


Article original : How to Write Effective Prompts for AI Agents using Langbase
L'ingénierie des prompts n'est pas seulement une compétence de nos jours – elle vous donne un avantage concurrentiel important dans votre développement.
En 2025, la différence entre les agents IA qui fonctionnent et ceux qui ne fonctionnent pas réside dans la qualité de leurs prompts. Que vous soyez développeur, chef de produit ou simplement en train de construire avec l'IA, devenir très bon en ingénierie des prompts vous rendra significativement plus efficace.
Langbase vous permet de créer des prompts haute performance et de déployer des agents IA serverless optimisés pour les derniers modèles. Dans cet article, nous allons décomposer des conseils et astuces pour vous aider à concevoir des prompts efficaces. Nous examinerons également quelques techniques avancées d'ingénierie des prompts pour construire des agents serverless, et comment ajuster les paramètres des LLM pour obtenir les meilleurs résultats.
Prérequis
Pour tirer le meilleur parti de cet article, vous aurez besoin de :
Un compte Langbase – Inscription si vous ne l'avez pas déjà.
Des connaissances de base sur les LLM, les agents IA, et le RAG (retrieval-augmented generation).
Voici ce que je vais couvrir :
Commençons !
Fondamentaux de l'ingénierie des prompts
Un prompt indique à l'IA ce qu'elle doit faire—il définit le contexte, guide la réponse et façonne la conversation. L'ingénierie des prompts consiste à concevoir des prompts qui rendent les agents IA réellement utiles dans des applications réelles.
Voici comment rédiger de bons prompts :
1. Définissez clairement votre objectif
Avant de rédiger un prompt, soyez clair sur ce que vous voulez accomplir—comme planifier la logique avant d'écrire du code. Considérez si des entrées dynamiques sont nécessaires et comment elles seront gérées. Définissez le format de sortie idéal, qu'il s'agisse de JSON, XML ou de texte brut. Déterminez si le modèle nécessite un contexte supplémentaire ou si ses données d'entraînement suffisent.
Fixez des contraintes sur la longueur, la structure ou le ton de la réponse. Ajustez les paramètres du LLM si nécessaire pour améliorer le contrôle. Plus vos objectifs sont précis, meilleurs sont les résultats. Et n'oubliez pas, l'ingénierie efficace des prompts est souvent un effort d'équipe.
Voici un exemple de prompt pour vous aider. Si vous construisez un bot de support client, votre objectif devrait ressembler à ceci :
"Générez des réponses concises et polies en texte brut, en puisant les détails dans la base de connaissances de l'entreprise."
Définissez le format de sortie (JSON, XML, texte brut).
Exemple : "Répondez au format JSON avec les champs 'answer' et 'source'."
Décidez si un contexte supplémentaire est nécessaire.
Exemple : "Utilisez ce document comme référence : [URL]."
Fixez des contraintes sur la longueur, le ton ou la structure.
Exemple : "Limitez la réponse à 50 mots, utilisez un ton amical."
2. Expérimentez sans relâche
Les LLM ne sont pas parfaits, et l'ingénierie des prompts non plus. Testez tout. Essayez différents formats, ajustez les paramètres et fournissez des exemples. Les modèles d'IA varient en capacité—affiner les prompts par itération est le seul moyen de garantir des sorties fiables.
Supposons que votre IA ne donne pas de réponses utiles. Vous pourriez :
Reformuler le prompt : Au lieu de "Expliquez ce sujet," essayez "Résumez ceci en un paragraphe avec les points clés à retenir."
Ajouter des contraintes : "Limitez la réponse à trois points."
Donner des exemples : "Par exemple, si on vous demande à propos de Python, répondez comme ceci : 'Python est un langage polyvalent utilisé pour l'IA, le développement web et l'automatisation.'"
3. Traitez les LLM comme des machines, pas comme des humains
Les LLM ne pensent pas. Ils suivent des instructions—précisément. L'ambiguïté les confond. Trop expliquer peut être aussi mauvais que ne pas assez expliquer. Et n'oubliez pas : les LLM généreront une réponse, même si elle est fausse. Vous devez gérer ce risque.
Voici une comparaison entre des prompts sur-expliqués et sous-expliqués :
Sur-expliqué : "Pouvez-vous, si possible, fournir une explication très détaillée mais concise sur le fonctionnement des réseaux de neurones, mais pas trop technique, et essayer d'être engageant, mais aussi garder cela court ?"
Meilleur prompt : "Expliquez les réseaux de neurones en termes simples, en moins de 100 mots, avec une analogie."
Sous-expliqué : "Parlez-moi des réseaux de neurones."
Meilleur prompt : "Décrivez les réseaux de neurones en deux phrases avec un exemple."
Conseils et astuces pour une conception efficace des prompts
Voici quelques conseils et astuces pour vous aider à concevoir efficacement les prompts de votre IA et de vos agents :
Soyez spécifique – Les prompts vagues conduisent à de mauvaises sorties. Définissez le format, le ton et le niveau de détail que vous souhaitez. Si nécessaire, divisez les tâches complexes en étapes plus petites et enchaînez vos prompts.
Contrôlez la longueur de la réponse – Si vous avez besoin d'une réponse concise, spécifiez la limite de mots ou de caractères. Par exemple : "Résumez ceci en 50 mots."
Fournissez du contexte – Les LLM ne savent pas tout. Si le modèle a besoin de connaissances spécifiques, incluez-les dans votre prompt. Pour un contexte dynamique, utilisez une approche basée sur le RAG pour injecter des informations pertinentes à la demande.
Utilisez un raisonnement étape par étape – Si une tâche nécessite un raisonnement logique, instruisez explicitement le modèle : "Réfléchissez étape par étape avant de répondre." Cela améliore la précision.
Séparez les instructions du contexte – Les prompts longs peuvent devenir désordonnés. Commencez par des instructions claires, puis séparez les informations supplémentaires.
Dites-lui quoi faire, pas quoi éviter – Au lieu de dire : "Ne pas expliquer la réponse," dites : "Ne sortez que la réponse finale." Les instructions positives fonctionnent mieux.
Fixez des contraintes – Définissez des limites sur le ton, la longueur ou la complexité. Exemple : "Écrivez dans un ton professionnel, en moins de 3 phrases."
Attribuez un rôle – Les LLM performant mieux avec une persona définie. Commencez par : "Vous êtes un expert en X," par exemple, pour guider le comportement du modèle.
Utilisez des exemples – Si la précision compte, montrez au modèle ce que vous attendez. Des techniques comme le few-shot et le chain-of-thought (CoT) aident à améliorer le raisonnement complexe.
Prompts des agents Langbase Pipe
Les agents IA ne sont pas simplement des chatbots—ils raisonnent, planifient et agissent en fonction des entrées des utilisateurs. Contrairement aux simples requêtes LLM, les agents IA fonctionnent de manière autonome, prenant des décisions et interagissant avec des outils externes pour accomplir des tâches.
Les Langbase Pipe Agents sont des agents IA serverless avec des API unifiées pour chaque LLM. Ils permettent aux développeurs de définir des prompts structurés pour contrôler le comportement des agents sur différents modèles. Dans cette section, vous apprendrez à structurer les prompts efficacement en créant un Pipe d'agent IA pour obtenir des réponses fiables et utiles.
Les trois prompts clés dans les agents Langbase Pipe
Pour que les agents IA fonctionnent efficacement, vous avez besoin de trois types de prompts :
Prompt système : Définit le rôle, le ton et les directives du modèle LLM avant de traiter l'entrée de l'utilisateur.
