


Article original : How to Reverse Engineer a Website – a Guide for Developers
En utilisant l'un de vos sites Web préférés, vous avez peut-être souvent pensé : "Et si ce site Web avait cette fonctionnalité particulière ? Ce serait génial !"
Si vous avez déjà eu de telles pensées, cet article est pour vous. Vous y apprendrez comment les sites Web communiquent avec les serveurs et obtiennent des données, et comment travailler à rebours pour comprendre le fonctionnement de ce site Web.
Vous verrez également comment ajouter des fonctionnalités à un site Web ou utiliser ses API pour le recréer vous-même. Vous utiliserez un simple site Web de démonstration dans l'article pour cela. Le site Web contient certaines données de ventes récupérées par une API distante. Dans la démonstration, vous utiliserez le site Web pour voir quelles API ont été utilisées pour obtenir les données et comment utiliser l'API des données de ventes.
Si vous comprenez comment accéder à l'API de données sur ce site Web, vous pouvez utiliser la même méthodologie pour accéder à ces données sur n'importe quel site Web que vous aimez.
Prérequis :
Cet article devrait être accessible à toute personne connaissant les bases de la programmation. Vous verrez des exemples en JavaScript, mais vous pouvez utiliser ces techniques dans votre langage préféré. Avoir quelques connaissances de base sur le fonctionnement du Web sera également utile.
Vous devez installer le projet depuis GitHub et l'exécuter pour expérimenter avec ce tutoriel.
Ce que nous allons couvrir :
Qu'est-ce qu'une API ?
Les interfaces de programmation d'applications (API) permettent à deux programmes informatiques de communiquer. Vous demandez les données que vous souhaitez utiliser dans votre projet à une API, et l'API les récupère pour vous.
Ces API peuvent être locales (comme les API Windows, les API Web, etc.) ou distantes (comme les API que les développeurs fournissent via Internet, telles que l'API météo et les API de sites Web).
Cet article se concentrera sur les API distantes, car les développeurs utilisent souvent cette approche sur les sites Web modernes. Les sites Web utilisent des API pour afficher des résultats basés sur une réponse.
Certaines entreprises peuvent fournir un accès à leurs API afin que vous puissiez développer sur leur base, mais ce n'est le cas que pour certaines. Parfois, une API peut ne pas fournir la fonctionnalité ou le design que vous souhaitez. Donc, d'abord, vous devriez regarder ce qu'un site offre et l'utiliser pour créer les fonctionnalités que vous voulez.
Dans ce tutoriel, vous apprendrez comment comprendre et explorer les API derrière un site Web afin de pouvoir les utiliser dans vos projets. Vous apprendrez d'abord comment fonctionnent les API, puis explorerez ce que signifie l'ingénierie inverse. Ensuite, vous utiliserez un site Web de démonstration et un exemple via Postman, où vous utiliserez une API pour obtenir certaines données du site Web. Vous pourrez utiliser ces données où vous le souhaitez.
Comment fonctionnent les API ?
La structure d'une API contient deux niveaux : le client et le serveur. Le client demande des données à l'API, et le serveur les fournit. Cette technologie existe depuis longtemps et est maintenant standardisée.
Le client commence à demander les données en se connectant avec le bon endpoint et en fournissant les informations liées pour le serveur. Le serveur vérifie ces données, et sur cette base, il fait sa magie et retourne une réponse au client sur le processus à utiliser.
Voici un simple dessin montrant ce processus :

Les requêtes et réponses des API ont généralement une structure similaire, qui est :
Requête :
Endpoints : l'URL cible de l'API.
Méthodes : disent au serveur quoi faire avec les données, comme obtenir les données, les mettre à jour, les supprimer, etc.
Paramètres : détails supplémentaires que vous fournissez au serveur pour des requêtes supplémentaires, comme le sujet, la catégorie, etc.
En-têtes : ces paires clé-valeur fournissent des informations sur le client, l'authentification, etc.
Corps : c'est le fournisseur de données réel, qui inclut tout ce que le client veut du serveur.
Réponse :
Code de statut : ce code de statut HTTP à trois chiffres informe le client du résultat du serveur.
En-tête : cela est similaire à la requête mais contient les informations du serveur. Il pourrait s'agir de la configuration des cookies ou d'autres détails.
Corps : contient les données réelles du serveur à utiliser.
Maintenant que vous en savez un peu sur les API et les requêtes HTTP, vous pouvez inverser le génie d'un site Web.
Qu'est-ce que l'ingénierie inverse ?
L'ingénierie inverse est l'art d'analyser un système pour comprendre comment les développeurs l'ont construit. Cela vous aide à comprendre comment il fonctionne afin que vous puissiez l'améliorer ou le pirater.
Certaines personnes utilisent l'ingénierie inverse pour craquer des programmes. D'autres l'utilisent pour les personnaliser ou même ajouter des fonctionnalités supplémentaires.
En ce qui concerne les sites Web, le processus d'ingénierie inverse vous aidera à comprendre quelles API un site possède et comment il les utilise. Cela vous permet d'écrire votre programme basé sur les API du site.
Parfois, l'ingénierie inverse peut être utilisée pour trouver des bugs, craquer des logiciels, ou même utiliser une API sans permission. Les développeurs de sites Web tendent à empêcher cela en fournissant une API officielle pour leur site Web, en fixant des limites pour l'utilisation de l'API et en détectant toute utilisation non autorisée.
Pour cette raison, lorsque vous commencez à inverser le génie de tout programme, vous devrez considérer les conditions d'utilisation et le côté légal de votre travail afin de ne rien faire d'illégal ou d'immoral.
