

Article original : How Not to Break Production – My Two Big Coding Mistakes and How to Avoid Them
Par John Mosesman
Dans cet article, je vais partager avec vous mes deux plus grosses erreurs en production.
Heureusement, il n'y en a que deux.
Ce n'est pas que je n'ai pas fait une tonne d'erreurs en production—j'en ai fait—mais ces deux-là en particulier ont nécessité que moi et le reste de l'équipe unissions nos efforts pour réparer les dégâts.
Quand votre erreur prend une journée entière à une équipe de cinq personnes pour la corriger, cela a tendance à rester gravé dans la mémoire.
Je n'ai pas honte de ces erreurs—c'était un peu embarrassant sur le moment, c'est sûr—but ce furent des erreurs honnêtes et les erreurs arrivent.
Je partage ces histoires avec vous pour que vous sachiez quoi faire quand vous casserez inévitablement quelque chose en production. Et si vous restez assez longtemps dans le monde du développement, cela arrivera.
Mais personne n'a besoin de perdre la tête. [Spoiler alert] Je n'ai pas été viré de l'un ou l'autre de ces emplois, et je n'ai même pas vraiment été réprimandé. Les gens font des erreurs et les autres membres de votre équipe et de votre entreprise le comprennent.
Tester, espérer et prier
Avec le temps, le monde du développement a adopté des pratiques pour aider à réduire les chances et la gravité des erreurs.
Nous écrivons des tests automatisés. Nous testons les changements dans un environnement de staging. Nous faisons des revues de code. Nous systématisons ou scriptons nos processus de déploiement.
Toutes ces pratiques attrapent ou écrasent un nombre incalculable de bugs chaque jour.
Mais, malgré toutes ces pratiques et processus, les erreurs arrivent encore. Au final, nous sommes toujours humains, et les humains font des erreurs.
Nous manquons des cas limites. Nous oublions de vérifier la mise en page dans IE9. Nous supprimons le mauvais enregistrement. Nous faisons tomber la moitié d'Internet en passant le mauvais paramètre à un script de déploiement.
Les erreurs que je partage avec vous se situent quelque part au milieu de celles-ci, et la première commence avec mon tout premier emploi en développement.
Premier emploi – première erreur.
J'ai fait la première de ces erreurs lors de mon tout premier emploi en développement.
Je n'étais à ce poste que depuis peut-être un an, et l'équipe sur laquelle j'étais construisait des applications internes pour aider à alimenter le reste du travail que l'entreprise faisait.
Nous avons construit des outils de support et de gestion client, mais nous avons également configuré et géré les bases de données et les services web construits sur ces bases de données qui alimentaient les produits de l'entreprise.
En bref, nous étions responsables de nombreuses requêtes SQL vraiment importantes et (trop) complexes.
C'était mon premier emploi de développeur, et je me battais pour apprendre SQL aussi vite que possible.
Nous avions un environnement QA ("assurance qualité") aka un environnement de test avec une copie de chaque base de données pour tester, et les nouveaux développeurs comme moi n'avaient pas de permissions d'écriture sur les bases de données de production (et à juste titre).
Pour faire une modification en production, je devais d'abord écrire et tester la requête contre ma base de données locale.
Après avoir cru qu'elle était bonne localement, je devais alors demander une revue de "code" à un membre de l'équipe plus expérimenté qui examinerait la requête et, si elle était solide, exécuterait les migrations structurelles dans l'environnement QA. Après cela, je pouvais alors tester à nouveau en QA.
Une fois que j'étais confiant que ma requête fonctionnait en QA, je devais alors demander une autre revue de code et demander que la requête soit exécutée en production.
Tout va bien, non ? Beaucoup de place pour pratiquer et beaucoup de points de contrôle pour s'assurer que les choses qui passent en production sont solides.