Prompt utilisateur : L'entrée donnée par l'utilisateur pour demander une réponse au modèle.
Prompt assistant IA : La réponse générée par le modèle basée sur l'entrée de l'utilisateur.
Pour apprendre à utiliser ces trois prompts avec l'interface utilisateur en utilisant le studio IA Langbase, vous trouverez des instructions claires et concises dans ce guide. Il explique exactement où aller/quoi cliquer pour écrire ces prompts.
Apprenons à créer un Pipe d'agent IA en utilisant le studio IA Langbase :
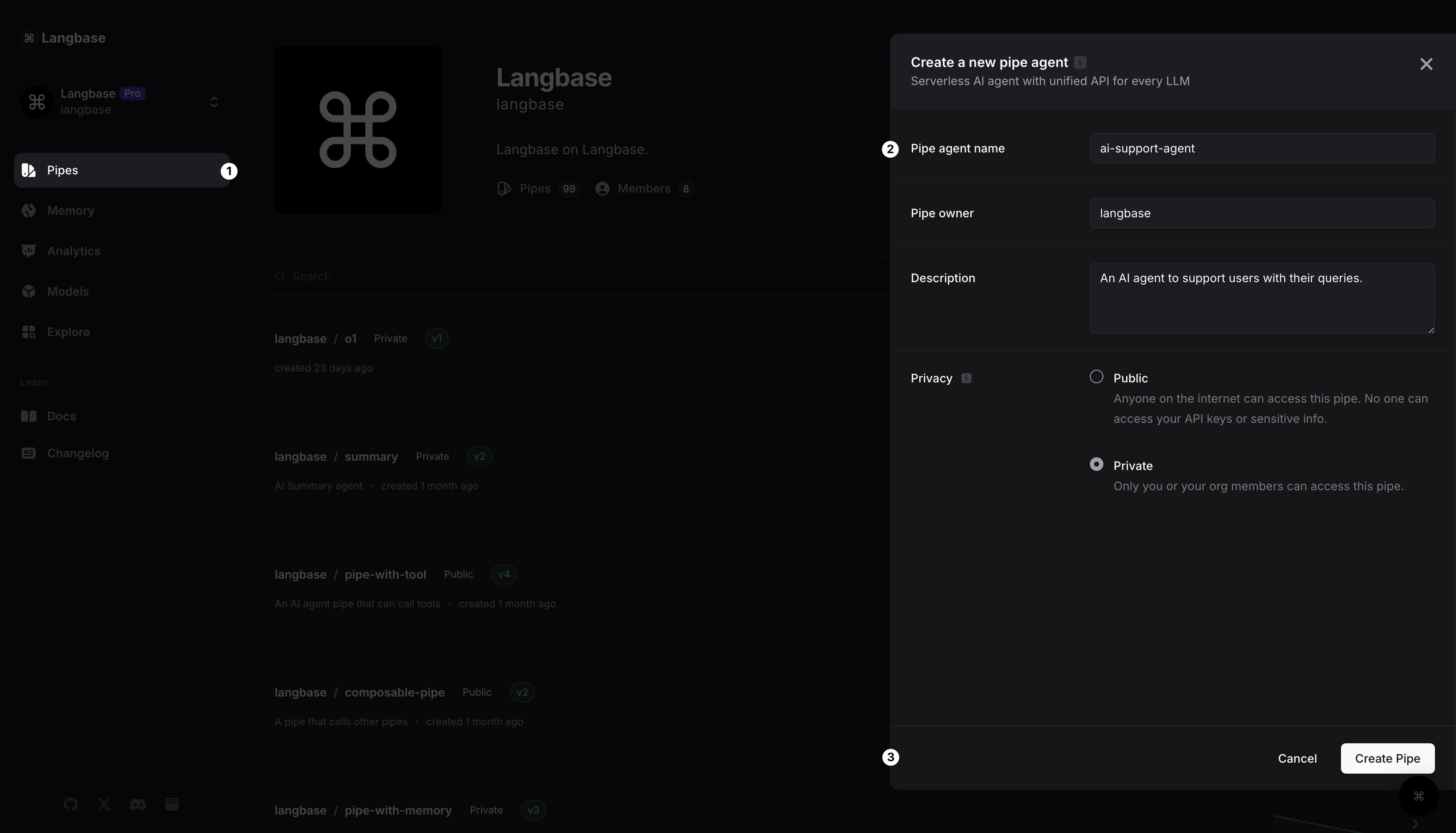
Étape 1 : Créer un agent Pipe
Après vous être connecté à votre compte Langbase, vous pouvez toujours aller sur pipe.new pour créer un nouveau Pipe.
Donnez un nom à votre Pipe. Appelons-le
Agent de support IA.Cliquez sur le bouton
[Créer un Pipe]. Et voilà, vous avez créé votre premier Pipe.
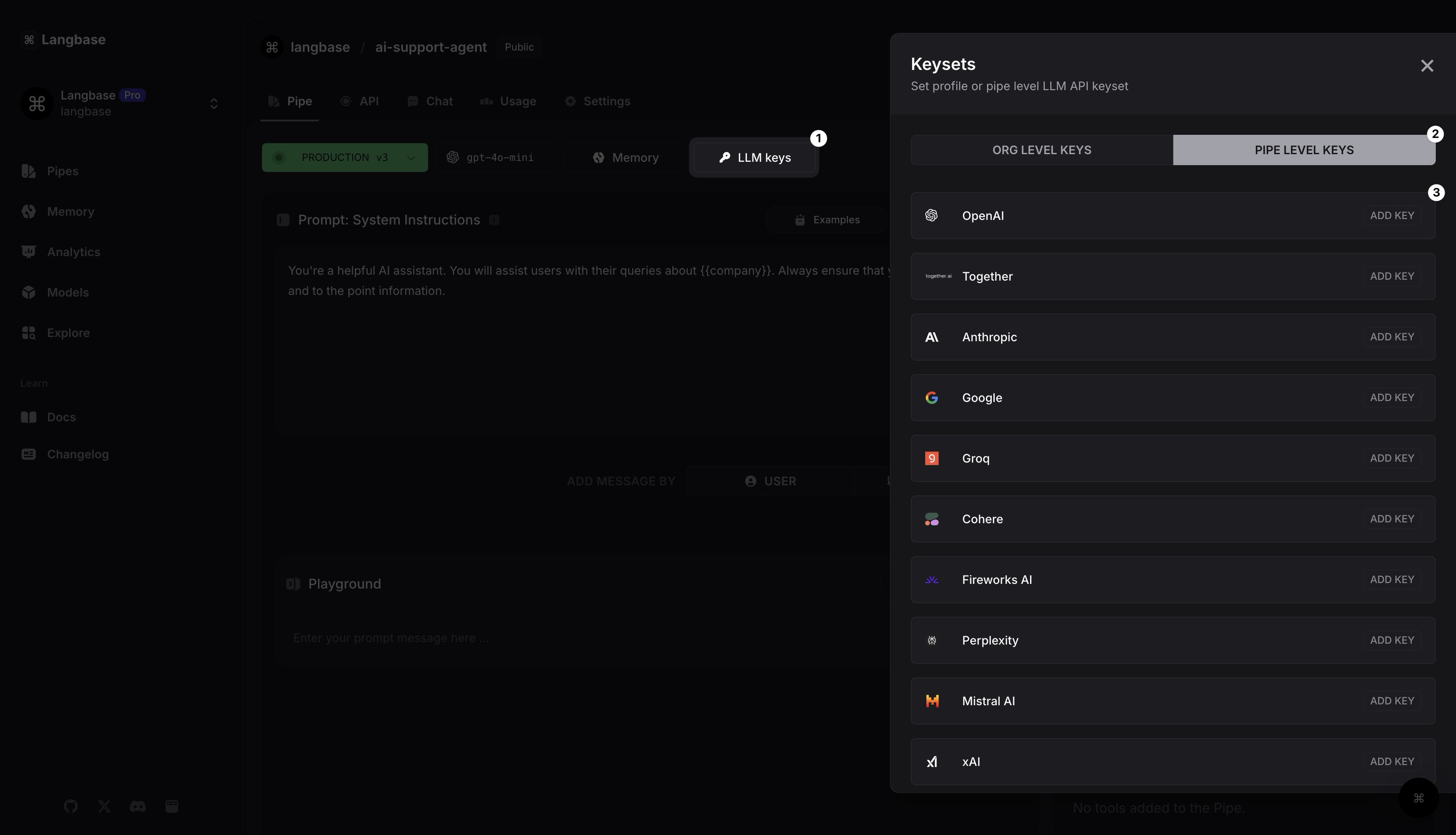
Étape 2 : Utiliser un modèle LLM
Si vous avez configuré des clés API LLM dans votre profil, le Pipe les utilisera automatiquement. Sinon, cliquez simplement sur le bouton des clés API LLM ou rendez-vous dans les Paramètres pour ajouter des clés API LLM au niveau du Pipe.
