


Article original : How to Monitor Your Kubernetes Clusters with Prometheus and Grafana on AWS
Créer une stratégie solide de surveillance et d'observabilité des applications est une étape fondamentale cruciale lors du déploiement d'infrastructures ou de logiciels dans n'importe quel environnement. La surveillance garantit que vos systèmes fonctionnent sans problème, tandis que l'observabilité fournit des informations sur l'état interne de votre application grâce aux données générées. Ensemble, elles vous aident à détecter et à résoudre les problèmes de manière proactive plutôt que de réagir après une panne.
Dans les environnements Kubernetes, la complexité de la gestion des microservices distribués peut être difficile. Par exemple, une application s'étend généralement sur plusieurs pods, nœuds et clusters. En raison de la nature dynamique de Kubernetes, où les pods sont fréquemment créés et terminés, une surveillance et une observabilité appropriées sont idéales pour capturer son comportement fugace.
Imaginez construire une application de microservices avec plusieurs services connectés gérant des composants critiques tels que l'authentification, les paiements et les bases de données sans surveillance appropriée. Une augmentation soudaine du trafic pourrait affecter un seul service, se répercutant sur d'autres services, provoquant la panne du système et entraînant des temps d'arrêt.
Sans une visibilité appropriée, vous pourriez avoir du mal à trouver la cause profonde du problème. Vous pourriez passer des heures à parcourir manuellement les journaux - et pendant ce temps, les utilisateurs sont frustrés et les entreprises perdent des revenus et la confiance des clients.
Avant de commencer le projet, vous apprendrez les concepts clés de la surveillance et de l'observabilité, ainsi que pourquoi des outils comme Prometheus et Grafana sont cruciaux pour mettre en place une pile de surveillance robuste sur votre infrastructure Kubernetes.
Voici ce que nous allons couvrir :
Comprendre la surveillance et l'observabilité
Mettre en œuvre une approche appropriée de surveillance et d'observabilité est important dans les environnements Kubernetes de production rapides. Cela aide dans les situations où les temps d'arrêt peuvent entraîner des pertes commerciales sérieuses et des dommages à la confiance des clients. Cela vous aidera, espérons-le, à éviter les redoutables appels à 2 heures du matin qui sont généralement déclenchés par le bruit des alertes afin que vous puissiez vous concentrer sur l'ajout de fonctionnalités plus innovantes à votre logiciel (plutôt que de passer tant d'énergie à éteindre des incendies).
La surveillance et l'observabilité sont souvent considérées comme la même chose. Mais elles servent deux objectifs différents, surtout pour les équipes de développement et d'ingénierie.
Surveillance
Dans le cycle de vie du développement logiciel, la surveillance est la pratique d'analyse des données en temps réel ou de révision des tendances des données pour assurer la santé et la performance des systèmes, des infrastructures et des applications. La surveillance agit comme les yeux et les oreilles de vos opérations informatiques, collectant des données perspicaces et les présentant de manière actionnable.
Si vous avez visité le département informatique d'une organisation bien établie, vous avez probablement vu de grands écrans affichant des tableaux de bord colorés avec des graphiques et des statistiques en temps réel. Cela offre une vue centralisée des métriques clés, telles que le temps de fonctionnement du serveur, les temps de réponse des applications et l'utilisation des ressources.
Observabilité
L'observabilité aide à résoudre les problèmes qui n'ont pas été anticipés. Ceux-ci sont généralement appelés "inconnus inconnus". Contrairement à la surveillance, qui traite des paramètres et des données prédéfinis, l'observabilité va plus loin dans l'application pour donner une vue plus large.
Cela aide non seulement à répondre à ce qui se passe dans votre système et pourquoi cela se produit. Il utilise également des modèles au sein du système et des opérations de l'application pour détecter et résoudre les problèmes efficacement.
L'observabilité tourne autour des trois piliers des données : métriques, journaux et traces.
1. Métriques
Les métriques consistent en des mesures de séries temporelles telles que l'utilisation du CPU et la consommation de mémoire. Ces points de données aident les équipes à gérer, optimiser et prédire les performances du système et les écarts par rapport au comportement attendu.
2. Journaux
Les journaux servent d'historique de ce qui s'est passé dans le système. C'est une trace pour les ingénieurs, surtout pendant le dépannage. Les journaux sont importants pour diagnostiquer les causes profondes et découvrir les activités malveillantes.
3. Traces
Les traces fournissent des informations sur les flux de travail des applications en suivant les requêtes lorsqu'elles se déplacent à travers divers composants. Elles sont bonnes pour mettre en évidence les problèmes de latence et les points de défaillance potentiels.
Outils pour la surveillance et l'observabilité
Maintenant que vous comprenez la théorie derrière la surveillance et l'observabilité, vous vous demandez peut-être quelles plateformes et outils sont disponibles pour les développeurs afin de collecter des données et obtenir des informations sur leurs services.
Dans le monde de l'infrastructure native du cloud et de Kubernetes, de nombreux utilisateurs se tournent vers la pile populaire de Prometheus et Grafana.
Prometheus
Prometheus est un outil open-source qui se spécialise dans la collecte de métriques en tant que données de séries temporelles. Les informations sont stockées avec l'horodatage auquel elles ont été enregistrées.
L'écosystème Prometheus comprend le serveur principal Prometheus, qui collecte et stocke les données de séries temporelles, un gestionnaire d'alertes pour gérer les alertes, une passerelle de poussée pour gérer les métriques des travaux de courte durée, et des exportateurs pour collecter les métriques de divers services connectés au cluster.
Il convient à la fois à la surveillance centrée sur la machine et à la surveillance centrée sur l'application, en particulier pour les microservices dans un cluster Kubernetes. Il est conçu pour être le système auquel vous vous tournez en cas de panne du système et dont vous avez besoin pour diagnostiquer rapidement les problèmes.
L'écosystème Prometheus comprend le serveur principal Prometheus, qui collecte et stocke les données de séries temporelles, un gestionnaire d'alertes pour gérer les alertes, une passerelle de poussée pour gérer les métriques des travaux de courte durée, et des exportateurs pour collecter les métriques de divers services connectés au cluster.
Prometheus convient à la fois à la surveillance centrée sur la machine et à la surveillance centrée sur l'application, en particulier pour les microservices dans un cluster Kubernetes. Il est conçu pour être le système auquel vous vous tournez en cas de panne du système et dont vous avez besoin pour diagnostiquer rapidement les problèmes.
