

Article original : How to ingest data into Neo4j from a Kafka stream
Par Andrea Santurbano
Cet article est la deuxième partie de la série Exploiter Neo4j Streams (La partie 1 est ici). Je vais montrer comment intégrer Neo4j dans votre flux Apache Kafka en utilisant le module Sink du projet Neo4j Streams en combinaison avec les API de Apache Spark pour le Structured Streaming.

Afin de montrer comment les intégrer, simplifier l'intégration et vous permettre de tester le projet complet vous-même, j'utiliserai Apache Zeppelin — un exécutant de notebook qui vous permet simplement d'interagir nativement avec Neo4j.
Exploiter Neo4j Streams
Le projet Neo4j Streams est composé de trois piliers principaux :
- Le Change Data Capture qui permet de diffuser les changements de la base de données via des topics Kafka
- Le Sink (le sujet du premier article) qui permet de consommer des flux de données à partir de topics Kafka
- Un ensemble de procédures qui permet de produire/consommer des données vers/depuis des topics Kafka
Le Neo4j Streams Sink
Ce module permet à Neo4j de consommer des données à partir d'un topic Kafka. Il le fait de manière "intelligente" : en permettant de définir vos propres requêtes. Ce que vous devez faire est d'écrire dans votre fichier neo4j.conf quelque chose comme ceci :
streams.sink.topic.cypher.<TOPIC>=<CYPHER_QUERY>
Ainsi, si vous définissez une requête comme ceci :
streams.sink.topic.my-topic=MERGE (n:Person{id: event.id}) \
ON CREATE SET n += event.properties
Et pour des événements comme ceci :
{id:"alice@example.com",properties:{name:"Alice",age:32}}
En interne, le module Sink exécutera une requête comme ceci :
UNWIND {batch} AS event
MERGE (n:Label {id: event.id})
ON CREATE SET n += event.properties
Le paramètre batch est un ensemble d'événements Kafka qui sont collectés par le SINK et traités dans une seule transaction afin de maximiser l'efficacité d'exécution.
Ainsi, en continuant avec l'exemple ci-dessus, une représentation complète possible pourrait être :
WITH [{id:"alice@example.com",properties:{name:"Alice",age:32}},
{id:"bob@example.com",properties:{name:"Bob",age:42}}] AS batch
UNWIND batch AS event
MERGE (n:Person {id: event.id})
ON CREATE SET n += event.properties
Cela donne au développeur le pouvoir de définir ses propres règles métier car vous pouvez choisir de mettre à jour, ajouter, supprimer ou adapter vos données de graphe en fonction des événements que vous recevez.
Un cas d'utilisation simple : Ingestion de données à partir d'API Open Data
Imaginez que votre pipeline de données doit lire des données à partir d'une API Open Data, les enrichir avec une autre source interne, et enfin les persister dans Neo4j. Dans ce cas, la meilleure solution pour le faire est d'utiliser Apache Spark. Cela permet facilement de gérer différentes sources de données avec la même abstraction Dataset.
Configuration de l'environnement
En allant sur le dépôt Github suivant, vous trouverez tout le code nécessaire pour reproduire ce que je présente dans cet article. Ce dont vous aurez besoin pour commencer est Docker, puis vous pouvez simplement lancer la stack en entrant dans le répertoire et en exécutant la commande suivante depuis le terminal :
$ docker-compose up
Cela démarrera tout l'environnement qui comprend :
- Neo4j + module Neo4j Streams + procédures APOC
- Apache Kafka
- Apache Spark
- Apache Zeppelin
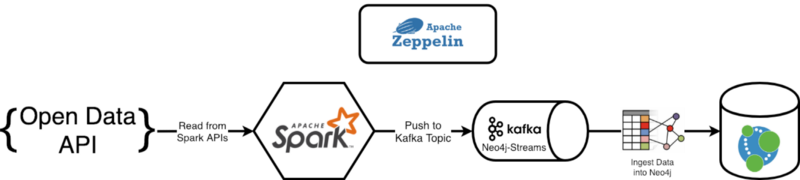
En allant dans Apache Zeppelin @ http://localhost:8080, vous trouverez dans le répertoire Medium/Part 2 un notebook « From Open Data to Sink » qui est le sujet de cet article.