Comment inverser le génie d'un site Web
Pour inverser le génie d'un site Web, vous devez faire deux choses : d'abord, vous devez explorer le site Web pour voir comment il fonctionne et apprendre quel type de données et d'endpoints il fournit. Ensuite, vous devez établir certaines hypothèses sur son fonctionnement et essayer de valider ces hypothèses.
Une hypothèse simple serait que, après vous être connecté au site Web, le site Web reçoit des informations d'authentification via des requêtes API. Obtenir ces informations vous permettra d'utiliser les API du site Web sans avoir besoin de vous connecter à chaque fois.
Pour valider cette hypothèse, vous devrez examiner les requêtes envoyées et reçues par le site Web. Ensuite, vous devrez envoyer vos requêtes vous-même à partir d'une source externe comme votre terminal via CURL ou un client HTTP comme Postman.
J'ai créé un site Web de démonstration que nous allons inverser. Vous exécuterez le site Web sur votre ordinateur, puis vous l'inverserez. Le site Web vous montre une simple page de connexion et contient certaines données clients. Votre objectif sera d'obtenir les données de ventes récentes du client.
Voici quelques captures d'écran du site Web et de ce que vous avez :
Page 1 : Connexion :
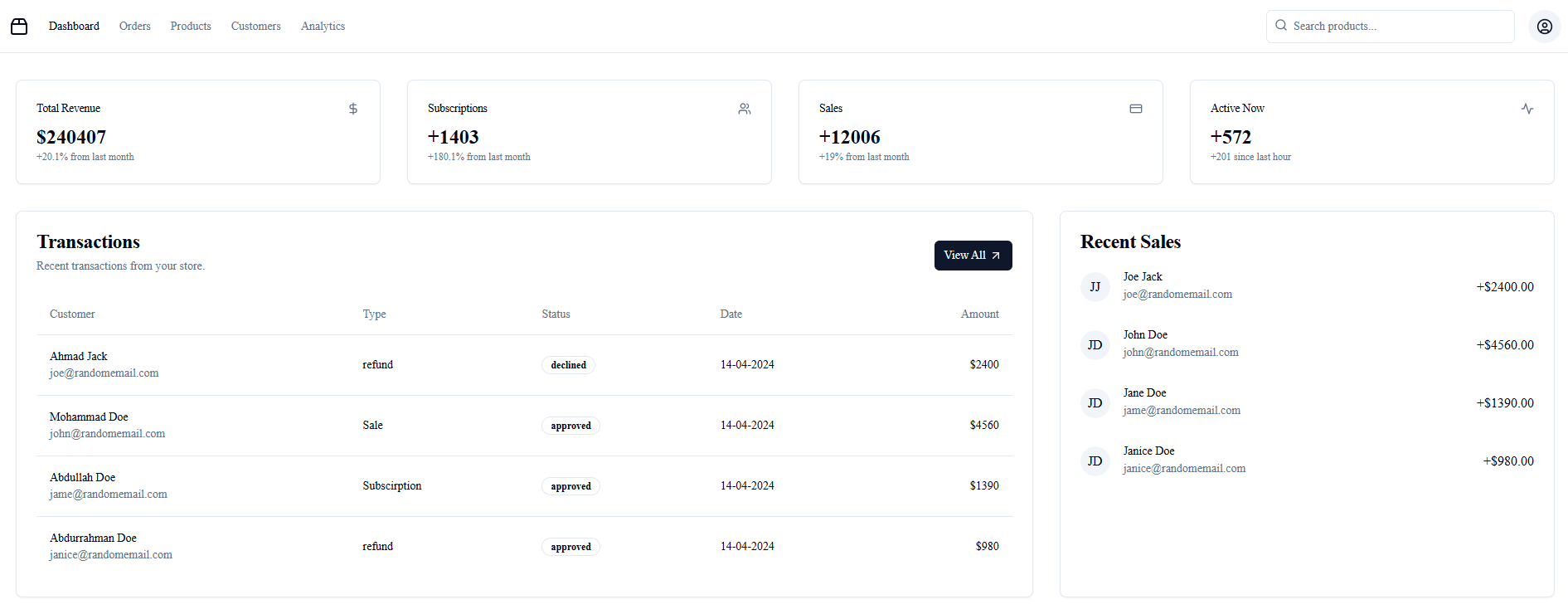
Page 2 : Les données du site Web
Explorer le site Web
La première étape de l'ingénierie inverse consiste à explorer le site Web et à voir comment il fonctionne. Pour ce faire, vous utiliserez les outils de développement Chrome pour vérifier les requêtes envoyées par le site Web et voir comment elles l'affectent. Vous rechercherez également les données reçues par ces requêtes et verrez comment vous pouvez les utiliser.
En même temps, vous devrez filtrer les requêtes, car certaines d'entre elles n'envoient ou ne reçoivent pas de données, mais elles obtiennent divers fichiers utilisés par le site Web, comme des fichiers CSS ou des images.
Les outils de développement Chrome vous aident à analyser et à comprendre un site Web, en vous montrant les éléments HTML, le réseau et le stockage utilisés par le site Web.
Vérifier les ventes
Votre objectif est de vérifier les ventes du site Web, vous devez donc vous connecter pour accéder au site Web et aller à la page du tableau de bord pour vérifier les ventes.
Sur la page des ventes, vous ferez ce qui suit :
Tout d'abord, ouvrez les outils de développement Chrome (en cliquant sur F12 ou en cliquant avec le bouton droit de la souris n'importe où, puis en ouvrant l'inspecteur) pour voir quel type d'API le site Web fournit.