Mettre mes grands pantalons
Après un certain temps à répéter ce processus avec succès, j'ai commencé à obtenir un accès en écriture à quelques-unes de ces bases de données—celles avec lesquelles j'étais familier et qui étaient directement pertinentes pour mon travail.
J'avais prouvé que j'étais prudent et que l'on pouvait me faire confiance avec l'accès à la production (vous savez déjà où cela mène).
Si vous n'êtes pas familier avec SQL, il existe quelques types différents de requêtes que vous pouvez exécuter.
Parfois, vous voulez simplement récupérer des informations, et parfois vous voulez insérer, mettre à jour ou supprimer des informations.
La majorité des requêtes que vous écrivez sont des SELECT—requêtes pour récupérer des informations. Seulement occasionnellement faites-vous un INSERT, UPDATE ou DELETE.
Donc, la plupart du temps, vos requêtes sont inoffensives. Un SELECT ne change aucune donnée, et il n'y a aucun risque que quelque chose aille mal.
Mais, parfois, vous devez changer ces données—et c'est là que vous devez être vraiment très prudent.
Un UPDATE qui a mal tourné
Je ne me souviens même pas de la tâche que je faisais ou pourquoi je la faisais.
La seule chose dont je me souviens maintenant était cette maudite instruction UPDATE.
Je mettais à jour quelque chose qui impliquait des informations client—mettre à jour quelque chose comme leur nom, email ou adresse.
J'avais écrit une instruction que je croyais correcte, et je la testais en tant que SELECT :
--UPDATE users SET name = 'blah', ...
SELECT * FROM users
WHERE ...
Remarquez l'instruction UPDATE qui est commentée au-dessus du SELECT. C'était un format pratique que j'ai appris à ce travail et qui aidait à réduire les erreurs lors de l'exécution de vos requêtes.
D'abord, vous écrivez une instruction UPDATE commentée avec les valeurs que vous voulez définir. Ensuite, vous écrivez un SELECT en dessous de cette instruction et utilisez le SELECT pour tester et finaliser le résultat de la requête.
En commentant la première instruction, vous éliminez la possibilité d'exécuter accidentellement l'UPDATE avant d'être prêt. La seule façon d'exécuter l'instruction est soit de la décommenter (ce qui prend une action), soit en surlignant le texte après le commentaire avec le reste de la requête puis en l'exécutant (ce qui est aussi une action délibérée).
Cette petite technique prévient de nombreuses erreurs. Mais revenons à mon écriture de requête.
Quand j'étais prêt, tout ce que j'avais à faire était de décommenter la ligne UPDATE, commenter la ligne SELECT, et appuyer sur exécuter.
Maintenant, l'exemple d'instruction que j'ai montré ci-dessus est grandement simplifié par rapport à la requête que j'avais écrite à l'époque.
L'instruction que j'avais écrite à l'époque était une instruction assez complexe. Elle avait beaucoup de jointures, de sous-requêtes, et vérifiait une certaine plage de commandes ou de produits ou autre chose—pas juste un simple WHERE id = blah.
Elle ressemblait probablement plus à ceci :
--UPDATE users SET name = 'blah', ...
SELECT * FROM users
JOIN something
ON something.user_id = users.id
JOIN another_thing
ON another_thing.something_id = something.id
WHERE 1=1
AND something.blah = 'bleh'
AND another_thing.bleh = 'blah'
OR (
users.name <> 'Karen'
AND thing = thing
);
(Ce n'est pas une histoire de "le poisson était si gros" je vous le jure.)
J'ai vérifié que les utilisateurs que j'ai obtenus étaient ceux que j'attendais. Je l'avais vérifié localement, testé en QA, et j'avais obtenu l'approbation d'un membre de l'équipe pour l'exécuter en production (voir ce n'était pas de ma faute (je plaisante)).
Voici où le problème survient. Et avant de vous dire ce que c'est, je vais vous donner un petit conseil pro qui vous empêchera que cela ne vous arrive jamais.
