


Article original : How to secure your Linux web server
Construire un serveur LAMP et le configurer correctement avec une gestion fiable des données, un domaine et un certificat TLS n'est que la moitié de la bataille. Vous devrez également vous assurer que votre infrastructure est protégée contre les nombreuses menaces effrayantes d'Internet.
Dans cet article — qui est un extrait du chapitre 9 de mon livre Manning, Linux in Action — j'explorerai la sécurité des sites web grâce à l'utilisation appropriée des groupes système, de l'isolement des processus et des audits réguliers de vos ressources système. Ce n'est pas toute l'histoire (mon livre Linux in Action couvre des outils supplémentaires comme l'installation de certificats TLS et le travail avec SELinux), mais c'est un excellent point de départ.
Groupes système et le principe du moindre privilège
Les développeurs que vous soutenez ont (enfin) réalisé qu'ils devaient restreindre l'accès public aux données et aux fichiers de configuration vivant sur le serveur d'application tout en permettant l'accès à diverses équipes de développement et informatiques.
La première partie de la solution est les groupes. Un groupe est un objet système — très similaire à un utilisateur — sauf que personne ne se connectera jamais au système en tant que groupe. La puissance des groupes réside dans la manière dont ils peuvent, comme les utilisateurs, être « assignés » à des fichiers ou des répertoires, permettant à tous les membres du groupe de partager les pouvoirs du groupe. Cela est illustré dans la figure.
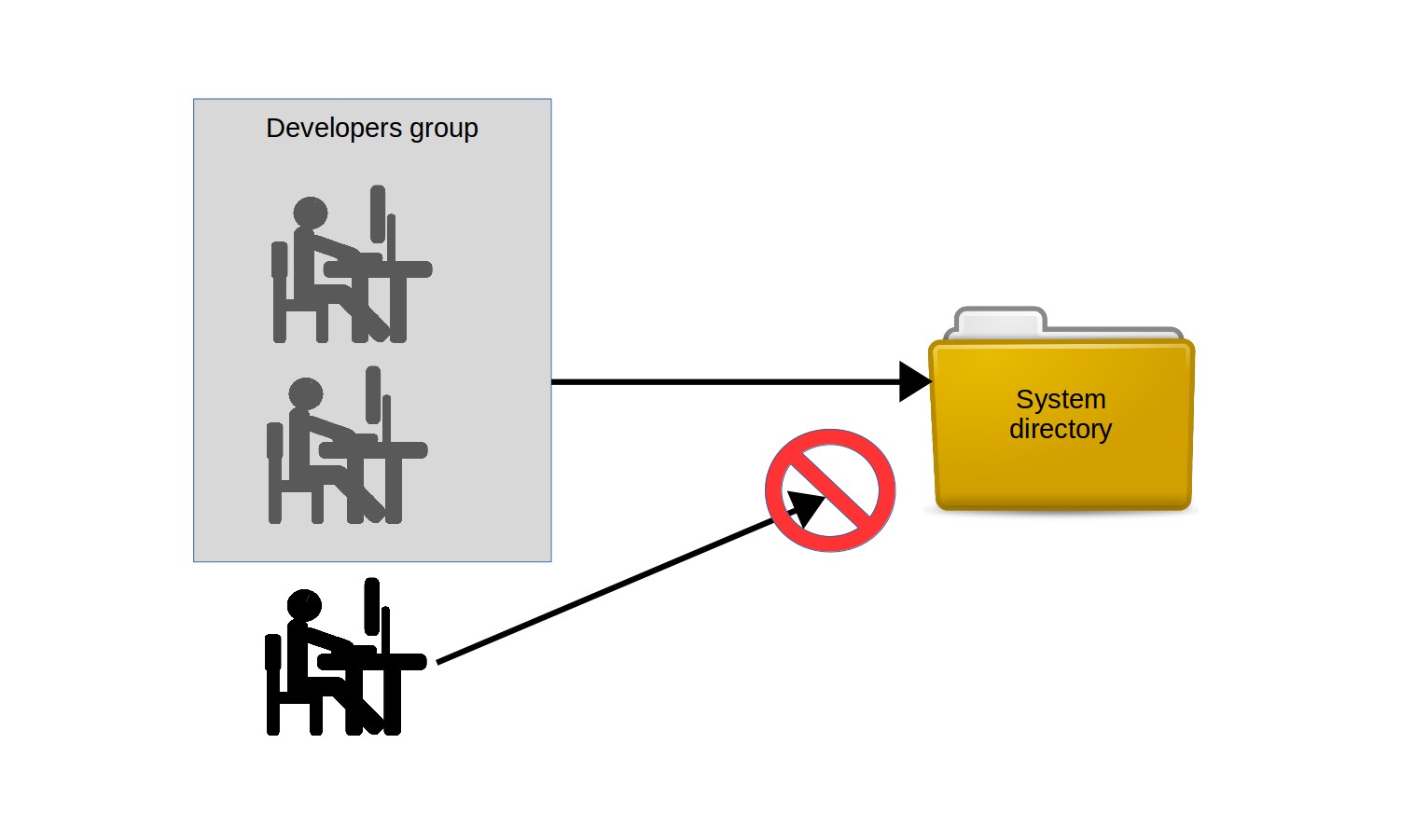 Les développeurs qui sont membres du groupe Développeurs peuvent se voir accorder l'accès à un répertoire particulier, contrairement à ceux qui ne font pas partie du groupe.
