

Article original : How I Built a Faster and More Reliable APOD API
Par Ella Nan
Astronomy Picture of the Day (APOD) est un peu comme le compte Instagram de l'univers. C'est un site web où une nouvelle image époustouflante de l'univers est publiée chaque jour depuis 1995.
Alors que je construisais un projet utilisant l'API officielle d'APOD, j'ai remarqué que les requêtes expiraient périodiquement ou prenaient un temps étonnamment long pour aboutir.
Curieuse et un peu confuse (les données renvoyées étant simples, elles ne devraient pas nécessiter beaucoup de calculs et devraient être faciles à mettre en cache), j'ai décidé de fouiller dans le dépôt de l'API pour voir si je pouvais en trouver la cause, et peut-être même la corriger.
Le site web comme base de données
J'ai été fascinée de découvrir qu'il n'y avait pas de base de données. L'API extrayait les données du code HTML du site web APOD à l'aide de BeautifulSoup, en direct pour chaque requête.
Puis je me suis souvenue que ce site avait été créé en 1995. MySQL n'était sorti que quelques semaines avant la première photo APOD du 16 juin.
 ap950616, le premier APOD
ap950616, le premier APOD
Ce n'était cependant pas idéal pour les performances, car chaque donnée quotidienne que l'API devait renvoyer nécessitait une requête réseau supplémentaire pour être récupérée.
Il semblait également que les requêtes pour des plages de dates étaient effectuées en série plutôt qu'en parallèle, de sorte que demander ne serait-ce qu'un mois de données prenait beaucoup de temps. Et il fallait plus d'une demi-minute pour les données d'une année, quand le serveur n'expirait pas ou ne renvoyait pas une erreur à la place.
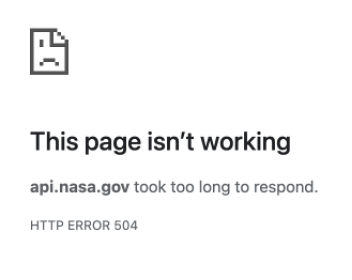 womp womp
womp womp
L'API officielle ne semblait pas non plus faire de mise en cache – une requête qui prenait 30 secondes à charger la première fois en prenait encore 30 la seconde fois.
Je pensais que nous pouvions faire mieux.
Une API APOD plus rapide et plus fiable
Puisque j'utilise l'API APOD pour alimenter un projet de portfolio (oui, je suis en recherche d'emploi 😜), j'ai vraiment besoin qu'elle soit fiable et qu'elle charge rapidement. J'ai donc décidé d'implémenter ma propre API.
Vous pouvez trouver tout le code dans ce dépôt GitHub si vous souhaitez l'examiner en détail au fil de votre lecture.
Voici les approches que j'ai adoptées :
1. Éviter le scraping à la demande
L'une des principales raisons pour lesquelles la réponse de l'API de la NASA est lente est que le scraping et le parsing des données se font en direct, ce qui ajoute une surcharge significative à chaque requête. Nous pouvons séparer l'étape d'extraction des données de la gestion des requêtes API.
J'ai fini par écrire un script pour dumper les données du site web dans un seul fichier JSON de 12 Mo. C'est assez volumineux pour un fichier JSON, mais étant donné qu'une fonction Vercel de l'offre gratuite peut avoir une taille décompressée de 250 Mo et dispose de 1024 Mo de mémoire, il est encore assez petit pour être chargé directement sans avoir à s'encombrer d'une base de données.
Le script se compose de deux parties :
[getDataByDate(date: DateTime)](https://github.com/ellanan/apod-api/blob/main/api/_data/getDataByDate.ts)est une fonction qui, pour une date donnée, récupère la page web APOD correspondante, extrait les données du HTML à l'aide de cheerio (l'équivalent JavaScript de BeautifulSoup), et renvoie des données structurées sous la forme d'un objet JavaScript.extractData.ts, qui appellegetDataByDateavec des jours provenant d'une plage de dates (initialement "chaque jour entre aujourd'hui et le 16 juin 1995") en utilisant la méthodeeachLimitde la bibliothèque async pour effectuer plusieurs requêtes en parallèle. Il stocke le résultat de chaque jour dans un fichier JSON séparé sur le système de fichiers, et enfin combine toutes les données JSON quotidiennes en un seul fichier data.json.
Vous pourriez vous demander : pourquoi ne pas récupérer toutes les données d'abord et ne sauvegarder qu'un seul fichier à la fin ? Lors de l'exécution de plus de 9000 requêtes réseau, certaines vont inévitablement échouer, et vous ne voulez vraiment pas avoir à repartir de zéro. Sauvegarder les données de chaque jour au fur et à mesure nous permet de reprendre là où l'échec s'est produit.