Lorsque vous exécutez une requête qui effectuera une écriture dans la base de données : faites glisser votre curseur du bas de la requête vers le haut de la requête.
Pourquoi la faire glisser du bas vers le haut, dites-vous ? Bonne question.
De bas en haut
Supposons que je commence au bas de cette requête et que je fasse glisser mon curseur vers le haut à moitié et que j'exécute la requête :
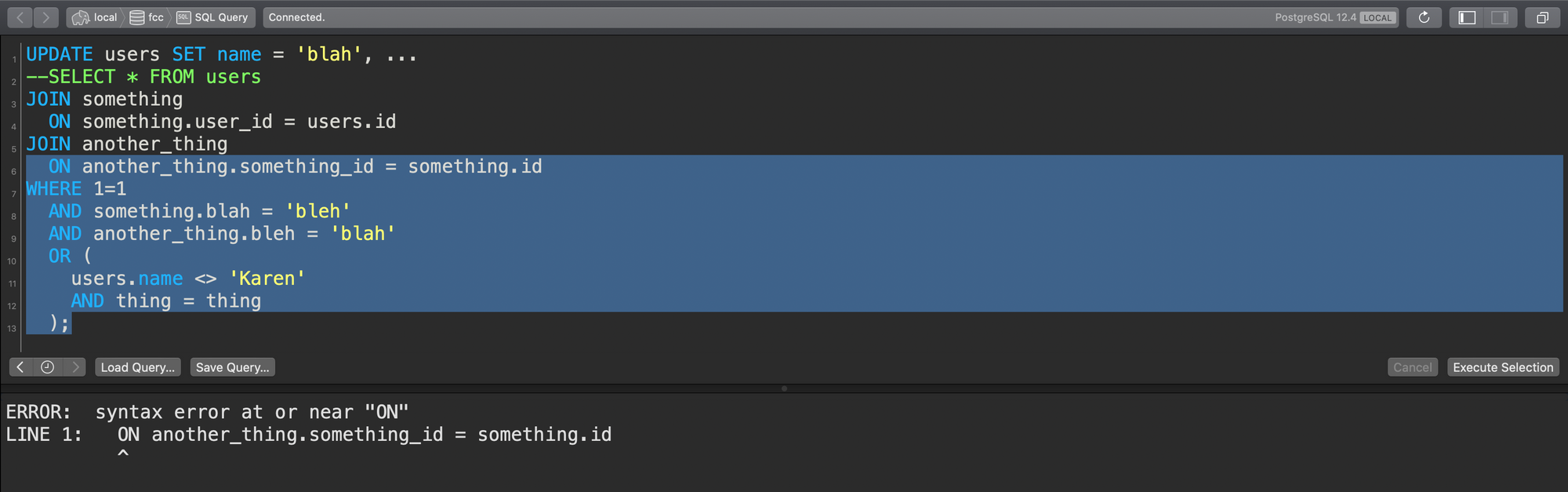 Glisser de bas en haut mais incomplet
Glisser de bas en haut mais incomplet
Que se passe-t-il ?
Eh bien, rien.
Je n'ai pas sélectionné une requête valide. L'analyseur de requête lancera une erreur et dira silly John ce n'est pas une requête valide, tu es un silly goose.
Oh merci analyseur de requête ! Pas de gros problème. J'essaierai à nouveau :
 Glisser de bas en haut complet
Glisser de bas en haut complet
Maintenant, j'ai sélectionné la requête complète, et elle s'exécute. Youpi !
Tout va bien, non ?
Maintenant, que se passe-t-il si vous travaillez sur cette requête et que, en raison de la taille de votre fenêtre ou de la position de défilement de votre outil de requête, vous commencez en haut de la requête et faites glisser vers le bas...
 Glisser de haut en bas avec ce que vous pensez être la requête complète
Glisser de haut en bas avec ce que vous pensez être la requête complète
Cette requête s'exécute—mais oops ! Le reste de la requête était en dehors de ma zone visible, et je n'ai inclus que la moitié de ma clause WHERE !