Ensuite, après avoir ouvert les outils de développement, vous devez aller à l'onglet réseau pour vérifier les requêtes réseau et voir ce que le site Web envoie au serveur.
L'onglet réseau vous montre les requêtes envoyées du site Web au serveur et comment le serveur a répondu à celles-ci.
Comme vous pouvez le voir dans l'image précédente, vous avez un réseau vide dans les outils de développement. Un réseau vide se produit lorsque vous ouvrez les outils de développement après que le site Web a envoyé les appels. Un rafraîchissement (F5) sur le site Web sera suffisant pour vérifier les appels.
Dans l'image suivante, vous pouvez voir les requêtes envoyées du site Web au serveur. Si vous analysez les noms des requêtes, vous trouverez l'une des requêtes appelée sales, qui est celle qui contient les données de ventes. Vous pouvez ouvrir l'appel et voir le résultat.
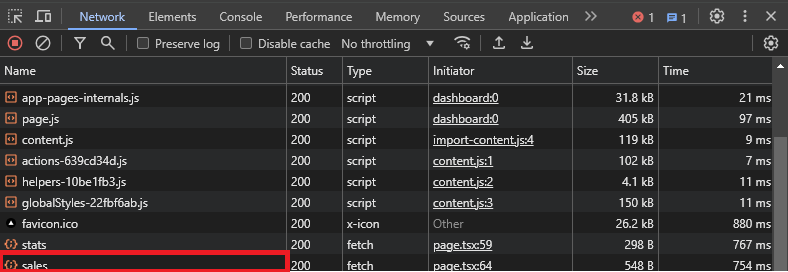
Si vous cliquez sur l'appel, vous verrez que vous avez les en-têtes, les cookies, les réponses, etc.
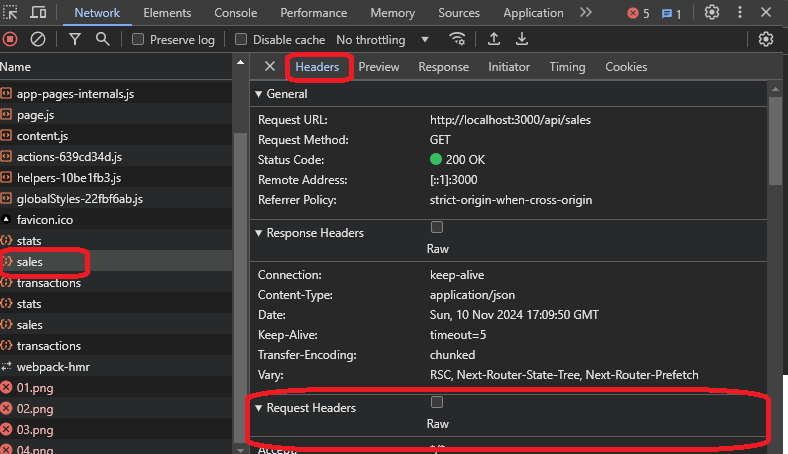
Ces onglets vous aideront à comprendre le résultat de l'appel, l'origine, et la requête et la réponse de la requête. Si vous allez à l'onglet réponse, vous pouvez voir les données de ventes au format JSON, qui est ce que le site Web utilise.
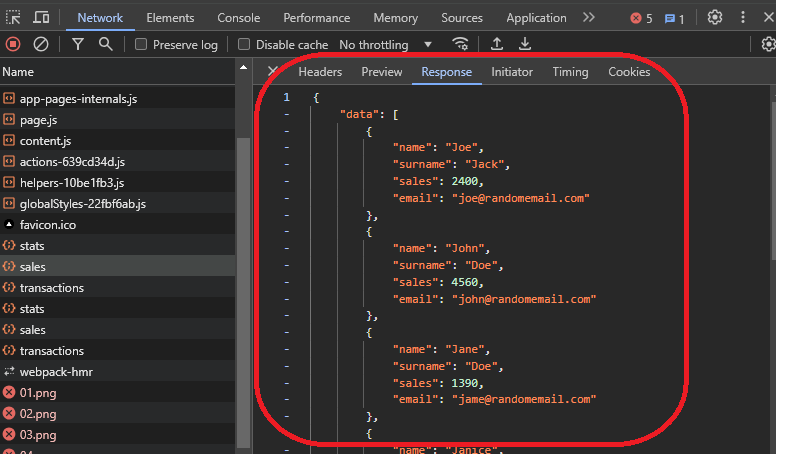
Maintenant, puisque vous avez cet appel, vous pouvez l'utiliser dans le navigateur pour obtenir le résultat. Pour ce faire, vous devez utiliser la fonction fetch de JavaScript. Cette approche vous aidera à voir le résultat de la fonction et comment elle fonctionne.
Un moyen simple de faire cela est de cliquer sur l'appel, puis d'aller à « copier », et de choisir « copier en tant que fetch ». Dans ce cas, « fetch it » signifie copier la requête pour la réutiliser en tant qu'appel fetch en JavaScript, avec tous les en-têtes et le corps inclus dans le texte copié.
