

Article original : Essential SQL Concepts for Data Analysts – Explained with Code Examples
Par Joel Hereth
Dans le vaste et toujours croissant domaine de l'analyse de données, le Structured Query Language (SQL) sert de bloc de construction fondamental.
Bien que les racines de SQL se trouvent dans la gestion de bases de données, il a élargi sa portée, devenant l'outil de prédilection pour l'extraction, la manipulation et l'analyse de données.
Que vous commeniez tout juste votre parcours en tant qu'analyste de données ou que vous cherchiez à renforcer votre maîtrise de ses outils, la compréhension des concepts essentiels de SQL est incontournable.
Ce guide vous emmènera à travers les aspects critiques de SQL qui sont importants pour votre succès dans le domaine de l'analyse de données.
Table des matières :
Le rôle de SQL dans l'analyse de données
Avant d'entrer dans les détails, il est important de comprendre le rôle pivot de SQL dans l'analyse de données.
SQL est la lingua franca du monde des bases de données, servant de traducteur entre l'homme et la machine. Cela en fait un incontournable pour quiconque plonge dans le domaine des données.
Pour apprécier l'importance de SQL, il suffit de regarder les tâches qu'il permet d'accomplir. De la transformation de données brutes en rapports perspicaces à la création d'applications basées sur les données et à l'exécution d'opérations complexes sur les données, SQL est la centrale électrique qui permet aux analystes et aux professionnels d'extraire des pépites cachées des vastes océans de bases de données.
Concepts clés de SQL à apprendre
Commandes de base
Les commandes SQL peuvent être catégorisées en entités qui gèrent la structure du schéma de la base de données (DDL - Data Definition Language), contrôlent le contenu des tables de la base de données (DML - Data Manipulation Language), et accèdent et travaillent sur les données au sein de la base de données (DQL - Data Query Language). Vous voudrez commencer par ici pour poser des bases solides.
Commandes DML :
SELECT: récupère des données d'une ou plusieurs tables.
SELECT product_name, price
FROM products
WHERE category = 'Electronics';
INSERT: insère de nouvelles lignes dans une table.
INSERT INTO customers (name, email)
VALUES ('John Doe', 'john@example.com');
UPDATE: modifie les données existantes au sein d'une table.
UPDATE inventory
SET quantity = 50
WHERE product_id = 101;
DELETE: supprime les lignes existantes d'une table.
DELETE FROM orders
WHERE order_id = 12345;
Commandes DDL :
CREATE TABLE: crée une nouvelle table au sein de la base de données.
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50),
salary DECIMAL(10, 2)
);
ALTER TABLE: modifie une table existante au sein de la base de données.
ALTER TABLE employees
ADD hire_date DATE;
DROP TABLE: supprime une table entière de la base de données.
DROP TABLE customers;
Commandes DQL :
SELECT: fait également partie de DML mais est souvent associé à DQL car il est utilisé pour interroger des données uniquement.
L'instruction CASE
L'instruction CASE prend des scalaires, des prédicats, des appels de fonction, et même des requêtes SQL comme entrée et retourne une valeur d'expression. C'est un outil extrêmement polyvalent qui peut être utilisé pour transformer des données, effectuer une logique si-alors-sinon, catégoriser des informations, et plus encore.
Syntaxe de base de CASE :
SELECT column_name,
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
ELSE result3
END
FROM table_name;
Comprendre comment et quand utiliser les instructions CASE est une compétence SQL cruciale à maîtriser en tant qu'analyste de données traitant des ensembles de données complexes. Pour montrer les différentes instructions CASE, nous avons la table actions avec les champs user_id, action, et date.
