
Article original : How to work in Data Science, AI, or Big Data based on my experience
Par Richard Freeman, PhD
En été 2013, j'ai passé un entretien pour un rôle de leader dans l'équipe de data science et d'analyse chez JustGiving, une entreprise de technologie pour le bien. Lors de l'entretien, j'ai dit que je prévoyais de livrer des systèmes de machine learning par lots, d'analyse de graphes et d'analyse de streaming, à la fois en interne et dans le cloud.
Quelques années plus tard, mon ancien patron Mike Bugembe et moi présentions lors de conférences internationales, remportions des prix et devenions auteurs !
Voici mon histoire, et ce que j'ai appris lors de ce parcours — plus mes recommandations pour vous.
Pourquoi l'ingénierie des Big Data et la Data Science ?
Je me suis toujours intéressé à l'intelligence artificielle (IA), au machine learning (ML) et au traitement du langage naturel (NLP). En particulier, je me suis intéressé aux systèmes scalables, et à rendre les robots plus intelligents et réactifs.
Mon intérêt pour l'ingénierie des données vient de mon expérience en tant qu'architecte de solutions. Dans ce rôle, j'ai apprécié construire des systèmes basés sur le cloud pour stocker et traiter des données afin d'en tirer de nouvelles informations et connaissances.
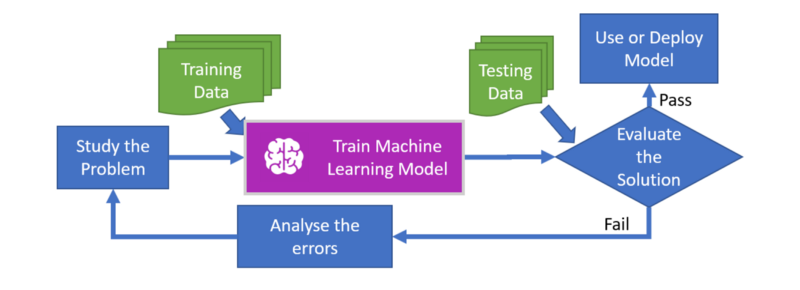
Je développe également des pipelines de big data et de ML pour automatiser l'ensemble du processus de ML. Cela aide les data scientists et les analystes à gagner du temps dans la préparation des données pour l'entraînement et le test de leurs algorithmes, l'exécution de métriques et la dérivation d'indicateurs de performance clés à grande échelle.
La préparation des données est particulièrement importante. Les data scientists passent généralement environ 80 % de leur temps dessus. Avoir accès à des données structurées de la bonne manière les rend plus productifs et plus heureux.
Mon expérience précédente
J'ai précédemment obtenu un master en ingénierie des systèmes informatiques et un doctorat en ML et NLP. J'ai complété les deux à l'Université de Manchester.
Plutôt que de rejoindre un fournisseur spécialisé dans mon domaine d'expertise de doctorat, j'ai décidé d'élargir mes compétences et de gagner plus d'exposition client en rejoignant Capgemini. Capgemini est une grande entreprise mondiale de conseil, de technologie et de services externalisés.
J'ai gravi les échelons, passant de développeur à architecte de solutions. Là-bas, j'ai aidé à livrer des projets à grande échelle pour des entreprises du Fortune Global 500 dans des secteurs incluant l'assurance, la banque de détail, les services financiers et le gouvernement central.
J'ai ensuite rejoint PageGroup. Là, j'ai travaillé en tant que développeur principal et architecte sur un programme de transformation mondiale dans 34 pays. J'ai dirigé la livraison technique de la recherche, de la communication multicanal, de la business intelligence, de l'analyse de texte, de l'intégration des tableaux d'offres d'emploi et des solutions publicitaires.
Rôles actuels
Maintenant, je suis ingénieur principal en big data et machine learning chez JustGiving. JustGiving est une entreprise de technologie pour le bien qui a aidé 26 millions d'utilisateurs dans 164 pays à lever 5 milliards de dollars pour de bonnes causes. Elle a été acquise en 2017 par Blackbaud — la principale entreprise de logiciels au monde alimentant le bien social.
