
Table des matières
- Programmation séquentielle
- Qu'est-ce que les threads ?
- Qu'est-ce que les processus ?
- Threads vs Processus
- Qu'est-ce que le multi-threading ?
- Qu'est-ce que le multi-processing ?
- Qu'est-ce que la programmation asynchrone ?
- Qu'est-ce que la concurrency ?
- Global Interpreter Lock (GIL)
- Comment supprimer les limitations du GIL
– Utiliser une autre version de Python
– Module multiprocessing
– Asyncio - Résumé
Programmation séquentielle
Ne vous inquiétez pas lorsque vous voyez le mot "Concurrency". Mettons-le de côté pour l'instant.
Lorsque vous commencez à apprendre des langages de programmation comme Python ou Java, votre programme s'exécute généralement dans une séquence, en commençant par le haut et en descendant.
Par exemple :
a = 25
b = 30
def add(a, b):
print("Valeur de l'addition : ", a+b)
def sub(a, b):
print("Valeur de la soustraction : ", a-b)
add(a,b)
sub(a,b)
Lorsque vous exécutez le programme ci-dessus, votre interpréteur Python commence à l'exécuter ligne par ligne de haut en bas dans une séquence. Il commence par la ligne a=25 et se termine à la fonction sub().
Peu importe la longueur de votre code, Python l'exécute de haut en bas. Cette façon d'exécuter le code est également connue sous le nom d'approche de haut en bas ou séquentielle – ou simplement programmation séquentielle !
Qu'est-ce que les threads ?
Lorsque vous exécutez votre programme, l'interpréteur Python crée un petit programme en interne et lui donne l'instruction de commencer à s'exécuter. Ce petit programme, créé par l'interpréteur, est appelé un Thread. Un thread est un petit programme qui effectue une certaine tâche.
Pour tout programme ou application, Python crée et instruit un thread pour commencer l'exécution. Ce thread est appelé le thread principal. Il est important de noter que le thread principal peut également créer plusieurs autres threads si vous lui demandez de le faire.
C'est correct ! Vous pouvez écrire un programme pour dire au thread principal de créer plusieurs autres threads qui effectuent vos tâches. Ainsi, un thread effectue un certain travail ou une certaine tâche (ici, le thread principal exécute votre programme de haut en bas).
Ainsi, vous pouvez créer plusieurs tâches et assigner un thread pour effectuer une tâche. Ou vous pouvez également créer un thread et exécuter plusieurs tâches – tout comme l'interpréteur Python a créé le thread principal et exécuté les deux tâches add et sub dans l'ordre séquentiel.
Qu'est-ce que les processus ?
Imaginez que vous possédez une entreprise et que vous avez de nombreuses tâches à accomplir. Pour les gérer, vous allez commencer à embaucher des personnes et à assigner une tâche à chaque personne.
Chaque personne travaille de manière indépendante sur sa tâche. Elles ont leur propre ensemble d'outils et de ressources, et si une personne termine sa tâche, cela n'affecte pas directement ce que font les autres.
Dans le monde des ordinateurs, chaque personne effectuant une tâche est comme un processus séparé. Les processus sont indépendants, ont leur propre espace mémoire et ne partagent pas directement les ressources.
Par exemple, lorsque vous allumez votre ordinateur et commencez à ouvrir un navigateur, un bloc-notes et MS Office, vous lancez essentiellement plusieurs processus. Chaque programme que vous ouvrez, comme le navigateur ou le bloc-notes, est un processus séparé avec sa propre mémoire. Ces processus ne sont pas connectés les uns aux autres.
Lorsque vous exécutez un programme, votre système d'exploitation crée un processus, lui attribue de la mémoire, lui dédie du temps CPU et exécute le programme à l'intérieur. La manière dont le programme fonctionne à l'intérieur du processus est déterminée par sa conception. En essence, nous pouvons dire qu'une application est un processus.
Threads vs Processus
Cela peut sembler confus, n'est-ce pas ? Mais il y a une petite différence entre les threads et les processus. Permettez-moi de vous l'expliquer.
Un processus est comme une seule tâche effectuée par le système d'exploitation. Il fonctionne de manière indépendante et a son propre espace mémoire.
Un thread est comme une petite partie d'une tâche au sein d'un programme. Il gère de petites tâches. Les threads sont créés au sein d'un processus et sont contrôlés par le programme.
Un programme peut créer plusieurs threads et ils peuvent partager des ressources, communiquer entre eux, mais uniquement au sein du même processus.
Pour simplifier, pensez à un navigateur comme à un processus. Au sein de ce processus, il peut exécuter un ou plusieurs threads.
Lorsque vous apprenez la concurrency en programmation, vous verrez des termes comme "Multi-Threading", "Multi-Processing", "Asynchrone", et enfin le grand "Concurrency". Ne laissez pas ces termes vous intimider – les concepts sont plus simples que vous ne le pensez. Et ce sont ceux que vous allez apprendre ensuite.
Qu'est-ce que le multi-threading ?
