


Article original : Decoding Chaos: How True Randomness Works in Software Engineering
Comprendre le hasard
Lorsque vous entendez le mot « hasard », qu'est-ce qui vous vient généralement à l'esprit ? Vous pourriez penser à quelque chose d'intangible, un concept abstrait sans forme ni contour précis — c'est aléatoire.
Mais le hasard est bien plus qu'une idée abstraite — c'est un aspect fondamental de nos décisions et choix quotidiens. Qu'il s'agisse de décider ce que l'on va manger au petit-déjeuner ou de choisir un chiffre de 1 à 10 dans un jeu, le hasard joue un rôle crucial.
Le hasard ne concerne pas seulement l'imprévisibilité. C'est aussi l'absence de motif ou de prévisibilité dans les événements. Par exemple, lorsque vous lancez une pièce, le résultat (pile ou face) est aléatoire car il est tout aussi probable qu'imprévisible.
Pourquoi le hasard est-il important dans le génie logiciel ?
Ce concept est incroyablement important dans le domaine du génie logiciel, où la génération d'un véritable hasard peut améliorer la sécurité, les simulations et les algorithmes. Dans le développement de logiciels, cette imprévisibilité n'est pas seulement une fonctionnalité — c'est une exigence fondamentale pour diverses fonctions critiques.
Sécurité
Le rôle le plus crucial du hasard dans les logiciels se situe dans le domaine de la sécurité. Les nombres aléatoires sont utilisés pour générer des clés sécurisées pour le chiffrement, garantissant que les données sensibles — qu'il s'agisse d'informations personnelles, de détails financiers ou de communications confidentielles — sont protégées contre tout accès non autorisé.
Le hasard garantit que ces clés ne peuvent pas être facilement prédites ou reproduites, renforçant ainsi les barrières de sécurité (voir plus dans la section Le hasard dans les systèmes cryptographiques).
Tests et assurance qualité
Les développeurs utilisent des entrées aléatoires pour simuler les performances d'un logiciel dans différentes conditions. Cette approche aide à découvrir des bugs inattendus et garantit que le logiciel peut gérer une variété de scénarios, améliorant ainsi sa fiabilité et sa stabilité.
Des entreprises comme Netflix, Facebook et Google utilisent le Chaos Engineering pour rendre leurs systèmes plus fiables (en savoir plus dans la section Chaos Engineering).
Simulation et modélisation
Le hasard est un composant clé des simulations qui imitent des phénomènes du monde réel, lesquels peuvent être intrinsèquement imprévisibles. Qu'il s'agisse de modéliser des modèles climatiques, des marchés économiques ou des flux de trafic, le hasard aide à créer des modèles plus précis qui reflètent mieux la complexité de ces systèmes.
Applications supplémentaires
Le hasard est utilisé dans de nombreux domaines : il aide à répartir les tâches entre les serveurs lors de l'équilibrage de charge, améliore l'efficacité du routage du trafic et ajoute du réalisme dans la génération d'images. De plus, il est crucial pour créer des identifiants uniques comme les GUIDs (Globally Unique Identifiers) et mélanger les listes de lecture pour améliorer l'expérience utilisateur. Comme vous pouvez le voir, les cas d'utilisation du hasard sont nombreux.
Prérequis
Cet article est conçu pour être accessible, avec des explications suffisamment simples pour des lecteurs d'horizons divers. Cependant, quelques prérequis de base peuvent faciliter votre compréhension :
- Connaissances de base en programmation : Bien que ce ne soit pas indispensable, une certaine familiarité avec les concepts de programmation dans des langages comme C#, Java ou Python pourrait vous aider à saisir plus rapidement les exemples de mise en œuvre du hasard dans le code.
- Compétences mathématiques élémentaires : Une compréhension de base des probabilités et des statistiques est bénéfique mais pas nécessaire, car l'article vise à expliquer ces concepts en termes simples.
- Introduction à la cryptographie : Si vous êtes curieux des aspects de sécurité du hasard, une connaissance des concepts de cryptographie comme le chiffrement et la génération de clés pourrait être utile.
Dans l'ensemble, l'article est structuré pour être facile à suivre, sans connaissances avancées requises. Il est destiné à introduire largement le concept de hasard dans le génie logiciel, ce qui le rend adapté aux lecteurs de divers domaines.
Voici ce que nous allons aborder dans cet article :
- Comprendre le hasard
- Paradigme du pile ou face
- L'illusion du hasard humain
- Comment fonctionnent les générateurs de nombres aléatoires
- Génération de nombres véritablement aléatoires (TRNG) et sources d'entropie
- Le hasard dans les tests logiciels
- Le hasard dans les systèmes cryptographiques
- Le hasard dans la simulation et la modélisation
- L'avenir du hasard dans le génie logiciel
- Conclusion
Paradigme du pile ou face

Lancer une pièce est-il un événement véritablement aléatoire ? À première vue, un lancer de pièce représente le paradigme du hasard : deux issues, chacune ayant une chance égale de se produire.
Mais si nous plongeons plus profondément dans la physique derrière un lancer de pièce, l'histoire commence à se dévoiler différemment. Hypothétiquement, si nous pouvions contrôler et reproduire chaque variable impliquée dans le lancer — la force appliquée, l'angle du lancer, la résistance de l'air et même la surface sur laquelle elle atterrit — le résultat serait-il toujours imprévisible ?
