

Article original : Comparing Brazilian and US university theses using natural language processing
Par Débora Mesquita
Les gens sont plus susceptibles de considérer une thèse écrite par un étudiant d'une université bien classée comme meilleure qu'une thèse produite par un étudiant d'une université de faible statut (ou sans statut).
Mais en quoi les travaux diffèrent-ils ? Que peuvent faire les étudiants des universités moins connues pour produire de meilleurs travaux et devenir plus connus ?
J'étais curieuse de répondre à ces questions, alors j'ai décidé d'explorer deux choses uniquement : les thèmes des travaux et leur nature. Mesurer la qualité d'une université est quelque chose de très complexe, et ce n'est pas mon objectif ici. Nous allons analyser un certain nombre de thèses de premier cycle en utilisant le traitement du langage naturel. Nous allons extraire des mots-clés en utilisant tf-idf et classer les thèses en utilisant l'Indexation Sémantique Latente (LSI).
Les données
Notre ensemble de données contient des résumés de thèses de premier cycle en informatique de l'Université Fédérale de Pernambuco (UFPE), située au Brésil, et de l'Université Carnegie Mellon, située aux États-Unis. Pourquoi Carnegie Mellon ? Parce que c'était la seule université où j'ai pu trouver une liste de thèses produites par des étudiants qui étaient à la fin de leur programme de premier cycle.
Le Times Higher Education World University Rankings indique que Carnegie Mellon a le 6ème meilleur programme en informatique, tandis que l'UFPE n'est même pas dans ce classement. Carnegie Mellon se classe 23ème dans le classement mondial des universités, et l'UFPE est autour de la 801ème place.
Tous les travaux ont été produits entre les années 2002 et 2016. Chaque thèse contient les informations suivantes :
- titre de la thèse
- résumé de la thèse
- année de la thèse
- université où la thèse a été produite
Les thèses de Carnegie Mellon peuvent être trouvées ici et les thèses de l'Université Fédérale de Pernambuco peuvent être trouvées ici.
Étape 1 — Investigation des thèmes des thèses
Extraction des mots-clés
Pour obtenir les thèmes de la thèse, nous allons utiliser un algorithme bien connu appelé tf-idf.
tf-idf
Ce que fait tf-idf, c'est pénaliser les mots qui apparaissent beaucoup dans un document et en même temps apparaissent beaucoup dans d'autres documents. Si cela se produit, le mot n'est pas un bon choix pour caractériser ce texte (car le mot pourrait également être utilisé pour caractériser tous les textes). Utilisons un exemple pour mieux comprendre cela. Nous avons deux documents :
Document 1 :
| Terme | Compte des termes | |--------|------------| | this | 1 | | is | 1 | | a | 2 | | sample | 1 |
Et Document 2 :
| Terme | Compte des termes | |---------|------------| | this | 1 | | is | 1 | | another | 2 | | example | 3 |
D'abord, voyons ce qui se passe. Le mot this apparaît 1 fois dans les deux documents. Cela pourrait signifier que le mot est neutre, n'est-ce pas ?
D'un autre côté, le mot example apparaît 3 fois dans le Document 2 et 0 fois dans le Document 1. Intéressant.
Maintenant, appliquons un peu de mathématiques. Nous devons calculer deux choses : TF (Fréquence des Termes) et IDF (Fréquence Inverse des Documents).
L'équation pour TF est :
TF(t) = (Nombre de fois que le terme t apparaît dans le document) / (Nombre total de termes dans le document)
Donc pour les termes this et example, nous avons :
TF('this', Document 1) = 1/5 = 0.2TF('example',Document 1) = 0/5 = 0
TF('this', Document 2) = 1/7 = 0.14TF('example',Document 2) = 3/7 = 0.43
L'équation pour IDF est :
IDF(t) = log_e(Nombre total de documents / Nombre de documents où le terme t est présent)
Pourquoi utilisons-nous un logarithme ici ? Parce que tf-idf est une heuristique.
