


Article original : How to Use Object Relational Mapping in Node.js – Optimize Database Interactions With Sequelize ORM
Les bases de données jouent un rôle vital dans le développement d'applications sur les plateformes mobiles et web. Une connaissance adéquate des interactions de données entre la structure de l'application et la base de données est essentielle pour stocker les données pertinentes de l'application.
Le mappage objet-relationnel, en tant que concept de programmation, est un protocole standard efficace pour faciliter une connexion transparente avec les bases de données. Mais que signifie-t-il vraiment, et comment le configurer en tant que développeur ? Nous répondrons à ces questions et mettrons en lumière d'autres aspects du mappage objet-relationnel.
Voici les prérequis :
Connaissance de Node.js
Utilisation du framework Express
Une base de données MySQL installée
Table des matières
Qu'est-ce qu'un ORM ?
Le mappage objet-relationnel (ORM) est un concept de communication avec les bases de données en programmation qui implique l'abstraction des types de données en variables de programmation orientée objet compatibles. Il élimine simplement l'utilisation des requêtes et des types de stockage définis par la base de données pour permettre une facilité de création de bases de données via les langages de programmation.
Son utilisation a été largement adoptée dans l'espace technologique car elle présente plus d'avantages que les méthodes conventionnelles de requêtes de base de données. En voici quelques-uns :
Il réduit le risque de manipulation de données : les injections SQL et non-SQL impliquent l'insertion de syntaxes et de requêtes SQL malveillantes dans la base de données, ce qui peut compromettre la sécurité de la base de données. Avoir un ORM en place ajoute une fonctionnalité de schéma de validation d'entrée et détaille la syntaxe de la variable d'entrée attendue et la traite en conséquence.
Facilité de communication avec la base de données : l'ORM sert à simplifier l'utilisation des bases de données en tant qu'outil de données sans subir le processus d'apprentissage d'un langage de requête de base de données différent. Le schéma ORM peut être mis en évidence de manière orientée objet dans le langage de l'application et peut être configuré pour traduire automatiquement le code en requêtes compatibles avec la base de données.
Cette fonctionnalité permet également une portabilité facile du code, maintenant une seule base de code d'intégration de base de données tout en changeant la base de données sans aucun résultat adverse. Il est hautement flexible et peut être utilisé dans n'importe quelle base de données de choix.
Il dispose également de fonctionnalités supplémentaires pour permettre les interactions avec la base de données. Des fonctionnalités de migration de base de données et des processus de contrôle de version sont fournis. Avec ceux-ci, nous avons vu certains de ses avantages, nous mettrons ensuite en lumière les outils ORM populaires utilisés mondialement.
Voici les outils ORM populaires :
Pour cet article, nous allons simplifier nos cas d'utilisation d'ORM à un projet Node.js de base lié à une base de données MySQL. Nous utiliserons l'ORM Sequelize comme outil de choix.
Avec une moyenne de téléchargements de packages de 8,5 millions par mois et une communauté de développement active, Sequelize propose des fonctionnalités robustes qui intègrent de manière transparente les bases de données avec les applications backend. Il fournit également une documentation orientée utilisateur qui aide à guider l'utilisateur sur la configuration et l'utilisation de l'outil.
Voici un lien vers la documentation. Il offre également un support pour MySQL, DB2, et SQLite Microsoft SQL server, et propose des fonctionnalités telles que la réplication de lecture, le chargement paresseux, et des propriétés de transaction de base de données efficaces.
Ensuite, nous allons configurer notre application web et installer Sequelize pour nous connecter à une base de données MySQL hébergée localement.
Comment configurer votre serveur Node.js
Dans cette section, vous allez configurer notre serveur Node. Naviguez vers la ligne de commande et exécutez npm init. Cette commande crée une nouvelle structure de projet Node pour vous.
Ensuite, installez le package Express - cela servira de framework backend. Vous pouvez le faire en exécutant la commande npm i express.
Comment intégrer les packages pertinents
Pour les besoins de ce tutoriel, nous allons installer le gestionnaire de packages Node Sequelize dans notre application Node afin de configurer la communication ORM avec la base de données.
Pour configurer cela, exécutez npm i sequelize.
Nous allons utiliser une base de données MySQL hébergée localement. Pour ce faire, nous allons installer un pilote de base de données npm. Dans ce cas, nous allons installer mysql2. Voici un lien vers le package
Exécutez npm i mysql2 pour l'installer.