Grafana
Grafana est un outil de visualisation qui transforme, interroge, visualise et définit des alertes sur les métriques brutes stockées dans Prometheus. Avec Grafana, vous pouvez explorer les métriques et les journaux où qu'ils soient stockés et afficher les données sur des tableaux de bord en direct. Cela permet aux équipes de surveiller les performances du système, d'identifier les tendances et d'agir rapidement sur les anomalies.
Prometheus et Grafana sont compatibles avec les applications conteneurisées, en particulier dans les environnements Kubernetes. Ils peuvent également gérer des charges de travail en dehors de Kubernetes pour plus de flexibilité. Ce sont tous deux des outils open-source qui donnent aux développeurs le contrôle sur la mise en œuvre. Il n'y a pas de coût de licence, ce qui aide les équipes qui ne peuvent pas se permettre des solutions coûteuses et puissantes.
En combinant Prometheus et Grafana, votre équipe obtient des informations utiles sur le système pour optimiser les performances, suivre les erreurs et aider les processus de dépannage.
Comment déployer Prometheus et Grafana sur AWS EKS en utilisant Helm
Prérequis
Pour ce projet, nous utiliserons une instance EC2 avec le système d'exploitation Ubuntu 22.04. Si vous utilisez Windows ou un Mac, connectez-vous à AWS pour créer votre machine virtuelle.
Voici ce dont vous aurez besoin d'autre :
1. Configuration du compte AWS avec des clés d'accès et des clés secrètes
2. Connaissance de Kubernetes
3. Installation de l'AWS CLI pour le serveur virtuel
Getting Started
Commençons par configurer un cluster EKS sur un serveur virtuel et installer les outils nécessaires sur le serveur. Ensuite, nous déployerons nos outils de surveillance, Prometheus et Grafana, en utilisant les graphiques Helm. Enfin, nous déployerons une application web NGINX sur Kubernetes et utiliserons Grafana pour visualiser les performances des pods et l'utilisation des ressources du cluster.
Étape 1 : Installer AWS CLI, eksctl, kubectl et Helm
AWS CLI est un outil qui permet aux utilisateurs d'interagir avec les services AWS en utilisant l'interface de ligne de commande. Il simplifie la gestion des ressources cloud et permet aux administrateurs de configurer les services AWS.
Ici, nous installerons AWS CLI sur notre serveur pour pouvoir créer des ressources Kubernetes.
Sur votre serveur, exécutez les commandes suivantes :
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
sudo apt install unzip
unzip awscliv2.zip
sudo ./aws/install
Vérifiez l'installation en exécutant ce qui suit :
aws --version
Après l'installation, configurez l'AWS CLI avec vos identifiants en utilisant la commande suivante :
aws configure
Vous serez invité à entrer votre ID de clé d'accès AWS, votre clé d'accès secrète, le nom de la région par défaut et le format de sortie par défaut.
Ensuite, nous devons installer eksctl. eksctl est un outil de ligne de commande qui simplifie la création et la gestion des clusters Kubernetes sur AWS. Il vous aide à configurer, définir et maintenir des clusters et vous permet de gérer les clusters plus efficacement.
Cet outil élimine les complexités de la configuration d'un cluster de qualité production, vous aidant, vous et vos administrateurs, à vous concentrer uniquement sur le développement et le déploiement d'applications.
Pour configurer eksctl sur votre machine, téléchargez la dernière version en utilisant la commande suivante :
# pour les systèmes ARM, définissez ARCH sur : arm64, armv6 ou armv7
ARCH=amd64
PLATFORM=$(uname -s)_$ARCH
curl -sLO "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_$PLATFORM.tar.gz"
# (Facultatif) Vérifiez la somme de contrôle
curl -sL "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_checksums.txt" | grep $PLATFORM | sha256sum --check
tar -xzf eksctl_$PLATFORM.tar.gz -C /tmp && rm eksctl_$PLATFORM.tar.gz
sudo mv /tmp/eksctl /usr/local/bin
Exécutez eksctl version pour confirmer son installation réussie et la version téléchargée.
eksctl version # 0.198.0
Ensuite, nous exécuterons Kubectl qui est une interface de ligne de commande pour gérer et interagir avec les clusters Kubernetes. Il permet aux utilisateurs de déployer et de gérer des applications dans un environnement Kubernetes.
Avec Kubectl, vous pouvez effectuer diverses opérations cruciales telles que la mise à l'échelle, les déploiements, l'inspection de l'état du cluster et la gestion du réseau.
Pour installer kubectl, exécutez les commandes suivantes :
curl -LO "https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin
Exécutez kubectl sur votre ligne de commande pour confirmer qu'il a été installé avec succès :
kubectl version
# client version: 0.198.0
# Kustomize Versionv: 5.4.2
# Server Version: v1.30.7-eks-56e63d8
Enfin, nous installerons Helm qui est un gestionnaire de paquets Kubernetes qui simplifie les déploiements et la gestion des applications dans Kubernetes. Il utilise des charts pour définir les ressources Kubernetes dans une collection de fichiers, gère la mise en template et la versioning, et facilite le déploiement des applications.
Ici, nous installerons le gestionnaire de paquets Helm sur notre machine virtuelle pour nos déploiements de cluster. Cela télécharge le script d'installation et l'enregistre dans le fichier get_helm.sh.
Ensuite, le fichier est défini comme exécutable, ce qui permet uniquement à l'utilisateur de l'exécuter. Enfin, le script est exécuté en utilisant la commande ./get_helm.sh.
