


Article original : How to Read and Write Data using Azure Databricks
Azure Databricks est une plateforme d'analyse de données hébergée sur Microsoft Azure qui vous aide à analyser des données en utilisant Apache Spark.
Databricks vous aide à créer des applications de données plus rapidement. Cela révèle des informations précieuses à partir de vos données et vous aide à créer des solutions robustes d'intelligence artificielle.
Azure Databricks combine également la puissance de Databricks en tant que plateforme Apache Spark de bout en bout avec la scalabilité et la sécurité de la plateforme Azure de Microsoft.
Dans ce tutoriel, vous apprendrez à commencer avec la plateforme dans Microsoft Azure et verrez comment effectuer des interactions de données, y compris la lecture, l'écriture et l'analyse de jeux de données. À la fin de ce tutoriel, vous serez en mesure d'utiliser Azure Databricks pour lire plusieurs types de fichiers, avec et sans schéma.
Prérequis
Vous aurez besoin d'un compte Microsoft Azure valide et actif.
- Essai gratuit Azure : Avec cette option, vous commencez avec 100 $ de crédit Azure et avez 30 jours pour l'utiliser en plus des services gratuits.
- Azure pour les étudiants : Cette offre est disponible uniquement pour les étudiants. Avec cette option, vous commencez avec 100 $ de crédit Azure sans besoin de carte de crédit. Vous aurez accès à des services populaires gratuitement tant que vous avez du crédit.
Comment créer votre espace de travail Databricks
Vous devez créer un espace de travail Azure Databricks dans votre abonnement Azure avant de pouvoir utiliser Azure Databricks. Rendez-vous sur le portail Azure pour ce faire. Tant que vous avez créé un compte Microsoft Azure valide et actif, cela fonctionnera.
 La page d'accueil de Microsoft Azure
La page d'accueil de Microsoft Azure
Une fois là-bas, cliquez sur le bouton Créer une ressource.
Dans la barre de recherche de la page Créer une ressource, recherchez Azure Databricks et sélectionnez l'option Azure Databricks.
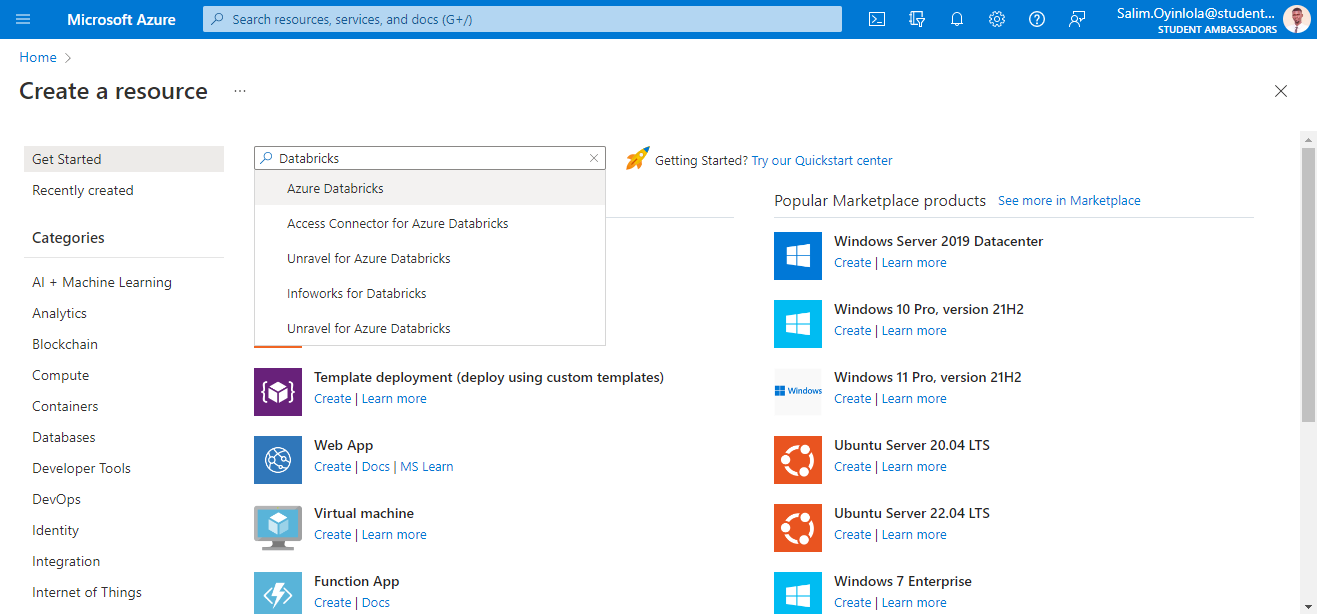 La page Microsoft Azure montrant la liste des ressources populaires
La page Microsoft Azure montrant la liste des ressources populaires
Ouvrez l'onglet Azure Databricks et créez une instance.
