

Article original : How to Measure Django Code Quality Using SonarQube, Pytest, and Coverage
Par Ridwan Yusuf
Salutations, passionnés de codage !
Nous allons plonger profondément dans le domaine de l'évaluation de la qualité du code Django. Dans ce guide complet, je vais vous guider à travers une approche approfondie pour mesurer la qualité du code de votre application basée sur Django.
À la fin de ce tutoriel, vous serez en mesure de :
- Construire des APIs CRUD en utilisant Django et DRF (Django REST Framework)
- Écrire des tests automatisés pour les APIs en utilisant Pytest
- Mesurer la couverture des tests de code en utilisant Coverage
- Utiliser SonarQube pour évaluer la qualité du code, identifier les mauvaises pratiques de code, les vulnérabilités de sécurité, et plus encore
Les prérequis pour suivre ce tutoriel incluent :
- L'installation de Python 3 sur votre système d'exploitation (OS) choisi. Nous utiliserons Python 3.10 dans ce tutoriel.
- Des connaissances de base en Python et Django
- Un éditeur de code de votre choix
Sans plus tarder, plongeons directement dans le vif du sujet.
Comment démarrer les APIs
Pour commencer, ouvrez votre Terminal ou bash. Créez un répertoire ou un dossier pour votre projet en utilisant la commande :
mkdir django-quality && cd django-quality
Dans mon cas, le nom du dossier est "django-quality".
Pour isoler les dépendances du projet, nous devons utiliser un environnement virtuel Python.
Pour créer un environnement virtuel, utilisez la commande suivante dans votre Terminal ou bash :
python3 -m venv venv
Activez le virtualenv en exécutant cette commande :
source venv/bin/activate
Si tout fonctionne correctement, vous devriez voir l'indicateur de l'environnement virtuel entouré de crochets, similaire à l'image montrée ci-dessous :
 Environnement virtuel Python activé avec succès
Environnement virtuel Python activé avec succès
À la racine de votre projet, créez un dossier appelé "requirements" qui contiendra les packages externes requis pour les différentes étapes de développement, telles que dev (développement) et staging.
À l'intérieur du dossier "requirements", créez deux fichiers : "base.txt" et "dev.txt". Le fichier "base.txt" inclura les packages génériques requis par l'application, tandis que le fichier "dev.txt" contiendra les dépendances spécifiques au mode développement.
À ce stade, le contenu de votre dossier de projet devrait avoir la structure suivante :
- requirements
base.txt
dev.txt
- venv
Voici le contenu mis à jour pour les fichiers "base.txt" et "dev.txt" :
base.txt
Django==4.0.6
djangorestframework==3.13.1
drf-spectacular==0.22.1
dev.txt
-r base.txt
pytest-django==4.5.2
pytest-factoryboy==2.5.0
pytest-cov==4.1.0
- djangorestframework : Utilisé pour le développement d'API.
- drf-spectacular : Utilisé pour la documentation automatisée des APIs.
- pytest-cov : Utilisé pour mesurer la couverture de code pendant les tests.
- pytest-factoryboy : Utilisé pour créer des données de test en utilisant des motifs de fabrique.
Assurez-vous que votre environnement virtuel est activé, puis exécutez la commande suivante à la racine du projet pour installer les dépendances spécifiées dans "dev.txt" :
pip install -r requirements/dev.txt
Pour créer un nouveau projet Django, vous pouvez exécuter la commande suivante :
django-admin startproject core .
Le nom du projet est 'core'. Vous pouvez décider d'utiliser un autre nom qui correspond à votre cas d'utilisation.
À ce stade, vous devriez voir plusieurs fichiers et dossiers créés automatiquement après avoir exécuté la commande.
Voici la structure actuelle du projet :
core
asgi.py
__init__.py
settings.py
urls.py
wsgi.py
manage.py
requirements
base.txt
dev.txt
venv
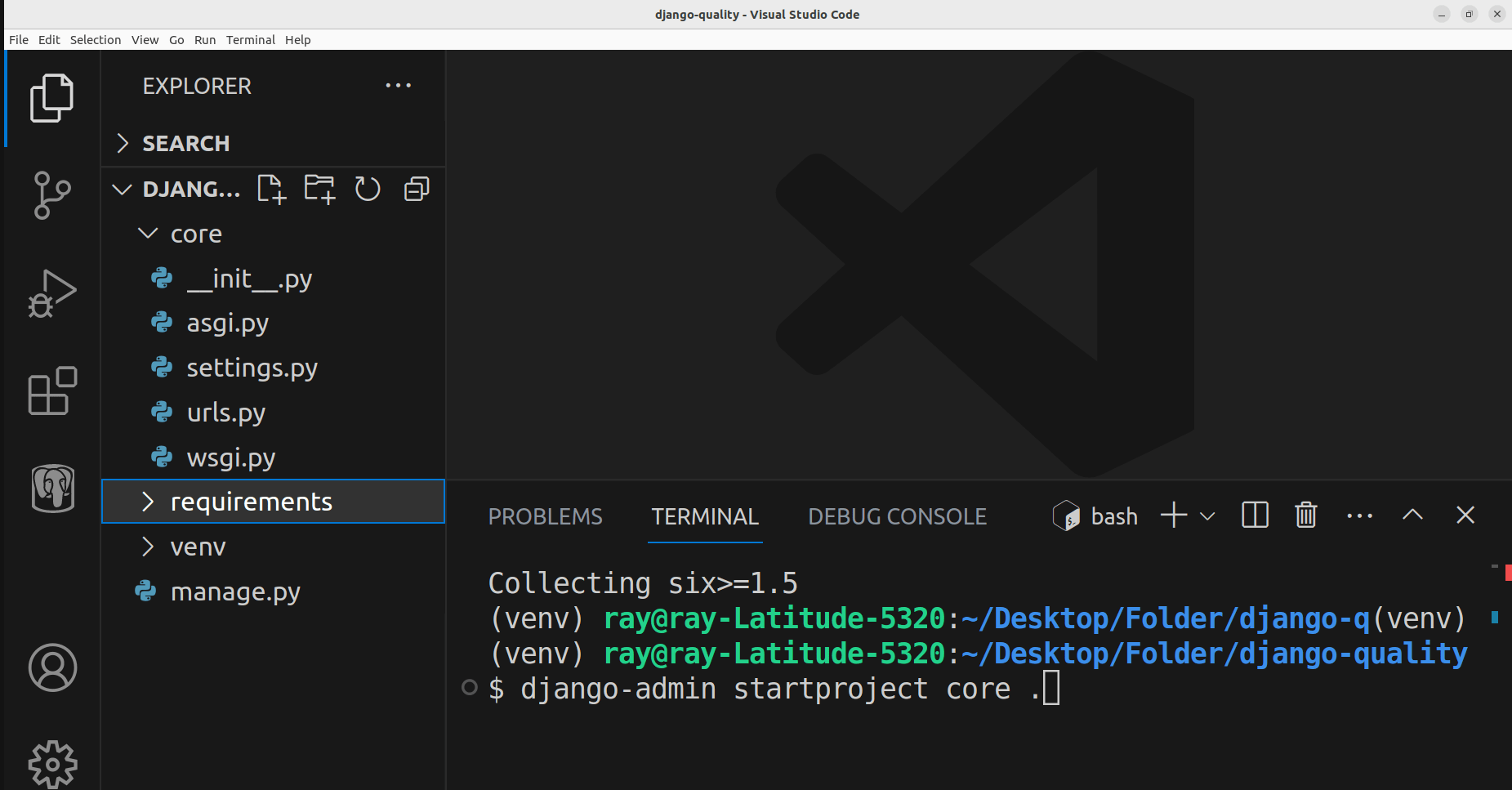 Structure actuelle du dossier dans VSCode
Structure actuelle du dossier dans VSCode
Les APIs que nous allons créer seront une API de blog basique avec une fonctionnalité CRUD. Créons une nouvelle application dans le projet pour héberger tous les fichiers liés aux fonctionnalités du blog.
Exécutez cette commande pour créer une nouvelle application appelée 'blog' :
python manage.py startapp blog
À ce stade, un nouveau dossier nommé 'blog' a été créé automatiquement par la commande.
Voici la structure du dossier :
blog
admin.py
apps.py
__init__.py
migrations
models.py
tests.py
views.py
core
manage.py
requirements
venv
Mettez à jour le fichier models.py dans le dossier blog. La classe Blog définit le schéma de la base de données pour le blog.
blog/models.py
from django.db import models
class Blog(models.Model):
title = models.CharField(max_length=50)
body = models.TextField()
published = models.BooleanField(default=True)
created_at = models.DateTimeField(auto_now_add=True)
Créez un nouveau fichier nommé 'serializers.py' dans le dossier 'blog' et mettez à jour son contenu comme indiqué ci-dessous :
blog/serializers.py
from rest_framework import serializers
from .models import Blog
class BlogSerializer(serializers.ModelSerializer):
class Meta:
model = Blog
fields = '__all__'
extra_kwargs = {
"created_at": {"read_only": True},
}
La classe BlogSerializer est utilisée pour valider les données de blog entrantes envoyées par le client (par exemple, depuis le frontend ou l'application mobile) pour s'assurer qu'elles respectent le format attendu.
De plus, la classe de sérialisation est utilisée à la fois pour la sérialisation (conversion des objets Python en un format transmissible comme JSON) et la désérialisation (conversion d'un format transmissible comme JSON en objets Python).
