


Article original : How to Use Python and Pandas to Map Major Storms, Pessimism, and Hard Data
Parfois, il peut être quelque peu réconfortant de réfléchir à combien tout est pire maintenant qu'à l'époque.
"Les enfants n'ont aucun respect."
"Tout coûte beaucoup trop cher."
"Les responsables publics n'inspirent pas confiance."
"Et qu'en est-il du temps ? Nous n'avions pas l'habitude d'avoir autant d'ouragans dévastateurs, n'est-ce pas ?"
Je suis assez vieux pour avoir fait le tour du pâté de maisons quelques fois et je ne suis pas sûr. Je n'étais pas exactement angélique enfant, les choses coûtaient toujours plus cher que ce que nous voulions, et les responsables publics n'ont jamais été les créatures les plus aimées de la planète. Mais les grandes tempêtes ? Je n'en ai aucune idée.
Il s'avère qu'il existe beaucoup d'excellentes données sur les tempêtes, donc il n'y a aucune raison de ne pas chercher au moins quelques indices. Et mes tentatives d'ajouter l'analyse de données à mon stock existant d'outils professionnels pourraient aider ici.
D'abord, cependant, nous devrions définir soigneusement quelques termes et remplir quelques détails de contexte.
Qu'est-ce qu'une grande tempête ?
Les ouragans - ou, plus précisément, les cyclones tropicaux - sont "tropicaux" dans le sens où ils se forment au-dessus des océans dans les régions tropicales. Le terme "tropiques" fait référence à la zone de la surface de la terre qui se situe à 23 degrés (ou environ) de l'équateur, au nord et au sud.
Les tempêtes sont appelées "cyclones" parce que le mouvement de leurs vents est cyclique (dans le sens des aiguilles d'une montre dans l'hémisphère sud et dans le sens inverse dans l'hémisphère nord).
Les cyclones sont alimentés par l'eau de l'océan évaporée et laissent derrière eux des orages violents et souvent violents - surtout après avoir dérivé sur des zones terrestres habitées.
En termes généraux, une tempête produisant des vents soutenus d'environ 34 à 63 nœuds (ou entre 39 et 72 miles par heure) est considérée comme une tempête tropicale. Les tempêtes avec des vents supérieurs à 64 nœuds (73 mph) sont des ouragans (ou, dans les océans Pacifique occidental ou Indien nord, des typhons).
Les ouragans sont mesurés par des catégories de un à cinq, où les ouragans de catégorie cinq sont les plus violents et dangereux.
D'où viennent les données sur les grandes tempêtes ?
Des données historiques fiables et largement cohérentes sur les tempêtes existent, au moins aux États-Unis, pour le siècle et demi passé. Mais comprendre correctement le contexte de ces données nécessitera quelques connaissances sur la manière dont ces observations ont été faites au fil des ans.
Jusqu'aux années 1940, la plupart des observations étaient faites par les équipages des navires océaniques. Mais les équipages des navires ne peuvent observer et rapporter que ce qu'ils voient, et ce qu'ils voient sera déterminé par l'endroit où ils vont.
Avant l'ouverture du canal de Panama en 1914, les navires voyageant entre l'Europe et l'océan Pacifique suivaient une route autour de la pointe sud de l'Amérique du Sud qui évitait largement les zones côtières des États-Unis. Par conséquent, il est probable qu'un pourcentage important d'événements météorologiques ait été simplement manqué.
De même, l'avènement de la reconnaissance aérienne dans les années 1940 aurait permis aux scientifiques de détecter davantage d'événements qui auraient autrement été manqués. Et l'utilisation de satellites météorologiques à partir des années 1960 nous a permis de détecter presque toute l'activité océanique.
Ces changements et leur impact sur les données des tempêtes sont résumés sur cette page du site de l'Administration nationale océanique et atmosphérique (NOAA) du gouvernement américain, basée sur une étude d'analyse de données réalisée pour le Geophysical Fluid Dynamics Laboratory (GFDL).