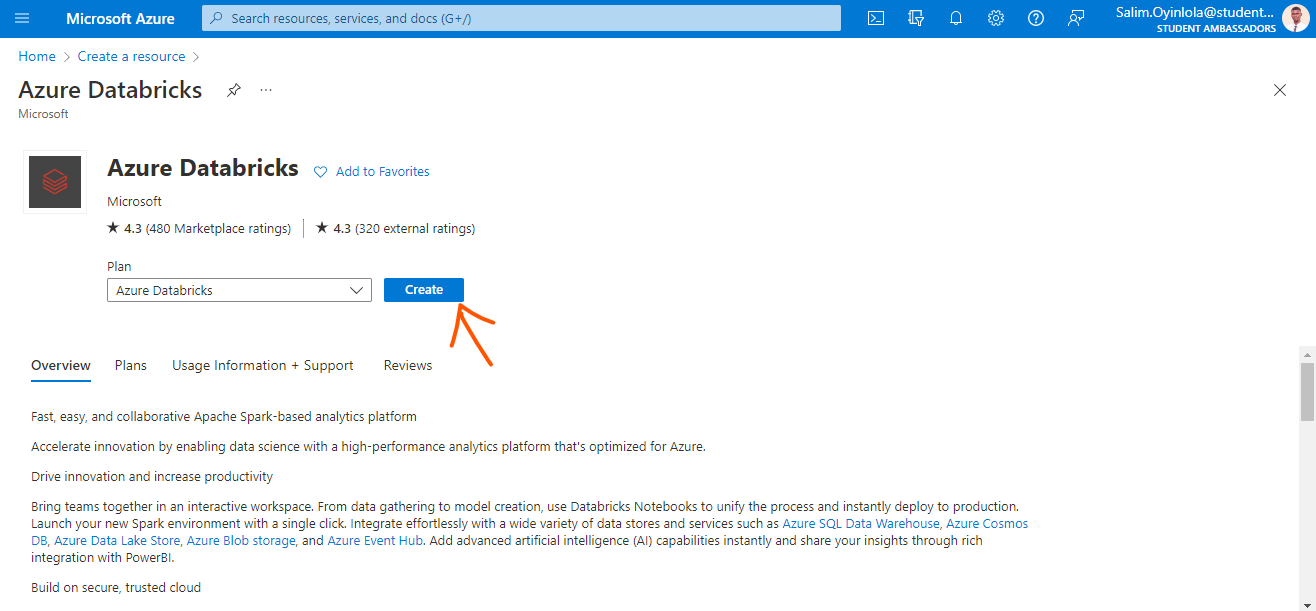 Le panneau Azure Databricks.
Le panneau Azure Databricks.
Cliquez sur le bouton bleu Créer (flèche pointée vers lui) pour créer une instance.
Ensuite, entrez les détails du projet avant de cliquer sur le bouton Vérifier + créer.
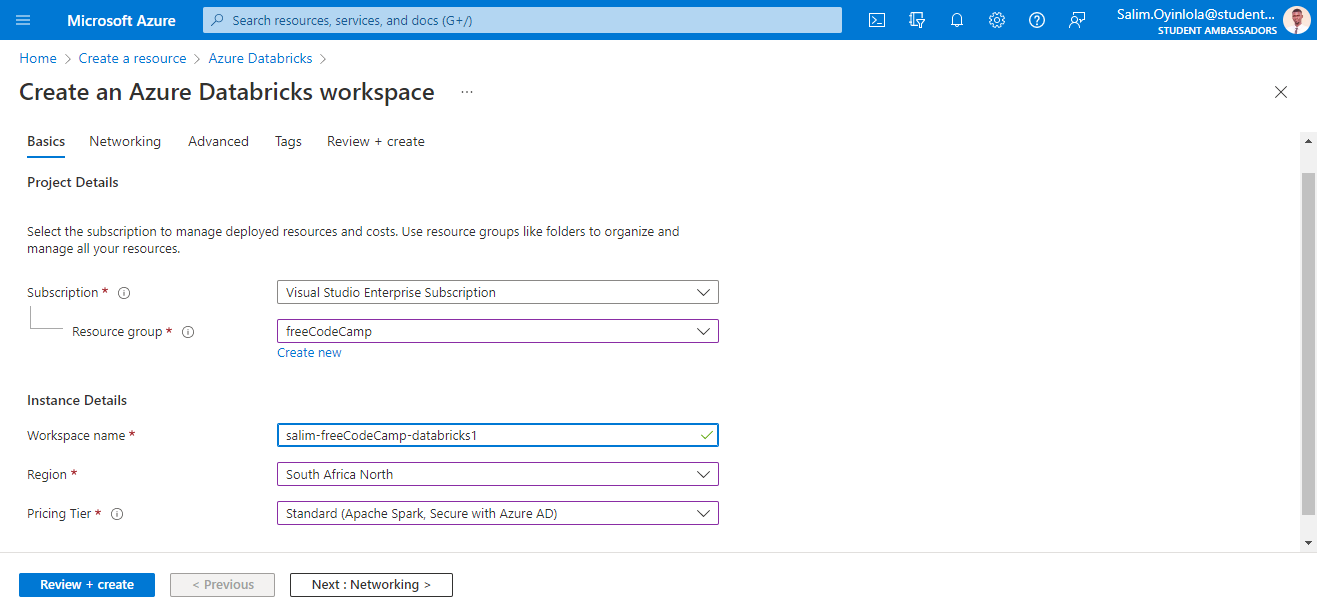 La page de configuration d'Azure Databricks
La page de configuration d'Azure Databricks
Il est important de noter que l'option Abonnement affichée ci-dessus sera différente de la vôtre. Elle dépendra de l'abonnement Azure disponible sur votre compte.
