


Article original : How to Use the Java Collections Framework – A Guide for Developers
Dans vos applications Java, vous travaillerez généralement avec divers types d'objets. Et vous pourriez vouloir effectuer des opérations comme le tri, la recherche et l'itération sur ces objets.
Avant l'introduction du framework Collections dans JDK 1.2, vous auriez utilisé des Arrays et des Vectors pour stocker et gérer un groupe d'objets. Mais ils avaient leurs propres inconvénients.
Le Java Collections Framework vise à surmonter ces problèmes en fournissant des implémentations haute performance de structures de données courantes. Cela vous permet de vous concentrer sur l'écriture de la logique de l'application au lieu de vous concentrer sur des opérations de bas niveau.
Ensuite, l'introduction des Generics dans JDK 1.5 a considérablement amélioré le Java Collections Framework. Les Generics vous permettent d'imposer la sécurité des types pour les objets stockés dans une collection, ce qui améliore la robustesse de vos applications. Vous pouvez en lire plus sur les Java Generics ici.
Dans cet article, je vais vous guider à travers l'utilisation du Java Collections Framework. Nous discuterons des différents types de collections, tels que les Listes, les Ensembles, les Files d'attente et les Maps. Je fournirai également une brève explication de leurs caractéristiques clés telles que :
Mécanismes internes
Gestion des doublons
Prise en charge des valeurs nulles
Ordre
Synchronisation
Performance
Méthodes clés
Implémentations courantes
Nous passerons également en revue quelques exemples de code pour une meilleure compréhension, et j'aborderai la classe utilitaire Collections et son utilisation.
Table des matières :
Comprendre le Java Collections Framework
Selon la documentation Java, « Une collection est un objet qui représente un groupe d'objets. Un framework de collections est une architecture unifiée pour représenter et manipuler des collections. »
En termes simples, le Java Collections Framework vous aide à gérer un groupe d'objets et à effectuer des opérations sur eux de manière efficace et organisée. Il facilite le développement d'applications en offrant diverses méthodes pour gérer des groupes d'objets. Vous pouvez ajouter, supprimer, rechercher et trier des objets efficacement en utilisant le Java Collections Framework.
Interfaces de Collection
En Java, une interface spécifie un contrat qui doit être rempli par toute classe qui l'implémente. Cela signifie que la classe implémentante doit fournir des implémentations concrètes pour toutes les méthodes déclarées dans l'interface.
Dans le Java Collections Framework, diverses interfaces de collection comme Set, List et Queue étendent l'interface Collection, et elles doivent adhérer au contrat défini par l'interface Collection.
Décodage de la hiérarchie du Java Collections Framework
Consultez ce diagramme pratique de cet article qui illustre la hiérarchie des collections Java :
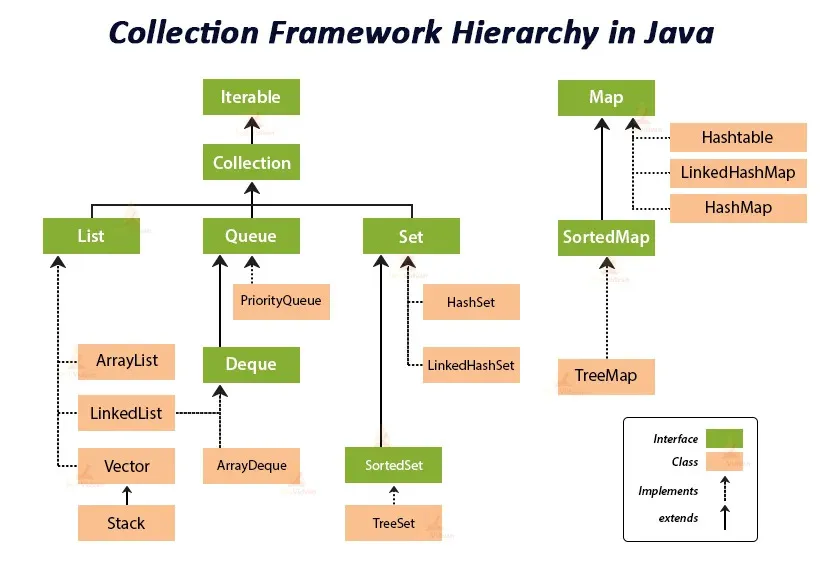
Nous commencerons par le haut et travaillerons vers le bas pour que vous puissiez comprendre ce que ce diagramme montre :
À la racine du Java Collections Framework se trouve l'interface
Iterable, qui vous permet d'itérer sur les éléments d'une collection.L'interface
Collectionétend l'interfaceIterable. Cela signifie qu'elle hérite des propriétés et du comportement de l'interfaceIterableet ajoute son propre comportement pour ajouter, supprimer et récupérer des éléments.Des interfaces spécifiques telles que
List,SetetQueueétendent davantage l'interfaceCollection. Chacune de ces interfaces a d'autres classes implémentant leurs méthodes. Par exemple,ArrayListest une implémentation populaire de l'interfaceList,HashSetimplémente l'interfaceSet, et ainsi de suite.L'interface