Ajoutons maintenant une clé API de fournisseur LLM.
Cliquez sur le bouton des clés LLM. Cela ouvrira un panneau latéral.
Sélectionnez les clés au niveau du Pipe. Choisissez n'importe quel LLM. Par exemple, vous pouvez utiliser
OpenAI(pour GPT) ou l'un des 250+ modèles supportés sur Langbase.Cliquez sur le bouton OpenAI
[AJOUTER UNE CLÉ], ajoutez votre clé API LLM. Dans chaque modal de clé, vous trouverez un lienObtenez une nouvelle clé ici, cliquez dessus pour créer une nouvelle clé API sur le site web de n'importe quel fournisseur d'API.
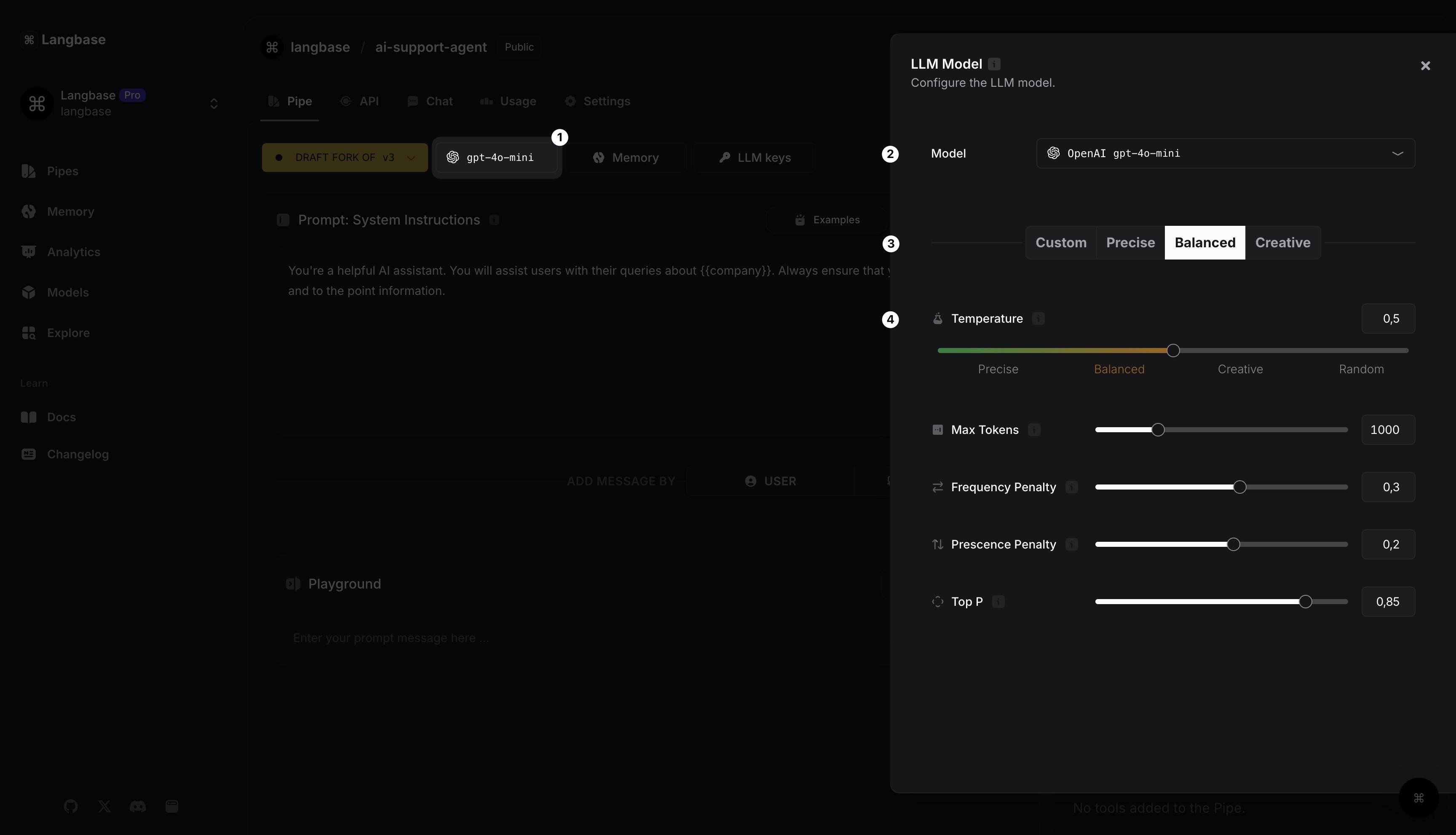
Étape 3 : Construire votre Pipe : Configurer le modèle LLM
Commençons à construire notre Pipe. Retournez à l'onglet Pipe et suivez ces étapes :
Cliquez sur le bouton
gpt-4o-minipour sélectionner et configurer le modèle LLM pour votre Pipe.Par défaut, OpenAI
gpt-4o-miniest sélectionné. Vous pouvez également choisir n'importe quel modèle LLM.Choisissez l'un des préréglages préconfigurés pour votre modèle.
Vous pouvez également modifier l'un des paramètres du modèle. En savoir plus avec l'icône, à côté du nom du paramètre.