La vie est plus facile lorsque vous avez beaucoup de travailleurs pour accomplir toutes les tâches nécessaires, n'est-ce pas ? De même, si vous avez plusieurs threads, ils vous aident à diviser toutes les tâches de votre programme en parties plus petites.
Bien sûr, si vous avez beaucoup de travailleurs, cela peut être difficile à gérer et cela coûte plus cher. Ce sont les avantages et les inconvénients du multi-threading également.
L'utilisation de plusieurs threads pour effectuer vos tâches est appelée multi-threading.
Reprenons l'exemple :
a = 25
b = 30
def add(a, b):
print("Valeur de l'addition : ", a+b)
def sub(a, b):
print("Valeur de la soustraction : ", a-b)
add(a,b)
sub(a,b)
Vous pouvez dire à l'interpréteur Python de créer deux threads et d'exécuter add() avec le thread-1 et sub() avec le thread-2. C'est bien, mais pourquoi voudriez-vous faire cela ?
Considérez l'approche séquentielle : l'interpréteur exécute d'abord add(), puis sub(). Pourquoi attendre sub() pendant que add() s'exécute ? Dans ce cas, l'addition et la soustraction sont entièrement différentes et ne dépendent pas l'une de l'autre, alors pourquoi attendre ? Les deux fonctions ne peuvent-elles pas s'exécuter simultanément ?
C'est là que les threads multiples entrent en jeu. Si vos tâches sont indépendantes et n'ont pas besoin d'attendre que les autres se terminent, alors vous avez le privilège d'exécuter vos tâches en utilisant plusieurs threads.
Notez que, que vous créiez un thread ou plus, votre interpréteur Python créera le thread principal et gérera l'exécution de votre programme. Si vous instruisez votre programme de créer 2 threads, le thread principal les créera pour vous et assignera quelle tâche doit être faite par chaque thread.
Ainsi, indépendamment du fait que vous créiez un thread dans votre programme ou non, le thread principal sera créé, et il prendra soin de l'exécution de votre programme.
Qu'est-ce que le multi-processing ?
D'après le nom lui-même, vous pouvez comprendre que le multiprocessing signifie exécuter plusieurs processus séparément sans partager directement les ressources.
Par exemple, imaginez deux restaurants, chacun avec ses propres chefs. La méthode qu'un chef du Restaurant 1 utilise pour cuisiner un plat n'affecte pas ou ne dépend pas du Restaurant 2. Ils opèrent de manière indépendante, même si vous passez la même commande dans les deux restaurants.
Mais vous vous demandez peut-être : comment parlons-nous du multitâche sur un ordinateur avec un seul processeur mais plusieurs cœurs CPU ?
Dans les ordinateurs modernes, certains processeurs ont plusieurs cœurs, et chaque cœur fonctionne comme son propre processeur. Si un processeur a 4 cœurs, il peut gérer 4 tâches simultanément en assignant chaque tâche à un cœur différent. Cela signifie que les ressources CPU, mémoire et stockage sont partagées entre ces tâches sans qu'elles ne dépendent les unes des autres.
Cette approche du multitâche sur plusieurs cœurs au sein d'un seul processeur est connue sous le nom de Symmetric Multiprocessing.
Si vous avez plusieurs processeurs, vous pouvez assigner chaque tâche à un processeur différent pour l'exécuter de manière indépendante. Ce type de multi-processing est appelé Distributed Multi-processing.
Je veux vous rappeler que le multi-threading se produit au sein d'un processus. En termes simples, le multi-threading ne se produit qu'au sein d'un processus.
Acquérons une compréhension pratique du multiprocessing. J'utiliserai le même exemple que nous avons discuté dans les sections Programmation séquentielle et Multi-threading, mais cette fois en utilisant une version multiprocessing.
Tout comme vous avez exécuté le programme en utilisant des threads, nous allons maintenant exécuter le programme en utilisant des processus.
from multiprocessing import Process
a = 25
b = 30
def add(a, b):
try:
print("Valeur de l'addition : ", a + b)
time.sleep(10)
except Exception as e:
print(e)
def sub(a, b):
try:
print("Valeur de la soustraction : ", a - b)
time.sleep(20)
except Exception as e:
print(e)
if __name__ == "__main__":
# Créer deux processus, un pour add et un pour sub
add_process = Process(target=add, args=(a, b))
sub_process = Process(target=sub, args=(a, b))
# Démarrer les processus
add_process.start()
sub_process.start()
# Attendre que les deux processus se terminent
add_process.join()
sub_process.join()
Nous utilisons le module multiprocessing dans ce programme pour créer 2 processus : add_process et sub_process. Un processus exécute la fonction add() et un autre exécute la fonction sub().
Nous démarrons ensuite les deux processus en utilisant la méthode .start() des deux objets de processus. Après cela, nous utilisons la méthode .join() des objets de processus pour faire attendre le thread principal jusqu'à ce que les deux processus se terminent.