L'API Open Data
Nous choisirons le jeu de données du Ministère italien de la Santé des magasins de pharmacie.
Définir la requête Sink
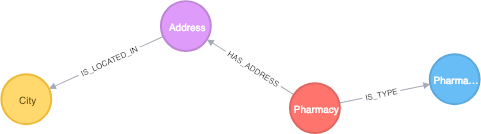
Si vous allez dans le fichier [d](http://localhost:8080)ocker-compose.yml, vous trouverez une nouvelle propriété qui correspond à la définition de la requête Sink :
NEO4J_streams_sink_topic_cypher_pharma: "
MERGE (p:Pharmacy{fiscalId: event.FISCAL_ID}) ON CREATE SET p.name = event.NAME
MERGE (t:PharmacyType{type: event.TYPE_NAME})
MERGE (a:Address{name: event.ADDRESS + ', ' + event.CITY})
ON CREATE SET a.latitude = event.LATITUDE,
a.longitude = event.LONGITUDE,
a.code = event.POSTAL_CODE,
a.point = event.POINT
MERGE (c:City{name: event.CITY})
MERGE (p)-[:IS_TYPE]-(t)
MERGE (p)-[:HAS_ADDRESS]-(a)
MERGE (a)-[:IS_LOCATED_IN]->(c)"
La propriété NEO4J_streams_sink_topic_cypher_pharma définit que toutes les données provenant d'un topic nommé pharma seront consommées avec la requête correspondante.
Le modèle de graphe qui résulte de la requête ci-dessus est :
Le Notebook — From Open Data to Sink
La première étape consiste à télécharger le CSV depuis le Portail Open Data et à le charger dans un Dataframe Spark :
val fileUrl = z.input("File Url").toString
val url = new java.net.URL(fileUrl)
val localFilePath = s"/zeppelin/spark-warehouse/${url.getPath.split("/").last}"
val src = scala.io.Source.fromURL(fileUrl)("ISO-8859-1")
val out = new java.io.FileWriter(localFilePath)
out.write(src.mkString)
out.close
val csvDF = (spark.read
.format("csv")
.option("delimiter", ";")
.option("header", "true")
.load(localFilePath))
Explorons maintenant la structure du csvDF :
