


Article original : How AI Models Think: The Key Role of Activation Functions with Code Examples
Dans le domaine de l'intelligence artificielle, l'apprentissage automatique est le fondement de la plupart des applications révolutionnaires. Du traitement du langage à la reconnaissance d'images, l'apprentissage automatique est partout.
L'apprentissage automatique repose sur des algorithmes, des modèles statistiques et des réseaux de neurones. Et l'apprentissage profond est le sous-domaine de l'apprentissage automatique qui se concentre uniquement sur les réseaux de neurones.
Un élément clé de tout réseau de neurones sont les fonctions d'activation. Mais comprendre exactement pourquoi elles sont essentielles à tout système de réseau de neurones est une question courante, et elle peut être difficile à répondre.
Ce tutoriel se concentre sur l'explication, de manière simple avec des analogies, pourquoi exactement les fonctions d'activation sont nécessaires.
En comprenant cela, vous comprendrez le processus de réflexion des modèles d'IA.
Avant cela, nous allons explorer les réseaux de neurones en IA. Nous allons également explorer les fonctions d'activation les plus couramment utilisées.
Nous allons également analyser chaque ligne d'un exemple de code PyTorch très simple d'un réseau de neurones.
Dans cet article, nous allons explorer :
- Intelligence Artificielle et l'essor de l'apprentissage profond
- Comprendre les fonctions d'activation : Simplifier la mécanique des réseaux de neurones
- Analogie simple : La nécessité des fonctions d'activation
- Que se passe-t-il sans fonctions d'activation ?
- Exemple de code de fonction d'activation PyTorch
- Conclusion : Les héros méconnus des réseaux de neurones en IA
Cet article ne couvrira pas le dropout ou d'autres techniques de régularisation, l'optimisation des hyperparamètres, les architectures complexes comme les CNNs, ou les différences détaillées des variantes de descente de gradient.
Je veux simplement montrer pourquoi les fonctions d'activation sont nécessaires et ce qui se passe lorsqu'elles ne sont pas appliquées aux réseaux de neurones.
Si vous ne savez pas grand-chose sur l'apprentissage profond, je recommande personnellement ce cours accéléré sur l'apprentissage profond sur la chaîne YouTube de freeCodeCamp :
Intelligence Artificielle et l'essor de l'apprentissage profond
Qu'est-ce que l'apprentissage profond en Intelligence Artificielle ?
L'apprentissage profond est un sous-domaine de l'intelligence artificielle. Il utilise des réseaux de neurones pour traiter des motifs complexes, tout comme les stratégies qu'une équipe sportive utilise pour gagner un match.
Plus le réseau de neurones est grand, plus il est capable de faire des choses incroyables – comme ChatGPT, par exemple, qui utilise le traitement du langage naturel pour répondre aux questions et interagir avec les utilisateurs.
Pour vraiment comprendre les bases des réseaux de neurones – ce que tous les modèles d'IA ont en commun qui leur permet de fonctionner – nous devons comprendre les couches d'activation.
Apprentissage profond = Entraînement des réseaux de neurones
 Réseau de neurones simple
Réseau de neurones simple
Au cœur de l'apprentissage profond se trouve l'entraînement des réseaux de neurones.
Cela signifie essentiellement utiliser des données pour obtenir les bonnes valeurs des poids afin de pouvoir prédire ce que nous voulons.
Les réseaux de neurones sont constitués de neurones organisés en couches. Chaque couche extrait des caractéristiques uniques des données.
Cette structure en couches permet aux modèles d'apprentissage profond d'analyser et d'interpréter des données complexes.
Comprendre les fonctions d'activation : Simplifier la mécanique des réseaux de neurones
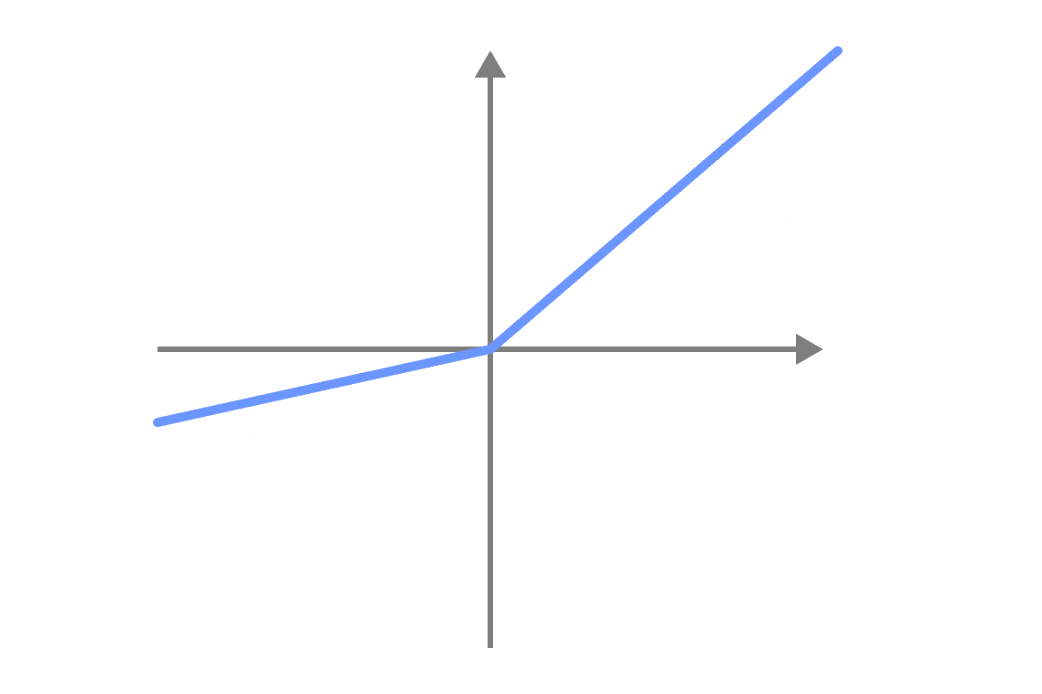 Fonction d'activation Leaky reLU
Fonction d'activation Leaky reLU
Les fonctions d'activation aident les réseaux de neurones à gérer des données complexes. Elles changent la valeur du neurone en fonction des données qu'ils reçoivent.