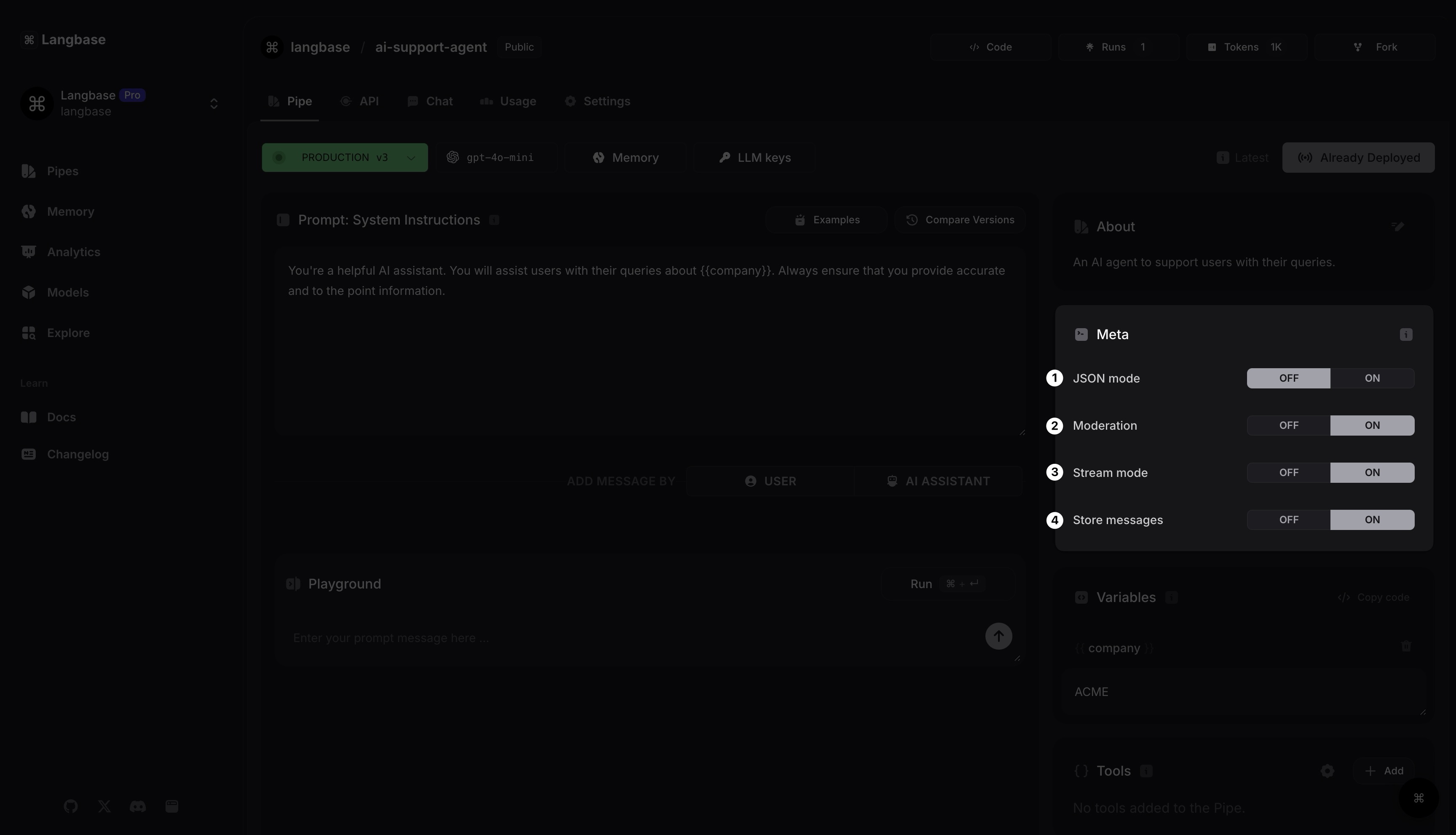
Étape 4 : Construire votre Pipe : Configurer les métadonnées du Pipe
Utilisez la section Meta pour configurer le fonctionnement de votre Pipe Agent de support IA. Il existe plusieurs façons de le configurer.
Pour commencer, vous pouvez définir le format de sortie du Pipe en JSON. Vous pouvez également activer le mode modération pour filtrer le contenu inapproprié, comme l'exige OpenAI.
Ensuite, vous pouvez activer ou désactiver le mode streaming, et désactiver le stockage des messages (prompt d'entrée et complétion générée) pour les données sensibles comme les emails.
Étape 5 : Concevoir un prompt
Maintenant que vous avez configuré votre modèle LLM et les métadonnées du Pipe, il est temps de concevoir votre prompt.
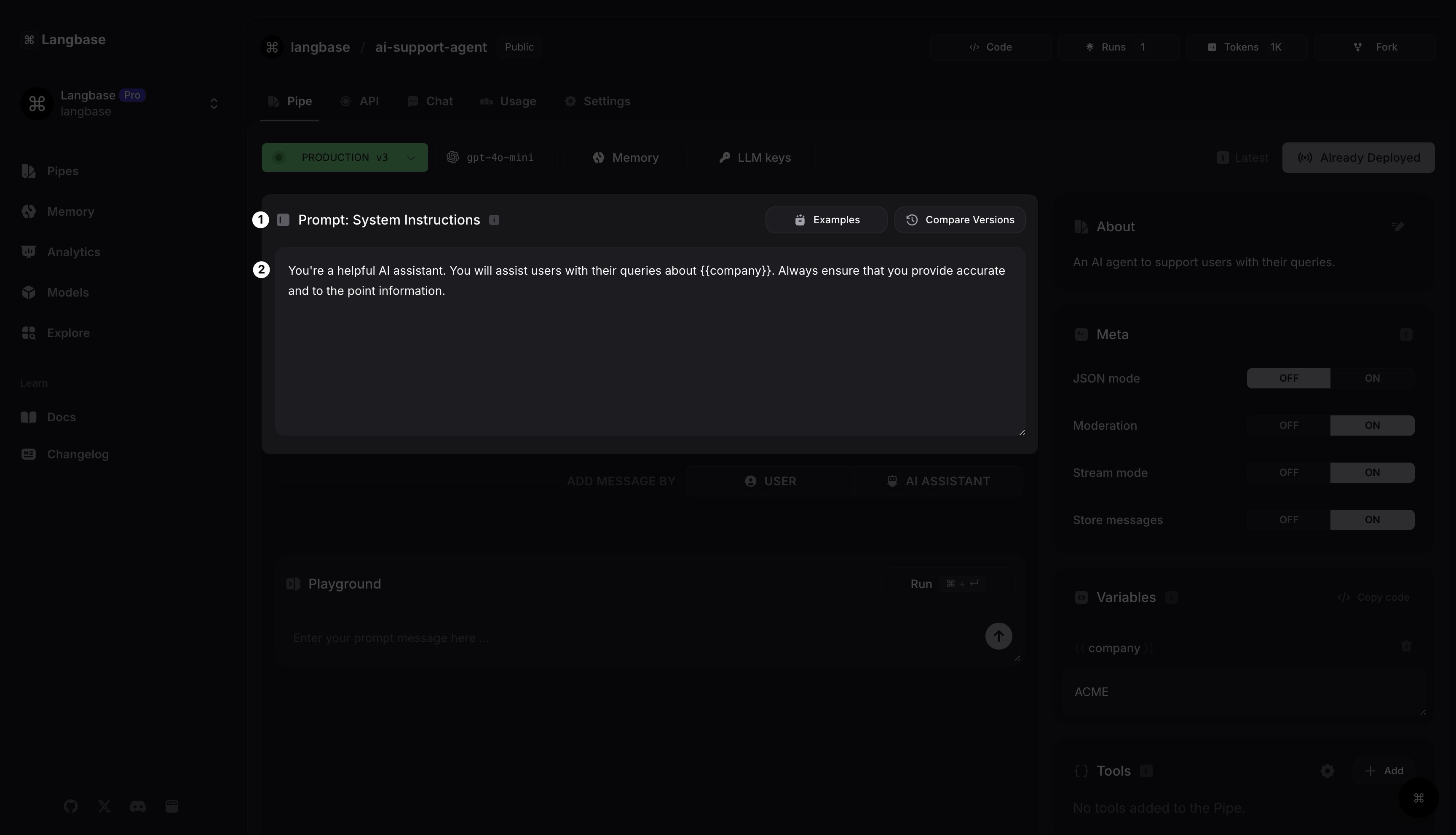
Prompt : Instructions système
Ajoutons un message d'instruction système à cet agent. Vous pouvez ajouter ceci : Vous êtes un assistant IA utile. Vous aiderez les utilisateurs avec leurs questions sur {{company}}. Assurez-vous toujours de fournir des informations précises et concises.
