

Article original : How to publish GitHub event data with GitHub Actions and Pages
Les équipes qui travaillent sur GitHub s'appuient sur les données d'événements pour collaborer. Les données enregistrées sous forme de problèmes, de demandes de tirage et de commentaires deviennent essentielles pour comprendre le projet.
Avec la disponibilité générale de GitHub Actions, nous avons la possibilité d'accéder et de préserver programmatiquement les données d'événements GitHub dans notre dépôt. Faire en sorte que les données fassent partie du dépôt lui-même est un moyen de les préserver en dehors de GitHub. Cela nous donne également la possibilité de mettre en avant les données sur un site web frontal, comme avec GitHub Pages.
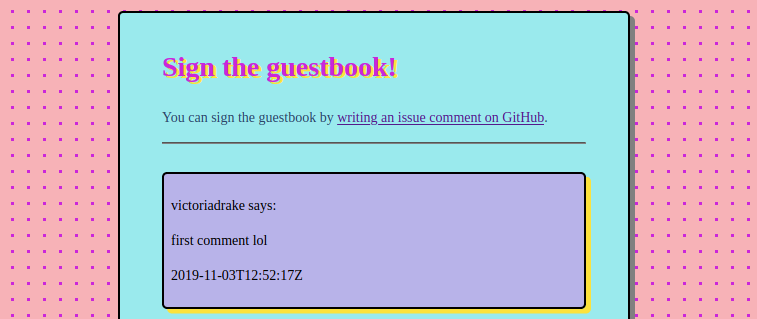
Et, si vous êtes comme moi, vous pouvez transformer les commentaires d'issues GitHub en une page de livre d'or des années 90 géniale.
Quelle que soit l'utilisation, les principes de base sont les mêmes. Nous pouvons utiliser Actions pour accéder, préserver et afficher les données d'événements GitHub - avec un seul fichier de workflow. Pour illustrer le processus, je vais vous guider à travers le code de workflow qui fait briller mon livre d'or.
Pour une introduction à GitHub Actions, y compris comment les workflows sont déclenchés, voir Un flux CI/CD léger et agnostique avec GitHub Actions.
Accéder aux données d'événements GitHub
Un workflow d'Action s'exécute dans un environnement avec certaines variables d'environnement par défaut. Beaucoup d'informations pratiques sont disponibles ici, y compris les données d'événements. La manière la plus complète d'accéder aux données d'événements est d'utiliser la variable $GITHUB_EVENT_PATH, le chemin du fichier avec la charge utile JSON complète de l'événement.
Le chemin développé ressemble à /home/runner/work/_temp/_github_workflow/event.json et ses données correspondent à son événement de webhook. Vous pouvez trouver la documentation pour les données d'événements de webhook dans l'API REST GitHub Types d'événements et charges utiles. Pour rendre les données JSON disponibles dans l'environnement de workflow, vous pouvez utiliser un outil comme jq pour analyser les données d'événements et les mettre dans une variable d'environnement.
Ci-dessous, je récupère l'ID du commentaire à partir d'un événement de commentaire d'issue :
ID="$(jq '.comment.id' $GITHUB_EVENT_PATH)"
La plupart des données d'événements sont également disponibles via la variable de contexte github.event sans avoir besoin d'analyser le JSON. Les champs sont accessibles en utilisant la notation par points, comme dans l'exemple ci-dessous où je récupère le même ID de commentaire :
ID=${{ github.event.comment.id }}
Pour mon livre d'or, je veux afficher les entrées avec le pseudonyme de l'utilisateur, ainsi que la date et l'heure. Je peux capturer ces données d'événements comme suit :
AUTHOR=${{ github.event.comment.user.login }}
DATE=${{ github.event.comment.created_at }}
Les variables shell sont pratiques pour accéder aux données, cependant, elles sont éphémères. L'environnement de workflow est recréé à chaque exécution, et même les variables shell définies dans une étape ne persistent pas dans les autres étapes. Pour préserver les données capturées, vous avez deux options : utiliser des artefacts, ou les commiter dans le dépôt.
