

Article original : How to use Spark clusters for parallel processing Big Data
Par Hari Santanam
Utiliser le Resilient Distributed Dataset (RDD) d'Apache Spark avec Databricks

En raison des limitations physiques, le processeur individuel d'ordinateur a largement atteint le plafond supérieur de vitesse avec les conceptions actuelles. Ainsi, les fabricants de matériel ont ajouté plus de processeurs à la carte mère (noyaux CPU parallèles, fonctionnant à la même vitesse).
Mais… la plupart des applications logicielles écrites au cours des dernières décennies n'ont pas été écrites pour le traitement parallèle.
De plus, la collecte de données est devenue exponentiellement plus importante, grâce à des dispositifs bon marché capables de collecter des données spécifiques (telles que la température, le son, la vitesse…).
Pour traiter ces données de manière plus efficace, de nouvelles méthodes de programmation étaient nécessaires.
Un cluster de processus informatiques est similaire à un groupe de travailleurs. Une équipe peut travailler mieux et plus efficacement qu'un seul travailleur. Ils mutualisent les ressources. Cela signifie qu'ils partagent des informations, décomposent les tâches et collectent des mises à jour et des résultats pour obtenir un ensemble unique de résultats.
Tout comme les agriculteurs sont passés du travail sur un seul champ à l'utilisation de moissonneuses-batteuses et de tracteurs pour produire efficacement de la nourriture à partir de plus grandes et nombreuses fermes, et que les coopératives agricoles ont facilité le traitement, le cluster travaille ensemble pour traiter des collections de données plus grandes et plus complexes.
Le calcul en cluster et le traitement parallèle étaient les réponses, et aujourd'hui nous avons le framework Apache Spark. Databricks est une plateforme d'analyse unifiée utilisée pour lancer le calcul en cluster Spark de manière simple et facile.
Qu'est-ce que Spark ?
Apache Spark est un moteur d'analyse unifié ultra-rapide pour le Big Data et le machine learning. Il a été initialement développé à l'UC Berkeley.
Spark est rapide. Il tire parti du calcul en mémoire et d'autres optimisations. Il détient actuellement le record du tri à grande échelle sur disque.
Spark utilise des Resilient Distributed Datasets (RDD) pour effectuer un traitement parallèle sur un cluster ou des processeurs d'ordinateur.
Il dispose d'API faciles à utiliser pour opérer sur de grands ensembles de données, dans divers langages de programmation. Il dispose également d'API pour transformer des données, et d'API de data frame familières pour manipuler des données semi-structurées.
En gros, Spark utilise un gestionnaire de cluster pour coordonner le travail sur un cluster d'ordinateurs. Un cluster est un groupe d'ordinateurs connectés qui coordonnent leurs actions pour traiter des données et effectuer des calculs.
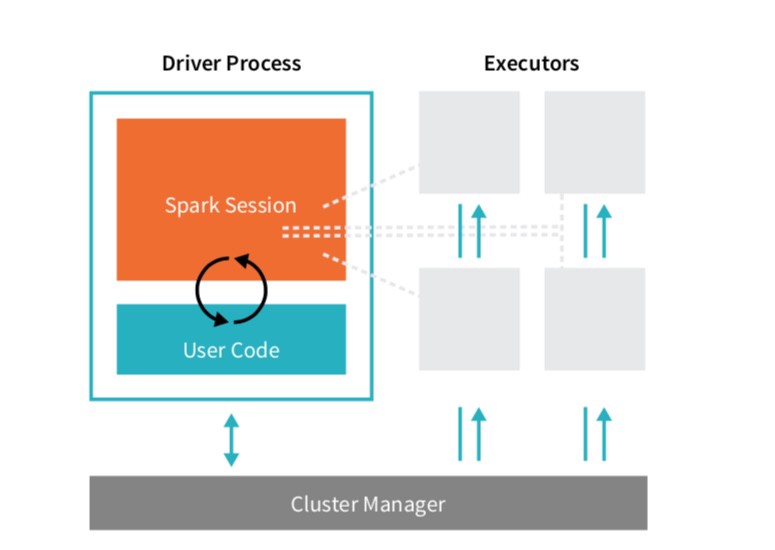
Les applications Spark se composent d'un processus pilote et de processus d'exécution.