La réponse penche vers une déclaration surprenante : dans un environnement parfaitement contrôlé, le résultat d'un lancer de pièce pourrait être prédit avec une quasi-certitude. Cela remet en question notre compréhension du hasard, suggérant que ce que nous percevons souvent comme aléatoire est influencé par de nombreux facteurs, dont beaucoup échappent à notre contrôle ou sont trop complexes à reproduire en pratique.
Ainsi, nous arrivons à une conclusion éclairante : hasard ≈ résultat de variables extrêmement difficiles à reproduire.
Une recherche importante de l'Université de Californie à Berkeley, intitulée « Dynamical Bias in the Coin Toss », explore ce phénomène :
Résumé : Nous analysons le processus naturel de lancer d'une pièce qui est rattrapée dans la main. Nous montrons que les pièces lancées vigoureusement ont tendance à retomber du même côté qu'au départ. La probabilité limite de retomber ainsi dépend d'un seul paramètre, l'angle entre la normale à la pièce et le vecteur du moment cinétique. Des mesures de ce paramètre basées sur la photographie à haute vitesse sont rapportées. Pour les lancers naturels, la chance de retomber comme au départ est d'environ 0,51.
 _[Dynamical Bias in the Coin Toss](https://www.stat.berkeley.edu/~aldous/157/Papers/diaconiscoinbias.pdf" rel="noopener)
_[Dynamical Bias in the Coin Toss](https://www.stat.berkeley.edu/~aldous/157/Papers/diaconiscoinbias.pdf" rel="noopener)
L'illusion du hasard humain
Pour les humains, c'est une tâche facile de générer un nombre aléatoire, de dire un mot au hasard ou de prendre une décision aléatoire. Mais encore une fois, s'agit-il vraiment d'un acte aléatoire et peut-il être en quelque sorte prédit comme nous l'avons affirmé pour le lancer de pièce ?
Si vous avez vu le film Diversion (Focus) de 2015, vous vous souvenez peut-être de la scène d'« amorçage » (priming) où ils passent la journée à « amorcer » leur victime pour qu'elle reconnaisse et choisisse inconsciemment le nombre 55 en le faisant apparaître tout autour de lui.
L'amorçage est l'un des principes psychologiques les plus importants à comprendre car il influence le comportement à travers la mémoire implicite. En d'autres termes, l'exposition à un indice dans un certain contexte peut former une association qui se prolonge dans un autre.
L'un des exemples d'amorçage nous vient d'un rayon vins d'un supermarché. Imaginez qu'une semaine, vous alliez acheter du vin et qu'il y ait de la musique française en fond sonore. Vous achetez votre vin et partez.
Imaginez maintenant que vous reveniez une semaine plus tard, mais cette fois-ci, c'est de la musique allemande qui passe par les haut-parleurs. Encore une fois, vous achetez votre vin et partez. Il est fort probable que lorsque la musique française passait, vous ayez acheté du vin français, et lorsque la musique allemande passait, du vin allemand — tout comme l'ont fait respectivement 77 % et 73 % des participants à une étude.
Ces consommateurs étaient-ils conscients de la musique et de son impact sur leur décision ? 86 % des gens ont répondu que non, que la musique n'avait eu aucun effet.
Ce phénomène souligne une vérité profonde : que nous le sachions ou non, nous sommes à la fois les amorceurs et les amorcés. Notre hasard perçu dans la prise de décision est continuellement façonné par les stimuli qui nous entourent. Cela révèle que l'essence du hasard humain est bien plus complexe et influencée que ce que nous pourrions croire initialement.
Comment fonctionnent les générateurs de nombres aléatoires
Faisons un voyage dans les premiers jours de l'informatique pour comprendre l'évolution des générateurs de nombres aléatoires.
Au départ, les ordinateurs étaient assez basiques par rapport aux machines sophistiquées d'aujourd'hui. Essentiellement, un ordinateur fonctionne sur un ensemble strict d'instructions : il ne peut pas générer spontanément un nombre comme un humain pourrait choisir au hasard un chiffre de 1 à 10.
Pour un ordinateur, générer un nombre aléatoire nécessite des instructions spécifiques. Aujourd'hui, cette tâche est devenue simple dans de nombreux langages de programmation grâce à des fonctions intégrées. Par exemple, en C#, vous pouvez générer un nombre aléatoire entre 1 et 10 avec cette commande simple :
Random.Next(1, 10) // <-- Génère un nombre aléatoire de 1 à 10
La partie intéressante commence lorsque nous regardons sous le capot.
Générateur de nombres aléatoires simple
Et si l'on vous donnait pour tâche de créer une fonction qui génère un nombre aléatoire ? Disons que vous avez cette fonction :
public static int GenerateRandomNumber(int start, int end)
{
return ✨🪄 magie ✨🪄
}
L'un des moyens les plus simples d'y parvenir est d'utiliser un Générateur Congruentiel Linéaire (LCG). L'exemple ci-dessous est une approche simplifiée et vous ne devriez pas l'utiliser à des fins cryptographiques ou pour des applications nécessitant des niveaux élevés de hasard.
using System;
class SimpleRandomGenerator
{
private long seed;
private const long a = 25214903917;
private const long c = 11;
private long m = (long)Math.Pow(2, 48);
public SimpleRandomGenerator(long seed)
{
this.seed = seed;
}
public int Next(int min, int max)
{
// Mettre à jour la graine (seed)
seed = (a * seed + c) % m;
// S'assurer que le résultat est dans les limites [min, max)
int result = (int)(min + (seed % (max - min)));
return result;
}
}
class Program
{
static void Main(string[] args)
{
var generator = new SimpleRandomGenerator(DateTime.Now.Ticks);
for(int i = 0; i < 15; i++)
{
var rndNumber = generator.Next(1, 101);
Console.WriteLine($"Nombre aléatoire entre 1 et 100 : {rndNumber}");
}
}
}
/* Sortie
Nombre aléatoire entre 1 et 100 : 78
Nombre aléatoire entre 1 et 100 : 9
Nombre aléatoire entre 1 et 100 : -48
...