Que montre le registre historique ?
Alors, après tout ce contexte, que disent réellement les données ? Les ouragans graves sont-ils plus fréquents maintenant qu'auparavant ? Eh bien, selon le site de la NOAA, la réponse est : "Non." Voici comment ils le formulent :
"Les tempêtes tropicales de l'Atlantique durant plus de 2 jours n'ont pas augmenté en nombre. Les tempêtes durant moins de deux jours ont fortement augmenté, mais cela est probablement dû à de meilleures observations... Nous ne sommes pas au courant d'un signal de changement climatique qui entraînerait une augmentation uniquement des tempêtes de durée la plus courte, tandis qu'une telle augmentation est qualitativement cohérente avec ce à quoi l'on pourrait s'attendre des améliorations des pratiques d'observation."
Vous obtiendrez toute l'histoire, y compris une bonne explication des choix de manipulation de données qu'ils ont faits, en lisant l'étude elle-même. En fait, je vous encourage à lire cette étude, car c'est un excellent exemple de la manière dont les professionnels abordent les problèmes de données.
À partir de maintenant, cependant, vous serez coincé avec mes tentatives d'amateur et simplifiées de visualiser le registre de données brutes et non ajustées.
Données sur les ouragans aux États-Unis : 1851-2019
Notre source pour les données sur les "Impacts/Terres des ouragans des États-Unis continentaux" est cette page web de la NOAA.
Pour télécharger les données, j'ai simplement copié en cliquant avec ma souris en haut à gauche (le champ d'en-tête "Année") et en faisant glisser jusqu'en bas à droite. Je l'ai ensuite collé dans un éditeur de texte brut sur mon ordinateur local et l'ai enregistré dans un fichier avec l'extension .csv.
Comment nettoyer les données sur les ouragans
Si vous regardez rapidement la page web elle-même, vous verrez un certain formatage qui nécessitera un nettoyage. Chaque décennie est introduite par une seule ligne ne contenant rien d'autre qu'une chaîne ressemblant à : 1850s. Nous voudrons simplement supprimer ces lignes. Les années sans événements contiennent la chaîne none dans la deuxième colonne. Celles-ci aussi devront être supprimées.
Il y a certains événements qui n'ont apparemment aucune donnée pour leurs vitesses de vent maximales. Au lieu d'un nombre (mesuré en nœuds), les valeurs de vitesse pour ces événements sont représentées par cinq tirets (-----). Nous devrons convertir cela en quelque chose avec lequel nous pouvons travailler.
Et enfin, bien que les mois soient généralement représentés par des abréviations de trois lettres, il y avait quelques événements qui s'étendaient sur deux mois. Donc, pour pouvoir traiter correctement ceux-ci, je vais convertir Sp-Oc et Jl-Au en Sep et Jul respectivement.
Le fait est que nous n'utiliserons pas réellement la colonne des mois, donc cela ne fera pas vraiment de différence. Mais c'est un bon outil à connaître.
Voici comment nous configurons les choses dans Jupyter :
import pandas as pd
import matplotlib as plt
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('all-us-hurricanes-noaa.csv')
Regardons les types de données pour chaque colonne. Nous pouvons ignorer les chaînes dans les colonnes États et Nom - nous ne sommes pas intéressés par celles-ci de toute façon. Mais nous devrons faire quelque chose avec les colonnes date et vent maximal - elles ne nous seront d'aucune utilité en tant qu'object.
df.dtypes
Year object
Month object
States Affected and Category by States object
Highest\nSaffir-\nSimpson\nU.S. Category float64
Central Pressure\n(mb) float64
Max Wind\n(kt) object
Name object
dtype: object
Je vais donc filtrer toutes les lignes de la colonne Year pour la lettre s et les supprimer simplement (== False). Cela prendra en charge tous les en-têtes de décennie (c'est-à-dire ces lignes contenant un s dans le cadre de quelque chose comme 1850s).
