

Article original : Deep Learning with Julia – How to Build and Train a Model using a Neural Network
Par Andrey Germanov
Julia est un langage de programmation généraliste bien adapté à l'analyse numérique et à la science computationnelle. Certains le considèrent comme l'avenir du machine learning et le remplacement le plus naturel de Python dans ce domaine.
Dans l'article précédent "Machine learning avec Julia – Comment construire et déployer un modèle d'IA entraîné en tant que service web", j'ai introduit les fonctionnalités de base du machine learning de Julia et expliqué pourquoi il est si bon pour cela.
Dans cet article, je souhaite aller un peu plus loin et explorer les fonctionnalités de deep learning de Julia pour montrer comment vous pouvez l'utiliser pour résoudre des tâches de vision par ordinateur en utilisant des réseaux de neurones.
La vision par ordinateur est l'un des domaines les plus impressionnants de l'intelligence artificielle. Elle inclut des tâches intéressantes telles que la classification d'images, la reconnaissance de texte, la détection d'objets et la segmentation d'images. Les réseaux de neurones ont montré les meilleures performances dans la résolution des problèmes de vision par ordinateur.
Dans ce tutoriel, je vais vous guider à travers le processus de construction et d'entraînement d'un réseau de neurones pour reconnaître des chiffres manuscrits en utilisant Julia. Je vais également expliquer comment créer un site web qui utilisera le modèle entraîné pour lire des numéros de téléphone manuscrits.
Voici ce que nous allons couvrir :
- Ce que vous devez savoir à l'avance
- Flux de travail de reconnaissance de chiffres manuscrits
- Comment collecter les données d'image initiales
- Comment travailler avec les images dans Julia
- Comment préparer les données d'image pour le machine learning
- Comment créer un modèle de machine learning
- Comment entraîner le modèle
- Comment évaluer la précision du modèle entraîné
- Comment créer et entraîner le réseau de neurones convolutionnel
- Comment exporter le modèle entraîné vers un fichier
- Comment créer un frontend
- Comment créer un backend
- Conclusion
Ce que vous devez savoir à l'avance
Ce tutoriel suppose que vous avez des connaissances de base en Julia, que vous pouvez acquérir en lisant mon article précédent. Cet article inclut également des instructions sur la façon d'installer Julia et de l'intégrer avec Jupyter notebook, qui sera utilisé pour écrire la majeure partie du code.
Le problème de la "Reconnaissance de chiffres manuscrits utilisant le deep learning" et la théorie qui le sous-tend sont bien connus. C'est pourquoi je ne le couvrirai que brièvement. Il existe de nombreuses bonnes ressources qui expliquent comment les réseaux de neurones sont utilisés pour résoudre les tâches de classification d'images. Personnellement, je recommande de regarder cette vidéo et de lire le premier chapitre de ce livre en ligne.
Le but de ce tutoriel est uniquement de vous montrer comment implémenter la théorie, expliquée dans ces ressources, en utilisant Julia.
Flux de travail de reconnaissance de chiffres manuscrits
Pour construire un modèle de machine learning, nous utiliserons le Framework Flux.jl qui est une implémentation pure Julia des types de réseaux de neurones les plus connus, y compris les réseaux feed forward, convolutionnels et récurrents.
La reconnaissance de chiffres manuscrits est une tâche de machine learning supervisé de classification d'images. Pour l'implémenter, vous devez avoir un ensemble de données étiquetées de chiffres manuscrits et l'utiliser pour entraîner le modèle de machine learning.
Voici à quoi ressemble le flux de travail du ML :
- Collectez les images de chiffres manuscrits pour la reconnaissance.
- Préparez un ensemble de données étiquetées pour le machine learning en nettoyant et en étiquetant les données.
- Créez un modèle de machine learning pour reconnaître les chiffres manuscrits.
- Entraînez le modèle en utilisant l'ensemble de données d'entraînement.
- Évaluez la précision du modèle entraîné en l'alimentant avec des données provenant d'un ensemble de données de test.
- Après avoir atteint une bonne précision, exportez le modèle vers un fichier pour l'utiliser dans des applications.
Comment collecter les données d'image initiales
La première étape de toute tâche de machine learning est de collecter les données qui seront utilisées pour l'entraînement. Habituellement, c'est la plus grande partie de tout le processus.
Comment collectez-vous les chiffres manuscrits pour cela ? Eh bien, par exemple, vous pouvez demander à tous vos amis sur les réseaux sociaux d'écrire des chiffres de 0 à 9 et de les sauvegarder en images. Ils peuvent également demander à leurs amis de faire de même et enfin vous envoyer toutes ces images.
Plus vous collectez de données, mieux c'est pour le machine learning.
Ensuite, vous pourriez créer des dossiers avec des noms de "0" à "9" et y organiser ces images. De plus, vous devez convertir les images au même format : les convertir en niveaux de gris et les redimensionner. Toutes les images doivent avoir la même taille et le même format de couleur.
Enfin, vous aurez une collection étiquetée de chiffres manuscrits prêts à être utilisés.
Heureusement, vous n'avez pas besoin de faire tout ce travail manuel, car cela a déjà été fait en 1998 par le National Institute of Standards and Technology. La base de données de chiffres manuscrits, appelée MNIST, est disponible en téléchargement depuis Kaggle ou depuis de nombreux autres endroits. Par exemple, vous pouvez télécharger et extraire l'archive MNIST en utilisant ce lien.
Cette base de données est déjà divisée en données de test et d'entraînement dans des dossiers appropriés. Chacun de ces dossiers contient des images de chiffres manuscrits, classées dans des dossiers de "0" à "9". Il y a 60000 images dans le dossier training et 10000 images dans le dossier testing :
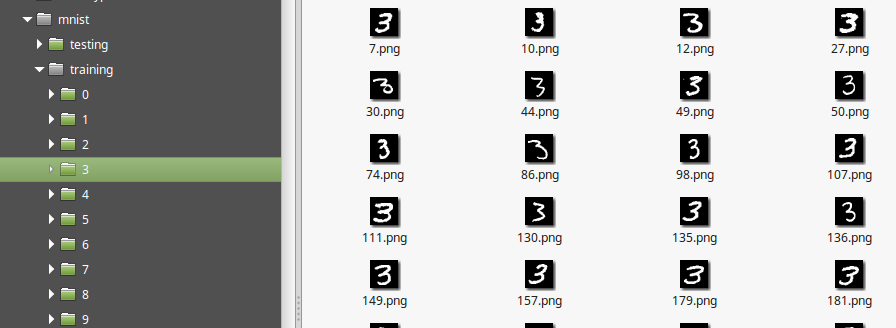 Images de la base de données MNIST
Images de la base de données MNIST
Chaque fichier est une image en niveaux de gris de 28x28. Nous utiliserons le contenu du dossier training pour préparer l'ensemble de données pour l'entraînement du modèle de réseau de neurones. Ensuite, nous utiliserons le contenu du dossier testing pour valider la précision du modèle entraîné. Avant de faire cela, nous devons convertir ces données brutes en ensembles de données.
Pour continuer, exécutez le notebook Jupyter et créez un nouveau notebook, en sélectionnant "Julia" comme langage. Ensuite, copiez les dossiers training et testing avec les images dans le dossier dans lequel vous avez créé le notebook.
Comment travailler avec les images dans Julia
Une image n'est pas un format de données naturel pour les modèles de machine learning. Les modèles ne comprennent que les nombres. C'est pourquoi, pour préparer les images pour le machine learning, vous devez les charger et les convertir en nombres.
Pour travailler avec les images dans Julia, nous utiliserons la bibliothèque Julia Images. En utilisant cette bibliothèque, vous pouvez charger l'image, la convertir en matrice de pixels, et appliquer différentes transformations qui peuvent être requises avant de la pousser vers le ML. Les transformations incluent le redimensionnement, la conversion de couleur en noir et blanc, l'inversion, le recadrage, et plus encore.
Pour commencer à travailler avec ces fonctions, vous devez installer le package Images et l'importer dans votre notebook :
using Pkg
Pkg.add("Images")
using Images
Comment charger et afficher l'image
Vous pouvez utiliser la fonction load pour charger l'image. Chargeons le premier chiffre de notre ensemble de données d'entraînement. Si ce fichier existe, il devrait le charger dans la variable img et afficher l'image elle-même :
img = load("training/0/1.png")
 Image de chiffre chargée
Image de chiffre chargée
C'est un chiffre chargé. Voyons la forme de la variable img :
size(img)
(28,28)
Comme vous pouvez le voir, la variable img est un tableau 2D ou une matrice de pixels d'image. La première dimension du tableau est un nombre de lignes et la deuxième dimension est un nombre de colonnes. C'est pourquoi la hauteur de l'image est la première valeur et la largeur de l'image est la deuxième valeur.
Voyons maintenant le type de cette variable :
typeof(img)
Matrix{Gray{N0f8}} (alias pour Array{Gray{Normed{UInt8, 8}}, 2})
Cela montre que c'est une matrice d'objets "Gray". Le type Gray définit un pixel gris. Cela signifie que l'image que nous avons chargée n'a pas d'information de couleur.
