


Article original : How to Work with SQL Databases in Go – Different Approaches and Examples
Différents langages de programmation ont leurs propres façons de travailler avec les bases de données relationnelles et SQL. Ruby on Rails a son Active Record, Python a SQLAlchemy, TypeScript a Drizzle, et ainsi de suite.
Go est un langage avec une bibliothèque standard assez diversifiée, qui inclut le célèbre package database/sql. Et il possède ses propres bibliothèques et solutions pour travailler avec SQL, adaptées à différents besoins, préférences et équipes.
Dans cet article, nous explorerons et comparerons les packages Go les plus populaires qui vous permettent de travailler avec SQL. Nous examinerons quelques exemples concrets, ainsi que les avantages et les inconvénients. Nous aborderons également brièvement le sujet des migrations de bases de données et la manière de les gérer en Go.
Vous tirerez le meilleur parti de cet article si vous avez déjà une certaine expérience de Go, de SQL et des bases de données relationnelles (peu importe laquelle).
Table des matières
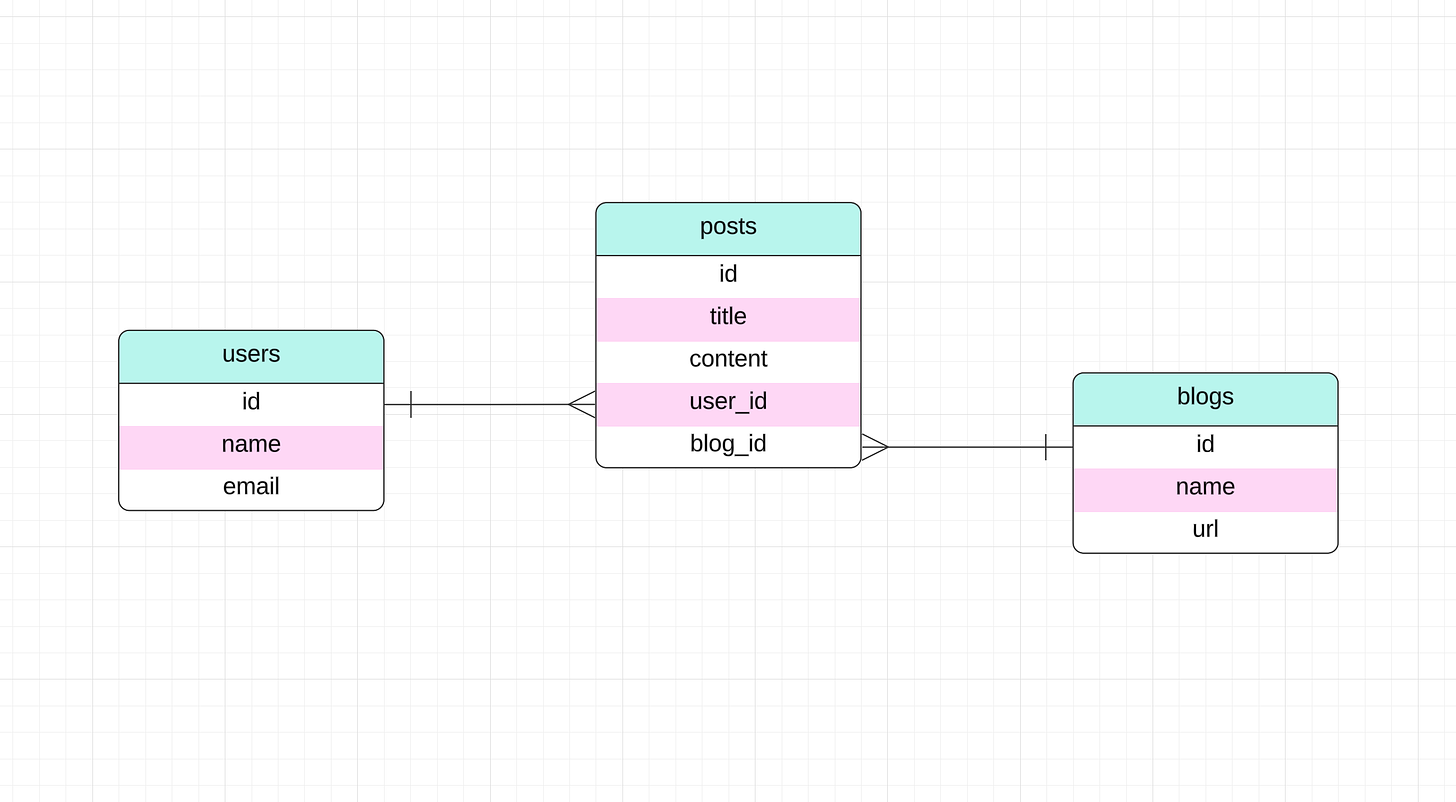
Schéma de démonstration
Pour cet article, nous utiliserons un schéma simple avec trois tables : users, posts, et blogs. Par simplicité, nous utiliserons SQLite comme moteur de base de données. Mais si vous souhaitez choisir un autre moteur, cela ne devrait pas poser de problème, car toutes les bibliothèques que nous explorerons supportent plusieurs dialectes SQL.