Les développeurs qui sont membres du groupe Développeurs peuvent se voir accorder l'accès à un répertoire particulier, contrairement à ceux qui ne font pas partie du groupe.
Essayez cela vous-même : utilisez un éditeur de texte pour créer un nouveau fichier. Ajoutez un texte « Hello world » pour pouvoir facilement savoir quand vous pouvez y accéder avec succès. Modifiez ensuite ses permissions en utilisant chmod 770 afin que le propriétaire et le groupe du fichier aient tous les droits sur le fichier, mais que les autres ne puissent même pas le lire.
nano datafile.txt
chmod 770 datafile.txt
Si votre système n'a pas déjà un utilisateur supplémentaire en plus de votre compte, créez-en un en utilisant soit adduser — la méthode Debian/Ubuntu — ou useradd si vous êtes sur CentOS. useradd fonctionnera également sur Ubuntu.
La commande useradd (par opposition à adduser de Debian) vous oblige à générer un mot de passe utilisateur séparément :
# useradd otheruser
# passwd otheruser
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Utilisez su pour basculer vers votre nouvel utilisateur. Une fois que vous avez entré le mot de passe de l'utilisateur, toutes les commandes que vous exécutez seront exécutées en tant que cet utilisateur. Vous travaillerez uniquement avec l'autorité de cet utilisateur : ni plus ni moins. Si vous essayez de lire le fichier datafile.txt (en utilisant cat), vous n'aurez pas de chance puisque, comme vous vous en souvenez, les autres se sont vu refuser l'accès en lecture. Lorsque vous avez terminé, tapez exit pour quitter le shell du nouvel utilisateur et revenir à votre shell d'origine.
$ su otheruser
Password:
$ cat /home/ubuntu/datafile.txt
cat: /home/ubuntu/datafile.txt: Permission denied
$ exit
Tout cela est attendu et facile à comprendre. Et, comme vous l'avez vu, ne pas pouvoir lire le fichier appartenant à un autre lecteur peut parfois poser problème. Voyons ce que nous pouvons faire à ce sujet en associant le fichier à un groupe, puis en configurant correctement les permissions du fichier.
Créez un nouveau groupe que vous pouvez utiliser pour gérer les données de votre application, puis modifiez les propriétés de votre fichier de données en utilisant chown. L'argument ubuntu:app-data-group laisse la propriété du fichier entre les mains de l'utilisateur ubuntu, mais change son groupe pour votre nouveau app-data-group.
groupadd app-data-group
chown ubuntu:app-data-group datafile.txt
Exécutez ls avec une sortie « longue » contre le fichier pour voir ses nouvelles permissions et son statut. Notez que, comme prévu, ubuntu est le propriétaire du fichier et app-data-group est son groupe.
$ ls -l | grep datafile.txt
-rwxrwx --- 1 ubuntu app-data-group 6 Aug 9 22:43 datafile.txt
Vous pouvez utiliser usermod pour ajouter votre utilisateur au groupe app-data-group, puis, une fois de plus, su pour basculer vers un shell déployant le compte de l'autre utilisateur. Cette fois, même si les permissions du fichier verrouillent les autres — et vous êtes définitivement en train d'agir en tant qu'utilisateur « autre » maintenant — vous devriez pouvoir le lire grâce à votre appartenance au groupe.
# usermod -aG app-data-group otheruser
$ su otheruser
$ cat datafile.txt
Hello World
Utilisez su pour basculer entre les comptes utilisateurs. Ce sont les contenus de mon fichier datafile.txt. Ce type d'organisation est la manière correcte et efficace de gérer de nombreux problèmes de permissions compliqués qui surgiront sur un système multi-utilisateurs.