CREATE TABLE actions (
"user_id" INTEGER,
"action" VARCHAR(50),
"date" DATE
);
INSERT INTO actions (
"user_id",
"action",
"date"
)
VALUES
(1, 'post', current_timestamp::DATE-3),
(2, 'edit', current_timestamp::DATE-2),
(3, 'post', current_timestamp::DATE-1),
(4, 'post', current_timestamp::DATE-1),
(5, 'edit', current_timestamp::DATE-5),
(6, 'cancel', current_timestamp::DATE-2),
(7, 'post', current_timestamp::DATE-2),
(8, 'post', current_timestamp::DATE-1),
(9, 'post', current_timestamp::DATE-1),
(10, 'cancel', current_timestamp::DATE-3),
(11, 'post', current_timestamp::DATE-2),
(12, 'post', current_timestamp::DATE-2);
Votre manager est sur le point d'entrer dans une réunion avec le directeur des événements et vous demande d'écrire une requête pour montrer le taux de publication actuel pour tous les temps arrondi à deux décimales. Dans ce cas, basé sur la structure de la table actions, nous devrons utiliser une instruction CASE.
select round(1.0*
sum(case when action='post' then 1 else 0 end)
/
count(1)
,2) post_rate
from actions;
Initialement, nous employons une instruction CASE pour assigner une valeur de 1 aux posts, et 0 sinon. Ensuite, nous agrégeons ces résultats en utilisant SUM(). Puis, nous divisons cette somme par le nombre total d'enregistrements, représenté par COUNT(1), qui inclut tous les enregistrements, pas exclusivement les posts.
Ce calcul donne notre taux de publication. Pour garantir la précision décimale, nous multiplions le numérateur par 1.0. Enfin, nous arrondissons le résultat entier à deux points décimaux comme nécessaire.
Sous-requêtes et expressions de table communes (CTE)
Les sous-requêtes, ou requêtes internes, vous permettent d'utiliser des requêtes au sein d'une autre instruction SQL. Les expressions de table communes (CTE) sont des ensembles de résultats temporaires nommés auxquels vous pouvez faire référence au sein d'une instruction SELECT, INSERT, UPDATE, ou DELETE.
Sous-requêtes :
- Sous-requête scalaire : une sous-requête qui retourne une seule valeur.
- Sous-requête de colonne : une sous-requête qui retourne une ou plusieurs colonnes.
- Sous-requête de table : une sous-requête qui ressemble à une table (utilisée avec n'importe quel opérateur attendant une table).
CTE :
- Fournissent une alternative plus lisible et maintenable à une table dérivée ou une sous-requête.
- Peuvent se référencer elles-mêmes, ce qui est utile pour les requêtes récursives.
Pour démontrer les cas d'utilisation, nous allons pratiquer avec à la fois la sous-requête traditionnelle et le CTE en utilisant le schéma SQL suivant :
CREATE TABLE all_numbers (
"phone_number" VARCHAR(25)
);
CREATE TABLE confirmed_numbers (
"phone_number" VARCHAR(25)
);
INSERT INTO all_numbers
("phone_number")
VALUES
('706-766-8523'),
('555-239-6874'),
('407-234-5041'),
('(123)351-6123'),
('251-874-3478');
INSERT INTO confirmed_numbers
("phone_number")
VALUES
('555-239-6874'),
('407-234-5041'),
('(123)351-6123');
Par exemple, disons que vous êtes un analyste de données chez DoorDash et on vous a demandé de récupérer tous les numéros de téléphone qui sont dans la table all_numbers mais qui ne sont pas présents dans la table confirmed_numbers. Vous pouvez résoudre cela en utilisant une sous-requête traditionnelle :
SELECT phone_number
FROM all_numbers
WHERE phone_number NOT IN (
SELECT phone_number
FROM confirmed_numbers
);
Alternativement, si la base de données est très grande, vous pourriez vouloir penser à utiliser un CTE puisque ils sont plus efficaces pour les grandes bases de données.
WITH excluded_numbers AS (
SELECT phone_number
FROM confirmed_numbers
)
SELECT phone_number
FROM all_numbers
WHERE phone_number NOT IN (
SELECT phone_number
FROM excluded_numbers
);
Jointures et unions
Les jointures vous aident à combiner des données de plusieurs tables basées sur une colonne liée entre elles, tandis que les unions vous permettent de combiner les ensembles de résultats de deux ou plusieurs instructions SELECT. Les deux sont critiques pour exploiter toute la puissance de vos requêtes SQL.
