


Article original : How to Use Object Storage for Data Parallelization and Experimentation
En utilisant le big data, les entreprises peuvent en apprendre beaucoup sur la performance de leurs activités. Des analyses sur les ventes, les taux d'attrition (churn) et d'autres indicateurs de base sont disponibles presque en temps réel au fur et à mesure que les données arrivent.
Il existe ensuite des analyses plus complexes que vous devrez effectuer. Parfois, les relations entre deux ensembles de données apparemment sans rapport peuvent fournir des informations surprenantes et dévoiler des opportunités importantes pour l'organisation.
Les data scientists et les ingénieurs continuent d'améliorer la façon dont ils décomposent et travaillent sur les données. L'expérimentation implique de découvrir les bonnes corrélations entre les points de données.
Cela signifie qu'ils doivent également effectuer une sorte de parallélisation de ces données et des modèles qui en résultent. La parallélisation signifie simplement que le même ensemble de données est exploité de nombreuses manières différentes sans compromettre l'intégrité des données d'origine.
Dans cet article, nous allons voir comment vous pouvez vous assurer que vous effectuez cette expérimentation et ce traitement parallèle de manière efficace et qu'ils fournissent un maximum d'informations. Nous aborderons différents concepts liés au stockage des données et au versionnage des données.
Stockage bloc vs Stockage objet
Pour les non-initiés, nous devons d'abord comprendre la différence entre le stockage bloc et le stockage objet, et pourquoi ce dernier est la meilleure option lorsqu'on traite de l'expérimentation de données.
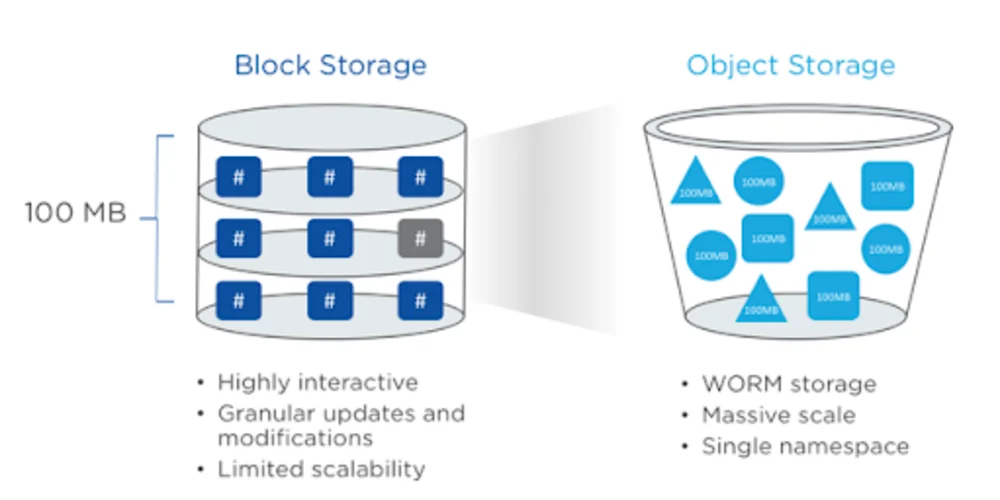 _
_Qu'est-ce que le stockage bloc ?
On l'appelle « stockage bloc » (également connu sous le nom de SAN) parce que chaque ensemble de données (sous forme de fichiers) est regroupé en blocs stockés sur des disques.
Un exemple classique de stockage bloc est le système de fichiers de votre ordinateur personnel. Pour les cas d'utilisation en entreprise, il est mis à l'échelle via un réseau de disques durs connectés par des câbles en fibre optique.
L'utilisation du stockage bloc présente quelques inconvénients. Premièrement, si un secteur (ou un bloc) est corrompu, cela peut endommager les fichiers. Un autre problème est le manque d'évolutivité (l'extension du réseau de câbles en fibre optique est coûteuse).
Qu'est-ce que le stockage objet ?