Voici une comparaison des temps de réponse avant et après l'évitement du scraping à la demande :
|
Arguments |
Mon API APOD |
API APOD de la NASA |
||
|
|
TTFB moyen |
Écart-type |
TTFB moyen |
Écart-type |
|
aucun argument |
110 ms |
21 ms |
58 ms |
29 ms |
|
date |
80 ms |
34 ms |
105 ms |
88 ms |
|
start_date=2021-01-01 |
151 ms |
63 ms |
35 358 ms |
2 891 ms |
|
count=100 |
96 ms |
48 ms |
9 701 ms |
1 198 ms |
getDataByDate, la même fonction que celle utilisée pour extraire les données du fichier JSON).
### 3. Mettre en cache les requêtes de manière agressive
La majeure partie du temps sur l'API officielle d'APOD était consacrée à attendre que le serveur envoie le premier octet. Comme les données historiques ne changent pas et que de nouvelles entrées sont ajoutées une fois par jour, le serveur d'application réel n'a pas besoin d'être sollicité la plupart du temps.
Nous pouvons utiliser des en-têtes pour dire au Réseau de diffusion de contenu (CDN) de mettre en cache de manière agressive la réponse de notre fonction cloud. J'héberge sur Vercel, mais cela devrait également fonctionner avec Netlify et Cloudflare.
Le code pour les en-têtes spécifiques que nous voulons envoyer depuis le gestionnaire de fonction est :
javascript
response
.status(200)
.setHeader(
'Cache-Control',
'max-age=0, ' +
`s-maxage=${cacheDurationSeconds}, `+
`stale-while-revalidate=${cacheDurationSeconds}`
)
En décomposant cela :
max-age indique aux navigateurs combien de temps mettre en cache une requête. Si une requête pour une ressource se situe dans le max-age, la réponse mise en cache sera utilisée. Nous fixons max-age à 0, suivant les conseils de Vercel, pour empêcher les navigateurs de mettre en cache la réponse de l'API localement. De cette façon, les clients recevront toujours les nouvelles données dès qu'elles seront mises à jour.
s-maxage indique aux serveurs combien de temps mettre en cache une requête. Ainsi, lorsqu'une requête pour une ressource se situe dans le s-maxage, le serveur (dans notre cas, le CDN de Vercel) enverra la réponse mise en cache. C'est très puissant car ce cache est partagé entre tous les utilisateurs et appareils.
Nous définissons s-maxage sur une durée variable, car pour les requêtes qui demandent des dates en utilisant un temps relatif ("données d'aujourd'hui", ou "données des 10 derniers jours"), nous ne voulons demander au CDN de mettre cela en cache que pendant environ une heure, car cela pourrait être mis à jour lors de la sortie du prochain APOD. Pour les requêtes qui demandent les données d'une date spécifique (par exemple entre "2001-01-01" et "2002-01-01"), nous pouvons demander au CDN de mettre cela en cache beaucoup plus longtemps, car cela n'est pas censé changer.
Enfin, nous définissons un en-tête stale-while-revalidate. De cette façon, lorsque le temps de cache spécifié expire, au lieu de faire attendre l'utilisateur suivant jusqu'à ce que les données fraîches reviennent, nous disons au CDN de servir les données mises en cache à l'utilisateur actuel – mais en même temps, de solliciter notre point de terminaison API pour obtenir des données fraîches et les mettre en cache pour la requête suivante.
Comme notre API chargeait déjà toutes les données en mémoire, la différence de performance entre les requêtes mises en cache et non mises en cache ne devrait pas être trop perceptible, mais plus c'est rapide, mieux c'est.
L'objectif principal de la mise en cache est d'éviter d'exécuter la fonction cloud, car l'offre gratuite de Vercel a un quota de 100 Go-heures (je ne suis pas sûre de ce que cela signifie, mais quoi que ce soit, je ne veux pas l'atteindre).
Comparaison des temps de réponse avant et après la mise en cache des requêtes :
|
Arguments |
Mon API APOD |
API APOD de la NASA |
||
|
TTFB moyen |
Écart-type |
TTFB moyen |
Écart-type |
|
|
aucun argument |
33 ms |
11 ms |
58 ms |
29 ms |
|
date |
37 ms |
23 ms |
105 ms |
88 ms |
|
start_date=2021-01-01 |
46 ms |
29 ms |
35 358 ms |
2 891 ms |
|
count=100 |
31 ms |
13 ms |
9 701 ms |
1 198 ms |
4. (Bonus) Mises à jour quotidiennes automatisées
Nous voulons garder notre fichier de données synchronisé avec le site web APOD de la NASA autant que possible, car lire les données de notre fichier JSON est beaucoup plus rapide que de se replier sur la récupération de données via le réseau.