Voici notre schéma de base de données en SQL :
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
CREATE TABLE blogs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
url TEXT NOT NULL UNIQUE
);
CREATE TABLE posts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
content TEXT NOT NULL,
user_id INTEGER NOT NULL,
blog_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) ON DELETE CASCADE,
FOREIGN KEY (blog_id) REFERENCES blogs (id) ON DELETE CASCADE
);
Et voici son Diagramme Entité-Relation (ERD) :
SQL brut et database/sql
Imaginons que votre application doive effectuer l'action suivante :
Trouver les utilisateurs qui ont publié au moins deux articles, ainsi que le nombre total d'articles qu'ils ont rédigés.
En SQL pur, vous pourriez traduire cela par la requête suivante :
SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= 2;
Une brève explication de cette requête : nous effectuons une jointure (JOIN) entre les tables users et posts, puis nous groupons (GROUP BY) par user_id. La clause HAVING filtre les résultats pour n'inclure que les utilisateurs ayant publié au moins 2 articles, et COUNT agrège la quantité d'articles.
Comme mentionné ci-dessus, Go fournit un package intégré appelé database/sql avec les outils nécessaires pour travailler avec des bases de données SQL. Il a été conçu dans un esprit de simplicité, mais supporte toutes les fonctionnalités nécessaires telles que les transactions, les requêtes paramétrées, la gestion du pool de connexions, etc.
Tant que vous êtes à l'aise pour écrire vos propres requêtes et gérer les erreurs et les résultats, c'est une excellente option. Certains diraient même que c'est la meilleure option, car il n'y a pas de logique cachée et vous pouvez toujours copier la requête et l'analyser avec EXPLAIN.
Voici comment vous pouvez obtenir les résultats de la requête ci-dessus en code Go en utilisant database/sql (certaines parties comme la connexion sont omises) :
type userStats struct {
UserName sql.NullString
PostCount sql.NullInt64
}
func getUsersStats(conn *sql.DB, minPosts int) ([]userStats, error) {
query := `SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= ?;`
rows, err := conn.Query(query, minPosts)
if err != nil {
return nil, err
}
defer rows.Close()
users := []userStats{}
for rows.Next() {
var user userStats
if err := rows.Scan(&user.UserName, &user.PostCount); err != nil {
return nil, err
}
users = append(users, user)
}
if err := rows.Err(); err != nil {
return nil, err
}
return users, nil
}
Dans ce code, nous :
Utilisons la requête SQL brute avec un paramètre anonyme, et passons la valeur de ce paramètre dans
conn.Query().Itérons sur les lignes retournées et scannons manuellement chaque ligne dans une structure
userStatsdéfinie plus haut. Notez que la structure utilise les typessql.Null*pour gérer correctement les valeurs nullables.Devons vérifier manuellement les erreurs possibles et fermer les lignes pour libérer les ressources.
Avantages :
Aucune abstraction ou complexité supplémentaire ajoutée. Facile de déboguer les requêtes SQL brutes.
Performance. Le package database/sql est très performant.
Fournit une abstraction suffisante par rapport aux différents moteurs de base de données.
Inconvénients :
Le code devient un peu verbeux car il est nécessaire de scanner chaque ligne, de définir les types appropriés et de gérer les erreurs.
Pas de sécurité de typage au moment de la compilation.
Vous pouvez trouver le code source complet de cet article dans ce dépôt GitHub.
SQL brut et sqlx
Jetons maintenant un coup d'œil à certains packages externes populaires dans la communauté Go.
Si vous connaissez déjà database/sql et appréciez sa simplicité, vous aimerez peut-être travailler avec sqlx. Il est construit par-dessus la bibliothèque standard et en étend simplement les fonctionnalités.
Il est très facile d'intégrer des bases de code existantes utilisant database/sql avec sqlx, car il laisse intactes les interfaces sous-jacentes telles que sql.DB, sql.Tx, etc.
Les fonctionnalités principales de sqlx sont :
Paramètres nommés.
Analyse (scanning) des lignes plus facile dans des structures avec support des structures imbriquées.