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
Étape 2 : Créer un cluster Kubernetes
Ensuite, nous devons créer notre cluster Kubernetes dans AWS avec la commande eksctl. Nous pouvons faire cela avec la commande suivante :
eksctl create cluster --name my-prac-cluster-1 --version 1.30 --region us-east-1 --nodegroup-name worker-nodes --node-type t2.medium --nodes 2 --nodes-min 2 --nodes-max 3
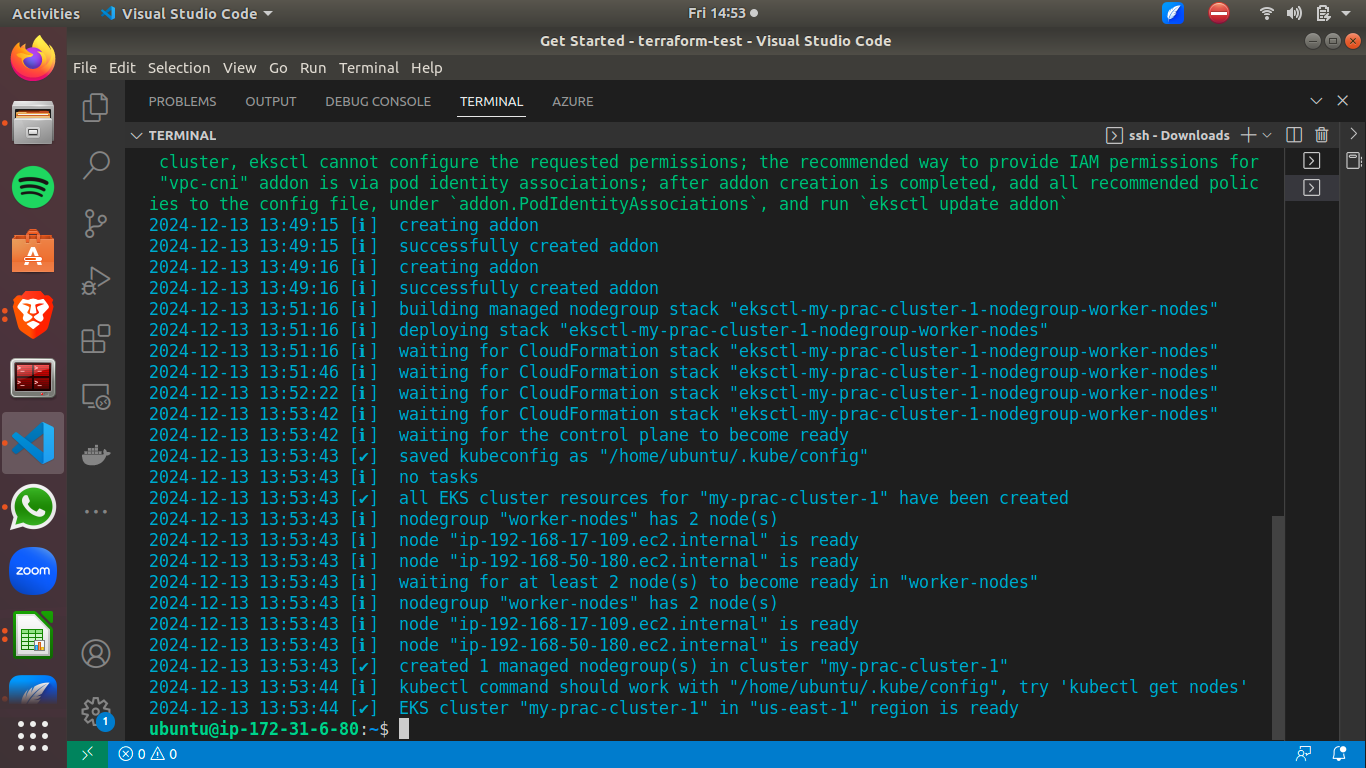
Décomposons la commande :
--name my-prac-cluster-1: Cela spécifie le nom du cluster EKS qui sera créé. Dans ce cas, le cluster sera nommé my-prac-cluster-1.--version 1.30: Cela définit la version Kubernetes pour le cluster. Ici, la version sera la version 1.30.--region us-east-1: Cela spécifie la région AWS où le cluster sera provisionné sur AWS. Ici, elle est définie sur us-east-1.--nodegroup-name worker-nodes: Cela définit le nom des groupes de nœuds qui seront créés. Dans ce cas, il est nommé worker-nodes.--node-type t2.large: Cela définit le type d'instance pour les nœuds de travail dans lenode-group.--nodes 2: Cela définit le nombre souhaité de nœuds de travail dans le groupe de nœuds.--nodes-min 2: Cela définit le nombre minimum de nœuds de travail qui doivent être maintenus dans le groupe de nœuds à 2.--nodes-max 3: Cela définit le nombre maximum de nœuds de travail autorisés dans le groupe de nœuds et le définit à 3.
Une fois le cluster opérationnel, exécutez la commande kubectl get nodes pour vous assurer que le cluster est configuré correctement.
Étape 3 : Installer le serveur de métriques
Le serveur de métriques est un composant qui collecte les données de ressources des Kubelets sur chaque nœud du cluster. Cela inclut les métriques telles que l'utilisation du CPU, de la mémoire et du réseau, auxquelles Prometheus peut accéder. Le serveur fournit une source unique de vérité pour les données de ressources et est facile à déployer et à utiliser.
Exécutez le script suivant pour installer le serveur de métriques :
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
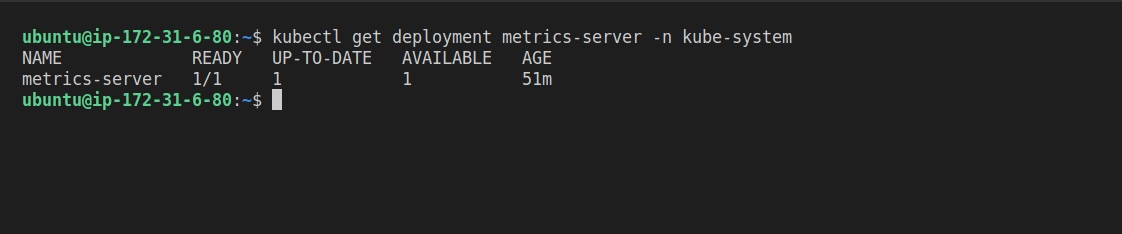
Pour vérifier l'installation, exécutez la commande suivante :
kubectl get deployment metrics-server -n kube-system
Étape 4 : Installer le fournisseur d'identité IAM OIDC et le pilote CSI Amazon EBS
Le fournisseur OpenID connect IAM permet à Kubernetes d'accéder aux ressources AWS au sein du cluster. Ici, nous avons besoin de volumes EBS pour créer un stockage persistant pour les pods Prometheus.