L'intuition était qu'un terme de requête qui apparaît dans de nombreux documents n'est pas un bon discriminateur, et devrait être donné moins de poids que celui qui apparaît dans peu de documents, et la mesure était une implémentation heuristique de cette intuition. — Stephen Robertson
Comme usɛr11852 l'explique ici :
L'aspect mis en avant est que la pertinence d'un terme ou d'un document n'augmente pas proportionnellement avec la fréquence du terme (ou du document). L'utilisation d'une fonction sous-linéaire (le logarithme) aide donc à atténuer cet effet. … L'influence de valeurs très grandes ou très petites (par exemple, des mots très rares) est également amortie. — usɛr11852
En utilisant l'équation pour IDF, nous avons :
IDF('this', Documents) = log(2/2) = 0
IDF('example',Documents) = log(2/1) = 0.30
Et enfin, le TF-IDF :
TF-IDF('this', Document 2) = 0.14 x 0 = 0TF-IDF('example',Document 2) = 0.43 x 0.30 = 0.13
J'ai utilisé les 4 mots avec les scores les plus élevés issus de l'algorithme tf-idf pour chaque thèse. J'ai fait cela en utilisant CountVectorizer et TfidfTransformer de scikit-learn.
Vous pouvez voir le Jupyter notebook avec le code ici.
Avec 4 mots-clés pour chaque thèse, j'ai utilisé la bibliothèque WordCloud pour visualiser les mots pour chaque université.


Modélisation des sujets
Une autre stratégie que j'ai utilisée pour explorer les thèmes des thèses des deux universités était la modélisation des sujets avec l'Indexation Sémantique Latente (LSI).
Indexation Sémantique Latente
Cet algorithme obtient des données à partir de tf-idf et utilise la décomposition de matrice pour regrouper les documents en sujets. Nous aurons besoin de quelques notions d'algèbre linéaire pour comprendre cela, alors commençons.
Décomposition en Valeurs Singulières (SVD)
Tout d'abord, nous devons définir comment faire cette décomposition de matrice. Nous allons utiliser la Décomposition en Valeurs Singulières (SVD). Étant donné une matrice M de dimensions m x n, M peut être décrite comme :
M = UDV*
Où U et V* sont des bases orthonormées (V* représente la transposée de la matrice V). Une base orthonormée est le résultat si nous avons deux choses (normal + orthogonal) :
- lorsque tous les vecteurs sont de longueur 1
- lorsque tous les vecteurs sont mutuellement orthogonaux (ils forment un angle de 90°)
D est une matrice diagonale (les entrées en dehors de la diagonale principale sont toutes à zéro).
Pour avoir une idée de la manière dont tout cela fonctionne ensemble, nous allons utiliser l'explication géométrique brillante de cet article par David Austing.
Disons que nous avons une matrice M :
M = | 3 0 | | 0 1 |
Nous pouvons prendre un point (x,y) dans le plan et le transformer en un autre point en utilisant la multiplication de matrices :
| 3 0 | . | x | = | 3x || 0 1 | | y | | y |
L'effet de cette transformation est montré ci-dessous :
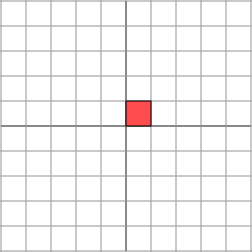
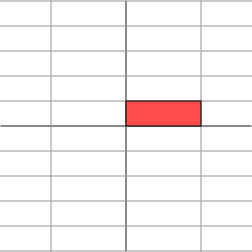
Comme nous pouvons le voir, le plan est étiré horizontalement d'un facteur de 3, tandis qu'il n'y a pas de changement vertical.
