

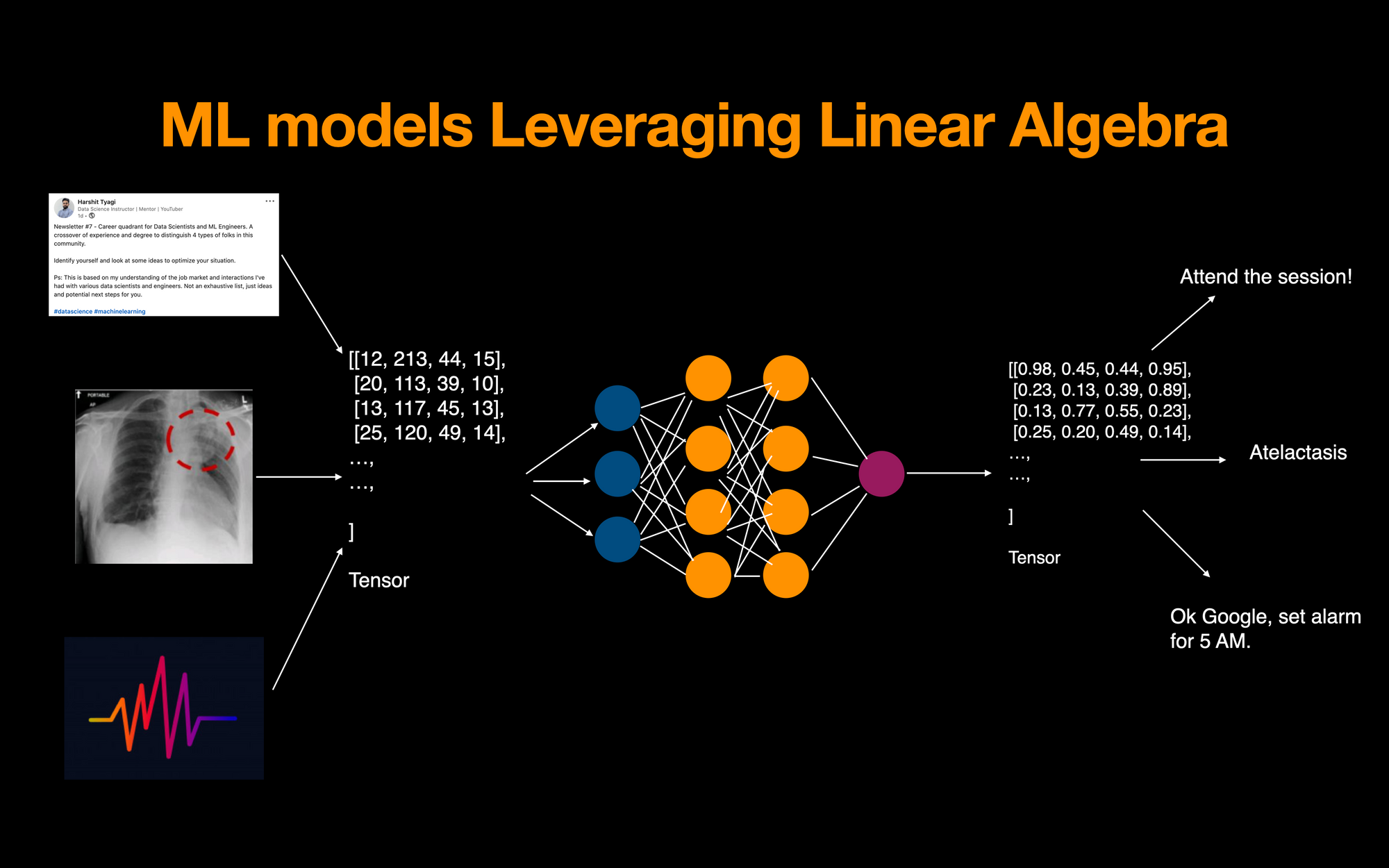
Article original : How Machine Learning Uses Linear Algebra to Solve Data Problems
Les machines ou les ordinateurs ne comprennent que les nombres. Et ces nombres doivent être représentés et traités de manière à ce que les machines résolvent des problèmes en apprenant à partir des données au lieu d'apprendre à partir d'instructions prédéfinies (comme dans le cas de la programmation).