Je dirige actuellement la livraison et l'architecture de notre plateforme de data science interne RAVEN et des systèmes de ML de production. Ceux-ci ont été initialement déployés avec Azure, mais sont maintenant hébergés dans AWS. Je plonge également en tant que data scientist spécialisé dans les algorithmes d'analyse de streaming scalable, de ML et de NLP.
Je partage mon expérience et mes connaissances techniques en interne et en externe concernant AWS, le traitement de flux, les piles serverless, le ML et le NLP. Je présente également régulièrement lors de conférences industrielles, open source mon code et écris des articles techniques sur Medium et pour AWS tels que Analysez une série temporelle en temps réel.
Je suis également un conseiller et consultant indépendant aidant les organisations avec l'architecture cloud, le computing serverless et le ML chez Starwolf.
Une journée typique au bureau
JustGiving est toujours une startup dans l'âme, donc il n'y a pas de journée typique. Je m'implique dans diverses tâches, telles que la capture des exigences de données et de rapports, l'ingénierie de nouveaux pipelines de données, l'investigation des problèmes opérationnels, l'exécution d'expériences de données, l'analyse de données non structurées à la recherche de motifs utiles, l'exploration de nouvelles façons d'utiliser les données pour répondre à des questions, la présentation d'une histoire de données, et le partage de mes connaissances et de mon expérience. Cela signifie que je travaille en étroite collaboration avec le marketing, les chefs de produit et les analystes de produit pour comprendre leurs besoins en données et quelles métriques et prédictions sont importantes pour eux.
Parler à d'autres personnes en dehors de votre domaine de spécialité aide à élargir vos vues, vous donne une nouvelle perspective et de nouveaux domaines où vous pouvez appliquer vos compétences.
Sur le plan technique, je travaille avec des ingénieurs, des analystes de données, des développeurs, des analystes de business intelligence, des opérations et des data scientists pour soutenir leurs besoins en données et en plateforme.
Ce que j'aime dans mon travail
Je suis passionné par le travail avec d'énormes ensembles de données, car vous êtes confronté à différents types de problèmes de performance, de coûts et d'exploitation qui vous obligent à penser différemment afin de mettre à l'échelle votre entrepôt de données, vos processus ETL et vos algorithmes, ainsi que la manière dont vous présentez vos résultats. Beaucoup de ce que vous savez sur l'entreposage de données avec leurs millions d'enregistrements est obsolète lorsque vous atteignez des centaines de milliards de lignes et que vous devez itérer ou effectuer des jointures complexes pour exécuter des requêtes de préparation de données ML.
La construction et l'exécution d'infrastructures de données à grande échelle et la formation de modèles distribués sont des domaines actifs dans le milieu universitaire et l'industrie. Ils évoluent à un rythme rapide, avec de nouveaux outils introduits tous les quelques mois. J'aime utiliser des solutions cloud de manière innovante pour améliorer notre plateforme de data science interne, améliorer nos processus métiers et rendre les insights de données disponibles pour les utilisateurs internes et externes.
J'ai constaté que beaucoup d'entreprises donnent leur pouvoir en utilisant des tiers pour leurs solutions d'analyse web, plutôt que de construire les leurs. Ces données sont ensuite cloisonnées dans les départements marketing ou commerciaux, il est difficile, voire impossible, de les récupérer sous leur forme brute, et elles ne peuvent pas être diffusées en continu, ce qui vous empêche par exemple de faire des recommandations ou des prédictions ML en temps réel directement dans votre produit.
Chez JustGiving, nous avons construit un produit d'analyse web interne appelé KOALA et avons ces données disponibles en temps réel sous forme de pile AWS Serverless. Cela nous a permis d'avoir une suite complète de pipelines de données pour la formation ML et l'analyse en interne, et des solutions comme MAGPIE qui nous permettent de créer des métriques et des insights en temps réel que nous pouvons renvoyer aux utilisateurs.
