

Article original : How to Optimize for Change in Software Development
Par swyx
Imaginez que vous travaillez chez Magic Money Corp, qui fonctionne avec seulement trois lignes de JavaScript :
let input = { step1: 'collecter des sous-vêtements' }
doStuff(input)
profit(input) // $$$!!!
Maintenant, imaginez que quelque chose ne va pas avec doStuff et que vous devez le retirer pour maintenance. Que se passe-t-il si vous commentez temporairement la deuxième ligne ?
Oh non ! profit() génère des erreurs partout. Vous avez cassé votre machine à argent magique !
Pour résoudre ce problème, vous devriez maintenant lire tout le code source de doStuff pour comprendre ce qu'il fait et remplacer le code critique pour que profit fonctionne. Cela semble être beaucoup de travail... peut-être devrions-nous le laisser ainsi et écrire une solution de contournement ?
Lorsque nous avons peur d'apporter des modifications à notre code, il commence à s'ossifier et à gonfler.
Maintenant, imaginons que vous ayez construit Magic Money Corp sur des structures de données immuables à la place (ou utilisé un langage fonctionnel) :
let input = ImmutableMap({ step1: 'collecter des sous-vêtements' })
doStuff(input)
profit(input) // $$$!!!
Cela semble identique, mais maintenant vous pouvez supprimer doStuff sans craindre de casser Magic Money Corp.
Je suis obsédé par le concept de Dan Abramov d'Optimizing for Change depuis qu'il a écrit à ce sujet il y a deux ans. Il articule clairement un principe de conception fondamental de React (les autres sont ici et ici). Pour moi, c'est l'une des 7 leçons qui survivront à React que j'essaie désormais d'appliquer partout ailleurs.
La question principale à laquelle il ne répond pas, cependant, est comment exactement optimiser pour le changement ?
Comment optimiser pour le changement – TL;DR
- Planifier les changements courants
- Utiliser des valeurs simples
- Minimiser la distance d'édition
- Détecter les erreurs tôt
Pourquoi optimiser pour le changement
D'abord, une explication obligatoire de cette idée :
- Le code difficile à supprimer évince le code facile à supprimer avec le temps
- De nombreuses couches de pansements sur du code difficile à supprimer provoquent une momification technique
- Par conséquent, nous devons essayer d'optimiser pour le changement dès la conception initiale
L'inspiration pour cette idée est venue de \"Les systèmes faciles à remplacer ont tendance à être remplacés par des systèmes difficiles à remplacer\" (Malte Ubl) et \"Écrivez du code facile à supprimer, pas facile à étendre\" (tef).
Les fans d'économie reconnaîtront cela comme une application de la loi de Gresham. L'idée est la même — une forme d'anti-entropie où l'inflexibilité augmente, au lieu du désordre.
Ce n'est pas que nous ne savons pas quand nos systèmes sont difficiles à remplacer. C'est que la réponse la plus expéditive est généralement d'ajouter une solution de contournement et de continuer.
Après un trop grand nombre de pansements, notre base de code se momifie. C'est la conséquence de ne pas avoir laissé de place au changement dans nos conceptions originales – une idée liée (mais distincte) à la \"dette technique\" (qui a ses propres problèmes).
La raison pour laquelle nous devons permettre les changements est que la volatilité des exigences est un problème central du génie logiciel.
Nous, développeurs, fantasmons souvent sur le fait que nos vies seraient beaucoup plus faciles si les spécifications des produits étaient, eh bien, entièrement spécifiées à l'avance. Mais c'est la vache sphérique sans frottement de la programmation.
En réalité, la seule constante est le changement. Nous devrions concevoir soigneusement nos abstractions et nos API en reconnaissant ce fait.
Comment planifier les changements courants
Une fois que vous êtes convaincu de la nécessité d'optimiser pour le changement, il est facile d'exagérer et d'être submergé par la paralysie de l'analyse. Comment concevoir pour n'importe quoi quand TOUT pourrait changer ?!
Vous pourriez en faire trop en plaçant, par exemple, des façades abstraites sur chaque interface ou en rendant chaque fonction asynchrone. Il est clair que doubler la taille de votre base de code en échange d'aucune différence dans l'ensemble des fonctionnalités n'est pas souhaitable non plus.