*/
Cet exemple utilise la méthode du Générateur Congruentiel Linéaire (LCG), qui est un générateur de nombres pseudo-aléatoires de base.
Les LCG sont l'une des méthodes les plus anciennes et les plus simples pour générer des séquences de nombres pseudo-aléatoires, et ils fonctionnent selon une formule mathématique simple : « nouvelle graine = (a × graine + c) mod m ». La graine est généralement initialisée à l'aide d'une valeur ayant une entropie suffisante, comme l'heure actuelle (DateTime.Now.Ticks dans ce cas). La méthode Next génère un nouveau nombre « aléatoire » dans la plage spécifiée [min, max).
Voici la logique étape par étape :
- Mettre à jour la graine : La graine est mise à jour à l'aide de la formule LCG mentionnée ci-dessus. Cette étape est critique, car elle utilise l'ancienne graine pour en produire une nouvelle, garantissant que chaque appel à
Nextproduit une sortie différente. - Mise à l'échelle de la sortie : Une fois la nouvelle graine calculée, elle doit être ajustée pour tomber dans la plage
[min, max)spécifiée par l'utilisateur. – L'opération moduloseed % (max - min)ramène la graine à une valeur comprise entre 0 et(max - min) - 1. – L'ajout demindéplace cette valeur mise à l'échelle dans la plage souhaitée, garantissant que le résultat est au moinsminmais inférieur àmax.
Génération de nombres véritablement aléatoires (TRNG) et sources d'entropie
La génération de nombres aléatoires basée sur des événements naturels ou des caractéristiques matérielles implique l'utilisation de sources imprévisibles et non déterministes. Cette approche est souvent appelée utilisation de « sources d'entropie » ou « génération de nombres véritablement aléatoires » (TRNG).
Contrairement aux générateurs de nombres pseudo-aléatoires (PRNG) qui utilisent des algorithmes mathématiques et nécessitent une valeur de graine, les générateurs de nombres véritablement aléatoires tirent leur hasard d'événements physiques presque imprévisibles. Voici quelques exemples :
Tremblements de terre dans TRNG
Les tremblements de terre génèrent des données sismiques presque imprévisibles qui peuvent être utilisées comme source de hasard. En mesurant l'activité sismique à l'aide de géophones ou de sismographes, les variations infimes des mouvements de la Terre peuvent être converties en nombres aléatoires.
Les tremblements de terre se produisent en raison du relâchement soudain d'énergie dans la croûte terrestre, ce qui provoque des secousses au sol. Ce relâchement d'énergie est imprévisible et varie en magnitude, en lieu et en fréquence. L'imprévisibilité du moment, de la durée et de l'intensité des événements sismiques en fait une source d'entropie viable.
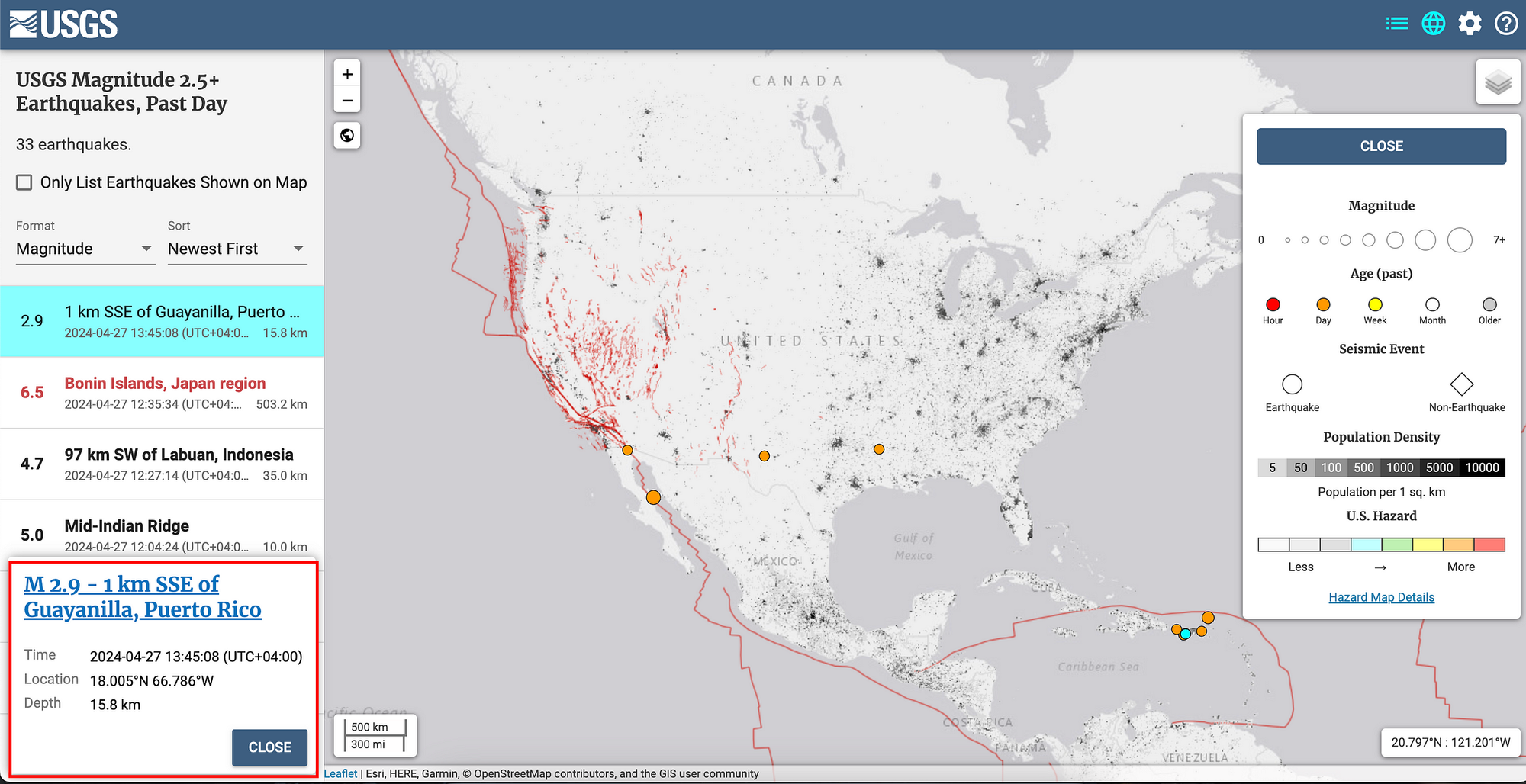 [Données de l'USGS sur les tremblements de terre de magnitude 2.5+, dernier jour](https://earthquake.usgs.gov/earthquakes/map/?currentFeatureId=pr71446783&extent=9.79568,-147.39258&extent=58.99531,-42.62695" rel="noopener)
[Données de l'USGS sur les tremblements de terre de magnitude 2.5+, dernier jour](https://earthquake.usgs.gov/earthquakes/map/?currentFeatureId=pr71446783&extent=9.79568,-147.39258&extent=58.99531,-42.62695" rel="noopener)
Détails techniques supplémentaires
Voici quelques détails techniques supplémentaires sur l'utilisation des tremblements de terre dans les TRNG :
La collecte de données se fait généralement à l'aide d'instruments appelés sismomètres ou géophones, qui sont sensibles aux vibrations du sol. Ces appareils convertissent l'énergie cinétique des mouvements du sol en signaux électriques qui peuvent ensuite être numérisés et analysés.