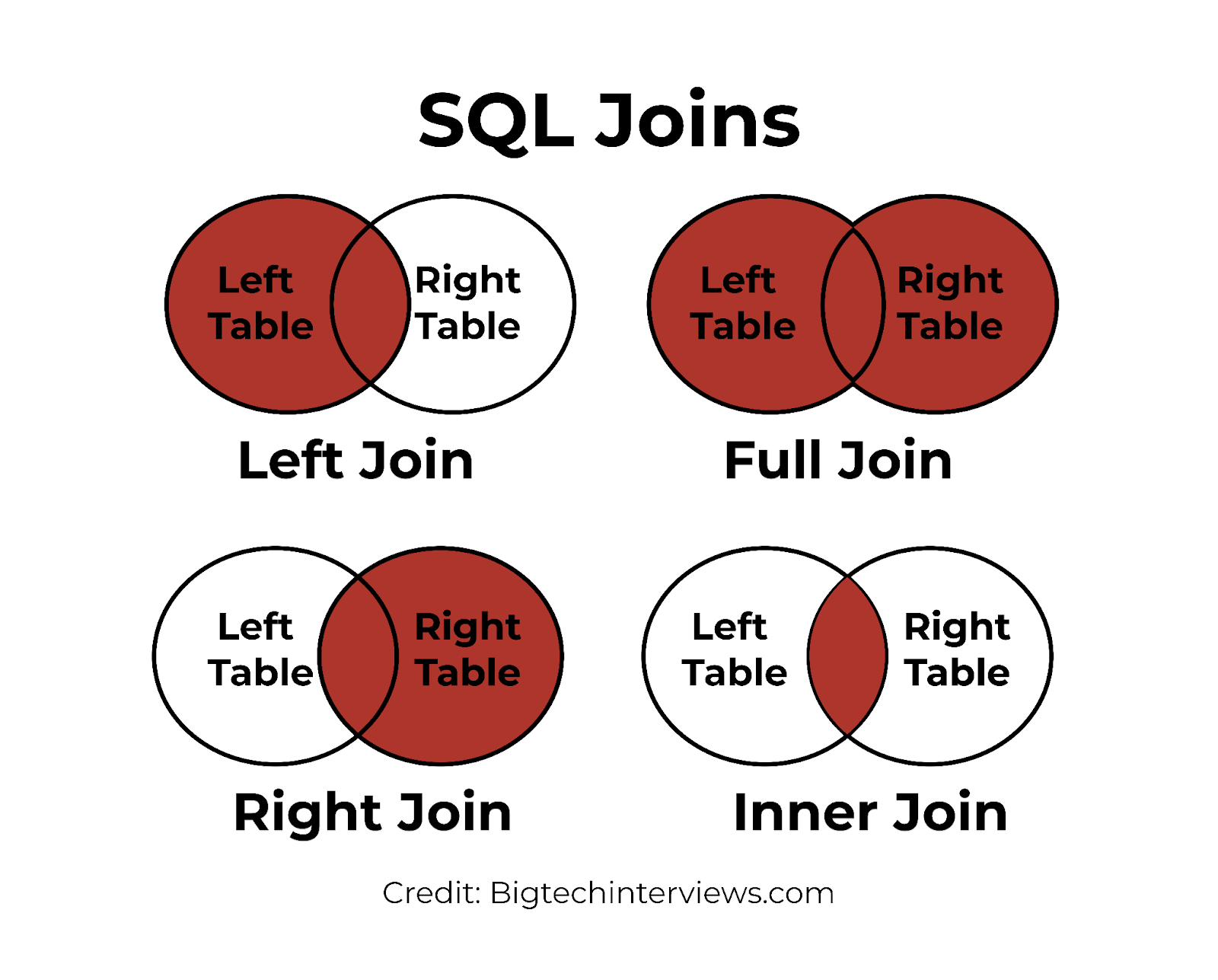
Types de jointures :
INNER JOIN: retourne les lignes lorsqu'il y a une correspondance dans les deux tables.LEFT JOIN: retourne toutes les lignes de la table de gauche et les lignes correspondantes de la table de droite.RIGHT JOIN: retourne toutes les lignes de la table de droite et les lignes correspondantes de la table de gauche.FULL JOIN: retourne toutes les lignes lorsqu'il y a une correspondance dans l'une des tables.