Mapfait partie du Java Collections Framework, mais elle n'étend pas l'interfaceCollection, contrairement aux autres mentionnées ci-dessus.Toutes les interfaces et classes de ce framework font partie du package
java.util.
Note : Une source courante de confusion dans le Java Collections Framework tourne autour de la différence entre Collection et Collections. Collection est une interface dans le framework, tandis que Collections est une classe utilitaire. La classe Collections fournit des méthodes statiques qui effectuent des opérations sur les éléments d'une collection.
Interfaces de Collection Java
À ce stade, vous êtes familiarisé avec les différents types de collections qui forment la base du framework de collections. Maintenant, nous allons examiner de plus près les interfaces List, Set, Queue et Map.
Dans cette section, nous discuterons de chacune de ces interfaces tout en explorant leurs mécanismes internes. Nous examinerons comment elles gèrent les éléments en double et si elles prennent en charge l'insertion de valeurs nulles. Nous comprendrons également l'ordre des éléments lors de l'insertion et leur prise en charge de la synchronisation, qui traite du concept de sécurité des threads. Ensuite, nous passerons en revue quelques méthodes clés de ces interfaces et conclurons par un examen des implémentations courantes et de leurs performances pour diverses opérations.
Avant de commencer, parlons brièvement de la Synchronisation et de la Performance.
La Synchronisation contrôle l'accès aux objets partagés par plusieurs threads, assurant leur intégrité et prévenant les conflits. Cela est crucial pour maintenir la sécurité des threads.
Lors du choix d'un type de collection, un facteur important est sa performance lors des opérations courantes comme l'insertion, la suppression et la récupération. La performance est généralement exprimée en utilisant la notation Big-O. Vous pouvez en apprendre plus à ce sujet ici.
Listes
Une List est une collection ordonnée ou séquentielle d'éléments. Elle suit un indexage basé sur zéro, permettant aux éléments d'être insérés, supprimés ou accès en utilisant leur position d'index.
Mécanisme interne : Une
Listest soutenue en interne par un tableau ou une liste chaînée, selon le type d'implémentation. Par exemple, unArrayListutilise un tableau, tandis qu'unLinkedListutilise une liste chaînée en interne. Vous pouvez en lire plus surLinkedListici. UneListredimensionne dynamiquement sa taille lors de l'ajout ou de la suppression d'éléments. La récupération basée sur l'indexation en fait un type de collection très efficace.Doublons : Les éléments en double sont autorisés dans une
List, ce qui signifie qu'il peut y avoir plus d'un élément dans uneListavec la même valeur. Toute valeur peut être récupérée en fonction de l'index auquel elle est stockée.Null : Les valeurs nulles sont également autorisées dans une
List. Puisque les doublons sont permis, vous pouvez également avoir plusieurs éléments nuls.Ordre : Une
Listmaintient l'ordre d'insertion, ce qui signifie que les éléments sont stockés dans le même ordre qu'ils ont été ajoutés. Cela est utile lorsque vous souhaitez récupérer les éléments dans l'ordre exact où ils ont été insérés.Synchronisation : Une
Listn'est pas synchronisée par défaut, ce qui signifie qu'elle n'a pas de moyen intégré pour gérer l'accès par plusieurs threads en même temps.Méthodes clés : Voici quelques méthodes clés d'une interface
List:add(E element),get(int index),set(int index, E element),remove(int index), etsize(). Regardons comment utiliser ces méthodes avec un exemple de programme.