Remplissez le champ Nom de l'espace de travail avec un nom globalement unique. Le mien s'appelle salim-freeCodeCamp-databricks1.
Entrez l'emplacement le plus proche de votre position dans l'option Région. Une région est un ensemble de centres de données physiques qui servent de serveurs. Comme je suis basé à Lagos, au Nigeria, j'ai sélectionné Afrique du Sud Nord.
Sélectionnez l'option Standard qui inclut Apache Spark avec Azure AD dans l'option Niveau tarifaire.
Avec toutes les configurations définies, cliquez sur le bouton Vérifier + créer. Le processus de validation prend généralement environ deux minutes.
Avec les processus de validation et de déploiement terminés pour l'espace de travail, lancez l'espace de travail en utilisant le bouton Lancer l'espace de travail qui apparaît.
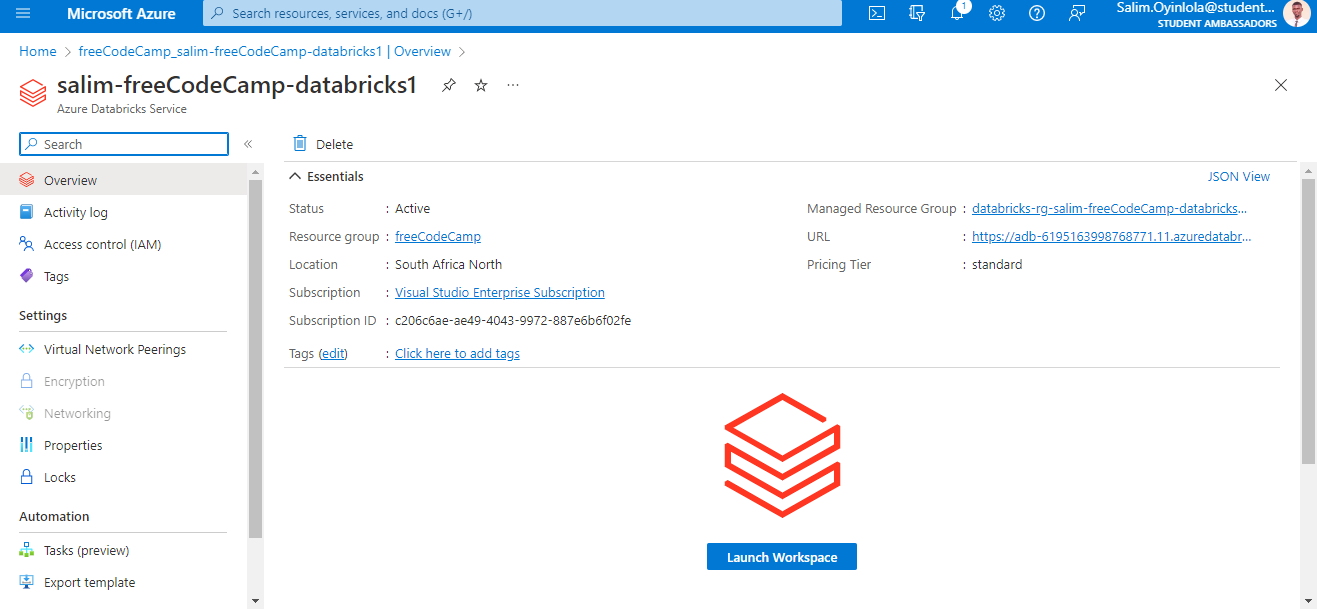 La page d'accueil de l'instance créée d'Azure Databricks -
La page d'accueil de l'instance créée d'Azure Databricks - salim-freeCodeCamp-databricks
Cliquez sur le bouton et vous serez automatiquement connecté en utilisant l'authentification unique du répertoire Azure.