Créons la vue pour gérer la fonctionnalité CRUD, en utilisant le ModelViewSet de DRF pour créer facilement des APIs avec seulement quelques lignes de code.
blog/views.py
from rest_framework import filters, viewsets
from .models import Blog
from .serializers import BlogSerializer
class BlogViewSet(viewsets.ModelViewSet):
queryset = Blog.objects.all()
http_method_names = ["get", "post", "delete", "patch","put"]
serializer_class = BlogSerializer
filter_backends = [
filters.SearchFilter,
filters.OrderingFilter,
]
filterset_fields = ["published"]
search_fields = ["title", "body"]
ordering_fields = [
"created_at",
]
Créez un nouveau fichier nommé 'blog.urls' dans le dossier 'blog'.
En utilisant le routeur DRF pour la configuration des URL, les URL sont générées automatiquement en fonction des méthodes autorisées définies dans le BlogViewSet.
blog/urls.py
from django.urls import include, path
from rest_framework.routers import DefaultRouter
from .views import BlogViewSet
app_name = "blog"
router = DefaultRouter()
router.register("", BlogViewSet)
urlpatterns = [
path("", include(router.urls)),
]
L'étape suivante consiste à enregistrer le fichier urls.py défini dans l'application 'blog' dans le fichier urls.py principal du projet. Pour ce faire, vous devez localiser le fichier urls.py du projet, qui sert de point de départ pour le routage des URL.
core/urls.py
from django.contrib import admin
from django.urls import path, include
from drf_spectacular.views import (
SpectacularAPIView,
SpectacularRedocView,
SpectacularSwaggerView,
)
urlpatterns = [
path('api/schema/', SpectacularAPIView.as_view(), name='schema'),
path('api/v1/doc/', SpectacularSwaggerView.as_view(url_name='schema'), name='swagger-ui'),
path('api/v1/redoc/', SpectacularRedocView.as_view(url_name='schema'), name='redoc'),
path('admin/', admin.site.urls),
path('api/v1/blogs/', include('blog.urls')),
]
L'URL api/v1/blogs/ est mappée aux URL définies dans blog.urls. De plus, d'autres URL sont utilisées pour la documentation automatisée des API.
Mettez à jour le fichier settings.py situé dans le dossier core. Ce fichier contient les configurations pour l'application Django.
Dans la section INSTALLED_APPS, enregistrez la nouvelle application 'blog', ainsi que les applications tierces souhaitées. Notez que pour plus de concision, les applications Django par défaut ne sont pas incluses dans la liste suivante :
settings.py
INSTALLED_APPS = [
#Applications tierces
'drf_spectacular',
#Applications locales
'blog',
]
Mettez à jour le fichier settings.py pour inclure les configurations liées à Django REST Framework (DRF) et à la documentation.
settings.py
REST_FRAMEWORK = {
"DEFAULT_SCHEMA_CLASS": "drf_spectacular.openapi.AutoSchema",
"TEST_REQUEST_DEFAULT_FORMAT": "json",
}
SPECTACULAR_SETTINGS = {
'SCHEMA_PATH_PREFIX': r'/api/v1',
'DEFAULT_GENERATOR_CLASS': 'drf_spectacular.generators.SchemaGenerator',
'SERVE_PERMISSIONS': ['rest_framework.permissions.AllowAny'],
'COMPONENT_SPLIT_PATCH': True,
'COMPONENT_SPLIT_REQUEST': True,
"SWAGGER_UI_SETTINGS": {
"deepLinking": True,
"persistAuthorization": True,
"displayOperationId": True,
"displayRequestDuration": True
},
'UPLOADED_FILES_USE_URL': True,
'TITLE': 'Django-Pytest-Sonarqube - Blog API',
'DESCRIPTION': 'Une configuration simple d\'API avec Django, Pytest & Sonarqube',
'VERSION': '1.0.0',
'LICENCE': {'name': 'Licence BSD'},
'CONTACT': {'name': 'Ridwan Ray', 'email': 'ridwanray.com'},
#SPEC OAUTH2
'OAUTH2_FLOWS': [],
'OAUTH2_AUTHORIZATION_URL': None,
'OAUTH2_TOKEN_URL': None,
'OAUTH2_REFRESH_URL': None,
'OAUTH2_SCOPES': None,
}
Avec toutes les configurations nécessaires en place, exécutons la commande de migration pour nous assurer que les modèles de l'application sont synchronisés avec le schéma de la base de données.
Exécutez les commandes suivantes dans le répertoire racine pour synchroniser les modèles avec le schéma de la base de données :
python manage.py makemigrations
python manage.py migrate
Pour démarrer le serveur de développement, exécutez la commande suivante :
python manage.py runserver
 Démarrage du serveur de développement local avec la commande runserver
Démarrage du serveur de développement local avec la commande runserver
L'application est maintenant en cours d'exécution à l'adresse http://127.0.0.1:8000/.
Pour accéder à la documentation, visitez http://127.0.0.1:8000/api/v1/doc/.
 Documentation automatisée de l'API de blog en utilisant drf-spectacular
Documentation automatisée de l'API de blog en utilisant drf-spectacular
Comment écrire des tests automatisés avec Pytest
Pytest, l'outil de test que nous utilisons pour écrire des tests automatisés, est inclus dans les dépendances déclarées dans le dossier des exigences. Maintenant, écrivons quelques tests et explorons ses fonctionnalités.
Dans le dossier blog, un fichier nommé "tests.py" est généré automatiquement lors du démarrage de l'application blog. Pour organiser les tests, créez un nouveau dossier appelé "tests" dans le répertoire blog.
Déplacez le fichier "tests.py" initial dans le nouveau dossier "tests" créé. Pour faire du dossier "tests" un module, créez un fichier vide nommé "init.py".
Créez un nouveau fichier nommé 'conftest.py' dans le dossier 'tests'. Ce fichier stockera les fixtures pytest (c'est-à-dire les composants réutilisables) nécessaires lors du processus d'écriture des tests.
Structure du dossier de test :
tests
conftest.py
factories.py
__init__.py
__pycache__
tests.py
tests/conftests.py
import pytest
from rest_framework.test import APIClient
@pytest.fixture
def api_client():
return APIClient()
La fonction api_client() est une fixture Pytest utilisée pour effectuer des appels réels à l'API.
Créez un nouveau fichier nommé 'factories.py'. Ce fichier contiendra les factories utilisées lors de l'écriture des tests. Les factories fournissent un moyen pratique de créer des objets (c'est-à-dire des instances de modèles) sans avoir à spécifier tous les attributs à chaque fois.
tests/factories.py
import factory
from faker import Faker
from blog.models import Blog
fake = Faker()
class BlogFactory(factory.django.DjangoModelFactory):
class Meta:
model = Blog
title = fake.name()
body = fake.text()
published = True
tests/tests.py
import pytest
from django.urls import reverse
from .factories import BlogFactory
pytestmark = pytest.mark.django_db
class TestBlogCRUD:
blog_list_url = reverse('blog:blog-list')
def test_create_blog(self, api_client):
data = {
"title": "Good news",
"body": "Something good starts small",
"published": True
}
response = api_client.post(self.blog_list_url, data)
assert response.status_code == 201
returned_json = response.json()
assert 'id' in returned_json
assert returned_json['title'] == data['title']
assert returned_json['body'] == data['body']
assert returned_json['published'] == data['published']
def test_retrieve_blogs(self, api_client):
BlogFactory.create_batch(5)
response = api_client.get(self.blog_list_url)
assert response.status_code == 200
assert len(response.json()) == 5
def test_delete_blog(self, api_client):
blog = BlogFactory()
url = reverse("blog:blog-detail",
kwargs={"pk": blog.id})
response = api_client.delete(url)
assert response.status_code == 204
def test_update_blog(self, api_client):
blog = BlogFactory(published= True)
data = {
"title": "New title",
"body": "New body",
"published": False,
}
url = reverse("blog:blog-detail",
kwargs={"pk": blog.id})
response = api_client.patch(url, data)
assert response.status_code == 200
returned_json = response.json()
assert returned_json['title'] == data['title']
assert returned_json['body'] == data['body']
assert returned_json['published'] == data['published']
La classe TestBlogCRUD teste les fonctionnalités CRUD de l'application. La classe définit quatre méthodes, chacune testant une fonctionnalité CRUD spécifique.