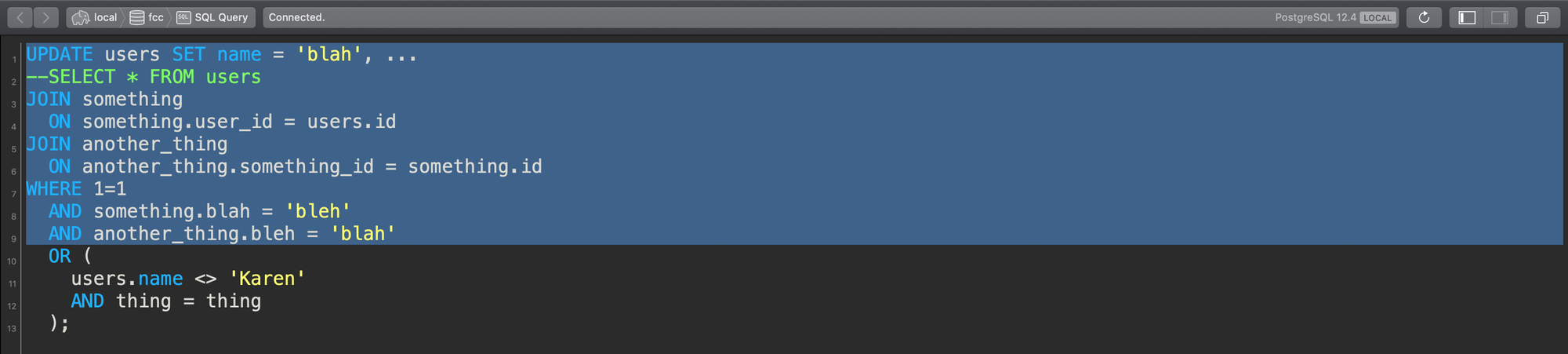 Glisser de haut en bas mais en manquant une partie de la requête !
Glisser de haut en bas mais en manquant une partie de la requête !
Et juste comme ça, cela arrive. L'UPDATE tourne mal.
C'est exactement ce que j'ai fait.
J'ai exécuté une partie de la requête, et elle manquait certaines des conditions de filtrage pour limiter correctement l'ensemble de résultats sur lequel j'agissais, et j'ai fini par mettre à jour toute la table users avec les informations d'une seule personne.
Chaque utilisateur de notre système était maintenant "John Smith au 1234 Main Street Ave".
J'avais fait une erreur, et j'ai réalisé le problème trop tard.
Alors, qu'ai-je fait ?
"Les secrets secrets ne sont pas amusants. Les secrets secrets font du mal à quelqu'un." - The Office S03E15
Voici la première leçon majeure (en plus de ce conseil sucré de requête "de bas en haut") : si vous faites une erreur—dites-le à quelqu'un. Immédiatement.
Il peut être très tentant d'essayer de cacher ou d'ignorer l'erreur que vous avez faite—surtout si elle est grave. J'ai été là. J'ai ressenti ces impulsions.
Vous réalisez votre erreur et la crainte s'installe. Oh non, qu'ai-je fait.
Quand cela arrive, il y a quelques choses à retenir :
- Chaque développeur d'expérience raisonnable a fait des erreurs en production
- Beaucoup de ces erreurs sont sensibles au temps
- Je ne connais personne qui a été viré pour une erreur honnête
Chaque développeur a fait des erreurs en production. J'en ai fait, et j'en referai (mais espérons pas les mêmes). Quiconque vous critiquerait pour cela est soit inexpérimenté, soit un imbécile. Dans les deux cas, vous ne devriez pas vous en soucier.
Beaucoup de ces erreurs sont aussi "sensibles au temps". Cela signifie que plus vous pouvez corriger le problème ou annuler le changement rapidement, moins de dégâts seront causés. Attendre pour reconnaître le problème peut entraîner un processus plus difficile pour le corriger.
