
Article original : How to produce and consume data streams directly via Cypher with Streams Procedures
Par Andrea Santurbano
Tirer parti de Neo4j Streams — Partie 3
Cet article est la troisième partie de la série Tirer parti de Neo4j Streams (la partie 1 est ici, la partie 2 est ici). Dans cet article, je vais vous montrer comment intégrer Neo4j dans votre flux Apache Kafka en utilisant les procédures de flux disponibles avec Neo4j Streams.
Afin de montrer comment les intégrer, simplifier l'intégration et vous permettre de tester l'ensemble du projet manuellement, j'utiliserai Apache Zeppelin, un exécuteur de notebooks qui permet simplement de interagir nativement avec Neo4j.
Qu'est-ce qu'une procédure stockée Neo4j ?
À partir de Neo4j 3.x, le concept de procédures et fonctions définies par l'utilisateur a été introduit. Il s'agit d'implémentations personnalisées de certaines fonctionnalités et/ou règles métiers qui ne peuvent pas être (facilement) exprimées en Cypher lui-même.
Neo4j fournit un certain nombre de procédures intégrées. La bibliothèque APOC en ajoute environ 450 pour couvrir tous types d'usages, de l'intégration de données aux refactorings de graphes.
Quelles sont les procédures de flux ?
Le projet Neo4j Streams propose deux procédures :
streams.publish: permet l'envoi de messages personnalisés de Neo4j vers l'environnement configuré en utilisant le Producteur configuré sous-jacentstreams.consume: permet de consommer des messages à partir d'un sujet donné.
Installation de l'environnement