import java.util.ArrayList;
import java.util.List;
public class ListExample {
public static void main(String[] args) {
// Créer une liste
List<String> list = new ArrayList<>();
// add(E element)
list.add("Apple");
list.add("Banana");
list.add("Cherry");
// get(int index)
String secondElement = list.get(1); // "Banana"
// set(int index, E element)
list.set(1, "Blueberry");
// remove(int index)
list.remove(0); // Supprime "Apple"
// size()
int size = list.size(); // 2
// Afficher la liste
System.out.println(list); // Sortie : [Blueberry, Cherry]
// Afficher la taille de la liste
System.out.println(size); // Sortie : 2
}
}
Implémentations courantes :
ArrayList,LinkedList,Vector,StackPerformance : Typiquement, les opérations d'insertion et de suppression sont rapides dans
ArrayListetLinkedList. Mais la récupération des éléments peut être lente car vous devez parcourir les nœuds.
| Opération | ArrayList | LinkedList |
| Insertion | Rapide à la fin - O(1) amorti, lent au début ou au milieu - O(n) | Rapide au début ou au milieu - O(1), lent à la fin - O(n) |
| Suppression | Rapide à la fin - O(1) amorti, lent au début ou au milieu - O(n) | Rapide - O(1) si la position est connue |
| Récupération | Rapide - O(1) pour un accès aléatoire | Lent - O(n) pour un accès aléatoire, car cela implique un parcours |
Ensembles
Un Set est un type de collection qui n'autorise pas les éléments en double et représente le concept d'un ensemble mathématique.
Mécanisme interne : Un
Setest soutenu en interne par unHashMap. Selon le type d'implémentation, il est soutenu par unHashMap, unLinkedHashMapou unTreeMap. J'ai écrit un article détaillé sur le fonctionnement interne deHashMapici. Assurez-vous de le consulter.Doublons : Puisqu'un
Setreprésente le concept d'un ensemble mathématique, les éléments en double ne sont pas autorisés. Cela garantit que tous les éléments sont uniques, maintenant l'intégrité de la collection.Null : Un maximum d'une valeur nulle est autorisé dans un
Setcar les doublons ne sont pas permis. Mais cela ne s'applique pas à l'implémentationTreeSet, où les valeurs nulles ne sont pas autorisées du tout.Ordre : L'ordre des éléments dans un
Setdépend du type d'implémentation.HashSet: L'ordre n'est pas garanti, et les éléments peuvent être placés à n'importe quelle position.LinkedHashSet: Cette implémentation maintient l'ordre d'insertion, donc vous pouvez récupérer les éléments dans le même ordre qu'ils ont été insérés.TreeSet: Les éléments sont insérés en fonction de leur ordre naturel. Alternativement, vous pouvez contrôler l'ordre d'insertion en spécifiant un comparateur personnalisé.Synchronisation : Un
Setn'est pas synchronisé, ce qui signifie que vous pourriez rencontrer des problèmes de concurrence, comme des conditions de course, qui peuvent affecter l'intégrité des données si deux threads ou plus tentent d'accéder à un objetSetsimultanément.Méthodes clés : Voici quelques méthodes clés d'une interface
Set:add(E element),remove(Object o),contains(Object o), etsize(). Regardons comment utiliser ces méthodes avec un exemple de programme.