En bref, le processus pilote exécute la fonction principale, et analyse et distribue le travail sur les exécuteurs. Les exécuteurs effectuent réellement les tâches assignées — exécutant du code et rapportant au nœud pilote.
Dans les applications réelles en entreprise et dans la programmation IA émergente, le traitement parallèle devient une nécessité pour l'efficacité, la vitesse et la complexité.
Super — alors qu'est-ce que Databricks ?
Databricks est une plateforme d'analyse unifiée, créée par les créateurs d'Apache Spark. Elle permet de lancer des clusters Spark optimisés pour le cloud en quelques minutes.
Pensez-y comme un package tout-en-un pour écrire votre code. Vous pouvez utiliser Spark (sans vous soucier des détails sous-jacents) et produire des résultats.
Elle inclut également des notebooks Jupyter qui peuvent être partagés, ainsi qu'une intégration GitHub, des connexions à de nombreux outils largement utilisés et une surveillance, une planification et un débogage automatisés. Voir ici pour plus d'informations.
Vous pouvez vous inscrire gratuitement avec l'édition communautaire. Cela vous permettra de vous familiariser avec les clusters Spark. D'autres avantages, selon le plan, incluent :
- Obtenez des clusters opérationnels en quelques secondes sur des instances AWS et Azure CPU et GPU pour une flexibilité maximale.
- Commencez rapidement avec une intégration prête à l'emploi de TensorFlow, Keras, et leurs dépendances sur les clusters Databricks.
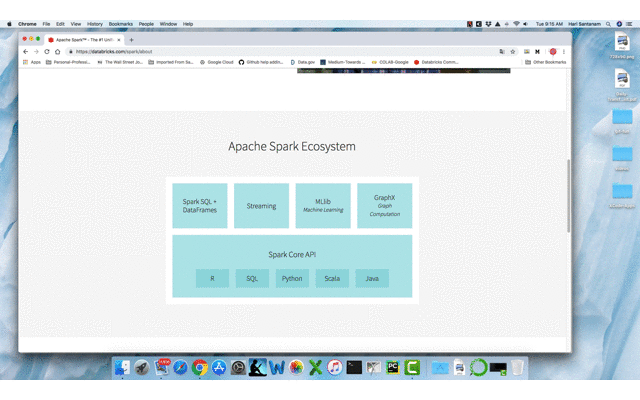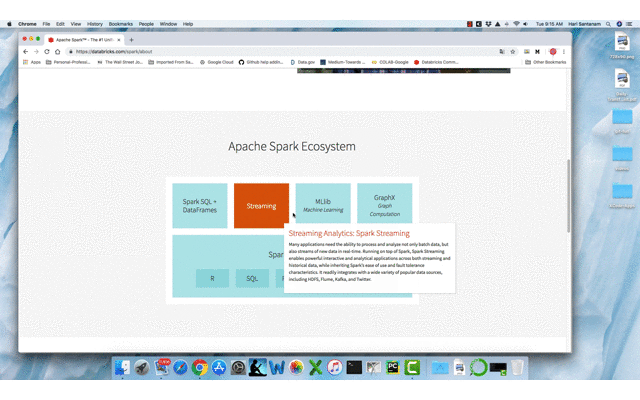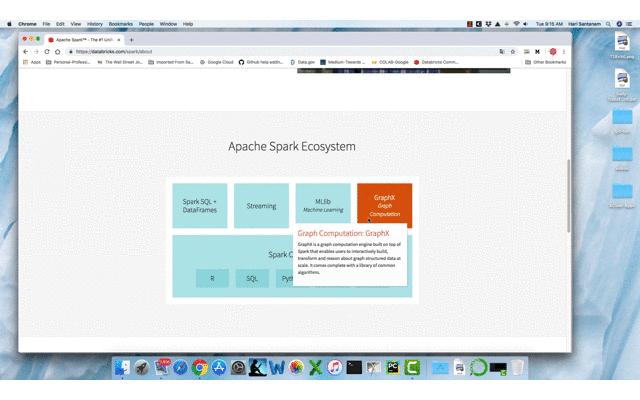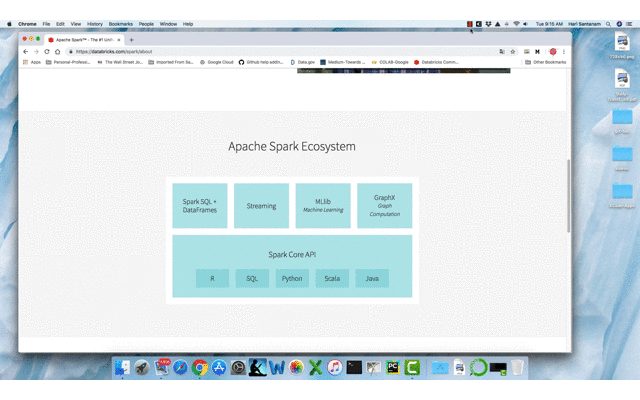
Commençons. Si vous avez déjà utilisé Databricks auparavant, passez à la partie suivante. Sinon, vous pouvez vous inscrire ici et sélectionner 'édition communautaire' pour l'essayer gratuitement.
Suivez les instructions. Elles sont claires, concises et faciles :
- Créer un cluster
- Attacher un notebook au cluster et exécuter des commandes dans le notebook sur le cluster
- Manipuler les données et créer un graphique
