
Article original : How to Orchestrate an ETL Data Pipeline with Apache Airflow
Par Aviator Ifeanyichukwu
L'orchestration de données implique l'utilisation de différents outils et technologies pour extraire, transformer et charger (ETL) des données provenant de plusieurs sources vers un dépôt central.
L'orchestration de données implique généralement une combinaison de technologies telles que des outils d'intégration de données et des entrepôts de données.
Apache Airflow est un outil pour l'orchestration de données.
Avec Airflow, les équipes de données peuvent planifier, surveiller et gérer l'ensemble du flux de travail des données. Airflow facilite la gestion des données, l'automatisation des flux de travail et l'obtention d'informations précieuses à partir des données pour les organisations.
Dans ce guide, vous allez écrire un pipeline de données ETL. Il téléchargera des données depuis Twitter, transformera les données en un fichier CSV et chargera les données dans une base de données Postgres, qui servira d'entrepôt de données.
Des utilisateurs ou applications externes pourront se connecter à la base de données pour créer des visualisations et prendre des décisions politiques.
Ce que vous allez apprendre
- Comment extraire des données de Twitter
- Comment écrire un script DAG
- Comment charger des données dans une base de données
- Comment utiliser les opérateurs Airflow
Ce dont vous avez besoin
Pour suivre ce tutoriel, vous aurez besoin des éléments suivants :
- Apache Airflow installé sur votre machine
- Environnement de développement Airflow opérationnel
- Une compréhension des blocs de construction d'Apache Airflow (Tâches, Opérateurs, etc.)
- Un IDE de votre choix. Le mien est VsCode.
Cela semble intéressant, n'est-ce pas ? Commençons.
Comment obtenir les données de Twitter
Twitter est une plateforme de médias sociaux où les utilisateurs se réunissent pour partager des informations et discuter des événements/sujets tendances dans le monde. Des tonnes de données sont générées quotidiennement via cette plateforme. Ce sera votre source de données.
Pour obtenir des données de Twitter, vous devez vous connecter à son API. De nombreuses bibliothèques facilitent la connexion à l'API Twitter. Pour ce guide, nous utiliserons snscrape. Vous aurez également besoin de Pandas, une bibliothèque Python pour l'exploration et la transformation de données.
Installation
Assurez-vous que votre environnement virtuel Airflow est actuellement actif.
pip install snscrape pandas
À l'intérieur du dossier dags d'Airflow, créez deux fichiers : extract.py et transform.py.
extract.py :
import snscrape.modules.twitter as sntwitter
import pandas as pd
from transform import transform_data
# Création d'une liste pour ajouter les données de tweets
def extract_data():
# extraire les tweets et les ajouter à une liste
for i,tweet in enumerate(sntwitter.TwitterSearchScraper('Chatham House since:2023-01-14').get_items()):
if i>1000:
break
tweets_list.append([tweet.date, tweet.user.username, tweet.rawContent,
tweet.sourceLabel,tweet.user.location
])
# convertir les tweets en un dataframe
tweets_df = pd.DataFrame(tweets_list, columns=['datetime', 'username', 'text', 'source', 'location'])
# sauvegarder les tweets en fichier csv
transform_data(tweets_df)
transform.py :
import pandas as pd
from airflow.hooks.postgres_hook import PostgresHook
# Charger les données propres dans la base de données postgres
def task_data_upload(data):
print(data.head() )
data = data.to_csv(index=None, header=None)
postgres_sql_upload = PostgresHook(postgres_conn_id="postgres_connection")
postgres_sql_upload.bulk_load('twitter_etl_table', data)
return True
## effectuer le nettoyage et la transformation des données
def transform_data(tweets_df):
print(tweets_df.info() )
### La transformation se fait ici
# charger les données transformées dans la base de données
task_data_upload(tweets_df)
###
La base de données
Airflow est livré avec une base de données SQLite3. Pour stocker vos données, vous utiliserez PostgreSQL comme base de données.
Vous devez avoir PostgreSQL installé et en cours d'exécution sur votre machine.
Installer les bibliothèques
pip install psycopg2
Si cela échoue, essayez d'installer la version binaire comme ceci :
pip install psycopg2-binary
Installez le package provider pour la base de données Postgres comme ceci :
pip install apache-airflow-providers-postgres
Comment configurer le script DAG
Créez un fichier nommé etl_pipeline.py à l'intérieur du dossier dags.