Comprenons cela un peu plus en détail. J'exécute le programme sur un ordinateur basé sur le système d'exploitation Windows. Ouvrez l'application gestionnaire des tâches pour voir tous les processus en cours d'exécution dans votre système d'exploitation. Pour exécuter votre programme, vous devez utiliser l'invite de commande de votre fenêtre ou cmd ou votre terminal dans votre Linux ou Mac.
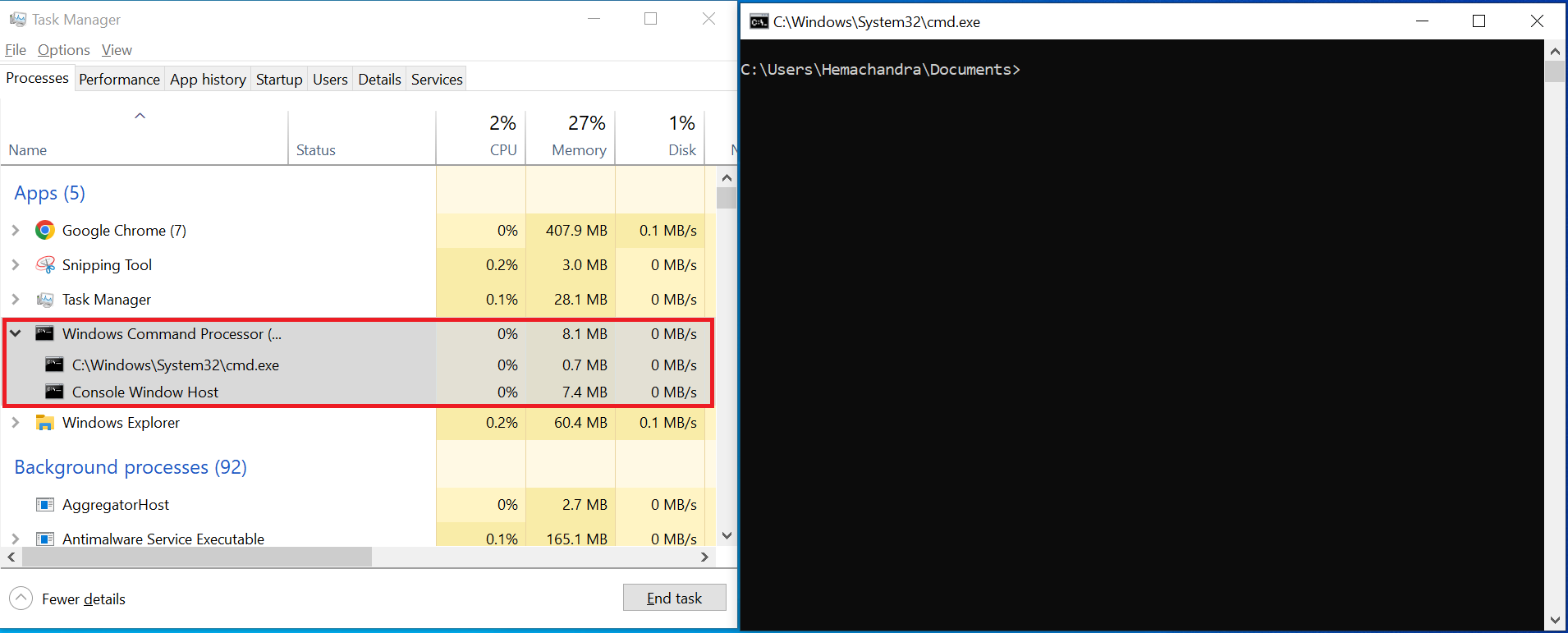 Gestionnaire des tâches et CMD
Gestionnaire des tâches et CMD
L'image ci-dessus montre le gestionnaire des tâches à gauche et CMD à droite. Vous pouvez facilement voir le processeur de commande Windows, ou CMD, s'exécuter en tant que processus dans le gestionnaire des tâches. Vous pouvez également voir que j'exécute Google Chrome et l'Outil de capture en arrière-plan, tous deux étant également listés dans mon Gestionnaire des tâches.
Je vais exécuter le programme maintenant à partir de CMD en exécutant la commande python sample.py, où sample est le nom du programme.