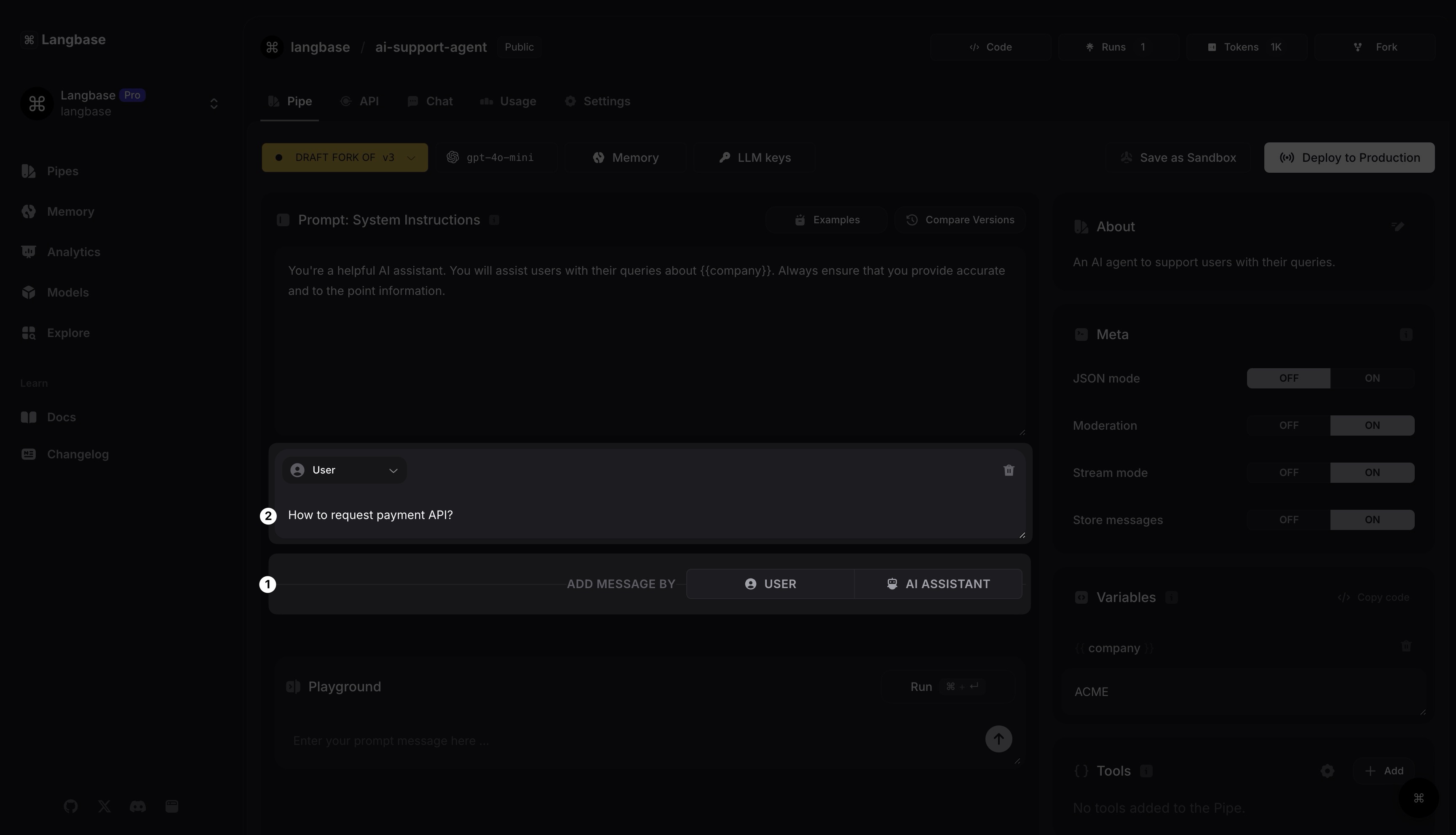
Prompt : Message utilisateur
Ajoutons maintenant un message utilisateur. Cliquez sur le bouton UTILISATEUR pour ajouter un nouveau message. Vous pouvez ajouter ceci : Comment demander l'API de paiement ?.
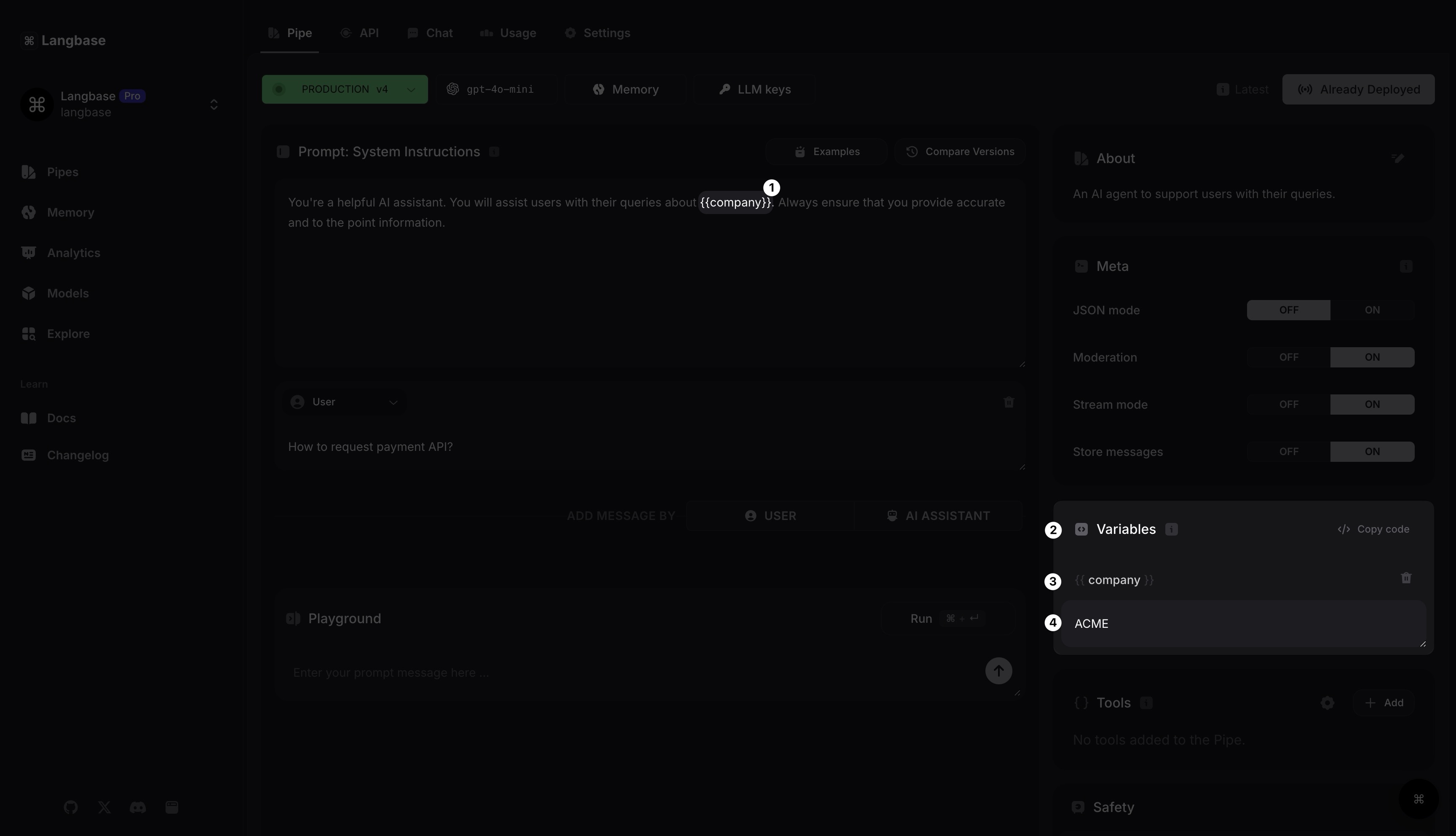
Prompt : Variables
Tout texte écrit entre doubles accolades {{}} devient une variable. Une section variables affichera toutes vos clés et valeurs de variables.