Le type de données Gray définit le pixel par une seule valeur – l'intensité de la couleur grise dans une plage entre 0 et 1. Donc, le 0 est complètement noir et le 1 est complètement blanc.
Vous pouvez changer la couleur de n'importe quel pixel en utilisant le code suivant :
img[5,5] = Gray(0.5)
De cette façon, vous définissez la couleur grise moyenne pour le pixel spécifié (qui était précédemment noir).
![]() L'image avec le pixel modifié
L'image avec le pixel modifié
Si vous chargez une image en couleur complète et demandez son type, elle affichera quelque chose comme ceci :
Matrix{RGB{N0f8}} (alias pour Array{RGB{Normed{UInt8, 8}}, 2})
Dans ce cas, chaque pixel a un type RGB qui est défini par 3 valeurs : l'intensité du Rouge, l'intensité du Vert et l'intensité du Bleu. De plus, si vous exécutez size(img) pour une image colorée, vous verrez que c'est un tableau 3D, comme ceci :
(3,28,28)
où la première dimension est un nombre de canaux de couleur, la deuxième dimension est une hauteur et la troisième dimension est une largeur.
En d'autres termes, cette image en couleur se compose de trois matrices de taille 28x28. Chacune d'elles contient les intensités de la couleur appropriée.
Pour définir la couleur de n'importe quel pixel dans cette image, vous devez spécifier les intensités des 3 canaux dans le constructeur de type RGB :
img[5,5] = RGB(1,0.5,0)
Ce code définit la couleur du pixel en orange.
Comment implémenter les transformations d'image de base
Parce que l'image est un tableau, vous pouvez utiliser la syntaxe de tableau pour accéder à n'importe quelle partie de l'image ou même à des pixels individuels.
Par exemple, vous pouvez exécuter ceci pour extraire les 10 premières lignes et 20 colonnes de cette image et les écrire dans la nouvelle image :
img2 = img[1:10,1:20]
 Partie de l'image
Partie de l'image
Vous pouvez recadrer l'image de 5 pixels de tous les côtés :
img3 = img[5:22,5:22]
 Image recadrée
Image recadrée
Vous pouvez appliquer différents filtres à l'image en appliquant la fonction spécifiée à chaque élément de la matrice, en utilisant la fonctionnalité de diffusion Julia via la syntaxe "point".
Par exemple, ce code applique la fonction Gray à chaque pixel de l'image. Cette approche peut être utilisée pour convertir les images de couleur en niveaux de gris :
img4 = Gray.(img)
De même, vous pouvez convertir les images en niveaux de gris en images colorées :
img5 = RGB.(img)
Vous pouvez appliquer des fonctions personnalisées à chaque pixel. Par exemple, si vous appliquez la fonction anonyme suivante à l'image en niveaux de gris de cette manière :
img6 = (x-> Gray(1)-x.val).(img)
elle inversera les couleurs de l'image en soustrayant la valeur de couleur de chaque pixel de 1. Si img a un chiffre blanc sur un fond noir, alors img6 aura un chiffre noir sur un fond blanc :
 Image inversée
Image inversée
Enfin, pour redimensionner l'image, vous pouvez utiliser la fonction imresize. Par exemple, pour redimensionner img à 50x50 pixels, vous pouvez utiliser le code suivant :
img6 = imresize(img,(50,50))
Nous n'utiliserons que les fonctionnalités décrites ci-dessus pour préparer les images pour la reconnaissance de chiffres manuscrits. Mais le module Images a beaucoup plus de choses intéressantes et amusantes. Regardez cette vidéo pour en voir certaines. De plus, vous pouvez trouver beaucoup d'informations intéressantes dans ce livre.
Comment convertir l'image en matrice numérique
La dernière étape de prétraitement de l'image consiste à convertir les pixels en nombres, car les objets de type Gray() ou RGB() ne conviennent pas comme entrée pour le modèle de machine learning.
Vous pouvez le faire en deux étapes. Tout d'abord, vous devez appliquer la fonction channelview à l'image pour obtenir la vue matricielle de l'objet image, puis convertir le résultat en nombres flottants. Donc, si vous exécutez cette commande :
data = Float32.(channelview(img))
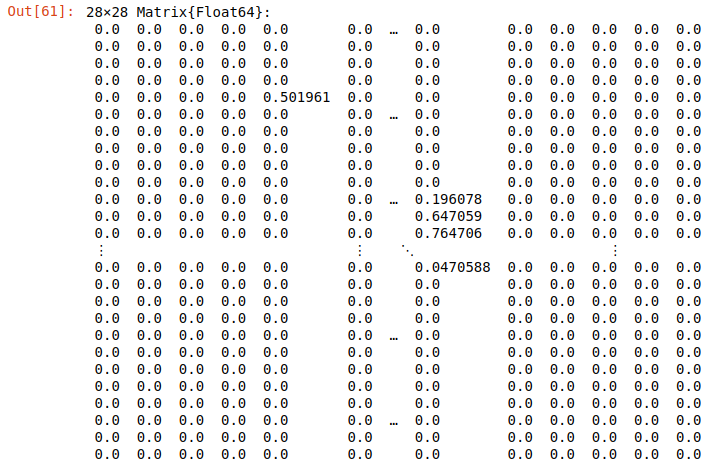 Matrice d'image
Matrice d'image
vous obtiendrez la matrice, où chaque valeur est un nombre flottant qui représente une intensité du pixel correspondant. Ces données sont prêtes à être envoyées au réseau de neurones.
Comment préparer les données d'image pour le machine learning
Comme je l'ai écrit dans un article précédent, l'ensemble de données d'entraînement doit être composé de données provenant de la matrice de caractéristiques et du vecteur d'étiquettes. Les deux doivent contenir uniquement des nombres.
Revenons à nos collections d'images dans les dossiers training et testing. Les étiquettes sont les noms des sous-dossiers où les images sont situées. Elles sont déjà des nombres. Les caractéristiques d'une image sont les pixels. Chaque pixel est défini par son intensité de couleur.
Ainsi, pour créer un ensemble de données prêt pour l'entraînement à partir du dossier d'images, vous devez lire tous les fichiers de tous les sous-dossiers, les convertir en matrices de nombres flottants, et les placer dans le tableau.
path = "training"
X = []
y = []
for label in readdir(path)
for file in readdir("$path/$label")
img = load("$path/$label/$file")
data = reshape(Float32.(channelview(img)),28,28,1)
if length(X) == 0
X = data
else
X = cat(X,data,dims=3)
end
push!(y,parse(Float32,label))
end
end
Assurez-vous que les dossiers "training" et "testing" avec les images MNIST existent dans le dossier courant avant d'exécuter ce programme. Il faudra un certain temps pour exécuter ce code, car il chargera 60000 images et les convertira en matrices.
Dans la boucle externe, il lit le contenu du dossier "training". Il y a des sous-dossiers avec des noms de 0 à 9 qui seront utilisés comme étiquettes.
Ensuite, dans la boucle interne, il lit tous les fichiers d'image de chacun de ces sous-dossiers en utilisant la fonction load du package Images.
Ensuite, il convertit chaque image en matrice d'intensités de couleur et la place dans la variable data. Après cela, il ajoute cette matrice à X.
Enfin, il ajoute le nom du sous-dossier (qui est un chiffre réel) au vecteur d'étiquettes y.
De cette façon, vous aurez un ensemble de données avec une matrice de caractéristiques dans X et un vecteur d'étiquettes dans y. Refactorisons ce code en une fonction pour pouvoir le réutiliser pour convertir n'importe quel dossier avec des images, classées de cette manière, en ensemble de données.
using Images
function createDataset(path)
X = []
y = []
for label in readdir(path)
for file in readdir("$path/$label")
img = load("$path/$label/$file")
data = reshape(Float32.(channelview(img)),28,28,1)
if length(X) == 0
X = data
else
X = cat(X,data,dims=3)
end
push!(y,parse(Float32,label))
end
end
return X,y
end
En utilisant cette fonction, vous pouvez maintenant facilement créer des ensembles de données d'entraînement et de test :
x_train, y_train = createDataset("training")
x_test, y_test = createDataset("testing")
Comment créer un modèle de machine learning
Nous utiliserons un réseau de neurones pour créer un modèle et l'entraîner en utilisant les données d'entraînement. Pour travailler avec les réseaux de neurones, nous utiliserons le Framework Flux.jl qui vous permet de créer et d'entraîner des réseaux de neurones de divers types, y compris les réseaux feed forward, convolutionnels et récurrents.
Pour la classification d'images manuscrites, nous implémenterons à la fois les réseaux Feed Forward et Convolutionnel et comparerons leur précision. Si nécessaire, vous pouvez réviser les bases des réseaux de neurones en regardant cette vidéo. C'est le meilleur moment pour regarder cela avant de continuer la lecture.
Bases des réseaux de neurones
Un réseau de neurones est une chaîne de couches. Chaque couche a un nombre défini de neurones avec des entrées et des sorties.