- Opérations sur l'API Python DataFrame ; créer un DataFrame à partir d'un ensemble de données Databricks
- Manipuler les données et afficher les résultats
Maintenant que vous avez créé un programme de données sur un cluster, passons à un autre ensemble de données, avec plus d'opérations pour que vous puissiez avoir plus de données.
L'ensemble de données est le rapport mondial sur le bonheur 2017 par pays, basé sur différents facteurs tels que le PIB, la générosité, la confiance, la famille, et autres. Les champs et leurs descriptions sont listés plus loin dans l'article.
J'ai précédemment téléchargé l'ensemble de données, puis je l'ai déplacé dans le DBFS de Databricks (DataBricks Files System) en le glissant-déposant simplement dans la fenêtre de Databricks.
Ou, vous pouvez cliquer sur Data dans le volet de navigation de gauche, cliquer sur Ajouter des données, puis soit glisser-déposer, soit parcourir et ajouter.
# Emplacement et type de fichier
# ce fichier a été glissé-déposé dans Databricks depuis l'emplacement stocké ; https://www.kaggle.com/unsdsn/world-happiness#2017.csv
file_location = "/FileStore/tables/2017.csv"
file_type = "csv"
# Options CSV
# Les options appliquées sont pour les fichiers CSV. Pour d'autres types de fichiers, celles-ci
# seront ignorées : Le schéma est inféré ; la première ligne est l'en-tête - J'ai
# supprimé la ligne d'en-tête dans l'éditeur et intentionnellement laissé 'false' pour
# contraster avec l'analyse RDD ultérieure,
# délimiteur
# séparé,
# file_location ; si vous ne supprimez pas la ligne d'en-tête, au lieu de lire
# C0, C1, il lirait "country", "dystopia" etc.
infer_schema = "true"
first_row_is_header = "false"
delimiter = ","
df = spark.read.format(file_type) \ .option("inferSchema", infer_schema) \ .option("header", first_row_is_header) \ .option("sep", delimiter) \ .load(file_location)
display(df)

Maintenant, chargeons le fichier dans le Resilient Distributed Dataset (RDD) de Spark mentionné précédemment. RDD effectue un traitement parallèle sur un cluster ou des processeurs d'ordinateur et rend les opérations de données plus rapides et plus efficaces.