Ce processus peut inclure :
- Conditionnement et filtrage du signal : Filtrage des signaux sismiques pour isoler les composants aléatoires du bruit prévisible ou des vibrations de fond.
- Numérisation : Conversion des signaux analogiques en valeurs numériques, ce qui implique généralement l'échantillonnage du signal à intervalles réguliers et la quantification de ces échantillons.
Les données numériques brutes dérivées de l'activité sismique pourraient ne pas être uniformément aléatoires en raison de biais naturels dans la façon dont les tremblements de terre se produisent ou dont les données sont collectées.
Pour garantir que les nombres générés conviennent à des applications nécessitant un hasard de haute qualité (comme les systèmes cryptographiques), un traitement supplémentaire peut être nécessaire.
Voici les techniques courantes :
- Débiaisage (Debiasing) : Application d'algorithmes pour supprimer tout motif ou biais prévisible des données.
- Blanchiment (Whitening) : Transformation des données pour assurer une distribution uniforme sur toutes les valeurs possibles. Cela implique souvent des tests statistiques pour ajuster la sortie jusqu'à ce qu'elle réponde aux critères de hasard.
L'utilisation des tremblements de terre pour la génération de nombres aléatoires pourrait être particulièrement précieuse dans les applications où une source de hasard externe et imprévisible est bénéfique.
Mais il y a des inconvénients et des considérations pratiques :
- Limitations géographiques : Tous les endroits ne connaissent pas une activité sismique fréquente, ce qui pourrait limiter la disponibilité de cette méthode à des régions spécifiques.
- Rareté des événements : Les événements sismiques importants sont relativement rares et imprévisibles dans le temps, ce qui peut ne pas fournir une source de hasard constante ou fiable en cas de besoin.
- Surcharge de collecte et de traitement des données : L'infrastructure et l'effort de calcul requis pour capturer, traiter et utiliser les données sismiques peuvent être importants.
Événements matériels dans TRNG
Les générateurs de nombres aléatoires matériels (HRNG) utilisent des processus physiques au sein des appareils informatiques pour générer du hasard. Les exemples incluent :
Bruit thermique (Bruit de Johnson-Nyquist) :
Le bruit thermique, également connu sous le nom de bruit de Johnson-Nyquist, est un type d'interférence naturellement présent dans tous les appareils et circuits électroniques. Il est causé par le mouvement aléatoire des électrons au sein d'un matériau dû à la chaleur. Ce phénomène peut être utilisé comme source de hasard pour générer des nombres aléatoires dans les dispositifs matériels.
Tout matériau conducteur d'électricité possède des électrons, qui sont de minuscules particules se déplaçant pour transporter le courant électrique. Même lorsqu'un appareil n'est pas utilisé activement, ces électrons ne sont jamais complètement immobiles — ils bougent de manière aléatoire à cause de l'énergie thermique présente dans le matériau. Plus la température est élevée, plus les électrons deviennent actifs.
Le bruit thermique est généré par l'énergie intrinsèque présente dans tous les matériaux à des températures supérieures au zéro absolu (-273,15 °C). À ces températures, les électrons gagnent de l'énergie et commencent à se déplacer de manière aléatoire. Ce mouvement provoque de minuscules fluctuations aléatoires du courant électrique lorsqu'il est mesuré aux bornes de composants comme des résistances.