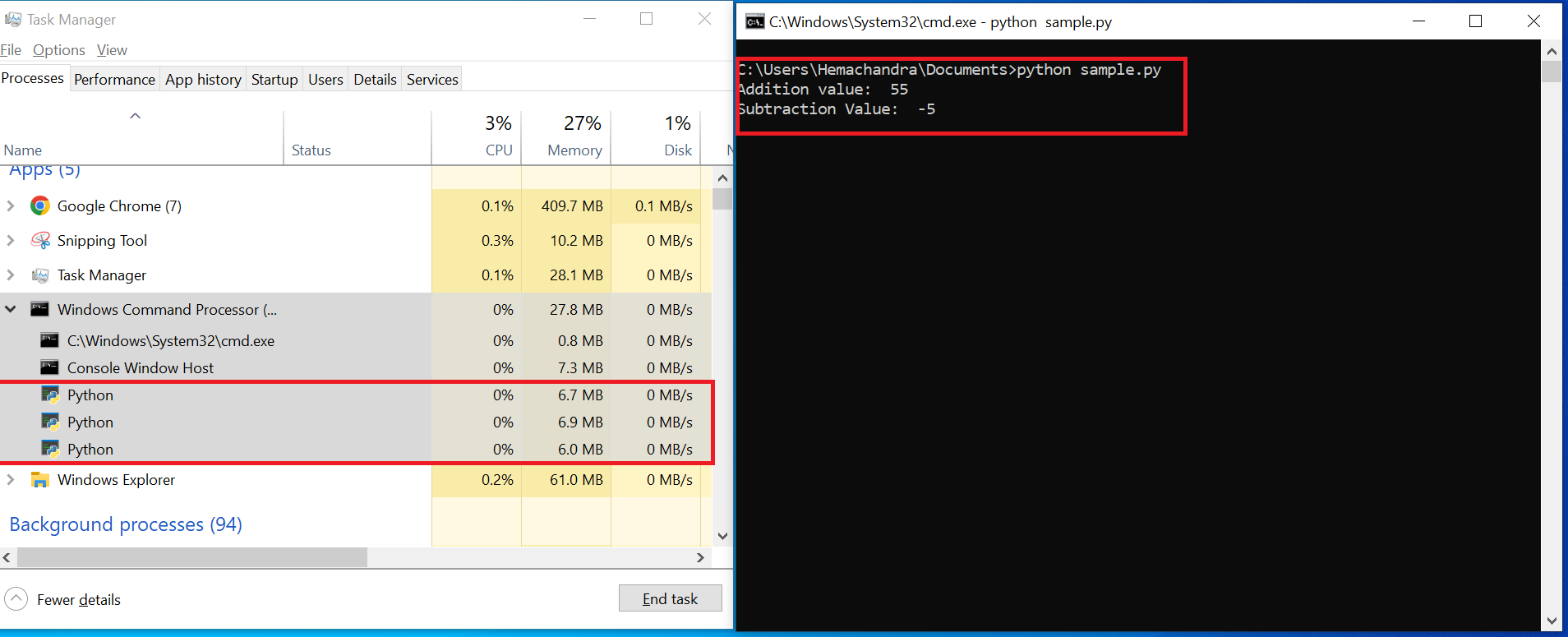 Exécution de sample.py dans CMD
Exécution de sample.py dans CMD
Dans l'image ci-dessus, j'exécute le programme dans CMD à droite. Le programme a immédiatement imprimé la sortie des deux fonctions add() et sub(). Le programme est toujours en cours d'exécution, car nous avons utilisé time.sleep() dans les deux fonctions, ce qui pause l'exécution de add_process pendant 10 secondes et sub_process pendant 20 secondes.
En mettant de côté la sortie, concentrons-nous sur le Gestionnaire des tâches. Si vous développez le Processeur de commande Windows, vous trouverez 3 processus Python en cours d'exécution. Explorons pourquoi il y a trois processus Python au lieu de deux (add_process et sub_process).
Puisque nous avons initié le programme via CMD, votre application Python est déclenchée par le Processeur de commande Windows ou CMD et est donc listée sous CMD. Nous savons déjà que lorsque vous exécutez un programme Python, votre interpréteur Python démarre le Thread principal, qui gère l'exécution du programme.
Ce Thread principal est listé comme un processus. Ensuite, comme nous créons deux processus au sein du programme, ils sont listés comme deux processus supplémentaires sous le Processeur de commande Windows (comme vu dans l'image ci-dessus).
Notez que les deux processus sont complètement indépendants et ne partagent aucune ressource. Si vous souhaitez partager quelque chose entre les processus, vous devez implémenter des mécanismes spéciaux comme une File d'attente.
Qu'est-ce que la programmation asynchrone ?
La programmation asynchrone est une approche spécifique pour gérer les tâches qui implique d'attendre que les opérations externes se terminent. Elle permet à un programme de continuer à s'exécuter d'autres tâches tout en attendant que ces opérations se terminent, plutôt que de bloquer jusqu'à ce qu'elles se terminent.
Note : Si vous n'êtes pas familier avec le codage multi-thread en Python, vous pouvez passer à l'exemple-2.