# charger le fichier dans le Resilient Distributed Dataset (RDD) de Spark
data_file = "/FileStore/tables/2017.csv"
raw_rdd = sc.textFile(data_file).cache()
# montrer les 5 premières lignes du fichieraw_rdd.take(5)
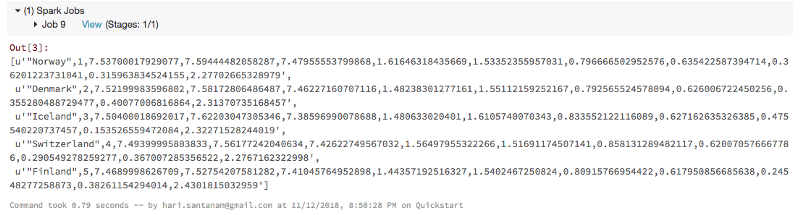
Notez les « Spark Jobs » ci-dessous, juste au-dessus de la sortie. Cliquez sur View pour voir les détails, comme montré dans la fenêtre encadrée à droite.
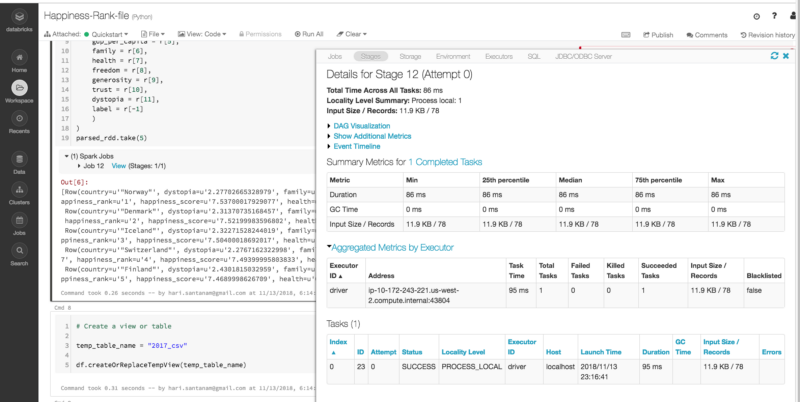
Databricks et Sparks ont d'excellentes visualisations des processus.
Dans Spark, un travail est associé à une chaîne de dépendances RDD organisée dans un graphe acyclique dirigé (DAG). Dans un DAG, les branches sont dirigées d'un nœud à un autre, sans boucle en arrière. Les tâches sont soumises à l'ordonnanceur, qui les exécute en utilisant le pipelining pour optimiser le travail et le transformer en stages minimaux.