Passons à la configuration de la connexion à la base de données et à la construction de notre projet de démonstration.
Projet de démonstration
Dans cette section, nous allons construire un simple serveur backend qui effectue des opérations Create-Read-Update-Delete, avec la bibliothèque Sequelize servant de pipeline de connexion.
Pour commencer le projet, nous devons configurer la connexion à la base de données pour notre application. Nous allons créer un fichier de connexion à la base de données et configurer nos identifiants de base de données. Vous pouvez nommer le fichier SequelizeConfig.
module.exports = {
HOST: "localhost",
USER: "root",
PASSWORD: "",
DB: "sequel",
dialect: "mysql"
}
Dans le code ci-dessus, les identifiants de la base de données ont été spécifiés, ainsi que l'adresse de l'hôte. Dans notre cas, la base de données est hébergée localement, donc localhost est l'hôte par défaut.
Les détails de connexion à la base de données ont également été fournis. L'utilisateur ici est root, tandis que le mot de passe a été défini comme une chaîne vide. Cela doit être ajusté pour assurer la sécurité de la base de données. J'ai également créé une base de données défectueuse nommée "sequel".
Le dialecte fait référence au type de base de données que l'utilisateur prévoit d'utiliser. Dans notre cas, le dialecte est MySQL. Notez que cela peut également être répliqué sur une base de données hébergée dans le cloud avec les identifiants obtenus. Avec cela, intégrons le fichier de connexion avec l'application.
const SequelConfig = require('../config/sequelize');
const Sequelize = require('sequelize');
const sequelize = new Sequelize(SequelCOnfig.DB, SequelCOnfig.USER, SequelCOnfig.PASSWORD, {
host: SequelCOnfig.HOST,
dialect: SequelCOnfig.dialect
});
Pour faciliter une connexion à la base de données, les variables dans le fichier de configuration ont été importées et initialisées dans le fichier de configuration Sequelize.
const db = {};
db.Sequelize = Sequelize;
db.sequelize = sequelize;
db.user = require('../model/user.model')(sequelize, Sequelize);
db.token = require('../model/token.model')(sequelize, Sequelize)
module.exports= db;
Ce fichier ci-dessus importe le fichier config créé précédemment et initialise la bibliothèque Sequelize. Le code récupère ensuite les détails de la base de données saisis dans le fichier de configuration et, lorsqu'il est exécuté, crée la base de données.
De plus, les différents modèles de base de données qui seront discutés par la suite sont ensuite intégrés avec la base de données défectueuse et génèrent une table de base de données SQL.
Pour mettre cela en route, le fichier de base de données créé est invoqué en utilisant la méthode sequelize.sync(). Toute erreur rencontrée est enregistrée et la connexion à la base de données est terminée.
db.sequelize.sync().then(() => {
console.log('user created ');
}).catch(err => {
console.error(err)
})
Nous allons maintenant discuter des modèles de base de données.
Modèles
const Sequelize = require("sequelize");
module.exports = (sequelize) => {
sequelize.define(
"user", {
firstName: {
type : Sequelize.DataTypes.STRING,
allowNull : false
},
lastName: {
type : Sequelize.DataTypes.STRING,
allowNull : false
},
email : {
type : Sequelize.DataTypes.STRING,
allowNull : false, unique: true
},
password: {
type : Sequelize.DataTypes.STRING,
allowNull : false
},
role: {
type : Sequelize.DataTypes.STRING,
allowNull : false
}
}
)
}
Dans le code ci-dessus, le modèle utilisateur a été initialisé dans Sequelize ORM et les détails des champs ont été spécifiés : email, role, lastName, et password. Le type de données à recevoir a également été spécifié.
Il offre également une option pour garantir l'unicité des détails de l'utilisateur, et l'option d'empêcher l'utilisateur de laisser certains champs vides via l'utilisation de allowNull = false.
Lors de l'exécution de l'application, l'ORM Sequelize crée un équivalent SQL du modèle sous forme de table de données.
Ensuite, nous allons travailler sur les fonctions CRUD en Node.js.