 Connexion à l'espace de travail de l'intégration de Microsoft Azure et Databricks
Connexion à l'espace de travail de l'intégration de Microsoft Azure et Databricks
La page d'accueil de Microsoft Azure Databricks s'ouvrira dans un nouvel onglet comme montré ci-dessous :
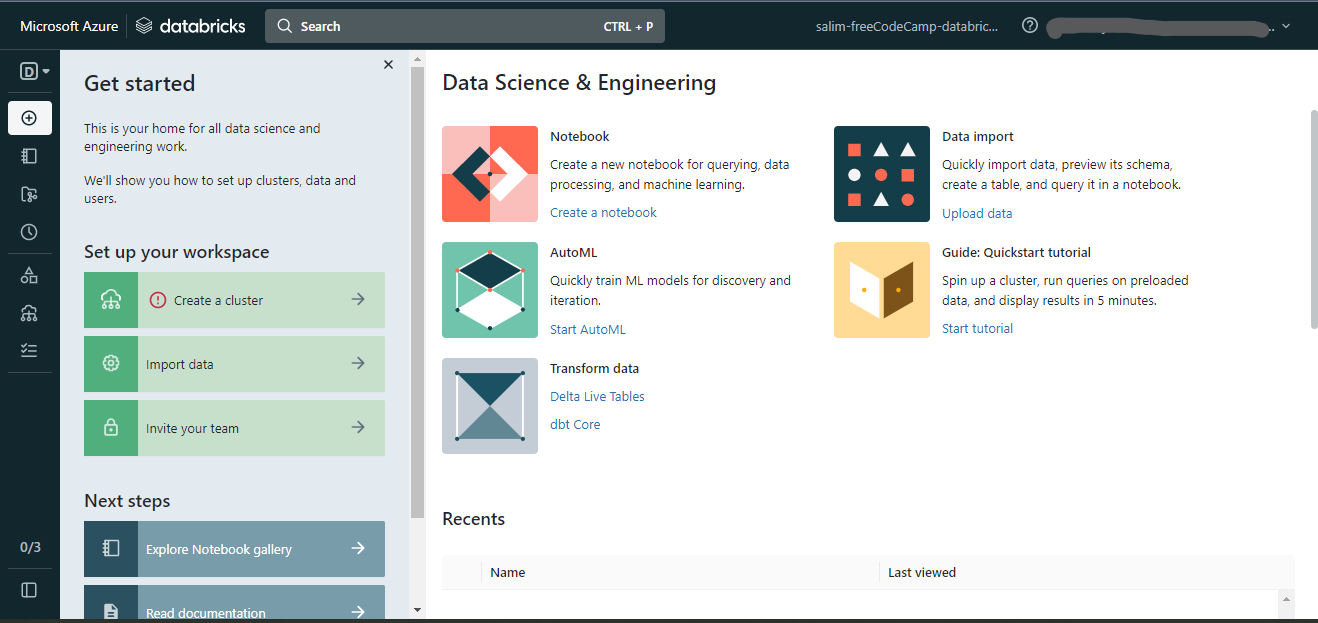 La page d'accueil de Microsoft Azure Databricks
La page d'accueil de Microsoft Azure Databricks
Avec le lancement de l'espace de travail, créez un cluster en utilisant l'option Créer un cluster à gauche de la page.
Après avoir cliqué sur le bouton et avoir créé un cluster précédent, vous en choisirez un et le développerez. Sinon, vous devrez créer un nouveau cluster en utilisant le bouton Créer un cluster.
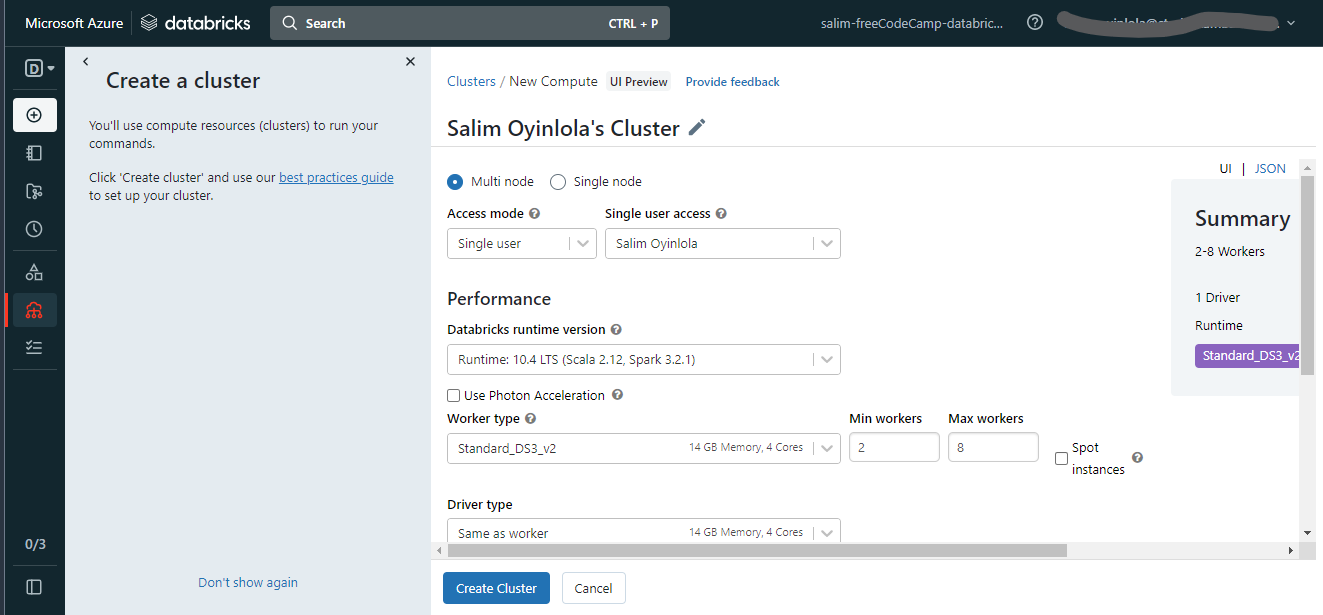 Définit les configurations pour le cluster Azure Databricks
Définit les configurations pour le cluster Azure Databricks
Pour créer le cluster, vous devez définir les configurations. Choisissez l'option Nœud unique, en changeant de l'option par défaut Multi-nœuds, et maintenez les autres options par défaut.