C'est presque comme un filtre que chaque neurone a avant d'envoyer sa valeur au neurone suivant.
Essentiellement, les fonctions d'activation contrôlent le flux d'informations des réseaux de neurones – elles décident quelles données sont pertinentes et lesquelles ne le sont pas.
Cela aide à prévenir les gradients qui disparaissent pour s'assurer que le réseau apprend correctement.
Le problème des gradients qui disparaissent se produit lorsque les signaux d'apprentissage du réseau de neurones sont trop faibles pour faire changer les valeurs des poids. Cela rend l'apprentissage à partir des données très difficile.
Analogie simple : Pourquoi les fonctions d'activation sont nécessaires
Dans un match de football, les joueurs décident de passer, dribbler ou tirer le ballon.
Ces décisions sont basées sur la situation actuelle du jeu, tout comme les neurones dans un réseau de neurones traitent les données.
Dans ce cas, les fonctions d'activation agissent comme cela dans le processus de prise de décision.
Sans elles, les neurones transmettraient les données sans aucune analyse sélective – comme des joueurs frappe le ballon sans réfléchir indépendamment du contexte du jeu.
De cette manière, les fonctions d'activation introduisent de la complexité dans un réseau de neurones, lui permettant d'apprendre des motifs complexes.
Que se passe-t-il sans fonctions d'activation ?
Pour comprendre ce qui se passerait sans fonctions d'activation, pensons d'abord à ce qui se passe si les joueurs frappent le ballon sans réfléchir dans un match de football.
Ils perdraient probablement le match car il n'y aurait aucun processus de prise de décision en tant qu'équipe. Ce ballon va toujours quelque part – mais la plupart du temps, il n'ira pas là où il est destiné.
Cela est similaire à ce qui se passe dans un réseau de neurones sans fonctions d'activation : le réseau de neurones ne fait pas de bonnes prédictions car les neurones se contentaient de transmettre les données les uns aux autres de manière aléatoire.
Nous obtenons toujours une prédiction. Juste pas ce que nous voulions, ou ce qui est utile.
Cela limite considérablement la capacité – à la fois de l'équipe de football et du réseau de neurones.
Explication intuitive des fonctions d'activation
Regardons maintenant un exemple pour que vous puissiez comprendre cela de manière intuitive.
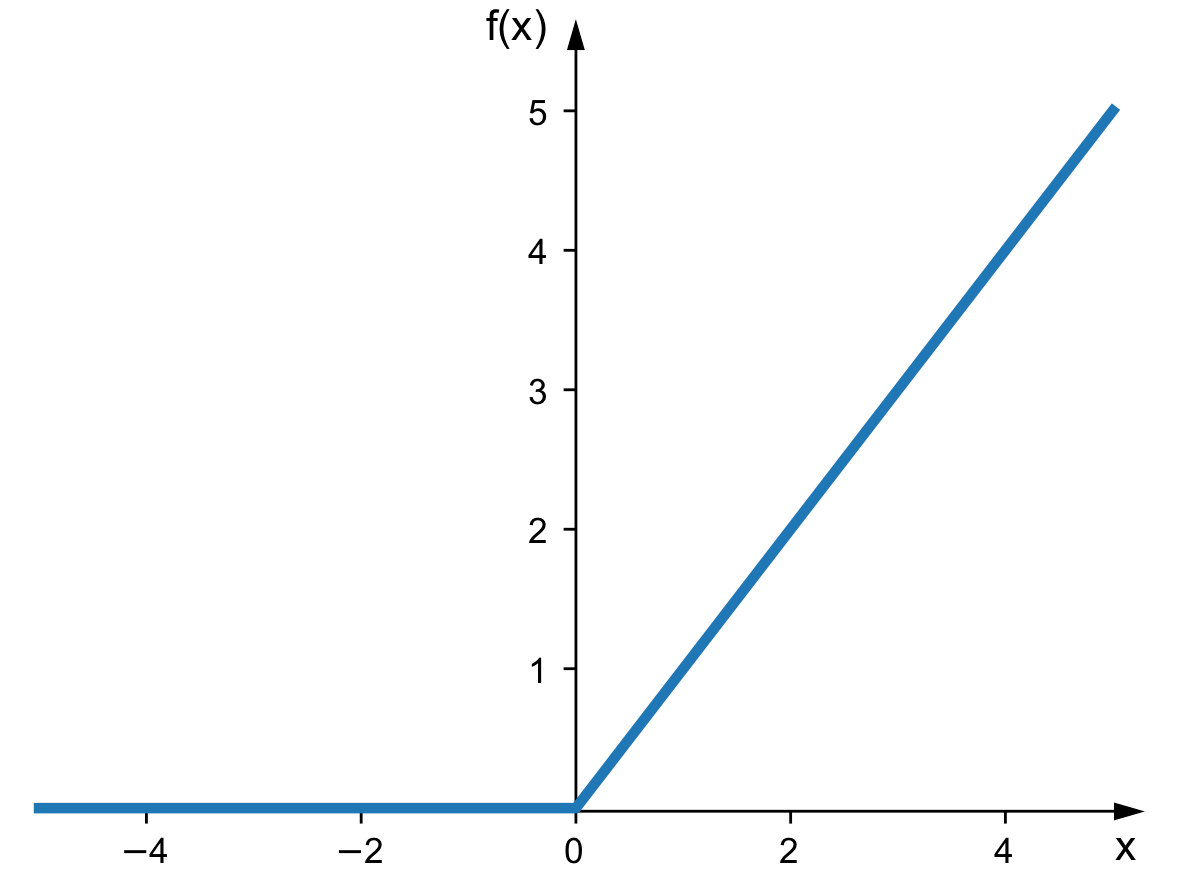 Fonction d'activation reLU
Fonction d'activation reLU
Commençons par la fonction d'activation la plus largement utilisée en apprentissage profond (c'est aussi l'une des plus simples).