Le bruit thermique est idéal pour les applications cryptographiques où une haute sécurité est essentielle. Cela inclut la génération de clés et les communications sécurisées où l'imprévisibilité est primordiale pour prévenir les attaques.
Dans le développement de protocoles de communication sécurisés pour des applications telles que la messagerie instantanée, la VoIP ou les systèmes de transmission de données, le bruit thermique peut être utilisé pour générer des clés de chiffrement presque impossibles à prédire, renforçant ainsi la sécurité.
Dérive d'horloge (Clock Drift)
La dérive d'horloge survient en raison des variations légères et imprévisibles des mécanismes de chronométrage (comme les oscillateurs à quartz) des ordinateurs et autres appareils numériques. La dérive d'horloge exploite la variabilité naturelle des horloges matérielles, qui sont conçues pour mesurer le temps mais peuvent s'écarter en raison de différences mineures dans la fréquence de leurs oscillateurs.
En comparant l'heure rapportée par deux ou plusieurs horloges indépendantes, de petites différences qui se produisent naturellement et de manière imprévisible peuvent être mesurées. Ces différences sont influencées par des facteurs tels que les changements de température, les imperfections matérielles et les variations de la tension d'alimentation.
 _[Un générateur de nombres véritablement aléatoires matériel branchable par USB](https://en.wikipedia.org/wiki/Hardware_random_number_generator#Clockdrift" rel="noopener)
_[Un générateur de nombres véritablement aléatoires matériel branchable par USB](https://en.wikipedia.org/wiki/Hardware_random_number_generator#Clockdrift" rel="noopener)
Émission photonique
La génération de nombres aléatoires basée sur l'émission photonique utilise le processus d'émission de lumière. Cette approche repose sur la nature quantique de la lumière — spécifiquement, le comportement des photons, qui sont les minuscules particules constituant la lumière.
L'émission photonique se produit lorsque de l'énergie est libérée par des atomes sous forme de lumière. Cela se produit dans des appareils comme les LED (diodes électroluminescentes) et les lasers.
Dans une LED, lorsque l'électricité circule dans l'appareil, elle excite les électrons vers des états d'énergie plus élevés. Lorsque ces électrons reviennent à leur état normal, ils libèrent de l'énergie sous forme de photons.
Le moment exact où un photon est émis est intrinsèquement imprévisibile en raison des principes de la mécanique quantique, où les particules comme les électrons se comportent de manière probabiliste.
Pour transformer l'émission photonique en nombres aléatoires, nous devons d'abord détecter ces photons. Nous pouvons le faire à l'aide d'un dispositif appelé photodétecteur, qui capture la lumière et convertit chaque impact de photon en un signal électrique.
La clé du hasard réside dans le moment de l'arrivée de chaque photon au détecteur. Comme l'émission de chaque photon est aléatoire, les moments où ils sont détectés le sont aussi. Ces temps sont ensuite enregistrés avec une grande précision.
Les lampes à lave de Cloudflare pour le hasard
Cloudflare, une entreprise de performance et de sécurité web, a installé un mur de lampes à lave dans le hall de son bureau de San Francisco. L'installation est connue sous le nom de système « LavaRand ». Elle exploite les mouvements imprévisibles et changeants de la « lave » à l'intérieur de ces lampes pour générer du hasard.
 Les lampes à lave de Cloudflare. Vue depuis la caméra.
Les lampes à lave de Cloudflare. Vue depuis la caméra.
Comment fonctionne LavaRand : Le processus commence par une capture visuelle. Une caméra est pointée vers le mur de lampes à lave. Les lampes contiennent des bulles de cire dans un liquide qui se dilatent et se déplacent de manière imprévisible lorsqu'elles sont chauffées.
À mesure que la cire chauffe, elle monte, et à mesure qu'elle refroidit, elle descend, créant un affichage visuellement chaotique et toujours changeant.
La caméra prend des images des lampes à lave à intervalles réguliers. Chaque image capture un motif unique et aléatoire de cire tourbillonnante. Ces images sont ensuite traitées à l'aide d'algorithmes informatiques pour extraire des données aléatoires des motifs observés dans les images.
Relation avec l'émission photonique : Bien que les lampes à lave de Cloudflare utilisent une forme d'émission photonique, c'est indirect. L'émission photonique dans ce contexte est la lumière émise par les lampes, qui illumine la cire à l'intérieur.
Le processus de génération de nombres aléatoires repose toutefois principalement sur les mouvements physiques chaotiques de la cire, capturés par la lumière et enregistrés par une caméra. Le hasard provient de la façon dont la lumière et les ombres jouent sur la lave en mouvement, plutôt que de l'émission et de la détection de photons au niveau quantique (ce qui est plus typique dans les systèmes RNG à émission photonique utilisant des LED ou des lasers).
Informations provenant du site officiel de Cloudflare :
LavaRand est un système qui utilise des lampes à lave comme source secondaire de hasard pour nos serveurs de production. Un mur de lampes à lave dans le hall de notre bureau de San Francisco fournit une entrée imprévisible à une caméra pointée vers le mur. Un flux vidéo de la caméra est envoyé à un CSPRNG, et ce CSPRNG fournit un flux de valeurs aléatoires qui peut être utilisé comme source supplémentaire de hasard par nos serveurs de production. Étant donné que le flux de la « lave » dans une lampe à lave est très imprévisible, « mesurer » les lampes en les filmant est un bon moyen d'obtenir un hasard imprévisible. Les ordinateurs stockent les images sous forme de très grands nombres, nous pouvons donc les utiliser comme entrée d'un CSPRNG comme n'importe quel autre nombre.