Tous les types de programmation utilisent les mathématiques à un certain niveau. L'apprentissage automatique implique de programmer des données pour apprendre la fonction qui décrit le mieux les données.
Le problème (ou processus) de trouver les meilleurs paramètres d'une fonction en utilisant des données est appelé entraînement de modèle en ML.
Par conséquent, en résumé, l'apprentissage automatique est la programmation pour optimiser la meilleure solution possible – et nous avons besoin des mathématiques pour comprendre comment ce problème est résolu.
La première étape pour apprendre les mathématiques pour le ML est d'apprendre l'algèbre linéaire.
L'algèbre linéaire est la fondation mathématique qui résout le problème de la représentation des données ainsi que des calculs dans les modèles d'apprentissage automatique.
C'est la mathématique des tableaux – techniquement appelés vecteurs, matrices et tenseurs.
Domaines d'application courants – L'algèbre linéaire en action

Source : [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
Dans le contexte du ML, toutes les phases majeures du développement d'un modèle utilisent l'algèbre linéaire en coulisses.
Les domaines d'application importants qui sont rendus possibles par l'algèbre linéaire sont :
représentation des données et des modèles appris
plongements de mots
réduction de dimensionnalité
Représentation des données
Le carburant des modèles de ML, c'est-à-dire les données, doit être converti en tableaux avant de pouvoir l'alimenter dans vos modèles. Les calculs effectués sur ces tableaux incluent des opérations comme la multiplication de matrices (produit scalaire). Cela retourne ensuite la sortie qui est également représentée sous forme de matrice/tenseur transformé de nombres.