Exemple 1 :
Le même exemple encore, mais cette fois les fonctions sont exécutées en utilisant des threads. add() est exécuté par thread-1 et sub() est exécuté par thread-2. Voici la version threading de l'exemple :
import threading
import time
a = 25
b = 30
def add(a, b):
print("À l'intérieur de la fonction add\n")
print("Attente de 20 secondes dans add \n")
time.sleep(20)
print("Valeur de l'addition :", a + b)
def sub(a, b):
print("À l'intérieur de la fonction sub\n")
print("Valeur de la soustraction {}:".format(a - b))
print("Attente de 10 secondes dans sub\n")
time.sleep(10)
# Créer des threads pour les fonctions add et sub
add_thread = threading.Thread(target=add, args=(a, b))
sub_thread = threading.Thread(target=sub, args=(a, b))
# Démarrer les deux threads
add_thread.start()
sub_thread.start()
# Attendre que les deux threads se terminent
add_thread.join()
sub_thread.join()
print("Complet")
Nous avons créé add_thread et sub_thread et assigné les fonctions add et sub comme cible. Si vous exécutez ce programme, vous pouvez voir la sortie suivante :
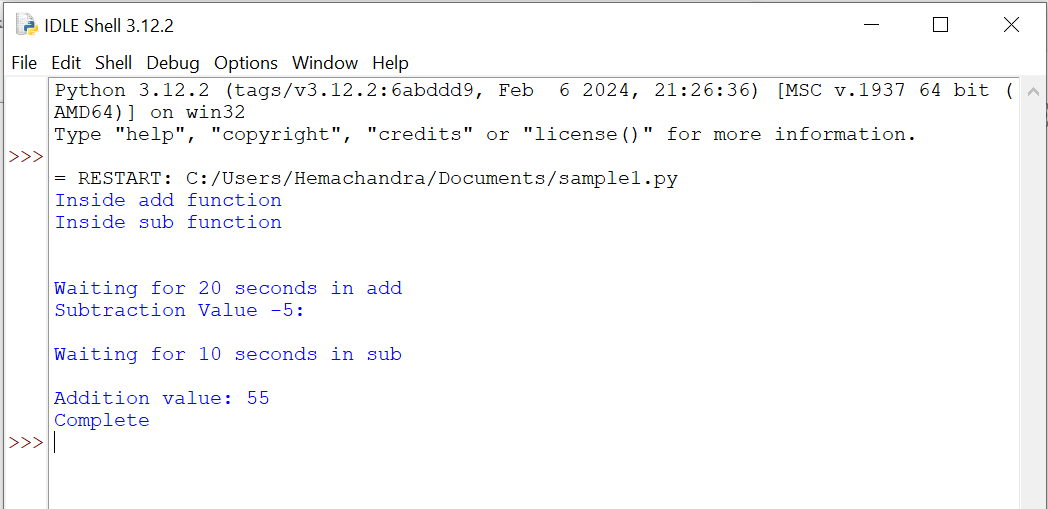 Sortie du programme
Sortie du programme
Décomposons la sortie :
- Les fonctions
addetsubsont démarrées en utilisant des threads séparés (add_threadetsub_thread). - La fonction
addimprime "À l'intérieur de la fonction add" puis indique qu'elle attend 20 secondes en utilisanttime.sleep(20). - La fonction
subimprime "À l'intérieur de la fonction sub" et "Valeur de la soustraction -5 :" (résultat de l'opération de soustraction), suivi d'un message indiquant qu'elle attend 10 secondes en utilisanttime.sleep(10). - Comme les threads s'exécutent en même temps, les messages des deux fonctions peuvent apparaître entrelacés, selon l'ordre d'exécution des threads.
- Après les périodes d'attente, les deux threads impriment les résultats de leurs opérations respectives. La fonction
addimprime "Valeur de l'addition : 55," et la fonctionsubn'imprime rien d'autre. - Enfin, le programme principal imprime "Complet" une fois que les deux threads ont terminé leur exécution.
Pendant que add_thread() attend 20 secondes, votre sub_thread() a fourni le résultat et a commencé à dormir pendant 10 secondes. Pendant ce temps, add_thread a terminé son temps d'attente, a calculé la valeur de l'addition et a imprimé le résultat. Ainsi, pendant qu'un thread attend, votre deuxième thread a commencé à s'exécuter, et pendant que votre deuxième thread attendait, votre premier thread a commencé à s'exécuter.
Cette façon de gérer les tâches pour les exécuter simultanément lorsqu'une tâche attend des ressources externes est appelée programmation asynchrone.
Le point clé à noter est que les threads s'exécutent simultanément, permettant au programme d'effectuer des tâches en parallèle. La sortie entrelacée démontre la nature asynchrone du threading, où différentes parties du programme peuvent s'exécuter simultanément.
Exemple 2 :
Considérons deux tâches : la tâche 1 récupère une liste d'employés à partir de la base de données d'une entreprise, et la tâche 2 récupère une liste de projets actifs de la même entreprise. Il est clair que ces tâches ne sont pas connectées ou dépendantes l'une de l'autre – ce sont des tâches indépendantes.
Écrivons un exemple de code pour ces tâches :
def get_employees():
# se connecter à la base de données
# code pour obtenir la liste des employés à partir de la base de données
return employees_list
def get_active_projects():
# se connecter à la base de données
# code pour obtenir les projets en développement
return active_projects
# exécuter la tâche1
get_employees()
# exécuter la tâche2
get_active_projects()
Ne vous inquiétez pas du code à l'intérieur des fonctions – nous voulons comprendre le concept ici.
Lorsque vous exécutez le programme ci-dessus, l'interpréteur Python dit au thread principal d'exécuter le programme étape par étape, en commençant par le haut et en descendant.