root
|-- CODICEIDENTIFICATIVOFARMACIA: string (nullable = true)
|-- CODFARMACIAASSEGNATODAASL: string (nullable = true)
|-- INDIRIZZO: string (nullable = true)
|-- DESCRIZIONEFARMACIA: string (nullable = true)
|-- PARTITAIVA: string (nullable = true)
|-- CAP: string (nullable = true)
|-- CODICECOMUNEISTAT: string (nullable = true)
|-- DESCRIZIONECOMUNE: string (nullable = true)
|-- FRAZIONE: string (nullable = true)
|-- CODICEPROVINCIAISTAT: string (nullable = true)
|-- SIGLAPROVINCIA: string (nullable = true)
|-- DESCRIZIONEPROVINCIA: string (nullable = true)
|-- CODICEREGIONE: string (nullable = true)
|-- DESCRIZIONEREGIONE: string (nullable = true)
|-- DATAINIZIOVALIDITA: string (nullable = true)
|-- DATAFINEVALIDITA: string (nullable = true)
|-- DESCRIZIONETIPOLOGIA: string (nullable = true)
|-- CODICETIPOLOGIA: string (nullable = true)
|-- LATITUDINE: string (nullable = true)
|-- LONGITUDINE: string (nullable = true)
|-- LOCALIZE: string (nullable = true)
Nous voulons nous concentrer sur deux champs :
- CODICEIDENTIFICATIVOFARMACIA : il "devrait" être l'identifiant unique donné par le Ministère italien de la Santé à une pharmacie
- DATAFINEVALIDITA : il indique si la pharmacie est toujours active (si elle n'a pas de valeur, elle est active, sinon elle est fermée)
Nous sauvegardons maintenant le Dataframe dans une vue temporaire Spark appelée OPEN_DATA :
csvDF.createOrReplaceTempView("open_data")
Remplaçons maintenant la vue temporaire OPEN_DATA en filtrant le jeu de données pour les enregistrements valides et en renommant certains champs :
%sql
CREATE OR REPLACE TEMP VIEW OPEN_DATA AS