Plongements de mots
Ne vous inquiétez pas de la terminologie ici – il s'agit simplement de représenter des données de grande dimension (pensez à un grand nombre de variables dans vos données) avec un vecteur de dimension plus petite.
Le traitement du langage naturel (NLP) traite des données textuelles. Traiter du texte signifie comprendre le sens d'un grand corpus de mots. Chaque mot représente un sens différent qui peut être similaire à un autre mot. Les plongements vectoriels en algèbre linéaire nous permettent de représenter ces mots plus efficacement.
Vecteurs propres (SVD)
Enfin, des concepts comme les vecteurs propres nous permettent de réduire le nombre de caractéristiques ou de dimensions des données tout en conservant l'essence de toutes celles-ci en utilisant ce que l'on appelle l'analyse en composantes principales.
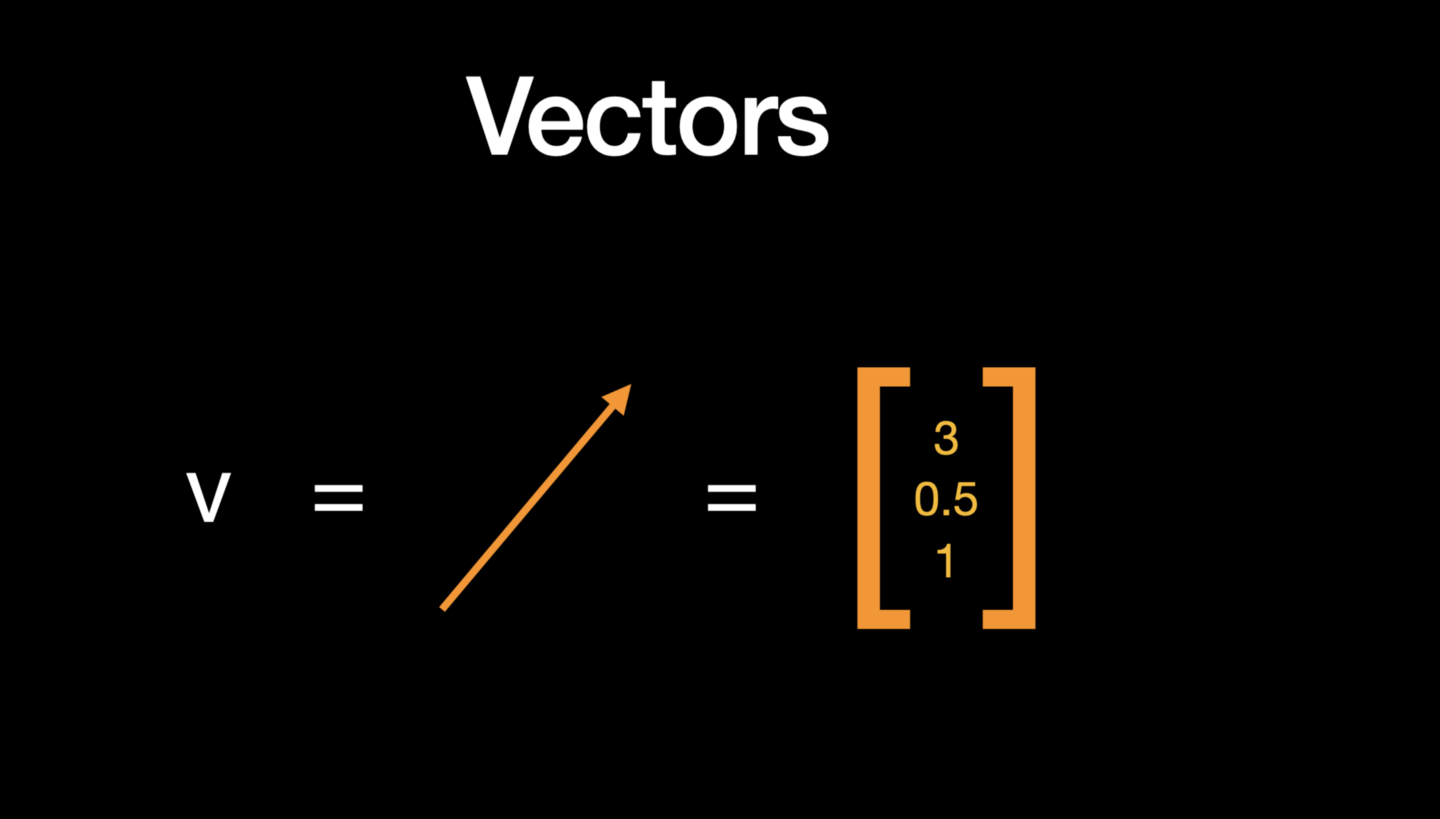
Des données aux vecteurs
Source : [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
L'algèbre linéaire traite principalement des vecteurs et des matrices (différentes formes de tableaux) et des opérations sur ces tableaux. Dans NumPy, les vecteurs sont essentiellement un tableau unidimensionnel de nombres, mais géométriquement, ils ont à la fois une magnitude et une direction.
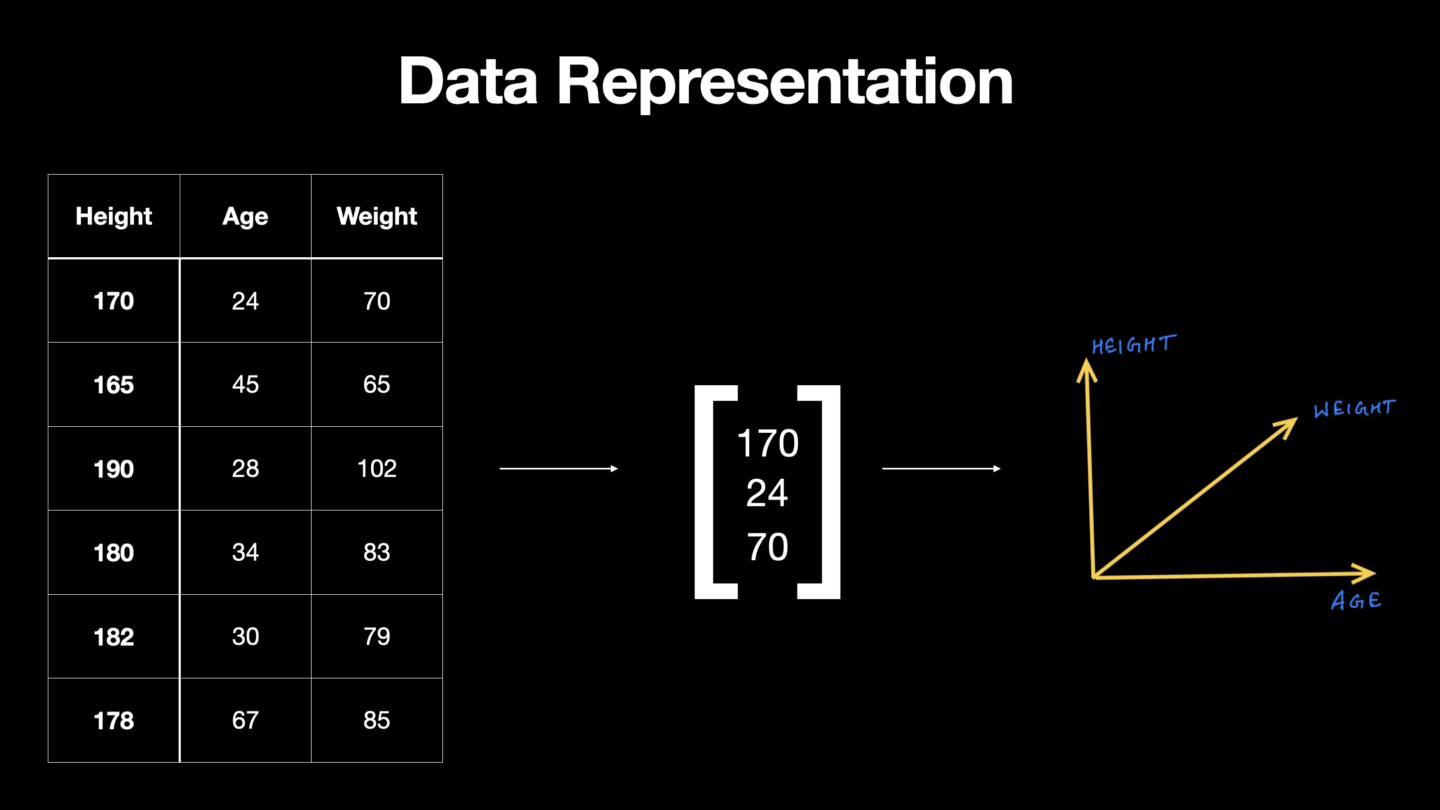
Source : [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
Nos données peuvent être représentées à l'aide d'un vecteur. Dans la figure ci-dessus, une ligne de ces données est représentée par un vecteur de caractéristiques qui comporte 3 éléments ou composantes représentant 3 dimensions différentes. N entrées dans un vecteur en font un espace vectoriel n-dimensionnel et dans ce cas, nous pouvons voir 3 dimensions.