Pour illustrer les différents types de JOIN en SQL, considérons un scénario où nous voulons compiler la relation entre les chiffres de ventes et leurs représentants commerciaux correspondants dans différentes régions.
À cette fin, nous avons deux tables : sales_data et representatives. Elles sont liées par le champ rep_id, qui sert de clé étrangère dans la table sales_data et de clé primaire dans la table representatives. Voici à quoi cela ressemble :
CREATE TABLE sales_data (
sale_id INT PRIMARY KEY,
rep_id INT,
region VARCHAR(50),
sales DECIMAL(10, 2)
);
INSERT INTO sales_data (sale_id, rep_id, region, sales) VALUES
(1, 101, 'East', 1000.00),
(2, 102, 'East', 1500.50),
(3, 103, 'West', 2000.00),
(4, 104, 'West', 2500.75),
(5, NULL, 'West', 3000.00);
CREATE TABLE representatives (
rep_id INT PRIMARY KEY,
sales_rep VARCHAR(100),
region VARCHAR(50)
);
INSERT INTO representatives (rep_id, sales_rep, region) VALUES
(101, 'John Doe', 'East'),
(102, 'Jane Smith', 'East'),
(105, 'Jim Beam', 'North'),
(106, 'Jill Jackson', 'North'),
(107, 'Jack Johnson', 'South');
Pour notre exemple, supposons que nous voulons faire correspondre les ventes aux représentants dans la région Est. Nous utiliserions un INNER JOIN pour récupérer uniquement les lignes avec un rep_id correspondant dans les deux tables :
SELECT s.sales, r.sales_rep
FROM sales_data s
INNER JOIN representatives r
ON s.rep_id = r.rep_id
WHERE s.region = 'East';