Créez un fichier de configuration Pytest nommé pytest.ini dans le répertoire racine. Ce fichier contiendra des paramètres qui indiquent à Pytest comment localiser les fichiers de test.
pytest.ini
[pytest]
DJANGO_SETTINGS_MODULE = core.settings
python_files = tests.py test_*.py *_tests.py
addopts = -p no:warnings --no-migrations --reuse-db
Pour exécuter les tests, exécutez la commande pytest dans le répertoire racine comme indiqué ci-dessous :
pytest
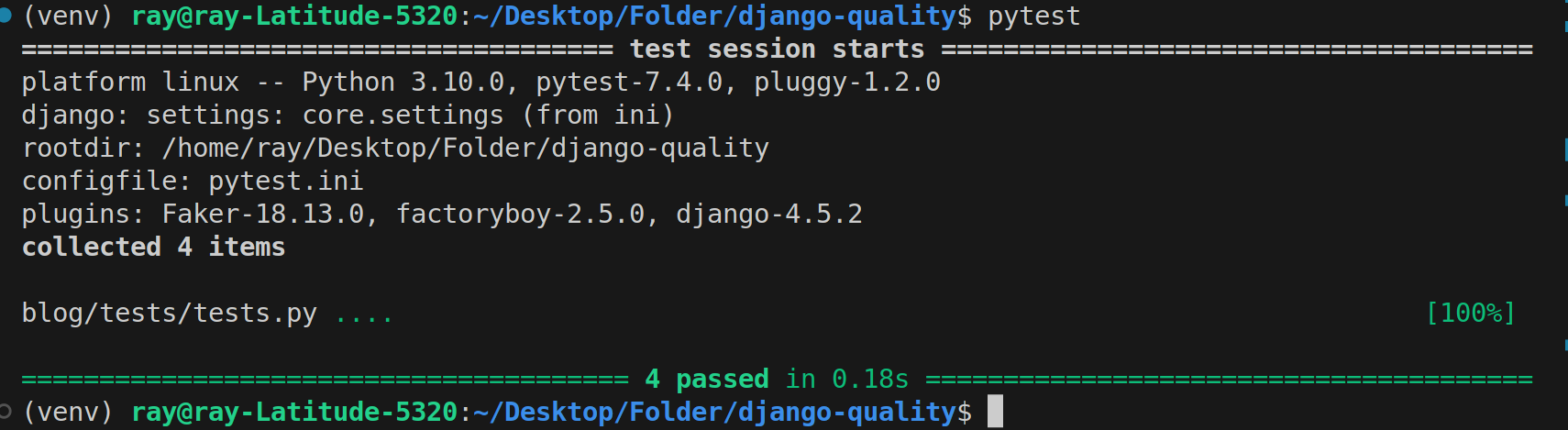 Résultat des tests Pytest
Résultat des tests Pytest
Les résultats des tests indiquent que les quatre cas de test ont réussi.
Au moment de la rédaction, deux outils populaires utilisés dans la communauté Python pour rapporter la couverture des tests dans une base de code sont Coverage et pytest-cov.
Dans notre cas, nous utiliserons pytest-cov pour sa flexibilité en matière de rapport de couverture des tests.
Créez un nouveau fichier nommé 'setup.cfg' dans le répertoire racine. Ce fichier sert de fichier de configuration pour coverage.
setup.cfg
[coverage:run]
source = .
branch = True
[coverage:report]
show_missing = True
skip_covered = True
La valeur source dans la section [coverage:run] spécifie l'emplacement du répertoire racine à partir duquel la couverture des tests sera mesurée.
En plus de la couverture des instructions dans le rapport de test, la couverture des branches identifie les branches non couvertes lors de l'utilisation d'instructions conditionnelles (par exemple, if, else, case).
Note : Il est possible de spécifier les dossiers à omettre de la couverture des tests, tels que les dossiers de migration, dans le fichier setup.cfg. Nous configurerons ces paramètres dans SonarQube.
Relançons les cas de test en utilisant la commande suivante :
pytest --cov --cov-report=xml
L'option --cov-report spécifie le format du rapport de couverture. Divers formats comme HTML, XML, JSON, etc., sont supportés. Dans ce cas, nous spécifions xml car il est supporté par SonarQube.
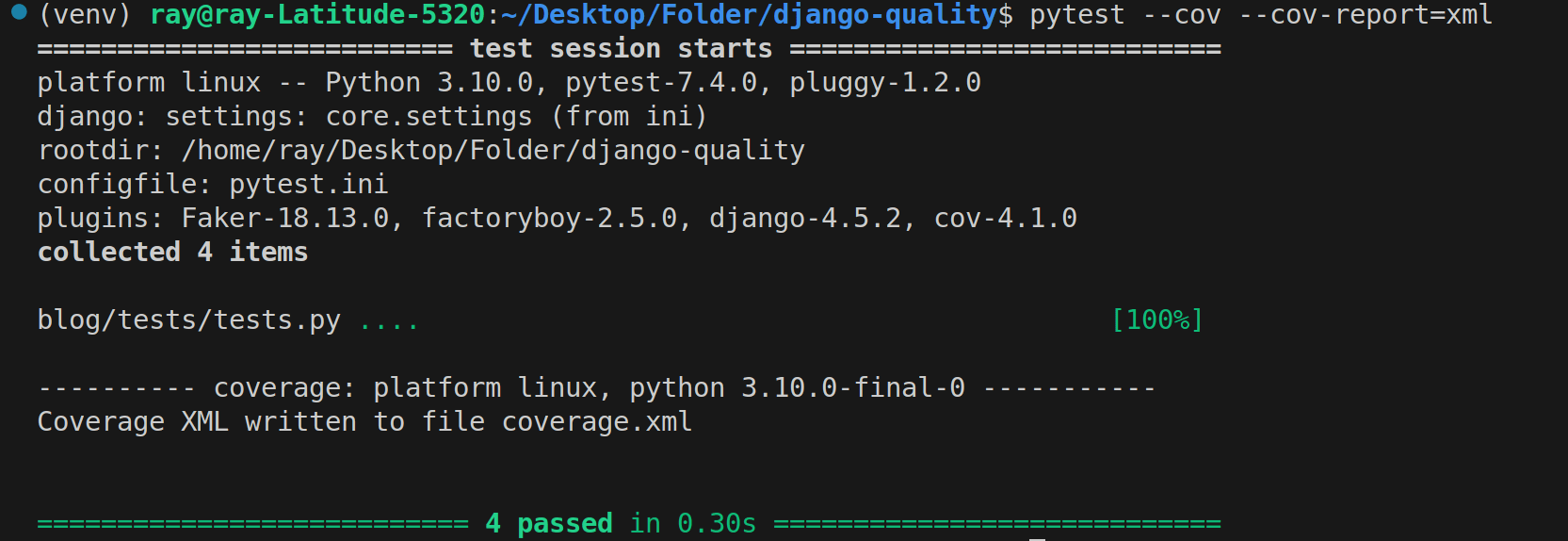 Rapport de couverture Pytest au format XML
Rapport de couverture Pytest au format XML
Pour le format HTML, un dossier nommé 'htmlcov' sera généré dans le répertoire racine. Ce dossier contient le fichier 'index.html', qui vous permet de visualiser les résultats de la couverture et les zones qui ne sont pas couvertes.
Comment configurer SonarQube
SonarQube est un outil utilisé pour l'analyse statique du code. Il aide à identifier les problèmes de qualité du code, les bugs, les vulnérabilités et les mauvaises pratiques de code dans les projets logiciels.
Pour simplifier le processus, nous pouvons exécuter un conteneur Docker basé sur l'image SonarQube.
Exécutez la commande suivante dans la ligne de commande :
docker run -d -p 9000:9000 -p 9092:9092 sonarqube
Après quelques instants, selon votre vitesse Internet, visitez http://0.0.0.0:9000/.
Vous pouvez utiliser les identifiants de connexion suivants pour accéder à l'application : Nom d'utilisateur : admin Mot de passe : admin
Ensuite, vous devez télécharger Sonar Scanner. Visitez ce lien et sélectionnez l'option compatible avec votre système d'exploitation (OS).
 Téléchargement de SonarScanner sur le site Sonarsource.com
Téléchargement de SonarScanner sur le site Sonarsource.com
Décompressez le sonar-scanner et déplacez-le du dossier 'Downloads' vers un répertoire sécurisé.
unzip sonar-scanner-cli-4.8.0.2856-linux.zip
mv sonar-scanner-4.2.0.1873-linux /opt/sonar-scanner
Ajoutez les lignes suivantes au contenu du fichier sonar-scanner.properties situé à /opt/sonar-scanner/conf/sonar-scanner.properties :
vim /opt/sonar-scanner/conf/sonar-scanner.properties
Ajoutez ces deux lignes et sauvegardez le fichier :
sonar.host.url=http://localhost:9000
sonar.sourceEncoding=UTF-8
Ajoutez /opt/sonar-scanner/bin à la variable d'environnement PATH du système en exécutant cette commande :
export PATH="$PATH:/opt/sonar-scanner/bin
Mettez à jour le contenu de .bashrc :
vim ~/.bashrc
Ajoutez cette ligne au fichier .bashrc et sauvegardez-le :
export PATH="$PATH:/opt/sonar-scanner/bin
Exécutez la commande suivante pour appliquer les modifications à votre session de terminal actuelle :
source ~/.bashrc
Pour vous assurer que tout fonctionne correctement, exécutez la commande suivante :
sonar-scanner -v
 Vérification de la version de sonarqube sur le terminal
Vérification de la version de sonarqube sur le terminal
Accédez à l'onglet 'Projets' sur le tableau de bord SonarQube et procédez à la création manuelle d'un nouveau projet.
