

Article original : How to scale your Node.js server using clustering
Par Michele Riva
La scalabilité est un sujet brûlant dans le domaine de la technologie, et chaque langage de programmation ou framework fournit sa propre manière de gérer des charges élevées de trafic.
Aujourd'hui, nous allons voir un exemple simple et direct sur le clustering Node.js. Il s'agit d'une technique de programmation qui vous aidera à paralléliser votre code et à accélérer les performances.
« Une seule instance de Node.js s'exécute dans un seul thread. Pour tirer parti des systèmes multi-cœurs, l'utilisateur voudra parfois lancer un cluster de processus Node.js pour gérer la charge. »
Nous allons créer un serveur web simple en utilisant Koa, qui est vraiment similaire à Express en termes d'utilisation.
L'exemple complet est disponible dans ce dépôt Github.
Ce que nous allons construire
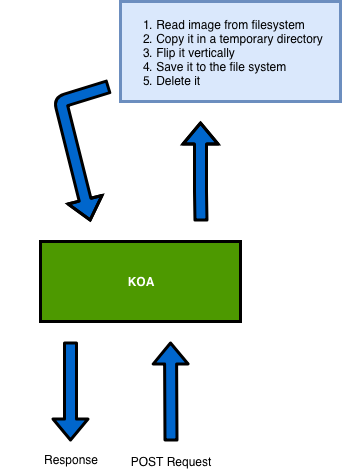
Nous allons construire un serveur web simple qui agira comme suit :
- Notre serveur recevra une requête
POST, nous ferons semblant que l'utilisateur nous envoie une image. - Nous copierons une image du système de fichiers dans un répertoire temporaire.
- Nous la retournerons verticalement en utilisant Jimp, une bibliothèque de traitement d'images pour Node.js.
- Nous l'enregistrerons dans le système de fichiers.
- Nous la supprimerons et enverrons une réponse à l'utilisateur.
Bien sûr, ce n'est pas une application réelle, mais elle s'en approche. Nous voulons simplement mesurer les avantages de l'utilisation du clustering.
Installation du projet
Je vais utiliser yarn pour installer mes dépendances et initialiser mon projet :
Puisque Node.js est mono-thread, si notre serveur web plante, il restera hors service jusqu'à ce qu'un autre processus le redémarre. Nous allons donc installer forever, un simple démon qui redémarrera notre serveur web s'il plante.
Nous installerons également Jimp, Koa et Koa Router.
Démarrage avec Koa
Voici la structure de dossier que nous devons créer :
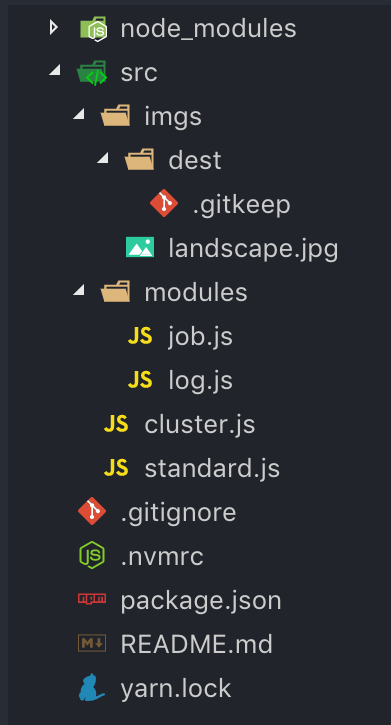
Nous aurons un dossier src qui contient deux fichiers JavaScript : cluster.js et standard.js.
Le premier sera le fichier où nous expérimenterons avec le module cluster. Le second est un serveur Koa simple qui fonctionnera sans clustering.
Dans le répertoire module, nous allons créer deux fichiers : job.js et log.js.
job.js effectuera le travail de manipulation d'image. log.js enregistrera chaque événement qui se produit pendant ce processus.
Le module Log
Le module Log sera une fonction simple qui prendra un argument et l'écrira dans le stdout (similaire à console.log).
Il ajoutera également l'horodatage actuel au début du log. Cela nous permettra de vérifier quand un processus a démarré et de mesurer ses performances.
Le module Job
Je vais être honnête, ce n'est pas un script super beau et optimisé. C'est juste un travail simple qui nous permettra de stresser notre machine.
Le serveur web Koa
Nous allons créer un serveur web très simple. Il répondra sur deux routes avec deux méthodes HTTP différentes.
Nous pourrons effectuer une requête GET sur [http://localhost:3000/](http://localhost:3000/.). Koa répondra avec un texte simple qui nous montrera le PID actuel (identifiant de processus).
La deuxième route n'acceptera que les requêtes POST sur le chemin /flip, et effectuera le travail que nous venons de créer.
Nous créerons également un middleware simple qui définira un en-tête X-Response-Time. Cela nous permettra de mesurer les performances.
Super ! Nous pouvons maintenant démarrer notre serveur en tapant node ./src/standard.js et tester nos routes.
Le problème
 L'image que je manipule actuellement (via Unsplash)
L'image que je manipule actuellement (via Unsplash)
Utilisons ma machine comme serveur :
- Macbook Pro 15 pouces 2016
- 2.7GHz Intel Core i7
- 16GB RAM
Si je fais une requête POST, le script ci-dessus m'enverra une réponse en ~3800 millisecondes. Pas si mal, étant donné que l'image sur laquelle je travaille fait environ 6.7MB.