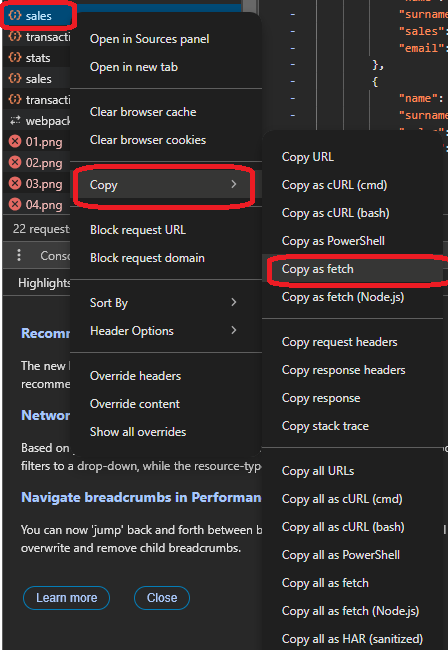
Voici le code du fetch :
let fetchResult = fetch("http://localhost:3000/api/sales", {
"headers": {
"accept": "*/*",
"accept-language": "en,tr-TR;q=0.9,tr;q=0.8,en-US;q=0.7,ar;q=0.6,it;q=0.5",
"sec-ch-ua": "\"Chromium\";v=\"124\", \"Google Chrome\";v=\"124\", \"Not-A.Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin"
},
"referrer": "http://localhost:3000/dashboard",
"referrerPolicy": "strict-origin-when-cross-origin",
"body": null,
"method": "GET",
"mode": "cors",
"credentials": "include"
})
Vous pouvez consommer cet appel en utilisant ce code :
fetchResult.then(res => res.json()).then(console.log)
Voici le résultat du fetch :
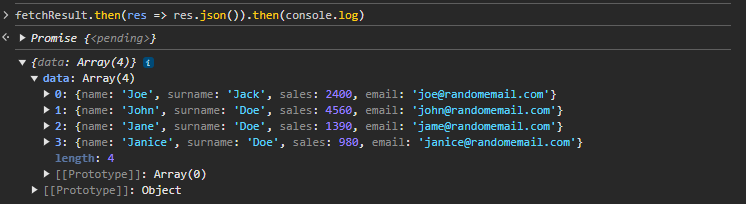
Comme vous pouvez le voir, vous avez pu utiliser l'API pour obtenir les résultats des ventes et les explorer. Vous pouvez maintenant utiliser ces données n'importe où sur le site Web actuel et récupérer l'API des ventes de manière programmatique.
Faire ce fetch via les outils de développement du navigateur supposera que vous le faites au nom du site Web. Cela ajoutera des en-têtes supplémentaires à la requête API, comme le nom d'hôte du site Web actuel dans les en-têtes et les cookies actuels attachés à la requête API.
Mais que se passe-t-il si vous allez utiliser l'API en dehors du même site Web ? Vous pourriez souhaiter utiliser l'API sur votre site Web ou un serveur. En l'utilisant sur votre site Web, je veux dire obtenir les données de ventes et les afficher sous forme de widget sur votre site Web, ou même obtenir ces données pour les stocker sur votre serveur et les traiter pour faire du data mining.
L'utilisation des données en dehors du site Web hôte nécessiterait un nom d'hôte différent à attacher aux en-têtes et d'autres cookies connectés à la requête API. Pour ces cas, vous devrez utiliser Postman, un logiciel de test de requêtes HTTP qui vous aide à tester, explorer et lire les données de requêtes API.
Comment utiliser l'API sur votre site Web
Puisque vous avez obtenu l'endpoint de l'API de la section précédente, qui était le suivant :
http://localhost:3000/api/sales
Vous pourriez vous attendre à utiliser cette URL et à récupérer les données que vous avez utilisées auparavant – et à ce que cela fonctionne immédiatement dans Postman et que vous puissiez l'utiliser sur votre site Web. Mais cela ne fonctionne pas comme cela, car cette requête fetch ne contient aucune donnée sur l'autorisation.
Vous pouvez l'essayer vous-même dans Postman pour voir l'erreur. Postman propose deux façons d'écrire l'URL de fetch : la première consiste à écrire l'appel dans l'interface utilisateur de Postman, et l'autre consiste à importer l'appel API pour l'essayer (comme vous pouvez le voir dans l'image ci-dessous).
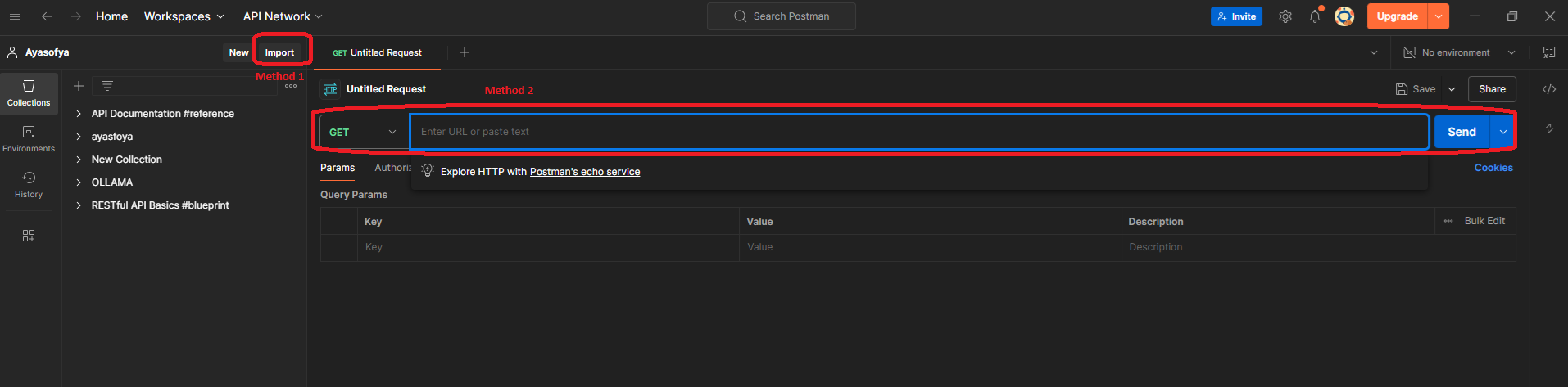
Pour importer la requête fetch dans Postman, vous devez d'abord cliquer sur l'appel dans l'onglet réseau et le copier comme :
cURL (Bash), puis le coller dans Postman. Copier l'appel en tant que cURL (Bash) vous permettra d'obtenir les en-têtes et toutes les données connexes du site Web, comme les cookies, etc.