Commencez par importer les différents opérateurs airflow comme ceci :
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from datetime import datetime, timedelta
with DAG(
'etl_twitter_pipeline',
description="Un simple pipeline ETL Twitter utilisant Python, PostgreSQL et Apache Airflow",
start_date=datetime(year=2023, month=2, day=5),
schedule_interval=timedelta(minutes=2)
) as dag:
start_pipeline = EmptyOperator(
task_id='start_pipeline',
)
start_pipeline
Avec un dag_id nommé 'etl_twitter_pipeline', ce dag est programmé pour s'exécuter toutes les deux minutes, comme défini par l'intervalle de planification.
Comment afficher l'interface Web
Démarrez le planificateur avec cette commande :
airflow scheduler
Puis démarrez le serveur web avec cette commande :
airflow webserver
Ouvrez le navigateur sur localhost:8080 pour afficher l'interface utilisateur.
Recherchez un dag nommé 'etl_twitter_pipeline', et cliquez sur l'icône de bascule à gauche pour démarrer le dag.
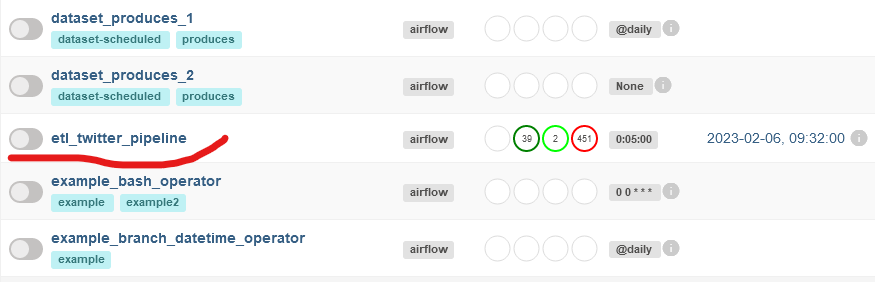 Interface utilisateur Airflow montrant les dags créés
Interface utilisateur Airflow montrant les dags créés
Comment configurer une connexion à une base de données Postgres
Vous devriez déjà avoir apache-airflow-providers-postgres et psycopg2 ou psycopg2-binary installés dans votre environnement virtuel.
Depuis l'interface utilisateur, naviguez vers Admin -> Connections. Cliquez sur le signe plus en haut à gauche de votre écran pour ajouter une nouvelle connexion et spécifiez les paramètres de connexion. Cliquez sur test pour vérifier la connexion au serveur de base de données. Une fois terminé, faites défiler jusqu'en bas de l'écran et cliquez sur Save.
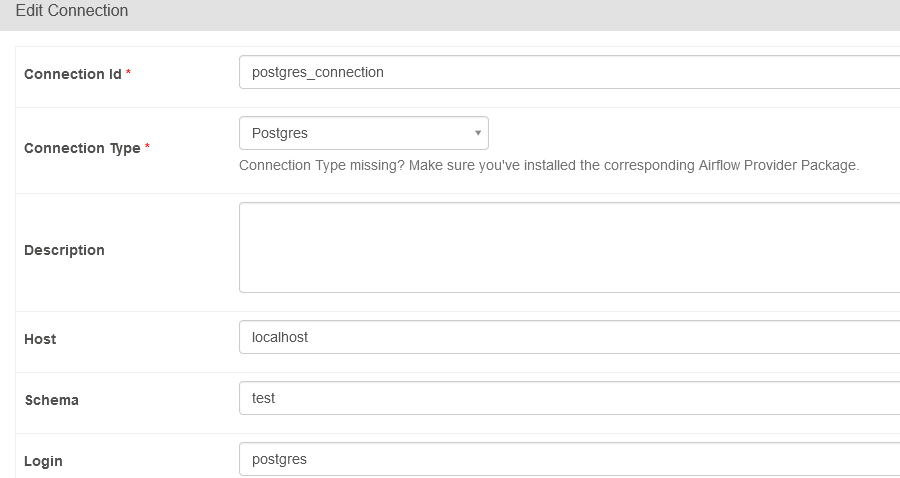 Connexion à la base de données PostgreSQL
Connexion à la base de données PostgreSQL
À l'intérieur du répertoire Airflow créé dans l'environnement virtuel, ouvrez le fichier airflow.cfg dans votre éditeur de texte, localisez la variable nommée sql_alchemy_conn, et définissez la chaîne de connexion PostgreSQL :
sql_alchemy_conn = postgresql+psycopg2://postgres:1234@localhost:5432/test
L'exécuteur Airflow est actuellement défini sur SequentialExecutor. Changez cela en LocalExecutor :
executor = LocalExecutor
 Exécuteur DAG Airflow
Exécuteur DAG Airflow
L'interface utilisateur Airflow est actuellement encombrée d'exemples de dags. Dans le fichier de configuration airflow.cfg, trouvez la variable load_examples, et définissez-la sur False.