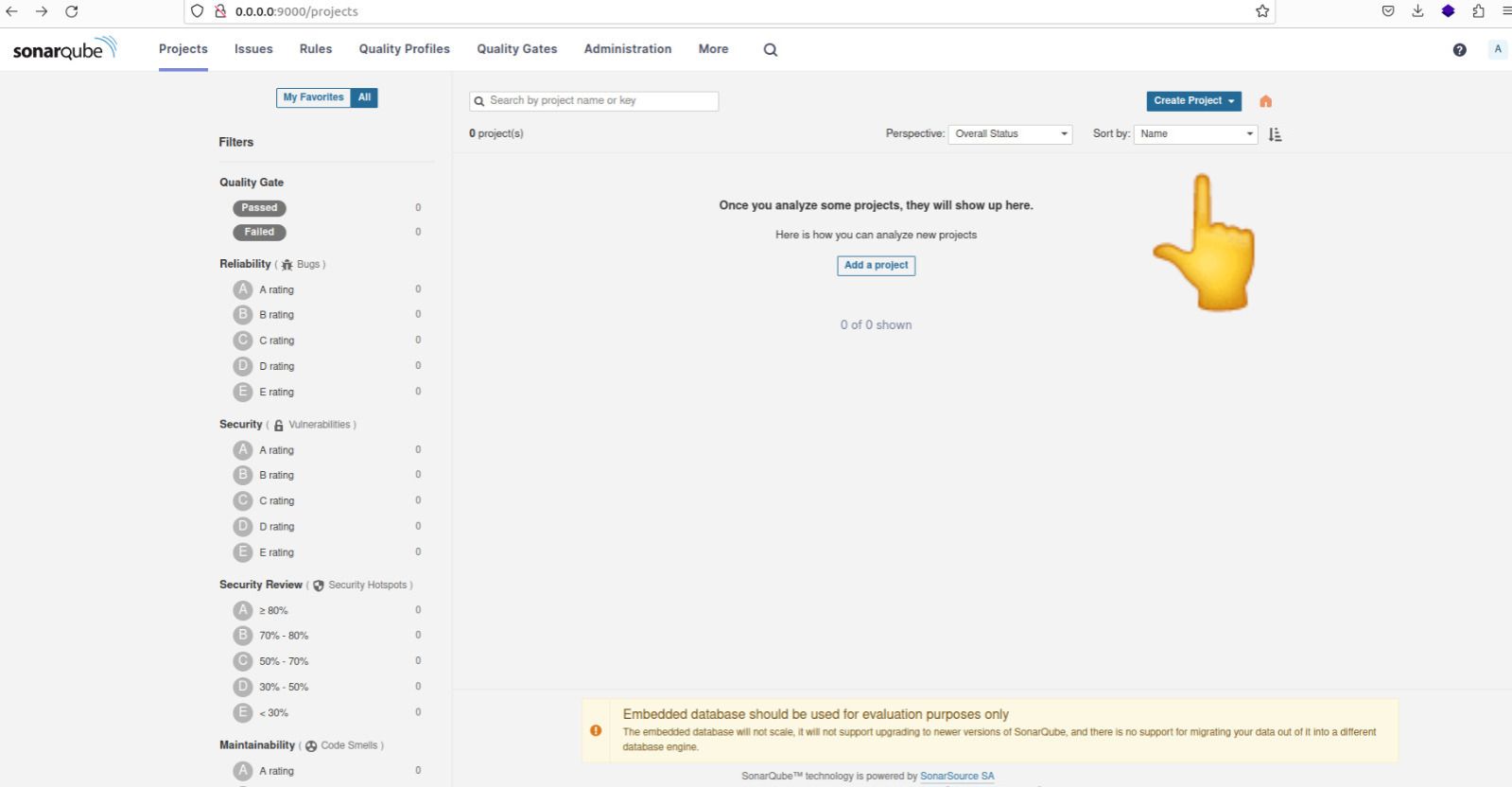 Création d'un nouveau projet sur le tableau de bord sonarqube
Création d'un nouveau projet sur le tableau de bord sonarqube
Fournissez un nom approprié pour le projet, puis sélectionnez l'option "Utiliser le paramètre global" avant de procéder à la création du projet.
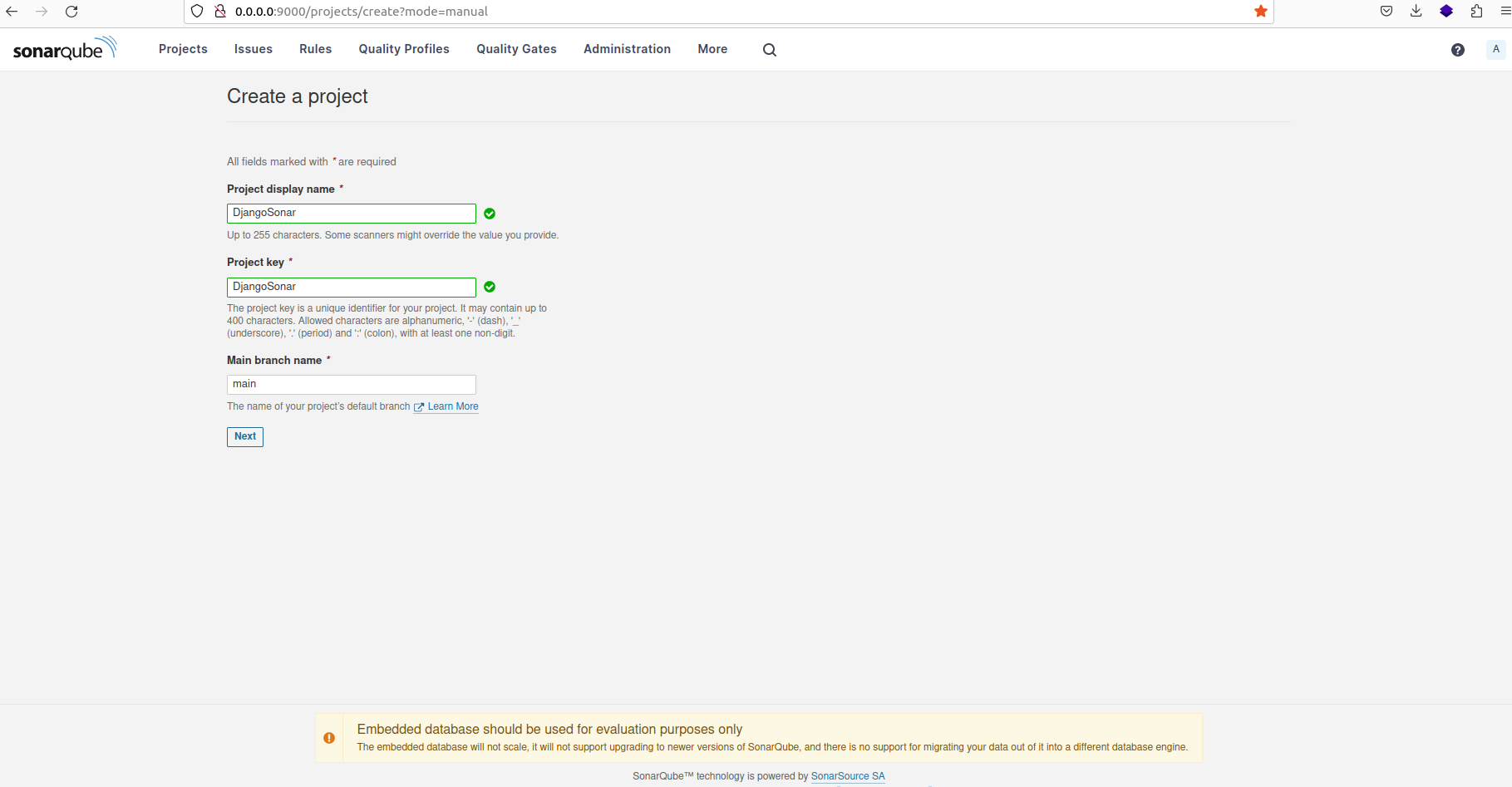 Choix d'un nom approprié pour le nouveau projet
Choix d'un nom approprié pour le nouveau projet
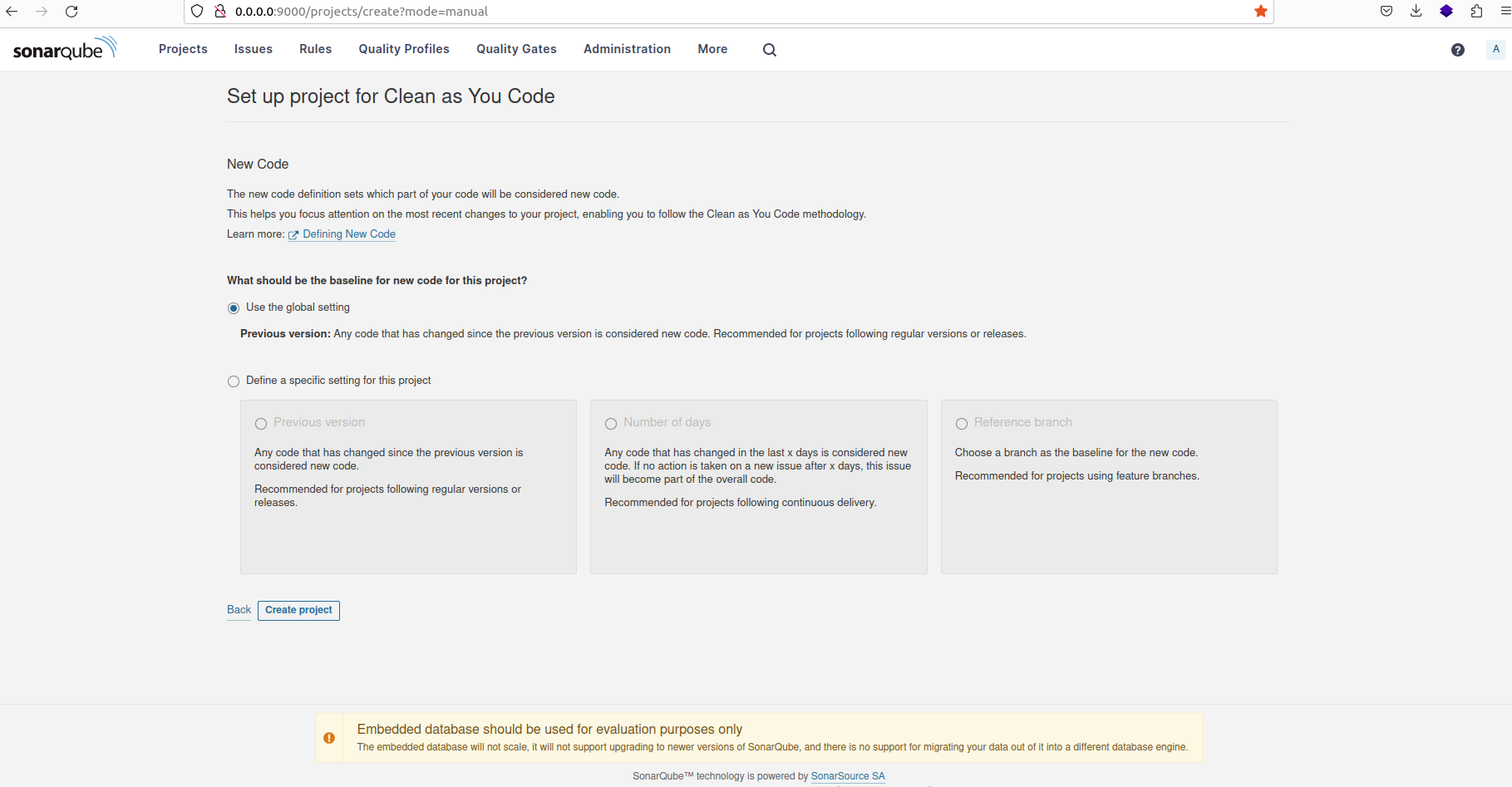 Configuration du nouveau projet pour utiliser les paramètres globaux
Configuration du nouveau projet pour utiliser les paramètres globaux
Après avoir créé le projet, vous serez invité à sélectionner la méthode d'analyse pour votre projet. Choisissez l'option 'Localement'.