URL uniquement, qui aura l'URL sans avoir de données supplémentaires.
Pour cet article, vous le copierez en tant qu'URL et le collerez dans Postman. Vous ferez cela pour obtenir un appel API propre sans les en-têtes et cookies connectés. Ensuite, vous cliquerez sur le bouton d'envoi dans Postman pour faire la requête et obtenir le résultat de l'API.
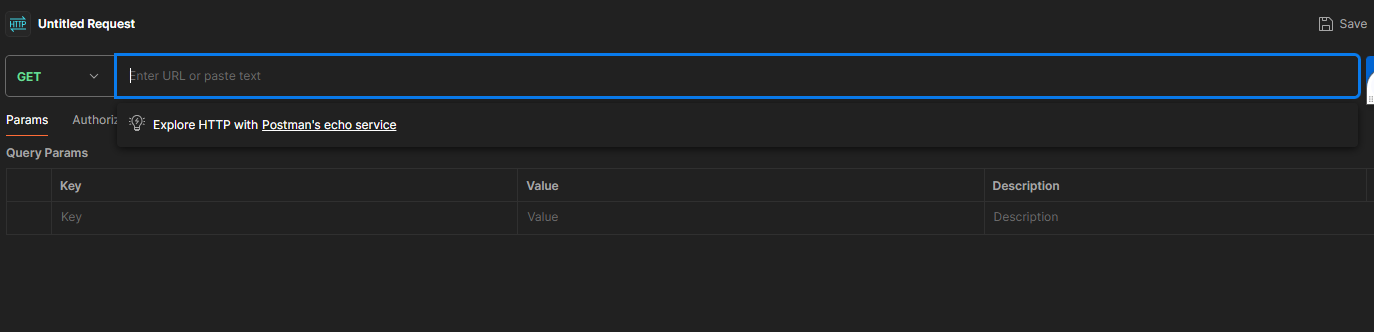
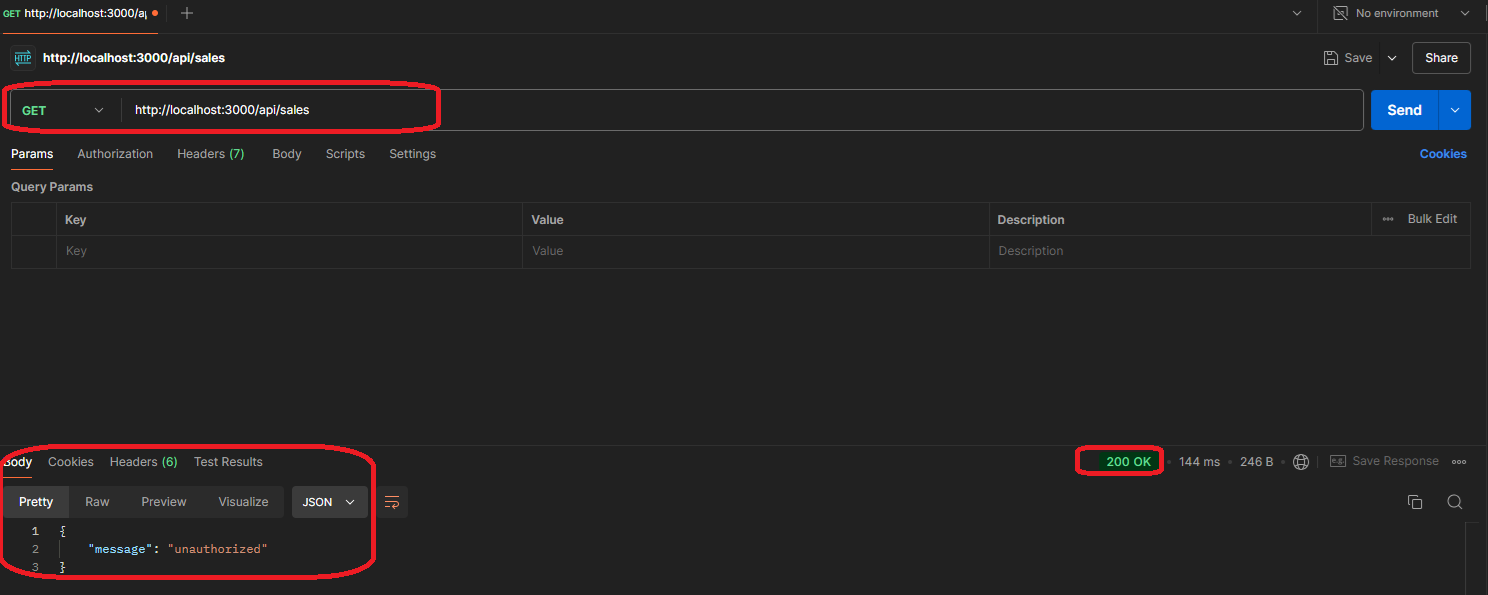
Lorsque vous cliquez sur envoyer, vous verrez que vous avez obtenu un message non autorisé du corps de l'API et un code de statut de 200. Le message non autorisé est arrivé parce que vous ne vous êtes pas connecté au site Web depuis Postman, et le code de statut est dû à la conception de l'API. Certaines API peuvent retourner un code de statut 401 : non autorisé, que vous pourriez rencontrer sur d'autres sites Web.