Je vais également supprimer les lignes contenant la chaîne None dans la colonne Month pour éliminer les années sans événements de tempête.
Bien que les années calmes puissent avoir un certain impact sur nos visualisations, je soupçonne que les inclure avec une sorte de valeur nulle risquerait probablement de fausser encore plus les choses dans l'autre sens. Elles compliqueraient également grandement nos visualisations.
Enfin, je vais remplacer ces deux lignes multi-mois.
df = df[(df.Year.str.contains("s")) == False]
df = df[(df.Month.str.contains("None")) == False]
df = df.replace('Sp-Oc','Sep')
df = df.replace('Jl-Au','Jul')
Ensuite, j'utiliserai la méthode pratique Pandas to-datetime pour convertir les abréviations de mois en trois lettres en nombres compris entre 1 et 12. Le code de format %b est l'une des désignations légales liées aux dates de Python et indique à Python que nous travaillons avec une abréviation en trois lettres. Pour la liste complète, voir cette page.
df.Month = pd.to_datetime(df.Month, format='%b').dt.month
J'aimerais resserrer un peu les en-têtes pour qu'ils soient un peu plus faciles à lire et à référencer dans notre code. df.columns changera toutes les valeurs d'en-tête de colonne en la liste que je spécifie ici :
df.columns =['Year', 'Month', 'States', 'Category',
'Pressure', 'Max Wind', 'Name']
Je devrai convertir les données de l'année d'objets chaîne en entiers, sinon Python ne saura pas comment travailler avec eux de manière appropriée. Cela se fait en utilisant astype.
Comme annoncé, je vais également convertir les valeurs nulles (-----) dans Max Wind en NaN - que NumPy lira comme "not a number". Je vais ensuite convertir les données dans Max Wind de object en float.
df = df.astype({'Year': 'int'})
df = df.replace('-----',np.NaN)
df = df.astype({'Max Wind': 'float'})
Voyons à quoi tout cela ressemble maintenant :
df.dtypes
Year int64
Month int64
States object
Category float64
Pressure float64
Max Wind float64
Name object
dtype: object
Beaucoup mieux.
Comment présenter les données sur les ouragans
Maintenant, en regardant nos données, je vais suggérer que nous décomposions les trois métriques : catégorie d'ouragan, pression barométrique et vitesses de vent maximales.
Mon raisonnement est qu'il y a peu à gagner de la complication ajoutée en les regroupant, et nous risquons de perdre de vue les différences importantes entre les incidents de tempêtes plus légères et plus graves.
Bien sûr, je peux toujours isoler des métriques individuelles pour voir à quoi ressembleraient leurs distributions. En utilisant value_counts contre la colonne Category, par exemple, cela me montre que les ouragans de catégorie 1 et 2 plus légers sont beaucoup plus fréquents que les événements plus dangereux.
df['Category'].value_counts()
1.0 121
2.0 83
3.0 62
4.0 25
5.0 4
Name: Category, dtype: int64
Et tracer un seul histogramme de l'ensemble complet de données nous donne un bon aperçu du nombre d'événements (représenté sur l'axe des y) à travers l'histoire, mais nous risquons de perdre certains des détails plus fins dans le processus.
À partir de cet histogramme, il est évident qu'il n'y a eu aucun changement notable dans la fréquence des tempêtes au fil du temps. Pour être sûr que mon choix du nombre de bins que nous utilisons ne masque pas involontairement des tendances importantes, expérimentez avec d'autres valeurs que 25.
df.hist(column='Year', bins=25)
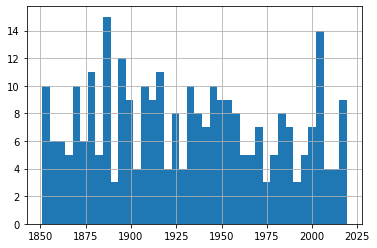 Tous les événements d'ouragans
Tous les événements d'ouragans
Mais pour nous permettre de nous concentrer sur chaque métrique, je vais tracer trois graphiques séparés. Pour ce faire, je vais créer trois nouveaux dataframes et remplir chacun d'entre eux avec le contenu de la colonne Year et la colonne de données respective.