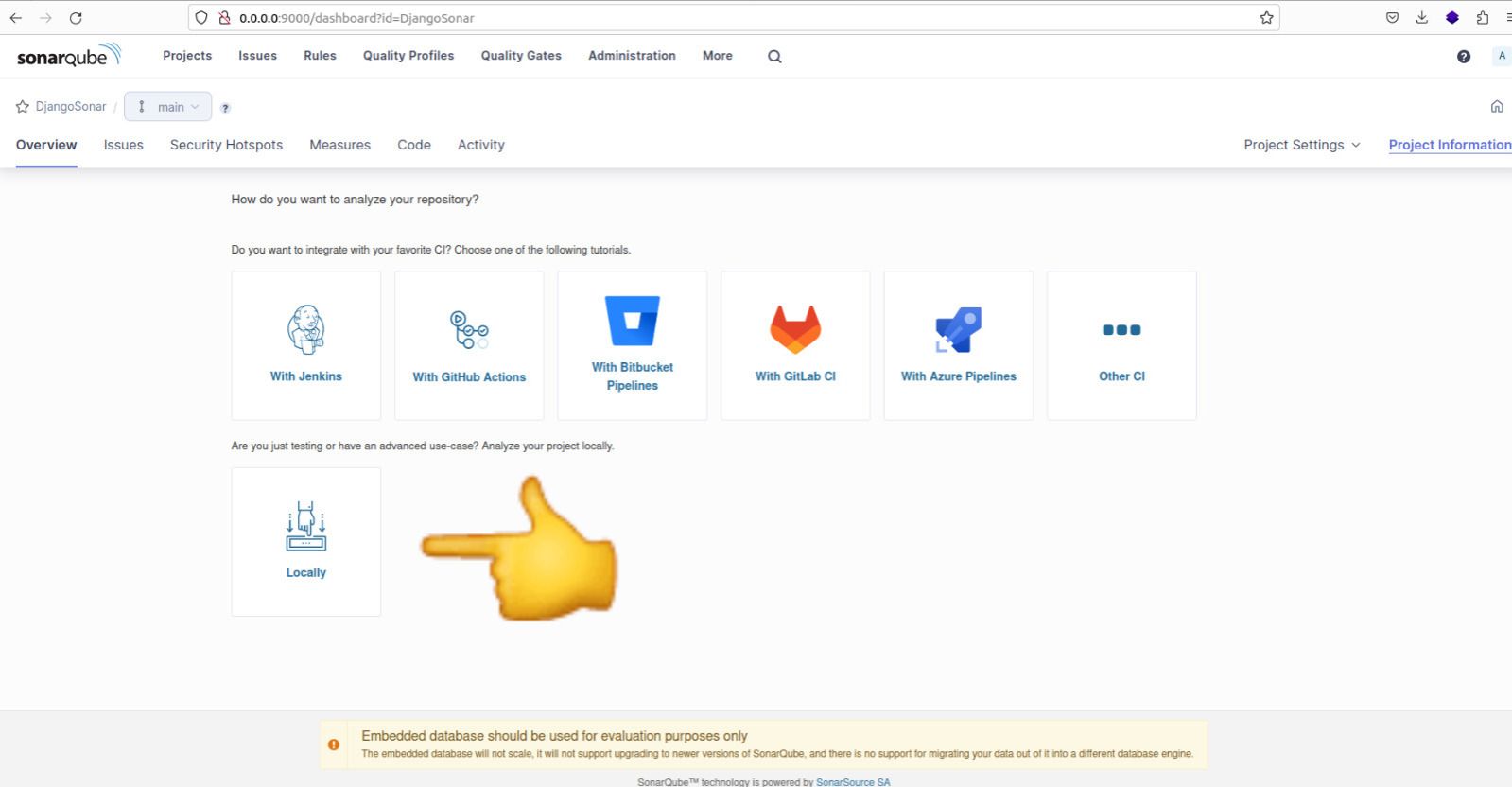 Exécution de l'analyse sur le projet localement
Exécution de l'analyse sur le projet localement
Après avoir sélectionné l'option 'Localement', vous devrez générer un jeton. Cliquez sur 'Continuer' pour procéder. Ensuite, sélectionnez le langage de programmation de votre projet et le système d'exploitation (OS) sur lequel il s'exécutera.
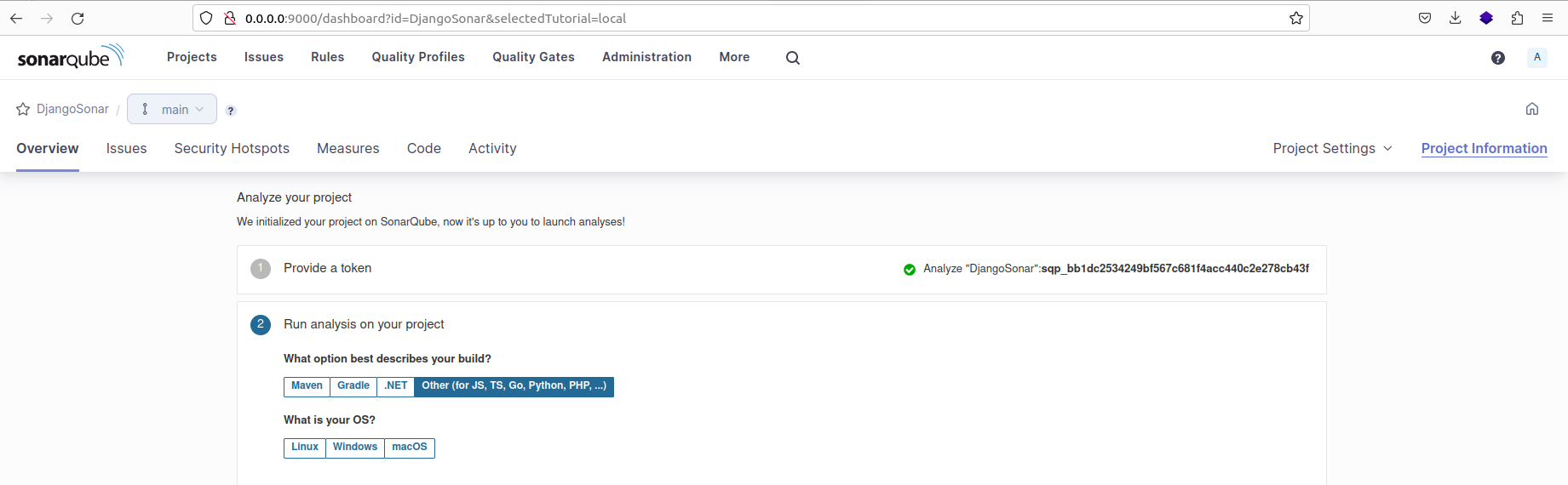 Choix du langage de programmation du projet et de l'OS
Choix du langage de programmation du projet et de l'OS
Copiez la commande affichée, car nous l'utiliserons pour exécuter l'analyse du projet.