Maintenant, si nous prenons une autre matrice, M' :
M' = | 2 1 | | 1 2 |
L'effet est :
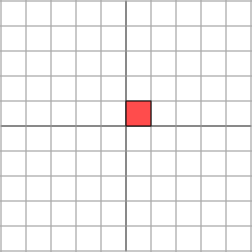
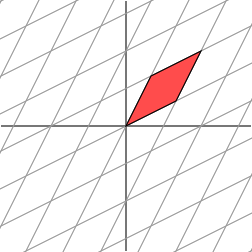
Il n'est pas si clair comment décrire simplement l'effet géométrique de la transformation. Cependant, tournons notre grille de 45 degrés et voyons ce qui se passe.
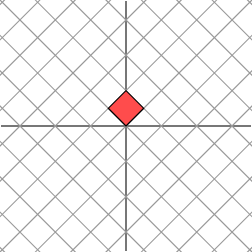
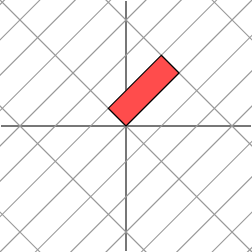
Nous voyons maintenant que cette nouvelle grille est transformée de la même manière que la grille originale était transformée par la matrice diagonale : la grille est étirée d'un facteur de 3 dans une direction.
Maintenant, utilisons quelques définitions. M est une matrice diagonale (les entrées en dehors de la diagonale principale sont toutes à zéro) et M et M' sont toutes deux symétriques (si nous prenons les colonnes et les utilisons comme nouvelles lignes, nous obtiendrons la même matrice).
Multiplier par une matrice diagonale entraîne un effet de mise à l'échelle (une transformation linéaire qui agrandit ou rétrécit les objets par un facteur d'échelle).
L'effet que nous avons vu (le même résultat pour M et M') est une situation très spéciale qui résulte du fait que la matrice M' est symétrique. Si nous avons une matrice symétrique 2 x 2, il s'avère que nous pouvons toujours faire tourner la grille dans le domaine de sorte que la matrice agisse en étirant et peut-être en réfléchissant dans les deux directions. En d'autres termes, les matrices symétriques se comportent comme des matrices diagonales. — David Austin
« C'est l'essence géométrique de la décomposition en valeurs singulières pour les matrices 2 x 2 : pour toute matrice 2 x 2, nous pouvons trouver une grille orthogonale qui est transformée en une autre grille orthogonale. » — David Austin
Nous allons exprimer ce fait en utilisant des vecteurs : avec un choix approprié de vecteurs unitaires orthogonaux v1 et v2, les vecteurs Mv1 et Mv2 sont orthogonaux.
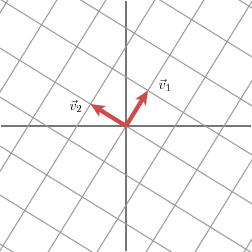
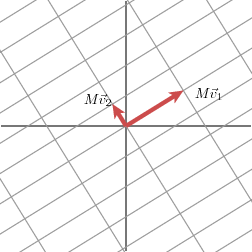
Nous allons utiliser n1 et n2 pour désigner les vecteurs unitaires dans la direction de Mv1 et Mv2. Les longueurs de Mv1 et Mv2 — désignées par σ1 et σ2 — décrivent la quantité dont la grille est étirée dans ces directions particulières.
Maintenant que nous avons une essence géométrique, revenons à la formule :
M = UDV*
- U est une matrice dont les colonnes sont les vecteurs n1 et n2 (vecteurs unitaires de la grille 'nouvelle', dans la direction de v1 et v2)
- D est une matrice diagonale dont les entrées sont σ1 et σ2 (la longueur de chaque vecteur)
- V* est une matrice dont les colonnes sont v1 et v2 (vecteurs de la grille 'ancienne')
Maintenant que nous comprenons un peu comment fonctionne la SVD, voyons comment la LSI utilise cette technique pour regrouper les textes. Comme le montre Ian Soboroff dans son cours de Recherche d'Information slides :
- U est une matrice pour transformer de nouveaux documents
- D est la matrice diagonale qui donne l'importance relative des dimensions (nous parlerons plus de ces dimensions dans un instant)
- V* est une représentation de M en k dimensions
Pour voir comment cela fonctionne, nous allons utiliser des titres de documents de deux domaines (Interaction Homme-Machine et Théorie des Graphes). Ces exemples proviennent de l'article An Introduction to Latent Semantic Analysis.