Pour convertir l'entrée en sortie pour chaque couche, les neurones utilisent la fonction d'activation, définie pour cette couche. Les caractéristiques de l'image sont les entrées de la première couche, et les résultats de classification sont les sorties de la dernière couche.
La meilleure façon de comprendre tout cela est de visualiser une architecture de réseau de neurones. Regardons le réseau de neurones de base suivant de 3 couches :
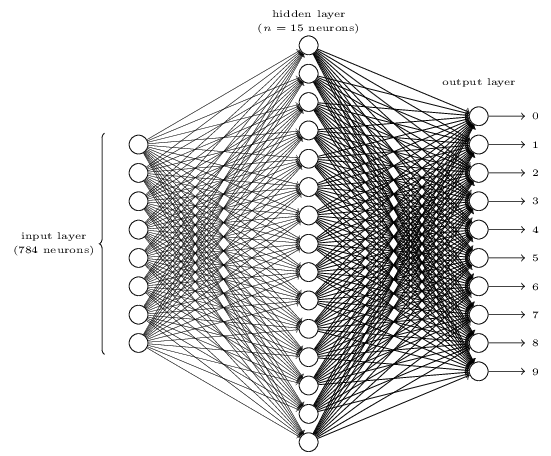 Réseau de neurones feed forward pour la reconnaissance de chiffres. Source : http://neuralnetworksanddeeplearning.com/chap1.html
Réseau de neurones feed forward pour la reconnaissance de chiffres. Source : http://neuralnetworksanddeeplearning.com/chap1.html
Dans cette image, la couche d'entrée contient 784 neurones qui doivent recevoir les caractéristiques de chaque image. Comme vous vous en souvenez, l'ensemble de données d'entraînement se compose d'images de 28x28, ce qui fait 784 pixels. Voici comment fonctionne ce réseau de neurones :
- La valeur de couleur de chaque pixel va à chaque neurone de la couche d'entrée.
- Chaque neurone de la couche d'entrée envoie sa valeur à chaque neurone de la couche cachée.
- Chaque neurone de la couche cachée a un coefficient de poids pour chaque entrée. Par défaut, ces coefficients sont des nombres aléatoires. Ainsi, chaque neurone de la couche cachée reçoit les valeurs d'entrée de la couche précédente et multiplie chaque entrée par le poids approprié, résume ces produits et applique la fonction d'activation à cette somme.
- Chaque neurone de la couche cachée envoie la somme résultante à chaque neurone de la couche de sortie, qui a 10 neurones.
- La couche de sortie fait exactement la même chose pour chaque valeur d'entrée que la couche précédente et accumule finalement une certaine somme à l'intérieur.
- Cette somme est traitée comme une probabilité du chiffre approprié, par exemple, le premier neurone doit contenir la probabilité que l'image d'entrée soit "0", le deuxième neurone doit contenir la probabilité que l'image soit "1", et ainsi de suite.
Ensuite, l'application doit regarder lequel de ces 10 neurones a la valeur la plus élevée et faire la prédiction appropriée.
Comment créer le réseau de neurones avec Flux
Créons ce réseau de neurones en utilisant Flux. Si vous ne l'avez pas encore installé et importé, faites-le dans votre notebook :
using Pkg
Pkg.add("Flux")
using Flux
Comme vous l'avez vu, le réseau de neurones est une chaîne de couches avec différents paramètres. Ainsi, Flux a une fonction Chain que vous utilisez pour construire des réseaux de neurones. Construisons ce réseau :
model = Chain(
Flux.flatten,
Dense(784=>15,relu),
Dense(15=>10,sigmoid),
softmax
)
La Chain reçoit un tableau de fonctions comme arguments. Chaque fonction définit une couche et ses paramètres. Chacune de ces fonctions reçoit certaines entrées, puis après les actions appropriées, retourne les sorties et les transmet comme entrées à la fonction suivante dans la chaîne.
Ainsi, voici comment fonctionne le réseau de neurones défini :
- L'image d'entrée, qui est un tableau de 28x28 d'intensités de couleur de pixels, arrive à la fonction
Flux.flatten. Cette fonction convertit simplement cette matrice de 28x28 en un vecteur avec 784 éléments. De cette façon, nous avons construit l'entrée pour la première couche Dense. - Ensuite, la fonction Dense suivante reçoit 784 valeurs par 15 neurones. Ensuite, elle multiplie ces valeurs par des poids, résume ces produits, applique la fonction d'activation
[relu](https://fluxml.ai/Flux.jl/stable/models/activation/#NNlib.relu)à cette somme, et transmet ces 15 valeurs à 10 neurones de la couche suivante. - Ensuite, la couche dense multiplie également chacune des 15 entrées par les coefficients de poids, les résume et applique la fonction d'activation
sigmoidpour convertir ces sommes en fractions de 1. - La fonction finale
[softmax](https://en.wikipedia.org/wiki/Softmax_function)ne construit pas réellement une nouvelle couche, mais elle convertit simplement les valeurs qui se sont accumulées dans les 10 neurones de la couche de sortie en probabilités correctes pour montrer correctement la distribution de probabilité. L'application de cette fonction garantit que la somme de toutes les 10 probabilités est égale à 1. Le tableau de ces probabilités sera retourné par le modèle comme résultat.
Vous pouvez appeler le model que vous venez de créer comme une fonction en passant une matrice d'image comme argument d'entrée.
Vous pouvez exécuter le modèle pour prédire le chiffre pour la première image de l'ensemble de données d'entraînement en utilisant le code suivant :
predict = model(Flux.unsqueeze(x_train[:,:,1],dims=3))
Nous utilisons la fonction [unsqueeze](https://fluxml.ai/Flux.jl/stable/utilities/#Flux.unsqueeze) ici pour convertir l'image sans canaux de la forme (28,28) en une image à canal unique de la forme (28,28,1).
C'est une règle importante pour le traitement des réseaux de neurones profonds – que l'image est quelque chose qui a une largeur, une hauteur et des canaux de couleur. Donc, même si elle n'a qu'un seul canal, il doit être spécifié.
La fonction du modèle reçoit la matrice d'image d'entrée, la fait passer à travers une chaîne de couches et retourne le tableau des probabilités.
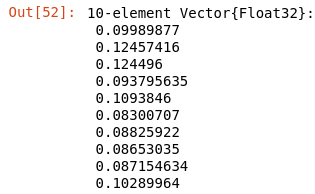 Probabilités du nouveau réseau de neurones
Probabilités du nouveau réseau de neurones
Comme vous pouvez le voir, le neurone numéro 2 a la probabilité la plus élevée (0.12457416), ce qui signifie que le modèle a prédit le chiffre "1". Cependant, si vous vérifiez la vraie réponse dans le vecteur d'étiquettes :
y_train[1]
vous verrez "0", donc la prédiction est incorrecte. Cela est dû au fait que ce modèle n'est pas entraîné et utilise simplement des poids aléatoires pour calculer la sortie pour chaque couche. Vous devez l'entraîner pour ajuster ces poids et calculer une probabilité plus précise.
Comment entraîner le modèle
Flux.jl propose différentes approches pour entraîner un modèle. La plus évidente est la fonction [Flux.train](https://fluxml.ai/Flux.jl/stable/training/reference/#Flux.Optimise.train!-NTuple{4,%20Any}). La fonction exécute le processus d'entraînement suivant :
- La fonction reçoit l'ensemble de données d'entraînement comme argument, y compris la matrice des caractéristiques et le vecteur des étiquettes.
- La fonction exécute le
modelpour chaque ligne de l'ensemble de données d'entraînement et reçoit le tableau de probabilités résultant. - La fonction compare ces probabilités avec les valeurs réelles du vecteur des étiquettes et calcule la quantité d'erreur (à ce sujet plus tard).
- En utilisant les informations sur l'erreur, la fonction ajuste les poids et le biais pour chaque neurone de chaque couche.
Habituellement, vous devez exécuter ce processus d'entraînement plusieurs fois dans une boucle. À chaque itération, il ajustera les poids pour chaque neurone, diminuant de plus en plus la valeur de l'erreur.
Cette visualisation montre comment le processus d'entraînement dans une boucle fonctionne pour un seul neurone sur une seule couche. Pour l'ensemble du réseau, il fonctionne de manière similaire.