Dans le stockage objet, les données sont stockées sous forme d'objets. Chaque objet contient les données réelles, appelées le blob, un identifiant unique (UUID) et des métadonnées, qui contiennent des informations sur l'objet (telles que l'horodatage, la version et l'auteur).
Le stockage objet permet de faire évoluer votre stockage de données de manière rentable — vous n'avez pas besoin de matériel complexe pour cela. Il rend également la récupération des données plus rapide car chaque objet peut être récupéré via son UUID.
Cela contraste avec le stockage bloc, où chaque emplacement de données doit être identifié avant que l'information réelle puisse être récupérée.
Un inconvénient du stockage objet est que les données ne peuvent être écrites qu'une seule fois et ne peuvent pas être mises à jour. Mais ce n'est pas vraiment un inconvénient, comme nous le verrons plus loin dans cet article.
Quels problèmes le stockage objet résout-il ?
Comme nous l'avons déjà vu, la récupération des données peut être incroyablement rapide avec le stockage objet (quelle que soit la taille du stockage). Mais lorsqu'il s'agit d'expérimentation et de parallélisation des données, le stockage objet brille de mille feux.
Comme mentionné précédemment, vous ne pouvez pas écraser des données déjà stockées en tant qu'objet. Cela garantit que le stockage objet est protégé contre la destruction ou la mise à jour non souhaitée (ou non autorisée) des données. C'est une excellente chose à savoir si vous effectuez beaucoup de traitements de données où une corruption accidentelle des informations pourrait se produire.
Un autre problème que le stockage objet peut résoudre est qu'il ne nécessite pas que les données soient structurées. Comme les entreprises produisent et consomment d'énormes quantités d'informations à chaque instant, les données non structurées (telles que les PDF, les vidéos, les images) ne sont souvent pas facilement transformées en formes utiles (comme pour l'analytique ou les tableaux de bord).
Avec le stockage objet, cela est désormais possible. Vous pouvez maintenant utiliser des données non structurées pour développer des modèles de machine learning.
Avec le stockage de données, il est possible d'avoir différentes versions du même blob (avec des métadonnées différentes). Tout comme il existe Git pour le contrôle de version du code, nous pouvons avoir des moyens similaires de gérer différentes versions des mêmes données.
Cela nous amène au concept de lacs de données (data lakes).
Que sont les lacs de données ?
Les lacs de données sont des dépôts centraux de données qui ne se soucient pas du format de ces données.
Les entreprises produisent et consomment d'énormes quantités de données. Traditionnellement, ces données se trouvent dans des silos parce qu'elles appartiennent à différents départements ou se présentent sous différentes formes (par exemple, les vidéos ne sont pas stockées dans le même répertoire que les données de la base de données MySQL).
Avec les lacs de données, n'importe quel département de l'entreprise peut stocker des informations sans avoir besoin de les prétraiter. De même, n'importe quelle donnée peut être récupérée et analysée par n'importe qui de n'importe quel département.
Les lacs de données sont importants car ils rendent l'analyse des données extrêmement rapide et pratique.
Comment l'expérimentation et la parallélisation des données fonctionnent avec le stockage objet
Comme pour le développement de logiciels, le travail sur les données nécessite l'utilisation d'outils capables de nous aider dans notre flux de travail. Un outil open source puissant pour expérimenter avec les données et effectuer de la parallélisation (c'est-à-dire travailler sur les mêmes données pour créer différents ensembles de modèles de machine learning) est LakeFS.
LakeFS est une plateforme open source qui offre des fonctionnalités de type Git lors du travail sur les données. Cela signifie que vous pouvez créer des branches (vous permettant d'expérimenter avec les données) et effectuer des Commit de versions de données (et de modèles de données).
Pourquoi cette fonctionnalité de type Git est-elle importante ?
Tout d'abord, vous devez vous assurer que votre lac de données est conforme à la norme ACID. Cela signifie que vos modifications de données peuvent se produire de manière isolée (dans des branches). Ainsi, l'intégrité des données est maintenue dans la branche master (jusqu'à ce que ces modifications soient prêtes à être fusionnées).