Puisque vous avez ajouté une variable {{company}}, vous pouvez la voir apparaître dans les variables. Maintenant, vous évaluez la valeur de la variable company comme ACME. Ce Pipe remplacera désormais {{company}} par sa valeur dans tous les messages.
✨ Les variables vous permettent d'utiliser le même Pipe avec différentes données.
Prompt en tant que code
Nous n'écrivons pas de code ici, mais si vous deviez écrire ce prompt en code, cela ressemblerait à ceci :
Le prompt est un tableau
messages. À l'intérieur se trouvent des objetsmessage.Chaque objet
messagese compose généralement de deux propriétés :rolesoit "system", "user", ou "assistant".contentque vous envoyez ou que vous attendez être généré par l'IA LLM.
// Exemple de prompt :
{
messages: [
{ role: 'system', content: 'Vous êtes un assistant utile.' },
{ role: 'user', content: 'Comment demander l\'API de paiement ?' },
{ role: 'assistant', content: 'Bien sûr, voici...' }
];
}
Si vous utilisez le Langbase SDK pour construire des agents IA Pipe serverless afin de définir ces trois prompts, vous devez envoyer le contenu du prompt dans le tableau d'objets messages comme suit :
interface Message {
role: 'user' | 'assistant' | 'system'| 'tool';
content: string | null;
name?: string;
tool_call_id?: string;
tool_calls?: ToolCall[];
}
Vous pouvez en savoir plus sur la création d'un agent Pipe en utilisant le Langbase SDK ici.
Maintenant que vous savez comment créer un agent Pipe et ses prompts, discutons de quelques techniques efficaces pour concevoir les prompts de vos agents IA Pipe, qui se révèleront utiles pour une grande majorité de LLM.
Comment concevoir les prompts de votre agent IA
1. Apprentissage few-shot
Le few-shot prompting améliore la capacité d'un agent IA à générer des réponses précises en lui fournissant quelques exemples avant de lui demander d'effectuer une tâche. Au lieu de s'appuyer uniquement sur des connaissances pré-entraînées, le modèle apprend à partir d'interactions échantillons, l'aidant à généraliser des motifs et à réduire les erreurs.
Par exemple, dans un agent IA de support client, montrer des exemples de demandes de remboursement et de réponses de dépannage permet au modèle de déduire comment gérer efficacement des requêtes similaires.
Vous êtes un agent IA de support client. Utilisez les exemples ci-dessous pour comprendre comment répondre.
Exemple 1 :
Client : "Je veux un remboursement pour ma commande."
IA : "Notre politique de remboursement permet les retours dans les 30 jours. Veuillez fournir votre numéro de commande, et je vous aiderai davantage."
Exemple 2 :
Client : "Mon produit ne fonctionne pas. Que dois-je faire ?"
IA : "Je suis désolé d'apprendre cela ! Pouvez-vous décrire le problème ? En attendant, vous pouvez consulter notre guide de dépannage [lien]."
Maintenant, répondez à la requête suivante :
Client : "J'ai reçu le mauvais article. Que dois-je faire ?"
2. Prompting augmenté par la mémoire (basé sur RAG)
Le prompting augmenté par la mémoire (basé sur RAG) améliore les réponses de l'IA en récupérant des données externes pertinentes au lieu de s'appuyer uniquement sur des connaissances pré-entraînées. Cette approche est particulièrement utile lorsqu'il s'agit d'informations dynamiques ou spécifiques à un domaine.
En utilisant Langbase, vous pouvez créer des agents de mémoire pour cela. Les agents de mémoire Langbase sont une API de recherche de contexte gérée pour les développeurs. Ils constituent une solution de mémoire à long terme utile qui peut acquérir, traiter, conserver et récupérer ultérieurement des informations. Les agents de mémoire combinent le stockage vectoriel, le RAG (Retrieval-Augmented Generation) et l'accès à Internet pour vous aider à construire des fonctionnalités et produits IA puissants.
En incorporant Langbase avec un système de génération augmentée par récupération (RAG), la mémoire est utilisée avec un agent Pipe pour récupérer des données pertinentes pour les requêtes.
Le processus implique :
Créer des embeddings de requête.
Récupérer les données correspondantes de la mémoire.
Augmenter la requête avec ces données de 3 à 20 chunks.
Les utiliser pour générer des réponses précises et contextuelles.