Exécutez les commandes suivantes pour créer le fournisseur OIDC IAM :
eksctl utils associate-iam-oidc-provider --cluster my-prac-cluster-1 --approve
Ensuite, nous créerons le pilote CSI Amazon EBS qui fournira des permissions au cluster pour accéder aux volumes EBS. Remplacez le nom de cluster "my-cluster" par le nom de votre cluster.
eksctl create iamserviceaccount \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster my-prac-cluster-1 \
--role-name AmazonEKS_EBS_CSI_DriverRole \
--role-only \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve
Maintenant, nous devons ajouter l'addon AWS EBS Driver au cluster en utilisant les commandes suivantes :
eksctl create addon --name aws-ebs-csi-driver --cluster <cluster_name> --service-account-role-arn arn:aws:iam::<AWS_ACCOUNT_ID>:role/AmazonEKS_EBS_CSI_DriverRole --force
L'ajout du pilote CSI AWS EBS à votre cluster Kubernetes permet au cluster de créer et de gérer dynamiquement des volumes EBS pour le stockage persistant au sein du cluster. Puisque notre installation de Prometheus a besoin de volumes persistants, cet add-on permettra au cluster de créer des volumes EBS pour persister les données.
Maintenant, notre future installation de Prometheus créera des volumes EBS pour le stockage persistant.
Étape 5 : Installer Prometheus et Grafana.
Pour installer Prometheus et Grafana, nous devons ajouter les graphiques Helm Stable pour le client local.
Exécutez la commande suivante :
helm repo add stable https://charts.helm.sh/stable
Ensuite, nous ajouterons le dépôt Helm de Prometheus :
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
Nous utiliserons la version de la communauté Prometheus car elle est bien maintenue par la communauté Prometheus. Elle offre des mises à jour plus rapides et des améliorations continues pour différents environnements Kubernetes.
Ensuite, créez l'espace de noms Prometheus :
kubectl create namespace prometheus
Installez Prometheus et Grafana via le chart Helm kube-prometheus-stack :
helm install stable prometheus-community/kube-prometheus-stack -n prometheus
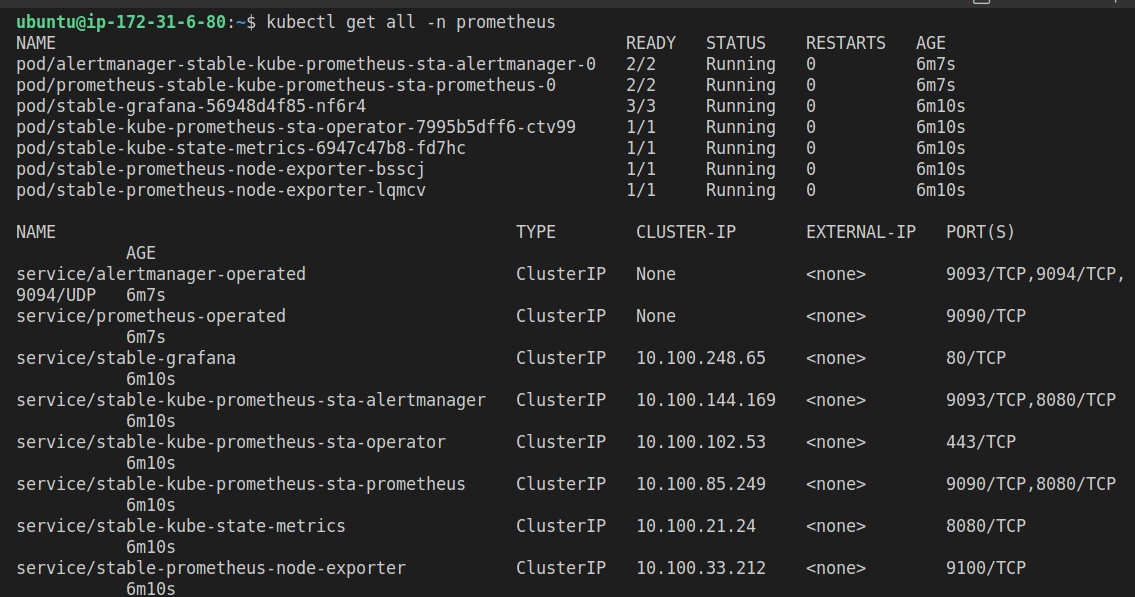
Une fois cela terminé, vérifiez que le déploiement et le service Prometheus sont installés en utilisant la commande suivante :
kubectl get all -n prometheus
À ce stade, vous devez changer le type de service de ClusterIP à LoadBalancer dans le fichier de manifeste. Nous pouvons mettre à jour le fichier en exécutant la commande suivante :
kubectl edit svc stable-kube-prometheus-sta-prometheus -n prometheus
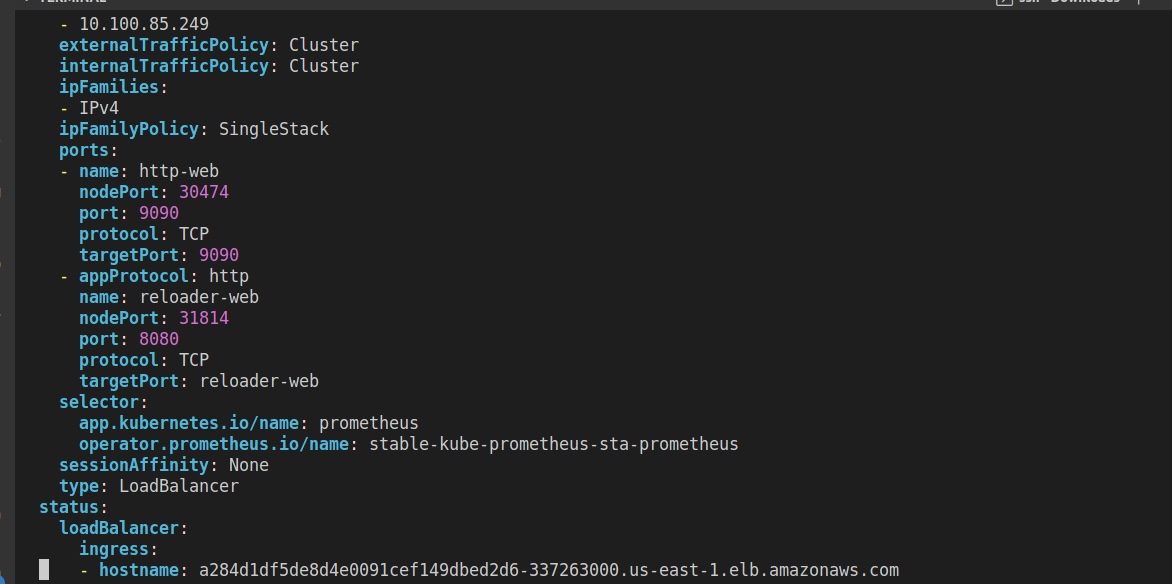
Après la mise à jour, une URL de LoadBalancer sera générée pour vous permettre d'accéder à votre tableau de bord Prometheus.