En vous rendant sur le dépôt Github suivant, vous trouverez tout ce qui est nécessaire pour reproduire ce que je présente dans cet article. Ce dont vous aurez besoin pour commencer est Docker, puis vous pourrez simplement lancer la pile en entrant dans le répertoire et en exécutant la commande suivante depuis le Terminal :
$ docker-compose up
Cela démarrera l'ensemble de l'environnement qui comprend :
- Neo4j + module Neo4j Streams + procédures APOC
- Apache Kafka
- Apache Spark (qui n'est pas nécessaire dans cet article, mais il est utilisé dans les deux précédents)
- Apache Zeppelin
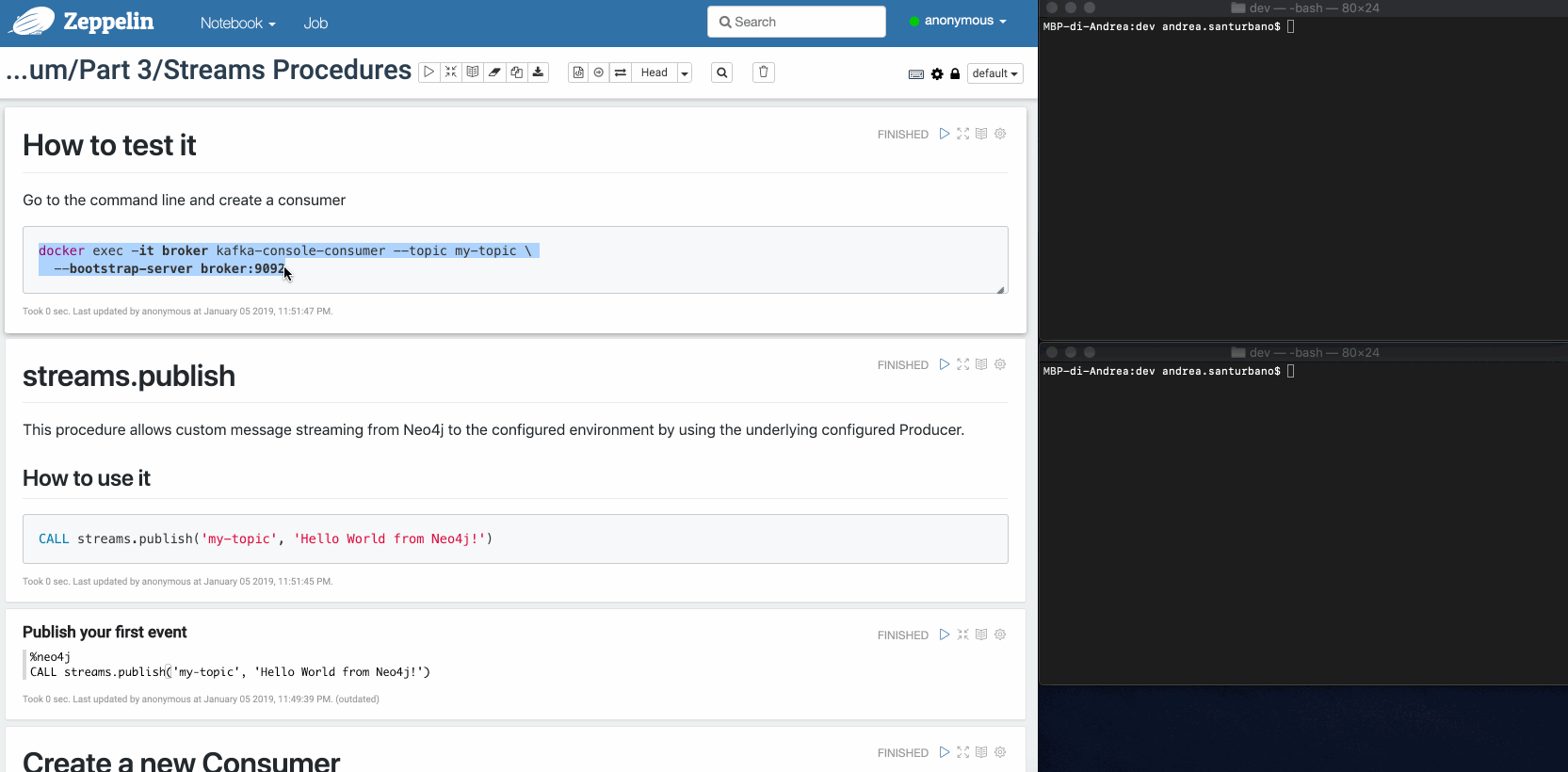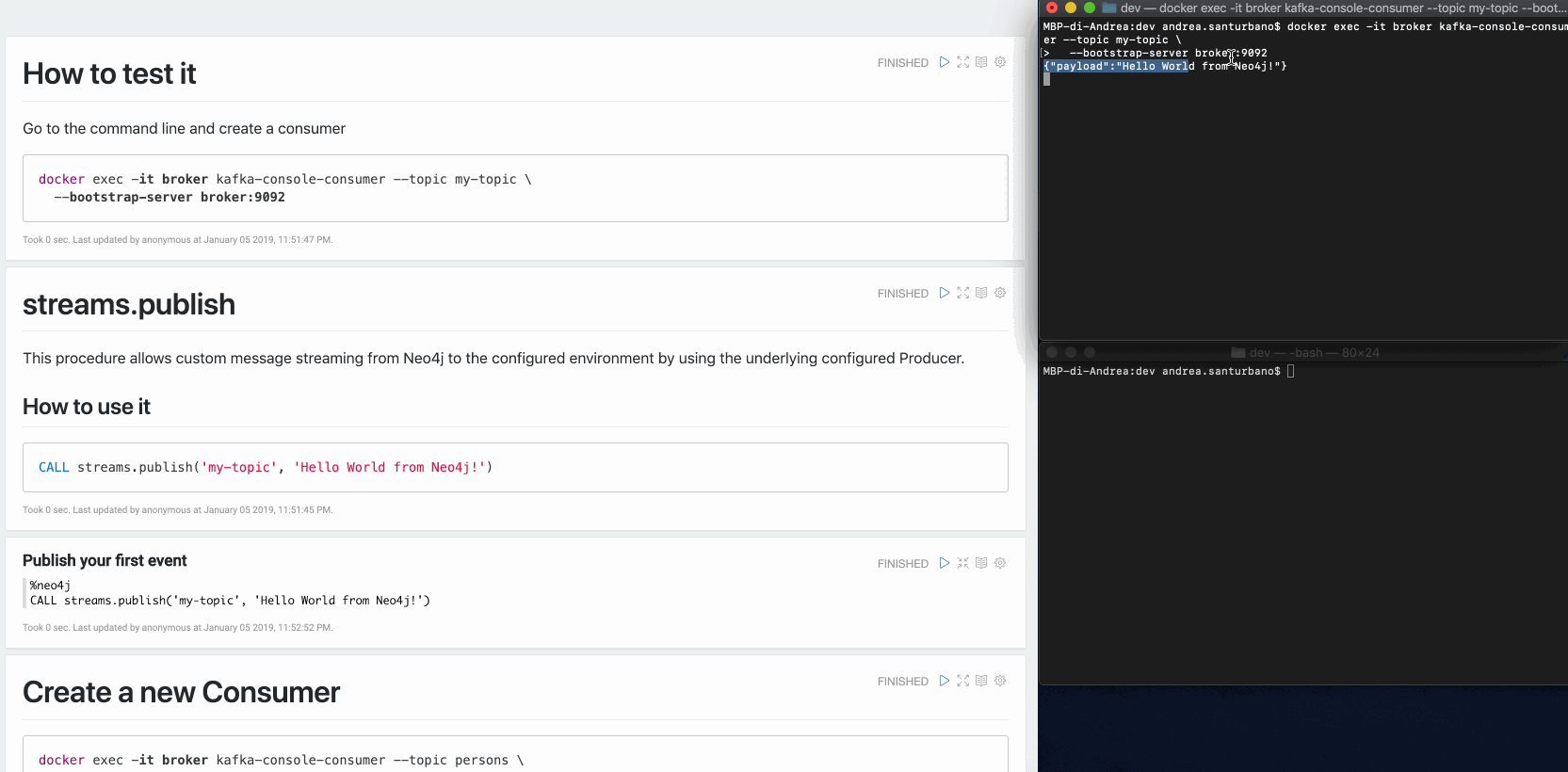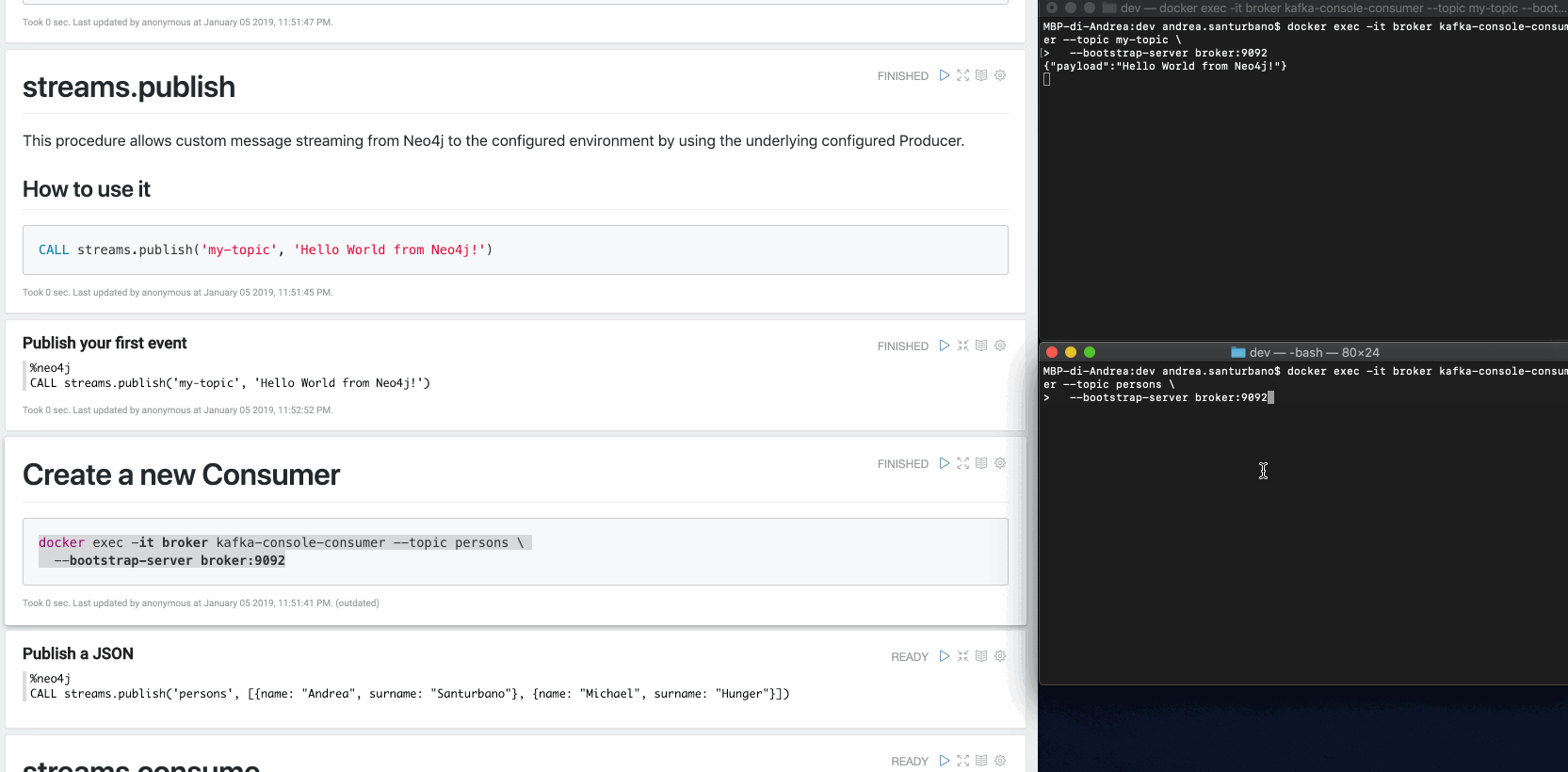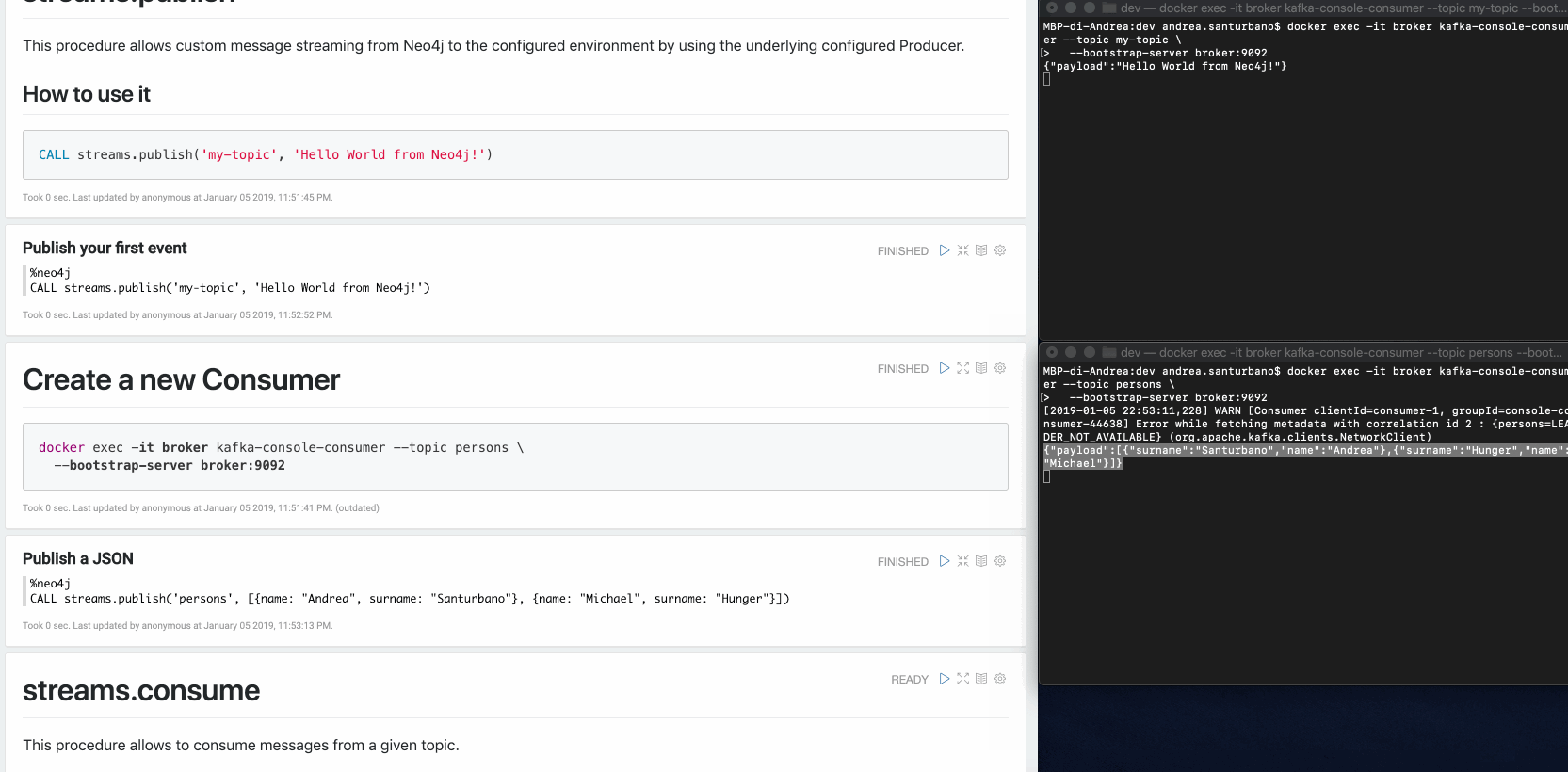
En accédant à Apache Zeppelin @ http://localhost:8080, vous trouverez dans le répertoire Medium/Part 3 un notebook appelé « Streams Procedures » qui est le sujet de cet article.