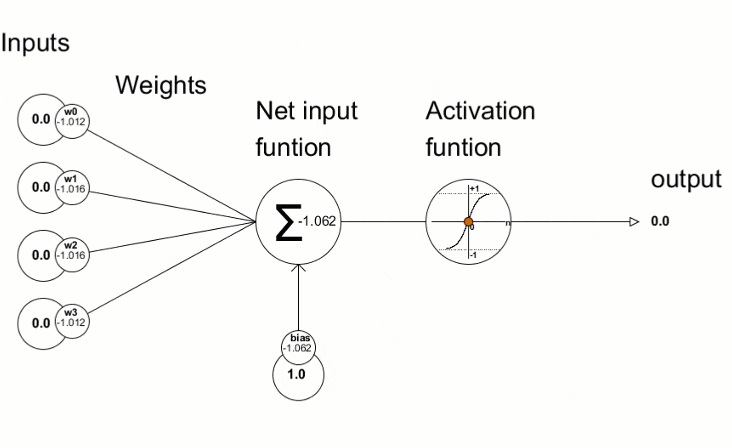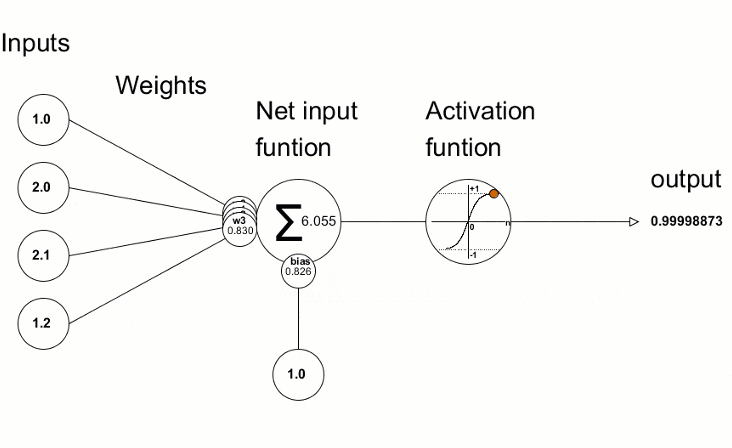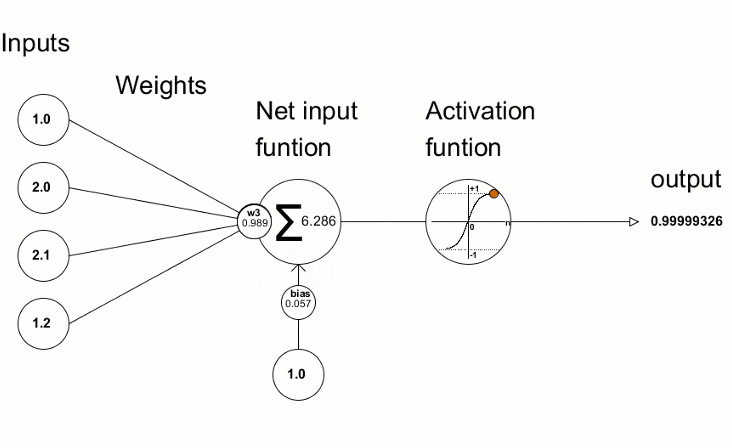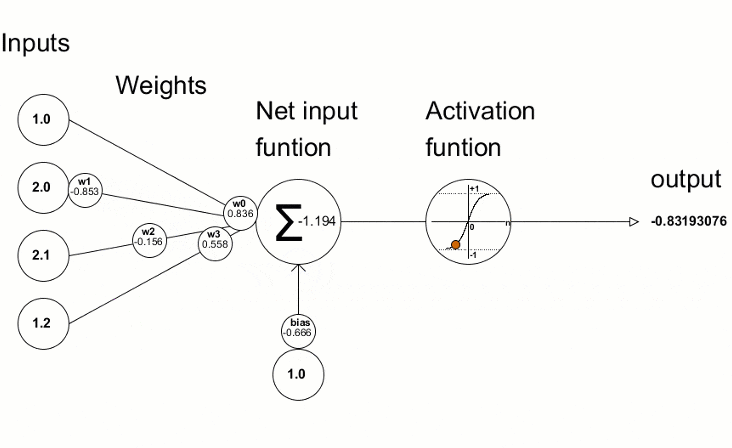 Le processus d'entraînement dans une boucle pour un seul neurone
Le processus d'entraînement dans une boucle pour un seul neurone
Voici la syntaxe de la fonction train :
Flux.train!(loss_function, model, data, optimizer)
Décomposons cela :
loss_function– comme je l'ai décrit précédemment, pendant le processus d'entraînement, la fonctiontrainmesure la quantité d'erreur. Pour ce faire, elle utilise laloss_function, que vous devez définir et fournir ici.
Cette fonction reçoit le modèle, la ligne des données d'entraînement et l'étiquette de vérité. Sur la base de ces arguments, la fonction de perte doit faire une prédiction en passant la ligne de données à travers le modèle, comparer cette prédiction avec l'étiquette de vérité, calculer la différence entre elles et retourner la quantité d'erreur sous forme de nombre flottant.
Il existe différents algorithmes pour calculer la quantité d'erreur pour différents types de problèmes de machine learning. Pour les problèmes de classification, nous utiliserons l'entropie croisée (cross entropy).
model– le modèle de réseau de neurones à entraîner.data– les données d'entraînement qui incluent à la foisx_trainety_trainassemblées en un seul tableau de tuples. Vous pouvez le faire simplement en utilisant la fonction[Flux.DataLoader](https://fluxml.ai/Flux.jl/v0.10/data/dataloader/), que nous utiliserons ci-dessous.optimizer– comme décrit ci-dessus, après avoir mesuré la quantité d'erreur, la fonction ajuste les poids pour diminuer l'erreur. Les poids ne sont pas ajustés de manière aléatoire, mais par l'optimizerqui définit l'algorithme. Vous l'utilisez pour ajuster les poids dans la bonne direction.
La plupart des algorithmes d'ajustement des poids sont basés sur la Descente de Gradient. En particulier, nous utiliserons l'optimiseur ADAM, qui est très courant aujourd'hui.
Relions toutes ces parties ensemble dans le code suivant :
# Assembler les données d'entraînement
data = Flux.DataLoader((x_train,y_train), shuffle=true)
# Initialiser l'optimiseur ADAM avec les paramètres par défaut
optimizer = Flux.setup(Adam(), model)
# Définir la fonction de perte qui utilise l'entropie croisée pour
# mesurer l'erreur en comparant les prédictions du modèle de la ligne de données "x"
# avec l'étiquette de données réelle dans "y"
function loss(model, x, y)
return Flux.crossentropy(model(x),Flux.onehotbatch(y,0:9))
end
# Entraîner le modèle 10 fois dans une boucle
for epoch in 1:10
Flux.train!(loss, model, data, optimizer)
end
Pour chaque ligne de données, Flux.train! appelle la fonction de perte, puis la fonction loss exécute le model. En utilisant l'entropie croisée, elle calcule la différence entre les prédictions et les valeurs réelles de cette ligne. Cette différence est retournée comme une erreur, puis l'optimizer est utilisé pour ajuster les poids des neurones du modèle en fonction de cette valeur d'erreur et de la fonction loss. À chaque itération, la valeur d'erreur devrait diminuer.
Enfin, après avoir exécuté le processus d'entraînement, vous pouvez vérifier comment il prédit le chiffre pour la première image en utilisant le modèle entraîné :
predict = model(Flux.unsqueeze(x_train[:,:,1],dims=3))
Lorsque je l'ai fait, j'ai reçu les probabilités suivantes :
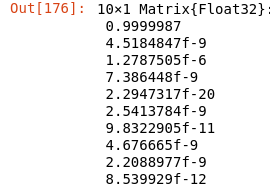 Probabilités du modèle entraîné
Probabilités du modèle entraîné
La première, liée à "0" est la plus élevée et c'est définitivement vrai. Vous pouvez essayer de vérifier d'autres images, comme l'image numéro 100 ou 200. Mais cela n'a pas beaucoup de sens de mesurer la qualité du modèle de cette manière, car ce sont des données d'entraînement que le modèle a déjà vues. Seules les données de test doivent être utilisées pour mesurer la précision du modèle.
Comment évaluer la précision du modèle entraîné
Nous avons l'ensemble de données de test dans la matrice de caractéristiques x_test et dans le vecteur d'étiquettes y_test. Nous allons exécuter le model pour chaque ligne de ces données et mesurer la précision : le nombre de prédictions correctes divisé par le nombre total de prédictions.
Créons une fonction pour cela :
function accuracy()
correct = 0
for index in 1:length(y_test)
probs = model(Flux.unsqueeze(x_test[:,:,index],dims=3))
predicted_digit = argmax(probs)[1]-1
if predicted_digit == y_test[index]
correct +=1
end
end
return correct/length(y_test)
end
La fonction parcourt tous les éléments de l'ensemble de données de test. Pour chaque élément, elle exécute le modèle et reçoit le tableau probs. Ensuite, elle écrit un index de la probabilité la plus élevée en utilisant la fonction [argmax](https://docs.julialang.org/en/v1/base/collections/#Base.argmax) dans la variable predicted_digit. Ensuite, elle compare le chiffre prédit avec la valeur de vérité du vecteur d'étiquettes y_test et augmente le nombre de prédictions correctes s'ils correspondent. La fonction retourne le quotient du nombre de prédictions correctes et du nombre total de lignes.
Vous pouvez maintenant exécuter cette fonction pour voir la précision. Par exemple, lorsque je l'ai exécutée, j'ai obtenu 0.9455, ce qui est environ 94.6%.