Nous ne sommes pas les premiers à faire cela. Notre système LavaRand a été inspiré par un système similaire proposé et construit par Silicon Graphics et breveté en 1996 (le brevet a depuis expiré).
Espérons que nous n'en aurons jamais besoin. Espérons que les sources primaires de hasard utilisées par nos serveurs de production resteront sécurisées et que LavaRand ne servira guère qu'à ajouter un peu de style à notre bureau. Mais s'il s'avère que nous nous trompons et que nos sources de hasard en production sont en réalité défectueuses, alors LavaRand sera notre couverture, rendant le piratage de Cloudflare un peu plus difficile.
En savoir plus ici.
 [Premier LavaRand proposé et breveté en 1996](https://patents.google.com/patent/US5732138" rel="noopener)
[Premier LavaRand proposé et breveté en 1996](https://patents.google.com/patent/US5732138" rel="noopener)
Facteurs humains dans TRNG
Mouseware
Certains outils comme Mouseware utilisent des facteurs humains pour générer du hasard. Mouseware utilise un générateur de nombres aléatoires cryptographiquement sécurisé basé sur les mouvements de votre souris pour générer des mots de passe sécurisés et mémorisables. Les mots de passe sont générés entièrement dans le navigateur, et aucune donnée n'est jamais envoyée sur le réseau.
Pour ces mots de passe générés, il faudrait 22 400,7 ans pour les deviner à raison de 1 000 tentatives/seconde et 2,0 heures à raison de 100 milliards de tentatives/seconde.
- 1 000 tentatives/seconde correspond au pire des cas pour une attaque en ligne. C'est généralement le seul type d'attaque réalisable contre un site web sécurisé.
- 100 milliards de tentatives/seconde correspond au pire des cas pour une attaque hors ligne lorsqu'une base de données de mots de passe hachés est volée par quelqu'un disposant de ressources techniques et financières non négligeables.
 Exemple du flux pour générer des nombres aléatoires basés sur les mouvements de la souris
Exemple du flux pour générer des nombres aléatoires basés sur les mouvements de la souris
Vous pouvez en savoir plus sur Mouseware sur leur site web.
Le hasard dans les tests logiciels
Chaos Monkey a développé mon Netflix
 Chaos Monkey
Chaos Monkey
Chaos Monkey est un outil innovant développé par Netflix. Il est chargé de terminer de manière aléatoire des instances de Netflix en production pour s'assurer que les ingénieurs conçoivent leurs services de manière à ce qu'ils soient résilients aux pannes d'instances.
Imaginez un singe virtuel et malicieux bricolant aléatoirement le réseau — éteignant des instances, déconnectant des serveurs ou surchargeant les systèmes pour simuler des pannes possibles.
Bien que cela puisse paraître contre-intuitif, le but de Chaos Monkey est de provoquer proactivement des pannes contrôlées. Cette stratégie permet aux ingénieurs de Netflix de tester la capacité de leurs systèmes à gérer des interruptions inattendues. L'objectif est d'identifier et de résoudre les faiblesses avant qu'elles n'impactent les utilisateurs, garantissant que l'infrastructure est suffisamment robuste pour résister aux problèmes du monde réel.
Par exemple, si Chaos Monkey arrête aléatoirement un serveur et que tout continue de fonctionner sans accroc, c'est une victoire. Si des problèmes surviennent, les ingénieurs les analysent et les rectifient rapidement, renforçant ainsi le système. Ce cycle continu de tests et d'améliorations permet de garantir que lorsque vous vous installez pour regarder votre série préférée, vous bénéficiez d'un streaming ininterrompu.
Grâce à des outils comme Chaos Monkey et aux principes du Chaos Engineering, Netflix peut offrir une expérience de visionnage fluide. La prochaine fois que vous regarderez une émission sans aucun problème technique, souvenez-vous des efforts déployés en coulisses par ces héros méconnus qui veillent à ce que votre divertissement soit impeccable.
Cet outil est également disponible en open source. Consultez la documentation ici.
Le hasard dans les systèmes cryptographiques
Le hasard joue un rôle critique dans les systèmes cryptographiques, formant la colonne vertébrale des protocoles de sécurité dans tout le paysage numérique. Cette section explore pourquoi le hasard est essentiel en cryptographie, comment il est généré et les défis impliqués pour garantir son efficacité.
Dans les systèmes cryptographiques, le hasard est utilisé pour générer des clés, initialiser des algorithmes cryptographiques et pour des processus de non-répudiation comme les signatures numériques et les communications sécurisées.
La force et la sécurité de presque toutes les techniques cryptographiques dépendent de la qualité du hasard utilisé. Si le hasard est prévisible, les clés cryptographiques le sont aussi, rendant le système vulnérable aux attaques.
Si nous chiffrons le texte « Hello World », nous obtiendrons ce texte « oO64D2IzNWKSQnDM8fcZ/w== ». Pour voir la puissance du chiffrement, chiffrons également des variations du texte : « HelloWorld » (sans espace) et « Hello world » (en minuscules), tout en expérimentant avec une clé de chiffrement différente.