Être non autorisé signifie que vous n'êtes pas connecté et que vous n'avez pas la permission d'utiliser cette API spécifique. Certaines API sont publiques, que vous pouvez utiliser sans aucune clé API ou détails supplémentaires. D'autres API ont besoin d'une autorisation en termes d'utilisation d'un nom d'utilisateur et d'un mot de passe ou même d'une clé fournie par le fournisseur de l'API.
Dans cet exemple, nous utilisons une API privée qui doit être autorisée. Ici, vous obtenez les données auxquelles vous êtes uniquement autorisé à accéder.
Comment obtenir l'autorisation et l'explorer à travers le site Web
Sur la base de la section précédente, lorsque vous avez essayé l'appel API, vous avez obtenu un message vous disant que vous n'êtes pas autorisé. La requête a besoin d'une autorisation.
Vous devez donc établir une hypothèse sur l'autorisation en disant que vous pouvez obtenir les informations d'autorisation à partir de la page de connexion du site Web de démonstration. Pour l'hypothèse ici, vous pourriez penser à la manière dont le site Web utilise le nom d'utilisateur et le mot de passe pour enregistrer la session. Habituellement, les sites Web enregistrent la session via des cookies.
Après vous être connecté, vous pourrez utiliser l'appel API pour obtenir les données que vous souhaitez.
Pour essayer cela, vous pouvez suivre les étapes suivantes :
Pour comprendre ce que le site Web fait pour obtenir l'autorisation, vous pouvez soit :
Essayer de copier l'URL en tant que bash et voir quels cookies et options supplémentaires vous obtenez
Essayer de vous connecter, obtenir les données de la connexion et les envoyer à l'appel protégé
Vérification de la méthode de connexion
Vous devez comprendre comment fonctionne la fonction de connexion du site Web et quelles données sont envoyées au serveur pour vérifier la requête API et obtenir l'autorisation. Vous devez donc vérifier la page de connexion et analyser les requêtes.
Voici les étapes :
Allez à la page de connexion
Ouvrez les outils de développement
Allez à l'onglet réseau
Cliquez sur le bouton de connexion
Lorsque vous cliquez sur connexion, activez l'option de conservation du journal pour conserver les journaux lorsque vous naviguez à travers différentes pages ou lorsque le site Web vous redirige.
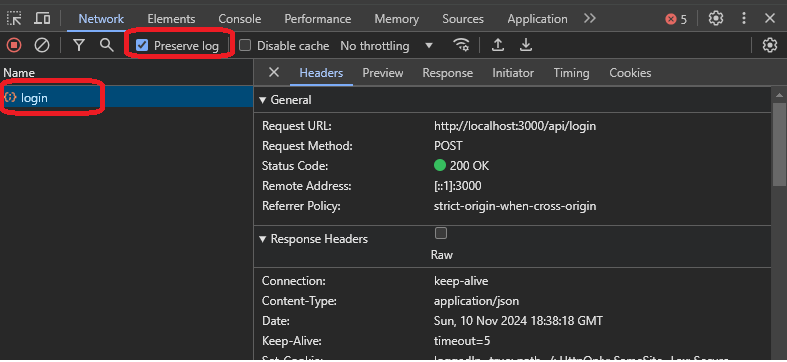
Comme vous pouvez le voir sur l'image ci-dessus, vous avez obtenu un appel de connexion depuis le site Web. Vous devez explorer l'appel et voir quels résultats vous obtenez. Voici l'explication des données de la réponse :
La réponse :
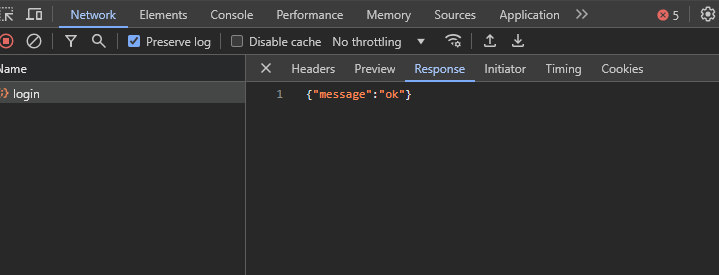
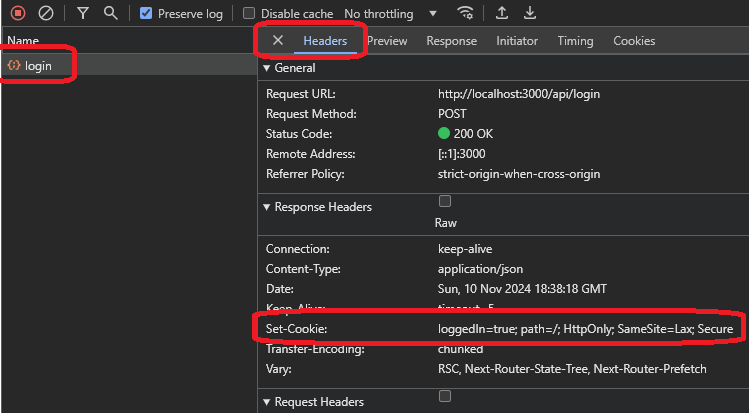
Sur l'image ci-dessus, vous pouvez voir que vous avez obtenu un message qui dit simplement « ok », ce qui ne fournit pas beaucoup de détails. Maintenant, vous devez vérifier les en-têtes et les cookies pour voir ce que le serveur a envoyé et si vous pouvez utiliser les en-têtes du serveur pour l'authentification.