Par exemple, voici une version précoce montrée dans ce Tweet lors d'une campagne de financement participatif pour les familles des victimes des attaques de Manchester en mai 2017.
En outre, KOALA nous permet de faire des prédictions à partir de données de streaming. C'est une solution extrêmement rentable par rapport au paiement d'un produit fournisseur. Si vous le comparez à une solution fournisseur basée sur le même trafic web, KOALA est 10 fois moins cher, plus convivial pour les développeurs, et nous obtenons les données brutes diffusées en temps réel, plutôt que par lots ou en ayant à utiliser un système de requête ou de reporting propriétaire verrouillé.
Je suis également un grand fan de Python et j'ai réussi à encourager son adoption dans l'entreprise et la communauté élargie pour les pipelines de données, le ML et le computing serverless. Pourquoi Python ? Il dispose de bibliothèques ML extensives, est scalable avec des solutions comme pySpark, et est facile à lire/écrire.
J'aime également travailler avec différentes organisations, associations caritatives, universités et redonner à la communauté technique élargie avec mon expérience et mon temps, comme lors du AWS et British Heart Foundation Hackathon récemment.
L'avenir du Big Data, de la Data Science et de l'IA
Je vois de plus en plus de personnes utiliser le ML, l'analyse en temps réel, l'analyse de graphes et le NLP dans leurs produits et applications, et pas seulement hors ligne sur leurs ordinateurs portables. Cela s'accélère à mesure que les fournisseurs de cloud proposent des interfaces de programmation d'applications (API) pour le ML et le NLP.
Pour l'analyse en temps réel, il y a une demande croissante de la part des consommateurs, qui sont beaucoup plus conscients des données et impatients. Par exemple, ils veulent savoir ce qui se passe maintenant, voir les résultats de leurs actions et utiliser des applications et des sites web plus intelligents qui s'adaptent lorsqu'ils interagissent avec eux.
Sur le plan de l'infrastructure, je vois le computing serverless et les infrastructures Platform as a Service (PaaS) dans le cloud public, comme AWS et Azure, devenir plus prometteurs. Les fonctions dans le computing serverless sont particulièrement intéressantes pour moi, car elles peuvent s'auto-scaler en moins de 100 millisecondes, sont hautement disponibles et peu coûteuses. Elles sont peu coûteuses car vous ne payez que pour le temps pendant lequel votre code est exécuté, plutôt que pour une machine ou un conteneur toujours en marche comme dans les infrastructures cloud plus traditionnelles. J'ai même montré que vous pouvez implémenter la plupart des modèles existants basés sur des conteneurs en utilisant une pile serverless.
Les frameworks open source et les langages de programmation continueront également de croître par rapport aux produits et langages spécifiques des fournisseurs fermés, par exemple le framework Apache Spark, Python, R, SQL. Il en va de même pour le stockage et l'accès aux données : le stockage cloud, les entrepôts de données et les data lakes stockeront les données dans des formats plus ouverts plutôt que propriétaires, et cela sera plus accessible via des API standard ou des protocoles ouverts.
Il y aura également des exigences croissantes pour analyser des sources de données non structurées et multimédias, et encore une fois, les fournisseurs de cloud auront un rôle croissant à jouer.
Nous verrons également plus d'entreprises effectuer la transition de l'utilisation de stratégies décidées par quelques-uns sur instinct au sommet, à devenir plus basées sur les expériences, les preuves et les données, comme décrit par mon ancien CAO Mike Bugembe dans son livre. Par exemple, le test de nouveaux produits ou fonctionnalités, l'identification de nouvelles opportunités et les décisions stratégiques viendront de plus en plus de l'analyse des données, des insights et des prédictions.
Cela nécessitera que plus de personnel s'implique dans la capture des données, la préparation des données, l'exécution d'expériences utilisant des algorithmes, la visualisation des données et la présentation des résultats.