En fait, non seulement il est utilisé pour donner aux utilisateurs individuels l'accès dont ils ont besoin, mais de nombreux processus système ne pourraient pas faire leur travail sans des appartenances à des groupes spéciaux. Jetez un coup d'œil rapide au fichier /etc/group et notez combien de processus système ont leurs propres groupes.
Un listing partiel du contenu du fichier /etc/group :
$ cat /etc/group
root:x:0:
daemon:x:1:
bin:x:2:
sys:x:3:
adm:x:4:syslog
tty:x:5:
disk:x:6:
lp:x:7:
mail:x:8:
news:x:9:
uucp:x:10:
man:x:12:
proxy:x:13:
[]
Isolation des processus dans des conteneurs
Vous craignez que les multiples services que vous avez en cours d'exécution sur un seul serveur soient tous en danger si un service est compromis ? Une façon de limiter les dégâts que des utilisateurs négligents ou malveillants peuvent causer est d'isoler les ressources et les processus du système. Ainsi, même si quelqu'un pourrait vouloir étendre sa portée au-delà d'une limite définie, il n'aura pas d'accès physique.
L'ancienne approche du problème consistait à provisionner une machine physique séparée pour chaque service. Mais la virtualisation peut rendre beaucoup plus facile — et plus abordable — la construction d'une infrastructure « cloisonnée ».
Cette architecture est souvent appelée microservices et vous amènerait à lancer plusieurs conteneurs, l'un exécutant peut-être uniquement une base de données, un autre Apache, et un troisième contenant des fichiers multimédias qui pourraient être intégrés dans vos pages web. En plus des nombreux avantages de performance et d'efficacité associés aux architectures de microservices, cela peut grandement réduire l'exposition aux risques de chaque composant individuel.
Par « conteneurs », je ne veux pas nécessairement dire ceux de la persuasion LXC. Ces jours-ci, pour ce type de déploiement, les conteneurs Docker sont beaucoup plus populaires. Si vous êtes intéressé à en apprendre davantage sur Docker, consultez mes cours Pluralsight qui abordent le sujet.
Recherche de valeurs d'ID utilisateur dangereuses
Bien que tout utilisateur admin puisse temporairement assumer l'autorité root en utilisant sudo, seul root est réellement root. Comme vous l'avez déjà vu, il n'est pas sûr d'effectuer des fonctions régulières en tant que root. Mais cela peut arriver — que ce soit par accident innocent ou par manipulation malveillante — qu'un utilisateur régulier puisse obtenir des droits admin à temps plein.
La bonne nouvelle est qu'il est facile de repérer les imposteurs : leurs numéros d'ID utilisateur et/ou groupe seront, comme root, zéro (0). Jetez un coup d'œil au fichier passwd dans /etc/. Ce fichier contient un enregistrement pour chaque compte utilisateur régulier et système qui existe actuellement. Le premier champ contient le nom du compte (root et ubuntu dans ce cas) et le deuxième champ peut contenir un x à la place d'un mot de passe (qui, s'il existe, apparaîtra chiffré dans le fichier /etc/shadow). Mais les deux champs suivants contiennent les ID utilisateur et groupe. Dans le cas d'ubuntu dans cet exemple, les deux ID sont 1000. Et, comme vous pouvez le voir, root a des zéros.
$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
[]
ubuntu:x:1000:1000::/home/ubuntu:/bin/bash
Si vous voyez un jour un utilisateur régulier avec un ID utilisateur ou groupe de 0, alors vous savez qu'il se passe quelque chose de mauvais et vous devriez vous mettre au travail pour le corriger. Le moyen rapide et facile de repérer un problème est d'exécuter cette commande awk contre le fichier passwd, qui imprimera toute ligne dont le troisième champ ne contient qu'un 0. Dans ce cas, à mon grand soulagement, le seul résultat était root. Vous pouvez l'exécuter une deuxième fois en substituant $4 à $3 pour capturer le champ ID de groupe.
$ awk -F: '($3 == "0") {print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
Audit des ressources système
Plus vous avez de choses en cours d'exécution, plus les chances que quelque chose se casse sont grandes. Il est donc logique que vous souhaitiez garder une trace de ce qui est en cours d'exécution. Cela s'appliquera aux ports réseau (s'ils sont « ouverts », alors, par définition, il doit y avoir un moyen d'entrer), aux services (s'ils sont actifs, alors les gens peuvent les exécuter) et aux logiciels installés (s'ils sont installés, ils peuvent être exécutés).
Pour que les audits soient utiles, vous devrez vous souvenir de les exécuter de temps en temps. Comme vous savez que vous allez oublier, vous serez beaucoup mieux loti en incorporant vos outils d'audit dans un script qui non seulement s'exécute régulièrement, mais idéalement, analyse également les résultats pour les rendre plus lisibles.