c1: Human machine interface for ABC computer applications c2: A survey of user opinion of computer system response time c3: System and human system engineering testing of EPS
m1: The generation of random, binary, ordered trees m2: The intersection graph of paths in trees m3: Graph minors: A survey
La première étape consiste à créer une matrice avec le nombre de fois que chaque terme apparaît :
| terme | c1 | c2 | c3 | m1 | m2 | m3 | |-----------|----|----|----|----|----|----|| human | 1 | 0 | 1 | 0 | 0 | 0 || interface | 1 | 0 | 0 | 0 | 0 | 0 | | computer | 1 | 1 | 0 | 0 | 0 | 0 | | user | 0 | 1 | 0 | 0 | 0 | 0 | | system | 0 | 1 | 2 | 0 | 0 | 0 | | survey | 0 | 1 | 0 | 0 | 0 | 1 | | trees | 0 | 0 | 0 | 1 | 1 | 0 | | graph | 0 | 0 | 0 | 0 | 1 | 1 | | minors | 0 | 0 | 0 | 0 | 0 | 1 |
En décomposant la matrice, nous obtenons ceci (vous pouvez utiliser cet outil en ligne pour appliquer la SVD) :
# Matrice U (pour transformer de nouveaux documents)
-0.386 0.222 -0.096 -0.458 0.357 -0.105-0.119 0.055 -0.434 -0.379 0.156 -0.040-0.345 -0.062 -0.615 -0.089 -0.264 0.135-0.226 -0.117 -0.181 0.290 -0.420 0.175-0.760 0.218 0.493 0.133 -0.018 0.044-0.284 -0.498 -0.176 0.374 0.033 -0.311-0.013 -0.321 0.289 -0.571 -0.582 -0.386-0.069 -0.621 0.185 -0.252 0.236 0.675-0.057 -0.382 0.005 0.085 0.453 -0.485
Matrice qui donne l'importance relative des dimensions :
# Matrice D (importance relative des dimensions)
2.672 0.000 0.000 0.000 0.000 0.0000.000 1.983 0.000 0.000 0.000 0.0000.000 0.000 1.625 0.000 0.000 0.0000.000 0.000 0.000 1.563 0.000 0.0000.000 0.000 0.000 0.000 1.263 0.0000.000 0.000 0.000 0.000 0.000 0.499
Représentation de M en k dimensions (dans ce cas, nous avons k documents) :
# Matrice V* (représentation de M en k dimensions)
-0.318 -0.604 -0.713 -0.005 -0.031 -0.153 0.108 -0.231 0.332 -0.162 -0.475 -0.757-0.705 -0.294 0.548 0.178 0.291 0.009-0.593 0.453 -0.122 -0.365 -0.527 0.132 0.197 -0.531 0.254 -0.461 -0.274 0.572-0.020 0.087 -0.033 -0.772 0.580 -0.242
D'accord, nous avons les matrices. Mais maintenant la matrice n'est pas 2 x 2. Avons-nous vraiment besoin du nombre de dimensions que cette matrice terme-document a ? Toutes les dimensions sont-elles des caractéristiques importantes pour chaque terme et chaque document ?
Revenons à l'exemple de David Austin. Disons maintenant que nous avons M'' :
M'' = | 1 1 | | 2 2 |
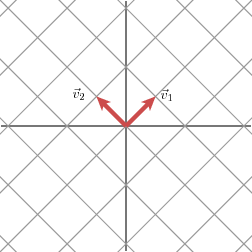
Maintenant, M'' n'est plus une matrice symétrique. Pour cette matrice, la valeur de σ2 est zéro. Sur la grille, le résultat de la multiplication est :
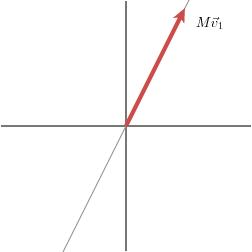
Nous avons que si une valeur de la diagonale principale de D est zéro, ce terme n'apparaît pas dans la décomposition de M.