Il s'agit d'une fonction d'activation ReLU. Elle agit essentiellement comme un filtre avant qu'un neurone envoie une valeur à son neurone suivant.
Ce filtre est essentiellement deux conditions :
- Si la valeur du poids est négative, elle devient 0
- Si la valeur du poids est positive, elle ne change rien
Avec cela, nous ajoutons un processus de prise de décision à chaque neurone. Il décide quelles données envoyer et lesquelles ne pas envoyer.
Regardons maintenant quelques exemples d'autres fonctions d'activation.
Fonctions d'activation Sigmoid
Cette fonction d'activation convertit la valeur d'entrée entre 0 et 1. Les Sigmoïdes sont largement utilisées dans les problèmes de classification binaire dans le dernier neurone.
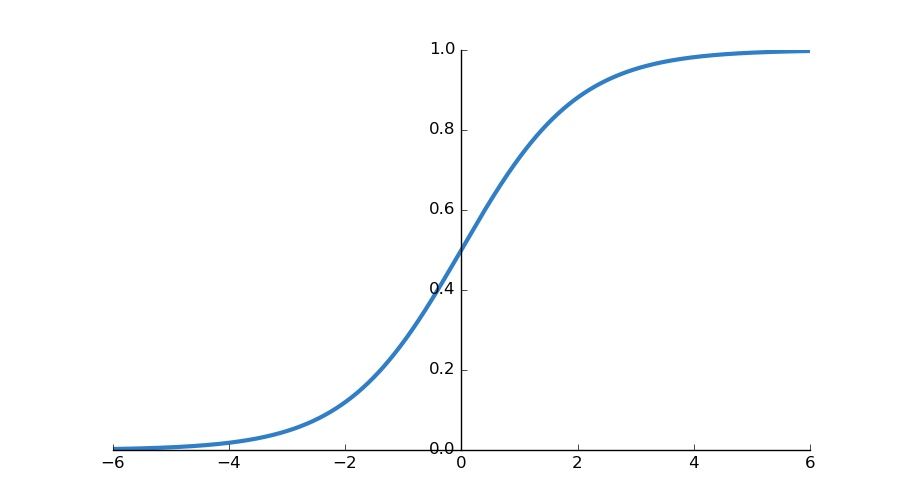 Fonction d'activation Sigmoid
Fonction d'activation Sigmoid
Il y a un problème avec les fonctions d'activation sigmoïdes, cependant. Prenons les valeurs de sortie d'une transformation linéaire donnée :
- 0.00000003
- 0.99999992
- 0.00000247
- 0.99993320
Il y a quelques questions sur ces valeurs que nous pouvons poser :
- Les valeurs comme 0.00000003 et 0.000002 sont-elles vraiment importantes ? Ne peuvent-elles pas être simplement 0 pour que nous ayons moins de choses à exécuter sur l'ordinateur ? N'oubliez pas que dans de nombreux modèles d'aujourd'hui, nous avons des millions de poids. Des millions de 0.00000003 et 0.000002 ne peuvent-ils pas être 0 ?
- Et si c'est une valeur positive, comment distinguera-t-elle une grande valeur d'une très grande valeur ? Par exemple, dans 0.99993320 et 0.99999992, où sont les valeurs d'entrée comme 7 et 13 ou 7 et 55 ? 0.99993320 et 0.99999992 ne décrivent pas avec précision leurs valeurs d'entrée.
Comment pouvons-nous distinguer les différences subtiles dans les sorties pour que la précision soit maintenue ?
C'est ce que les fonctions d'activation ReLU ont résolu : mettre les nombres négatifs à zéro tout en gardant les positifs améliore l'efficacité computationnelle du réseau de neurones.
Fonctions d'activation Tanh (Tangente hyperbolique)
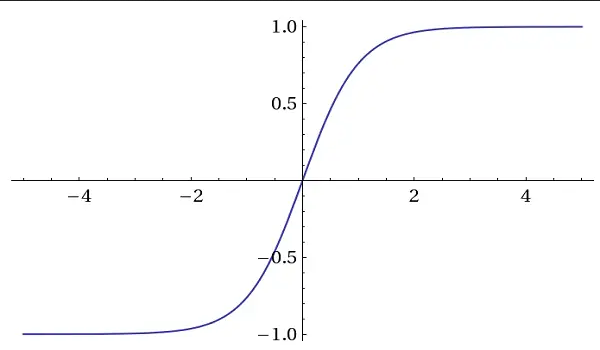 Fonction d'activation tanh
Fonction d'activation tanh
Ces fonctions d'activation produisent des valeurs entre -1 et 1, similaires à Sigmoid.
Elles sont souvent utilisées dans les réseaux de neurones récurrents (RNN) et les réseaux de mémoire à long et court terme (LSTM).
Tanh est également utilisé car il est centré sur zéro. Cela signifie que la moyenne des valeurs de sortie est autour de zéro. Cette propriété aide à traiter le problème des gradients qui disparaissent.