Ici, cependant, je me concentrerai sur la présentation de trois outils d'audit clés pour vous aider à scanner les ports ouverts, les services actifs et les packages logiciels inutiles. L'automatisation sera votre travail.
Scanning des ports ouverts
Un port est considéré comme « ouvert » s'il y a un processus en cours d'exécution sur l'hôte qui écoute sur ce port pour les requêtes. Garder un œil sur vos ports ouverts peut vous tenir informé de ce qui se passe vraiment avec votre serveur.
Vous savez déjà qu'un serveur web régulier aura probablement HTTP (80) et SSH (22) ouverts, donc cela ne devrait pas être une surprise de tomber sur ceux-ci. Mais vous voudrez vraiment vous concentrer sur d'autres résultats inattendus. netstat affichera les ports ouverts ainsi qu'une multitude d'informations sur la manière dont ils sont utilisés.
Dans cet exemple exécuté contre un serveur multi-usage assez typique, -n indique à netstat d'inclure les ports et adresses numériques. -l inclut uniquement les sockets en écoute, et -p ajoute l'ID de processus du programme en écoute. Naturellement, si vous voyez quelque chose, faites quelque chose.
# netstat -npl
Active Internet connections (only servers)
Proto Local Address Foreign Address State PID/Program name
tcp 127.0.0.1:3306 0.0.0.0:* LISTEN 403/mysqld
tcp 0.0.0.0:139 0.0.0.0:* LISTEN 270/smbd
tcp 0.0.0.0:22 0.0.0.0:* LISTEN 333/sshd
tcp 0.0.0.0:445 0.0.0.0:* LISTEN 270/smbd
tcp6 :::80 :::* LISTEN 417/apache2
[]
Ces dernières années, ss a commencé à remplacer netstat pour de nombreux usages. Juste au cas où vous vous retrouveriez à une fête un jour et que quelqu'un vous demande à propos de ss, cet exemple (qui liste toutes les connexions SSH établies) devrait vous donner suffisamment d'informations pour vous sauver d'une profonde embarrassment :
$ ss -o state established '( dport = :ssh or sport = :ssh )'
Netid Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp 0 0 10.0.3.1:39874 10.0.3.96:ssh
timer:(keepalive,18min,0)
Scanning des services actifs
Obtenir un instantané rapide des services gérés par systemd actuellement activés sur votre machine peut vous aider à repérer une activité qui ne devrait pas être là. systemctl peut lister tous les services existants, qui peuvent ensuite être réduits aux seuls résultats dont les descriptions incluent enabled. Cela ne retournera que les services actifs.
# systemctl list-unit-files --type=service --state=enabled
autovt@.service enabled
bind9.service enabled
cron.service enabled
dbus-org.freedesktop.thermald.service enabled
docker.service enabled
getty@.service enabled
haveged.service enabled
mysql.service enabled
networking.service enabled
resolvconf.service enabled
rsyslog.service enabled
ssh.service enabled
sshd.service enabled
syslog.service enabled
systemd-timesyncd.service enabled
thermald.service enabled
unattended-upgrades.service enabled
ureadahead.service enabled
Si vous trouvez quelque chose qui ne devrait pas être là, vous pouvez utiliser systemctl pour à la fois arrêter le service et vous assurer qu'il ne redémarre pas avec le prochain démarrage.
systemctl stop haveged
systemctl disable haveged
Il n'y a en fait rien de sombre et de sinistre à propos du service haveged que j'arrête dans cet exemple : c'est un outil très petit que j'installe souvent pour générer une activité système aléatoire en arrière-plan lorsque je crée des clés de chiffrement.
Recherche de logiciels installés
Quelqu'un ou quelque chose aurait-il pu installer un logiciel sur votre système sans que vous le sachiez ? Eh bien, comment le sauriez-vous si vous ne regardez pas ? yum list installed ou, sur Debian/Ubuntu, dpkg --list vous donnera tout le briefing, tandis que remove devrait supprimer tous les packages qui ne devraient pas être là.
yum list installed
yum remove packageName
Voici comment cela se passe sur Ubuntu :
dpkg --list
apt-get remove packageName
Il est également bon d'être conscient des changements apportés à vos fichiers de configuration système — ce que je couvre dans le chapitre 11.
_Cet article est un extrait de mon livre Manning « Linux in Action ». Il y a beaucoup plus de plaisir d'où cela vient, y compris un cours hybride appelé Linux in Motion qui est composé de plus de deux heures de vidéo et d'environ 40 % du texte de Linux in Action. Qui sait... Vous pourriez également apprécier mon récent Learn Amazon Web Services in a Month of Lunches._