Cliquez sur le bouton Créer un cluster en bas de la page. Notez que cela prendra quelques minutes et que si le jeu de données est volumineux, vous pouvez explorer l'option Multi-nœuds.
Ayant créé le cluster, importez quelques notebooks prêts à l'emploi en naviguant vers Espace de travail > Utilisateurs > votre_compte sur la barre des tâches de gauche.
Faites un clic droit et sélectionnez l'option Importer dans le menu déroulant.
Avec le cluster créé, vous devrez ensuite importer quelques notebooks prêts à l'emploi.
Pour ce faire, en utilisant la barre des tâches de gauche, vous naviguerez à travers Espace de travail > Utilisateurs > votre_compte. Ensuite, faites un clic droit pour voir le menu déroulant. Vous sélectionnerez ensuite l'option Importer dans le menu déroulant.
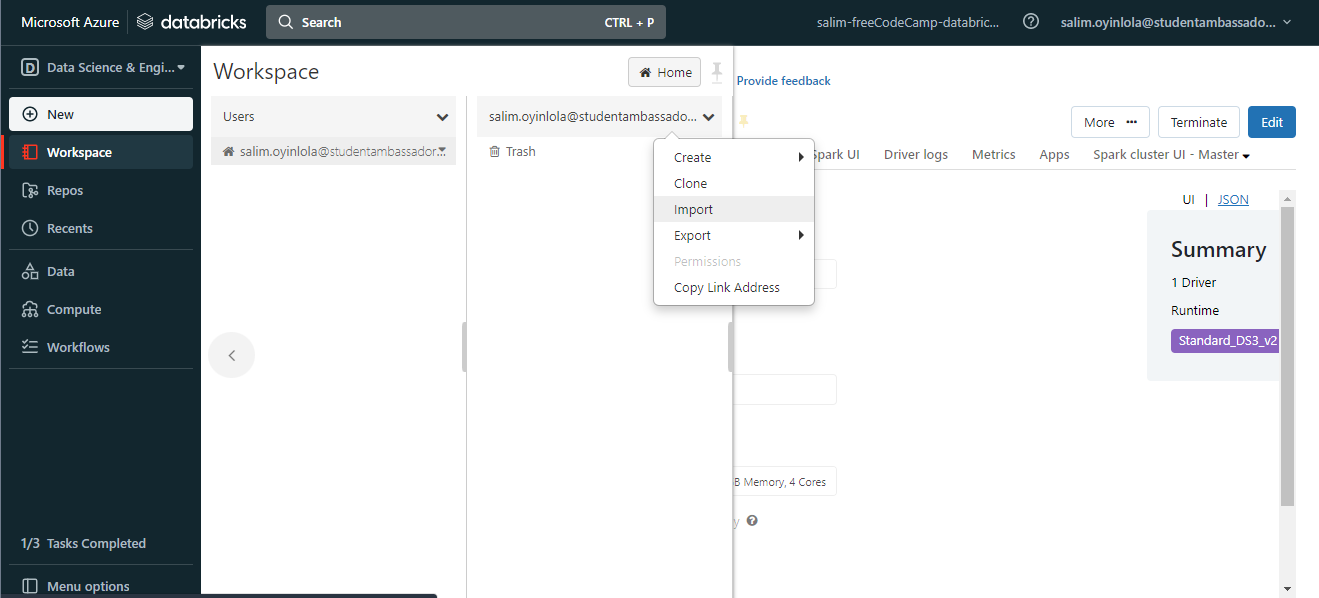 Le bouton
Le bouton importer sera utilisé pour importer le jeu de données à utiliser