Meilleure séparation entre les lignes uniques et multiples en utilisant les méthodes
Get()etSelect().Possibilité de lier une tranche (slice) de valeurs comme un paramètre unique à une requête IN.
Voici comment obtenir les résultats de la requête ci-dessus en utilisant sqlx :
type userStats struct {
UserName string `db:"name"`
PostCount string `db:"post_count"`
}
func getUsersStats(conn *sqlx.DB, minPosts int) ([]userStats, error) {
users := []userStats{}
query := `SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= ?;`
if err := conn.Select(&users, query, minPosts); err != nil {
return nil, err
}
return users, nil
}
Dans ce code, nous utilisons la méthode Select() qui gère le scan des lignes. Elle ferme également les lignes automatiquement, nous n'avons donc pas à nous en occuper.
Le code est beaucoup plus court que la version database/sql, mais il peut nous masquer certains détails d'implémentation. Par exemple, sachez que Select charge l'ensemble des données en mémoire en une seule fois.
Avantages :
Très proche de database/sql. Toujours facile de déboguer les requêtes SQL brutes.
Un ensemble de fonctionnalités intéressantes pour réduire la verbosité du code.
Inconvénients :
- Les mêmes que database/sql.
ORM
L'Object-relational mapping (ORM) est une technique (certains l'appellent un patron de conception) permettant d'accéder à une base de données relationnelle en travaillant avec des objets sans avoir à rédiger des instructions SQL complexes. C'est très populaire dans les langages orientés objet – Ruby on Rails a son Active Record, Python a SQLAlchemy, TypeScript a Drizzle, et ainsi de suite.
Et Go possède GORM. En résumé, il vous permet d'écrire des requêtes sous forme de code Go en appelant diverses méthodes sur des objets, lesquelles sont ensuite traduites en requêtes SQL. Mais ce n'est pas tout : il propose d'autres fonctionnalités comme les migrations de base de données, les résolveurs de base de données, et bien plus encore.
Vous devrez peut-être passer un peu de temps au début pour configurer vos modèles GORM, mais par la suite, cela peut réduire considérablement le code répétitif (boilerplate).
Notre exemple simple de schéma et de requête n'est peut-être pas le meilleur pour visualiser les forces et faiblesses de GORM, mais il devrait suffire à démontrer comment nous pouvons exécuter une requête similaire et scanner les résultats :
type User struct {
gorm.Model
ID int
Name string
Posts []Post
}
type Post struct {
gorm.Model
ID int
UserID int
}
type userStats struct {
Name string
Count int `gorm:"column:post_count"`
}
func getUsersStats(conn *gorm.DB, minPosts int) ([]userStats, error) {
var users []userStats
err := conn.Model(&User{}).
Select("name", "COUNT(p.id) AS post_count").
Joins("JOIN posts AS p ON users.id = p.user_id").
Group("users.id").
Having("post_count >= ?", minPosts).
Find(&users).Error
return users, err
}
La requête SQL générée par gorm sera approximativement la même que celle que nous avons écrite manuellement dans la variante database/sql.
Pour résumer le code ci-dessus :
Nous avons déclaré nos modèles User et Post et les avons étendus avec la structure par défaut
gorm.Model. Plus tard, nous pouvons utiliser ces deux modèles pour construire toutes les requêtes souhaitées en utilisant les méthodes de gorm.Nous avons également défini notre petit type de résultat
userStats.Nous avons utilisé des méthodes telles que
Select(),Joins(),Group(), etHaving()pour produire la requête voulue.
Avec un exemple aussi simple, il est difficile de voir les problèmes potentiels – tout semble correct. Mais lorsque votre projet deviendra plus complexe, vous rencontrerez très certainement des difficultés. Il suffit de regarder les questions StackOverflow marquées avec le tag go-gorm.
Il est bon d'être prudent quant à l'utilisation des ORM dans les systèmes où la performance est critique ou lorsque vous avez besoin d'un contrôle direct sur les interactions avec la base de données. C'est parce que GORM utilise beaucoup de réflexion (reflection), ce qui peut ajouter une surcharge et parfois obscurcir ce qui se passe au niveau de la base de données. Tout projet où la fonctionnalité est enveloppée dans une autre couche massive court le risque d'augmenter la complexité globale.
Avantages :
Abstraction par rapport aux différents moteurs de base de données.
Grand ensemble de fonctionnalités : migrations, hooks, résolveurs de base de données, etc.
Évite une bonne partie de codage fastidieux.
Inconvénients :
Une couche supplémentaire de complexité et de surcharge. Difficile de déboguer les requêtes SQL brutes.
Inconvénients de performance. Peut ne pas être aussi efficace pour certaines applications critiques.
La configuration initiale peut nécessiter du temps pour configurer tous les modèles.