Une autre caractéristique importante de LakeFS est l'intégration continue des données (encore une fois, tout comme dans le développement de logiciels). Les entreprises doivent incorporer de nouvelles données rapidement et sans interruption. Par conséquent, cette capacité à avoir un flux de travail CI/CD est inestimable.
Voyons donc comment nous pouvons commencer à utiliser LakeFS pour notre expérimentation et notre parallélisation de stockage objet.
Comment installer LakeFS
Localement, vous pouvez installer LakeFS en exécutant la commande suivante dans votre terminal :*
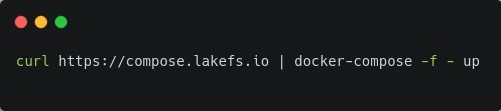
_*Ceci suppose que Docker et Docker-Compose sont installés sur votre système. Si vous n'avez pas Docker et Docker-Compose, vous pouvez essayer d'autres méthodes d'installation ici._
Visitez maintenant http://127.0.0.1:8000/setup dans votre navigateur pour vérifier que vous l'avez installé correctement.
Comment créer un dépôt dans LakeFS
Une fois que vous avez vérifié que LakeFS est correctement installé, créez un utilisateur administrateur.
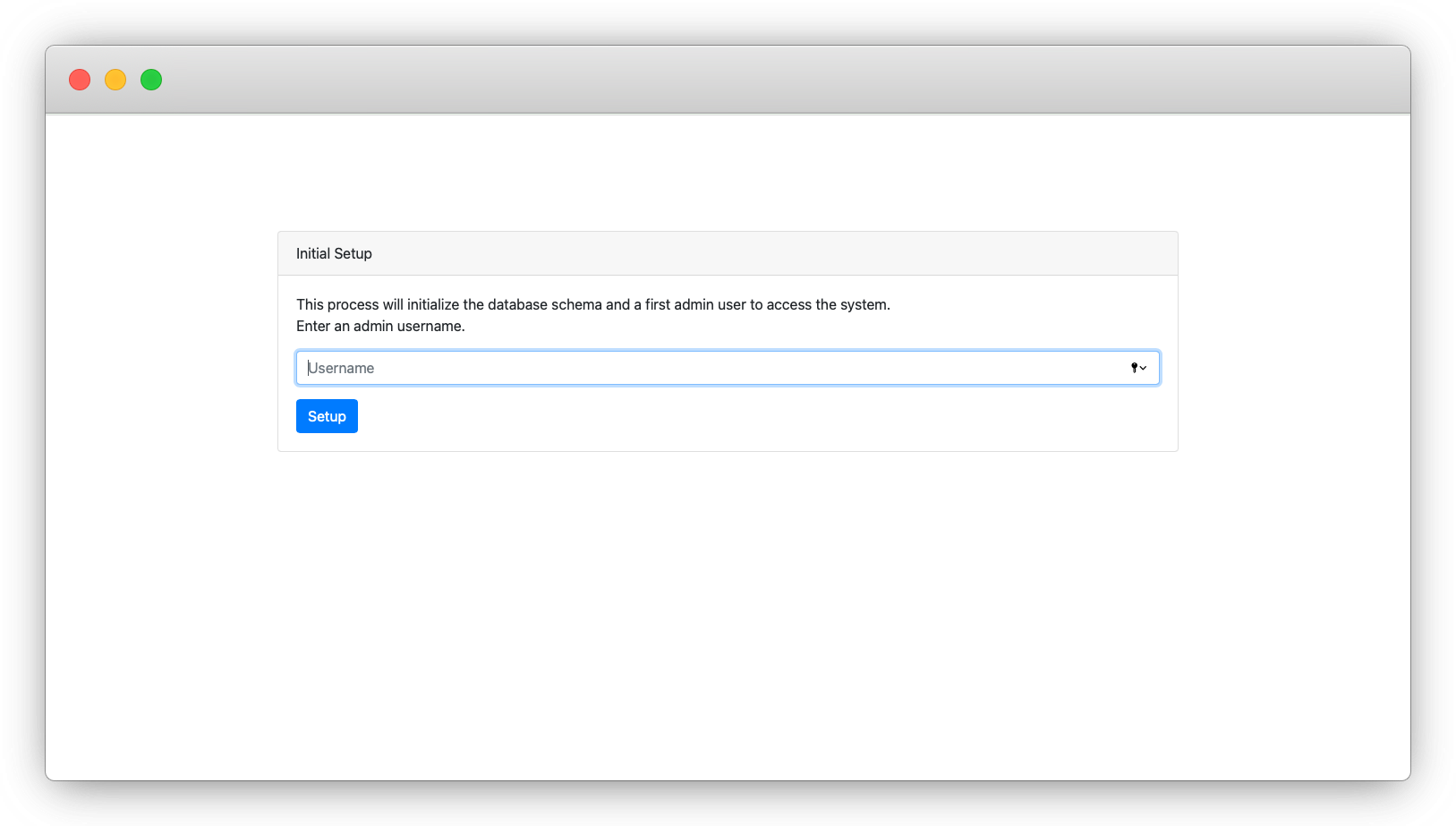
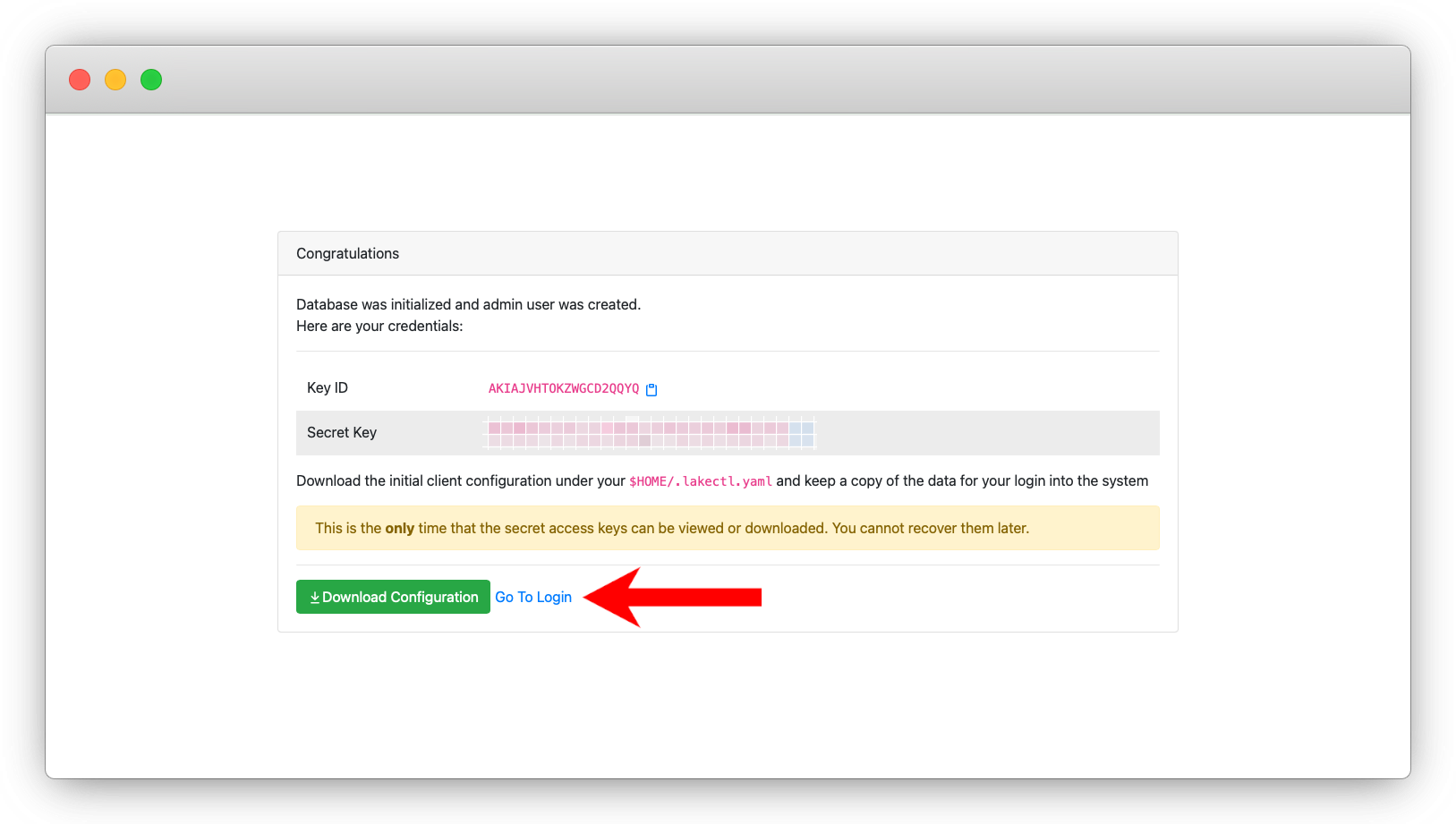 _
_Cliquez sur le lien de connexion et connectez-vous en tant qu'administrateur.
Sur la page vers laquelle vous êtes redirigé, cliquez sur Create Repository (Créer un dépôt). Une fenêtre contextuelle apparaîtra :
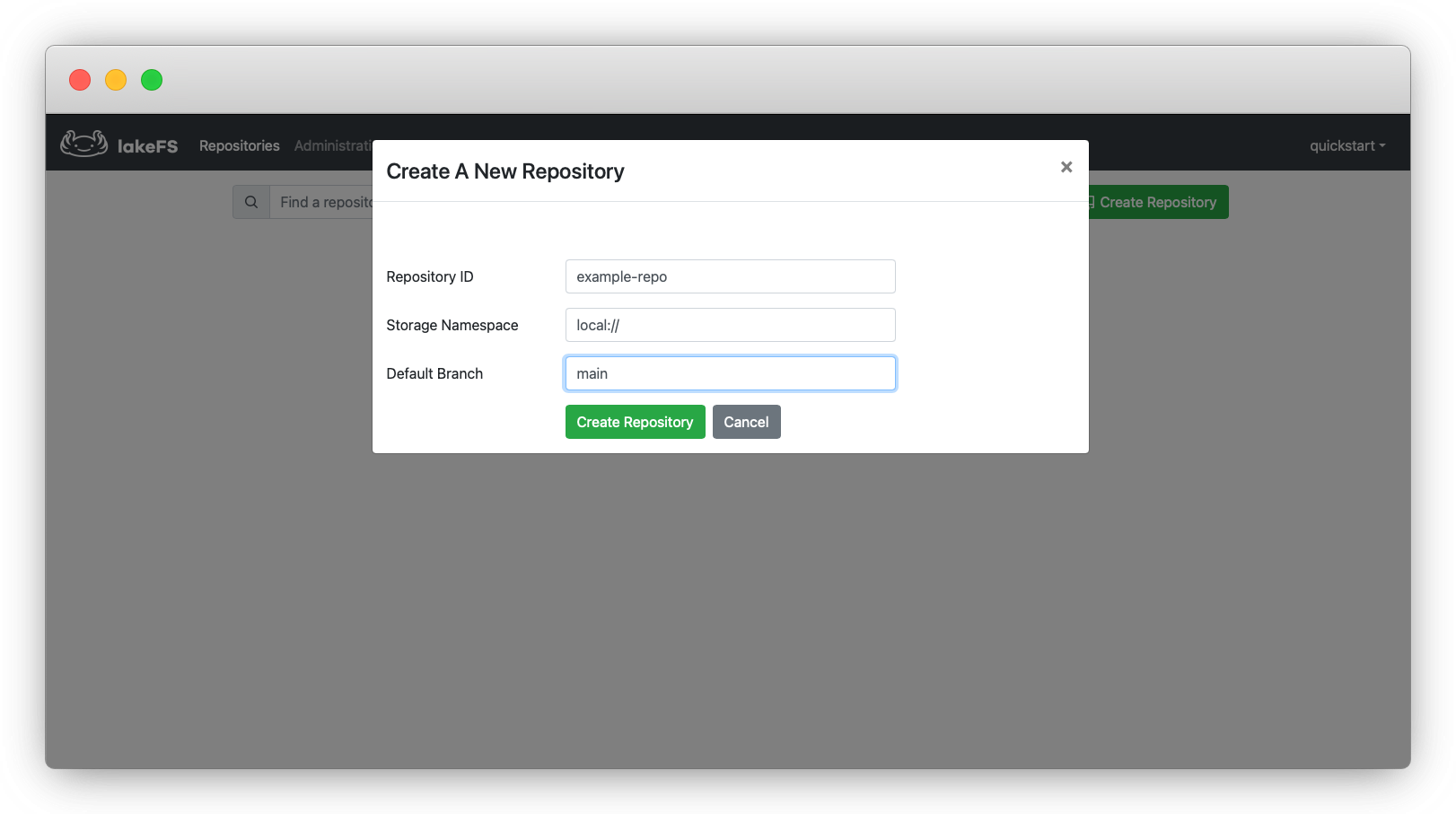 _