De toutes les erreurs que j'ai faites et de toutes les erreurs que j'ai vues les autres faire, je ne connais pas une seule personne qui a été virée ou même sérieusement réprimandée pour une erreur honnête.
Je pense que c'est parce que la programmation est difficile et que quiconque est arrivé à un poste de direction a fait quelque chose de similaire ou pire.
Alors voici ce que vous faites :
- Assumez-en la responsabilité
- Assumez-en la responsabilité rapidement
- Travaillez pour aider à la corriger
Assumez la responsabilité de l'erreur. Ne rejetez pas la faute ou ne faites pas d'excuses—expliquez simplement ce qui s'est mal passé et ce que vous avez vu ou fait.
Alertez votre patron ou le responsable de l'équipe dès que vous reconnaissez le problème. La gravité de l'alarme que vous déclenchez est probablement proportionnelle à la taille de l'erreur.
"Oups, j'ai fait une erreur dans la validation de ce champ, je suis passé à l'étape suivante et j'ai fait une autre PR pour la corriger."
Si c'est une petite chose, peut-être pouvez-vous simplement faire une nouvelle PR pour la corriger et dire à quelqu'un de la réviser. Petit problème, petite correction—pas de gros souci.
Si, par hasard, vous mettez à jour une table de production avec une valeur unique dans toute la table—vous déclenchez l'alarme rapidement.
Mettre à jour une table entière
Dès que le oh non s'est installé, j'ai attrapé mon responsable d'équipe et lui ai dit ce qui s'était passé.
Heureusement, il a été cool à ce sujet, et nous nous sommes mis au travail pour essayer de l'annuler.
Le problème avec une mauvaise mise à jour de base de données est qu'il n'y a pas vraiment de moyen facile de revenir en arrière. Vous ne pouvez pas simplement annuler quelques commits et redéployer—une base de données est un stockage persistant pour une raison.
Quand quelque chose ne va pas avec les données, vous avez quelques options :
- Écrire une nouvelle requête pour annuler les données (si possible)
- Charger une sauvegarde de la base de données et trouver les bonnes données, les extraire et exécuter une nouvelle mise à jour
- Partir pour le Mexique
Bien que l'option #3 soit tentante, nous avons choisi l'option #2.
Cela s'est passé il y a presque dix ans, donc le devops était un peu différent à l'époque.
Cette entreprise gérait ses propres serveurs et bases de données et avait des "sauvegardes sur bande". Ils ne gardaient aussi que des sauvegardes quotidiennes, donc au mieux nous pouvions obtenir des données du début de la veille.
Inutile de dire que cela allait être douloureux.
Pour faire court, nous avons essayé de voir s'il y avait un moyen de recréer les données originales et de les mettre à jour à nouveau. Après quelques heures, nous avions les données revenues à leur état d'origine—mais ce n'est pas la partie importante de l'histoire.
La partie importante est d'admettre l'erreur. Essayer de la corriger. Apprendre et ne pas laisser cela se reproduire.
Si vous faites une erreur, vos coéquipiers apprécieront grandement que vous travailliez activement à essayer de la corriger. Même si cela consiste simplement à vous associer et à les regarder corriger le problème, plongez-vous et prenez part.
Enfin, apprenez de cette erreur et ne faites pas deux fois la même erreur.
(Glissez de bas en haut.)
Erreur #2 : 7 ans plus tard...
Après cette période, j'ai profité d'une longue période sans erreur d'environ sept ans—au moins pour les erreurs majeures.
Maintenant, sept ans plus tard, au lieu du titre Développeur Junior, je portais le chapeau brillant de Ingénieur Logiciel Senior (wooOoOo).
C'était juste une journée normale. Écrire du code, le pousser, des revues de code, déployer—juste un écrasement général des codes.
J'ai reçu un ping sur Slack concernant un tas de travailleurs en arrière-plan qui échouaient. Mon collègue a dit que cela semblait lié à ma dernière PR que j'avais récemment fusionnée.