Une fois que vous cliquez sur le bouton Importer, vous sélectionnerez ensuite l'option URL et collerez l'URL suivante :
https://github.com/salimcodes/microsoft-learning-paths-databricks-notebooks/blob/master/data-engineering/DBC/03-Reading-and-writing-data-in-Azure-Databricks.dbc
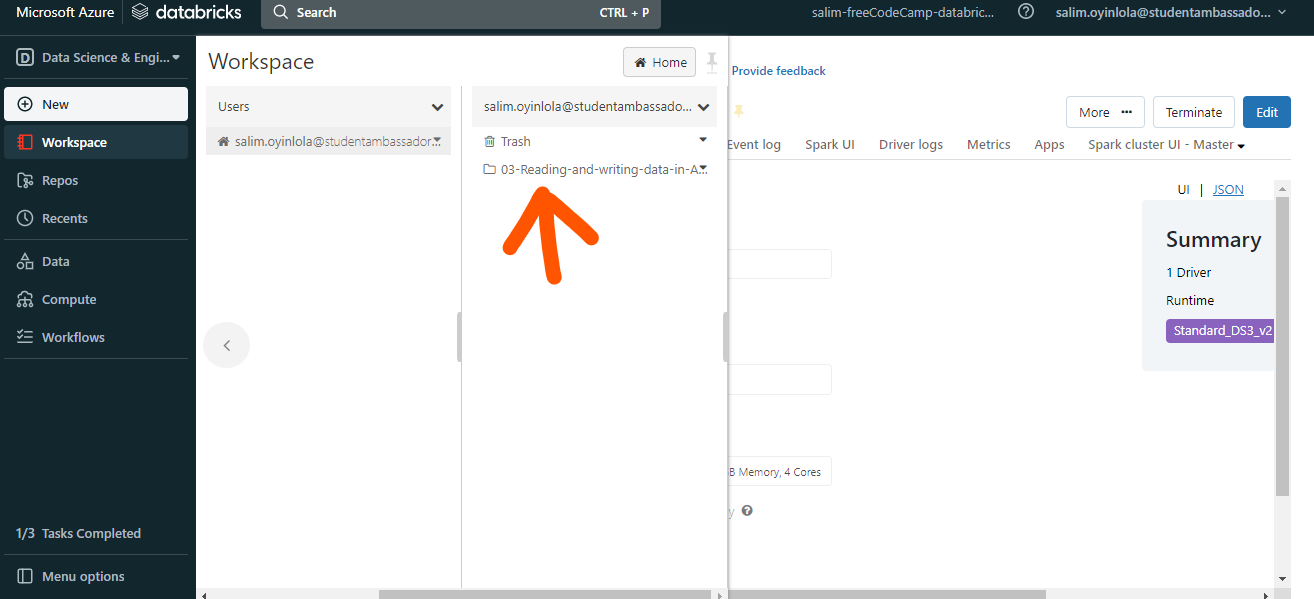 Le dossier de base de données nommé
Le dossier de base de données nommé 03-Reading-and-writing-data-in-Azure-Databricks.dbc sera utilisé,
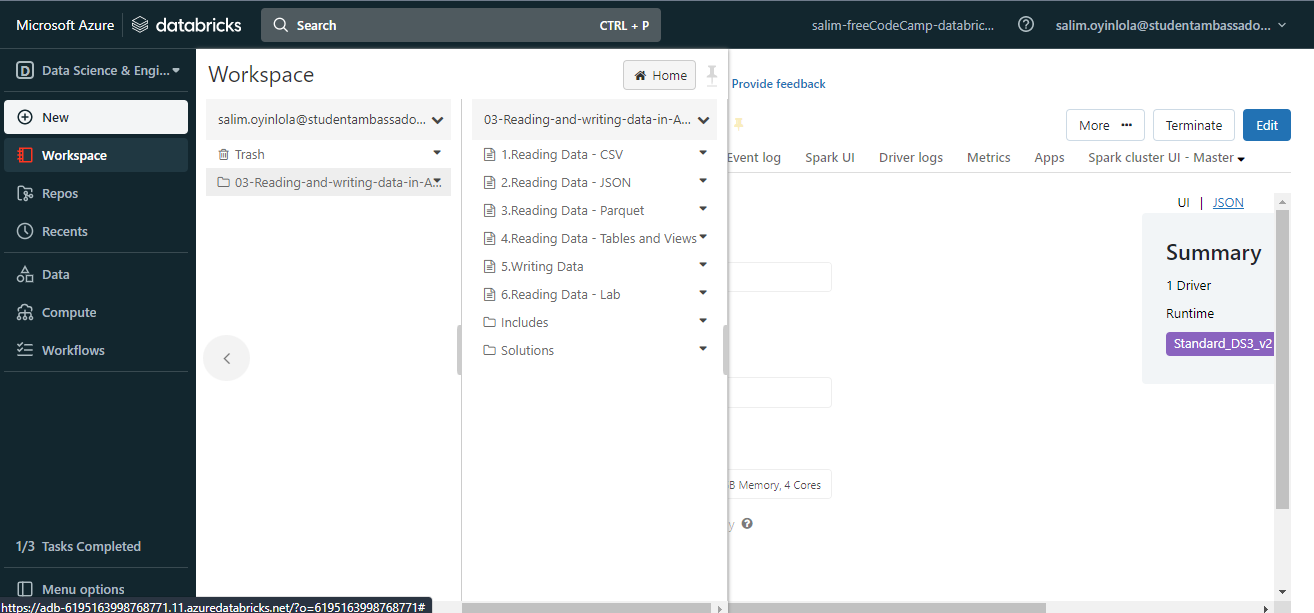 Vous verrez la liste des fichiers dans le dossier de base de données
Vous verrez la liste des fichiers dans le dossier de base de données 03-Reading-and-writing-data-in-Azure-Databricks.dbc
L'image ci-dessus montre à quoi ressemble l'espace de travail après avoir téléchargé le fichier. Ainsi, vous avez créé un espace de travail Databricks.
Comment lire les données au format CSV
Ouvrez le fichier nommé Reading Data - CSV.