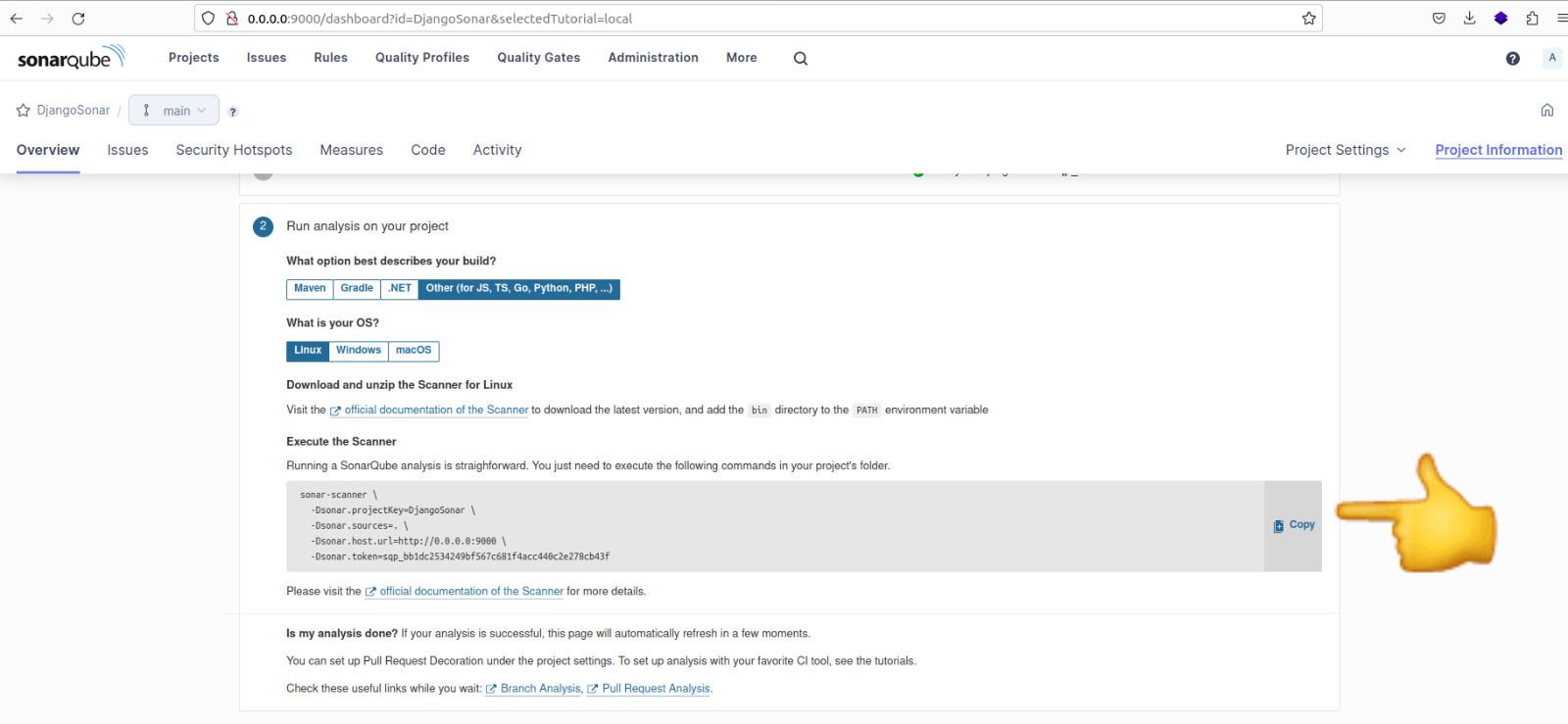 Code nécessaire pour exécuter l'analyse
Code nécessaire pour exécuter l'analyse
Voici le contenu de la commande :
sonar-scanner \
-Dsonar.projectKey=newretailer \
-Dsonar.sources=. \
-Dsonar.host.url=http://0.0.0.0:9000 \
-Dsonar.token=sqp_7b6aada8ce53e97ebb7b2bf5e9b64d53b8938a6f \
-Dsonar.python.version=3
Note : Nous avons ajouté une ligne supplémentaire à la commande pour spécifier la version de Python comme -Dsonar.python.version=3.
Avant d'exécuter la commande d'analyse, suivez ces étapes :
- Cliquez sur "Paramètres du projet" puis sélectionnez "Paramètres généraux".
- Ensuite, accédez à l'onglet "Portée de l'analyse".
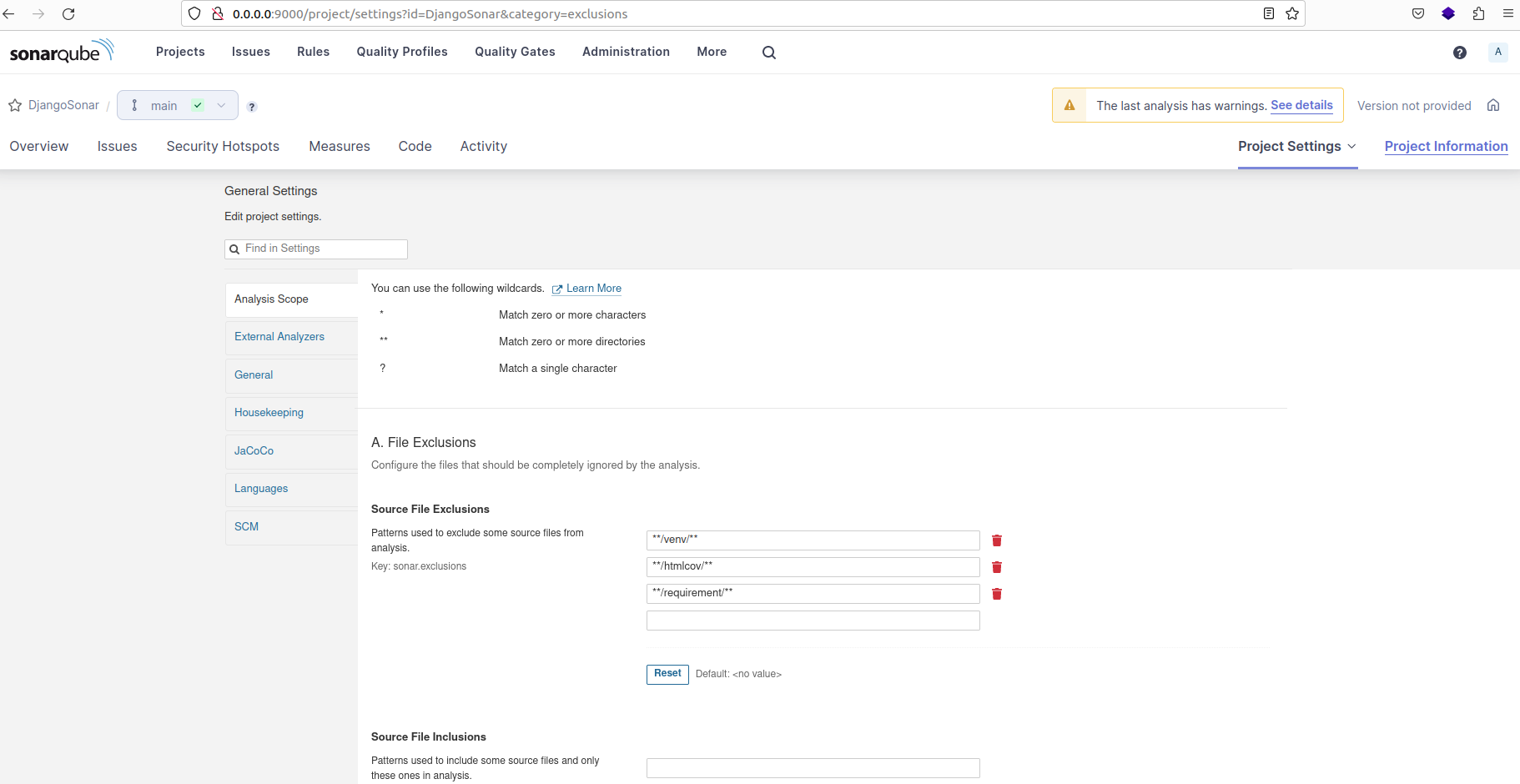 Fichiers sources qui doivent être ignorés par l'analyse
Fichiers sources qui doivent être ignorés par l'analyse
Les exclusions de fichiers sources sont utilisées pour spécifier les fichiers ou dossiers que SonarQube ne doit pas analyser dans le cadre de la base de code. Ceux-ci peuvent inclure des fichiers ou répertoires qui ne font pas directement partie du code mais sont présents dans le répertoire du projet.
Voici quelques exemples courants de tels fichiers ou dossiers :
- venv (environnement virtuel)
- htmlcov (format HTML de couverture)
- node_modules (répertoire des modules Node.js)
Les exclusions de couverture de code sont utilisées pour spécifier les fichiers ou dossiers qui doivent être exclus lors du calcul du pourcentage de couverture.