"Ok merci, je vais vérifier", ai-je répondu.
Oui, il y avait définitivement un bon nombre de jobs qui échouaient et ils s'accumulaient.
Je n'étais pas trop alarmé. Les jobs en arrière-plan sont généralement écrits de manière "idempotente"—ils sont généralement sûrs à réexécuter lorsqu'ils échouent. La plupart des systèmes de mise en file d'attente en arrière-plan ont également un moyen intégré de réessayer automatiquement les jobs après leur échec.
Ce n'est pas longtemps après cela, cependant, que les choses ont pris un tournant pour le pire.
Les alarmes ont commencé à sonner—ou plus réalistement—les notifications Slack dans la salle de garde ont commencé à retentir.
Dépassements de délai après dépassements de délai après dépassements de délai. L'utilisation de la base de données atteignait 100%. Tout le système arrivait à un point mort. Tous les produits de l'entreprise s'arrêtaient.
Oh non.
Je ne savais pas pourquoi cela arrivait, mais je savais que c'était grave.
Et donc j'ai fait la seule chose que je savais faire : me déconnecter et partir pour le Mexi—je veux dire, le dire à quelqu'un immédiatement.
Nous avons sauté dans un appel Zoom (avant que Zoom ne soit connu de toute la planète merci 2020).
Alors que nous enquêtions sur le problème, nous avons remarqué qu'une requête particulière prenait un temps vraiment long à se compléter.
Chaque instance de cette requête prenait plusieurs minutes à s'exécuter, et il y avait un nombre toujours croissant de celles-ci qui étaient lancées chaque minute.
Nous avons commencé à regarder les commits récents dans la partie de la base de code d'où le problème semblait provenir et nous avons trouvé quelque chose de suspect : ma dernière pull request.
Dans cette pull request, j'ai mis à jour un job en arrière-plan et changé son comportement.
Ce projet était une base de code Ruby on Rails, et le changement que j'ai fait était quelque chose comme ceci—mais si vous n'avez jamais vu Rails auparavant, ne vous inquiétez pas, je vais expliquer chaque ligne :
def run(some_status)
items = Item.where(status: some_status).all
items.each do |item|
# faire quelques requêtes et mises à jour de la base de données
end
end
Ce job en arrière-plan appelle une fonction, run, et une valeur de statut est passée en tant que paramètre (some_status).
La première ligne de la fonction interroge certains enregistrements de la base de données.
Cette ligne utilise des méthodes de la partie ActiveRecord du framework Rails, mais ce ne sont vraiment que des enveloppes sympas autour de requêtes SQL basiques.
items = Item.where(status: some_status).all
Cette ligne est vraiment juste une simple instruction SQL :
SELECT *
FROM items
WHERE status = ?
Lorsque la requête est exécutée, la valeur de some_status est liée au placeholder (?) dans la requête puis exécutée.
Après que la base de données retourne les résultats de la requête, Rails prend ces enregistrements et crée de beaux et nets objets Ruby.
Donc en résumé, nous interrogeons la table items où le status est une certaine valeur.
(Encore une fois, ce n'est probablement pas exactement ce que je faisais mais c'est assez proche pour illustrer le scénario.)
Les lignes suivantes sont une simple boucle sur les éléments que nous avons récupérés, et pour chaque élément, nous faisons quelques requêtes supplémentaires sur la base de données puis mettons à jour certaines informations sur l'élément.
items.each do |item|
# faire quelques requêtes sur la base de données
# puis mettre à jour l'élément
end
Assez simple, non ? Obtenez les trucs. Bouclez sur les trucs. Mettez à jour les trucs.
Cependant, il y a une chose que je n'ai pas réalisée ici—et c'est une grosse.
Petit NULL—ou nil
Le champ status n'a pas de contrainte NOT NULL. Cela signifie que le champ status peut être NULL—ou dans le monde Ruby : nil (ou null dans d'autres langues).