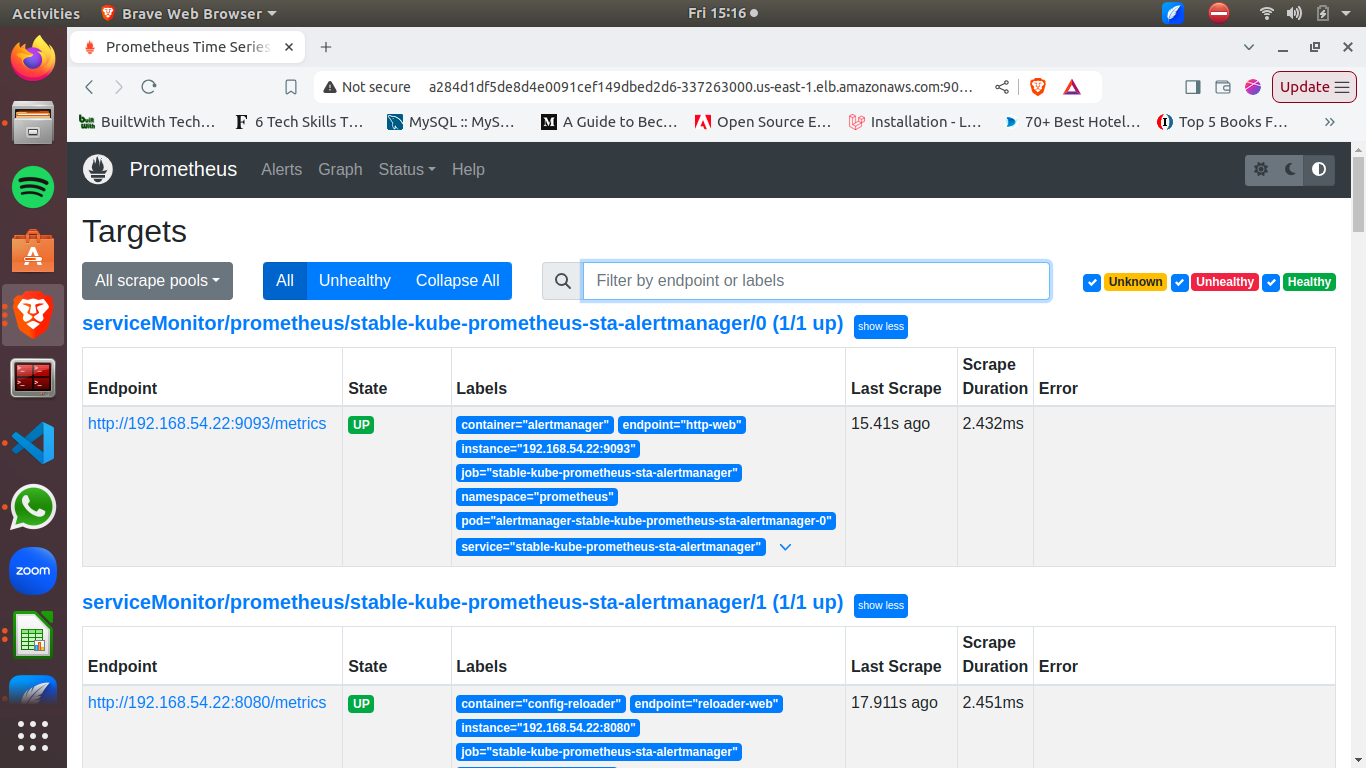
Ensuite, nous passerons à Grafana. Changez le fichier SVC de Grafana pour créer un LoadBalancer et l'exposer au public en utilisant la commande suivante :
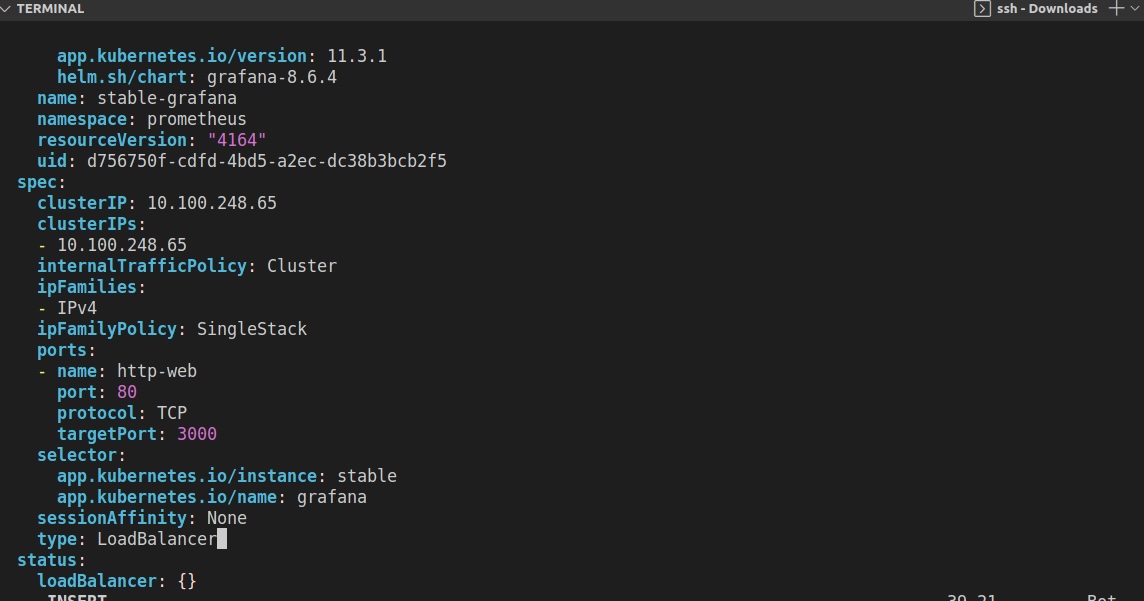
kubectl edit svc stable-grafana -n prometheus
Ensuite, nous mettrons à jour le fichier SVC de Grafana en changeant le type de service de ClusterIP à LoadBalancer pour l'exposer au public en utilisant la commande suivante :
kubectl edit svc stable-grafana -n prometheus
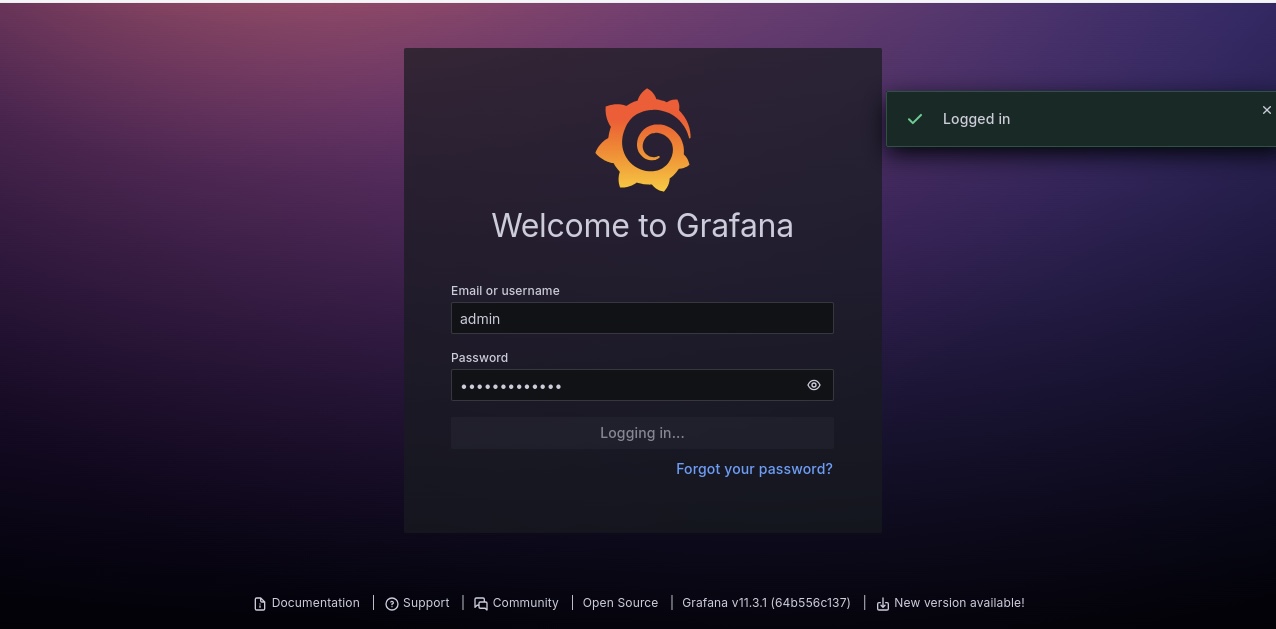
Une fois les paramètres enregistrés, vous pouvez utiliser le lien LoadBalancer pour accéder à votre tableau de bord Grafana depuis le