Voici les motifs pour les fichiers et dossiers ignorés :
/tests/, /migrations/, /admin.py, /apps.py, core/asgi.py, core/wsgi.py, manage.py
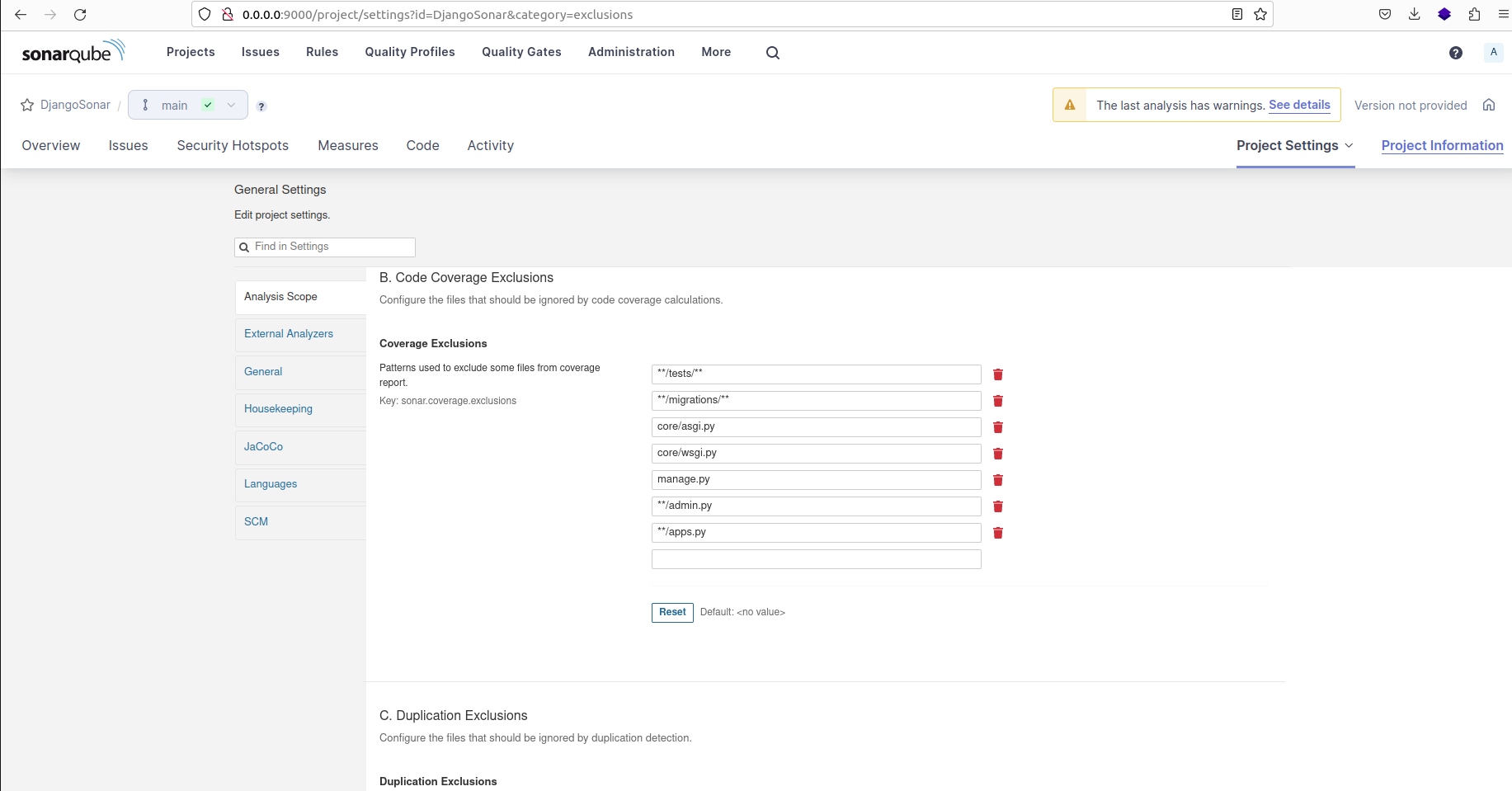 Motifs utilisés pour exclure certains fichiers du rapport de couverture et du calcul du pourcentage de couverture
Motifs utilisés pour exclure certains fichiers du rapport de couverture et du calcul du pourcentage de couverture
Dans l'onglet "Langages", sélectionnez "Python" comme langage de programmation pour le projet. Ensuite, mettez à jour le chemin vers le rapport de couverture comme "coverage.xml".
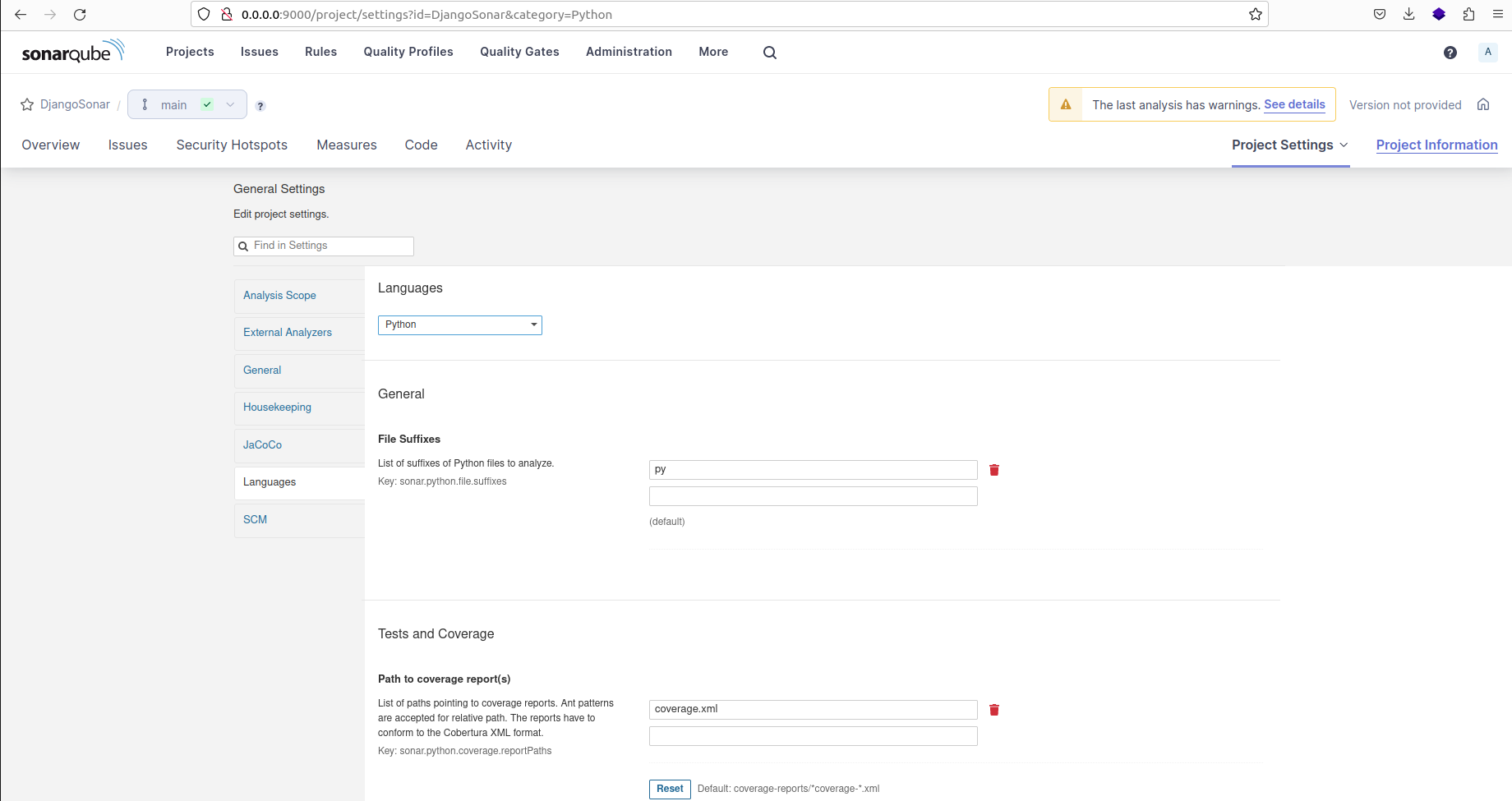 Sélection du langage de programmation et emplacement du rapport de couverture XML
Sélection du langage de programmation et emplacement du rapport de couverture XML
Exécutez la commande fournie précédemment à la racine du projet :
sonar-scanner -Dsonar.projectKey=DjangoSonar -Dsonar.sources=. -Dsonar.host.url=http://0.0.0.0:9000 -Dsonar.token=sqp_bb1dc2534249bf567c681f4acc440c2e278cb43f -Dsonar.python.coverage.reportPaths=coverage.xml -Dsonar.python.version=3
Si tout fonctionne correctement, vous devriez voir un résultat réussi.
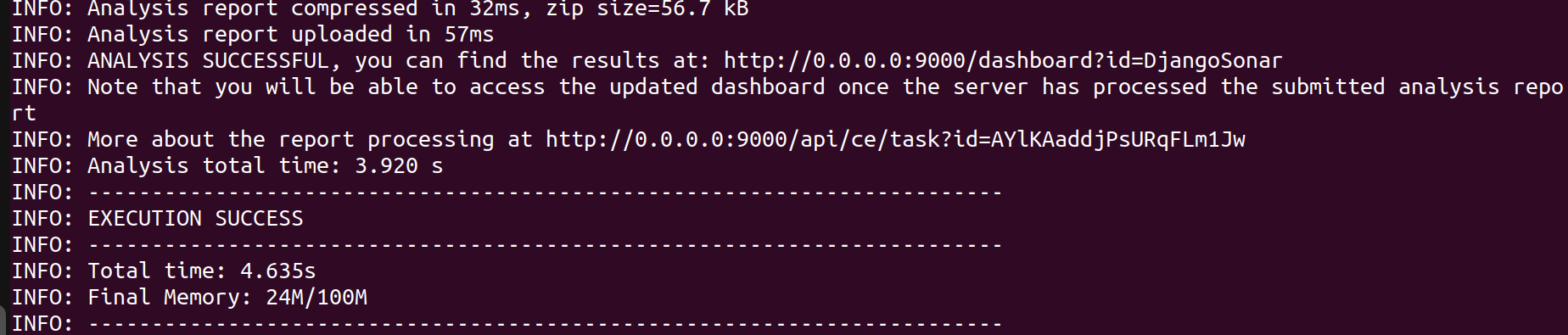 Exécution de l'analyse sonarqube sur le projet avec la commande donnée sur le tableau de bord
Exécution de l'analyse sonarqube sur le projet avec la commande donnée sur le tableau de bord
Si vous rencontrez des erreurs liées à un accès non autorisé ou à des problèmes de permission lors de l'analyse d'un projet localement, suivez ces étapes :
- Visitez l'interface d'administration de SonarQube.