Lors de l'ouverture du fichier, vous verrez le notebook montré ci-dessous :
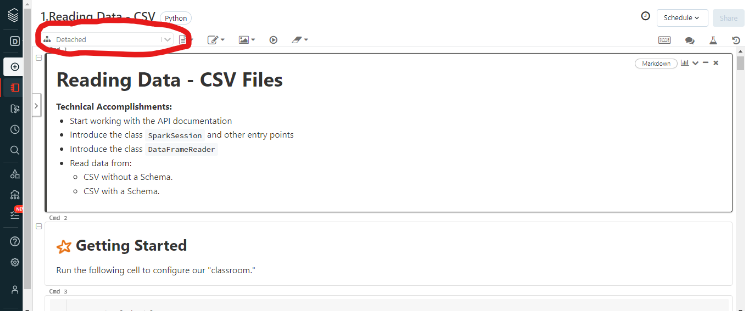 Vous verrez que le cluster créé précédemment n'a pas été attaché.
Vous verrez que le cluster créé précédemment n'a pas été attaché.
Dans le coin supérieur gauche, vous changerez le menu déroulant qui montre initialement Détaché par le nom de votre cluster. Le mien s'appelle Salim Oyinlola's freeCodeCamp Cluster.
 Le cluster initialement créé est maintenant attaché au notebook python
Le cluster initialement créé est maintenant attaché au notebook python
Avec votre cluster attaché, vous exécuterez ensuite toutes les cellules les unes après les autres.
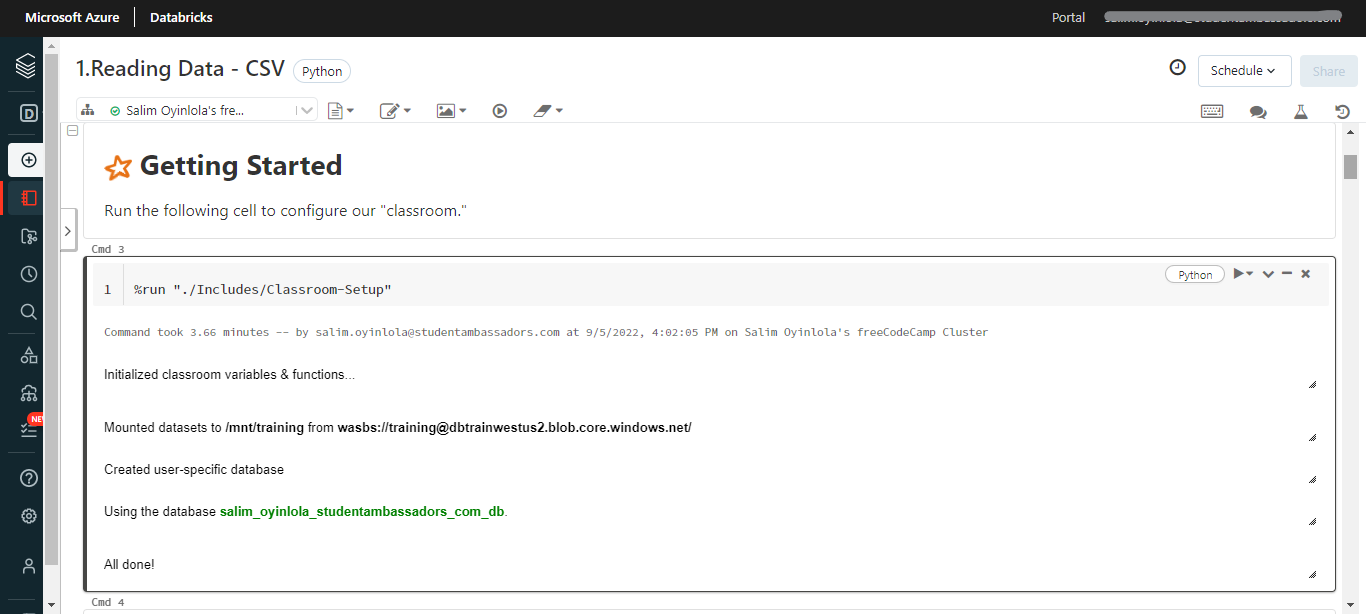 L'exécution de la première cellule du notebook python initialisera les variables et fonctions de la classe, montera le jeu de données et créera une base de données spécifique à l'utilisateur
L'exécution de la première cellule du notebook python initialisera les variables et fonctions de la classe, montera le jeu de données et créera une base de données spécifique à l'utilisateur
Au cœur du notebook, il lit simplement les données au format csv. Ensuite, il ajoute une option qui indique au lecteur que les données contiennent un en-tête et d'utiliser cet en-tête pour déterminer nos noms de colonnes.
Vous pouvez également ajouter une option qui indique au lecteur d'inférer les types de données de chaque colonne (également connu sous le nom de schéma).
Il est important de noter que les données peuvent être lues dans différents formats tels que JSON (avec ou sans schémas), parquet, et table et vues. Pour y parvenir, vous pouvez simplement exécuter les notebooks respectifs pour chaque format.