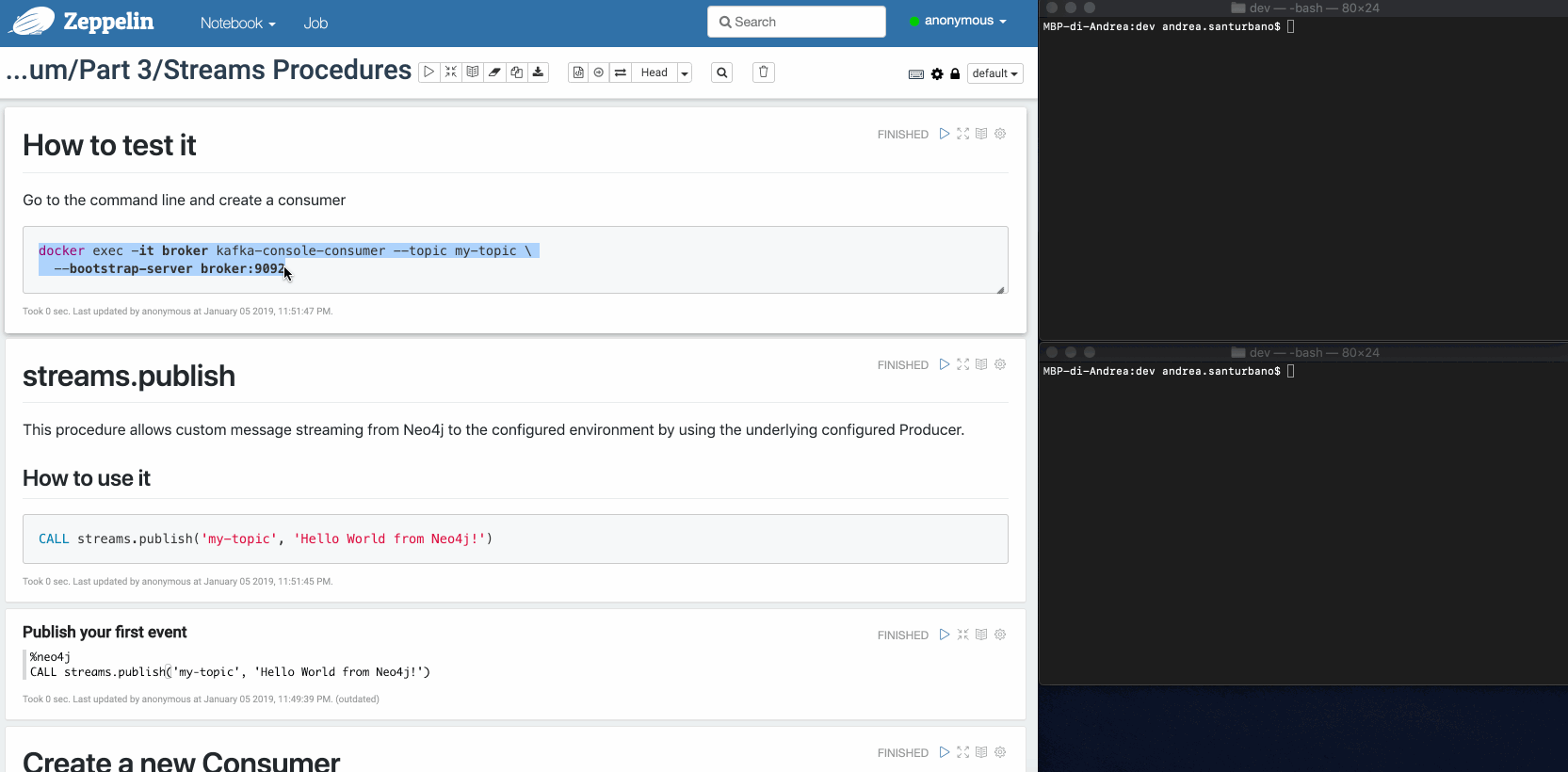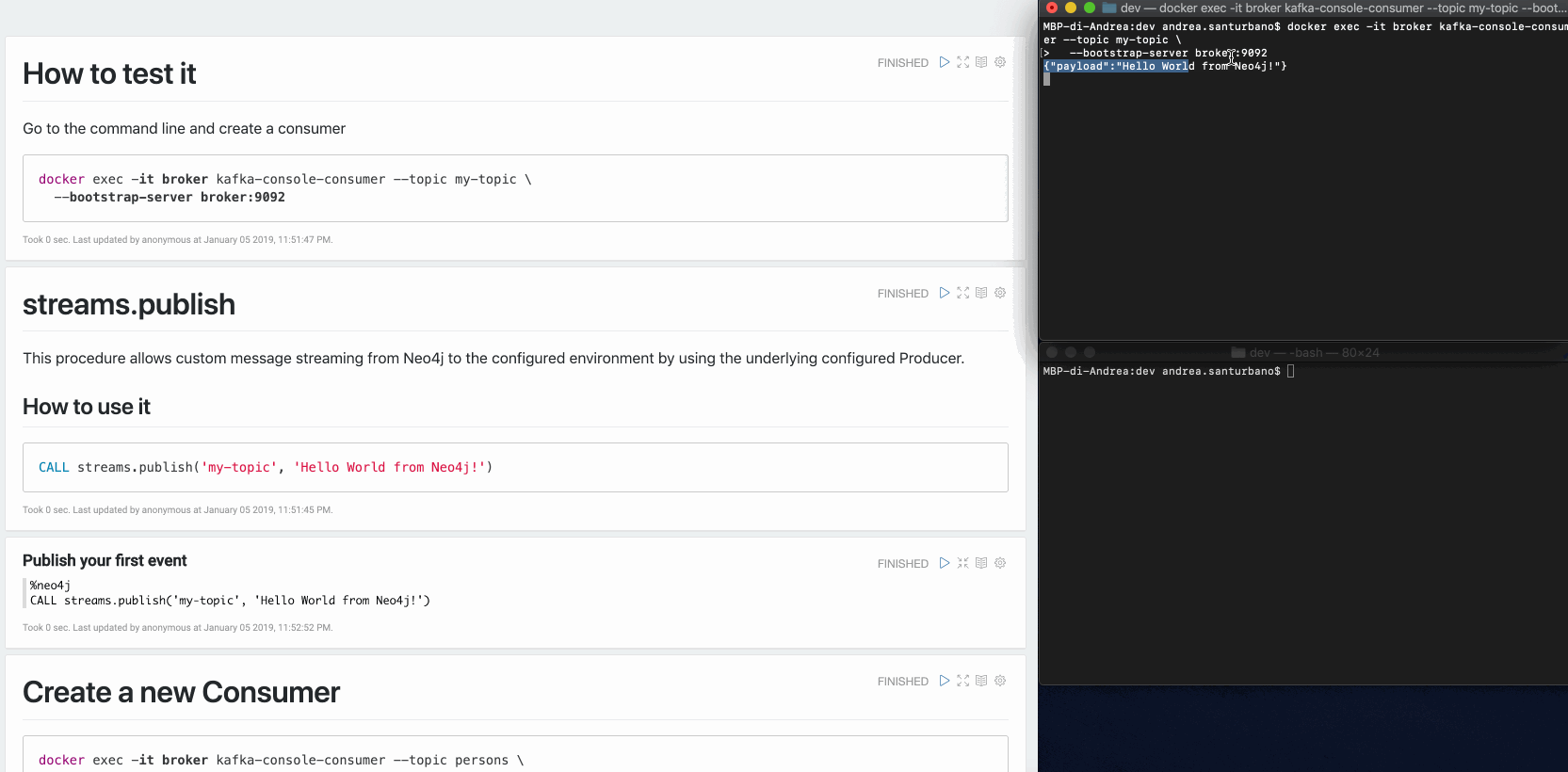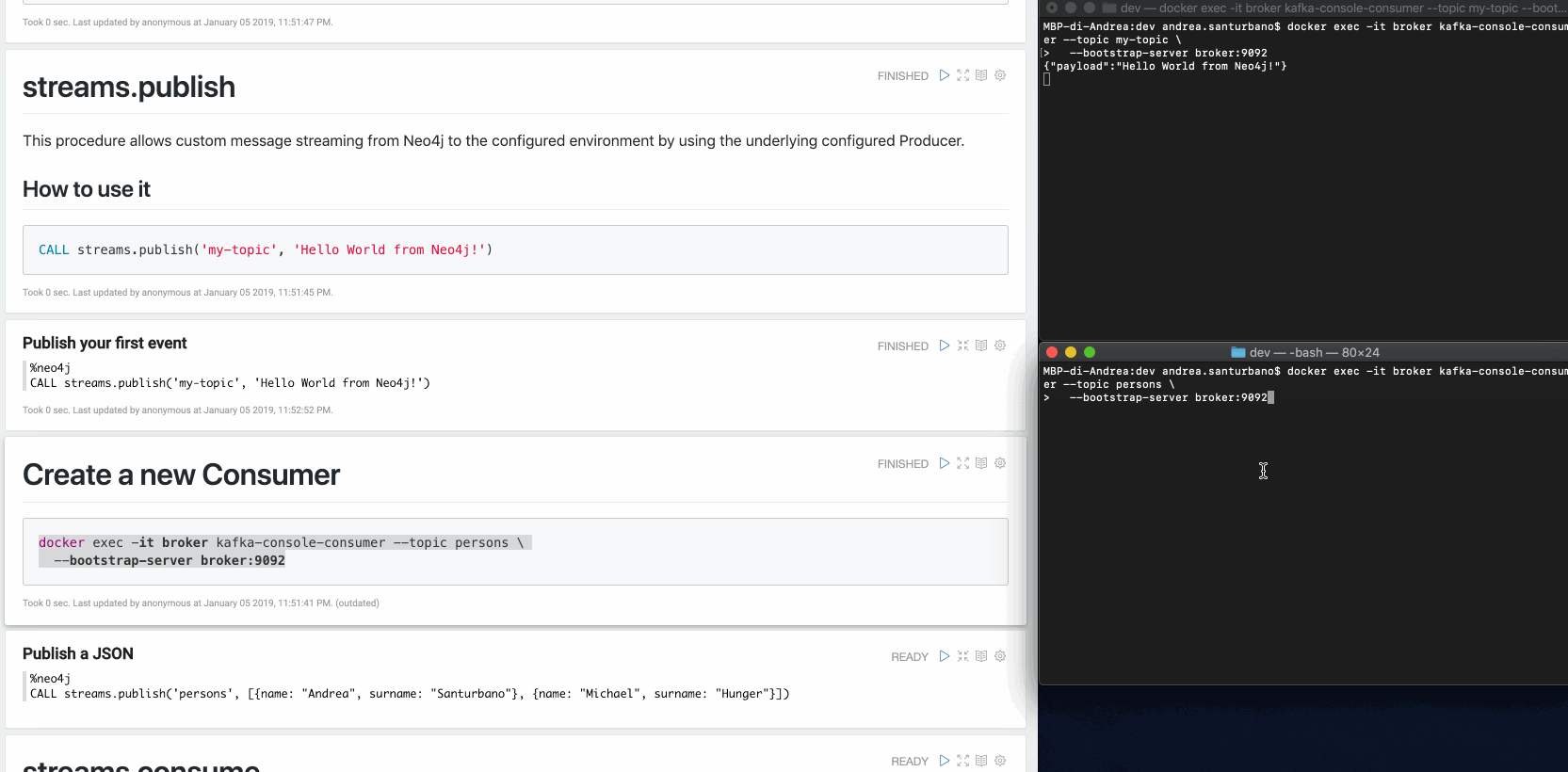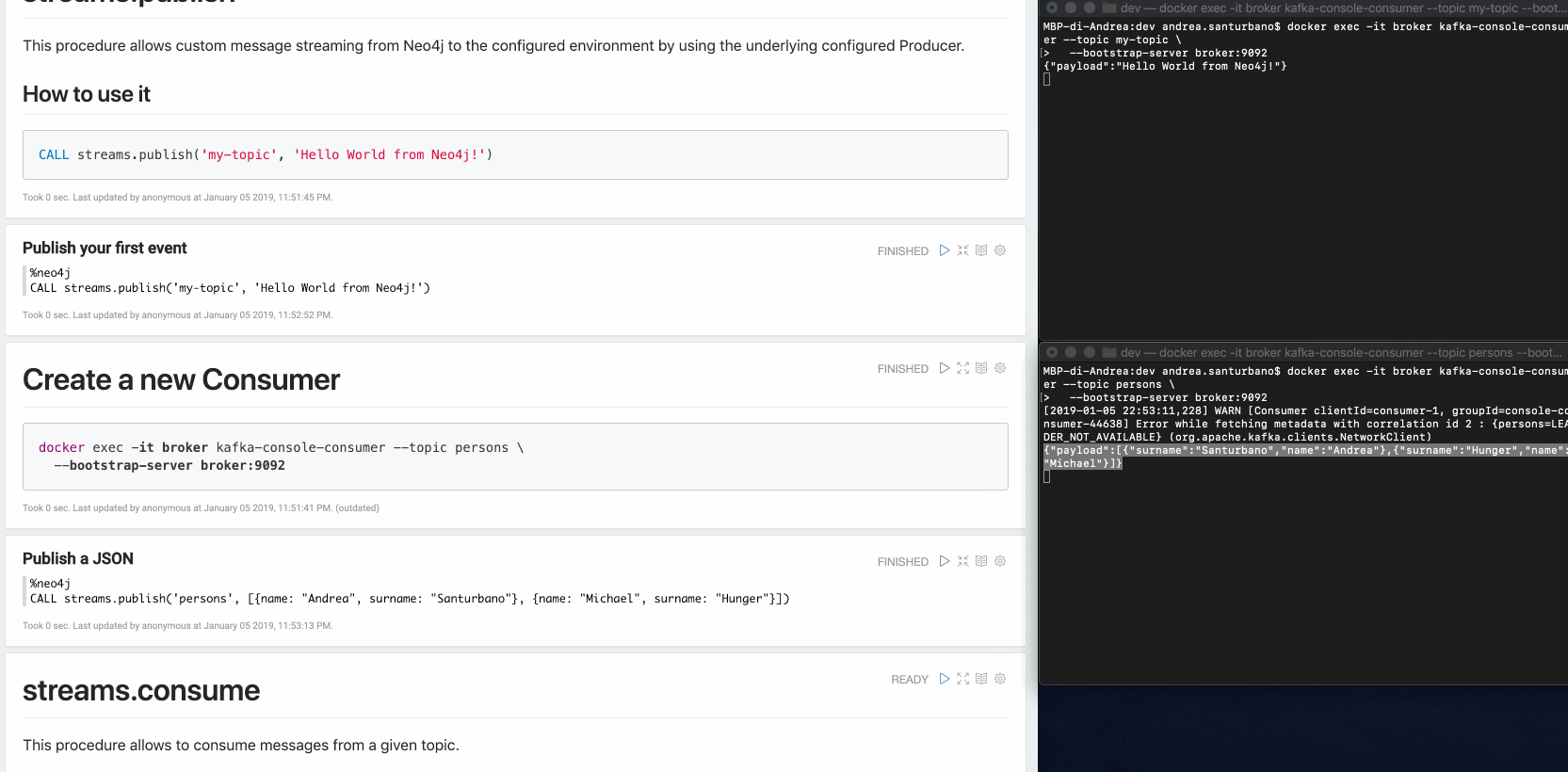
streams.publish
Cette procédure permet l'envoi de messages personnalisés de Neo4j vers l'environnement configuré en utilisant le Producteur configuré sous-jacent.