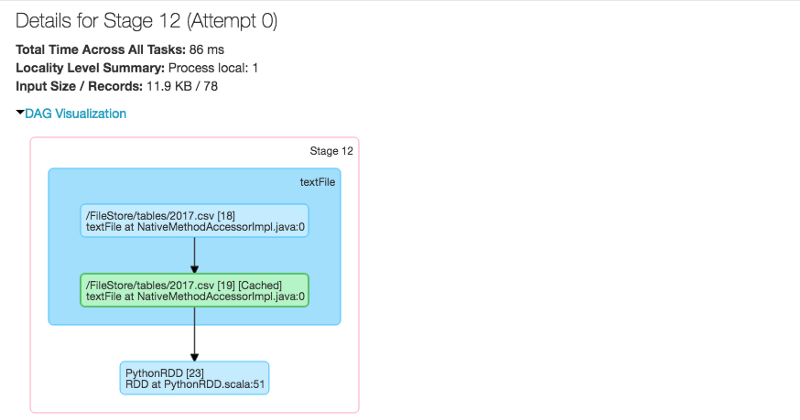
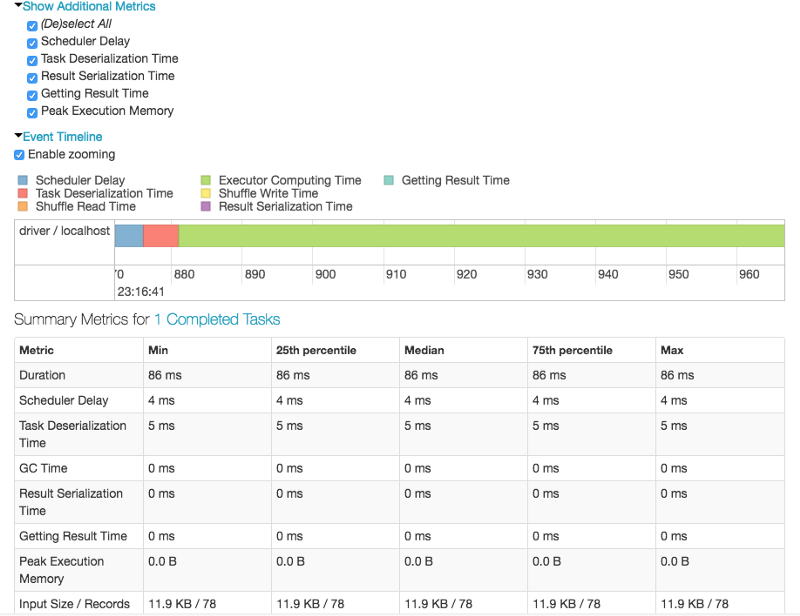
Ne vous inquiétez pas si les éléments ci-dessus semblent compliqués. Il y a des instantanés visuels des processus se produisant pendant la phase spécifique pour laquelle vous avez appuyé sur le bouton de vue Spark Job. Vous pouvez avoir besoin ou non de ces informations — elles sont là si vous en avez besoin.
Les entrées RDD sont séparées par des virgules, que nous devons diviser avant l'analyse et la construction d'un dataframe. Nous prendrons ensuite des colonnes spécifiques de l'ensemble de données à utiliser.
# diviser RDD avant l'analyse et la construction du dataframe
csv_rdd = raw_rdd.map(lambda row: row.split(","))
# imprimer 2 lignes
print(csv_rdd.take(2))
# imprimer les types
print(type(csv_rdd))
print('nombre potentiel de colonnes : ', len(csv_rdd.take(1)[0]))
# utiliser des colonnes spécifiques de l'ensemble de données
from pyspark.sql import Row
parsed_rdd = csv_rdd.map(lambda r: Row( country = r[0], # pays, position 1, type=string happiness_rank = r[1], happiness_score = r[2], gdp_per_capita = r[5], family = r[6], health = r[7], freedom = r[8], generosity = r[9], trust = r[10], dystopia = r[11], label = r[-1] ))
parsed_rdd.take(5)
Voici les colonnes et les définitions pour l'ensemble de données sur le bonheur :
Colonnes et définitions de l'ensemble de données sur le bonheur
Pays — Nom du pays.
Région — Région à laquelle appartient le pays.
Classement du bonheur — Classement du pays basé sur le score de bonheur.
Score de bonheur — Une métrique mesurée en 2015 en posant aux personnes échantillonnées la question : « Comment évalueriez-vous votre bonheur sur une échelle de 0 à 10 où 10 est le plus heureux. »
Économie (PIB par habitant) — Dans quelle mesure le PIB (Produit Intérieur Brut) contribue au calcul du score de bonheur.
Famille — Dans quelle mesure la famille contribue au calcul du score de bonheur.
Santé — (Espérance de vie) Dans quelle mesure l'espérance de vie a contribué au calcul du score de bonheur.
Liberté — Dans quelle mesure la liberté a contribué au calcul du score de bonheur.
Confiance — (Corruption gouvernementale) Dans quelle mesure la perception de la corruption contribue au score de bonheur.