navigateur. Le nom d'utilisateur est admin. Pour obtenir le mot de passe de connexion imprimé dans le terminal, exécutez la commande suivante :
kubectl get secret --namespace prometheus stable-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
Après vous être connecté avec succès au tableau de bord Grafana, la première étape consiste à créer une source de données qui fournira les métriques pour la visualisation Grafana.
Allez à Ajouter votre première source de données et choisissez Prometheus comme source de données.
Insérez l'URL de Prometheus, et cliquez sur "Enregistrer et tester". Il devrait indiquer succès si Grafana interroge l'URL de Prometheus avec succès.
L'étape suivante consiste à créer un tableau de bord que notre visualisation Grafana utilisera pour afficher les métriques de nos pods. Pour ce faire, cliquez sur "Tableaux de bord" puis sur "Ajouter une visualisation".
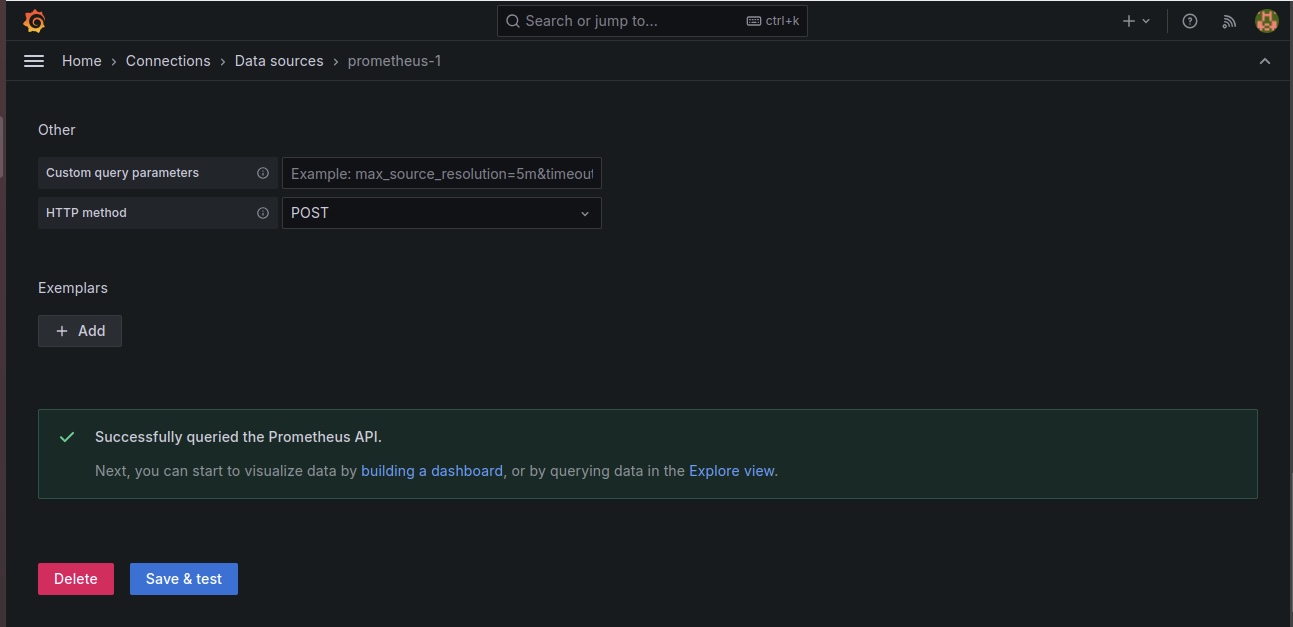
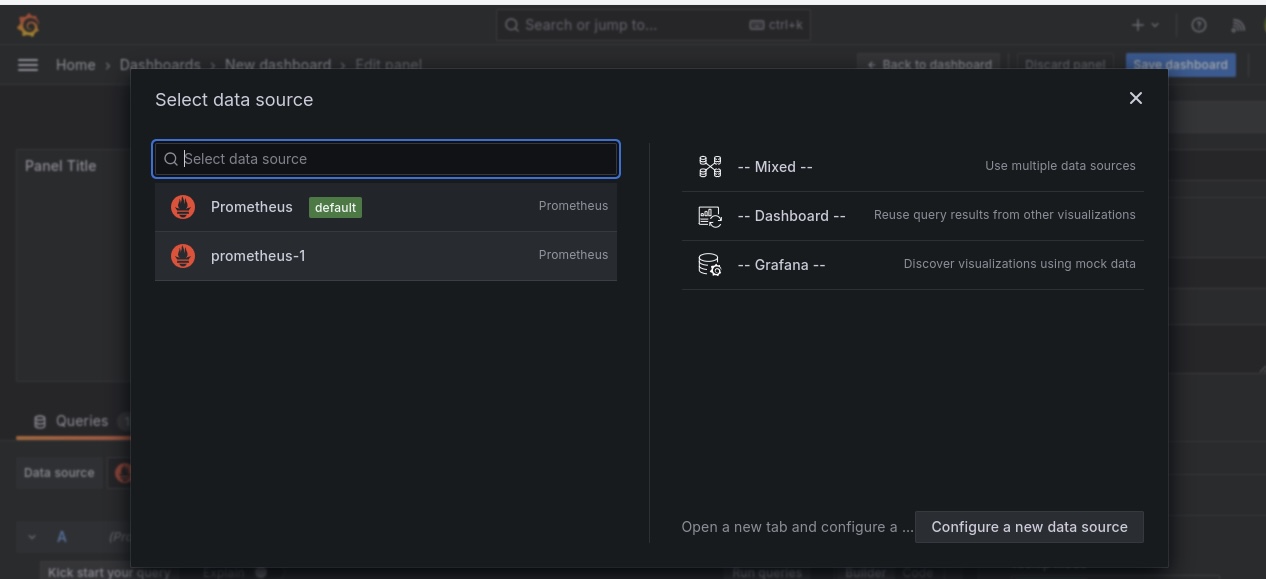
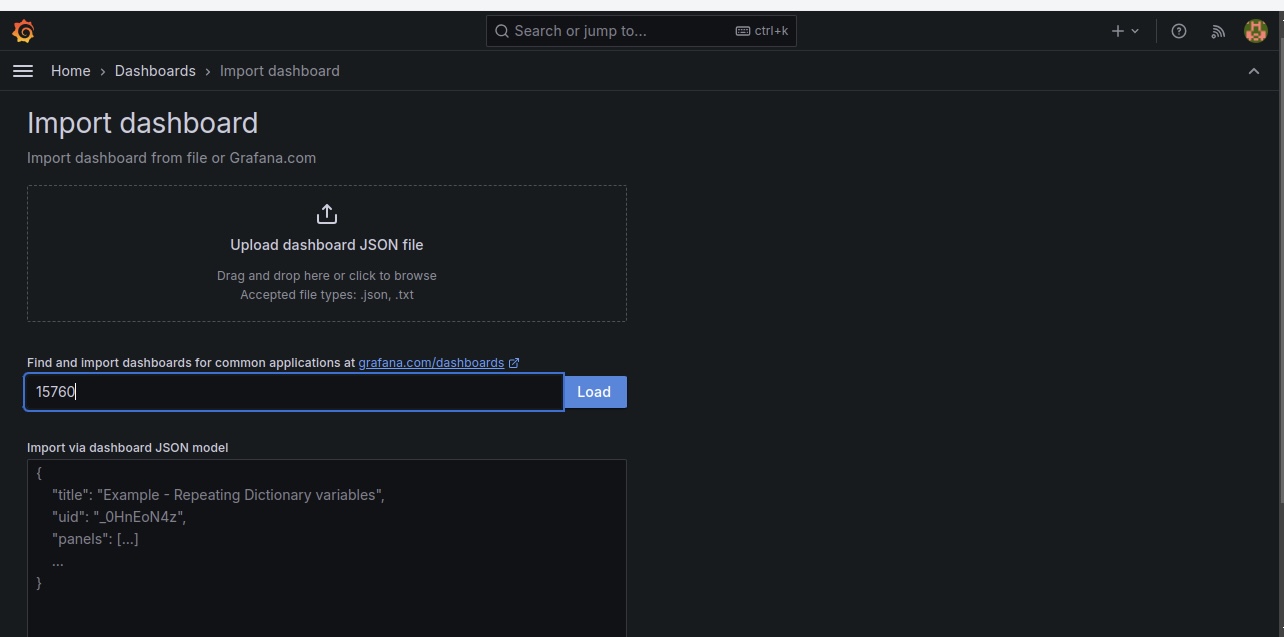
Vous serez redirigé vers un environnement où vous devrez importer un tableau de bord. Sélectionnez la source de données comme "Prometheus-1" et utilisez le code "15760" pour importer le tableau de bord Node Exporter pour visualiser nos pods.
Cliquez sur Charger après avoir importé le tableau de bord, et vous verrez votre nouveau tableau de bord.