Leaky reLU
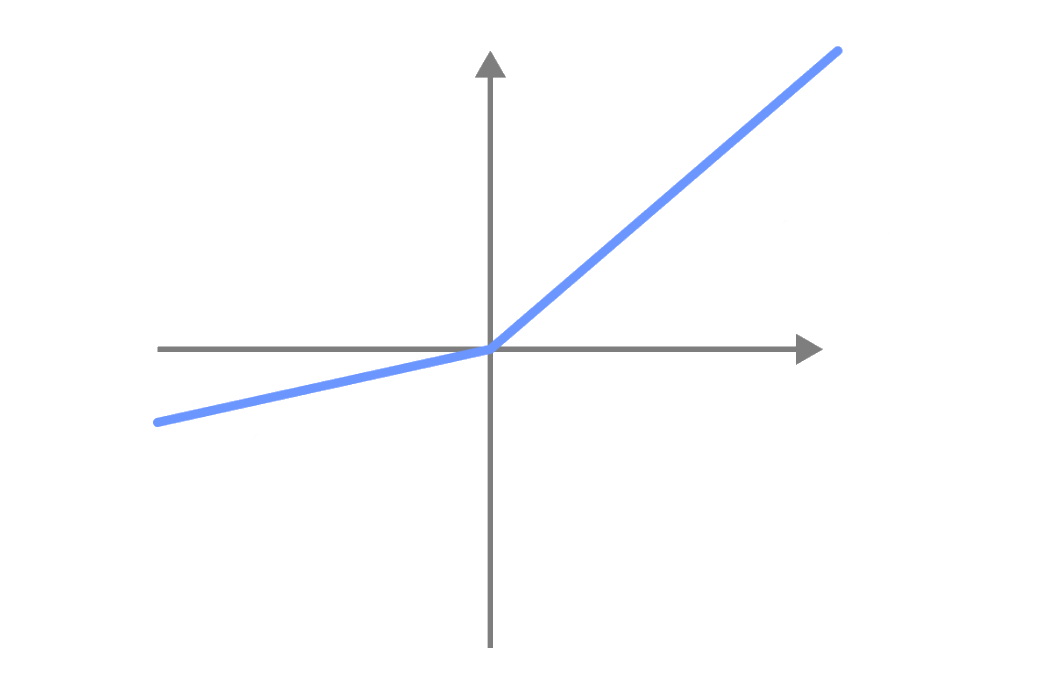 Fonction d'activation Leaky reLU
Fonction d'activation Leaky reLU
Au lieu d'ignorer les valeurs négatives, les fonctions d'activation Leaky ReLU vont avoir une petite valeur négative.
De cette manière, les valeurs négatives sont également utilisées lors de l'entraînement des réseaux de neurones.
Avec la fonction d'activation ReLU, les neurones avec des valeurs négatives sont inactifs et ne contribuent pas au processus d'apprentissage.
Avec la fonction d'activation Leaky ReLU, les neurones avec des valeurs négatives sont actifs et contribuent au processus d'apprentissage.
Ce processus de prise de décision est mis en œuvre par les fonctions d'activation. Sans cela, il enverrait simplement les données au neurone suivant (comme un joueur qui frappe le ballon sans réfléchir).
Explication mathématique des fonctions d'activation
Les neurones font deux choses :
- Ils utilisent des transformations linéaires avec les valeurs de poids des neurones précédents
- Ils utilisent des fonctions d'activation pour filtrer certaines valeurs afin de transmettre sélectivement des valeurs.
Sans fonctions d'activation, le réseau de neurones ne fait qu'une seule chose : des transformations linéaires.
S'il ne fait que des transformations linéaires, c'est un système linéaire.
S'il s'agit d'un système linéaire, en termes très simples sans être trop technique, le théorème de superposition nous dit que tout mélange de deux transformations linéaires ou plus peut être simplifié en une seule transformation.
Essentiellement, cela signifie que, sans fonctions d'activation, ce réseau de neurones complexe :
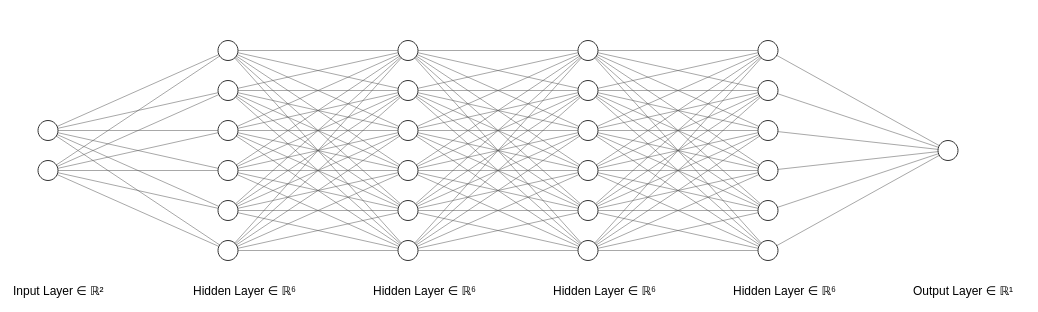 Réseau de neurones long sans fonctions d'activation
Réseau de neurones long sans fonctions d'activation
Est le même que celui-ci simple :
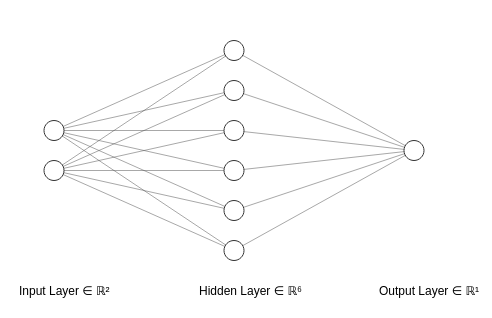 Réseau de neurones court sans fonctions d'activation
Réseau de neurones court sans fonctions d'activation
C'est parce que chaque couche sous sa forme matricielle est un produit de transformations linéaires des couches précédentes.
Et selon le théorème, puisque tout mélange de deux transformations linéaires ou plus peut être simplifié en une seule transformation, alors tout mélange de couches cachées (c'est-à-dire les couches entre les entrées et les sorties des neurones) dans un réseau de neurones peut être simplifié en une seule couche.