Voici les résultats :
╔═════════════╦═══════════╦══════════════════════════╗
║ Texte ║ Mot de p. ║ Valeur encodée ║
╠═════════════╬═══════════╬══════════════════════════╣
║ Hello World ║ 1234 ║ oO64D2IzNWKSQnDM8fcZ/w== ║
╠─────────────╬───────────╬──────────────────────────╣
║ HelloWorld ║ 1234 ║ KvqAEHQhP9iBdFWhOUcYVg== ║
╠─────────────╬───────────╬──────────────────────────╣
║ Hello world ║ 1234 ║ jdKRaAw9ULCFb627e3mNpQ== ║
╠─────────────╬───────────╬──────────────────────────╣
║ Hello World ║ 123 ║ S/eGTyDQsgLwcEIrCWUAJw== ║
╠─────────────╬───────────╬──────────────────────────╣
║ HelloWorld ║ 123 ║ /JRa5+mllydL/F0m7NuxYA== ║
╠─────────────╬───────────╬──────────────────────────╣
║ Hello world ║ 123 ║ s3AydwlvlgHCcpiAhaurXg== ║
╚═════════════╩═══════════╩══════════════════════════╝
Si vous examinez le tableau ci-dessus, vous remarquerez que même un petit changement, comme une modification de l'espacement ou d'un seul caractère, conduit à une transformation complète du texte chiffré.
Cela signifie que si l'intrus parvient à obtenir à la fois le texte original et sa forme chiffrée, il ferait toujours face à un défi de taille en essayant de deviner le mot de passe requis pour déverrouiller l'ensemble de la base de données.
Pourriez-vous pirater le chiffrement ?
Les attaques par force brute sont une méthode simple mais puissante utilisée par les attaquants pour craquer les mots de passe et les clés de chiffrement.
Une attaque par force brute consiste à vérifier systématiquement toutes les combinaisons possibles jusqu'à ce que la bonne soit trouvée. Les attaquants utilisent des méthodes de force brute pour essayer chaque clé ou mot de passe possible jusqu'à ce qu'ils déchiffrent les données ciblées.
 En savoir plus sur les attaques par force brute
En savoir plus sur les attaques par force brute
Dans notre cas, pour déchiffrer le mot, nous devrions essayer chaque combinaison possible (même des chaînes comme a, aa, b, bb et ainsi de suite).
Calculons maintenant le temps nécessaire pour déchiffrer/vérifier chaque combinaison possible pour notre mot de passe. Supposons que vous possédiez un superordinateur exceptionnellement puissant, doté d'une technologie de pointe et de ressources pratiquement illimitées.
Disons que l'ordinateur dispose d'un énorme téraoctet (To) de RAM lui permettant de gérer de nombreuses tâches à la fois. Pour le processeur, ce superordinateur affiche une vitesse ahurissante de 1 exaflop, ce qui signifie qu'il peut effectuer environ 1 quintillion de calculs en une seule seconde. 1 exaflop est égal à 1 000 000 de gigaflops. Ainsi, pour atteindre 1 exaflop de puissance de calcul en utilisant des processeurs Intel i9 avec une performance de 300 gigaflops chacun, il vous faudrait 1 000 000 de gigaflops / 300 gigaflops = 3 333 333 processeurs Intel i9.
Ce superordinateur hypothétique, effectuant des calculs hallucinants à la vitesse de l'éclair, pourrait mener une attaque par force brute sur un algorithme de chiffrement.
Si notre superordinateur hypothétique tentait chaque combinaison possible de texte pour déchiffrer les données chiffrées, il serait confronté à un nombre astronomique de possibilités — 2²⁵⁶. On estime qu'il faudrait non pas des années, ni même des siècles, mais potentiellement des dizaines de milliers de décennies.
Pour en savoir plus à ce sujet, vous pouvez consulter cet article que j'ai écrit.
Le hasard dans la simulation et la modélisation
Simulation de Monte-Carlo
La simulation de Monte-Carlo est une technique mathématique utilisée pour comprendre l'impact du risque et de l'incertitude dans les modèles de prédiction et de prévision. Essentiellement, c'est une méthode utilisée pour prédire la probabilité de différents résultats lorsque l'intervention de variables aléatoires est présente.
Nommée d'après le célèbre casino de Monte-Carlo en raison de sa dépendance au hasard, cette méthode est largement utilisée dans la finance, l'ingénierie, la recherche, et bien plus encore.
Dans le contexte de la finance, la simulation de Monte-Carlo est couramment utilisée pour évaluer le risque et la valeur des instruments financiers, tels que les options ou les portefeuilles. En générant un grand nombre de scénarios aléatoires pour différentes variables d'entrée, telles que les prix des actifs ou les taux d'intérêt, la simulation de Monte-Carlo peut fournir une gamme de résultats possibles et leurs probabilités associées. Cette méthode est principalement utilisée lorsqu'il n'existe pas de solution analytique au problème donné.
Les télécoms les utilisent pour évaluer les performances du réseau dans divers scénarios, ce qui les aide à optimiser leurs réseaux. Les analystes financiers utilisent les simulations de Monte-Carlo pour évaluer le risque qu'une entité fasse défaut, et pour analyser les produits dérivés tels que les options. Les assureurs et les foreurs de puits de pétrole les utilisent également pour mesurer le risque.
Pour en savoir plus, consultez cet article.