Code Go généré à partir de SQL avec sqlc
Cela nous amène tout naturellement à une autre approche unique consistant à générer du code Go à partir de requêtes SQL en utilisant sqlc. Avec sqlc, vous écrivez votre schéma et vos requêtes SQL, puis vous utilisez un outil CLI pour générer du code Go à partir de ceux-ci, et vous utilisez ensuite le code généré pour interagir avec les bases de données.
Cela garantit que vos requêtes sont syntaxiquement correctes et type-safe. C'est idéal pour ceux qui préfèrent écrire du SQL mais recherchent un moyen efficace de l'intégrer dans une application Go.
sqlc doit connaître votre schéma de base de données et vos requêtes pour générer le code, il nécessite donc une configuration initiale. Nous pouvons ajouter notre schéma et notre requête ci-dessus dans les fichiers schema.sql et query.sql. Ensuite, en utilisant la configuration suivante, nous pouvons générer le code Go :
version: "2"
sql:
- engine: "sqlite"
queries: "query.sql"
schema: "schema.sql"
gen:
go:
package: "main"
out: "."
Nous devons également nommer notre requête dans query.sql et marquer les paramètres :
-- name: GetUsersStats :many
SELECT u.name, COUNT(p.id) AS post_count
FROM users AS u
JOIN posts AS p ON u.id = p.user_id
GROUP BY u.id
HAVING post_count >= ?;
Après avoir exécuté sqlc generate, nous pouvons utiliser les types et fonctions générés suivants, qui rendent notre code type-safe et assez court.
func getUsersStats(conn *sql.DB, minPosts int) ([]GetUsersStatsRow, error) {
queries := New(conn)
ctx := context.Background()
return queries.GetUsersStats(ctx, minPosts)
}
Ce qui rend sqlc spécial, c'est qu'il comprend votre schéma de base de données et l'utilise pour valider le SQL que vous écrivez. Ainsi, vos requêtes SQL sont validées par rapport aux tables réelles de la base de données, et sqlc vous donnera une erreur au moment de la compilation si quelque chose ne va pas.
Avantages :
Sécurité de typage (type safety) avec le code Go généré.
Toujours facile de déboguer le code SQL.
Évite une bonne partie de codage fastidieux.
Performance.
Inconvénients :
Configuration initiale du schéma de base de données et des requêtes.
Analyse statique pas toujours parfaite. Parfois, vous devez définir explicitement le type de paramètre, etc.
Si vous êtes doué en requêtes SQL et préférez ne pas utiliser trop de code pour exprimer vos interactions avec la base de données, ce package est fait pour vous.
Migrations de bases de données
Puisque nous abordons le sujet des bases de données SQL, passons brièvement en revue le fonctionnement des migrations de bases de données en Go. Le schéma de la base de données évolue presque toujours avec le temps et personne ne veut effectuer ces changements manuellement. Des outils ont donc été développés pour faciliter cette tâche.
L'objectif principal des outils de migration est de garantir que tous les environnements ont le même schéma et que les développeurs peuvent facilement appliquer les changements ou les annuler.
J'ai mentionné plus haut que GORM peut également gérer les migrations si votre projet l'utilise comme ORM. Si vous utilisez database/sql, sqlx ou sqlc, vous devrez utiliser des projets distincts pour les gérer.
Les projets les plus populaires sont :
golang-migrate : l'un des outils les plus célèbres pour gérer les migrations de bases de données. Il supporte de nombreux pilotes de base de données et sources de migration, et adopte une approche simple et directe.
goose : une autre option solide. Il supporte également les principaux pilotes de base de données. Deux de ses fonctionnalités principales sont le support des migrations écrites en Go et un meilleur contrôle sur le processus d'application des migrations.
Vous pouvez ensuite intégrer ces outils directement dans votre application ou dans votre CI/CD. Mais les exécuter correctement en CI/CD nécessite une certaine configuration (par exemple en cas de déploiement sur Kubernetes), et j'approfondirai ce sujet dans mes prochains articles.
Conclusion
Il existe de nombreux packages de base de données bien écrits, testés et supportés pour Go, qui peuvent vous aider à développer plus rapidement et à écrire un code plus propre. Il y a aussi le très puissant database/sql inclus dans la bibliothèque standard qui peut accomplir la majeure partie de votre travail quotidien.
Mais que vous deviez l'utiliser ou non dépend de vos besoins en tant que développeur, de vos préférences et de votre projet. Dans cet article, j'ai essayé de mettre en lumière les forces et les faiblesses de chaque option.
Vous pouvez trouver le code source complet de cet article sur ce dépôt GitHub.
Je terminerai cet article par ce célèbre mème :