Que signifie tout cela ?
Cela signifie qu'il ne peut modéliser les données que de manière linéaire. Mais dans la vie réelle avec des données réelles, chaque système est non linéaire. Nous avons donc besoin de fonctions d'activation.
Nous introduisons la non-linéarité dans un réseau de neurones afin qu'il apprenne des motifs non linéaires.
Exemple de code de fonction d'activation PyTorch
Dans cette section, nous allons entraîner le réseau de neurones ci-dessous :
 Réseau de neurones simple à propagation directe
Réseau de neurones simple à propagation directe
Il s'agit d'un modèle d'IA de réseau de neurones simple avec quatre couches :
- Couche d'entrée avec 10 neurones
- Deux couches cachées avec 18 neurones
- Une couche cachée avec 18 neurones
- Une couche de sortie avec 1 neurone
Dans le code, nous pouvons choisir l'une des quatre fonctions d'activation mentionnées dans ce tutoriel.
Voici le code complet – nous en discuterons en détail ci-dessous :
import torch
import torch.nn as nn
import torch.optim as optim
#Choisir quelle fonction d'activation utiliser dans le code
defined_activation_function = 'relu'
activation_functions = {
'relu': nn.ReLU(),
'sigmoid': nn.Sigmoid(),
'tanh': nn.Tanh(),
'leaky_relu': nn.LeakyReLU()
}
# Initialisation des hyperparamètres
num_samples = 100
batch_size = 10
num_epochs = 150
learning_rate = 0.001
# Définir un ensemble de données synthétique simple
def generate_data(num_samples):
X = torch.randn(num_samples, 10)
y = torch.randn(num_samples, 1)
return X, y
# Générer des données synthétiques
X, y = generate_data(num_samples)
class SimpleModel(nn.Module):
def __init__(self, activation=defined_activation_function):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(in_features=10, out_features=18)
self.fc2 = nn.Linear(in_features=18, out_features=18)
self.fc3 = nn.Linear(in_features=18, out_features=4)
self.fc4 = nn.Linear(in_features=4, out_features=1)
self.activation = activation_functions[activation]
def forward(self, x):
x = self.fc1(x)
x = self.activation(x)
x = self.fc2(x)
x = self.activation(x)
x = self.fc3(x)
x = self.activation(x)
x = self.fc4(x)
return x
# Initialiser le modèle, définir la fonction de perte et l'optimiseur
model = SimpleModel(activation=defined_activation_function)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Boucle d'entraînement
for epoch in range(num_epochs):
for i in range(0, num_samples, batch_size):
# Obtenir le mini-lot
inputs = X[i:i+batch_size]
labels = y[i:i+batch_size]
# Mettre à zéro les gradients des paramètres
optimizer.zero_grad()
# Passe avant
outputs = model(inputs)
# Calculer la perte
loss = criterion(outputs, labels)
# Passe arrière et optimisation
loss.backward()
optimizer.step()
print(f'Époque {epoch+1}/{num_epochs}, Perte : {loss}')
print("Entraînement terminé.")
Cela semble beaucoup, n'est-ce pas ? Ne vous inquiétez pas – nous allons le prendre morceau par morceau.
1 : Importation des bibliothèques et définition des fonctions d'activation
import torch
import torch.nn as nn
import torch.optim as optim
#Choisir quelle fonction d'activation utiliser dans le code
defined_activation_function = 'relu'
activation_functions = {
'relu': nn.ReLU(),
'sigmoid': nn.Sigmoid(),
'tanh': nn.Tanh(),
'leaky_relu': nn.LeakyReLU()
}
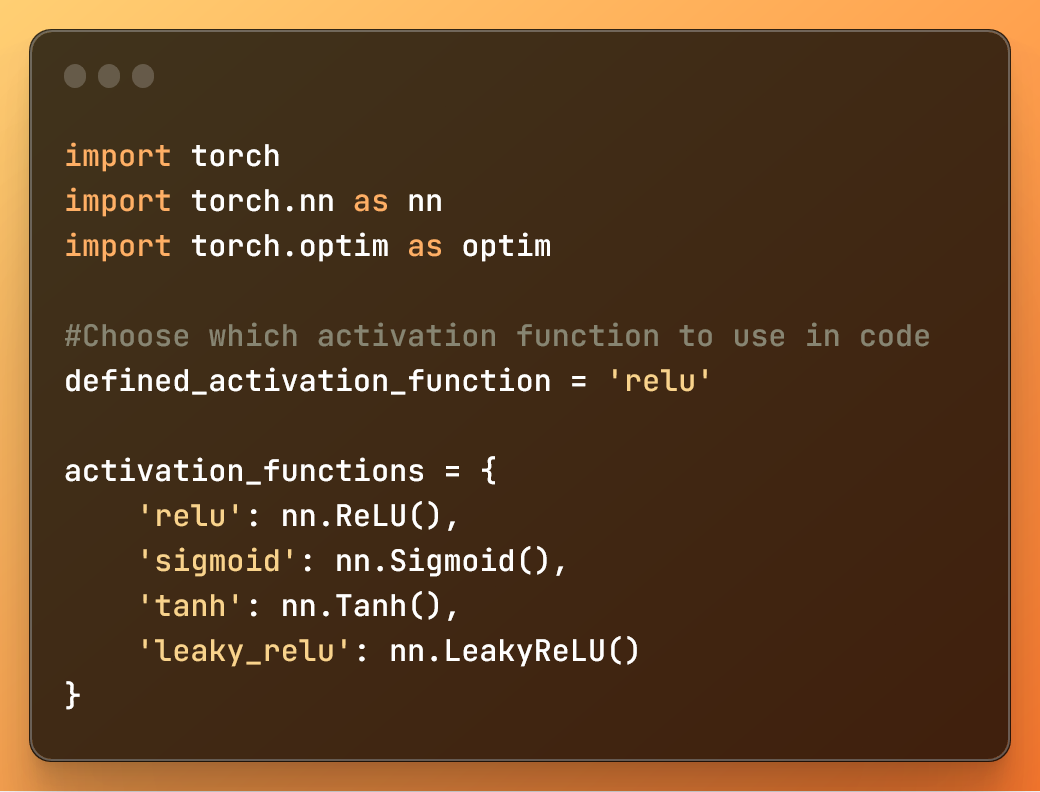 Importation des bibliothèques et définition du dictionnaire avec les fonctions d'activation
Importation des bibliothèques et définition du dictionnaire avec les fonctions d'activation
Dans ce code :
import torch: Importe la bibliothèque PyTorch.import torch.nn as nn: Importe le module de réseau de neurones de PyTorch.import torch.optim as optim: Importe le module d'optimisation de PyTorch.