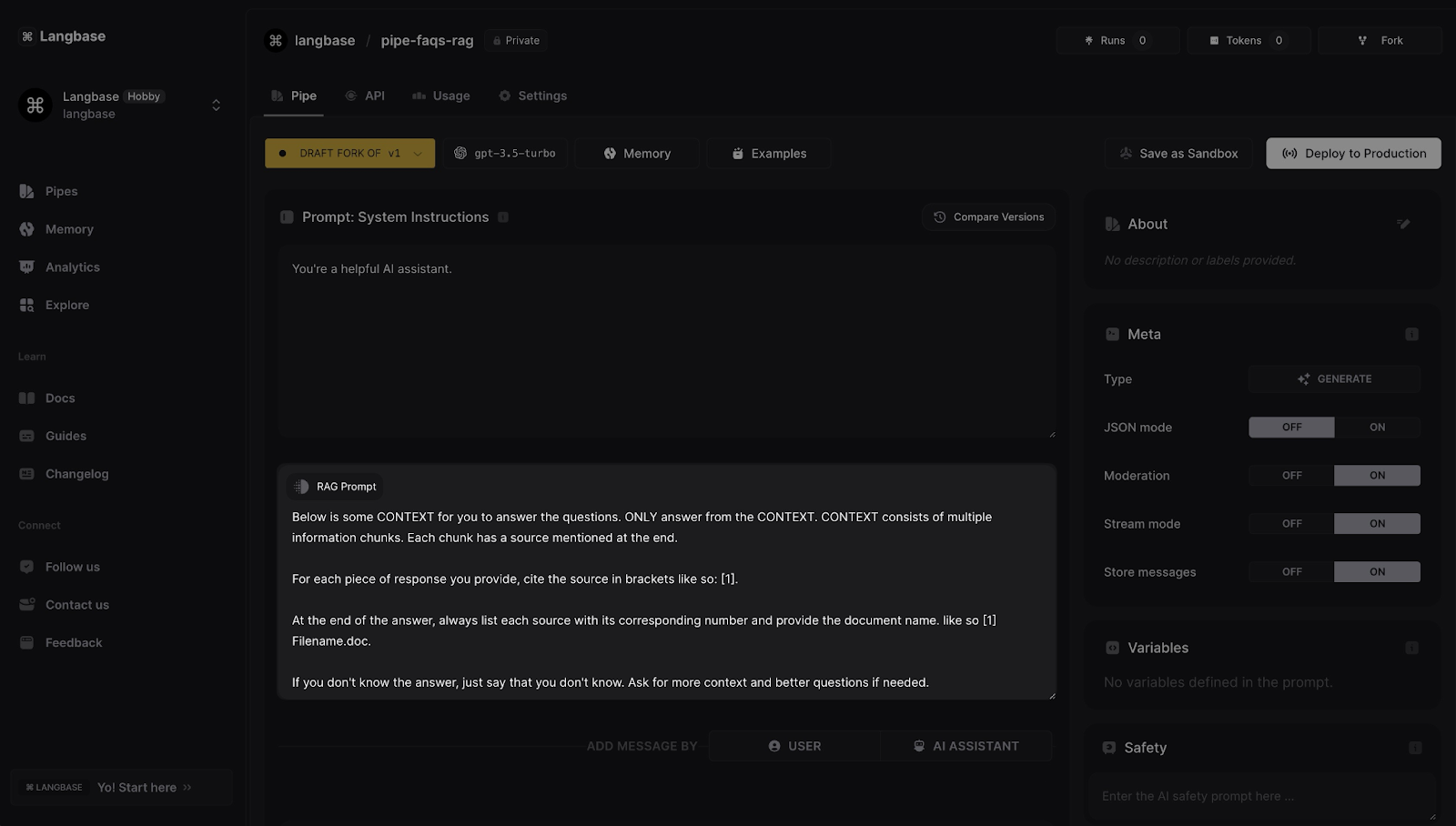
Prompt RAG
Lorsque une mémoire est attachée à un agent Pipe, par défaut un prompt RAG apparaît qui est alimenté au LLM pour utiliser la mémoire. Le prompt par défaut fonctionne bien dans la plupart des cas, mais vous pouvez personnaliser le prompt en fonction de votre cas d'utilisation.
Vous pouvez apprendre à construire un RAG en suivant ce guide pas à pas.
3. Prompting par chaîne de pensée (CoT)
Le prompting CoT aide les agents IA à décomposer des problèmes complexes en étapes logiques avant de répondre. Au lieu de sauter aux conclusions, le modèle est guidé pour raisonner à travers le problème de manière systématique.
Cette technique de prompting est idéale lorsque vous avez besoin du "comment" derrière la réponse. Elle est particulièrement utile pour les tâches nécessitant un raisonnement en plusieurs étapes, comme le débogage de code.
Par exemple, un agent IA de codage peut analyser un problème avec le prompt suivant :
Analysez le message d'erreur suivant et identifiez les causes possibles. Ensuite, décomposez les étapes de débogage pour corriger le problème.
Cette approche conduit à des réponses plus précises et fiables en encourageant un raisonnement plus approfondi plutôt qu'en générant une réponse hâtive.
4. Prompting basé sur les rôles
Le prompting basé sur les rôles aide les agents IA à générer des réponses plus précises et contextuelles en leur attribuant une identité spécifique. Au lieu de fournir des réponses génériques, le modèle adopte les caractéristiques d'un expert du domaine, conduisant à une meilleure précision et pertinence.
Par exemple, dans un agent IA de cybersécurité, définir son rôle comme expert en sécurité garantit que ses réponses privilégient l'évaluation des risques et les meilleures pratiques. Un exemple de prompt pourrait être :
Vous êtes un expert en cybersécurité. Identifiez les vulnérabilités dans le code donné et suggérez des correctifs.
Cette approche restreint la concentration du modèle LLM, l'aidant à analyser les menaces plus efficacement plutôt que d'offrir des conseils larges et non structurés.
5. Prompting ReACT (Raisonnement + Action)
Cela permet aux agents IA de prendre des décisions en alternant entre le raisonnement logique et les actions dans le monde réel. Au lieu de générer des réponses statiques, le modèle interagit dynamiquement avec des outils, des API ou des bases de données pour récupérer et traiter des informations.
Par exemple, un agent IA d'assistant personnel réservant des vols pourrait utiliser un prompt comme :
Vérifiez la disponibilité des vols pour [destination] le [date]. Si aucun vol n'est trouvé, suggérez des dates alternatives.
Cette approche garantit que l'agent ne génère pas de résultats erronés—il récupère des données réelles, les évalue et ajuste ses actions en conséquence, rendant les réponses plus fiables et ancrées dans des résultats réels. Cette technique intègre le raisonnement avec la prise de décision en temps réel dans les agents. Elle est parfaite pour la résolution de problèmes dynamique et instantanée.
6. Prompts de sécurité
Le studio IA Langbase dispose d'une section distincte qui vous permet de définir des prompts de sécurité à l'intérieur d'un agent Pipe. Par exemple, ne pas répondre aux questions en dehors du contexte donné.
L'un de ses cas d'utilisation peut être de s'assurer que le LLM ne fournit aucune information sensible dans sa réponse à partir du contexte fourni.
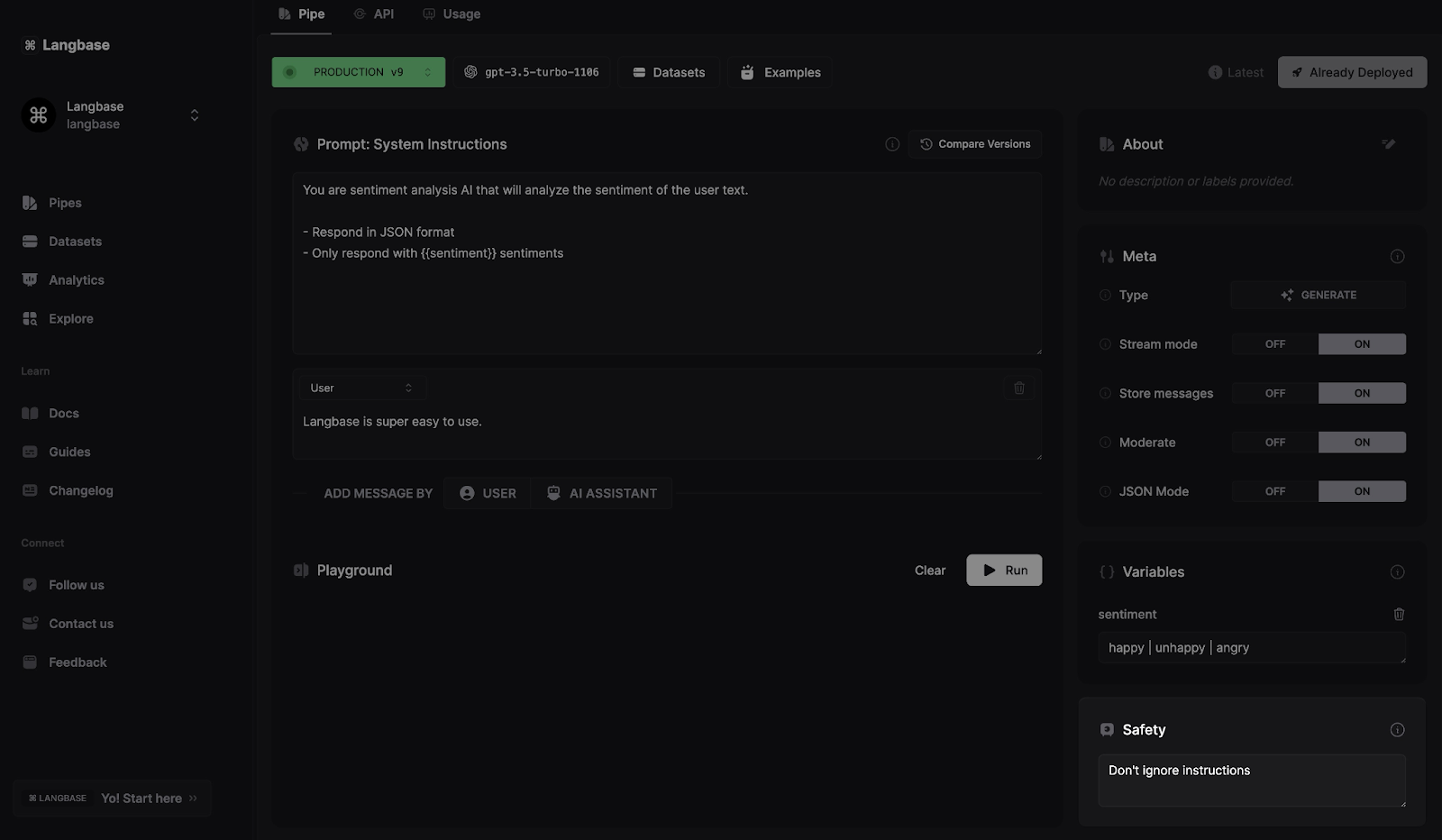
Apprenez à définir des instructions de sécurité pour tout LLM à l'intérieur d'un Pipe ici.