df_category = df[['Year','Category']]
df_wind = df[['Year','Max Wind']]
df_pressure = df[['Year','Pressure']]
Envoyer chacun de ces dataframes directement à un graphique manquera le point, car il ne distinguera pas la gravité des tempêtes. Je vais donc vous montrer comment nous pouvons décomposer les données par catégorie (1-5). Cette boucle for va itérer à travers les nombres 1-6 (ce qui est "Python" pour retourner les nombres entre 1 et 5) et utilise chacun de ces nombres à son tour pour rechercher des ouragans de cette catégorie.
Les lignes dont la catégorie correspond au nombre seront écrites dans un nouveau dataframe (temporaire) appelé df1 qui sera, à son tour, utilisé pour tracer un histogramme. La ligne plt.title applique un titre au graphique imprimé qui inclura le numéro de catégorie (la valeur actuelle de converted_num).
La boucle va parcourir le processus cinq fois, écrivant chaque fois le nombre d'événements de la catégorie actuelle dans df1. Les cinq histogrammes seront imprimés, les uns après les autres.
for x in range(1, 6):
cat_num = x
converted_num = str(cat_num)
dfcat = df_category['Category']==(x)
df1 = df_category[dfcat]
df1.hist(column='Year', bins=20)
plt.title("Total Category " + (converted_num) + " Events")
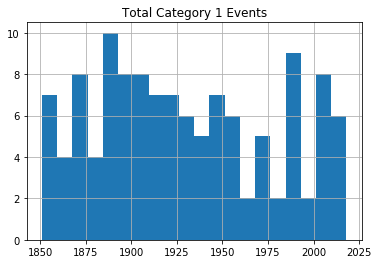 Ouragans de catégorie 1
Ouragans de catégorie 1
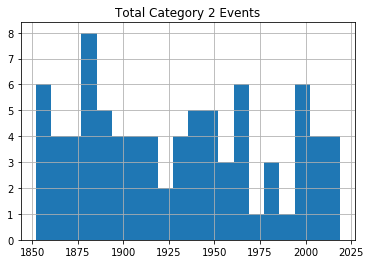 Ouragans de catégorie 2
Ouragans de catégorie 2
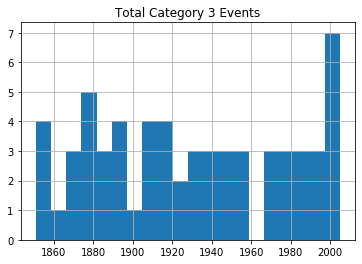 Ouragans de catégorie 3
Ouragans de catégorie 3
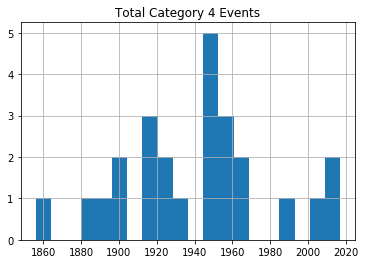 Ouragans de catégorie 4
Ouragans de catégorie 4
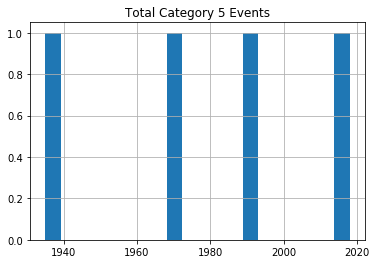 Ouragans de catégorie 5
Ouragans de catégorie 5
Comme vous pouvez le voir, il n'y a aucune preuve notable d'une augmentation significative de la fréquence des tempêtes au fil du temps.
