

Article original : How I Reverse Engineered A Chrome Extension To Write My Own Flask App
Par Tushar Agrawal
Fondamentalement, si je n'ai pas l'intention d'utiliser un service, je ne me donnerai pas la peine de le reverse-engineering. — Jon Lech Johansen
Comme le montre ma bio, je suis fou de musique et de tout ce qui s'y rapporte. Et je crois que les clips musicaux, s'ils sont bien réalisés, sont probablement le meilleur moyen de ressentir l'âme inhérente de la musique.
Tout a commencé avec moi regardant le clip d'une chanson « Heavydirtysoul » de Twenty One Pilots. Le clip était si génial que je ne me souciais même pas des paroles. Ce n'est qu'après l'avoir écouté plusieurs fois que j'ai réalisé que je n'avais pas compris grand-chose des paroles, à part le refrain.
C'est un problème réel pour de nombreux locuteurs ESL (anglais comme seconde langue). Vous ne pouvez pas apprécier pleinement une chanson si vous ne comprenez pas les paroles.
C'est alors que j'ai eu une idée : et si je pouvais afficher les paroles d'une chanson en même temps que les clips musicaux (un peu comme des sous-titres) ? Ce serait génial si je pouvais créer des fichiers de sous-titres pour mes clips musicaux et les lire sur mon lecteur vidéo !
Approche initiale et découverte de Musixmatch
J'ai alors commencé une recherche approfondie de sites ou d'API qui pourraient me fournir les paroles d'une chanson. Et comme prévu, j'ai trouvé une douzaine de sites qui fournissaient les paroles. Cool... n'est-ce pas ?
Non. Parce que ce dont j'avais vraiment besoin, c'étaient des paroles synchronisées, un peu comme des sous-titres pour un film. Je voulais que le texte des paroles synchronise avec l'image vidéo actuelle à l'écran. Après beaucoup de recherches, je n'ai pas trouvé un tel service.
Ce n'est qu'après une semaine que quelqu'un m'a parlé de Musixmatch, une extension Chrome qui intégrait les paroles aux vidéos YouTube. Donc, oui, il y avait quelqu'un qui faisait déjà ce à quoi j'avais pensé. Cela ressemblait à la plupart des autres idées soi-disant nouvelles que j'avais eues... et j'étais à un pas de récupérer des fichiers de sous-titres SubRip « srt » pour mes clips musicaux préférés.
Et le piratage a commencé...
J'avais déjà un peu d'expérience avec les outils de développement Chrome (grâce à Node.js et à la conception front-end). J'ai donc enfilé mes lunettes de pirate et lancé les outils de développement Chrome. Je suis passé à l'onglet réseau et j'ai commencé à chercher un fichier texte qui pourrait contenir les paroles.
 Capture d'écran des outils de développement avec une vidéo YouTube en lecture
Capture d'écran des outils de développement avec une vidéo YouTube en lecture
Mais j'analysais les requêtes sur une page qui lisait des vidéos YouTube, donc j'avais beaucoup de requêtes. Et comme l'extension récupérait les paroles, la requête devait avoir quelque chose à voir avec le domaine Musixmatch.
J'ai donc filtré en utilisant le mot-clé « musix » et j'ai patiemment cherché mon fichier, et je l'ai finalement trouvé. Les paroles avec le timestamp. J'ai noté l'URL de cette requête et, franchement, tout cela me semblait du charabia. Quoi qu'il en soit, j'ai copié la chaîne d'URL telle quelle et je l'ai collée dans la barre d'URL, et voilà, j'ai obtenu les paroles.
Il ne restait donc plus qu'à découvrir comment l'URL était construite et quels étaient les paramètres...
 URL de la requête
URL de la requête
Paramètres et quoi ?
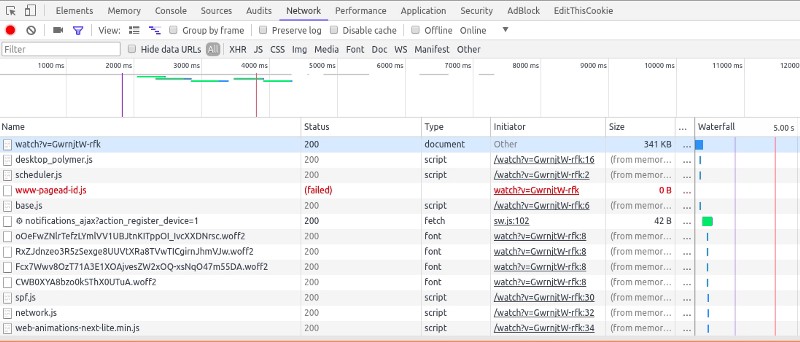
Après toute l'analyse et le filtrage, j'ai finalement abouti à ceci. Une longue URL avec un tas de paramètres inconnus.