Dans le cas où nous voulons voir toutes les données de ventes dans la région Ouest, y compris celles sans représentant commercial correspondant, un LEFT JOIN est utile :
SELECT s.sales, r.sales_rep
FROM sales_data s
LEFT JOIN representatives r
ON s.rep_id = r.rep_id
WHERE s.region = 'West';
Si notre intérêt est plutôt pour tous les représentants dans la région Nord, même ceux sans données de ventes associées, nous utiliserions un RIGHT JOIN :
SELECT s.sales, r.sales_rep
FROM sales_data s
RIGHT JOIN representatives r
ON s.rep_id = r.rep_id
WHERE r.region = 'North';
Enfin, pour voir toutes les combinaisons possibles de ventes et de représentants dans toutes les régions, indépendamment du rep_id correspondant, nous utilisons un FULL JOIN :
SELECT s.sales, r.sales_rep
FROM sales_data s
FULL JOIN representatives r
ON s.rep_id = r.rep_id;
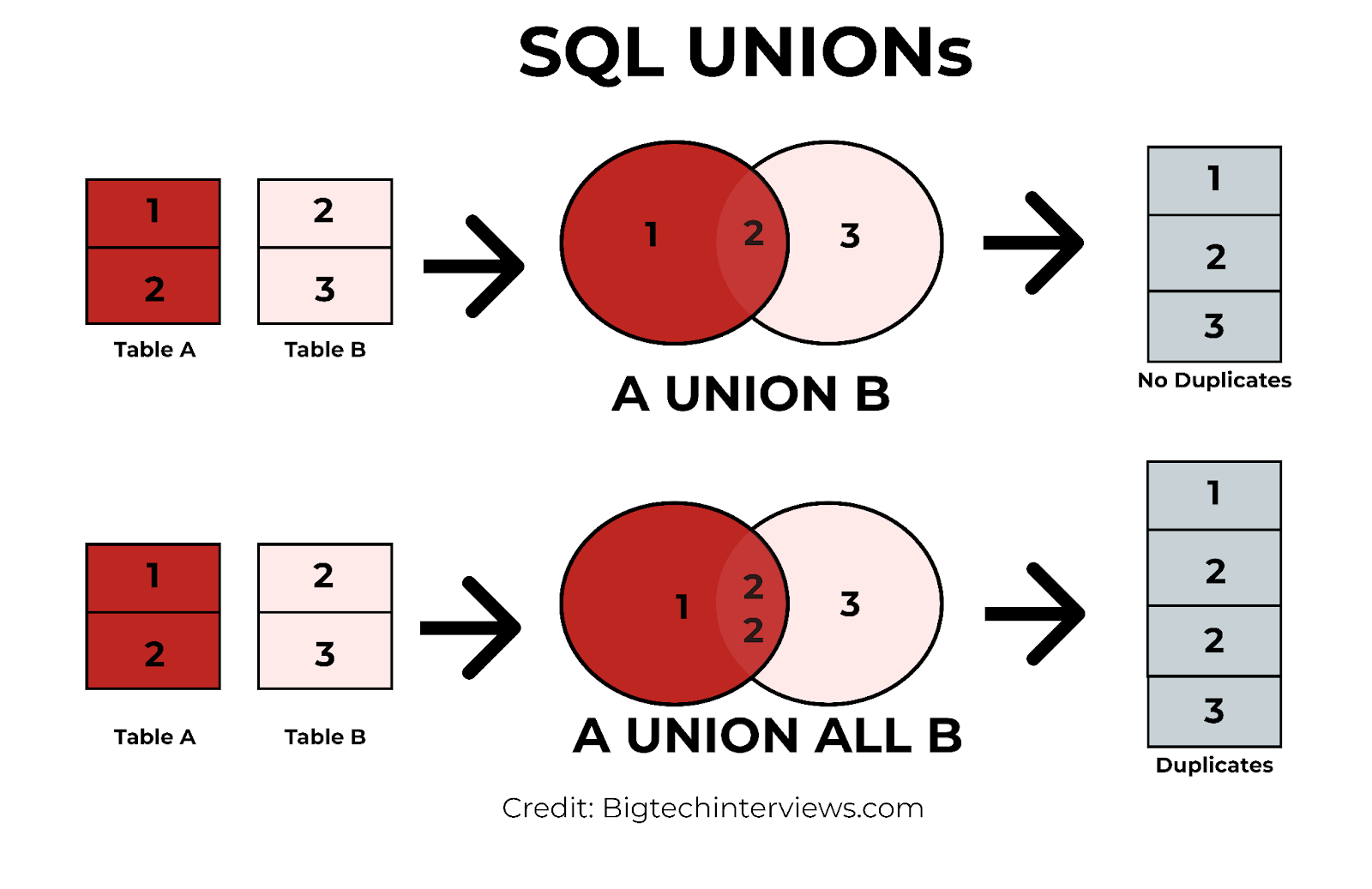
Union et Union All :
UNION: retourne les lignes distinctes qui apparaissent dans l'un ou l'autre des deux ensembles de résultats.UNION ALL: retourne toutes les lignes y compris les doublons.
En continuant avec le même schéma SQL ci-dessus contenant la table sales_data et la table representatives, examinons les scénarios où nous voudrions utiliser un UNION et un UNION ALL.
En utilisant un UNION, construisons une requête SQL pour récupérer efficacement les noms de tous les représentants commerciaux des tables sales_data et representatives.
