

Article original : How to Think Less About Data Visualization
Par Allan Campopiano
Dans votre langue maternelle, vous n'êtes pas conscient de la traduction entre la pensée et la parole. Vous pensez à ce que vous voulez dire et vous le dites. Le chemin de la pensée à la parole semble direct. C'est une cartographie instantanée, 1:1.
En revanche, lorsqu'il s'agit de visualisation de données, il y a souvent plusieurs étapes de traduction consciente entre votre idée d'un graphique et les graphiques réels à l'écran.
Considérez ces exemples courants de traduction :
- Le jeu de données qui sous-tend votre hypothèse nécessite une transformation avant de pouvoir l'afficher sous forme de graphique.
- Votre image mentale du graphique doit être traduite en menus déroulants et cases à cocher dans Excel.
- Vous vous surprenez à parcourir une base de données mentale de signatures de fonctions et d'API (comment faire un diagramme circulaire dans Matplotlib encore ?). Heureusement que vous avez marqué les docs, mais quand même...
Y a-t-il un moyen de penser moins au processus de production de graphiques ? Existe-t-il des heuristiques que nous pouvons suivre pour que la visualisation de données ressemble davantage à la parole dans notre langue maternelle ?
Grâce au travail pionnier du regretté Leland Wilkinson, la réponse à ces questions est Oui.
En 1999, Leland a écrit le livre "The Grammar of Graphics" qui non seulement a introduit une nouvelle façon de raisonner sur les graphiques, mais a également fourni les fondements mathématiques dont nous avons besoin pour écrire des programmes puissants de visualisation de données de haut niveau.
Leland a changé à jamais la façon dont nous pensons à la visualisation de données.
Dans cet article, je vais montrer par l'exemple comment aborder la visualisation de données en utilisant les concepts de The Grammar of Graphics. L'objectif est de fournir une manière structurée et réutilisable de penser qui soutient le passage du graphique dans votre esprit au graphique à l'écran.
En outre, je fournis un cahier dans Deepnote qui contient 30 défis, de difficulté croissante, pour vous aider à tester vos nouvelles connaissances en visualisation de données. Le cahier s'exécute dans le cloud, il est donc prêt à être utilisé immédiatement (aucune installation ou configuration requise).
Comparaison des paradigmes de visualisation
Lorsqu'on pense à la visualisation de données, il faut considérer les paradigmes suivants, en particulier en termes de leur impact sur l'exploration des données.
Pour l'exemple, supposons que vous souhaitez tracer trois catégories sous forme de points sur le plan X-Y (c'est-à-dire un nuage de points coloré).
La visualisation impérative spécifie comment quelque chose doit être fait. Par exemple, commencez par instancier une toile vierge. Utilisez une instruction for loop pour parcourir une liste qui mappe les catégories aux couleurs. Dessinez sur la toile à chaque itération, en sélectionnant les données correctes en fonction du mappage. Définissez les étiquettes des axes et l'emplacement de la légende.
Voici un exemple de visualisation impérative utilisant Matplotlib :
La visualisation déclarative spécifie ce qui doit être fait. Par exemple, dites au programme que vous souhaitez représenter deux colonnes quantitatives sous forme de points X-Y. Une troisième colonne catégorielle sera utilisée pour encoder la couleur.
Voici un exemple de visualisation déclarative utilisant Altair :
Comme vous pouvez le voir ci-dessus, les deux exemples représentent les données de manière similaire. Le chemin pour y parvenir, cependant, est très différent.
Le paradigme impératif est de bas niveau. Il fournit un contrôle fin sur le graphique au prix d'être verbeux. Remarquez que de nombreux détails doivent être spécifiés manuellement (par exemple, l'emplacement de la légende, les étiquettes des axes, etc.).
Le paradigme déclaratif, en revanche, est de haut niveau. Il ne nécessite pas beaucoup d'informations pour produire un graphique (remarquez que des valeurs par défaut sensées sont choisies par le programme sous-jacent plutôt que d'avoir à être explicitement écrites en code).
Cela peut se faire au détriment du contrôle ultime sur chaque détail de la toile. Mais une bonne implémentation de The Grammar of Graphics peut produire une variété impressionnante de graphiques pour de nombreux cas d'utilisation. Les bibliothèques de visualisation déclaratives de haut niveau permettent aux utilisateurs de passer de la pensée au graphique avec moins d'étapes programmatiques.
Comme vous le verrez dans la section suivante, les avantages ne s'arrêtent pas à la réduction des lignes de code. Ils s'étendent à la façon dont nous pensons à la visualisation dès le départ.
La visualisation déclarative vous permet de penser aux données et aux relations, plutôt qu'aux détails incidentels. – Jake VanderPlas (source)
Pourquoi vous devriez éviter les taxonomies de graphiques
Une taxonomie de graphiques est un moyen d'organiser les graphiques en groupes en fonction de leur fonction et de leur apparence. Elles peuvent sembler utiles au premier abord, mais les taxonomies de graphiques peuvent être insidieuses. La manière dont elles regroupent les graphiques est incohérente, bien que perceptuellement cela ne soit pas clair au premier regard.
En d'autres termes, cette méthode de regroupement des graphiques ne suit pas un ensemble bien défini de règles logiques (mathématiques). Je vais expliquer pourquoi cela compte, mais d'abord, laissez-moi fournir deux exemples canoniques de la façon dont une taxonomie de graphiques échoue.