Apprentissage profond – Tenseurs circulant à travers un réseau de neurones
Nous pouvons voir l'algèbre linéaire en action dans toutes les applications majeures aujourd'hui. Les exemples incluent l'analyse de sentiments sur un poste LinkedIn ou Twitter (plongements), la détection d'un type d'infection pulmonaire à partir d'images radiographiques (vision par ordinateur), ou tout bot de conversion de parole en texte (NLP).
Tous ces types de données sont représentés par des nombres dans des tenseurs. Nous exécutons des opérations vectorisées pour apprendre des motifs à partir de ceux-ci en utilisant un réseau de neurones. Il produit ensuite un tenseur traité qui est à son tour décodé pour produire l'inférence finale du modèle.
Chaque phase effectue des opérations mathématiques sur ces tableaux de données.
Réduction de dimensionnalité – Transformation de l'espace vectoriel

Source : [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
En ce qui concerne les plongements, vous pouvez essentiellement penser à un vecteur n-dimensionnel étant remplacé par un autre vecteur qui appartient à un espace de dimension inférieure. Cela est plus significatif et c'est celui qui surmonte les complexités computationnelles.
Par exemple, voici un vecteur tridimensionnel qui est remplacé par un espace bidimensionnel. Mais vous pouvez l'extrapoler à un scénario du monde réel où vous avez un très grand nombre de dimensions.
Réduire les dimensions ne signifie pas supprimer des caractéristiques des données. Au lieu de cela, il s'agit de trouver de nouvelles caractéristiques qui sont des fonctions linéaires des caractéristiques originales et de préserver la variance des caractéristiques originales.