Opération de création
const createUser = async (userInfo) => {
try {
// Vérifier si l'email existe déjà dans la base de données
const ifEmailExists = await User.findOne({ where: { email: userInfo.email } });
if (ifEmailExists) {
throw new ApiError('Email has already been registered');
}
// Créer le nouvel utilisateur
const newUser = await User.create(userInfo);
return newUser; // Retourner l'objet utilisateur créé
} catch (error) {
// Gérer les erreurs telles que la validation ou la contrainte d'unicité
throw error;
}
};
La fonction ci-dessus met en évidence la fonction de contrôleur pour créer des entrées utilisateur dans le serveur Express.
La fonction est asynchrone, ce qui permet l'exécution de certaines commandes avant l'exécution finale. Le code garantit que l'email de l'utilisateur n'existe pas dans la base de données avant de créer un nouvel utilisateur.
De plus, nous avons également veillé à ce que chaque champ d'email soit unique. Si les détails de l'utilisateur sont entrés avec succès dans la base de données, une réponse "succès" est renvoyée au serveur. De plus, toute erreur rencontrée entraîne l'arrêt de la fonction et l'erreur est renvoyée au serveur.
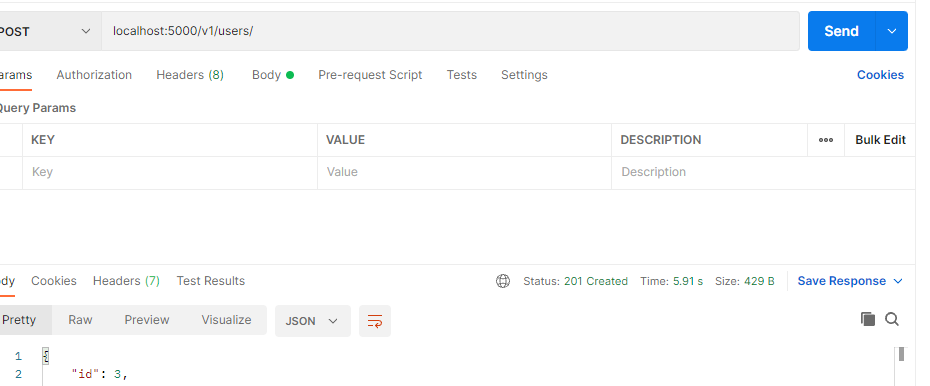
Opération de lecture
const FetchUser = async (userId) => {
let userDets;
if (userId) {
// Récupérer un seul utilisateur par ID si userId est fourni
userDets = await User.findOne({ where: { id: userId } });
// Vérifier si l'utilisateur existe
if (!userDets) {
throw new ApiError(httpStatus.NOT_FOUND, 'User not found');
}
} else {
// Récupérer tous les utilisateurs si aucun userId n'est fourni
userDets = await User.findAll();
// Vérifier si des utilisateurs ont été trouvés
if (userDets.length === 0) {
throw new ApiError(httpStatus.NOT_FOUND, 'No users found');
}
}
L'opération de lecture récupère la requête souhaitée et la renvoie à l'utilisateur sans modification. L'ID utilisateur, qui doit être unique, est utilisé pour rechercher un utilisateur spécifique. Dans ce scénario, nous voulons accéder à tous les utilisateurs créés dans la base de données.
Dans le cas où la requête demandée n'est pas trouvée, un code d'erreur approprié est généré.
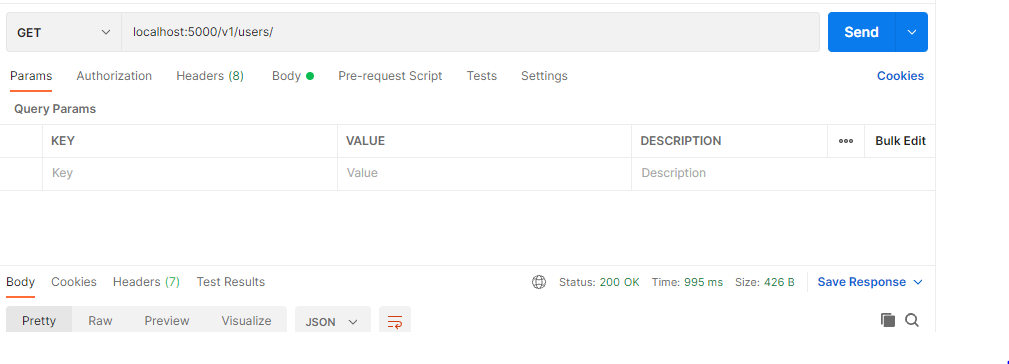
Opération de mise à jour
const updateUser = async (userId, userDetails) => {
// Tout d'abord, trouver l'utilisateur par son ID
const user = await User.findOne({ where: { id: userId } });
if (!user) {
throw new ApiError(httpStatus.BAD_REQUEST, "User doesn't exist");
}
// Mettre à jour l'utilisateur avec les nouveaux détails
await User.update(userDetails, { where: { id: userId } });
// Récupérer l'utilisateur mis à jour pour le retourner
const updatedUser = await User.findOne({ where: { id: userId } });
console.log('Updated user:', updatedUser); // Journaliser l'utilisateur mis à jour
return updatedUser; // Retourner l'objet utilisateur mis à jour
};
L'opération de mise à jour vise à modifier les données saisies dans les opérations précédentes. C'est-à-dire, pour mettre à jour certains champs de données.