La variable et le dictionnaire ci-dessus vous aident à définir facilement, pour ce modèle d'apprentissage profond, la fonction d'activation que vous souhaitez utiliser.
2 : Définition des hyperparamètres et génération d'un ensemble de données
# Initialisation des hyperparamètres
num_samples = 100
batch_size = 10
num_epochs = 150
learning_rate = 0.001
# Définir un ensemble de données synthétique simple
def generate_data(num_samples):
X = torch.randn(num_samples, 10)
y = torch.randn(num_samples, 1)
return X, y
# Générer des données synthétiques
X, y = generate_data(num_samples)
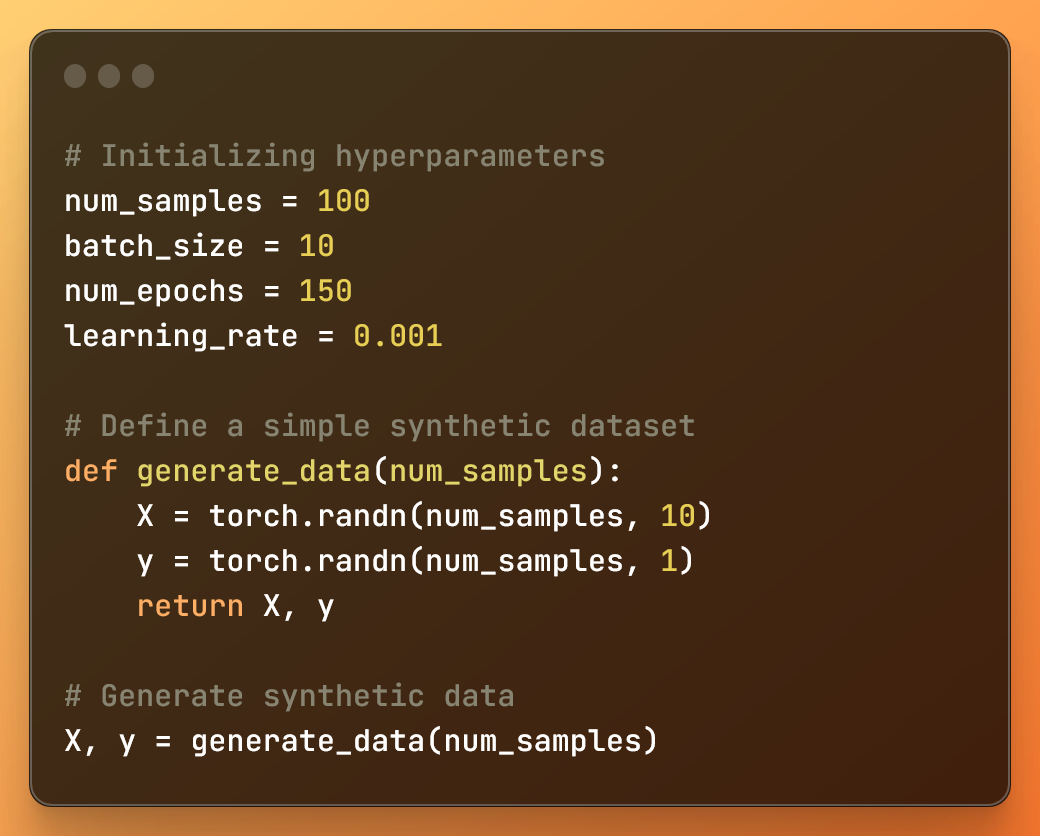 Initialisation des hyperparamètres et création, avec une fonction, d'un ensemble de données synthétique
Initialisation des hyperparamètres et création, avec une fonction, d'un ensemble de données synthétique
Dans ce code :
num_samplesest le nombre d'échantillons dans l'ensemble de données synthétique.batch_sizeest la taille de chaque mini-lot pendant l'entraînement.num_epochsest le nombre d'itérations sur l'ensemble de données pendant l'entraînement.learning_rateest le taux d'apprentissage utilisé par l'algorithme d'optimisation.
En outre, nous définissons une fonction generate_data pour créer deux tenseurs avec des valeurs aléatoires. Ensuite, elle appelle la fonction et génère, pour X et y, deux tenseurs avec des valeurs aléatoires.