- Accédez à la section 'Sécurité'.
- Recherchez l'option intitulée 'Forcer l'authentification de l'utilisateur' et désactivez-la.
- Enregistrez les modifications et relancez l'analyse en utilisant la commande précédente.
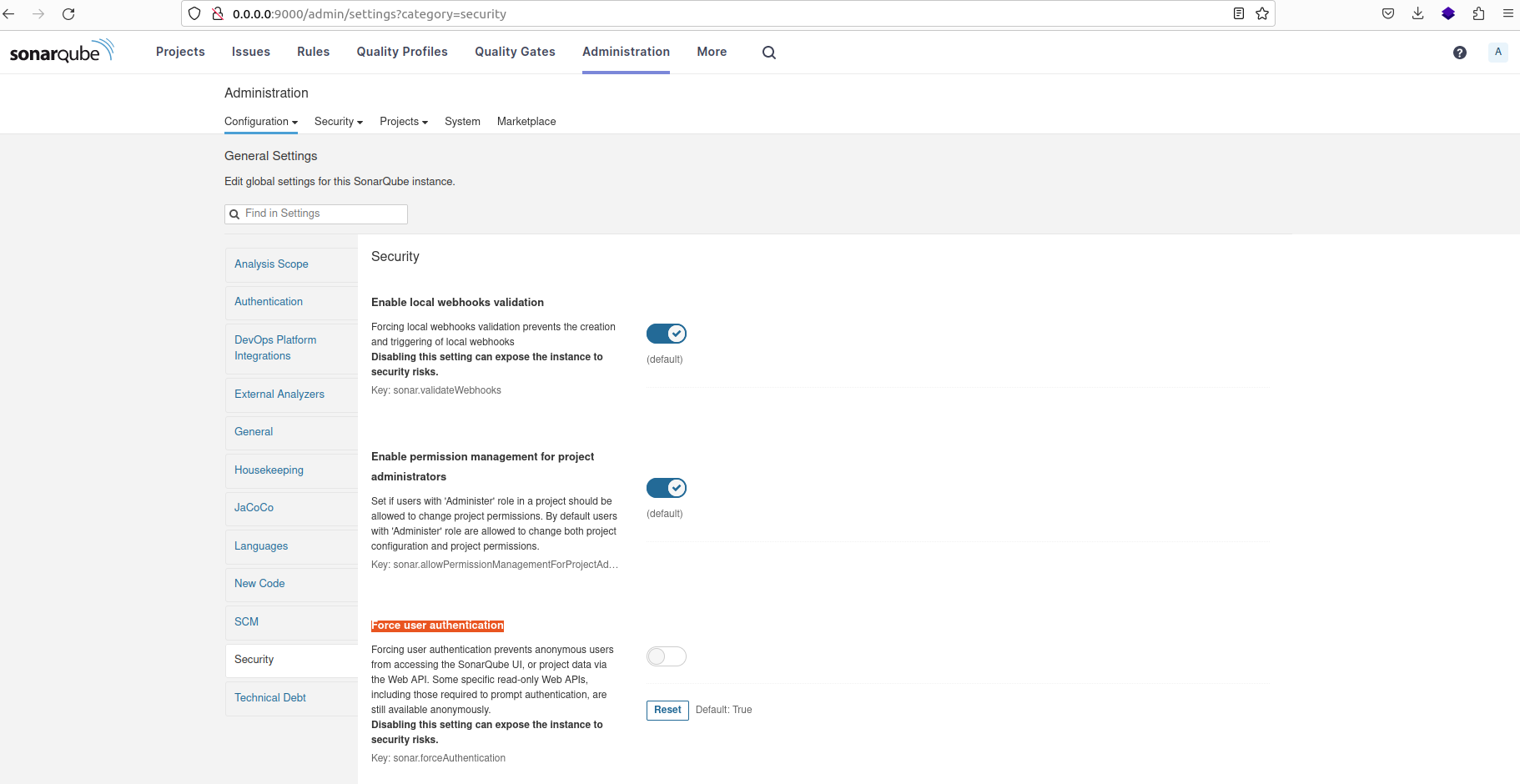 Débogage de l'erreur d'authentification lors de l'analyse du projet
Débogage de l'erreur d'authentification lors de l'analyse du projet
Une autre façon de résoudre les erreurs est de visiter les notifications d'avertissement et de vérifier les erreurs rencontrées lors de l'analyse du projet.
 Messages d'avertissement pour l'analyse
Messages d'avertissement pour l'analyse
Cliquez sur "Code global" pour accéder à la section d'analyse globale du code :
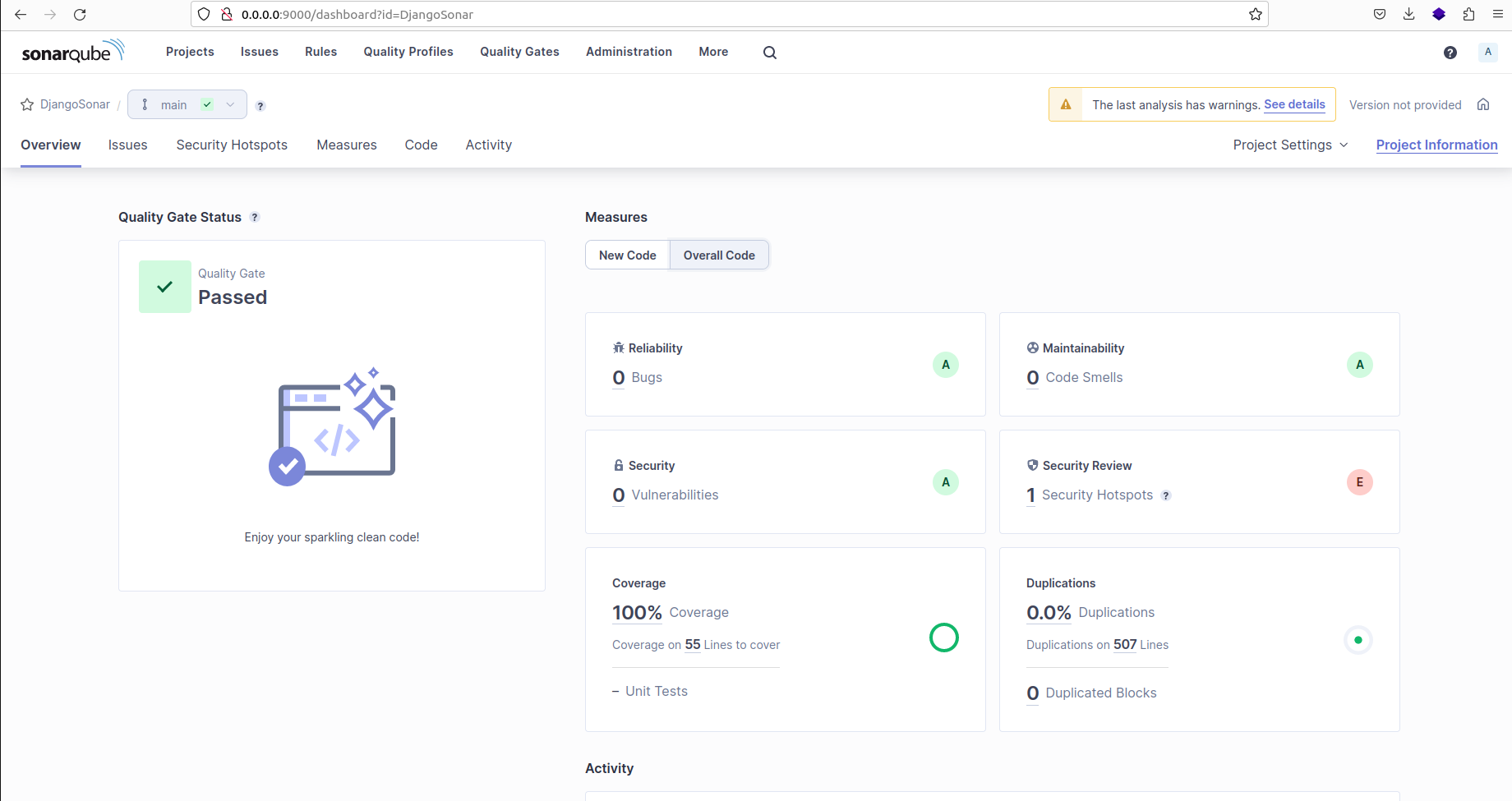 Résultat de l'analyse SonarQube pour le projet sur le tableau de bord
Résultat de l'analyse SonarQube pour le projet sur le tableau de bord
Conclusion
Le code source complet de ce projet est disponible sur Github.
N'oubliez pas de créer un fichier .gitignore dans le répertoire racine de votre dépôt GitHub pour spécifier les fichiers et répertoires qui doivent être ignorés et non commités.
Cet article a exploré le processus de mesure de la qualité du code Django en utilisant des outils puissants tels que SonarQube, Pytest et Coverage. En intégrant ces outils, vous pouvez obtenir des informations sur la santé du code, écrire des tests efficaces et garantir une couverture de code adéquate.
L'application de ces pratiques améliore la qualité du code, ce qui entraîne des processus de développement efficaces et des logiciels de haute qualité.
Si vous avez aimé cet article, vous pouvez consulter ma collection de vidéos sur YouTube pour trouver plus de choses amusantes à apprendre. Et suivez-moi sur LinkedIn