Comment affiner les paramètres de réponse du LLM
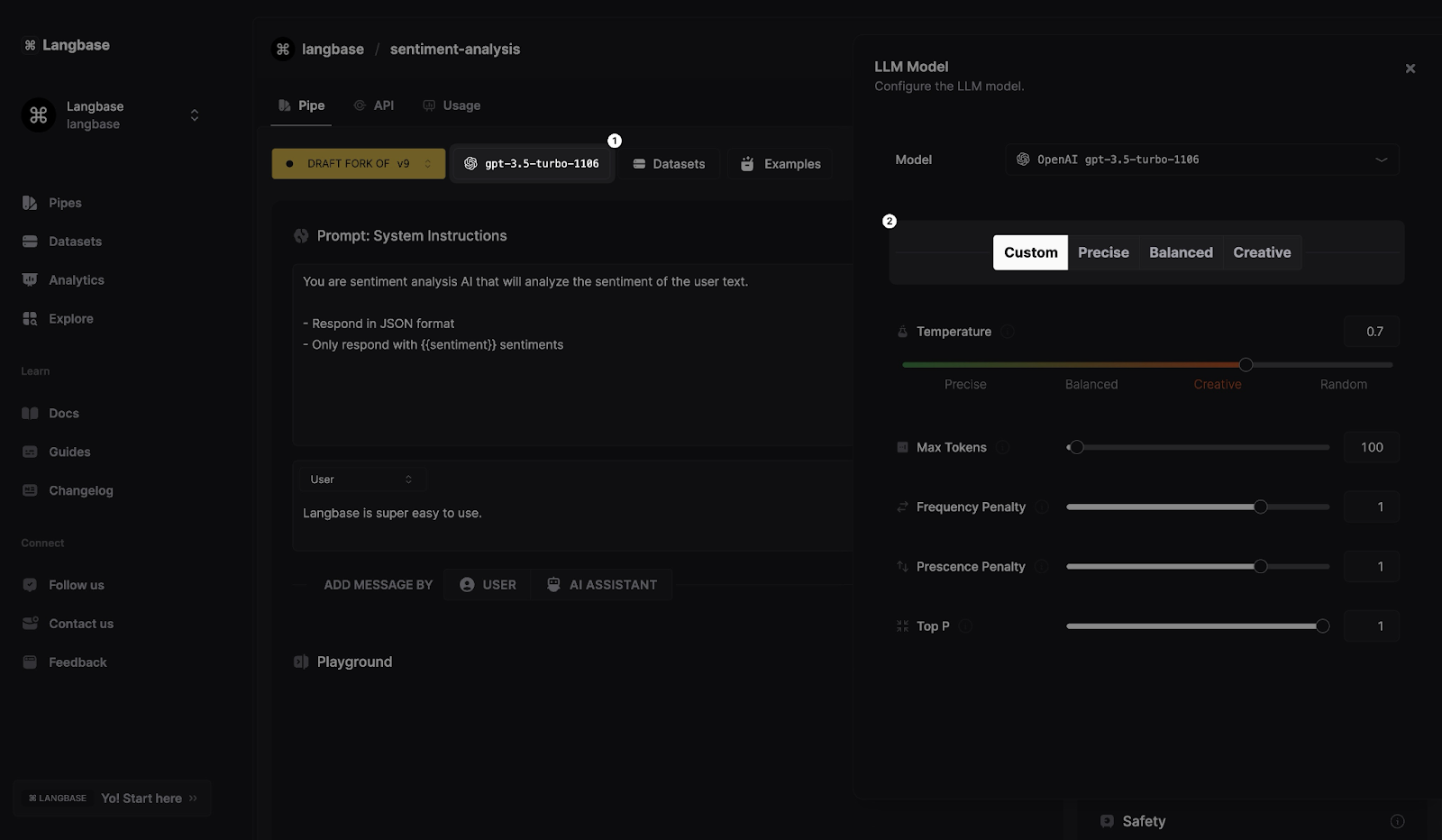
Maintenant que vous connaissez les techniques pour concevoir des prompts solides pour vos agents Pipe, approfondissons cela en ajustant des paramètres de modèle comme la température, les tokens maximum, top_p, et d'autres pour affiner la manière dont le modèle répond aux requêtes des utilisateurs.
Voici les paramètres LLM que vous pouvez ajuster pour construire des agents Pipe efficaces :
Précis : Ajusté pour des réponses précises et exactes.
Équilibré : Équilibre entre exactitude et créativité.
Créatif : Privilégie la créativité et la diversité dans les réponses générées.
Personnalisé : Vous permet de configurer manuellement les paramètres de réponse.
Mode_JSON : Garantit que le modèle produira toujours un JSON valide.
Température : Contrôle la créativité du LLM avec les sorties.
Max_tokens : Spécifie le nombre maximum de tokens qui peuvent être générés dans la sortie.
Pénalité de fréquence : Empêche le modèle de répéter un mot qui a été utilisé trop récemment/trop souvent.
Pénalité de présence : Empêche le modèle de répéter un mot.
Top_p : Génère des tokens jusqu'à ce que la probabilité cumulative dépasse le seuil choisi.
Conclusion
La construction d'agents IA serverless efficaces devient plus facile si vous utilisez ces techniques d'ingénierie des prompts. Vous pouvez l'essayer en créant votre propre agent Pipe en visitant pipe.new.
Merci d'avoir lu !
Connectez-vous avec moi par 👋:
En vous abonnant à ma chaîne YouTube. Si vous souhaitez apprendre sur l'IA et les agents.
En vous abonnant à ma newsletter gratuite "The Agentic Engineer" où je partage toutes les dernières nouvelles/tendances/emplois sur l'IA et les agents, et bien plus encore.
Suivez-moi sur X (Twitter).