Cependant, il est préférable de placer cet appel de fonction à l'intérieur de la boucle d'entraînement, juste après la ligne Flux.train! pour voir comment la précision change après chaque itération d'entraînement.
for epoch in 1:10
Flux.train!(loss, model, data, optimizer)
println(accuracy())
end
Ensuite, relancez l'entraînement. Vous devriez recevoir une sortie similaire à celle-ci :
 Précision du réseau de neurones
Précision du réseau de neurones
Cela montre que la précision augmentait jusqu'à la 6ème itération. Depuis lors, elle a commencé à diminuer, ce qui pourrait être un signe que le modèle a commencé à surajuster.
Pour augmenter la qualité de prédiction, vous pouvez soit ajouter plus de données à l'ensemble de données d'entraînement, soit changer l'architecture du modèle.
Par exemple, vous pouvez ajouter plus de couches Dense, augmenter le nombre de neurones sur la couche cachée, ou changer les fonctions d'activation de relu à sigmoid ou vice versa.
Lorsque j'ai augmenté le nombre de neurones de 15 à 42 sur la couche cachée et ensuite supprimé l'activation sigmoid de la couche de sortie, j'ai atteint environ 97% de précision. Mais lorsque j'ai ajouté une autre couche cachée avant la sortie, la précision est tombée à 90%.
Ainsi, la construction de l'architecture du réseau de neurones est comme un art – vous devez essayer différentes options de nombreuses fois et finalement sélectionner celle qui fonctionne le mieux.
Quelles que soient les options que j'ai choisies, je n'ai jamais pu obtenir plus de 97%. De plus, lorsque j'ai finalement essayé d'utiliser cette architecture de réseau en production avec de vrais chiffres manuscrits des utilisateurs, la qualité de prédiction était médiocre. Très souvent, il ne pouvait pas reconnaître correctement le chiffre 7, et il reconnaissait 1 comme 4 et 6 comme 5.
Cela est dû au fait que l'utilisation du réseau de neurones feed forward, dans lequel nous mettons simplement tous les 784 pixels de l'image comme entrée sans aucun filtre, n'est pas la meilleure approche.
Pour la plupart des tâches de machine learning avec des images, les réseaux de neurones Convolutionnels sont la meilleure option. Nous allons créer et essayer celui-ci dans la section suivante.
Comment créer et entraîner le réseau de neurones convolutionnel
L'étape la plus importante pendant le processus de machine learning est le prétraitement des données. Si les caractéristiques d'entrée sont traitées correctement, alors la précision de prédiction sera meilleure.
Pour augmenter la qualité du modèle, vous devez supprimer le bruit des données, ou les caractéristiques qui ne sont pas pertinentes pour la valeur que vous devez prédire.
De plus, souvent, vous devez créer de nouvelles caractéristiques à partir de celles existantes qui pourraient être plus pertinentes pour le résultat.
Par exemple, pour le problème de machine learning du Titanic, vous pouvez supprimer des caractéristiques telles que "ID du passager" et "Nom du passager", car elles ne peuvent pas aider à prédire si le passager pourrait survivre ou non.
De plus, si vous avez une tâche de prédiction du prix d'un appartement et que vous avez des données d'entrée avec des champs de surfaces de pièces comme "Surface 1", "Surface 2" et ainsi de suite, vous pouvez créer un nouveau champ "Surface totale de l'appartement" et y écrire la somme de toutes les surfaces de pièces.
Peut-être que cette nouvelle caractéristique que vous avez générée est plus pertinente que les autres pour le modèle, donc vous pouvez supprimer les champs à partir desquels vous avez généré cette nouvelle colonne.
En utilisant ces techniques, vous généralisez les données en conservant et en créant les caractéristiques qui sont importantes et en supprimant les autres qui ne peuvent que confondre le modèle de machine learning.
Lorsque vous travaillez avec des données tabulaires, vous pouvez utiliser votre propre expérience ou des méthodes statistiques pour trouver quelles caractéristiques générer ou supprimer des données d'entrée. Mais lorsque vous travaillez avec des images, les choses ne sont pas aussi claires qu'avec des chaînes ou des nombres.
Par exemple, le modèle pour la tâche de reconnaissance de chiffres manuscrits reçoit les 784 couleurs de pixels en une seule ligne comme entrée. Ils ont une valeur égale d'un point de vue humain, et il est inconnu lesquels d'entre eux sont plus importants et lesquels le sont moins.
Pour vous aider dans cela, vous pouvez utiliser des réseaux de neurones convolutionnels pour prétraiter ce type de données. Ils vous aident à faire l'ingénierie des caractéristiques automatiquement.
Vous construisez un réseau de neurones convolutionnel à partir de deux types de couches :
- Couches de convolution utilisées pour générer de nouvelles caractéristiques à partir des pixels de l'image d'entrée.
- Couches de pooling utilisées pour généraliser les caractéristiques en utilisant certaines règles et ainsi réduire leur quantité.
En combinant ces deux types de couches dans la chaîne, vous pouvez prétraiter la matrice d'image d'entrée pour recevoir un nombre réduit des caractéristiques les plus précieuses. Ensuite, vous pouvez entraîner le réseau en utilisant ces caractéristiques générées comme données d'entrée de la même manière que vous l'avez fait auparavant.
Je pense qu'il est difficile de décrire les CNNs mieux que ce qui est fait dans cette vidéo, donc je recommande vivement de la regarder (ou au moins les 15 premières minutes) avant de continuer. Elle explique clairement les aspects théoriques de toutes les étapes que vous allez faire ci-dessous.
Ainsi, passons en revue le réseau de neurones que vous avez maintenant :
model = Chain(
Flux.flatten,
Dense(784=>15,relu),
Dense(15=>10,sigmoid),
softmax
)
La seule étape de prétraitement des données ici est Flux.flatten, qui reçoit l'image de 28x28 pixels et la retourne jointe en une seule ligne de 784 nombres. Nous devons ajouter quelques couches de convolution avant Flux.flatten pour donner à notre réseau la capacité de générer de meilleures caractéristiques que de simples pixels bruts.
Pour créer la couche de convolution, Flux.jl a la fonction [Conv](https://fluxml.ai/Flux.jl/stable/models/layers/#Flux.Conv) avec les principaux paramètres suivants :
Conv(filter,in=>out,activation_function)
- filter définit les dimensions de la matrice du noyau qui sera appliquée à chaque pixel de la matrice d'entrée pour créer une caractéristique à partir de celui-ci. Par exemple, la valeur (3,3) définit la matrice du noyau de 3x3. Voici comment la convolution utilisant cette matrice du noyau fonctionne pour générer les caractéristiques pour une image de taille 6x6 :
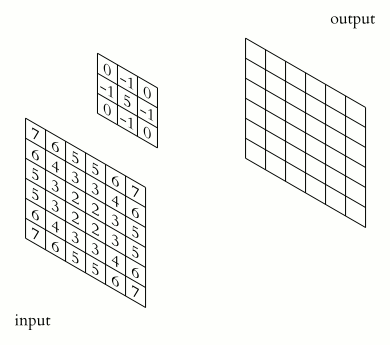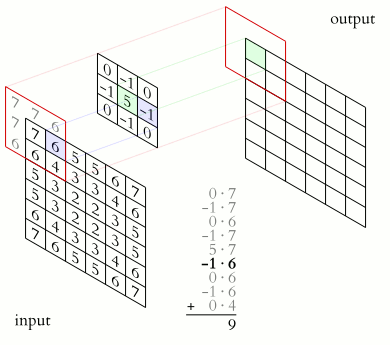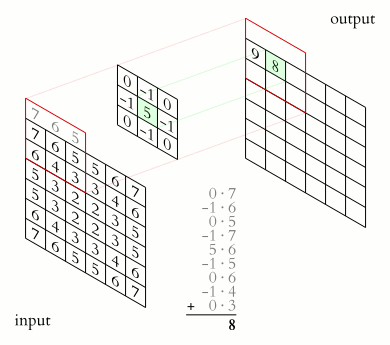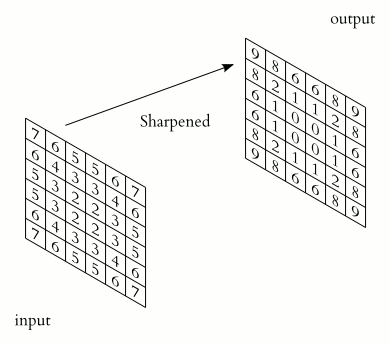 Comment fonctionne la couche de convolution
Comment fonctionne la couche de convolution
- in est le nombre de canaux de l'image d'entrée. Pour nos données d'entrée, les images en niveaux de gris ont un seul canal. Pour les autres couches, le nombre de canaux in de la couche actuelle doit être égal aux canaux out de la couche précédente.
- out est le nombre de canaux de sortie après l'application de la convolution. En d'autres termes, c'est un nombre de caractéristiques qui seront générées pour chaque pixel.
- activation_function est la fonction qui sera appliquée à chaque caractéristique après la convolution et avant l'envoi à la couche suivante du réseau, comme nous l'avons fait auparavant pour les couches
Dense.
