

Article original : How to Bridge Stateful and Event-Sourced Systems
Par Jonathan Solórzano-Hamilton
Vous avez un nouveau système CQRS tout brillant, il est "dev complet", et vous êtes sur le point de commencer les tests d'intégration. Et le gorille de 800 livres qui dormait dans le coin pendant vos discussions de domaine se réveille.
Sans un seul regard à vos diagrammes de domaine complets, vos histoires utilisateur engageantes, vos maquettes d'interface utilisateur ou vos critères d'acceptation bien documentés, il traverse la "limite de contexte" en pointillés qui était censée le retenir.
Le gorille fait des ravages dans le bâtiment, brisant des entités, réduisant la valeur en décombres, déracinant des agrégats et détruisant généralement tout consensus sur le projet. Gorille, ton nom est Intégration Legacy.

Les systèmes legacy et l'intégration des processus peuvent couler un projet autrement parfaitement exécuté. C'est un problème de migraine monstrueux qui ne s'enseigne que dans l'école des coups durs. C'est aussi un problème que, en tant que développeur, vous rencontrerez dans votre carrière (si ce n'est déjà fait) lorsque vous commencerez à travailler avec des entreprises et des domaines suffisamment établis.
Bien sûr, si vous avez de la chance, vous n'avez pas encore commencé à coder — ou du moins, c'est encore tôt dans le processus — lorsque le gorille se réveille. Ou, si vous êtes intelligent, vous voyez le gorille se cacher sous l'abat-jour dans le coin et, en frottant les cicatrices de votre dernière rencontre, vous prévenez sa rampage inévitable en l'incorporant dans votre architecture dès le départ.
Travailler avec les systèmes legacy
En tant que directeur adjoint de l'architecture au bureau des systèmes d'information de recherche de l'UCLA, je suis responsable de combler de nombreuses lacunes de systèmes et de données. L'UCLA dispose d'un pipeline de plusieurs décennies de processus et de systèmes commerciaux legacy autour de la recherche qui entrent en conflit avec toute tentative de "disrupt" ces approches traditionnelles avec de nouvelles technologies.
Le plus redoutable, ce pipeline est bouché par l'occasionnel iceberg impénétrable de données legacy qui nécessite souvent un traitement en temps réel.

Dans mon bureau, nous avons été chargés de fournir une intégration à ces systèmes legacy à un rythme croissant. Nous augmentons également nos systèmes transactionnels sur mesure pour gérer les petits processus commerciaux.
Pour nos propres systèmes, nous suivons généralement le modèle microservice. Nous incorporons plus de complexité, comme la conception pilotée par le domaine (DDD) et l'event-sourcing, lorsque cela est nécessaire. Notre principal défi pour ces systèmes est l'intégration legacy dans les systèmes de persistance d'état.
Aborder l'intégration
Je vais décrire notre approche dans les prochains paragraphes. C'est ainsi que nous avons abordé l'un des problèmes qui surviennent lors du pontage d'un système d'événements, en particulier un système d'événements hybride, à un système purement piloté par l'état.
Un principe clé que les implémenteurs oublient souvent est que l'event sourcing ne doit pas être utilisé partout. Cela selon Greg Young, qui est largement crédité d'avoir introduit le modèle d'architecture logicielle "event sourcing".
Dans nos systèmes, nous utilisons l'event sourcing pour répondre à des exigences spécifiquement ciblées. Parfois, cela entraîne le fait que nos applications ont un état qui peut résider en dehors du flux d'événements. De plus, certains de nos déclencheurs d'événements proviennent de changements d'état du système source peu fiables. Cela demanderait beaucoup de correction d'événements post-hoc et de "rembobinage-relecture" pour corriger si nous devions dépendre uniquement du flux d'événements.