Générosité — Dans quelle mesure la générosité a contribué au calcul du score de bonheur.
Résiduel de dystopie — Dans quelle mesure le résiduel de dystopie a contribué au calcul du score de bonheur (Dystopie = lieu ou état imaginé dans lequel tout est désagréable ou mauvais, typiquement un état totalitaire ou dégradé sur le plan environnemental. Résiduel — ce qui reste ou subsiste après que tout le reste a été pris en compte ou enlevé).
# Créer une vue ou une table
temp_table_name = "2017_csv"
df.createOrReplaceTempView(temp_table_name)
# construire un dataframe à partir du RDD créé précédemment
df = sqlContext.createDataFrame(parsed_rdd)
display(df.head(10)
# voir le schéma du dataframe
df.printSchema()


# construire une table temporaire pour exécuter des commandes SQL
# table vivante uniquement pour la session
# table limitée au cluster ; fortement optimisée
df.registerTempTable("happiness")
# afficher les comptes de happiness_score en utilisant la syntaxe de dataframe
display(df.groupBy('happiness_score') .count() .orderBy('count', ascending=False) )
df.registerTempTable("happiness")
# afficher les comptes de happiness_score en utilisant la syntaxe de dataframe
display(df.groupBy('happiness_score') .count() .orderBy('count', ascending=False) )

Maintenant, utilisons SQL pour exécuter une requête afin de faire la même chose. Le but est de vous montrer différentes façons de traiter les données et de comparer les méthodes.
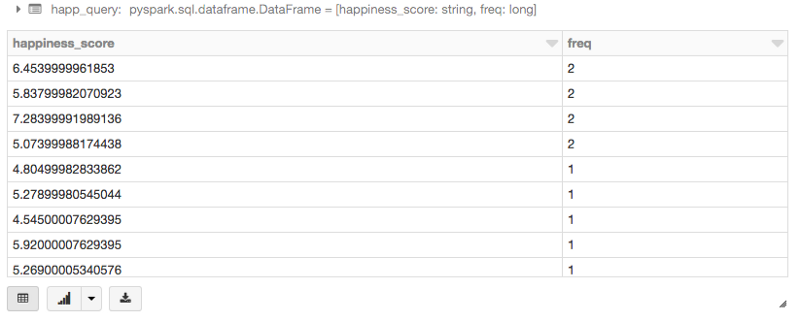
# utiliser SQL pour exécuter une requête afin de faire la même chose que précédemment avec le dataframe (compter par happiness_score)
happ_query = sqlContext.sql(""" SELECT happiness_score, count(*) as freq FROM happiness GROUP BY happiness_score ORDER BY 2 DESC """)
display(happ_query)
Une autre requête SQL pour pratiquer notre traitement de données :
# une autre requête SQL
happ_stats = sqlContext.sql(""" SELECT country, happiness_rank, dystopia FROM happiness WHERE happiness_rank > 20 """)
display(happ_stats)

Voilà ! Vous l'avez fait — créé un cluster alimenté par Spark et terminé un processus de requête de jeu de données en utilisant ce cluster. Vous pouvez utiliser cela avec vos propres jeux de données pour traiter et sortir vos projets de Big Data.
Vous pouvez également jouer avec les graphiques — cliquez sur l'icône de graphique en bas de toute sortie, spécifiez les valeurs et le type de graphique et voyez ce qui se passe. C'est amusant.
Le code est publié dans un notebook ici sur le forum public de Databricks et sera disponible pendant environ 6 mois selon Databricks.
- Pour plus d'informations sur l'utilisation de Sparks avec le Deep Learning, lisez cet excellent article par Favio Vázquez
Merci d'avoir lu ! J'espère que vous aurez des programmes intéressants avec Databricks et que vous l'apprécierez autant que moi. Veuillez applaudir si vous l'avez trouvé intéressant ou utile.
Pour une liste complète de mes articles, voir ici.