 Taxonomie de graphiques (source)
Taxonomie de graphiques (source)
... et j'en suis venu à réaliser que ces taxonomies de graphiques ne sont pas seulement inutiles, elles sont nocives. – Leland Wilkinson (source)
Les deux graphiques suivants sont considérés comme différents selon les taxonomies de graphiques :
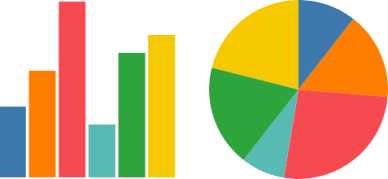
Cependant, les deux graphiques sont en réalité plus similaires que différents. Le graphique de gauche utilise des coordonnées cartésiennes et le graphique du haut utilise des coordonnées polaires. C'est la seule différence.
Examinons le problème opposé. Les deux graphiques suivants sont considérés comme similaires selon les taxonomies de graphiques :
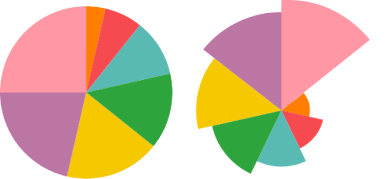
Cependant, à y regarder de plus près, ces graphiques ne sont pas du tout similaires en termes de représentation des données. Le graphique de gauche utilise des angles pour représenter des quantités dans les données. Le graphique de droite, en revanche, utilise la longueur des segments pour représenter les données tout en gardant les angles identiques.
Pourquoi cela compte-t-il ?
Imaginez un programme de visualisation qui utilise sa propre idée de taxonomie de graphiques pour mapper sur des menus GUI et/ou des appels de fonctions. Pour chaque type de graphique défini arbitrairement, le programme devrait avoir un menu/fonction correspondant (par exemple, une fonction pour un diagramme circulaire, une fonction pour un graphique à barres, une fonction pour un histogramme, etc.).
Bien sûr, certaines de ces fonctions pourraient être combinées, mais le diable est dans les détails (c'est-à-dire, quelles règles régissent le fait de donner ou non aux graphiques leur propre fonction ?). Un tel programme finira par devenir incohérent et gonflé, comme le note Wilkinson.
Si, en revanche, nous suivons l'approche de The Grammar of Graphics, qui fournit des règles mathématiques rigoureuses pour raisonner sur la visualisation de données, nous pourrions aboutir à des bibliothèques et des interfaces graphiques plus cohérentes en interne et moins gonflées. Cela les rend plus faciles à utiliser et à maintenir.
Par exemple, regardez ces deux graphiques et leur code associé :
Les deux graphiques sont basés sur les mêmes données sous-jacentes. Malgré le fait que les graphiques aient une apparence visuelle très différente (l'un est un nuage de points, l'autre est un graphique à barres avec agrégation), ils sont produits avec un code remarquablement similaire.
Remarquez que l'API n'est pas gouvernée par une taxonomie de graphiques qui mappe sur un ensemble d'appels de fonctions. En conséquence, si elle est bien implémentée, l'approche basée sur la grammaire permet des API cohérentes et faciles à retenir.
Par exemple, pour de nombreux graphiques statistiques dans Altair, il suffit souvent de retenir seulement deux déclarations pour traduire la pensée en graphiques.
Quelle forme géométrique je veux ?
Barre, cercle, ligne, arc, etc...
Comment je veux représenter les colonnes dans mes données ?
Couleur, forme, taille, position, etc...
En utilisant l'exemple du nuage de points ci-dessus, vous pourriez dire ce qui suit :
Je veux utiliser un cercle comme forme géométrique
Je veux représenter petalLength sur l'axe X, petalWidth sur l'axe Y, et species comme couleur
Si vous comparez le code associé à ces déclarations, vous pouvez voir qu'ils se mappe naturellement l'un à l'autre, sans avoir besoin de beaucoup de traduction entre la pensée, le code et le graphique.
alt.Chart(df).mark_circle().encode(
x='petalLength',
y='petalWidth',
color='species'
)
Appel à l'action
La visualisation basée sur la grammaire n'est pas une panacée. Mais une fois que vous apprenez à penser de cette manière, la création de graphiques peut sembler beaucoup plus naturelle, comme parler une langue.
Les graphiques que vous voyez dans votre esprit peuvent se retrouver à l'écran sans avoir à passer par plusieurs étapes de traduction où le code résultant finit par ressembler très différemment de la façon dont vous décrirez le graphique avec des mots.
Une fois que The Grammar of Graphics fait partie de votre répertoire, vous serez non seulement plus rapide dans l'exploration des données, mais votre raisonnement sur la visualisation des données changera, devenant plus efficace et cohérent.
Ce n'est pas seulement une question d'apprendre un nouvel outil, mais plutôt de changer la façon dont nous pensons à la visualisation des données. Après tout, en reprenant une idée d'une citation célèbre :
Une langue qui n'affecte pas la façon dont vous pensez à la programmation n'est pas digne d'être connue. – Alan J. Perlis
Pour vous lancer dans cette nouvelle façon de penser, j'ai préparé ce cahier dans Deepnote. Le cahier s'exécute dans le cloud, il est donc prêt à être utilisé immédiatement (aucune installation ou configuration requise).
Vous y trouverez 30 défis de Grammar Of Graphics, de difficulté croissante, qui vous attendent. Bonne chance !