Dans le cas de Sequelize, la méthode update est invoquée. Pour réussir cela, l'utilisateur particulier à éditer doit être identifié. Le code ci-dessus génère ensuite le champ de données mis à jour et l'envoie comme sortie d'une requête réussie.
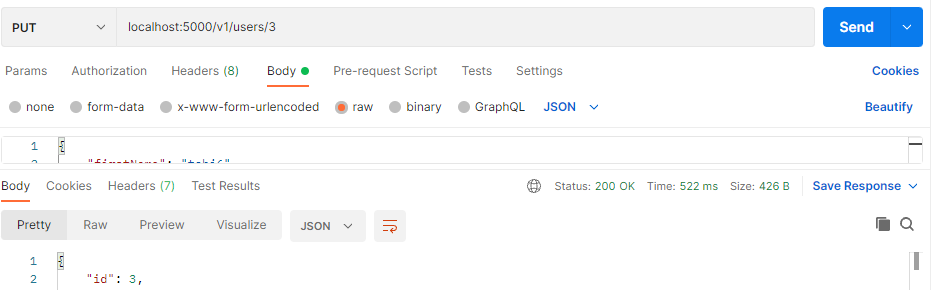
Opération de suppression
const deleteUser = async (userId) => {
const user = await User.findOne({ where: { id: userId } });
if (!user) {
throw new ApiError(httpStatus.BAD_REQUEST, "User doesn't exist");
}
// Supprimer l'utilisateur
await user.destroy();
console.log('Deleted user:', user); // Journaliser l'utilisateur supprimé
return user; // Retourner l'objet utilisateur supprimé (utile pour confirmation)
};
L'opération de suppression est invoquée lorsque des données dans la table de la base de données doivent être supprimées. Sequelize prévoit cela via l'utilisation de la méthode destroy. Cette méthode supprime un utilisateur spécifique. Lorsqu'elle est exécutée, un code de réponse de succès est affiché.
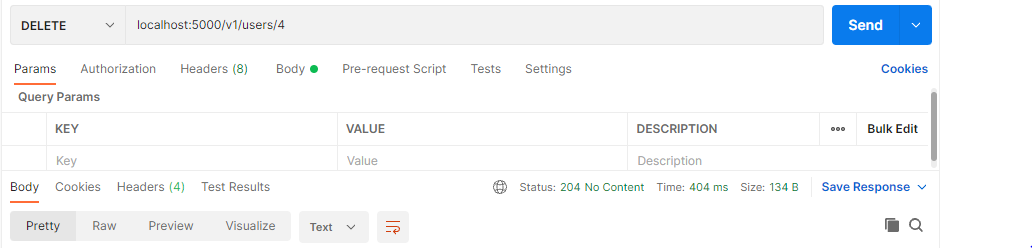
Informations supplémentaires
Jusqu'à présent, nous avons intégré une bibliothèque ORM pour servir de connexion entre notre application backend et notre base de données relationnelle. Nous avons également exploré des concepts avancés tels que les migrations de base de données et les opérations CRUD. Pour en savoir plus, vous pouvez explorer la documentation et l'utiliser pour construire des projets plus complexes, car l'apprentissage pratique est fortement encouragé.
N'hésitez pas à me contacter sur mon blog et à consulter mes autres articles ici. Jusqu'à la prochaine fois, continuez à coder !