Comme toujours, analysez vos données (en utilisant des outils comme value_counts()) pour confirmer que les graphiques ont du sens dans le monde réel.
Données sur les tempêtes tropicales aux États-Unis : 1851-1965, 1983-2019
Les ouragans (ou cyclones) ne sont, bien sûr, qu'une partie de l'histoire. Une augmentation de la fréquence des tempêtes tropicales destructrices serait également une source de préoccupation.
Heureusement, la NOAA met à disposition des données pertinentes dans un format largement similaire à celui de leurs données sur les ouragans. Voici la page web où vous trouverez le tableau. Copiez les données dans un fichier .csv de la même manière qu'auparavant.
Notez, cependant, qu'il n'y a pas de données pour les années 1966-1982. Ne me demandez pas pourquoi. Il n'y en a tout simplement pas. Drôle de chose, la météo.
Je créerais un nouveau notebook Jupyter pour cette partie du projet, car il n'y a rien dont nous aurons besoin de la version ouragan. Par conséquent, vous allez configurer les choses comme toujours :
import pandas as pd
import matplotlib as plt
import numpy as np
df = pd.read_csv('all-us-tropical-storms-noaa.csv')
Nettoyons les données sur les tempêtes tropicales
Les lignes représentant les années sans événements doivent, à nouveau, être supprimées :
df = df[(df.Date.str.contains("None")) == False]
La colonne Date de cet ensemble de données contient des caractères pointant vers cinq notes de bas de page : $, *, #, %, et &. Les notes de bas de page contiennent des informations importantes, mais ces caractères nous causeront des ennuis si nous ne les supprimons pas.
Ces commandes feront cela, en remplaçant toutes ces chaînes dans la colonne Date par rien :
df['Date'] = df.Date.str.replace('\$', '')
df['Date'] = df.Date.str.replace('\*', '')
df['Date'] = df.Date.str.replace('\#', '')
df['Date'] = df.Date.str.replace('\%', '')
df['Date'] = df.Date.str.replace('\&', '')
Ensuite, je vais réinitialiser les en-têtes de colonne. D'abord, parce que ce sera plus facile de travailler avec des noms courts et agréables. Mais principalement parce que, en tant qu'administrateur système Linux, je trouve les espaces dans les noms de fichiers ou les en-têtes moralement offensants.
df.columns =['Storm#', 'Date', 'Time', 'Lat', 'Lon',
'MaxWinds', 'LandfallState', 'StormName']
Les types de données des colonnes vont nécessiter un certain travail :
df.dtypes
Storm# object
Date object
Time object
Lat object
Lon object
MaxWinds float64
LandfallState object
StormName object
dtype: object
Voyons à quoi ressemblent nos données :
df.head()
Storm# Date Time Lat Lon MaxWindsLandfallState StormName
6 10/19/1851 1500Z 41.1N 71.7W 50.0 NY NaN
3 8/19/1856 1100Z 34.8 76.4 50.0 NC NaN
4 9/30/1857 1000Z 25.8 97 50.0 TX NaN
3 9/14/1858 1500Z 27.6 82.7 60.0 FL NaN
3 9/16/1858 0300Z 35.2 75.2 50.0 NC NaN
Je ne suis pas vraiment sûr de ce que signifient ces valeurs Storm #, mais elles ne font de mal à personne. Les dates sont mieux formatées qu'elles ne l'étaient pour les données sur les ouragans. Mais je devrai les convertir dans un nouveau format. Faisons cela correctement et utilisons datetime.
df.Date = pd.to_datetime(df.Date)
Comment présenter les données sur les tempêtes tropicales
Pour nos besoins, la seule colonne de données qui compte vraiment est MaxWinds - car c'est ce qui définit l'intensité de la tempête. Cette commande créera un nouveau dataframe composé des colonnes Date et MaxWinds :
df1 = df[['Date','MaxWinds']]
Aucune raison de reporter cela : nous pourrions aussi bien lancer un histogramme tout de suite. Vous verrez immédiatement l'écart autour de 1970 où il n'y avait pas de données. Vous verrez également que, encore une fois, il ne semble pas y avoir beaucoup de tendance à la hausse.