Préserver les données d'événements : utiliser des artefacts
En utilisant des artefacts, vous pouvez préserver les données entre les jobs de workflow sans les commiter dans votre dépôt. Cela est pratique lorsque, par exemple, vous souhaitez transformer ou incorporer les données avant de les mettre quelque part de plus permanent. Il est nécessaire de préserver les données entre les jobs de workflow parce que :
Chaque job dans un workflow s'exécute dans une nouvelle instance de l'environnement virtuel. Lorsque le job est terminé, le runner termine et supprime l'instance de l'environnement virtuel. (Préserver les données de workflow en utilisant des artefacts)
Deux actions aident à utiliser les artefacts : upload-artifact et download-artifact. Vous pouvez utiliser ces actions pour rendre des fichiers disponibles pour d'autres jobs dans le même workflow. Pour un exemple complet, voir passer des données entre les jobs dans un workflow.
Le fichier action.yml de l'action upload-artifact contient une explication des mots-clés. Les fichiers téléchargés sont sauvegardés au format .zip. Un autre job dans le même workflow peut utiliser l'action download-artifact pour utiliser les données dans une autre étape.
Vous pouvez également télécharger manuellement l'archive sur la page d'exécution du workflow, sous l'onglet Actions du dépôt.
La persistance des données de workflow entre les jobs ne modifie aucun fichier du dépôt, car les artefacts générés vivent uniquement dans l'environnement de workflow.
Personnellement, étant à l'aise dans un environnement shell, je vois un cas d'utilisation étroit pour les artefacts, bien que j'aurais été négligente de ne pas les mentionner. En plus de passer des données entre les jobs, ils pourraient être utiles pour créer des archives au format .zip de, par exemple, des données de sortie de test. Dans le cas de mon exemple de livre d'or, j'ai simplement exécuté toutes les étapes nécessaires en un seul job, annulant tout besoin de passer des données entre les jobs.
Préserver les données d'événements : pousser les fichiers de workflow vers le dépôt
Pour préserver les données capturées dans le workflow dans le dépôt lui-même, il est nécessaire d'ajouter et de pousser ces données vers le dépôt Git. Vous pouvez faire cela dans le workflow en créant de nouveaux fichiers avec les données, ou en ajoutant des données à des fichiers existants, en utilisant des commandes shell.
Créer des fichiers dans le workflow
Pour travailler avec les fichiers du dépôt dans le workflow, utilisez l'action checkout pour obtenir d'abord une copie à travailler :
- uses: actions/checkout@master
with:
fetch-depth: 1
Pour ajouter des commentaires à mon livre d'or, je transforme les données d'événements capturées dans des variables shell en fichiers appropriés, en utilisant des substitutions dans l'expansion de paramètres shell pour assainir l'entrée utilisateur et traduire les nouvelles lignes en paragraphes. J'ai écrit précédemment sur pourquoi l'entrée utilisateur doit être traitée avec soin.
- name: Transformer le commentaire en fichier
run: |
ID=${{ github.event.comment.id }}
AUTHOR=${{ github.event.comment.user.login }}
DATE=${{ github.event.comment.created_at }}
COMMENT=$(echo "${{ github.event.comment.body }}")
NO_TAGS=${COMMENT//[<>]/\`}
FOLDER=comments
printf '%b\n' "<div class=\"comment\"><p>${AUTHOR} dit :</p><p>${NO_TAGS//$'\n'/\<\/p\>\<p\>}</p><p>${DATE}</p></div>\r\n" > ${FOLDER}/${ID}.html
En utilisant printf et en dirigeant sa sortie avec > vers un nouveau fichier, les données d'événements sont transformées en un fichier HTML, nommé avec le numéro d'ID du commentaire, qui contient les données d'événements capturées. Formaté, cela ressemble à :
<div class="comment">
<p>victoriadrake dit :</p>
<p>Ceci est un commentaire !</p>
<p>2019-11-04T00:28:36Z</p>
</div>
Lors de la gestion des commentaires, un effet de nommer les fichiers en utilisant l'ID du commentaire est qu'un nouveau fichier avec le même ID écrasera le précédent. Cela est pratique pour un livre d'or, car cela permet à toute modification d'un commentaire de remplacer le fichier de commentaire original.
Si vous utilisez un générateur de site statique comme Hugo, vous pourriez construire un fichier au format Markdown, le placer dans votre dossier content/, et la construction régulière du site s'occupera du reste.
Dans le cas de mon livre d'or simpliste, j'ai une étape supplémentaire pour consolider les fichiers de commentaires individuels en une page. Chaque fois qu'il s'exécute, il écrase l'index.html existant avec la portion header.html (>), puis trouve et ajoute (>>) tout le contenu des fichiers de commentaires dans l'ordre décroissant, et enfin ajoute la portion footer.html pour terminer la page.