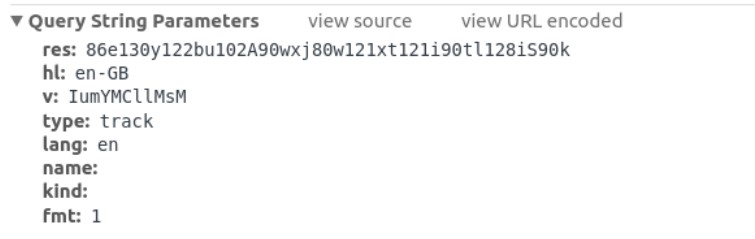 Paramètres pour l'URL
Paramètres pour l'URL
Je devais creuser plus profondément pour comprendre l'importance de chaque paramètre. À première vue, il était clair que les seuls paramètres qui comptaient vraiment étaient res et v. Les autres n'étaient que pour des tâches de maintenance. J'ai alors commencé à explorer les options et j'ai fini par perdre une heure juste pour découvrir que le paramètre v n'était rien d'autre que l'ID de la vidéo YouTube.
Par exemple, l'ID de la vidéo ou v pour une vidéo YouTube avec une URL https://www.youtube.com/watch?v=ZQeq_T_2VE8 est ZQeq_T_2VE8. Maintenant que j'avais percé le mystère de v, je pensais qu'il ne me faudrait qu'une heure de plus pour découvrir res, mais j'avais tort.
Le cas curieux du paramètre « res »
Une heure d'analyse et de recherche approfondies ne m'a rien donné. Un peu plus tard, j'ai réalisé que l'URL fonctionnait même lorsque je changeais quelques lettres. J'ai continué à creuser et, au bout de 3 heures, j'ai compris que les lettres de la chaîne ne voulaient rien dire. Elles étaient simplement placées au hasard.
Une valeur typique de res : 90rt120b114xz70xv82w85vv90a94hn90vb102av86
J'en avais donc fini avec les lettres, mais les valeurs numériques m'étaient encore étrangères. La seule chose à laquelle je pouvais penser était d'appliquer un peu de reverse-engineering pour analyser les nombres.
J'ai commencé par supprimer toutes les lettres, car elles ne voulaient rien dire, et la première chose que j'ai remarquée, c'est que le nombre de ces valeurs était fixe, à savoir 11. J'ai essayé avec de nombreuses autres vidéos, mais le nombre est resté constant.
Soudain, cela m'a frappé, l'ID de la vidéo, le v, dont nous avons parlé plus tôt, avait également 11 caractères. Cependant, chaque caractère dans v pouvait être une lettre, un chiffre ou même un « - » ou « _ », contrairement à res qui ne contenait que des nombres.
J'ai donc essayé la correspondance la plus évidente qui peut mapper un caractère à sa valeur numérique, l'ASCII, et voilà, c'était ça. Les caractères étaient encodés en ASCII et les lettres étaient placées au hasard entre les nombres pour rendre toute la chaîne plus aléatoire, je suppose.
À ce stade, j'étais ravi. Après tout, j'avais appris tous les paramètres et je n'étais qu'à un pas d'écrire mon propre script pratique pour télécharger le fichier de paroles au format « srt ». Juste pour être sûr, j'ai vérifié avec différentes vidéos et il semblait n'y avoir aucun problème. J'ai également partagé l'URL avec un de mes amis (oui, un amateur de musique).
J'ai reçu une réponse rapide qui disait « Qu'est-ce que c'est ? Il n'y a rien ». J'ai vérifié l'URL et elle fonctionnait bien sur mon navigateur.