df1['Date'].hist()
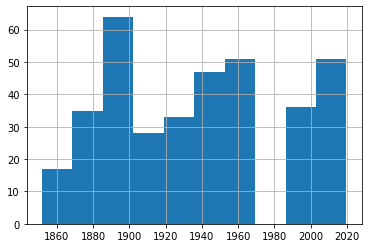 Histogramme de toutes les tempêtes tropicales
Histogramme de toutes les tempêtes tropicales
Mais nous devrions vraiment creuser un peu plus ici. Après tout, ces données mélangent simplement des tempêtes de 30 nœuds avec des tempêtes de 75 nœuds. Nous voudrons définitivement savoir si elles se produisent à des rythmes similaires ou non.
Découvrons combien de lignes de données nous avons. shape nous dit que nous avons 362 événements au total.
print(df1.shape)
(362, 2)
L'impression de notre dataframe nous montre que les valeurs MaxWinds sont toutes des multiples de 5. Si vous parcourez les données vous-même, vous verrez qu'elles varient entre 30 et 70 environ.
df1
Date MaxWinds
1 1851-10-19 50.0
6 1856-08-19 50.0
7 1857-09-30 50.0
8 1858-09-14 60.0
9 1858-09-16 50.0
... ... ...
391 2017-09-27 45.0
392 2018-05-28 40.0
393 2018-09-03 45.0
394 2018-09-03 45.0
395 2019-09-17 40.0
362 rows × 2 columns
Divisons donc nos données en quatre ensembles plus petits en tant que proxys raisonnables pour les tempêtes de divers niveaux d'intensité. J'ai créé quatre dataframes et les ai remplis avec des événements tombant dans leurs plages plus étroites (c'est-à-dire entre 30 et 39 nœuds, 40 et 49, 50 et 59, et 60 et 79). Cela devrait nous donner un cadre de référence raisonnable pour nos événements.
df_30 = df1[df1['MaxWinds'].between(30, 39)]
df_40 = df1[df1['MaxWinds'].between(40, 49)]
df_50 = df1[df1['MaxWinds'].between(50, 59)]
df_60 = df1[df1['MaxWinds'].between(60, 79)]
Confirmons que les points de coupure que nous avons choisis ont du sens. Ce code imprimera de manière attrayante le nombre de lignes dans l'index de chacun de nos quatre dataframes.
st1 = len(df_30.index)
print('Le nombre de tempêtes entre 30 et 39 : ', st1)
st2 = len(df_40.index)
print('Le nombre de tempêtes entre 40 et 49 : ', st2)
st3 = len(df_50.index)
print('Le nombre de tempêtes entre 50 et 59 : ', st3)
st4 = len(df_60.index)
print('Le nombre de tempêtes entre 60 et 79 : ', st4)
Le nombre de tempêtes entre 30 et 39 : 51
Le nombre de tempêtes entre 40 et 49 : 113
Le nombre de tempêtes entre 50 et 59 : 142
Le nombre de tempêtes entre 60 et 79 : 56
Il existe probablement une manière élégante de combiner ces quatre commandes en une seule. Mais ma philosophie est que la syntaxe qui me prendrait une heure à comprendre ne surpassera jamais la simplicité de cinq secondes de copier-coller. Jamais.
Nous pourrions également regarder un peu plus en profondeur dans les données en utilisant notre vieil ami, value_counts(). Cela nous montrera qu'il y a eu 71 événements de 40 nœuds et 42 événements de 45 nœuds tout au long de notre période.
df_40['MaxWinds'].value_counts()
40.0 71
45.0 42
Name: MaxWinds, dtype: int64
Nous pouvons tracer un seul graphique en ligne pour afficher nos quatre sous-ensembles ensemble. Ce graphique ajoute des étiquettes d'axe et de graphique ainsi qu'une légende pour faciliter la compréhension des données. La valeur subplot(111) contrôle la taille de la figure.