load_examples = False
 Désactiver les dags d'exemple
Désactiver les dags d'exemple
Redémarrez le serveur web, rechargez l'interface utilisateur web, et vous devriez maintenant avoir une interface utilisateur propre :
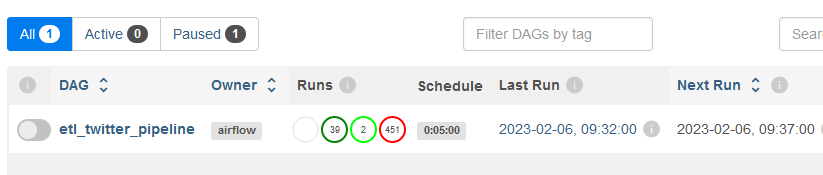 Interface utilisateur Airflow
Interface utilisateur Airflow
Comment utiliser l'opérateur Postgres
Commencez par importer les différents opérateurs Airflow. Vous devrez également importer les fichiers Python extract et transform.
etl_pipeline.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.empty import EmptyOperator
from airflow.operators.postgres_operator import PostgresOperator
from datetime import datetime, timedelta
from extract import extract_data
with DAG(
'etl_twitter_pipeline',
description="Un simple pipeline ETL Twitter utilisant Python, PostgreSQL et Apache Airflow",
start_date=datetime(year=2023, month=2, day=5),
schedule_interval=timedelta(minutes=5)
) as dag:
start_pipeline = EmptyOperator(
task_id='start_pipeline',
)
create_table = PostgresOperator(
task_id='create_table',
postgres_conn_id='postgres_connection',
sql='sql/create_table.sql'
)
etl = PythonOperator(
task_id = 'extract_data',
python_callable = extract_data
)
clean_table = PostgresOperator(
task_id='clean_sql_table',
postgres_conn_id='postgres_connection',
sql=["""TRUNCATE TABLE twitter_etl_table"""]
)
end_pipeline = EmptyOperator(
task_id='end_pipeline',
)
sql/create_table.sql
sql="""CREATE TABLE IF NOT EXISTS twitter_etl_table(
id SERIAL PRIMARY KEY,
datetime DATE NOT NULL,
username VARCHAR(200) NOT NULL,
text TEXT,
source VARCHAR(200),
location VARCHAR(200)
);"""
La tâche create_table établit une connexion à postgres pour créer une table.
La tâche ETL appelle la fonction extract_data() où se déroule notre traitement de données ETL.
La tâche clean_table invoque le postgresOperator qui troncate la table des contenus précédents avant que de nouveaux contenus ne soient insérés dans la table postgres.
La tâche end_pipeline marque la fin de la définition de la tâche.
Comment créer des dépendances entre les tâches
La dernière étape consiste à créer des dépendances entre les tâches, pour permettre à Airflow de connaître l'ordre de priorité pour planifier les tâches.
start_pipeline >> create_table >> clean_table >> etl >> end_pipeline
Comment tester le flux de travail
Pour commencer, cliquez sur le dag 'etl_twitter_pipeline'. Cliquez sur l'option de vue graphique, et vous pouvez maintenant voir le flux de votre pipeline ETL et les dépendances entre les tâches.
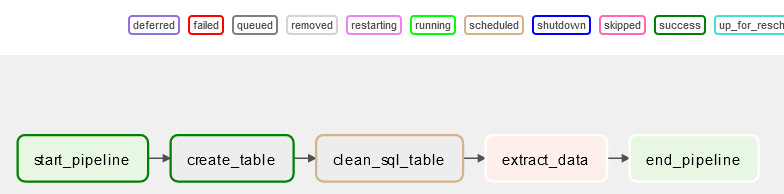 Airflow exécutant le pipeline de données
Airflow exécutant le pipeline de données
Et voilà, votre pipeline de données ETL dans Airflow. J'espère que vous l'avez trouvé utile et que le vôtre fonctionne correctement.
Conclusion
Apache Airflow est un outil d'orchestration facile à utiliser, rendant facile la planification et la surveillance des pipelines de données. Avec vos connaissances en Python, vous pouvez écrire des scripts DAG pour planifier et surveiller votre pipeline de données.
Dans ce guide, vous avez appris comment configurer un pipeline ETL en utilisant Airflow et également comment planifier et surveiller le pipeline.
Vous avez également vu l'utilisation de certains opérateurs Airflow tels que PythonOperator, PostgresOperator et EmptyOperator.
J'espère que vous avez appris quelque chose de ce guide.