Elle prend deux variables en entrée et ne retourne rien (car elle envoie sa charge utile de manière asynchrone au flux) :
- topic, type String : où les données seront publiées
- payload, type Object : ce que vous souhaitez envoyer en flux.
Exemple :
CALL streams.publish('my-topic', 'Hello World from Neo4j!')
Le message récupéré par le Consommateur est le suivant :
{"payload": "Hello world from Neo4j!"}
Vous pouvez envoyer tout type de données dans la charge utile : nœuds, relations, chemins, listes, cartes, valeurs scalaires et versions imbriquées de ceux-ci.
Dans le cas de nœuds et/ou de relations, si le sujet est défini dans les motifs fournis par la configuration de Capture des Données Modifiées (CDC), leurs propriétés seront filtrées selon la configuration.
Voici une simple vidéo qui montre la procédure en action :
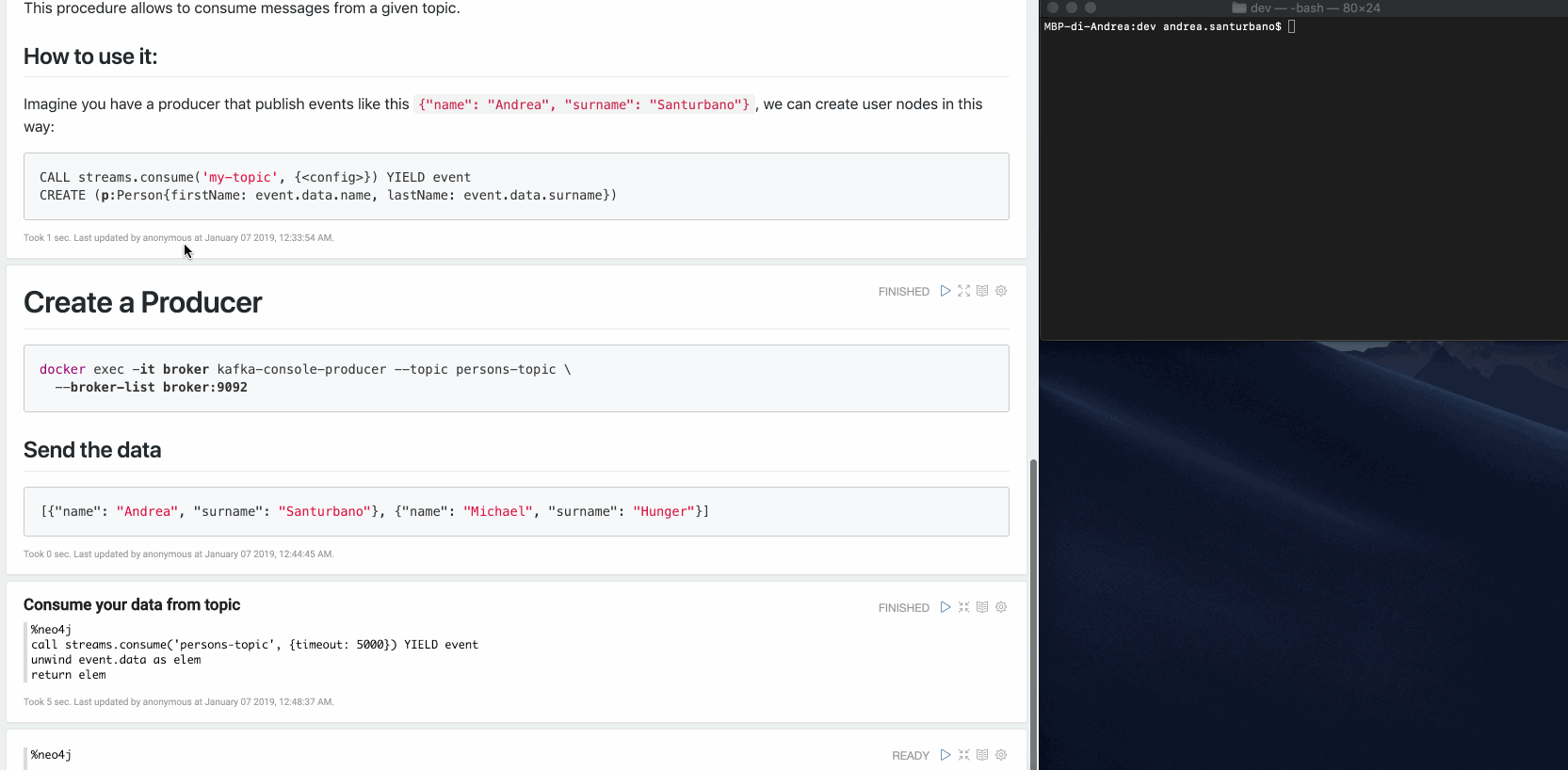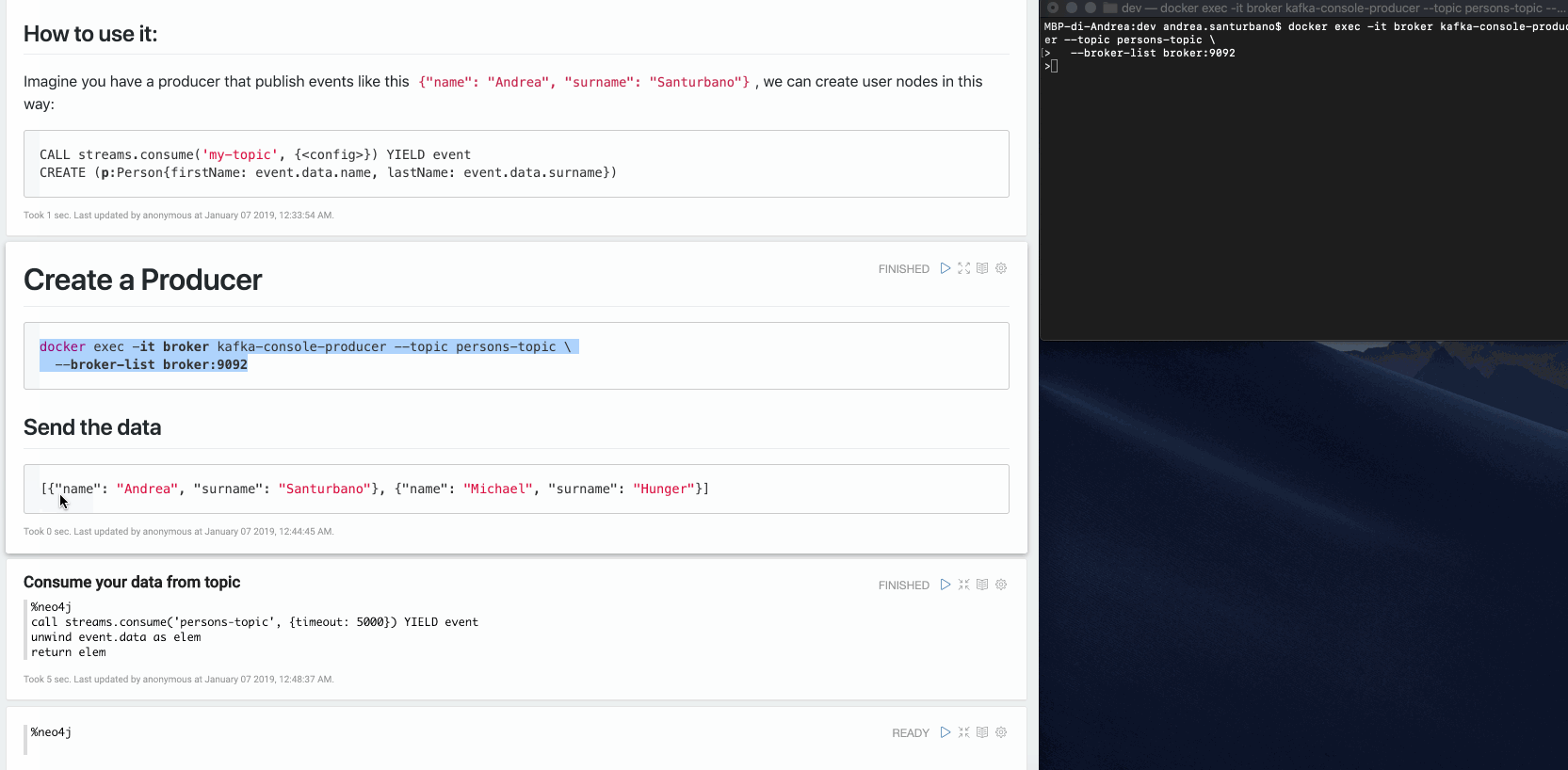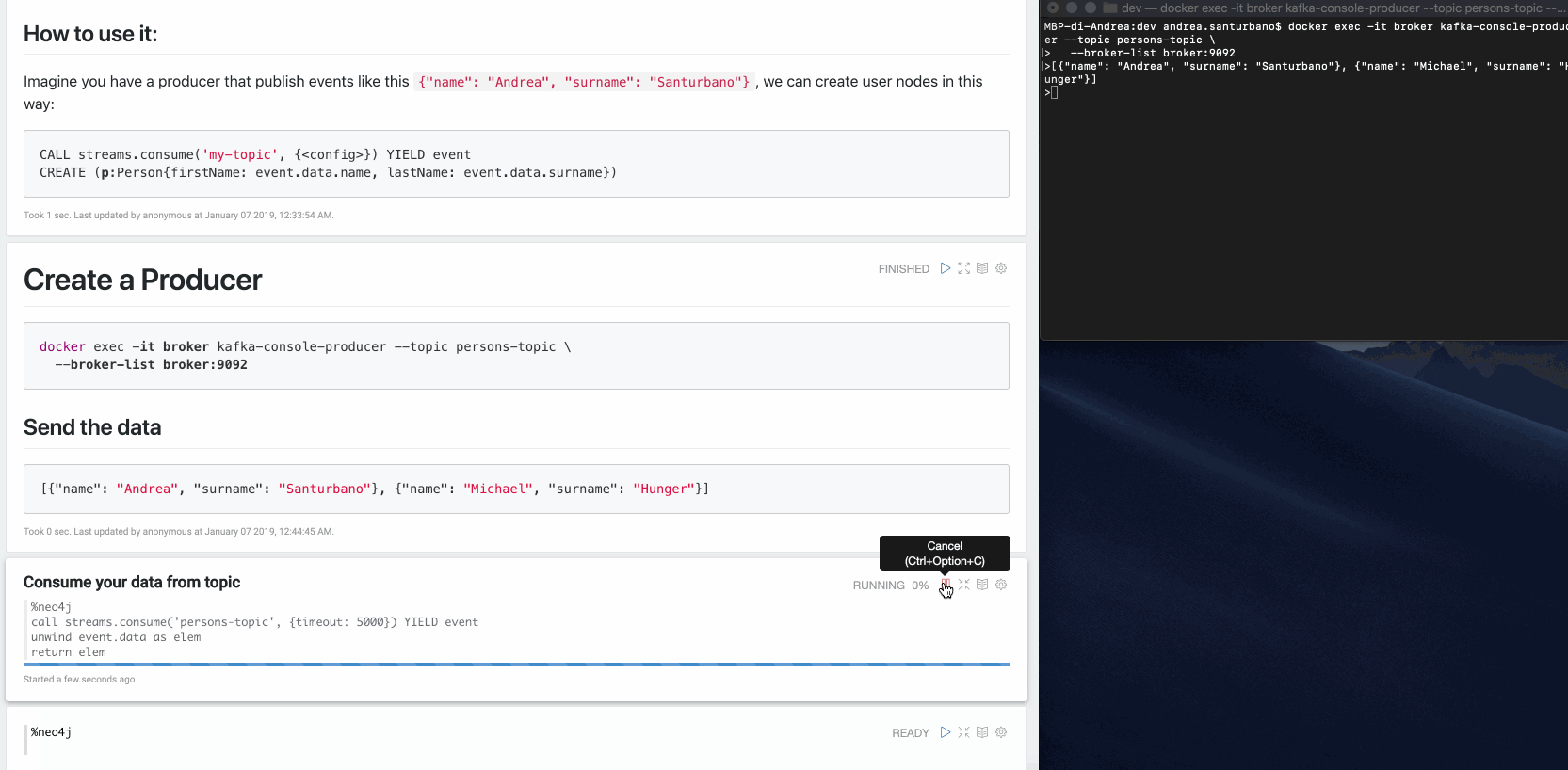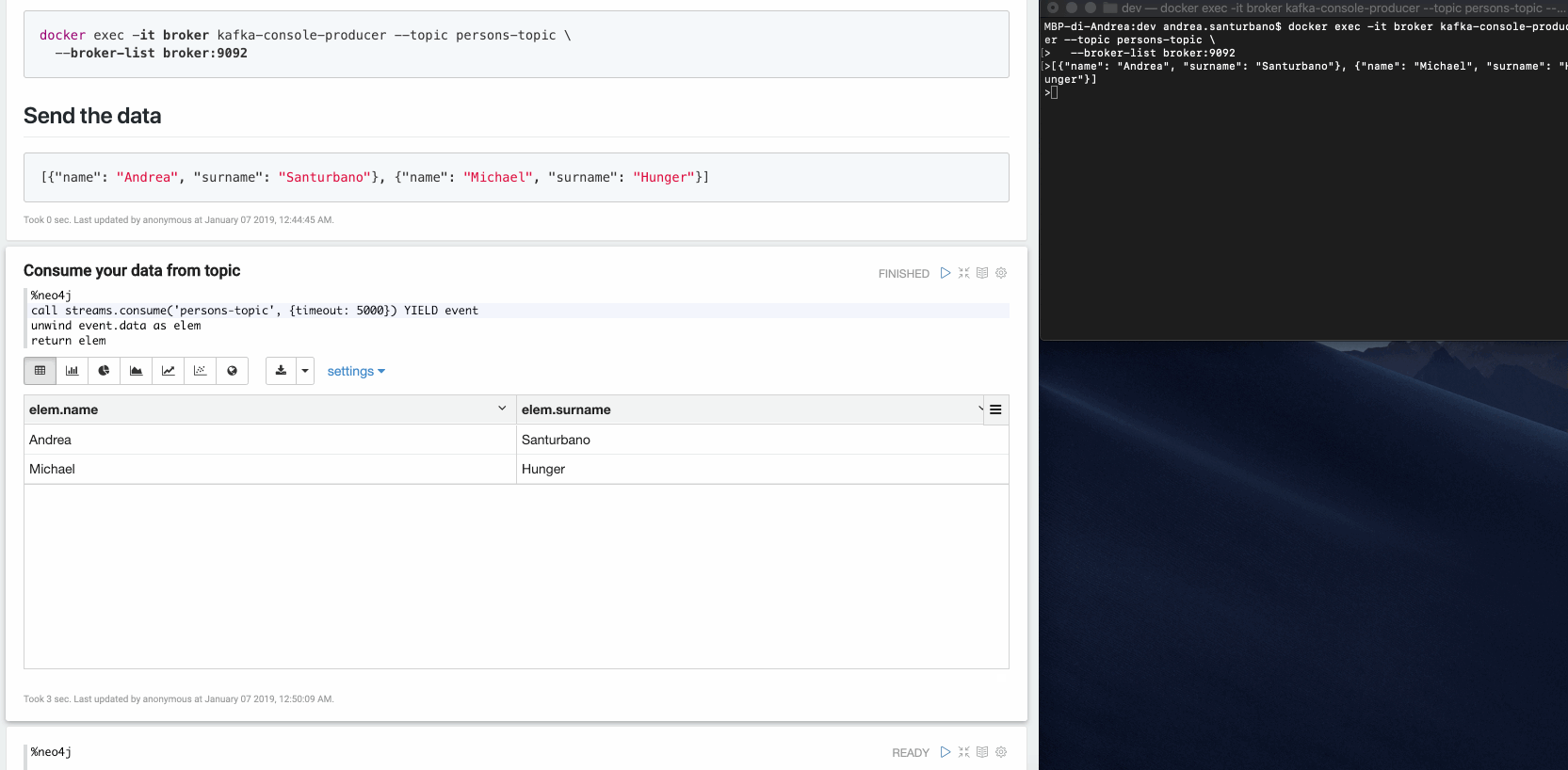
streams.consume
Cette procédure permet de consommer des messages à partir d'un sujet donné.
Elle prend deux variables en entrée :
- topic, type String : où vous souhaitez consommer les données
- config, type Map : les paramètres de configuration
et retourne une liste d'événements collectés.
Les paramètres de config sont :
- timeout, type Long : il s'agit de la valeur passée à la méthode Kafka
[Consumer#poll](https://kafka.apache.org/10/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html#poll-long-)(millisecondes). Par défaut 1000. - from, type String : il s'agit du paramètre de configuration Kafka
auto.offset.reset
Utilisation :
CALL streams.consume('my-topic', {<config>}) YIELD event RETURN event
Exemple : Imaginez que vous avez un producteur qui publie des événements comme ceci :
{"name": "Andrea", "surname": "Santurbano"}
Nous pouvons créer des nœuds utilisateur de cette manière :
CALL streams.consume('my-topic', {<config>}) YIELD eventCREATE (p:Person{firstName: event.data.name, lastName: event.data.surname})
Voici une simple vidéo qui montre la procédure en action :
Nous voici à la fin de la série « Tirer parti de Neo4j Streams », j'espère que vous l'avez appréciée !
Si vous avez déjà testé le module Neo4j-Streams ou l'avez testé via ce notebook, veuillez remplir notre enquête de feedback.
Si vous rencontrez des problèmes ou avez des idées pour améliorer notre travail, veuillez ouvrir une issue GitHub.