_Félicitations ! Vous avez maintenant votre premier dépôt. C'est le « bucket » principal dans lequel vous allez stocker vos données.
Ensuite, nous allons commencer à ajouter des données.
Comment ajouter des données à votre dépôt LakeFS
Visitez ici pour installer l'AWS CLI.
Avec les identifiants créés lors de la phase de création de l'utilisateur administrateur, configurez un nouveau profil de connexion :
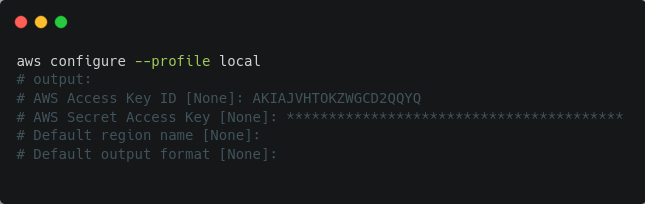
Pour tester si la connexion fonctionne, exécutez ce qui suit :
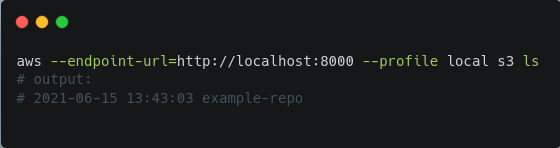
Maintenant, pour copier des fichiers dans la branche main :

Notez simplement que nous devons préfixer le chemin avec le nom de la branche que nous voulons utiliser.