import java.util.HashSet;
import java.util.Set;
public class SetExample {
public static void main(String[] args) {
// Créer un ensemble
Set<String> set = new HashSet<>();
// Ajouter des éléments à l'ensemble
set.add("Apple");
set.add("Banana");
set.add("Cherry");
// Supprimer un élément de l'ensemble
set.remove("Banana");
// Vérifier si l'ensemble contient un élément
boolean containsApple = set.contains("Apple");
System.out.println("Contient Apple : " + containsApple);
// Obtenir la taille de l'ensemble
int size = set.size();
System.out.println("Taille de l'ensemble : " + size);
}
}
Implémentations courantes :
HashSet,LinkedHashSet,TreeSetPerformance : Les implémentations de
Setoffrent des performances rapides pour les opérations de base, sauf pour unTreeSet, où les performances peuvent être relativement plus lentes car la structure de données interne implique le tri des éléments lors de ces opérations.
| Opération | HashSet | LinkedHashSet | TreeSet |
| Insertion | Rapide - O(1) | Rapide - O(1) | Plus lent - O(log n) |
| Suppression | Rapide - O(1) | Rapide - O(1) | Plus lent - O(log n) |
| Récupération | Rapide - O(1) | Rapide - O(1) | Plus lent - O(log n) |
Files d'attente
Une Queue est une collection linéaire d'éléments utilisée pour contenir plusieurs éléments avant le traitement, généralement suivant l'ordre FIFO (premier entré, premier sorti). Cela signifie que les éléments sont ajoutés à une extrémité et retirés de l'autre, donc le premier élément ajouté à la file d'attente est le premier à être retiré.
Mécanisme interne : Le fonctionnement interne d'une
Queuepeut différer en fonction de son implémentation spécifique.LinkedList– utilise une liste doublement chaînée pour stocker les éléments, ce qui signifie que vous pouvez parcourir à la fois vers l'avant et vers l'arrière, permettant des opérations flexibles.PriorityQueue– est soutenu en interne par un tas binaire, qui est très efficace pour les opérations de récupération.ArrayDeque– est implémenté en utilisant un tableau qui s'étend ou se réduit à mesure que des éléments sont ajoutés ou retirés. Ici, les éléments peuvent être ajoutés ou retirés des deux extrémités de la file d'attente.Doublons : Dans une
Queue, les éléments en double sont autorisés, permettant plusieurs instances de la même valeur à être insérées.Null : Vous ne pouvez pas insérer une valeur nulle dans une
Queuecar, par conception, certaines méthodes d'uneQueueretournent null pour indiquer qu'elle est vide. Pour éviter la confusion, les valeurs nulles ne sont pas autorisées.Ordre : Les éléments sont insérés en fonction de leur ordre naturel. Alternativement, vous pouvez contrôler l'ordre d'insertion en spécifiant un comparateur personnalisé.
Synchronisation : Une
Queuen'est pas synchronisée par défaut. Mais, vous pouvez utiliser une implémentationConcurrentLinkedQueueouBlockingQueuepour obtenir la sécurité des threads.Méthodes clés : Voici quelques méthodes clés d'une interface
Queue:add(E element),offer(E element),poll(), etpeek(). Regardons comment utiliser ces méthodes avec un exemple de programme.
import java.util.LinkedList;
import java.util.Queue;
public class QueueExample {
public static void main(String[] args) {
// Créer une file d'attente en utilisant LinkedList
Queue<String> queue = new LinkedList<>();
// Utiliser la méthode add pour insérer des éléments, lance une exception si l'insertion échoue
queue.add("Element1");
queue.add("Element2");
queue.add("Element3");
// Utiliser la méthode offer pour insérer des éléments, retourne false si l'insertion échoue
queue.offer("Element4");
// Afficher la file d'attente
System.out.println("File d'attente : " + queue);
// Regarder le premier élément (ne le supprime pas)
String firstElement = queue.peek();
System.out.println("Peek : " + firstElement); // affiche "Element1"
// Récupérer le premier élément (le récupère et le supprime)
String polledElement = queue.poll();
System.out.println("Poll : " + polledElement); // affiche "Element1"
// Afficher la file d'attente après poll
System.out.println("File d'attente après poll : " + queue);
}
}
Implémentations courantes :
LinkedList,PriorityQueue,ArrayDequePerformance : Les implémentations comme
LinkedListetArrayDequesont généralement rapides pour ajouter et supprimer des éléments. LePriorityQueueest un peu plus lent car il insère des éléments en fonction de l'ordre de priorité défini.