3 : Création du modèle d'apprentissage profond
class SimpleModel(nn.Module):
def __init__(self, activation=defined_activation_function):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(in_features=10, out_features=18)
self.fc2 = nn.Linear(in_features=18, out_features=18)
self.fc3 = nn.Linear(in_features=18, out_features=4)
self.fc4 = nn.Linear(in_features=4, out_features=1)
self.activation = activation_functions[activation]
def forward(self, x):
x = self.fc1(x)
x = self.activation(x)
x = self.fc2(x)
x = self.activation(x)
x = self.fc3(x)
x = self.activation(x)
x = self.fc4(x)
return x
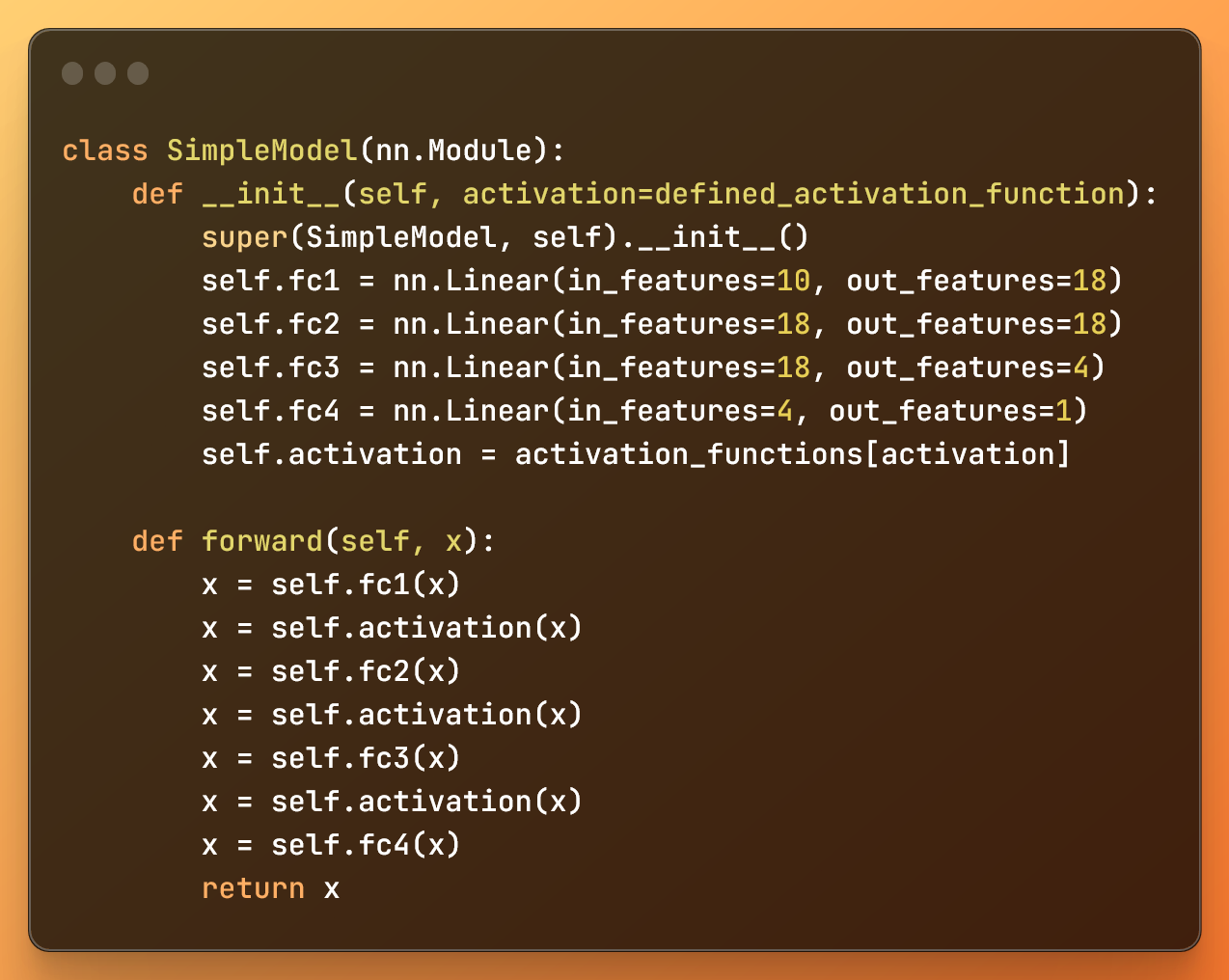 Un modèle d'IA de réseau de neurones simple à propagation directe
Un modèle d'IA de réseau de neurones simple à propagation directe
La méthode __init__ dans la classe SimpleModel initialise l'architecture du réseau de neurones. Elle initialise quatre couches entièrement connectées et définit la fonction d'activation que nous allons utiliser.
Nous créons chaque couche en utilisant nn.Linear, tandis que la méthode forward définit comment les données circulent à travers le réseau de neurones.
4 : Initialisation du modèle et définition de la fonction de perte et de l'optimiseur
model = SimpleModel(activation=defined_activation_function)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
 Définition de la fonction d'activation, de la fonction de perte et de la variation de descente de gradient à utiliser
Définition de la fonction d'activation, de la fonction de perte et de la variation de descente de gradient à utiliser
Dans ce code :
model = SimpleModel(activation=defined_activation_function)crée un modèle de réseau de neurones avec une fonction d'activation spécifiée.criterion = nn.MSELoss()définit la fonction de perte d'erreur quadratique moyenne (MSE).optimizer = optim.Adam(model.parameters(), lr=learning_rate)configure l'optimiseur Adam pour la mise à jour des paramètres du modèle pendant l'entraînement, avec un taux d'apprentissage spécifié.