Automatiser cela n'améliore pas exactement les performances – je pourrais régler une alarme pour lancer moi-même le script d'extraction chaque soir à minuit, effectuer un Commit des changements et pousser le code pour déclencher un nouveau déploiement.
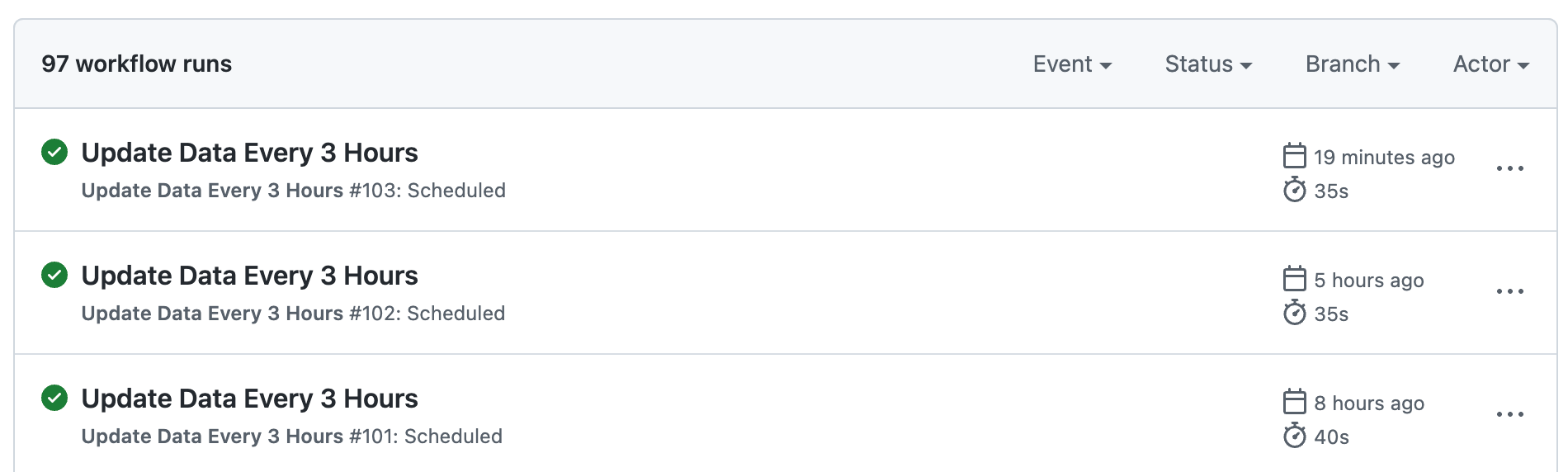
Heureusement, je n'aurai pas à le faire, car apparemment les GitHub Actions ne sont pas limitées à une exécution lors des Pull Requests, vous pouvez aussi les planifier.
name: Mise à jour des données toutes les 3 heures
on:
schedule:
# À la 15ème minute toutes les 3 heures.
- cron: '15 */3 * * *'
workflow_dispatch:
jobs:
update-data:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
node-version: '16'
- run: npm install
- run: npm run update-data
- name: Commit des changements
run: |
if [ -n "$(git status --porcelain)" ]; then
git config --global user.name 'your_username'
git config --global user.email 'your_email@users.noreply.github.com'
git add .
git commit -m "Mise à jour automatique des données"
git push
else
echo "aucun changement";
fi
Conclusion
En résumé, là où c'est possible et judicieux :
- Extraire les données avant que les requêtes ne soient reçues et essayer de les maintenir à jour
- Effectuer les requêtes de repli en parallèle
- Mettre en cache les réponses sur le CDN
Le code pour tout cela est un peu trop long pour tenir dans un article, mais je pense que ces principes devraient être plus largement applicables pour les API publiques (il y en a beaucoup d'autres rien que sur api.nasa.gov !). N'hésitez pas à parcourir le dépôt pour voir comment tout cela s'articule.
Merci de m'avoir lue ! J'aimerais beaucoup recevoir vos commentaires. Vous pouvez me trouver sur Twitter @ellanan_ ou sur LinkedIn.