| Opération | LinkedList | PriorityQueue | ArrayDeque |
| Insertion | Rapide au début ou au milieu - O(1), lent à la fin - O(n) | Plus lent - O(log n) | Rapide - O(1), Lent - O(n), si cela implique un redimensionnement du tableau interne |
| Suppression | Rapide - O(1) si la position est connue | Plus lent - O(log n) | Rapide - O(1), Lent - O(n), si cela implique un redimensionnement du tableau interne |
| Récupération | Lent - O(n) pour un accès aléatoire, car cela implique un parcours | Rapide - O(1) | Rapide - O(1) |
Maps
Une Map représente une collection de paires clé-valeur, chaque clé étant associée à une seule valeur. Bien que Map fasse partie du framework de collection Java, elle n'étend pas l'interface java.util.Collection.
Mécanisme interne : Une
Mapfonctionne en interne en utilisant uneHashTablebasée sur le concept de hachage. J'ai écrit un article détaillé sur ce sujet ici, alors lisez-le pour une compréhension plus approfondie.Doublons : Une
Mapstocke les données sous forme de paires clé-valeur. Ici, chaque clé est unique, donc les clés en double ne sont pas autorisées. Mais les valeurs en double sont permises.Null : Puisque les clés en double ne sont pas autorisées, une
Mapne peut avoir qu'une seule clé nulle. Comme les valeurs en double sont permises, elle peut avoir plusieurs valeurs nulles. Dans l'implémentationTreeMap, les clés ne peuvent pas être nulles car elle trie les éléments en fonction des clés. Cependant, les valeurs nulles sont autorisées.Ordre : L'ordre d'insertion d'une
Mapvarie selon l'implémentation :HashMap– l'ordre d'insertion n'est pas garanti car ils sont déterminés en fonction du concept de hachage.LinkedHashMap– l'ordre d'insertion est préservé et vous pouvez récupérer les éléments dans le même ordre qu'ils ont été ajoutés à la collection.TreeMap– Les éléments sont insérés en fonction de leur ordre naturel. Alternativement, vous pouvez contrôler l'ordre d'insertion en spécifiant un comparateur personnalisé.Synchronisation : Une
Mapn'est pas synchronisée par défaut. Mais vous pouvez utiliserCollections.synchronizedMap()ou les implémentationsConcurrentHashMappour obtenir la sécurité des threads.Méthodes clés : Voici quelques méthodes clés d'une interface
Map:put(K key, V value),get(Object key),remove(Object key),containsKey(Object key), etkeySet(). Regardons comment utiliser ces méthodes avec un exemple de programme.
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapMethodsExample {
public static void main(String[] args) {
// Créer une nouvelle HashMap
Map<String, Integer> map = new HashMap<>();
// put(K key, V value) - Insère des paires clé-valeur dans la map
map.put("Apple", 1);
map.put("Banana", 2);
map.put("Orange", 3);
// get(Object key) - Retourne la valeur associée à la clé
Integer value = map.get("Banana");
System.out.println("Valeur pour 'Banana' : " + value);
// remove(Object key) - Supprime la paire clé-valeur pour la clé spécifiée
map.remove("Orange");
// containsKey(Object key) - Vérifie si la map contient la clé spécifiée
boolean hasApple = map.containsKey("Apple");
System.out.println("Contient 'Apple' : " + hasApple);
// keySet() - Retourne une vue de type Set des clés contenues dans la map
Set<String> keys = map.keySet();
System.out.println("Clés dans la map : " + keys);
}
}
Implémentations courantes :
HashMap,LinkedHashMap,TreeMap,Hashtable,ConcurrentHashMapPerformance : L'implémentation
HashMapest largement utilisée principalement en raison de ses caractéristiques de performance efficaces illustrées dans le tableau ci-dessous.