De cette manière, nous voyons que le rang de M, qui est la dimension de l'image de la transformation linéaire, est égal au nombre de valeurs non nulles. — David Austin
Ce que fait la LSI, c'est changer la dimensionnalité des termes.
Dans la matrice originale, les termes sont k-dimensionnels (k est le nombre de documents). Le nouvel espace a une dimensionnalité plus faible, donc les dimensions sont maintenant des groupes de termes qui tendent à co-occurrencer dans les mêmes documents. — Ian Soboroff
Maintenant, nous pouvons revenir à l'exemple. Créons un espace avec deux dimensions. Pour cela, nous n'utiliserons que deux valeurs de la matrice diagonale D :
# Matrice D2
2.672 0.000 0.000 0.000 0.000 0.0000.000 1.983 0.000 0.000 0.000 0.0000.000 0.000 0.000 0.000 0.000 0.0000.000 0.000 0.000 0.000 0.000 0.0000.000 0.000 0.000 0.000 0.000 0.0000.000 0.000 0.000 0.000 0.000 0.000
Comme Alex Thomo l'explique dans ce tutoriel, les termes sont représentés par les vecteurs lignes de U2 x D2 (U2 est U avec seulement 2 dimensions) et les documents sont représentés par les vecteurs colonnes de D2 x V2* (V2* est V* avec seulement 2 dimensions). Nous multiplions par D2 parce que D est la matrice diagonale qui donne l'importance relative des dimensions, vous vous souvenez ?
Ensuite, nous calculons les coordonnées de chaque terme et de chaque document à travers ces multiplications. Le résultat est :
human = (-1.031, 0.440)interface = (-0.318, 0.109)computer = (-0.922, -0.123)user = (-0.604, -0.232)system = (-2.031, -0.232) survey = (-0.759, -0.988)trees = (-0.035, -0.637)graph = (-0.184, -1.231) minors = (-0.152, -0.758)
c1 = (-0.850, 0.214)c2 = (-1.614, -0.458)c3 = (-1.905, 0.658)m1 = (-0.013, -0.321)m2 = (-0.083, -0.942)m3 = (-0.409, -1.501)
En utilisant matplotlib pour visualiser cela, nous avons :

Cool, n'est-ce pas ? Les vecteurs en rouge sont des documents d'Interaction Homme-Machine et ceux en bleu sont des documents de Théorie des Graphes.
Et le choix du nombre de dimensions ?
Le nombre de dimensions retenues dans la LSI est une question empirique. Parce que le principe sous-jacent est que les données originales ne doivent pas être parfaitement régénérées, mais plutôt qu'une dimensionnalité optimale doit être trouvée pour induire correctement les relations sous-jacentes, l'approche factorielle analytique habituelle consistant à choisir une dimensionnalité qui représente le plus parcimonieusement la vraie variance des données originales n'est pas appropriée. — Source
La mesure de similarité calculée dans l'espace de dimension réduite est généralement, mais pas toujours, le cosinus entre les vecteurs.