Une façon raisonnable de tracer la ligne est de concevoir pour de petits ajustements courants, et de ne pas s'inquiéter des grandes migrations peu fréquentes. Hillel Wayne appelle cela des perturbations des exigences — les demandes de fonctionnalités petites et typiques ne devraient pas bouleverser toute votre conception.
Pour les esprits enclins aux probabilités, le mieux que nous puissions faire est de nous assurer que notre conception s'adapte bien aux changements de 1 à 3 \"écarts-types\". Les changements plus importants que cela sont rares (par définition) et justifient une réécriture plus invasive lorsqu'ils se produisent.
De cette façon, nous évitons également d'optimiser pour un changement qui pourrait ne jamais arriver, ce qui peut être une source importante de gonflement et de complexité logicielle.
Les changements courants peuvent être accumulés avec l'expérience - l'exemple humoristique en est la loi de Zawinski, mais il existe de nombreux changements beaucoup moins extrêmes qui sont tout à fait routiniers et peuvent être anticipés, que ce soit par la Pluralisation préemptive ou la Stratégie commerciale.
Utiliser des valeurs simples
Une fois que nous avons limité la portée de nos ambitions, j'aime plonger directement dans la réflexion sur la conception des API. L'objectif final est clair. Afin de rendre le code facile à changer :
- il doit d'abord être facile à supprimer
- ce qui le rend ensuite plus facile à couper et coller
- ce qui facilite la création et la décomposition des abstractions
- et ainsi de suite, jusqu'à couvrir toutes les tâches de maintenance courantes, y compris la journalisation, le débogage, les tests et l'optimisation des performances.
Rich Hickey est bien connu pour prêcher la Value of Values et la Simplicity. Il vaut la peine de comprendre profondément les implications de cette approche pour la conception d'API.
Là où vous pourriez passer des instances de classe ou des objets avec des références dynamiques, vous pourriez à la place passer des valeurs simples et immuables. Cela élimine toute une classe de bogues potentiels (et débloque la journalisation, la sérialisation et d'autres avantages).
 la diapositive clé pour Simple vs Complex tirée de "Simple Made Easy"
la diapositive clé pour Simple vs Complex tirée de "Simple Made Easy"
À partir de ces exigences de valeurs simples et non complexifiées, vous pouvez dériver des principes fondamentaux un nombre surprenant de \"meilleures\" pratiques — la programmation immuable, la limitation de l'état avec un noyau fonctionnel, enveloppe impérative, parser, ne pas valider, et gérer la couleur des fonctions.
La recherche de la simplicité n'est pas une proposition sans coût, mais une variété de techniques allant du partage structurel à l'analyse statique peut aider.
Au lieu de mémoriser un tableau de bons/mauvais exemples, la meilleure approche est de comprendre qu'il s'agit tous d'instances de la même règle générale : La complexité naît du couplage.
Minimiser la distance d'édition
Je me représente mentalement les tresses de Simple Made Easy maintenant, chaque fois que je pense à la complexité.

Lorsque vous avez plusieurs cordes les unes à côté des autres, vous pouvez les tresser et les nouer. C'est la complexité — la complexité est difficile à dénouer. Ce n'est que lorsque vous n'avez qu'une seule corde qu'il devient impossible de la tresser.
Plus précisément, nous devrions essayer de réduire autant que possible notre dépendance à l'ordre :
- Ordre d'exécution — Si je supprime quelque chose à la ligne 2, avec quelle facilité le développeur peut-il dire si quelque chose à la ligne 3 va exploser ? Combien de changements dois-je faire pour corriger cela ?
- Ordre de résolution — Si des processus concurrents se résolvent dans le désordre, avec quelle facilité puis-je corriger ou garantir l'absence de conditions de concurrence ?
- Ordre du système de fichiers — Si je déplace du code d'un endroit à un autre, combien d'autres fichiers doivent être modifiés pour refléter cela ?
- Ordre des arguments — Si j'échange la position de certains arguments, que ce soit dans un appel de fonction, un constructeur de classe ou un fichier de configuration YAML, le programme implose-t-il ?