Trouver ces nouvelles variables (caractéristiques) se traduit par trouver les composantes principales (CP). Cela converge ensuite vers la résolution des problèmes de vecteurs propres et de valeurs propres.
Moteurs de recommandation – Utilisation des plongements
Vous pouvez penser à un plongement comme un plan 2D intégré dans un espace 3D et c'est de là que vient ce terme. Vous pouvez penser au sol sur lequel vous vous tenez comme un plan 2D qui est intégré dans cet espace dans lequel vous vivez.
Pour vous donner un cas d'utilisation réel en rapport avec toute cette discussion sur les plongements vectoriels, toutes les applications qui vous donnent des recommandations personnalisées utilisent des plongements vectoriels sous une forme ou une autre.

Par exemple, le graphique ci-dessus provient du cours de Google sur les systèmes de recommandation où nous avons ces données sur différents utilisateurs et leurs films préférés. Certains utilisateurs sont des enfants et d'autres sont des adultes, certains films sont des classiques intemporels tandis que d'autres sont plus artistiques. Certains films sont ciblés pour un jeune public tandis que des films comme Memento sont préférés par les adultes.
Maintenant, nous devons non seulement représenter ces informations en nombres, mais aussi trouver de nouvelles représentations vectorielles de dimension plus petite qui capturent bien toutes ces caractéristiques.

Une façon très rapide de comprendre comment nous pouvons réaliser cette tâche est de comprendre quelque chose appelé la factorisation de matrices qui nous permet de décomposer une grande matrice en matrices plus petites.
Ignorez les nombres et les couleurs pour l'instant et essayez simplement de comprendre comment nous avons décomposé une grande matrice en deux plus petites.
Par exemple, ici cette matrice de 4X5, 4 lignes et 5 caractéristiques, a été décomposée en deux matrices, une de 4X2 et l'autre de 2X5. Nous avons essentiellement de nouveaux vecteurs de dimension plus petite pour les utilisateurs et les films.
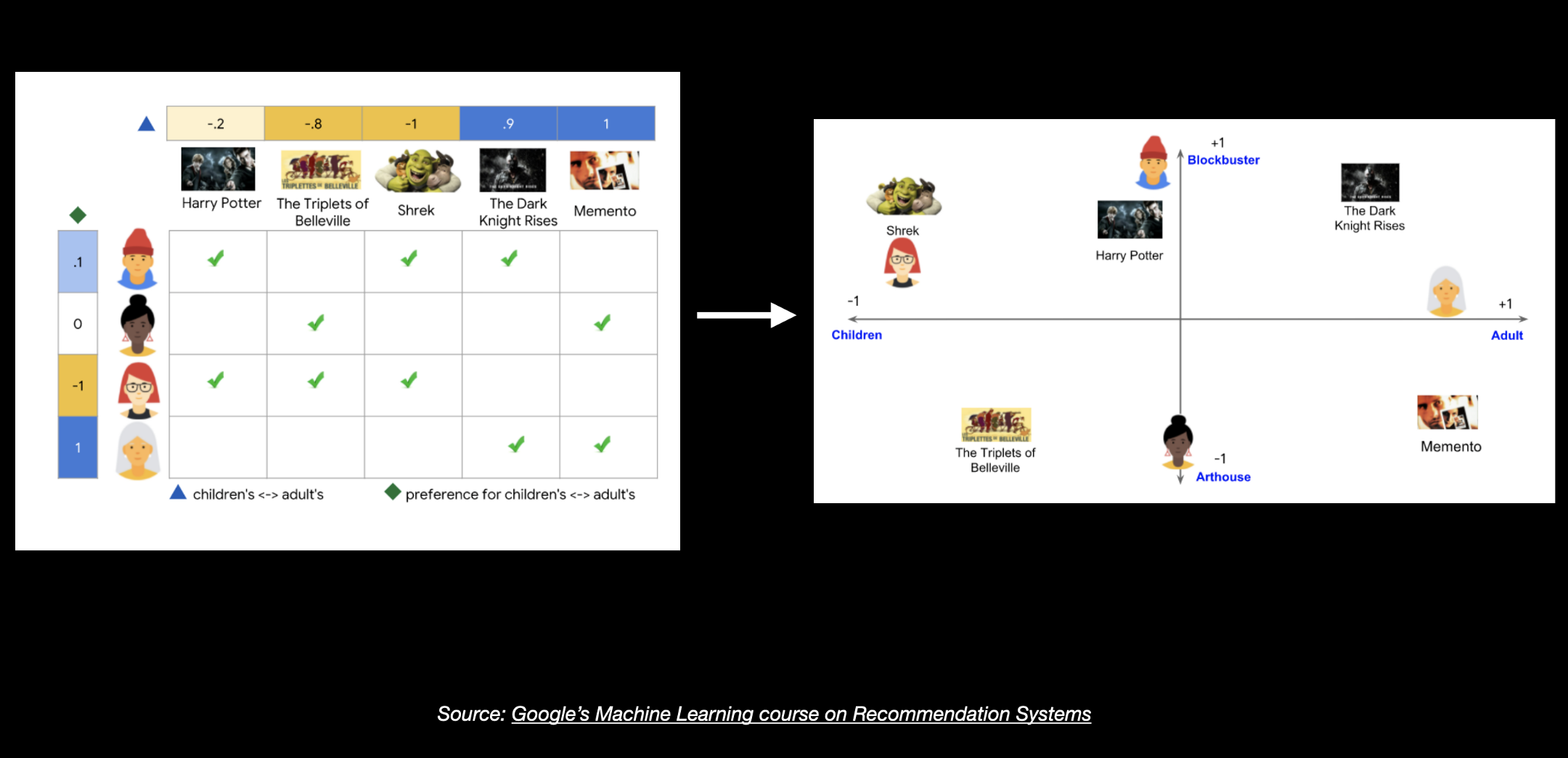
Et cela nous permet de tracer cela sur un espace vectoriel 2D. Ici, vous verrez que l'utilisateur #1 et le film Harry Potter sont plus proches et l'utilisateur #3 et le film Shrek sont plus proches.