Et maintenant, nous pouvons revenir à l'ensemble de données avec les thèses des universités. J'ai utilisé le modèle lsi de gensim. Je n'ai pas trouvé beaucoup de différences entre les travaux des universités (tous semblaient appartenir au même cluster). Le sujet qui différenciait le plus les travaux des universités était celui-ci :
y topic:[('object', 0.29383227033104375), ('software', -0.22197520420133632), ('algorithm', 0.20537550622495102), ('robot', 0.18498675015157251), ('model', -0.17565360130127983), ('project', -0.164945961528315), ('busines', -0.15603883815175643), ('management', -0.15160458583774569), ('process', -0.13630070297362168), ('visual', 0.12762128292042879)]
Visuellement, nous avons :
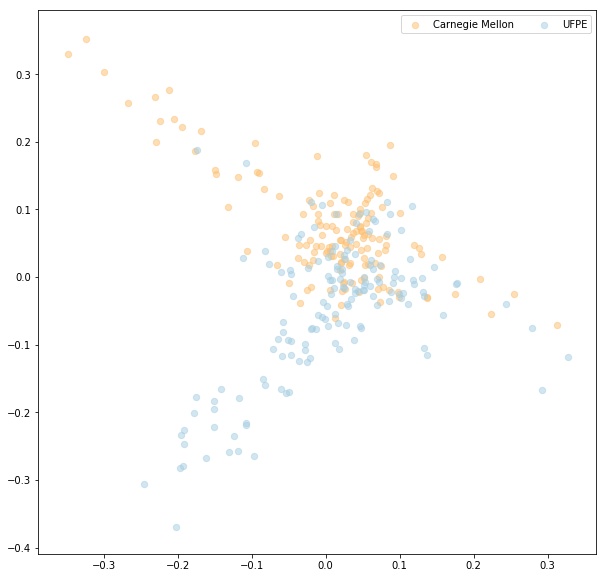
Sur l'image, le sujet y est sur l'axe des y. Nous pouvons voir que les thèses de Carnegie Mellon sont plus associées à 'object', 'robot', et 'algorithm' et les thèses de l'UFPE sont plus associées à 'software', 'project', et 'business'.
Vous pouvez voir le Jupyter notebook avec le code ici.
Étape 2 — Investigation de la nature des travaux
J'ai toujours eu l'impression qu'au Brésil, les étudiants produisent beaucoup de thèses avec des revues de littérature, tandis que dans les autres universités, ils font peu de thèses comme celle-ci. Pour vérifier, j'ai analysé les titres des thèses.
Habituellement, lorsqu'une thèse est une revue de littérature, le mot 'study' apparaît dans le titre. J'ai ensuite pris tous les titres de toutes les thèses et vérifié les mots qui apparaissent le plus, pour chaque université. Les résultats étaient :


Vous pouvez voir le Jupyter notebook avec le code ici.
Résultats
L'impression que j'ai eue de cette analyse simple était que les thèmes des travaux ne différaient pas beaucoup. Mais il était possible de visualiser ce qui semble être les spécialités de chaque institution. L'Université Fédérale de Pernambuco produit plus de travaux liés aux projets et aux affaires et Carnegie Mellon produit plus de travaux liés aux robots et aux algorithmes. À mon avis, cette différence de spécialités n'est pas quelque chose de mauvais, elle montre simplement que chaque université est spécialisée dans certains domaines.
Un point à retenir était qu'au Brésil, nous devons produire des travaux différents au lieu de simplement faire des revues de littérature.
Une chose importante que j'ai réalisée en faisant l'analyse (et qui ne vient pas des résultats de l'analyse elle-même), c'est que simplement avoir la meilleure thèse ne suffit pas. J'ai commencé l'analyse en essayant d'identifier pourquoi ils produisent de meilleurs travaux que nous et ce que nous pouvons faire pour y arriver et devenir plus connus. Mais j'ai senti que peut-être une façon d'y arriver est simplement de montrer plus de nos travaux et d'échanger plus de connaissances avec eux. La raison est que cela peut nous forcer à produire des articles plus pertinents et à nous améliorer avec les retours.
Je pense aussi que cela s'applique à tout le monde, tant pour les étudiants universitaires que pour nous, les professionnels. Cette citation qui résume bien cela :
« Ce n'est pas suffisant d'être bon. Pour être trouvé, il faut être trouvable. » — Austin Kleon
Et c'est tout, merci d'avoir lu !
Si vous avez trouvé cet article utile, cela signifierait beaucoup si vous cliquez sur le ? et partagez avec des amis. Suivez-moi pour plus d'articles sur la Science des Données et l'Apprentissage Automatique.