Tout d'abord, il effectue la tâche-1, qui, disons, prend 2 secondes, puis il passe à la tâche-2, qui, disons, prend également 2 secondes. Nous savons que ces tâches sont indépendantes, alors pourquoi la tâche-2 devrait-elle attendre que la tâche-1 se termine ?
S'il existe un mécanisme où je peux dire à l'interpréteur de démarrer la tâche-1 (obtenir une liste d'employés à partir de la base de données), et pendant qu'il attend que la tâche-1 se termine, je peux également lui dire de démarrer la tâche-2 (obtenir une liste de projets actifs à partir de la base de données), alors j'exécute essentiellement les deux tâches presque simultanément. Cela m'aide à réduire le temps d'exécution total des deux tâches. C'est un autre exemple de programmation asynchrone.
Maintenant, c'est clair. Comment faisons-nous cela ? Comment nous assurons-nous que la tâche-2 s'exécute pendant que nous attendons que la tâche-1 obtienne la liste des employés à partir de la base de données ? Nous avons de nombreux outils pour cela. Le Multi-threading en est un.
Dans l'exemple ci-dessus, vous utilisez deux threads : thread-1 pour la tâche-1 puis démarrez immédiatement thread-2 pour la tâche-2. Thread-2 n'a pas à attendre que Thread-1 se termine.
Vous pouvez également utiliser des concepts comme async/await, callbacks, et promises dans divers langages de programmation pour implémenter la programmation asynchrone. Vous pouvez lire plus sur ces concepts en JavaScript ici.
Qu'est-ce que la concurrency ?
Enfin, nous sommes arrivés à la concurrency !
Vous devriez maintenant comprendre que le multi-threading ou le multi-processing implique l'utilisation de plusieurs threads et processus pour effectuer plusieurs tâches simultanément afin de diminuer le temps qu'il faut pour qu'un programme ou une application s'exécute.
Mais comment cela se produit-il ? Que se passe-t-il en arrière-plan ? Comment le processeur s'assure-t-il que les threads ou les processus s'exécutent simultanément ?
Imaginez que vous avez deux tâches : conduire une voiture et passer un appel téléphonique. Vous décidez de faire les deux en même temps. Pendant que vous conduisez, vous commencez à appeler votre ami en utilisant votre téléphone portable et à parler.
Vous faites ces tâches simultanément, mais il y a un petit détail qui est important : votre cerveau scanne rapidement la route, vérifie les autres voitures et s'assure que vous êtes concentré et stable. Il passe environ une milliseconde ici, puis passe à parler avec votre ami, ce qui peut prendre une autre milliseconde, puis revient à la conduite toutes les millisecondes. Il bascule continuellement entre les deux tâches.
Comme le temps passé sur chaque tâche est très court (juste une milliseconde), vous pourriez penser que vous faites les deux tâches en même temps. Mais il y a une très petite différence de temps pour chaque tâche, ce qui donne l'impression que les deux tâches sont faites simultanément.
De manière similaire, lorsqu'il y a deux tâches exécutées par deux threads ou deux processus, votre processeur bascule entre ces tâches très rapidement. Il exécute le thread-1 pendant 1 milliseconde, puis sauvegarde son état et bascule vers le thread-2, l'exécutant pendant une autre milliseconde. Après avoir sauvegardé l'état du thread-2, il revient au thread-1 et l'exécute pendant une autre milliseconde.
J'utilise 1 milliseconde comme exemple, mais en réalité, cela se produit encore plus rapidement. La vitesse de basculement dépend de votre processeur.
Comme le basculement entre les tâches est si rapide, cela donne l'impression que les deux tâches s'exécutent simultanément. Mais il est important de noter que même si vous demandez à la fois au thread-1 et au thread-2 de s'exécuter en même temps, votre processeur et votre système d'exploitation décident lequel prioriser en premier, combien de temps allouer à chacun, et dans quel ordre les exécuter.
En résumé, c'est comme jongler avec plusieurs tâches simultanément. Vous commencez une tâche, basculez vers une autre lorsque nécessaire, et continuez à cycler à travers elles jusqu'à ce que tout soit fait. Ce concept est appelé concurrency.
"La concurrency est un concept de gestion de la progression de plusieurs tâches en même temps, même si elles ne s'exécutent pas simultanément."
Comment y parvenir ? En utilisant à nouveau le multi-threading et le multi-processing !
À ce stade, vous avez peut-être compris que la concurrency et la programmation asynchrone sont les concepts de base, tandis que le multi-threading et le multi-processing sont des implémentations de ces concepts.
Global Interpreter Lock (GIL)
Les concepts de concurrency et de programmation asynchrone sont les mêmes, quel que soit le langage de programmation que vous utilisez. Mais l'implémentation de ces concepts dépend du langage de programmation que vous choisissez.
En ce qui concerne le multi-threading, Python se comporte un peu bizarrement. Comprenons cela avec un petit exemple.
Dans mon enfance, mon jeune frère et moi jouions à des jeux vidéo. Ma mère a établi une règle selon laquelle mon frère devait jouer en premier pendant 30 minutes et ensuite je pouvais jouer pendant 30 minutes. Cette règle était pour s'assurer que personne ne gâche le jeu en essayant de faire des choses en même temps. Donc, j'attendais 30 minutes jusqu'à ce que ce soit mon tour de jouer au jeu pendant 30 minutes.