- ceci est une liste ad hoc ; il y en a probablement d'autres importantes que j'oublie ici, n'hésitez pas à me le faire savoir.
Vous pouvez même quantifier cette complexité avec la notion de \"distance d'édition\" :
- Si j'utilise des fonctions à arité multiple, je ne peux pas facilement ajouter, supprimer ou réorganiser des paramètres sans mettre à jour tous les sites d'appel, ou ajouter des paramètres par défaut dont je ne veux pas vraiment. Les fonctions à arité unique/langages avec paramètres nommés ne nécessitent que les mises à jour essentielles et rien de plus. (Cela ne va pas sans compromis bien sûr — plus de discussion ici.)
- Transformer un composant sans état en composant avec état avec React (avant les Hooks) nécessitait l'édition/l'ajout de 7 lignes de code. Avec les React Hooks, cela n'en prend qu'une.
- L'asynchronisme et la dépendance aux données ont tendance à se propager dans une base de code. Si une exigence changeait et que quelque chose en bas devait être asynchrone (par exemple, il a besoin d'une récupération de données), je devais auparavant basculer entre au moins 3 fichiers et dossiers, et ajouter des réducteurs, des actions et des sélecteurs avec Redux pour coordonner cela. Il vaut mieux décomplexifier les relations parent-enfant — un objectif de conception proéminent dans React Suspense, Relay Compiler et le dataloader de GraphQL.
On pourrait même imaginer une mesure de complexité similaire à la formule de spécificité CSS – une complexité de C(1,0,0,0) serait plus difficile à changer que C(0,2,3,4). Ainsi, optimiser pour le changement signifierait réduire le profil de complexité de \"distance d'édition\" des opérations courantes.
Je n'ai pas encore exactement élaboré la formule, mais nous pouvons le sentir lorsqu'une base de code est difficile à changer. Le développement progresse plus lentement en conséquence.
Mais ce n'est que l'effet visible — parce qu'il n'est pas amusant d'expérimenter dans la base de code, les idées novatrices ne sont jamais trouvées. Le coût invisible de l'innovation manquée est directement lié à la facilité avec laquelle on peut essayer des choses ou changer d'avis.
Pour rendre le code facile à changer, rendez impossible le \"tressage\" de votre code.
Détecter les erreurs tôt
Même si nous pouvons essayer de contenir la complexité accidentelle de notre code par la conception d'API et le style de code, nous ne pourrons jamais l'éliminer complètement, sauf pour les programmes les plus triviaux.
Pour la complexité essentielle restante, nous devons garder nos boucles de rétroaction aussi courtes que possible.
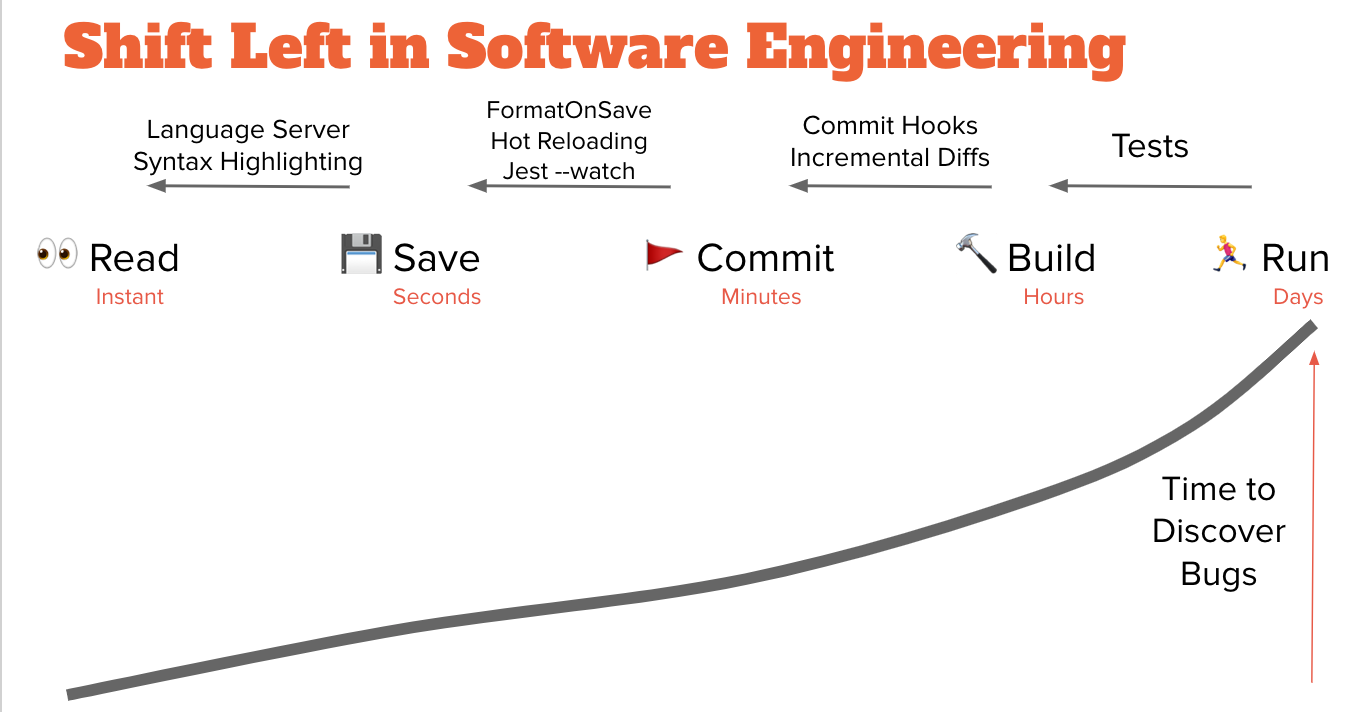