Par exemple, si vous ajoutez la couche Conv suivante au-dessus des autres à la Chain :
model = Chain(
Conv((5,5),1=>6,relu),
Flux.flatten,
Dense(4704=>15,relu),
Dense(15=>10,sigmoid),
softmax
)
ce réseau recevra une image à canal unique de la forme suivante : (28,28,1). Il produira 6 matrices à partir de cette image en appliquant différents noyaux de convolution de 5x5 aux données d'entrée.
La sortie de cette couche sera l'image de la forme suivante : (28,28,6). En d'autres termes, cette couche de convolution générera 28286 = 4704 caractéristiques à partir de 784 pixels d'entrée pour notre réseau.
Mais si vous avez plus de caractéristiques, cela ne signifie pas qu'elles sont toutes bonnes. Peut-être devez-vous les généraliser et ne garder que les plus précieuses. C'est pourquoi les couches de pooling sont créées.
Dans Flux.jl, la couche de pooling peut être définie en utilisant la fonction [MaxPool](https://fluxml.ai/Flux.jl/stable/models/layers/#Flux.MaxPool). Elle reçoit les dimensions de la fenêtre de pooling comme argument.
Par exemple, si vous créez la couche MaxPool suivante :
MaxPool((2,2))
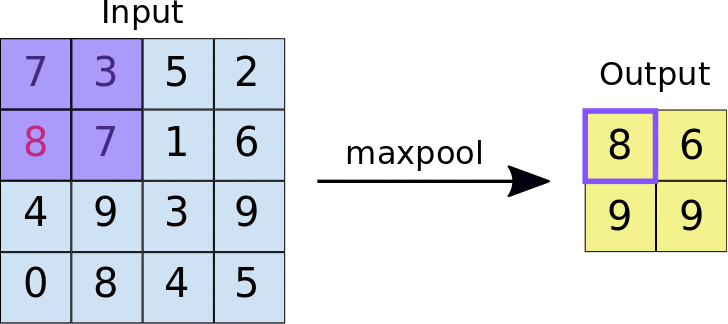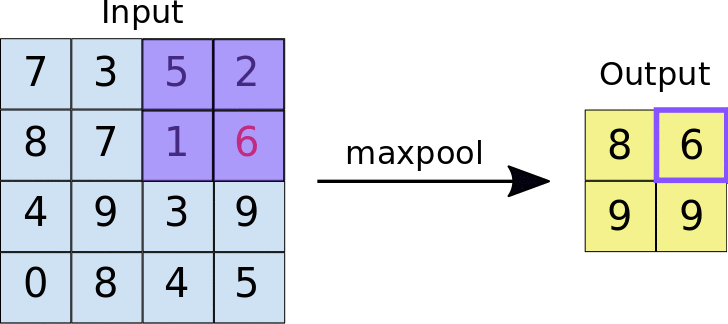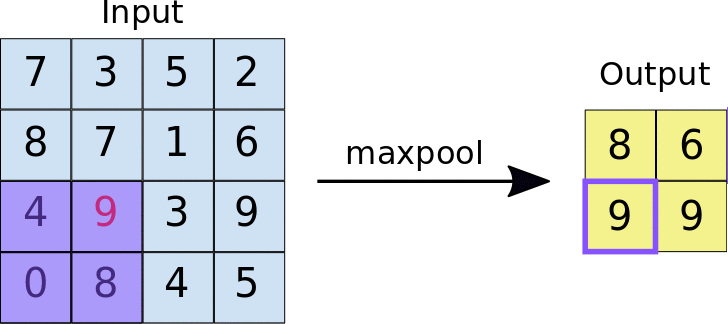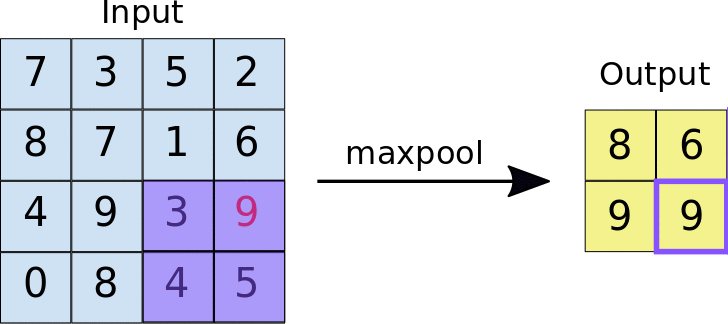 Comment fonctionne la couche Max pool
Comment fonctionne la couche Max pool
elle appliquera la fenêtre de pooling de 2x2 à l'image d'entrée. Comme vous pouvez le voir, pour chaque fenêtre, elle sélectionne la valeur maximale et l'ajoute à la sortie. De cette façon, elle réduit les données d'entrée en ne laissant que les maximums. C'est pourquoi elle est appelée la couche MAX pool.
Ajoutons la couche MaxPool à la chaîne :
model = Chain(
Conv((5,5),1=>6,relu),
MaxPool((2,2)),
Flux.flatten,
Dense(1176=>15,relu),
Dense(15=>10,sigmoid),
softmax
)
Ainsi, le MaxPool reçoit l'image de taille (28,28,6) de la couche de convolution, applique la fenêtre de max pool de 2x2 et produit une image de (14,14,6). Après cela, les 14146=1176 caractéristiques généralisées sont transmises aux couches du réseau ci-dessous.
La question principale est de savoir comment connaître le nombre de couches de convolution et de max pool à ajouter, et quels paramètres définir pour chacune d'elles afin d'obtenir une bonne précision de prédiction.
Eh bien, la première façon est d'essayer différentes options. Mais pour construire une bonne architecture de réseau de neurones de cette manière, cela pourrait prendre des jours, des mois, voire des années.
Heureusement, pour de nombreuses tâches de machine learning, cela a déjà été fait par d'autres personnes. Vous pouvez trouver des architectures adaptées à la plupart de vos problèmes, y compris le modèle pour la reconnaissance de chiffres manuscrits.
L'architecture la plus connue pour cette tâche a été créée par Yann LeCun, et elle est nommée LeNet. Vous pouvez trouver une description complète et des implémentations de ce modèle pour différentes plateformes ML ici. Il a été créé exactement pour les images de chiffres du jeu de données MNIST. Il est relativement ancien, mais toujours utilisé dans de nombreux guichets automatiques pour reconnaître les chiffres lors du traitement des dépôts.
Voici à quoi ressemble cette architecture :
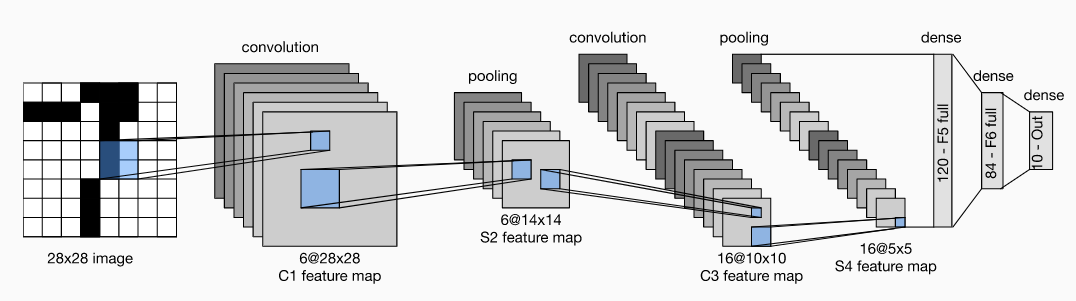 Architecture LeNet
Architecture LeNet
Tout comme le réseau que nous avons créé, celui-ci se compose d'une partie convolutionnelle et d'une partie feed forward. La partie réseau convolutionnel se compose de 2 couches Conv et 2 couches MaxPool. La partie réseau de neurones feed forward se compose de 3 couches denses.
Vous pouvez créer ce réseau en utilisant Flux.jl de cette manière :
model = Chain(
Conv((5,5),1 => 6, relu),
MaxPool((2,2)),
Conv((5,5),6 => 16, relu),
MaxPool((2,2)),
Flux.flatten,
Dense(256=>120,relu),
Dense(120=>84, relu),
Dense(84=>10, sigmoid),
softmax
)
Après avoir appliqué 2 convolutions et pooling à la matrice d'image d'entrée, la couche Flux.flatten reçoit l'image de 4x4x16 et la convertit en 4416=256 caractéristiques généralisées. Ensuite, elles passent par 3 couches denses pour enfin calculer les probabilités pour 10 chiffres.
Avant d'entraîner ce modèle en utilisant les données de x_train, vous devez le remodeler un peu. La couche de convolution s'attend à recevoir les données dans la forme 4-dimensionnelle suivante (largeur, hauteur, canaux, longueur), mais x_train a la forme suivante : (28,28,60000) qui est 60000 images de 28x28.