Dans le monde des ordinateurs, les programmes sont comme mon frère et moi essayant de jouer au jeu. Le Global Interpreter Lock (GIL) est comme la règle qui permet seulement à l'un d'entre nous, soit mon frère soit moi (ou thread), de jouer au jeu (ou d'exécuter le bytecode Python) à la fois.
Le GIL est une règle qui permet seulement à un thread à la fois d'exécuter le bytecode Python. Le Global Interpreter Lock est un verrou qui protège l'accès aux objets Python, empêchant plusieurs threads d'exécuter le bytecode Python simultanément dans un seul processus. Cela signifie que même dans un programme Python multi-thread, un seul thread peut exécuter le bytecode Python à un moment donné.
En conséquence, cela entraîne des limitations de performance du multi-threading dans les tâches liées au CPU. Notez que les tâches liées au CPU sont les tâches qui dépendent beaucoup du CPU plutôt que des opérations d'E/S. Les calculs mathématiques, la compression et la décompression de fichiers, et la compilation de programmes par un compilateur de programme sont quelques exemples de tâches liées au CPU qui utilisent plus de CPU.
Regardons un exemple :
import time
def count_up():
count = 0
for i in range(100000000):
count = count + i
def count_down():
count = 0
for i in range(100000000):
count = count + i
if __name__ == "__main__":
start_time = time.time()
count_up()
count_down()
end_time = time.time()
print(f"Temps écoulé : {end_time - start_time} secondes")
Dans le programme ci-dessus, nous exécutons les fonctions count_up() et count_down() séquentiellement l'une après l'autre. Les fonctions count_up et count_down itèrent chacune à travers une grande plage, calculant la somme cumulative des nombres. La sortie du programme est :
Temps écoulé : 25.86127805709839 secondes
Écrivons le même programme en utilisant le multi-threading comme suit :
import threading
import time
def count_up():
count = 0
for i in range(100000000):
count = count + i
def count_down():
count = 0
for i in range(100000000):
count = count + i
if __name__ == "__main__":
start_time = time.time()
# Créer deux threads, chacun exécutant une tâche liée au CPU
thread1 = threading.Thread(target=count_up)
thread2 = threading.Thread(target=count_down)
# Démarrer les deux threads
thread1.start()
thread2.start()
# Attendre que les deux threads se terminent
thread1.join()
thread2.join()
end_time = time.time()
print(f"Temps écoulé : {end_time - start_time} secondes")
Deux threads thread1 et thread2 sont créés pour exécuter les fonctions count_up et count_down simultanément. Le programme mesure le temps qu'il faut pour que les deux threads se terminent en utilisant le module time. La sortie du programme est :
Temps écoulé : 24.498752117156982 secondes
Notez que sur votre PC, le temps nécessaire pour que ce programme se termine peut être différent. Si vous observez, la sortie pour les versions séquentielle et multi-threading du programme (25.8 secondes vs 24.98 secondes) il n'y a pas beaucoup de différence entre le temps pris. Cela est dû au GIL.
Le Global Interpreter Lock (GIL) dans CPython, qui permet à un seul thread d'exécuter le bytecode Python à la fois, signifie que le temps d'exécution ne montrera pas une amélioration significative par rapport à l'exécution des tâches séquentiellement.
Cela met en évidence la limitation du multi-threading en Python pour les tâches liées au CPU en raison du GIL.
Mais il est important de noter que bien que le GIL empêche plusieurs threads d'exécuter le bytecode Python en même temps, il n'empêche pas le threading en général. Les threads Python peuvent toujours être utiles pour les tâches liées aux E/S où les threads passent la plupart de leur temps à attendre des opérations externes (comme les E/S réseau ou disque) plutôt que d'effectuer des calculs intensifs en CPU.
Alors, comment supprimer les limitations du GIL ?
Utiliser une autre version de Python
L'implémentation standard de Python est Cpython. C'est le Python conçu en utilisant le langage C et est utilisé dans le monde entier. Pour éviter le GIL, nous pouvons utiliser Jython (Python développé en utilisant Java), IronPython (Python développé en utilisant .NET), ou PyPy (Python développé en utilisant Python).
Vous pouvez consulter les ressources suivantes pour plus d'informations :
Utiliser le module multiprocessing
Le multiprocessing est un module qui vous aide à tirer parti de vos multiples cœurs CPU pour exécuter votre programme dans des processus séparés.
Chaque processus a son propre cœur CPU, sa mémoire, ses ressources et son interpréteur. Oui, chaque processus a son propre interpréteur pour exécuter votre code Python. Si vous avez 4 cœurs CPU, vous pouvez exécuter 4 processus, chacun ayant son propre interpréteur qui exécute votre application dans sa propre mémoire.