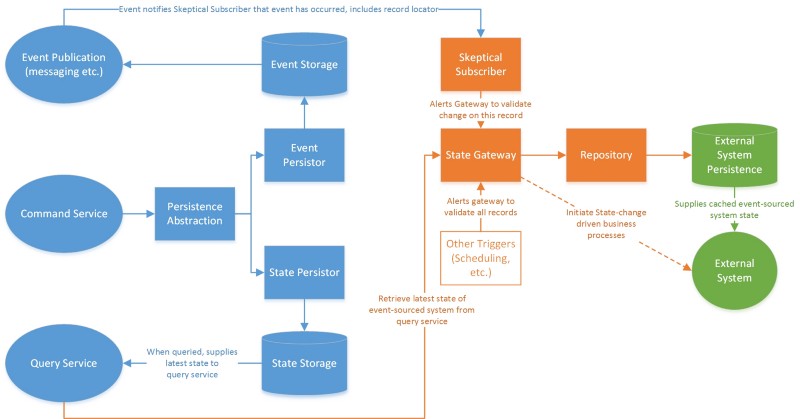
Une solution sceptique
La solution que nous avons trouvée pour cela est celle que j'appelle le "Skeptical Subscriber". Le Skeptical Subscriber aborde le problème de "l'irréliabilité" dans la partie événementielle du système, au moins du point de vue de la machine d'état legacy. Il aborde également les systèmes qui peuvent manquer la génération d'événements en raison de problèmes de données legacy externes :
- La source d'événements peut générer des événements qui ne résultent pas en des changements d'état pertinents pour la machine d'état legacy. De son point de vue, ce sont des événements "faux positifs"
- La source d'événements peut ne pas générer d'événements pour les changements d'état qui sont pertinents pour la machine d'état legacy. De son point de vue, ce sont des événements "manqués" ou "sautés"
- Les événements peuvent ne pas être générés du tout en raison de bugs ou d'erreurs dans la source originale de l'événement. Cela se produit particulièrement dans les flux extract-transform-load (ETL) à partir de dépôts de données legacy. De n'importe quel point de vue, ce sont des événements "sautés" authentiques
L'approche du Skeptical Subscriber aborde ces préoccupations en restant méfiant envers le flux d'événements. Il traite le flux d'événements comme un possible déclencheur ou notification que l'état a changé, mais il accepte également d'autres déclencheurs possibles. Il se méfie également du fait que les notifications de changement d'état soient correctes.
Une fois qu'il est notifié que l'état peut avoir changé, l'abonné notifie une passerelle d'état qui interroge l'état du système basé sur les événements.
Cette passerelle d'état évalue l'état par rapport au dernier état connu (tel que le système abonné le connaissait).
Si le changement est pertinent, il met alors à jour l'état du système abonné et, si nécessaire, initie les processus commerciaux du système abonné.
Certaines exigences
Pour utiliser cette approche, votre système abonné doit :
- Déjà persister, ou être capable de dériver de ce qu'il persiste, les attributs d'état qui l'intéressent à partir du système d'event sourcing
- Vous permettre de refaire comment vous injectez les données de changement d'état
Votre système d'event-sourcing doit :
- Fournir un service de requête qui représente de manière fiable l'état du système et inclut tous les attributs d'état requis par le système abonné
- Fournir suffisamment de données dans le flux d'événements pour localiser les enregistrements pertinents dans le service de requête
- Prendre en charge une requête "liste" ou autre requête par lots à partir du service de requête
Le Skeptical Subscriber que vous implémentez doit inclure :
- Une passerelle d'état qui peut interroger le service de requête pour un enregistrement particulier (piloté par événement) ou pour une liste d'enregistrements (autre déclencheur, pour rattraper les événements "manqués")
- La passerelle d'état doit inclure une logique de comparaison de domaine à partir du contexte du système abonné qui écarte les enregistrements si, dans la mesure où le domaine abonné est concerné, ils n'ont pas changé
- Une implémentation d'abonnement aux événements pour appeler la passerelle par enregistrement à partir des événements
- La capacité de mettre à jour la couche de persistance du système abonné avec les changements (afin qu'il ne mette pas à jour le même enregistrement la prochaine fois), par exemple via un dépôt
Le Skeptical Subscriber peut également implémenter l'initiation des processus commerciaux dans le système abonné.