Le concept de produit scalaire (multiplication de matrices) de vecteurs nous en dit plus sur la similarité de deux vecteurs. Et il a des applications dans le calcul de corrélation/covariance, la régression linéaire, la régression logistique, l'ACP, les convolutions, le PageRank et de nombreux autres algorithmes.
Industries où l'algèbre linéaire est fortement utilisée
J'espère que vous êtes maintenant convaincu que l'algèbre linéaire est à la base des initiatives de ML dans de nombreux domaines aujourd'hui. Si ce n'est pas le cas, voici une liste pour en nommer quelques-uns :
Statistiques
Physique chimique
Génomique
Plongements de mots – réseaux de neurones/apprentissage profond
Robotique
Traitement d'image
Physique quantique
Combien d'algèbre linéaire devez-vous connaître pour commencer avec le ML / DL ?
Maintenant, la question importante est de savoir comment vous pouvez apprendre à programmer ces concepts d'algèbre linéaire. La réponse est que vous n'avez pas à réinventer la roue, vous devez simplement comprendre les bases de l'algèbre vectorielle de manière computationnelle et ensuite apprendre à programmer ces concepts en utilisant NumPy.
NumPy est un package de calcul scientifique qui nous donne accès à tous les concepts sous-jacents de l'algèbre linéaire. Il est rapide car il exécute du code C compilé et il dispose d'un grand nombre de fonctions mathématiques et scientifiques que nous pouvons utiliser.
Ressources recommandées
Liste de lecture sur l'algèbre linéaire par 3Blue1Brown – visualisations très engageantes qui expliquent l'essence de l'algèbre linéaire et ses applications. Peut être un peu trop difficile pour les débutants.
Livre sur l'apprentissage profond par Ian Goodfellow & Yoshua Bengio – une ressource fantastique pour apprendre le ML et les mathématiques appliquées. Lisez-le, quelques personnes peuvent le trouver trop technique et lourd en notations au début.
Fondements de la science des données et du ML – J'ai créé un cours qui vous donne une compréhension suffisante de la programmation, des mathématiques (algèbre de base, algèbre linéaire et calcul) et des statistiques. Un package complet pour les premières étapes de l'apprentissage de la DS/ML.
👉 Vous pouvez utiliser le code **FREECODECAMP10** pour obtenir 10 % de réduction.
Consultez le plan du cours ici :