IBM a inventé le terme \"Shift Left\" après avoir découvert que plus on détecte les erreurs tôt, moins elles sont coûteuses à corriger.
Si vous organisez le cycle de vie du développement logiciel de la gauche (conception) vers la droite (production), l'idée est que si vous déplacez vos erreurs vers la \"gauche\", vous économiserez de l'argent réel en détectant les erreurs plus tôt.
(Pour en savoir plus, consultez ma discussion et mes sources dans Language Servers are the New Frameworks).
En termes concrets, cela pourrait se traduire par :
- des tests unitaires qui identifient ce qui a cassé dans votre code lors d'un refactoring
- des types qui codifient les contrats entre les données et les fonctions
- des déploiements continus qui prennent moins de 15 minutes (vous avez probablement des gains faciles à réaliser en frontend ou backend)
- des serveurs de développement locaux qui émulent votre environnement cloud
- des valeurs \"en direct\" fournies soit par des Language Servers, des plugins d'éditeur ou des enregistrements de replay
La causalité peut être bidirectionnelle. Si vous facilitez le changement des choses, vous pourrez effectuer des changements plus fréquemment.
Mais cela pourrait aussi fonctionner dans l'autre sens — parce que vous vous attendez à faire des changements fréquents, vous êtes plus incité à rendre les choses faciles à changer.
Un exemple extrême de cela implique non seulement le code, mais aussi la communauté. Plus une bibliothèque (ou un langage) reste longtemps en version 1, plus il est difficile de passer à la version 2. Tandis que les écosystèmes qui publient régulièrement des versions majeures (en échange d'améliorations claires) semblent éviter la stagnation par simple exposition.
Une mise en garde contre trop de changement
Toute bonne idée devient mauvaise lorsqu'elle est poussée à l'extrême. Si vous changez les choses trop, vous risquez de favoriser la vélocité au détriment de la stabilité — et la stabilité est tout à fait une fonctionnalité sur laquelle vos utilisateurs et consommateurs de code comptent.
La loi de Hyrum garantit qu'avec suffisamment d'utilisateurs et de temps, même vos bogues seront exploités, et les gens seront mécontents si vous les corrigez.
Cela dit, dans l'ensemble, je trouve qu'Optimiser pour le changement est un gain net dans mes décisions de programmation, de produit et de conception de système, et je suis heureux de l'avoir résumé en quatre principes :
- Planifier les changements courants
- Utiliser des valeurs simples
- Minimiser la distance d'édition, et
- Détecter les erreurs tôt.
Merci de m'avoir lu !