Je peux essayer de faire plus de requêtes, mais le temps de réponse ne diminuera pas trop. Cela est dû au fait que les requêtes seront effectuées séquentiellement.
Alors, que se passerait-il si j'essayais de faire 10, 100, 1000 requêtes simultanées ?
J'ai fait un simple script Elixir qui effectue plusieurs requêtes HTTP simultanées :
J'ai choisi Elixir parce qu'il est vraiment facile de créer des processus parallèles, mais vous pouvez utiliser ce que vous préférez !
Test de dix requêtes simultanées — sans clustering
Comme vous pouvez le voir, nous lançons 10 processus simultanés depuis notre iex (un REPL Elixir).
Le serveur Node.js copiera immédiatement notre image et commencera à la retourner. La première réponse sera enregistrée après 16 secondes et la dernière après 40 secondes.
Une telle diminution dramatique des performances ! Avec seulement 10 requêtes simultanées, nous avons diminué les performances du serveur web de 950 % !
Introduction au clustering
 Tous les crédits à Pexels
Tous les crédits à Pexels
Vous souvenez-vous de ce que j'ai mentionné au début de l'article ?
Pour tirer parti des systèmes multi-cœurs, l'utilisateur voudra parfois lancer un cluster de processus Node.js pour gérer la charge.
Selon le serveur sur lequel nous allons exécuter notre application Koa, nous pourrions avoir un nombre différent de cœurs.
Chaque cœur sera responsable de la gestion de la charge individuellement. En gros, chaque requête HTTP sera satisfaite par un seul cœur.
Ainsi, par exemple, ma machine, qui a huit cœurs, gérera huit requêtes simultanées.
Nous pouvons maintenant compter combien de CPU nous avons grâce au module os :
La méthode cpus() retournera un tableau d'objets qui décrivent nos CPU. Nous pouvons lier sa longueur à une constante qui sera appelée numWorkers, car c'est le nombre de workers que nous allons utiliser.
Nous sommes maintenant prêts à utiliser le module cluster.
Nous avons maintenant besoin d'un moyen de diviser notre processus principal en N processus distincts. Nous appellerons notre processus principal master et les autres processus workers.
Le module cluster de Node.js offre une méthode appelée isMaster. Elle retournera une valeur booléenne qui nous indiquera si le processus actuel est dirigé par un worker ou un master :
Super. La règle d'or ici est que nous ne voulons pas servir notre application Koa sous le processus master.
Nous voulons créer une application Koa pour chaque worker, donc lorsqu'une requête arrive, le premier worker libre s'en occupera.
La méthode cluster.fork() conviendra à notre objectif :
D'accord, au début, cela peut sembler un peu délicat.
Comme vous pouvez le voir dans le script ci-dessus, si notre script a été exécuté par le processus master, nous allons déclarer une constante appelée workers. Cela créera un worker pour chaque cœur de notre CPU, et stockera toutes les informations à leur sujet.
Si vous vous sentez incertain quant à la syntaxe adoptée, utiliser [...Array(x)].map() est la même chose que :
Je préfère simplement utiliser des valeurs immuables lors du développement d'une application à haute concurrency.
Ajout de Koa
 Tous les crédits à Pexels
Tous les crédits à Pexels
Comme nous l'avons dit précédemment, nous ne voulons pas servir notre application Koa sous le processus master.
Copions la structure de notre application Koa dans l'instruction else, afin d'être sûr qu'elle sera servie par un worker :
Comme vous pouvez le voir, nous avons également ajouté quelques écouteurs d'événements dans l'instruction isMaster :
Le premier nous indiquera qu'un nouveau worker a été lancé. Le second créera un nouveau worker lorsqu'un autre worker plante.
De cette manière, le processus master ne sera responsable que de la création de nouveaux workers et de leur orchestration. Chaque worker servira une instance de Koa qui sera accessible sur le port :3000.
Test de dix requêtes simultanées — avec clustering
Comme vous pouvez le voir, nous avons obtenu notre première réponse après environ 10 secondes, et la dernière après environ 14 secondes. C'est une amélioration incroyable par rapport au temps de réponse précédent de 40 secondes !
Nous avons fait dix requêtes simultanées, et le serveur Koa en a pris huit immédiatement. Lorsque le premier worker a envoyé sa réponse au client, il a pris une des requêtes restantes et l'a traitée !
Conclusion
Node.js a une capacité incroyable de gérer des charges élevées, mais il ne serait pas judicieux d'arrêter une requête jusqu'à ce que le serveur termine son processus.
En fait, les serveurs web Node.js peuvent gérer des milliers de requêtes simultanées uniquement si vous envoyez immédiatement une réponse au client.
Une bonne pratique serait d'ajouter une interface de messagerie pub/sub en utilisant Redis ou tout autre outil amazing. Lorsque le client envoie une requête, le serveur commence une communication en temps réel avec d'autres services. Cela prend en charge les travaux coûteux.
Les équilibreurs de charge aideraient également beaucoup à répartir les charges de trafic élevé.
Une fois de plus, la technologie nous offre des possibilités infinies, et nous sommes sûrs de trouver la bonne solution pour mettre à l'échelle notre application à l'infini et au-delà !