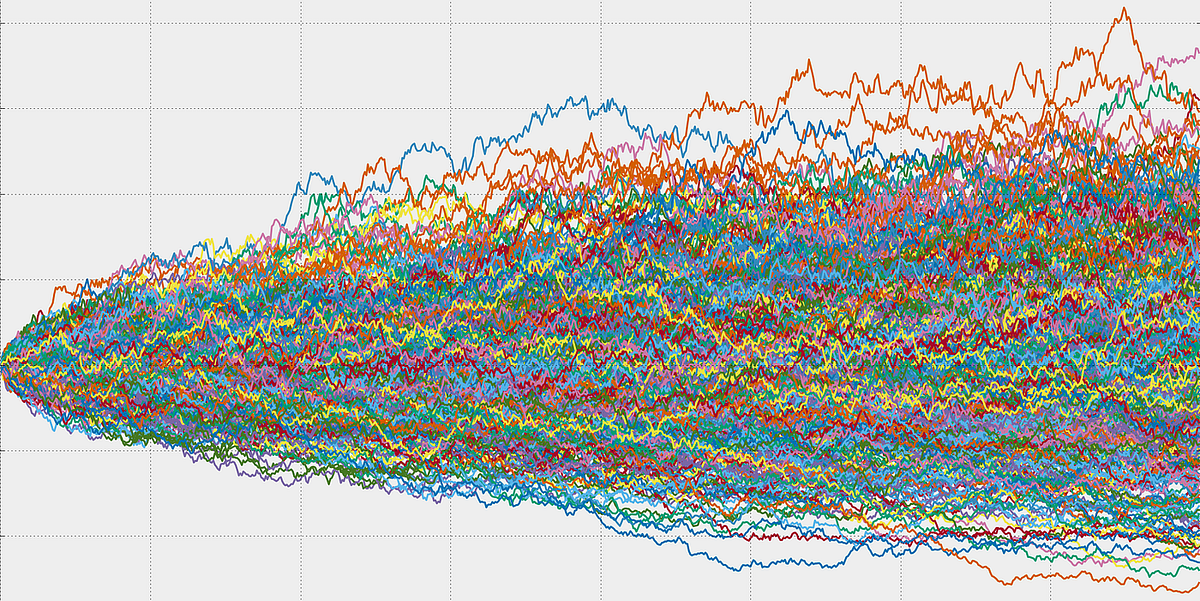 Sortie d'une simulation de Monte-Carlo sur le prix d'une action. Tiré de cet article
Sortie d'une simulation de Monte-Carlo sur le prix d'une action. Tiré de cet article
L'avenir du hasard dans le génie logiciel
L'avenir du hasard dans le génie logiciel semble particulièrement prometteur, avec des avancées significatives attendues de la part de technologies émergentes comme l'informatique quantique.
Informatique quantique et hasard quantique
L'informatique quantique introduit un élément intrinsèquement stochastique connu sous le nom de hasard quantique.
Contrairement à l'informatique classique, qui repose sur des processus déterministes, les processus quantiques sont imprévisibles par nature. Les générateurs de nombres aléatoires quantiques (QRNG) exploitent cette propriété pour générer de véritables nombres aléatoires directement à partir de phénomènes quantiques, tels que la superposition d'états quantiques ou la mesure de particules intriquées.
Ces dispositifs devraient fournir une source de hasard plus sécurisée et fondamentalement imprévisible que ce qui est actuellement possible.
 Le nouvel ordinateur quantique de 53 qubits d'IBM
Le nouvel ordinateur quantique de 53 qubits d'IBM
L'informatique quantique a le potentiel de révolutionner la cryptographie. Les systèmes cryptographiques actuels reposent sur la difficulté de calcul de certains problèmes (comme la factorisation de grands nombres) que les ordinateurs quantiques pourraient résoudre sans effort. Mais la cryptographie quantique, utilisant le hasard quantique pour la distribution des clés, promet d'être virtuellement inviolable grâce aux lois de la mécanique quantique.
État actuel de l'informatique quantique
À l'heure actuelle, l'informatique quantique est dans une phase expérimentale. Des chercheurs et des entreprises comme Google, IBM et D-Wave développent activement des ordinateurs quantiques et ont réalisé des progrès significatifs ces dernières années.
Par exemple, Google a annoncé la « suprématie quantique » en 2019, affirmant que son ordinateur quantique avait résolu un problème qu'il serait pratiquement impossible de résoudre pour un ordinateur classique dans un délai raisonnable.
Les bits quantiques, ou qubits, qui sont les unités de base de l'information en informatique quantique, sont très sensibles aux interférences de leur environnement. Cela entraîne des taux d'erreur élevés dans les calculs quantiques. Le développement de codes correcteurs d'erreurs et la recherche de moyens pour rendre les qubits plus stables constituent un axe majeur de la recherche actuelle.
Actuellement, les ordinateurs quantiques ont un nombre limité de qubits. Pour être pratiques pour une utilisation généralisée, les ordinateurs quantiques doivent augmenter considérablement le nombre de qubits sans augmentation correspondante des taux d'erreur.
De plus, ces ordinateurs doivent fonctionner à des températures extrêmement basses, proches du zéro absolu, pour maintenir l'état quantique des qubits. Le maintien de telles conditions est techniquement difficile et coûteux.
Le consensus parmi les experts est prudemment optimiste, mais varie considérablement quant au moment où l'informatique quantique deviendra pratique pour une utilisation large.
Certains experts pensent que d'ici la prochaine décennie, nous commencerons à voir des ordinateurs quantiques résoudre des problèmes plus pratiques du monde réel, révolutionnant potentiellement des domaines comme la cryptographie, la science des matériaux et la simulation de systèmes complexes. D'autres pensent que ces applications pourraient rester hors de portée pendant plusieurs décennies supplémentaires.
Conclusion
L'avenir du hasard dans le génie logiciel détient un vaste potentiel pour stimuler l'innovation dans de multiples domaines.
Alors que nous approfondissons l'informatique quantique et améliorons nos technologies actuelles, le hasard jouera un rôle de plus en plus critique dans le façonnement de la prochaine génération de solutions logicielles, les rendant plus sûres, plus efficaces et plus représentatives du monde complexe qu'elles modélisent.