Qui était le coupable ? :P
Je ne reçois rien d'étrange comme des sous-vêtements. Je reçois des cookies. :P — Jennifer Aniston
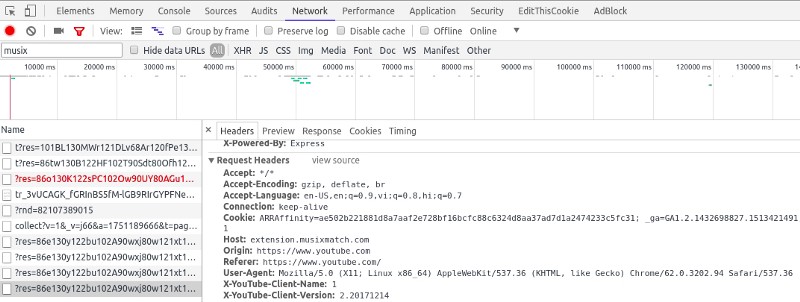 Champ Cookie dans les en-têtes de requête
Champ Cookie dans les en-têtes de requête
J'ai relancé les outils de développement, puis j'ai copié le lien pour une nouvelle chanson. Cela a fonctionné à nouveau, puis je suis passé à un onglet de navigation privée et j'ai collé la même URL. Cela n'a pas fonctionné.
Mon expérience des concours CTF (Capture The Flag) m'a immédiatement dit que cela avait quelque chose à voir avec les cookies. C'est le cas le plus probable si une URL fonctionne dans une fenêtre de navigateur et pas dans une autre.
Je suis passé à la console de développement et j'ai vu que le cookie était effectivement envoyé par le navigateur. Pour être sûr, j'ai analysé la requête plusieurs fois et il m'est finalement apparu que le cookie envoyé était le même que celui que le serveur Musixmatch envoie dans la réponse. De plus, chaque cookie n'est valable que pour une certaine période de temps.
J'ai donc écrit un script Python utilisant urllib qui récupère d'abord le cookie à partir d'une réponse HTTP normale, car le cookie fonctionne sur tout le domaine. Ensuite, le cookie, ainsi que d'autres paramètres, a été formaté comme une requête HTTP et nous avons obtenu les paroles... Enfin !!
Préparation des paramètres pour une requête réussie
Voici le code Python pour toutes les étapes discutées ci-dessus. Le code génère d'abord les paramètres, suivis d'une requête pour obtenir les cookies. L'URL est ensuite préparée en utilisant les paramètres. Ensuite, le cookie est défini dans la requête d'en-tête avec d'autres champs d'en-tête comme « Host » et « User-agent » pour lui donner un aspect de requête plus authentique.
Analyse des paroles brutes synchronisées au format srt
Maintenant, la prochaine grande chose ou la seule tâche restante était de convertir les données brutes de paroles synchronisées en un format srt (SubRip Text) propre. Voici à quoi ressemblait le format des paroles de MusixMatch.
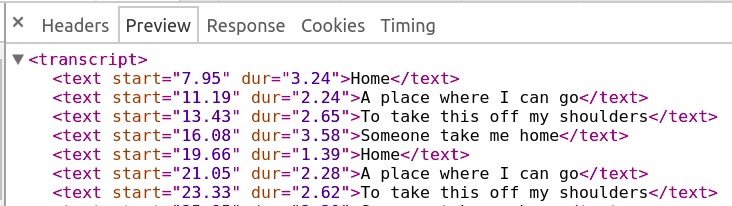 Réponse HTTP pour les paroles
Réponse HTTP pour les paroles
Ci-dessous se trouve un format propre pour un fichier srt. Ces fichiers contiennent des lignes formatées de texte brut en groupes séparés par une ligne vide. Les sous-titres sont numérotés séquentiellement, commençant à 1 comme illustré dans la figure ci-dessous.
100:00:00,350 --> 00:00:03,45071 buildings explodedor caught fire.
200:00:03,490 --> 00:00:05,020Elliot, tell me what it isthat you think he did.
300:00:05,060 --> 00:00:06,930Sorry.I don't know if I can say.
Cela semblait nécessiter beaucoup de travail, car les données n'étaient pas encore correctement formatées. Mais, si vous avez les données nécessaires et une connaissance de Python, il suffit d'un simple script pour gérer les données, et c'est exactement ce que j'ai fait. Les balises HTML m'ont un peu énervé pendant l'analyse HTML, mais devinez quoi, il existe une bibliothèque géniale juste pour l'analyse HTML qui a rendu tout le processus très facile. Aucun point pour deviner le nom de la bibliothèque, HTMLParser :-).
Mots de la fin
J'ai donc rassemblé ce script avec quelques modifications et, avec une interface frontale simple sur un serveur Flask, j'avais ma propre interface de récupération de paroles, probablement la seule de son genre dans le monde entier !!
Au fait, si vous êtes passionné de musique, jetez un coup d'œil à Musixmatch. C'est vraiment génial. Cet exercice était uniquement à des fins éducatives et n'a pas été utilisé d'une manière qui violerait le droit d'auteur de Musixmatch.