S'il est purement piloté par l'état, cela peut se faire en persistant de nouveaux enregistrements de processus pour lancer les processus concomitants. Sinon, il peut appeler n'importe quelle API de processus exposée.
Si vous initiez ces processus commerciaux, vous devez également implémenter un verrouillage dans la passerelle afin de ne pas doubler l'initiation du processus si un déclencheur d'événement se produit pendant le processus ETL.
Résultats positifs
Il existe de nombreux autres défis associés à l'intégration des systèmes legacy, en particulier lors du passage entre des contextes basés sur les événements et des contextes étatiques. Ce modèle, cependant, nous aide à minimiser le fardeau technique associé à la maintenance des événements lors de la consommation de données legacy (et irrégulières).
Avant de suivre ce modèle, nous avions travaillé dans une approche strictement basée sur les événements. Nous avions perdu l'accès rapide aux opportunités de support offertes par la possession d'un état directement modifiable. Avec ce modèle, nous avons regagné ces opportunités. Lorsque le système legacy se comporte mal parce qu'il n'aime pas les événements qu'il reçoit, nous avons déplacé le fardeau de la modification du flux d'événements d'une manière ou d'une autre à une simple modification d'état.
Nous avons également ajouté une couche de couplage lâche pour isoler généralement le système abonné de l'exposition directe aux événements. Cela permet la redirection d'autres déclencheurs du système abonné.
Par exemple, un ETL legacy peut servir de déclencheur initial de la passerelle d'état jusqu'à ce que vous soyez prêt à passer à un flux d'événements. Et nous l'avons fait sans surcompliquer le service CQRS en implémentant l'abonné sceptique interstitiel en tant qu'entité indépendante.
Voici un conseil pro pour les scientifiques des données et les ingénieurs qui les servent : si vous implémentez la persistance polyglotte dans le dépôt abonné, vous pouvez également construire un magasin de documents qui est déjà automatiquement filtré pour les changements de données qui reflètent un processus commercial significatif.
Enfin, dans le cas où un événement est "sauté" ou "manqué", nous avons un chemin de support facile à la demande à suivre. Nous notifions à nouveau l'abonné à propos de cet enregistrement (si nous savons quel enregistrement a manqué un événement), ou nous effectuons une requête de "rattrapage" du système complet (si nous ne sommes pas sûrs).
Nous pouvons faire cela sans avoir à toucher le flux d'événements. Cela signifie que les autres applications abonnées ne seront pas impactées par l'activité de support.
Réflexions finales
Ce n'est pas la bonne solution pour tous les problèmes (ou même pour la plupart des problèmes). Mais c'est une excellente solution pour tirer parti du couplage lâche et des autres avantages en aval de l'event sourcing et du CQRS, tout en minimisant les frais généraux de support pour le dépannage des flux de données legacy. Cela permet à nos développeurs de passer plus de temps à écrire de nouvelles applications et augmente notre valeur pour nos consommateurs.
Si vous avez aimé cet article, veuillez cliquer sur le bouton ci-dessous et me donner quelques applaudissements pour que plus de gens le voient. Merci !
Jonathan est le directeur adjoint de l'architecture et des opérations au département des systèmes d'information de recherche de l'UCLA. Après avoir obtenu un diplôme en physique de l'Université de Stanford, il a passé plus de 10 ans à travailler dans l'architecture des systèmes d'information, l'amélioration des processus commerciaux pilotés par les données et la gestion organisationnelle. Il est également le fondateur de Peach Pie Apps Workshop, une entreprise qui se concentre sur la construction de solutions de données pour les organisations à but non lucratif.