| Opération | HashMap | LinkedHashMap | TreeMap |
| Insertion | Rapide - O(1) | Rapide - O(1) | Plus lent - O(log n) |
| Suppression | Rapide - O(1) | Rapide - O(1) | Plus lent - O(log n) |
| Récupération | Rapide - O(1) | Rapide - O(1) | Plus lent - O(log n) |
Classe utilitaire Collections
Comme souligné au début de cet article, la classe utilitaire Collections dispose de plusieurs méthodes statiques utiles qui vous permettent d'effectuer des opérations couramment utilisées sur les éléments d'une collection. Ces méthodes vous aident à réduire le code redondant dans votre application et vous permettent de vous concentrer sur la logique métier.
Voici quelques fonctionnalités et méthodes clés, ainsi que ce qu'elles font, brièvement énumérées :
Tri :
Collections.sort(List<T>)– cette méthode est utilisée pour trier les éléments d'une liste par ordre croissant.Recherche :
Collections.binarySearch(List<T>, key)– cette méthode est utilisée pour rechercher un élément spécifique dans une liste triée et retourner son index.Ordre inverse :
Collections.reverse(List<T>)– cette méthode est utilisée pour inverser l'ordre des éléments dans une liste.Opérations Min/Max :
Collections.min(Collection<T>)etCollections.max(Collection<T>)– ces méthodes sont utilisées pour trouver les éléments minimum et maximum dans une collection, respectivement.Synchronisation :
Collections.synchronizedList(List<T>)– cette méthode est utilisée pour rendre une liste thread-safe en la synchronisant.Collections non modifiables :
Collections.unmodifiableList(List<T>)– cette méthode est utilisée pour créer une vue en lecture seule d'une liste, empêchant les modifications.
Voici un exemple de programme Java qui démontre diverses fonctionnalités de la classe utilitaire Collections :
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(5);
numbers.add(3);
numbers.add(8);
numbers.add(1);
// Tri
Collections.sort(numbers);
System.out.println("Liste triée : " + numbers);
// Recherche
int index = Collections.binarySearch(numbers, 3);
System.out.println("Index de 3 : " + index);
// Ordre inverse
Collections.reverse(numbers);
System.out.println("Liste inversée : " + numbers);
// Opérations Min/Max
int min = Collections.min(numbers);
int max = Collections.max(numbers);
System.out.println("Min : " + min + ", Max : " + max);
// Synchronisation
List<Integer> synchronizedList = Collections.synchronizedList(numbers);
System.out.println("Liste synchronisée : " + synchronizedList);
// Collections non modifiables
List<Integer> unmodifiableList = Collections.unmodifiableList(numbers);
System.out.println("Liste non modifiable : " + unmodifiableList);
}
}
Ce programme démontre le tri, la recherche, l'inversion, la recherche des valeurs minimale et maximale, la synchronisation et la création d'une liste non modifiable en utilisant la classe utilitaire Collections.
Conclusion
Dans cet article, vous avez appris le Java Collections Framework et comment il aide à gérer des groupes d'objets dans les applications Java. Nous avons exploré divers types de collections comme les Listes, les Ensembles, les Files d'attente et les Maps, et nous avons acquis des connaissances sur certaines des caractéristiques clés et comment chacun de ces types les prend en charge.
Vous avez appris la performance, la synchronisation et les méthodes clés, obtenant des informations précieuses pour choisir les bonnes structures de données pour vos besoins.
En comprenant ces concepts, vous pouvez pleinement utiliser le Java Collections Framework, ce qui vous permet d'écrire un code plus efficace et de construire des applications robustes.
Si vous avez trouvé cet article intéressant, n'hésitez pas à consulter mes autres articles sur freeCodeCamp et à me connecter sur LinkedIn.