Si vous vérifiez les en-têtes, vous pouvez trouver un en-tête de réponse appelé set-cookie, qui est responsable de la définition d'un cookie sur votre machine. Celui-ci a une valeur loggedin=true, indiquant un indicateur de connexion que le site Web pourrait utiliser.
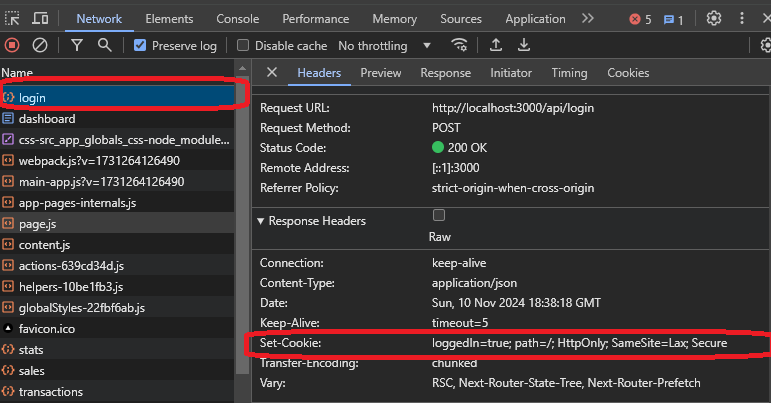
Vous verrez la même valeur lorsque vous irez à l'onglet cookies.
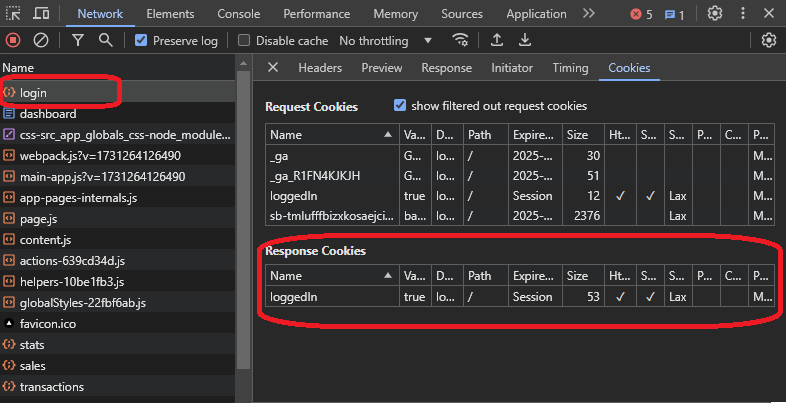
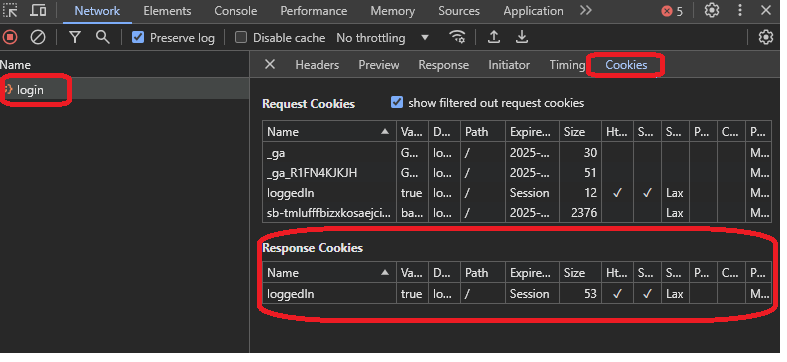
Ici, vous pourriez penser qu'avoir un cookie envoyé avec l'en-tête de requête « sales » pourrait autoriser la requête. Pour double-vérifier cela, vous pouvez ouvrir la requête de ventes à partir des outils de développement et voir quels détails supplémentaires les en-têtes de requête ont, des en-têtes ou des cookies :
Si vous allez à l'onglet cookies, vous remarquerez que la requête a envoyé les mêmes cookies :
Pour vous assurer que les cookies sont la raison, vous pouvez revenir à l'appel Postman et ajouter un cookie pour tester l'appel.
Vous devez faire ce qui suit :
Ouvrir l'onglet des en-têtes
Ajouter un cookie en tant qu'en-tête
Envoyer la requête
Vérifier le résultat
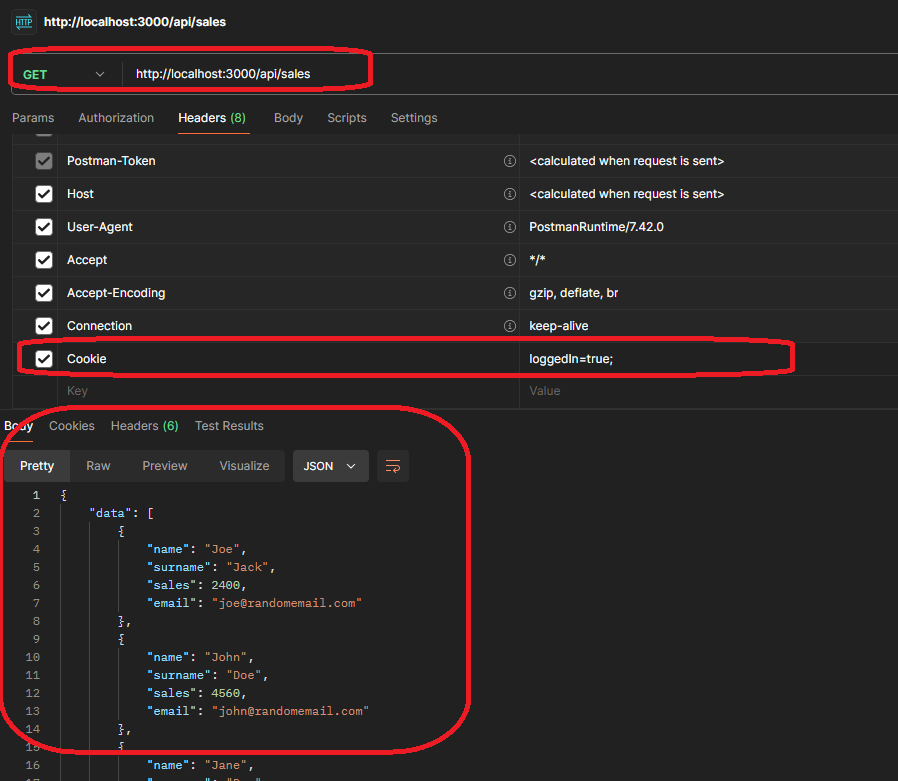
Comme vous pouvez le voir, vous avez obtenu un résultat des données, ce qui signifie que le serveur a autorisé la requête et que vous pouvez accéder aux données. Obtenir les données confirme l'hypothèse que vous avez établie au début : l'endpoint a besoin d'une authentification.