SELECT sales_rep AS representative_name FROM representatives
UNION
SELECT DISTINCT rep_id AS representative_name FROM sales_data;
Maintenant, explorons comment utiliser une opération UNION ALL pour récupérer les noms de tous les représentants commerciaux des tables sales_data et representatives, y compris les doublons.
SELECT sales_rep AS representative_name FROM representatives
UNION ALL
SELECT DISTINCT rep_id AS representative_name FROM sales_data;
Formatage de chaînes et de dates
La manipulation des valeurs de chaînes et de dates est courante dans l'analyse de données. Comprendre comment formater ces types correctement est crucial pour une analyse significative.
Fonctions de chaînes :
CONCAT: fusionne deux ou plusieurs chaînes en une seule.SUBSTRING: retourne une partie d'une chaîne.LENGTHouLEN: retourne la longueur d'une chaîne.
Fonctions de dates :
DATEADD: ajoute un intervalle à une date.DATEDIFF: retourne le temps entre deux dates.DATENAMEouTO_CHAR: Retourne une partie d'une date comme le jour, le mois ou l'année.
Pour démontrer l'utilisation des fonctions de chaînes et de dates en SQL, plongeons dans un scénario impliquant des commandes et des livraisons.
Nous avons deux tables : orders et deliveries. Voici une ventilation de chaque table et de ses colonnes :
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
total_amount DECIMAL(10, 2)
);
INSERT INTO orders (order_id, customer_id, order_date, total_amount) VALUES
(1, 201, '2024-02-20', 500.00),
(2, 202, '2024-02-21', 750.25),
(3, 203, '2024-02-21', 1000.00),
(4, 204, '2024-02-22', 1200.75),
(5, 205, '2024-02-22', 1500.00);
CREATE TABLE deliveries (
delivery_id INT PRIMARY KEY,
order_id INT,
delivery_date DATE,
delivery_status VARCHAR(50)
);
INSERT INTO deliveries (delivery_id, order_id, delivery_date, delivery_status) VALUES
(1, 1, '2024-02-21', 'Delivered'),
(2, 2, '2024-02-22', 'In transit'),
(3, 3, '2024-02-22', 'Delivered'),
(4, 4, NULL, 'Pending'),
(5, 5, NULL, 'Pending');
Disons que vous avez été chargé d'optimiser les systèmes de suivi des commandes. Pour rationaliser ce processus, vous devez créer des identifiants de commande uniques en fusionnant les ID de client et les ID de commande. En utilisant la fonction CONCAT en SQL, vous fusionnez ces identifiants, assurant une gestion et une analyse efficaces des commandes.
SELECT CONCAT(customer_id, '-', order_id) AS order_identifier
FROM orders;
Votre prochaine tâche est de catégoriser avec précision les statuts de livraison, ce qui est essentiel pour l'efficacité opérationnelle. Mais les messages de statut de livraison contiennent souvent des détails non pertinents.
Pour simplifier ce processus, vous utilisez la fonction SUBSTRING en SQL pour extraire les caractères initiaux du statut de livraison. Cela permet une catégorisation et une analyse rapides de la progression de la livraison.
SELECT SUBSTRING(delivery_status, 1, 3) AS status_summary
FROM deliveries;
Maintenant, imaginez que vous devez garantir la cohérence des messages de statut de livraison. Il est crucial de valider que les mises à jour du statut de livraison respectent les contraintes de longueur définies.
En employant la fonction LENGTH/LEN en SQL, vous calculez la longueur de chaque message de statut de livraison. Cela facilite des mécanismes de validation robustes, garantissant l'uniformité et l'intégrité de vos données.
SELECT delivery_id, LENGTH(delivery_status) AS status_length
FROM deliveries;
Fonctions de dates
Lors de l'interrogation des tables orders et deliveries dans le schéma SQL fourni, la fonction DATEADD est particulièrement utile dans les scénarios où vous devez calculer des dates futures ou des délais basés sur des dates existantes.
Par exemple, vous pourriez utiliser DATEADD pour trouver la date de livraison prévue en ajoutant un certain nombre de jours à order_date pour garantir la livraison dans un délai prédéterminé.