Comment écrire des données dans un fichier Parquet
Tout comme il existe de nombreuses façons de lire des données, il existe de nombreuses façons d'écrire des données. Mais dans ce notebook, nous allons jeter un coup d'œil rapide sur la façon d'écrire des données dans des fichiers Parquet.
Apache Parquet est un format de fichier de stockage en colonnes que les systèmes Hadoop (tels que Spark et Hive) utilisent. Le format de fichier est multiplateforme, indépendant du langage, et il stocke les données dans une disposition en colonnes en utilisant une représentation binaire.
Les fichiers Parquet, qui stockent efficacement de grands ensembles de données, ont l'extension .parquet.
Comme ce que vous avez fait lors de la lecture des données, vous exécuterez également les cellules les unes après les autres.
 La cellule pour écrire des données dans un fichier parquet
La cellule pour écrire des données dans un fichier parquet
Intégral à l'écriture dans le fichier parquet est la création d'un DataFrame. Vous allez en créer un en exécutant cette cellule.
 Cette cellule montre que les fichiers existants sont en cours de remplacement
Cette cellule montre que les fichiers existants sont en cours de remplacement
La méthode .mode"overwrite" montrée ci-dessous implique qu'en écrivant DataFrame dans des fichiers parquet, vous remplacez les fichiers existants.
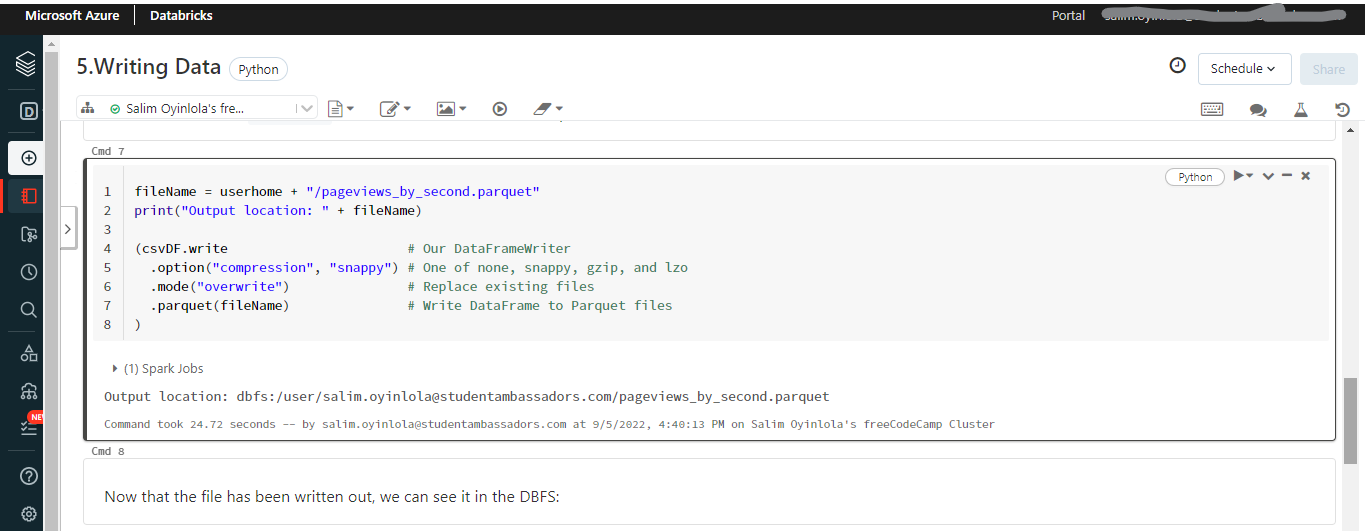 Le fichier a été écrit et enregistré dans un emplacement de sortie.
Le fichier a été écrit et enregistré dans un emplacement de sortie.
Au cœur du notebook, il lit un fichier .tsv (le même utilisé pour lire le fichier .csv) et l'écrit en tant que fichier Parquet.
Comment supprimer l'instance Azure Databricks (facultatif)
Enfin, les ressources Azure que vous avez créées dans ce tutoriel peuvent entraîner des coûts continus. Pour éviter de tels coûts, il est important de supprimer la ressource ou le groupe de ressources qui contient toutes ces ressources. Vous pouvez le faire en utilisant le portail Azure.
- Accédez au portail Azure.
- Accédez au groupe de ressources qui contient votre instance Azure Databricks.
- Sélectionnez
Supprimer le groupe de ressources. - Tapez le nom du groupe de ressources dans la zone de texte de confirmation.
- Sélectionnez
Supprimer.
Conclusion
Dans ce tutoriel, vous avez appris les bases de la lecture et de l'écriture de données dans Azure Databricks.
Vous comprenez maintenant les bases d'Azure Databricks, y compris ce que c'est, comment l'installer, comment lire les fichiers CSV et parquet, et comment lire les fichiers parquet dans le système de fichiers Databricks (DBFS) en utilisant des options de compression.
Enfin, je partage mes écrits sur Twitter si vous avez aimé cet article et souhaitez en voir plus.
Merci d'avoir lu :)