Vérification des ventes avec cURL (Bash)
Une méthode plus simple et plus accessible pour faire cela serait de copier la requête en tant que cURL (Bash), qui apporte toutes les options à Postman. Ensuite, vous devez analyser les options et voir quels en-têtes le serveur a envoyés pour l'autorisation.
Vous pouvez consulter l'image suivante, qui a l'URL collée en tant que cURL (Bash) :
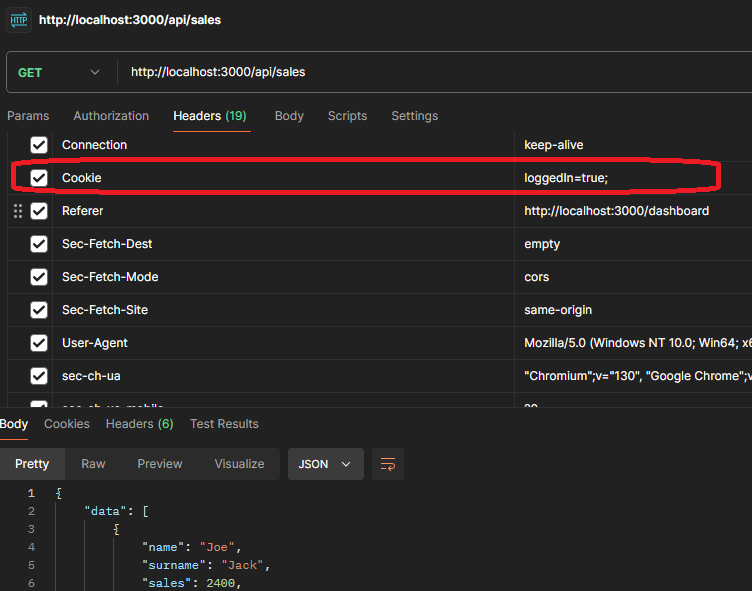
Sur l'image, vous pouvez voir que vous avez ajouté 12 en-têtes supplémentaires, et vous pouvez les vérifier et les analyser. Parfois, vous pourriez trouver un en-tête d'autorisation. D'autres fois, vous pourriez avoir d'autres en-têtes de jeton que vous devez prendre en compte.
Lorsque vous remarquez l'en-tête responsable de l'autorisation, vous devez revenir au site Web et l'analyser depuis le début pour vérifier quel endpoint fournit l'autorisation connexe. Vous l'avez fait de la manière difficile au début pour vous permettre de comprendre comment vous authentifier si les cookies étaient un jeton ou quelque chose qui serait difficile à comprendre.
Comme vous le verrez dans la section suivante, l'authentification des sites Web devient de plus en plus compliquée chaque jour, et vous devez être prêt à essayer toutes les méthodes.
Prochaines étapes : Autorisation et authentification
L'authentification et la sécurité sont des problèmes significatifs. Comme vous l'avez remarqué sur le site Web, vous avez dû utiliser les cookies pour montrer l'authentification, ce qui serait valable pour certains sites Web.
D'autres sites Web pourraient avoir des méthodes de chiffrement plus avancées pour s'authentifier et autoriser. Pour ces situations, des connaissances de base et de la curiosité vous aideront à explorer et à utiliser les API du site Web.
Certains sites Web utilisent les normes OAuth pour autoriser, en enregistrant un jeton sur le site Web pour envoyer des requêtes. À mesure que vous avancez et inversez le génie de plus de sites Web, vous remarquerez les différents modèles et serez en mesure de les comprendre et de devenir meilleur dans ce travail.
Conclusion
Cet article était à des fins éducatives, c'est pourquoi nous avons utilisé un site Web propre pour vous aider à voir les choses rapidement.
Dans des exemples du monde réel, les choses sont compliquées et vous devrez les explorer davantage. Mais les principes principaux restent similaires pour toutes les situations : un endpoint apporte les données d'autorisation/authentification et un autre qui apporte les données connexes.
L'ingénierie inverse n'est pas facile et nécessite une bonne dose de patience, de dévouement et de persévérance. Comme vous pouvez le voir, comprendre le site Web prend beaucoup de temps. Tous les sites Web n'ont pas des appels API propres, et certains ont les appels mélangés avec un nombre différent de fichiers nécessaires pour le site Web, comme des scripts CSS ou même des images. Tout ce dont vous avez besoin, c'est d'être patient et d'essayer de penser en dehors de la boîte.
Si vous aimez cet article, abonnez-vous à ma newsletter et suivez-moi sur Twitter.