Pour le rendre compatible, vous devez le remodeler en (28, 28, 1, 60000). Vous pouvez le faire en utilisant le code suivant :
x_train = reshape(x_train, 28, 28, 1, :)
Vous devrez faire de même avec x_test :
x_test = reshape(x_test, 28, 28, 1, :)
Pour exécuter ce modèle, vous devez également passer une structure d'image à 4 dimensions à la fonction model. Par exemple, pour faire une prédiction pour la première image, vous pouvez exécuter ceci :
model(Flux.unsqueeze(x_test[:,:,:,1],dims=4))
Ensuite, vous pouvez entraîner le modèle de la même manière que vous l'avez fait auparavant.
Voici le code complet pour définir et entraîner le réseau convolutionnel :
# Créer un modèle LeNet
model = Chain(
Conv((5,5),1 => 6, relu),
MaxPool((2,2)),
Conv((5,5),6 => 16, relu),
MaxPool((2,2)),
Flux.flatten,
Dense(256=>120,relu),
Dense(120=>84, relu),
Dense(84=>10, sigmoid),
softmax
)
# Fonction pour mesurer la précision du modèle
function accuracy()
correct = 0
for index in 1:length(y_test)
probs = model(Flux.unsqueeze(x_test[:,:,:,index],dims=4))
predicted_digit = argmax(probs)[1]-1
if predicted_digit == y_test[index]
correct +=1
end
end
return correct/length(y_test)
end
# Redimensionner les données
x_train = reshape(x_train, 28, 28, 1, :)
x_test = reshape(x_test, 28, 28, 1, :)
# Assembler les données d'entraînement
train_data = Flux.DataLoader((x_train,y_train), shuffle=true)
# Initialiser l'optimiseur ADAM avec les paramètres par défaut
optimizer = Flux.setup(Adam(), model)
# Définir la fonction de perte qui utilise l'entropie croisée pour
# mesurer l'erreur en comparant les prédictions du modèle de
# la ligne de données "x" avec les données réelles de l'étiquette "y"
function loss(model, x, y)
return Flux.crossentropy(model(x),Flux.onehotbatch(y,0:9))
end
# Entraîner le modèle 10 fois dans une boucle
for epoch in 1:10
Flux.train!(loss, model, train_data, optimizer)
println(accuracy())
end
Après avoir exécuté ce code, j'ai obtenu environ 99% de précision, ce qui est proche de l'idéal :
 Précision du réseau convolutionnel
Précision du réseau convolutionnel
Il est maintenant temps de sauvegarder ce modèle dans un fichier et de le déplacer en production.
Comment exporter le modèle entraîné vers un fichier
Les modèles Flux.jl peuvent être sauvegardés dans des fichiers BSON. Vous devez importer le package BSON et utiliser la commande de macro @save pour exporter l'objet model :
using BSON
BSON.@save "digits.bson" model
Cela sauvegardera le modèle dans le fichier digits.bson dans le dossier courant.
C'est la fin de votre travail dans le notebook Jupyter. Nous implémenterons le code suivant en tant que nouvelle application.
Comment créer un frontend
L'application que vous allez créer permettra à un utilisateur d'écrire son numéro de téléphone et de le reconnaître en utilisant le modèle que vous avez créé et entraîné précédemment. La page frontend ressemblera à ceci :
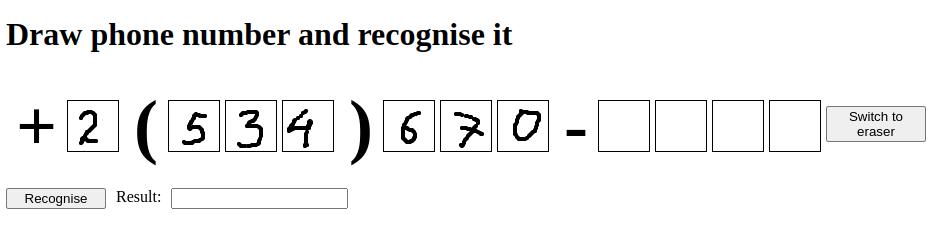 Frontend
Frontend
En utilisant cette interface, l'utilisateur peut dessiner les chiffres d'un numéro de téléphone dans les cases à l'aide de la souris, puis appuyer sur le bouton "Reconnaître" et afficher les chiffres reconnus dans le champ de saisie "Résultat".
Il y a également un bouton "Passer à la gomme". Lorsque l'utilisateur appuie dessus, le mode de dessin passe au mode gomme et l'utilisateur peut effacer n'importe quel chiffre dans n'importe quelle case.
Commençons à construire l'application web. Créez un nouveau dossier avec le nom que vous souhaitez. Ensuite, créez un fichier index.html et copiez le code suivant dans ce fichier :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Lecteur de téléphones</title>
</head>
<body>
<h1>Dessinez un numéro de téléphone et reconnaissez-le</h1>
<div class="digits">
<strong>+</strong>
<canvas width="50" height="50"></canvas>
<strong>(</strong>
<canvas width="50" height="50"></canvas>
<canvas width="50" height="50"></canvas>
<canvas width="50" height="50"></canvas>
<strong>)</strong>
<canvas width="50" height="50"></canvas>
<canvas width="50" height="50"></canvas>
<canvas width="50" height="50"></canvas>
<strong>-</strong>
<canvas width="50" height="50"></canvas>
<canvas width="50" height="50"></canvas>
<canvas width="50" height="50"></canvas>
<canvas width="50" height="50"></canvas>
<div class="buttons">
<button id="mode">Passer à la gomme</button>
</div>
</div>
<div class="result">
<button id="recognise">Reconnaître</button>
<label>Résultat :</label>
<input id="result"></div>
</div>
</body>
<script>
let mode = "brush";
// Gestionnaire du bouton "Switch". Passe du mode
// pinceau à gomme et vice versa
document.querySelector("#mode").addEventListener("click",() => {
if (mode === "brush") {
mode = "eraser";
event.target.innerHTML = "Passer au pinceau";
} else {
mode = "brush";
event.target.innerHTML = "Passer à la gomme";
}
});
// Gestionnaire de mouvement de souris des canvases de chiffres.
// Si le bouton de la souris est enfoncé pendant que l'utilisateur déplace la souris
// sur le canvas, il dessine des cercles à la position du curseur.
// Si mode="brush", les cercles sont noirs, sinon
// ils sont blancs
document.querySelectorAll("canvas").forEach(item => {
ctx = item.getContext("2d");
ctx.fillStyle="#FFFFFF";
ctx.fillRect(0,0,50,50);
item.addEventListener("mousemove", (event) => {
if (event.buttons) {
ctx = event.target.getContext("2d");
if (mode === "brush") {
ctx.fillStyle = "#000000";
} else {
ctx.fillStyle = "#FFFFFF";
}
ctx.beginPath();
ctx.arc(event.offsetX-1,event.offsetY-1,2,0, 2 * Math.PI);
ctx.fill();
}
})
})
// Gestionnaire du clic du bouton "Reconnaître". Capture
// le contenu de tous les canvases de chiffres sous forme de BLOB.
// Construit des fichiers à partir de ces blobs et
// les envoie au backend en tant que fichiers dans un
// formulaire multipart
document.querySelector("#recognise").addEventListener("click", async() => {
data = new FormData();
canvases = document.querySelectorAll("canvas");
const getPng = (canvas) => {
return new Promise(resolve => {
canvas.toBlob(png => {
resolve(png)
})
})
}
index = 0
for (let canvas of canvases) {
const png = await getPng(canvas);
data.append((++index)+".png",new File([png],index+".png"));
}
const response = await fetch("http://localhost:8080/api/recognize", {
body: data,
method: "POST"
})
document.querySelector("#result").value = await response.text();
})
</script>
<style>
body {
display:flex;
flex-direction: column;
justify-content: flex-start;
align-items: flex-start;
}
canvas {
border-width:1px;
border-color:black;
border-style: solid;
margin-right:5px;
cursor:crosshair;
}
.digits {
display:flex;
flex-direction: row;
align-items: center;
justify-content: flex-start;
}
.digits strong {
font-size: 72px;
margin:10px;
}
.buttons {
display:flex;
flex-direction: column;
justify-content: flex-start;
align-items: center;
}
button {
width:100px;
margin-bottom:5px;
margin-right:10px;
}
.result {
margin-top:10px;
display:flex;
flex-direction: row;
align-items: flex-start;
justify-content: flex-start;
}
input {
margin-left:10px;
}
</style>
</html>
La partie HTML de ce code contient 11 éléments HTML5 canvas qui affichent les cases où vous pouvez dessiner. Chaque case a une taille de 50x50 pixels et est remplie d'une couleur blanche. De plus, le HTML contient les boutons "Passer à ..." et "Reconnaître" ainsi que le champ de saisie "Résultat".
La partie JavaScript définit la variable globale "mode", qui est égale à "brush" par défaut. Lorsque l'utilisateur appuie sur le bouton "Passer à ...", il change le mode en "eraser". S'il appuie à nouveau, il revient à "brush".