5 : Entraînement du modèle d'apprentissage profond
for epoch in range(num_epochs):
for i in range(0, num_samples, batch_size):
# Obtenir le mini-lot
inputs = X[i:i+batch_size]
labels = y[i:i+batch_size]
# Mettre à zéro les gradients des paramètres
optimizer.zero_grad()
# Passe avant
outputs = model(inputs)
# Calculer la perte
loss = criterion(outputs, labels)
# Passe arrière et optimisation
loss.backward()
optimizer.step()
print(f'Époque {epoch+1}/{num_epochs}, Perte : {loss}')
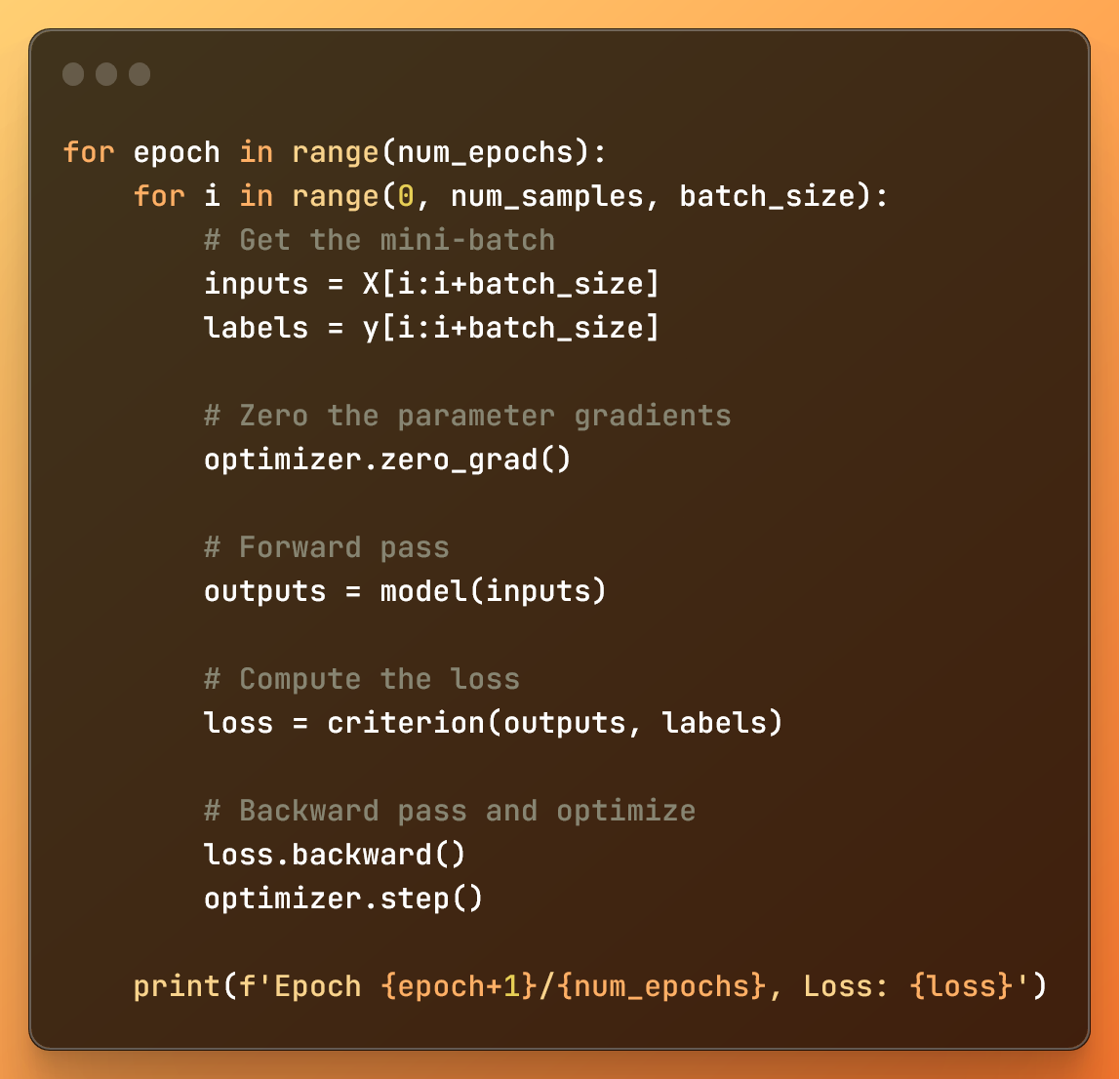 Entraînement du modèle
Entraînement du modèle
- La boucle externe, basée sur
num_epochs(nombre d'époques), contrôle combien de fois l'ensemble de données est traité. - La boucle interne divise l'ensemble de données en mini-lots en utilisant la fonction range.
Dans chaque mini-boucle :
- Avec les entrées et les étiquettes, nous obtenons les données du mini-lot que nous voulons traiter
- Nous éliminons avec
optimizer.zero_grad(), les gradients – variables qui nous disent comment ajuster les poids pour des prédictions précises – de l'itération précédente du mini-lot. Cela est important pour éviter de mélanger les informations de gradient entre les mini-lots. - La passe avant nous donne les prédictions du modèle (
outputs), et la perte est calculée en utilisant la fonction de perte spécifiée (criterion). - Avec
loss.backward(), nous calculons les gradients pour les poids. - Enfin,
optimizer.step()met à jour les poids du modèle en fonction de ces gradients pour minimiser la fonction de perte.
C'est le code complet pour entraîner un modèle d'apprentissage profond très simple sur un ensemble de données très simple.
Il n'a rien de plus avancé comme les réseaux de neurones convolutionnels.
Conclusion : Les héros méconnus des réseaux de neurones en IA
Les fonctions d'activation sont comme des gardiens. En restreignant le flux d'informations, le réseau de neurones peut mieux apprendre.
Les fonctions d'activation sont comme les personnes lorsqu'elles étudient, ou les joueurs de football lorsqu'ils décident quoi faire avec un ballon.
Ces fonctions donnent aux réseaux de neurones la capacité d'apprendre et de prédire correctement.
Mathématiquement, les fonctions d'activation sont ce qui permet l'approximation correcte de toute fonction linéaire ou non linéaire dans les réseaux de neurones. Sans elles, les réseaux de neurones n'approximeraient que des fonctions linéaires.
Et je vous laisse avec ceci :
L'idée mathématique qu'un réseau de neurones puisse approximer toute fonction non linéaire s'appelle le théorème d'approximation universelle.
Vous pouvez trouver le code complet sur GitHub ici :