Écrivons le programme que nous avons discuté dans le concept GIL en utilisant le multi-processing comme suit :
import multiprocessing
import time
def count_up():
count = 0
for i in range(100000000):
count = count + i
def count_down():
count = 0
for i in range(100000000):
count = count + i
if __name__ == "__main__":
start_time = time.time()
# Créer deux threads, chacun exécutant une tâche liée au CPU
process1 = multiprocessing.Process(target=count_up)
process2 = multiprocessing.Process(target=count_down)
# Démarrer les deux threads
process1.start()
process2.start()
# Attendre que les deux threads se terminent
process1.join()
process2.join()
end_time = time.time()
print(f"Temps écoulé : {end_time - start_time} secondes")
La sortie du programme lorsque vous l'exécutez via votre terminal ou CMD est :
Temps écoulé : 8.376060724258423 secondes
Cela représente une amélioration significative du temps pris par rapport aux techniques telles que Séquentiel et Multi-threading (25.8 vs 24.4 vs 8.3 secondes). Cela illustre comment l'utilisation du multiprocessing peut aider à réduire votre temps CPU.
Notez qu'il y aura un surcoût si vous souhaitez communiquer entre les processus. Par conséquent, bien que le multiprocessing puisse être efficace pour les tâches liées au CPU, il peut ne pas être adapté à tous les scénarios, en particulier ceux impliquant une communication fréquente ou des transferts de données importants entre les processus.
Implémenter la programmation asynchrone !
Si votre programme ou application n'est pas lourd en CPU ou dépend davantage du traitement CPU, en utilisant le module asyncio de Python, vous pouvez implémenter le concept de programmation asynchrone (ne pas attendre que la tâche 1 se termine avant de commencer la tâche 2).
Ce module est principalement utilisé dans les opérations d'E/S. Asyncio vous permet d'écrire du code asynchrone qui multitâche de manière coopérative sans dépendre des threads, ce qui peut aider dans les situations où les threads seraient autrement bloqués en attendant que les opérations d'E/S se terminent.
En utilisant asyncio, vous pouvez écrire du code non bloquant qui permet à d'autres tâches de s'exécuter en attendant que les opérations d'E/S se terminent, améliorant ainsi potentiellement la concurrency globale et la réactivité de votre application.
Il est important de noter qu'asyncio n'élimine pas le GIL lui-même – plutôt, il fournit un modèle de concurrency alternatif qui peut être plus efficace pour certains types d'applications.
Pour les tâches liées au CPU, asyncio peut ne pas offrir les mêmes avantages de performance que le multiprocessing ou d'autres techniques de parallélisme, car il fonctionne toujours dans les contraintes du GIL. Dans de tels cas, le multiprocessing ou d'autres approches de concurrency peuvent être plus adaptés.
Résumé
Dans cet article, vous avez appris les différences entre le multi-threading, le multi-processing, la programmation asynchrone et la concurrency. Passons-les brièvement en revue maintenant :
Multi-threading :
- Définition : Le multi-threading implique l'utilisation de plusieurs threads pour exécuter des tâches concurrentes au sein d'un seul processus. Concurrentes n'est rien d'autre que le concept de concurrency ici.
- Clarification : Les threads partagent le même espace mémoire, ce qui leur permet de communiquer facilement mais nécessite une synchronisation minutieuse pour éviter les conflits.
Multi-processing :
- Définition : Le multi-processing implique l'utilisation de plusieurs processus pour exécuter votre application ou vos tâches. Chaque processus a son propre espace mémoire et ses ressources.
- Clarification : Les processus sont indépendants, et la communication entre eux nécessite souvent des mécanismes de communication inter-processus (IPC). Chaque processus fonctionne dans son propre espace mémoire.
Programmation asynchrone :
- Définition : La programmation asynchrone est un concept de programmation qui permet aux tâches de s'exécuter séparément du flux principal du programme. Elle n'implique pas nécessairement une exécution concurrente.
- Clarification : Les tâches asynchrones ne bloquent pas le programme principal, permettant au programme de continuer son exécution tout en attendant que les tâches asynchrones se terminent. Cela est couramment utilisé dans les opérations d'E/S pour améliorer l'efficacité.
Concurrency :
- Définition : La concurrency est un concept plus large qui fait référence à la capacité d'un système à exécuter plusieurs tâches dans des intervalles de temps qui se chevauchent, c'est-à-dire à basculer entre les tâches à des intervalles spécifiques.
- Clarification : La concurrency ne garantit pas une exécution simultanée mais se concentre plutôt sur la gestion efficace de plusieurs tâches en basculant entre elles. Elle englobe le multi-threading, le multi-processing et la programmation asynchrone comme moyens d'atteindre une exécution concurrente.
J'espère que vous avez maintenant une compréhension claire des concepts qui pouvaient sembler effrayants auparavant. Je comprends que c'est surtout théorique, mais je veux m'assurer que vous comprenez bien le concept avant de plonger dans l'aspect pratique.
En attendant, votre ami ici, Hemachandra, se déconnecte...
Pour plus de cours, vous pouvez visiter mon site personnel website.
_Passez une excellente journée !