Ensuite, le code JavaScript définit les gestionnaires d'événements "mousemove" pour toutes les cases de canvas. Si l'utilisateur appuie sur le bouton gauche de la souris en mode "brush" et déplace la souris dans la case, il dessine des cercles noirs à la position du curseur de la souris. De cette façon, l'utilisateur dessine les chiffres. Si le mode est "eraser", alors il dessine des cercles blancs. De cette façon, l'utilisateur peut effacer les marques noires.
Enfin, nous avons défini le gestionnaire de clic du bouton "Reconnaître". Lorsque l'utilisateur clique sur ce bouton, la fonction de gestionnaire collecte 11 images de chiffres à partir des éléments canvas et les convertit en objets BLOB au format d'image PNG.
Ensuite, il crée une requête POST, place ces 11 images de chiffres dedans en tant que fichiers avec les noms 1.png, 2.png et ainsi de suite, et les envoie au point de terminaison /api/recognize du service backend sur le port 8080 d'un hôte local (que nous créerons dans la section suivante).
Le backend doit recevoir ces images, reconnaître les chiffres qu'elles contiennent, et retourner le résultat de la reconnaissance sous forme de chaîne. Cette chaîne sera affichée dans le champ de saisie "Résultat".
Enfin, j'ai défini un peu de CSS pour appliquer des styles de base à cette page. Vous pouvez les modifier comme vous le souhaitez. Passons maintenant à la partie la plus intéressante – le backend de reconnaissance de chiffres.
Comment créer un backend
En tant que langage de programmation moderne et mature, Julia dispose de nombreuses bibliothèques et frameworks pour différentes tâches. Les frameworks web ne font pas exception. Nous utiliserons le framework Genie.jl, qui est similaire à Express dans Node.js ou Flask dans Python.
Avec Genie.jl, vous pouvez exécuter un service web de base en deux lignes de code :
using Genie
up(8080, async=false)
Il exécutera un serveur web sur le port 8080 d'un hôte local.
En utilisant n'importe quel éditeur de texte, par exemple VSCode avec l'extension Julia, créez un nouveau fichier Julia comme digits.jl dans le même dossier que le index.html. C'est là que vous écrirez le prochain morceau de code.
Ce service web aura deux points de terminaison :
/pour afficher la page web index.html que vous avez créée précédemment./api/recognizepour recevoir les requêtes POST avec les images des chiffres, les reconnaître et retourner une chaîne avec les chiffres reconnus.
Comme pour la plupart des autres frameworks web, pour recevoir et traiter les requêtes HTTP, Genie.jl utilise des routes. Cette application aura deux routes :
using Genie, Genie.Router, Genie.Requests
route("/") do
return String(read("index.html"))
end
route("/api/recognize", method=POST) do
result = ""
# TODO: dans une boucle, extraire chaque image
# du corps de la requête POST, l'envoyer à
# la fonction de reconnaissance de chiffre,
# recevoir le chiffre reconnu et l'ajouter
# au résultat
return result
end
up(8080, async=false)
Pour travailler avec les routes et les requêtes, vous devez importer deux sous-packages supplémentaires – Genie.Router et Genie.Requests.
La première route retourne simplement le contenu du fichier index.html.
La deuxième route traite les requêtes POST vers le point de terminaison /api/recognize. Voici comment vous pouvez la définir :
using Images
route("/api/recognize", method=POST) do
result = ""
files = filespayload();
for index in 1:11
file = files["$index.png"]
img = load(IOBuffer(file.data))
result *= recognizeDigit(img)
end
return result
end
Pour charger le fichier reçu en tant qu'image, nous utiliserons la bibliothèque Julia Images que nous avons importée à la première ligne.
Ensuite, la fonction [filespayload](https://github.com/GenieFramework/Genie.jl/blob/7eb45c9ec32f0e4659abb08559b0b2729451421a/src/Requests.jl#L50)() extrait tous les fichiers de la requête reçue.
Ensuite, nous supposons que la requête contient 11 fichiers et nous les traitons dans une boucle. Chaque fichier de données est extrait sous forme de tableau d'octets, mais la fonction [load](https://juliaimages.org/stable/function_reference/#FileIO.load) nécessite l'objet qui implémente un tampon IO. C'est pourquoi [IOBuffer](https://docs.julialang.org/en/v1/base/io-network/#Base.IOBuffer) convertit le tableau d'octets en un format approprié.
Ensuite, l'image chargée est transmise à la fonction recognizeDigit. Cette fonction sera écrite ci-dessous. Elle doit recevoir l'image, puis la reconnaître en utilisant le modèle entraîné et retourner le chiffre reconnu sous forme de chaîne. Ce chiffre sera ajouté à la chaîne result. Enfin, le résultat avec 11 chiffres reconnus sera envoyé à la page web.
Avant d'écrire la fonction recognizeDigit, assurez-vous que le fichier de modèle sauvegardé digits.bson a été copié dans le dossier avec votre code backend.
De plus, il est important de comprendre que nous ne pouvons pas traiter l'image d'entrée telle quelle car elle a une taille de 50x50, et c'est un chiffre noir sur un fond blanc.
Si le modèle est entraîné sur des images de taille 28x28, alors il ne peut pas être utilisé pour reconnaître des images d'autres tailles.
De plus, le modèle entraîné sur des images qui avaient du texte blanc écrit sur un fond noir fonctionnera mal pour les images colorées et pour les images avec du texte noir sur un fond blanc.
Ainsi, avant d'envoyer l'image au modèle pour la reconnaissance, vous devez la prétraiter en utilisant les étapes suivantes :
- Convertir les images en niveaux de gris
- Inverser les couleurs
- Les redimensionner à 28x28
Vous êtes maintenant prêt à implémenter la fonction de reconnaissance de chiffres :
using Flux, MLUtils, BSON
function recognizeDigit(img)
# charger le modèle
BSON.@load "digits.bson" model
# Convertir l'image en niveaux de gris
img = Gray.(img)
# Inverser la couleur de chaque pixel
img = (x->Gray(1)-x.val).(img)
# redimensionner l'image à 28x28 pixels
img = imresize(img,(28,28))
# Obtenir la matrice de l'image
digit_data = Float32.(channelview(img))
# prédire le chiffre (obtenir les probabilités)
probs = model(cat(digit_data,dims=4))
# retourner le chiffre avec la plus grande
# probabilité, converti en une chaîne
return "$(argmax(probs)[1]-1)"
end
Lorsque tout cela est fait, vous êtes presque prêt à exécuter l'application. Avant de le faire, assurez-vous que tous les packages requis sont installés. Exécutez le REPL julia dans un dossier de projet. Ensuite, exécutez le code suivant ligne par ligne, pour installer tous les packages mentionnés dans les lignes using :
using Pkg
Pkg.add("Genie")
Pkg.add("Images")
Pkg.add("Flux")
Pkg.add("MLUtils")
Ensuite, quittez le repl en utilisant la commande exit().
Vous pouvez maintenant exécuter l'application. Pour ce faire, exécutez la commande julia digits.jl à partir du terminal ou appuyez sur Ctrl+F5 dans VSCode.
Ensuite, allez sur http://localhost:8080 dans un navigateur web, dessinez les chiffres, appuyez sur le bouton "Reconnaître", et en quelques instants, vous verrez le numéro reconnu sous forme de texte dans le champ "Résultat".
Conclusion
Dans ce tutoriel, j'ai démontré comment créer et entraîner à la fois des réseaux de neurones feed forward et convolutionnels en utilisant Julia. Vous avez également appris comment les exporter et les utiliser dans une application web.
De plus, j'ai essayé de montrer que vous ne devez pas réinventer la roue lors de la création de réseaux de neurones.
Lorsque vous résolvez des problèmes réels, vous ne devez pas construire des architectures de réseaux de neurones à partir de zéro. La plupart d'entre elles ont déjà été créées par des scientifiques des données et des passionnés du monde entier. En pratique, vous les réutiliserez simplement.
Vous devrez simplement trouver l'architecture adaptée et soit l'utiliser telle quelle, soit modifier les dernières couches pour ajuster les sorties selon vos besoins.
Par exemple, vous pouvez rechercher dans cette collection où vous trouverez différents modèles classés par types de problèmes. Même si beaucoup d'entre eux n'ont pas été créés avec Julia, vous pouvez les créer en utilisant Flux.jl après avoir lu leurs descriptions.
La manière dont nous avons créé et entraîné notre réseau de neurones n'est pas la meilleure ni la seule possible. Peut-être qu'à certains égards, j'ai trop simplifié les choses, car je voulais expliquer tout cela aussi simplement que possible.
Mais si vous avez compris les exemples ici, vous pouvez apprendre et réutiliser les solutions Julia plus avancées suivantes pour la tâche de reconnaissance de chiffres manuscrits :
Vous pouvez voir le code source de cet article, y compris le Jupyter Notebook et le service web, dans ce dépôt.
Amusez-vous bien à coder et ne cessez jamais d'apprendre !
Vous pouvez me trouver sur LinkedIn, Twitter, et Facebook pour être le premier informé des nouveaux articles comme celui-ci et d'autres nouvelles sur le développement logiciel.