Ainsi, de nouveaux emplois orientés données basés sur la création et la formation de modèles de données émergeront, perturbant certains des domaines spécialisés existants tels que les soins de santé, la comptabilité et le droit. L'IA, l'Internet des objets (IoT) et la robotique remplaceront également certains emplois existants de cols bleus et blancs, donc nous devrons penser à la formation et à la montée en compétences des personnes face au paysage changeant, et éventuellement introduire une sorte de revenu de base universel.
Vous pouvez établir des parallèles avec le changement observé lors de la révolution industrielle, passant des temps agrariens ou pré-industriels. Pour que l'IA décolle, nous avons besoin de deux choses : que le coût des travailleurs humains devienne plus élevé que l'alternative IA, et que l'IA soit déployée de manière scalable.
À plus long terme, l'informatique quantique perturbera à nouveau le domaine en termes de traitement, d'analyse et de stockage des données, et transformera des domaines comme la cybersécurité, la banque et l'IA existante.
Comment inspirer les gens à poursuivre des carrières en data science
Je pense qu'il est beaucoup plus facile d'intéresser les gens au big data et à la data science qu'avant, grâce à des entreprises comme Google et Facebook qui rendent à la mode le fait d'être intelligent et de travailler dans la technologie.
De plus, le nombre croissant de jeunes startups flexibles avec des infrastructures dans le cloud public réussissent à concurrencer et à gagner des parts de marché aux grandes entreprises établies. Les employeurs doivent être prêts à éduquer et à monter en compétences le personnel existant ou les diplômés plutôt que de recruter uniquement des personnes ayant déjà des compétences en ingénierie des données ou en data science.
Pour inspirer le personnel existant, nous devons montrer les avantages, les cas d'utilisation et les sources de données les plus pertinents pour eux, ce qui les rend plus productifs et leur travail plus facile. Avec plus d'outils d'exploration de données disponibles, le personnel d'autres départements en dehors de l'IT ou de la finance, tels que le support client, le marketing et les chefs de produit, seront autonomes sur les données et les insights.
Pour les personnes qui n'ont pas travaillé dans l'industrie, je pense que nous devons commencer tôt dans les écoles puis les universités. Les enseignants et les conférenciers dans des matières non informatiques pourraient rendre les données plus visuelles et interactives dans leurs domaines respectifs.
Je pense que presque n'importe quelle matière peut en bénéficier — par exemple, même en littérature anglaise, vous pouvez tracer un graphe de relation des personnages et de leurs connexions liées aux thèmes principaux, aux événements et aux lieux. En cours d'histoire, vous pourriez avoir des cartes visuelles interactives et des représentations graphiques évolutives des événements clés et de leurs dépendances.
Conseils que je donnerais à quelqu'un envisageant une carrière dans le Big Data et la Data Science
Que vous soyez diplômé, que vous travailliez déjà dans une organisation ou que vous ne veniez pas d'un milieu technique, vous pouvez bénéficier de l'analyse et de la compréhension des données. Par exemple, les journalistes de données ne viennent généralement pas d'un milieu technique ou scientifique, mais sont capables de faire des analyses simples et de créer une histoire de données intéressante pour le grand public.
C'est une question de motivation personnelle : lorsque les choses évoluent à un rythme si rapide, vous pouvez regarder largement à travers le secteur pour obtenir une compréhension générale. Mais vous devez également concentrer votre énergie sur un cours ou un projet spécifique et le terminer. L'industrie a également tendance à reconditionner d'anciennes technologies avec quelques améliorations en tant que nouvelles tendances, comme la cybersécurité, l'informatique cognitive, les chatbots, la réalité virtuelle et le deep learning en ce moment. Je suivrais donc votre cœur pour les domaines qui vous intéressent vraiment et sur lesquels vous voulez vous concentrer plutôt que la dernière tendance.
Derrière chaque tendance virale, il y a généralement eu des explorateurs précoces qui ont travaillé et lutté dans ce domaine pendant des années !
En termes d'acquisition de connaissances, c'est beaucoup plus facile qu'avant. Par exemple, dans le passé, vous deviez payer pour une formation spécifique à un fournisseur et il y avait le coût du produit lui-même. Vous pouvez maintenant accéder aux matériels d'apprentissage, aux sources de données et aux outils tous gratuitement, donc il n'y a aucune excuse pour ne pas commencer aujourd'hui !