Il est facile de s'habituer à interroger des choses comme les IDs que vous savez toujours présents. Une ligne similaire comme...
items = Item.where(id: list_of_ids).all
...n'aurait pas produit le même problème. Une requête recherchant des enregistrements par leur ID avec une liste vide d'IDs retourne rien, et donc rien n'est fait.
Mais dans ce cas, voici le problème. Cette partie du code :
items = Item.where(status: some_status).all
Recherche tous les enregistrements Item par un statut spécifique—celui passé via le paramètre some_status.
Mais, cette valeur de colonne peut être NULL (ou nil).
Donc, si le paramètre some_status se trouve être passé comme nil, il essaierait de rechercher tous les enregistrements Item où status = nil.
D'accord, mais cela ne semble pas si grave, non ?
Eh bien, la couche suivante de cet oignon d'horreur est le fait que cette table items contenait 40 millions de lignes—et la plupart d'entre elles n'avaient pas de statut.
Cette petite fonction qui essayait à l'origine de charger quelques enregistrements, de boucler dessus et de faire un peu de travail bouclait maintenant sur toute la table.
Donc, lorsque chacune de ces centaines ou milliers de jobs qui étaient lancées à intervalles réguliers (si je me souviens bien, environ toutes les 15 minutes) démarrèrent, chacune d'elles commença à effectuer des requêtes très coûteuses pour presque chaque enregistrement de la table.
Cela seul aurait probablement suffi à faire couler le système, mais cela s'est en réalité aggravé.
Vous voyez, je ne m'attendais pas à ce qu'une valeur nil soit passée. Cette valeur nil a également cassé une partie du code que le job était censé exécuter, et donc chacun de ces jobs a commencé à échouer à son tour.
Normalement, ce ne serait pas un gros problème, mais dans la plupart des systèmes, lorsqu'un job en arrière-plan échoue, il est remis en file d'attente peu de temps après.
Donc, non seulement tous ces jobs très coûteux échouent, mais ils échouent tous et redémarrent peu de temps après—et ils continuaient à s'accumuler.
Les jobs en échec finiraient par être confrontés à un nouveau lot de jobs démarrant sur leur propre intervalle, et le système s'est simplement arrêté.
La dernière goutte est que le travail que ce job en arrière-plan était censé faire était mettre à jour tous ces enregistrements.
Cela signifiait que je bouclais sur chaque enregistrement de cette table et mettais à jour toute la table avec de mauvaises données.
Par pure chance, j'avais une grâce salvatrice ici.
Le résultat de cette requête n'était pas ordonné. Cela signifie que par défaut, les enregistrements les plus anciens (ou les premiers) de la table étaient retournés en premier.
Cela peut ne pas sembler pertinent, mais les premiers et plus anciens enregistrements étaient effectivement des données héritées—donc mettre à jour ces enregistrements n'était pas près d'être aussi grave que les enregistrements avec lesquels les clients interagissent chaque jour.
De plus, le job continuait à planter tôt dans son exécution et à redémarrer—ce qui a entraîné les jobs à ne mettre à jour que la même petite et ancienne portion de la table encore et encore.
Cela signifiait que ces jobs n'atteignaient jamais les lignes plus récentes et plus pertinentes de la table.
En gros, le job ne mettait à jour qu'une petite portion insignifiante de la table avant de s'arrêter et d'essayer à nouveau (si je me souviens bien, seulement quelques milliers de lignes sur les ~40 millions).
C'était comme si j'avais métaphoriquement trébuché et était tombé en marchant vers un passage piéton—ce qui m'a empêché d'être frappé par la voiture qui allait brûler le stop.
Une solution simple
Alors que nous passions en revue ma PR lors de l'appel Zoom, quelqu'un a finalement trouvé l'erreur et pointé la ligne fautive (la requête recherchant les enregistrements par leur status).