- name: Assembler la page
run: |
cat header.html > index.html
find comments/ -name "*.html" | sort -r | xargs -I % cat % >> index.html
cat footer.html >> index.html
Commiter les changements vers le dépôt
Puisque l'action checkout n'est pas tout à fait la même que le clonage du dépôt, au moment de l'écriture, il y a encore quelques problèmes à contourner. Quelques étapes supplémentaires sont nécessaires pour pull, checkout, et push avec succès les changements vers la branche master, mais cela est assez trivial à faire dans le shell.
Ci-dessous se trouve l'étape qui ajoute, commite et pousse les changements effectués par le workflow vers la branche master du dépôt.
- name: Pousser les changements vers le dépôt
run: |
REMOTE=https://${{ secrets.GITHUB_TOKEN }}@github.com/${{ github.repository }}
git config user.email "${{ github.actor }}@users.noreply.github.com"
git config user.name "${{ github.actor }}"
git pull ${REMOTE}
git checkout master
git add .
git status
git commit -am "Ajouter un nouveau commentaire"
git push ${REMOTE} master
Le dépôt distant, en fait notre dépôt, est spécifié en utilisant la variable de contexte github.repository. Pour que notre workflow soit autorisé à pousser vers master, nous utilisons la variable secrets.GITHUB_TOKEN.
Puisque l'environnement de workflow est tout neuf, nous devons configurer Git. Dans l'exemple ci-dessus, j'ai utilisé la variable de contexte github.actor pour entrer le nom d'utilisateur du compte initiant le workflow. L'email est configuré de manière similaire en utilisant l'adresse email noreply par défaut de GitHub.
Afficher les données d'événements
Correction du 6 novembre 2019 : GitHub Actions nécessite un jeton d'accès personnel pour déclencher une construction de site Pages.
Si vous utilisez GitHub Pages avec la variable secrets.GITHUB_TOKEN par défaut et sans générateur de site, pousser des changements vers le dépôt dans le workflow ne mettra à jour que les fichiers du dépôt. La construction GitHub Pages échouera avec une erreur, "Votre site rencontre des problèmes de construction : la construction de la page a échoué."
Pour permettre aux Actions de déclencher une construction de site Pages, vous devrez créer un jeton d'accès personnel. Ce jeton peut être stocké comme un secret dans les paramètres du dépôt et passé dans le workflow à la place de la variable secrets.GITHUB_TOKEN par défaut. J'ai écrit plus sur l'environnement et les variables des Actions dans cet article.
Avec l'utilisation d'un jeton d'accès personnel, un push initié par le workflow Actions mettra également à jour le site Pages. Vous pouvez le voir par vous-même en laissant un commentaire dans mon livre d'or ! L'événement de création de commentaire déclenche le workflow, qui prend ensuite environ 30 secondes à une minute pour s'exécuter et mettre à jour la page du livre d'or.
Là où une construction de site est nécessaire pour que les changements soient publiés, comme lors de l'utilisation de Hugo, une Action peut également le faire. Cependant, afin d'éviter de créer des boucles non intentionnelles, un workflow d'Action n'en déclenchera pas un autre. Au lieu de cela, il est extrêmement pratique de gérer le processus de construction du site avec un Makefile, que n'importe quel workflow peut ensuite exécuter. Il suffit d'ajouter l'exécution du Makefile comme dernière étape dans votre job de workflow, avec le jeton de dépôt si nécessaire :
- name: Exécuter le Makefile
env:
TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: make all
Cela garantit que la dernière étape de votre workflow construit et déploie le site mis à jour.
Plus d'horizon pour les données d'événements
GitHub Actions fournit un moyen pratique de capturer et d'utiliser les données d'événements afin qu'elles ne soient pas seulement disponibles au sein de GitHub. Les possibilités ne sont limitées que par votre imagination ! Voici quelques idées de choses que cela nous permet de créer :
- Un tableau de problèmes public, où les clients sans compte GitHub peuvent voir et donner leur avis sur les problèmes du projet.
- Un flux RSS automatiquement mis à jour des nouveaux problèmes, commentaires ou PR pour n'importe quel dépôt.
- Un système de commentaires pour les sites statiques, utilisant les commentaires d'issues GitHub comme méthode d'entrée.
- Une page de livre d'or des années 90 géniale.
Ai-je mentionné que j'ai créé une page de livre d'or des années 90 ? Mon Geocities-nerd intérieur est un peu excité.