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.subplot(111)
df_30['MaxWinds'].plot(ax=ax, label='df_30')
df_40['MaxWinds'].plot(ax=ax, label='df_40')
df_50['MaxWinds'].plot(ax=ax, label='df_50')
df_60['MaxWinds'].plot(ax=ax, label='df_60')
ax.set_ylabel('Vitesse du vent en nœuds')
ax.set_xlabel('Temps entre 1851 et 2019')
plt.title('Tempêtes tropicales par vitesses de vent maximales (nœuds)')
ax.legend()
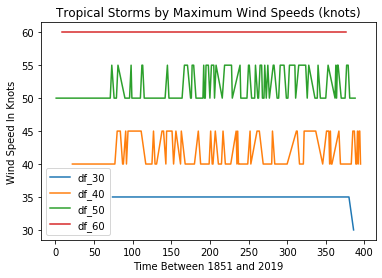 Toutes les tempêtes tropicales
Toutes les tempêtes tropicales
Cela peut être utile pour confirmer que nous ne faisons pas un gâchis des données elles-mêmes. Vérifier visuellement montrera, par exemple, qu'il y a eu, en effet, un seul événement de 30 nœuds dans notre ensemble de données et qu'il a eu lieu vers la fin de notre période en 2016. Mais ce n'est pas une excellente manière de nous montrer les changements dans la fréquence des événements.
Pour cela, nous examinerons les données contenues dans chacun de nos dataframes.
df_30['Date'].hist(bins=20)
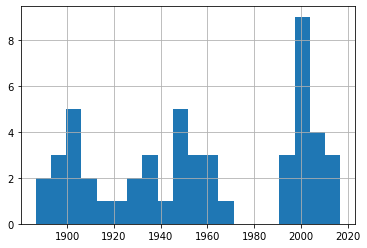 Événements de 30-39 nœuds
Événements de 30-39 nœuds
df_40['Date'].hist(bins=20)
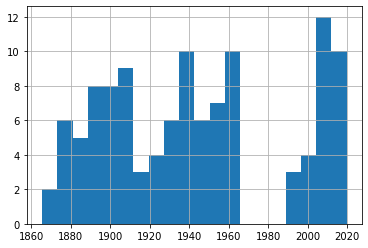 Événements de 40-49 nœuds
Événements de 40-49 nœuds
df_50['Date'].hist(bins=20)
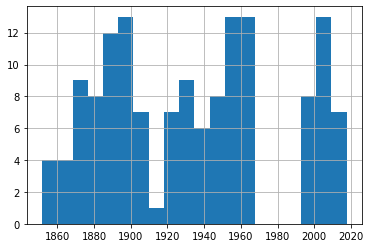 Événements de 50-59 nœuds
Événements de 50-59 nœuds
df_60['Date'].hist(bins=20)
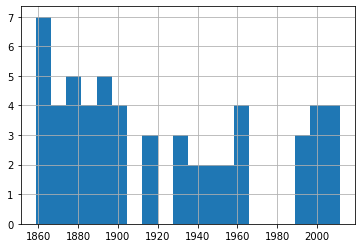 Événements de 60-79 nœuds
Événements de 60-79 nœuds
Un rapide coup d'œil à ces quatre graphiques nous montre une fréquence d'événements assez constante sur les 150 ans ou plus de nos données. Encore une fois, essayez-le vous-même en utilisant différents nombres de bins pour vous assurer que nous ne manquons pas certaines tendances importantes.
Vous pouvez trouver beaucoup plus de contenu technologique par David Clinton à travers son site web. En particulier, vous pourriez apprécier son nouveau livre, Keeping Up: Backgrounders to all the big technology trends you can’t afford to ignore_.