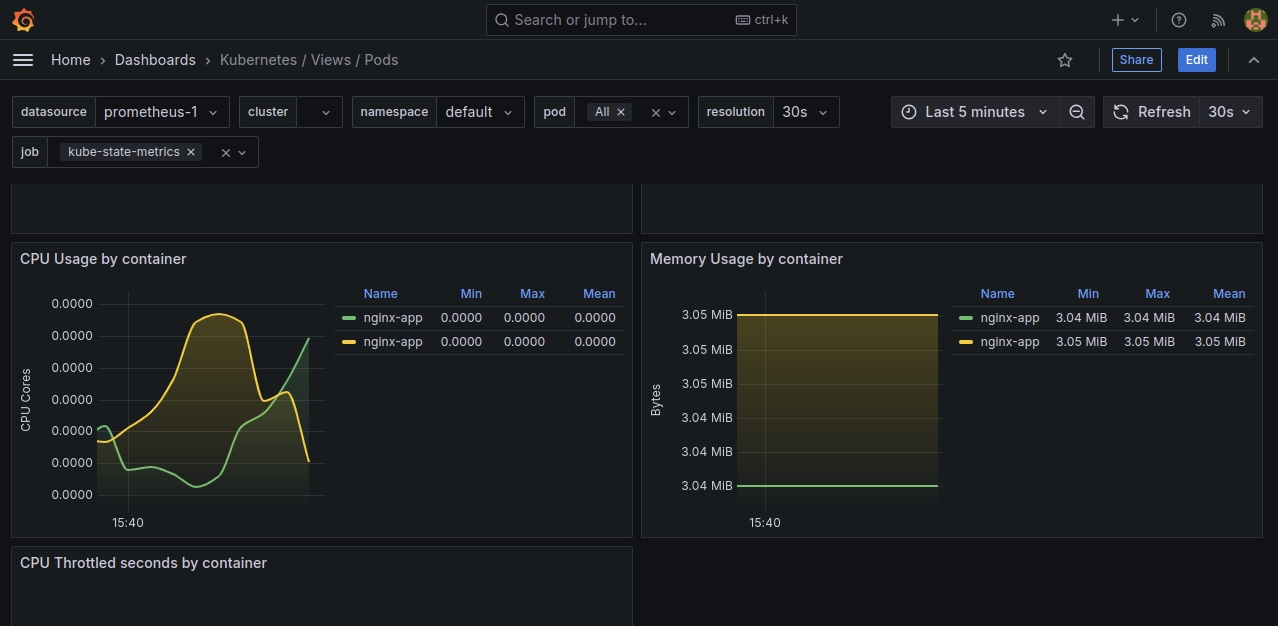
Ici, nous pouvons voir toutes les données du cluster, l'utilisation du CPU et de la RAM, et les données concernant les pods dans un espace de noms spécifié.
Étape 6 : Déployer une application sur Kubernetes pour la surveiller sur Grafana.
Enfin, nous allons déployer un conteneur NGINX dans notre cluster EKS pour le surveiller en utilisant Grafana. Nous devons créer un fichier de déploiement et de service Yaml.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-app
spec:
replicas: 2
selector:
matchLabels:
app: nginx-app
template:
metadata:
labels:
app: nginx-app
spec:
containers:
- name: nginx-app
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-app
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80
selector:
app: nginx-app
Pour déployer l'application Node.js sur le cluster Kubernetes, utilisez la commande kubectl suivante. Vérifiez le déploiement en exécutant la commande kubectl suivante :
kubectl apply -f deployment.yml
kubectl get deployment
kubectl get pods
Cliquez sur l'URL du load balancer pour voir votre application sur votre navigateur :
Rafraîchissons notre tableau de bord Grafana pour voir notre application web NGINX dans Grafana.
Étape 7 : Supprimer le cluster
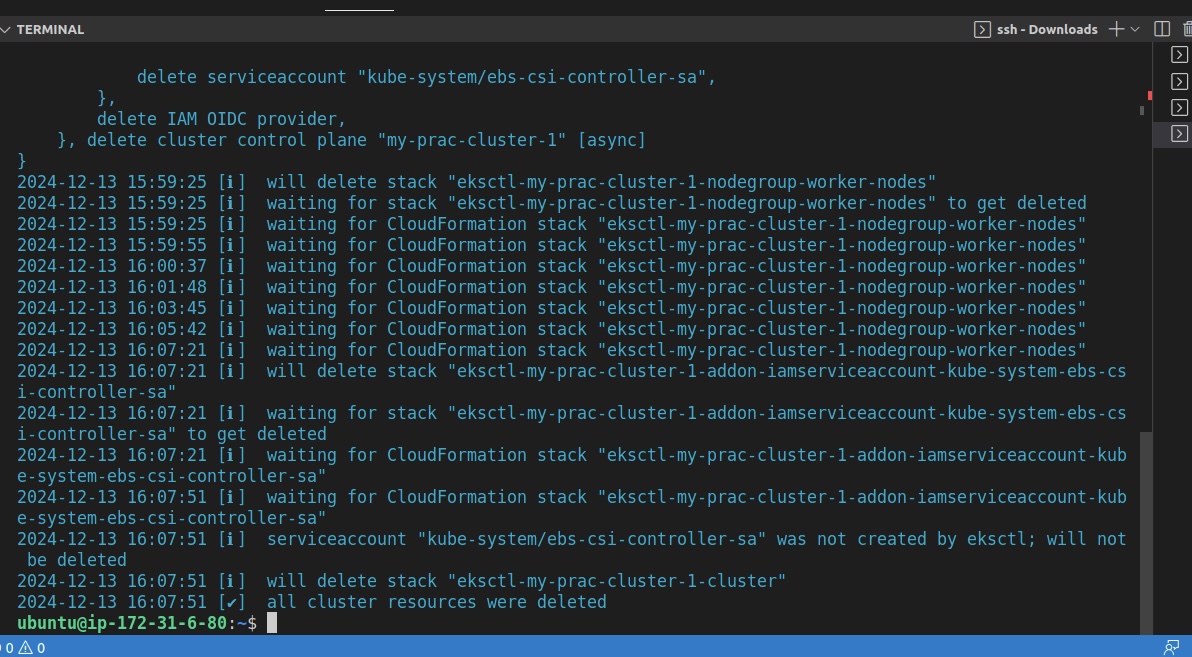
Maintenant que tout est configuré, nous pouvons supprimer notre cluster Kubernetes pour éviter des coûts supplémentaires. Exécutez les commandes suivantes pour ce faire :
eksctl delete cluster my-prac-cluster-1 --region us-east-1
Conclusion
Cet article enseigne la théorie derrière la surveillance et l'observabilité et met en évidence les rôles de Prometheus et Grafana dans ces processus.
Nous avons passé en revue un déploiement pratique de Prometheus et Grafana sur un cluster EKS et une application web pour illustrer comment ils peuvent être surveillés efficacement en utilisant Grafana.
En tirant parti de ces outils, les administrateurs peuvent bénéficier d'une visibilité en temps réel sur leur infrastructure Kubernetes, identifier facilement les goulots d'étranglement de performance et prendre des décisions en toute confiance pour améliorer les performances et la fiabilité des applications.