SELECT order_id, customer_id, DATEADD(day, 3, order_date) AS expected_delivery_date
FROM orders;
La fonction DATEDIFF peut également être utile pour calculer les différences entre les dates. Par exemple, si vous devez trouver le temps moyen nécessaire pour qu'une commande soit livrée, vous pourriez soustraire order_date de delivery_date puis calculer la moyenne en utilisant AVG.
SELECT AVG(DATEDIFF(day,order_date,delivery_date)) AS average_delivery_time
FROM orders o INNER JOIN deliveries d ON o.order_id = d.order_id
WHERE delivery_status = 'Delivered';
La fonction TO_CHAR peut être utile pour convertir les dates dans un format spécifique. Par exemple, si vous devez afficher la date de livraison sous la forme Month DD, YYYY au lieu du format par défaut, vous pourriez utiliser TO_CHAR dans votre requête.
SELECT order_id, customer_id, TO_CHAR(delivery_date,'Month DD, YYYY') AS formatted_delivery_date
FROM orders o INNER JOIN deliveries d ON o.order_id = d.order_id;
Fonctions de fenêtre
Les fonctions de fenêtre sont une fonctionnalité puissante qui vous permet d'effectuer des calculs sur un ensemble de lignes de table liées à la ligne actuelle, connu sous le nom de fenêtre, sans avoir besoin d'une auto-jointure. Cela inclut la capacité à effectuer des totaux cumulés, des moyennes mobiles, et plus encore.
Fonctions de fenêtre courantes :
ROW_NUMBER(): assigne un numéro unique à chaque ligne à laquelle une fonction de fenêtre est appliquée.RANK(): fournit un rang à chaque ligne au sein d'un ensemble de résultats, avec le même rang donné aux lignes qui ont le même classement.DENSE_RANK(): similaire àRANK(), mais les rangs sont consécutifs.
CREATE TABLE product_data (
product_id INT PRIMARY KEY,
total_inventory INT NOT NULL,
total_sales INT NOT NULL,
region VARCHAR(50) NOT NULL
);
INSERT INTO product_data (product_id, total_inventory, total_sales, region) VALUES
(1, 100, 500, 'North America'),
(2, 150, 750, 'Europe'),
(3, 200, 1000, 'Asia'),
(4, 120, 1200, 'North America'),
(5, 180, 1500, 'Europe');
Par exemple, votre directeur des ventes vous envoie un message sur Slack et vous demande de calculer un total cumulé des ventes sur l'inventaire des produits. Vous pouvez faire cela en utilisant une fonction de fenêtre SUM de base.
SELECT
product_id,
total_inventory,
SUM(total_sales) OVER(ORDER BY product_id) AS running_total_sales
FROM product_data;
Maintenant, en approfondissant le problème. Supposons que c'est un grand ensemble de données et qu'Excel ne suffit pas pour cette tâche et que vous souhaitez le partitionner par region. Vous pouvez faire cela en appliquant ROW_NUMBER().
SELECT
region,
product_id,
ROW_NUMBER() OVER(PARTITION BY region ORDER BY product_id) AS region_product_rank
FROM product_data;
Alternativement, vous pourriez remplacer ROW_NUMBER() par DENSE_RANK() ou RANK() selon le cas d'utilisation.
Conclusion
En tant qu'analyste de données, votre maîtrise de SQL évoluera à mesure que vous traiterez des scénarios et des questions de données plus complexes.
Ces concepts SQL essentiels servent de bon point de départ – mais l'apprentissage continu et l'application de ces concepts dans des scénarios pratiques sont ce qui consolidera vraiment votre compréhension et votre expertise.
Continuez à explorer de nouvelles fonctionnalités, outils et ressources comme freeCodeCamp ou Big Tech Interviews, et vous trouverez que SQL est une compétence toujours gratifiante et toujours approfondissante à avoir dans votre boîte à outils de données.