Pour les matériels d'apprentissage, une grande partie du contenu est disponible gratuitement dans des cours en ligne ouverts massifs, des formulaires, des blogs et des dépôts de code source. De même, il existe de nombreuses sources de données gratuites comme les ensembles de données ML, les données ouvertes, les flux d'actualités et les médias sociaux que vous pouvez utiliser.
Il existe de nombreux outils. Certains sont graphiques, mais à mon avis, vous devriez apprendre à programmer en SQL, Python ou R. Les trois ont la capacité de faire de la data science à grande échelle grâce à des frameworks comme Apache Spark. J'aime particulièrement Python car il bénéficie d'être un langage de développement efficace avec un framework de test solide et de nombreux packages de data science.
En tant qu'ingénieur ML ou data scientist, attendez-vous à passer beaucoup de temps sur la préparation des données. Il s'agit d'un processus important à maîtriser, qui implique le nettoyage, l'analyse, l'enrichissement et la structuration des données afin qu'elles puissent être utilisées dans les algorithmes et les expériences de ML. Dans l'ensemble, rappelez-vous que les processus, les outils et les sources de données évoluent constamment, donc il n'y a pas de formation unique et magique que vous pouvez suivre. Vous devrez être motivé et ouvert à l'apprentissage et à l'adaptation constants à l'écosystème des données.
Je vous recommande d'apprendre une autre langue comme le mandarin (1,1 milliard de locuteurs) ou l'espagnol (0,5 milliard de locuteurs), pour rester mobile, obtenir plus d'opportunités de carrière et être compétitif dans ce monde interconnecté. Cela ouvrira également votre esprit et vous donnera un aperçu d'autres cultures et valeurs, et de la manière dont elles utilisent leurs données.
Le cloud computing signifie également que vous n'avez plus besoin d'une présence physique dans un pays pour y opérer, donc vous devez être ouvert à la construction de systèmes à travers les régions et à l'analyse de données provenant de nombreux pays. Commencez à utiliser des outils collaboratifs et participez à des communautés tech pour le bien.
Certains emplois et professions seront remplacés, et certaines expertises humaines seront perdues, mais nous continuerons à nous appuyer sur les données et les algorithmes. Par exemple, une fois que le transport sans conducteur sera largement adopté et considéré comme plus sûr, moins cher et plus pratique que les conducteurs humains, les générations futures ne voudront peut-être pas conduire une voiture ou même avoir un permis de conduire. Cependant, les humains seront toujours impliqués dans les systèmes qui automatisent la conduite, l'analyse créative de la télémétrie et des données IoT, la supervision et la surveillance de l'écosystème, et la participation plus large à l'industrie des transports et à l'économie du partage.
Résumé
Si vous souhaitez faire carrière dans la data science, le ML ou l'ingénierie des données, les besoins de l'entreprise guident toujours le développement logiciel et l'analyse. Pensez aux métriques que vous souhaitez calculer et qui bénéficieront à vos décisions commerciales, ou à l'hypothèse que vous souhaitez valider avec une expérience.
Quelles actions votre audience entreprendra-t-elle avec vos résultats ? Quelles opportunités de croissance ou d'économies de coûts pour une entreprise existent ? Ensuite, travaillez à rebours pour voir quelles données, modèles et infrastructure vous avez besoin pour la tâche. Je pense que la curiosité, l'esprit d'investigation et l'esprit expérimental sont des qualités importantes.
N'hésitez pas à me contacter sur LinkedIn, à me suivre sur Twitter, ou à m'envoyer un message pour des commentaires et des questions. Si vous souhaitez avoir une discussion plus personnalisée avec moi, basée sur vos demandes, je propose des appels Skype de 30 minutes sur des conseils de carrière ou du mentorat pour une petite somme. Je fais également du conseil à court terme et fournis des services d'expertise et d'audit aux organisations qui construisent et exploitent des plateformes de big data et de data science dans le cloud.