Maintenant, nous verrons le fichier que nous avons ajouté dans l'interface utilisateur :
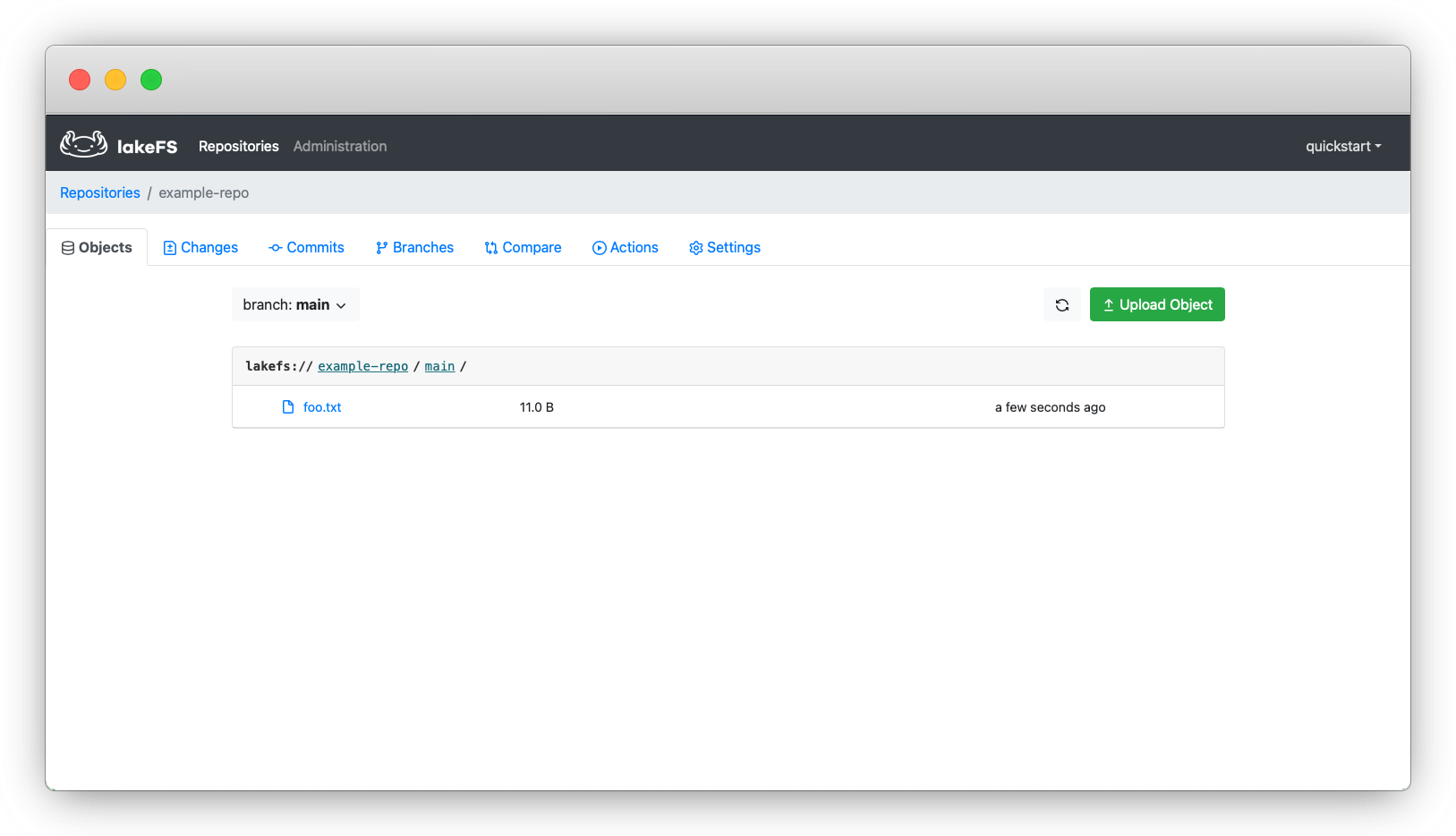 _
_Ensuite, nous devrons savoir comment effectuer un Commit et créer des branches. Pour ce faire, nous devrons installer le CLI LakeFS.
Comment installer le CLI LakeFS
Vous devez d'abord télécharger le fichier binaire ici.
Encore une fois, nous devons utiliser les identifiants administrateur créés précédemment :
Voici quelques-unes des commandes que nous pouvons exécuter pour essayer :

Vous pouvez trouver toutes les autres commandes, telles que la création de branches, etc., en ligne.
Et voilà ! Vous pouvez maintenant travailler avec vos données comme bon vous semble. Expérimentez sans culpabilité et créez plusieurs versions de vos modèles de données.
En conclusion
Dans cet article, nous avons couvert pas mal de terrain. Nous avons appris les différents types de mécanismes de stockage de données et pourquoi le stockage objet présente de nombreux avantages pour l'expérimentation et le parallélisme des données.
Ensuite, nous avons exploré les lacs de données et LakeFS, qui est un outil puissant pour travailler avec les données.
Au premier abord, cela peut sembler une tâche ardue. Mais, comme nous l'avons montré ici, avec le bon ensemble d'outils et de connaissances, vous pouvez accomplir énormément de choses.