Même après qu'ils aient dit le problème à voix haute, je ne l'ai toujours pas vu. Après qu'ils aient essayé de l'expliquer à nouveau (et peut-être même une autre fois), cela a enfin cliqué.
C'est une ligne de code trompeuse comme celle-ci :
items = Item.where(status: some_status).all
Rechercher l'élément par son statut—semble bien. Si vous n'êtes pas prudent, vous ferez comme moi et manquerez la recherche avec le cas critique nil.
Heureusement, la correction pour cela est vraiment facile. Protégez la fonction et faites un retour rapide comme ceci si le statut est nil :
def run(some_status)
return if some_status.nil?
items = Item.where(status: some_status).all
...
end
Si vous n'êtes pas familier avec Ruby et Rails, cette ligne unique est juste un peu de sucre syntaxique pour ceci :
def run(some_status)
if some_status == nil
return
end
items = Item.where(status: some_status).all
...
end
En gros, si some_status est nil, retournez simplement tôt de la fonction et sortez de là, mon ami.
C'est la correction que nous avons finie par déployer, et après quelques redémarrages de serveur et l'arrêt de la file d'attente croissante de jobs en arrière-plan et de requêtes longues, les choses sont finalement revenues à la normale.
Puisque c'était en 2019, nous avions de meilleures solutions de sauvegarde en place. Nous avons chargé une sauvegarde récente et (prudemment) fait une instruction de mise à jour pour revenir aux données précédentes.
UpdateGate2019™ était enfin terminé.
Ce que nous pouvons apprendre de cela
Il y a quelques leçons clés à tirer de ces histoires.
La première est que les instructions de mise à jour sont effrayantes.
Mes deux erreurs étaient des instructions de mise à jour. Lorsque vous mettez à jour (ou supprimez) des enregistrements, prenez des précautions supplémentaires pour vous assurer que les enregistrements que vous allez mettre à jour sont les bons.
Si vous exécutez une requête SQL brute, assurez-vous de glisser "de bas en haut" pour vous assurer d'exécuter toute l'instruction. Si vous faites une mise à jour via du code, soyez particulièrement prudent avec les paramètres et les parties dynamiques de votre requête. Vérifiez nil, NULL, ou null selon votre langage.
La deuxième leçon importante est que si quelque chose ne va pas—dites-le à quelqu'un immédiatement.
Cacher ou ignorer le problème ne fera qu'empirer les choses. Plus vous pouvez signaler un problème à votre équipe rapidement, plus vous pouvez arrêter les dégâts qui continuent d'être faits, et cela vous épargnera beaucoup de peine à long terme.
Troisièmement : Je ne connais personne qui a été viré pour avoir fait une erreur.
Dans les deux cas, mon équipe a réalisé que c'était une erreur honnête.
Par la suite, nous avons fait une petite rétrospective pour déterminer comment cela s'est produit et ce que nous pouvions faire pour éviter cette même erreur à l'avenir.
Les erreurs proviennent souvent de la même cause racine : se précipiter pour terminer le travail.
Les délais imminents, les esprits fatigués et le fait de ne pas réviser les PR avec assez de rigueur peuvent faire glisser de nombreuses erreurs à travers les mailles du filet.
En avant
Je suis content de savoir que j'ai encore six bonnes années devant moi avant de faire une autre terrible erreur (je plaisante).
Je sais que je ferai une autre erreur—les erreurs arrivent.
Mais ces erreurs n'ont pas détruit ma carrière ou ne m'ont pas rempli de honte. Ce n'est qu'une erreur. J'ai essayé d'en tirer des leçons, et j'espère qu'en lisant ceci, vous apprendrez également de mes erreurs sans avoir à les vivre vous-même.
Si vous avez aimé cet article, vous pouvez me suivre sur Twitter où je parle de choses comme celle-ci—développement de carrière et comment réussir en tant que développeur. J'écris également sur ces mêmes sujets sur mon site.
Merci d'avoir lu !
John