SELECT CODICEIDENTIFICATIVOFARMACIA AS PHARMA_ID,
INDIRIZZO AS ADDRESS,
DESCRIZIONEFARMACIA AS NAME,
PARTITAIVA AS FISCAL_ID,
CAP AS POSTAL_CODE,
DESCRIZIONECOMUNE AS CITY,
DESCRIZIONEPROVINCIA AS PROVINCE,
DATAFINEVALIDITA,
DESCRIZIONETIPOLOGIA AS TYPE_NAME,
CODICETIPOLOGIA AS TYPE,
REPLACE(LATITUDINE, ,, .) AS LATITUDE,
REPLACE(LONGITUDINE, ,, .) AS LONGITUDE,
REPLACE(LATITUDINE, ,, .) || , || REPLACE(LONGITUDINE, ,, .) AS POINT
FROM OPEN_DATA
WHERE DATAFINEVALIDITA <> -
AND CODICEIDENTIFICATIVOFARMACIA <> -
Créons maintenant la vue temporaire OPEN_DATA_KAFKA_STAGE qui doit contenir deux colonnes :
- VALUE : JSON qui représente les données que nous voulons envoyer au topic Kafka
- KEY : une clé qui identifie la ligne
Vous pouvez remarquer que ceci est exactement le minimum requis pour un ProducerRecord :
%sql
CREATE OR REPLACE TEMP VIEW OPEN_DATA_KAFKA_STAGE AS
SELECT TO_JSON(
STRUCT(PHARMA_ID,
ADDRESS,
NAME,
FISCAL_ID,
POSTAL_CODE,
CITY,
PROVINCE,
TYPE_NAME,
TYPE,
LATITUDE,
LONGITUDE,
POINT)
) AS VALUE,
PHARMA_ID AS KEY
FROM OPEN_DATA
Envoyons maintenant les données au topic pharma via Spark :
(spark.table("OPEN_DATA_KAFKA_STAGE").selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.write
.format("kafka")
.option("kafka.enable.auto.commit", "true")
.option("kafka.bootstrap.servers", "broker:9093")
.option("topic", "pharma")
.save())
Les données diffusées vers le topic pharma via le job Spark seront maintenant consommées par le module Neo4j Streams Sink grâce au modèle Cypher que nous avons défini au début de l'article.
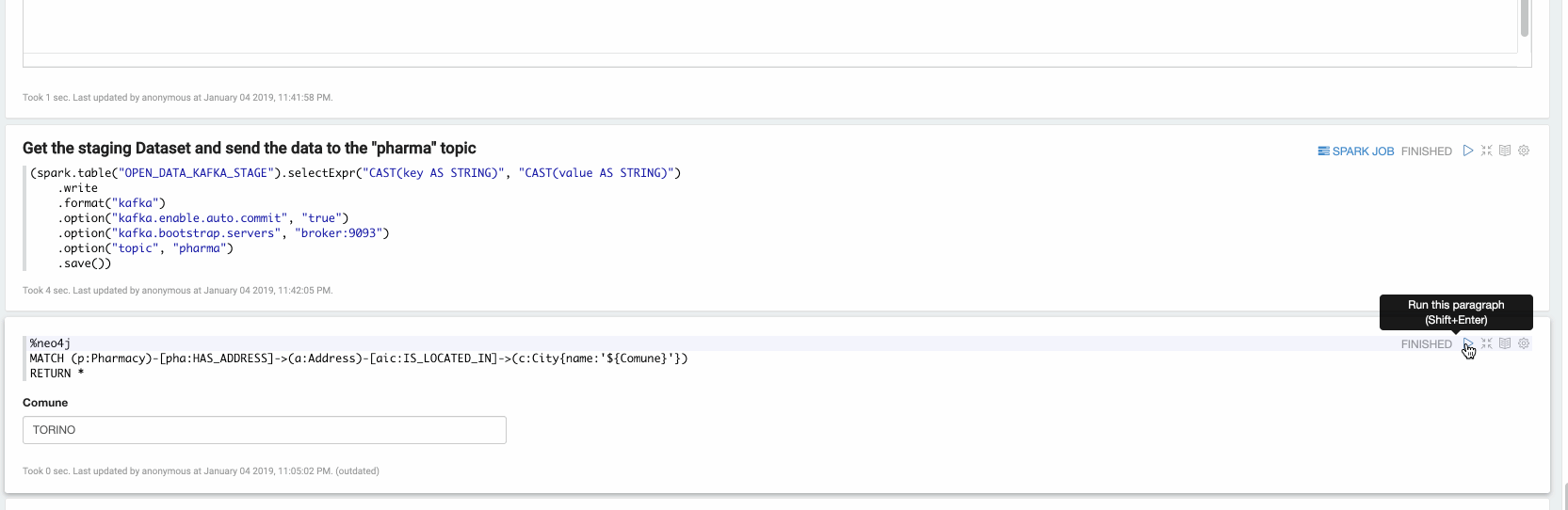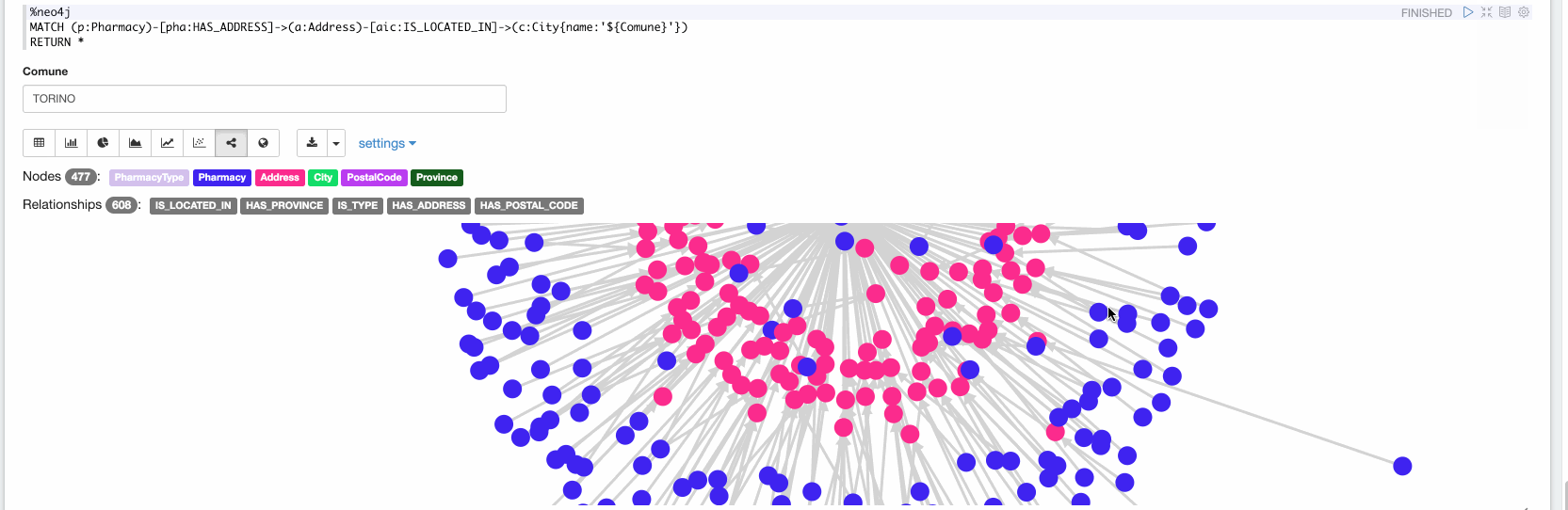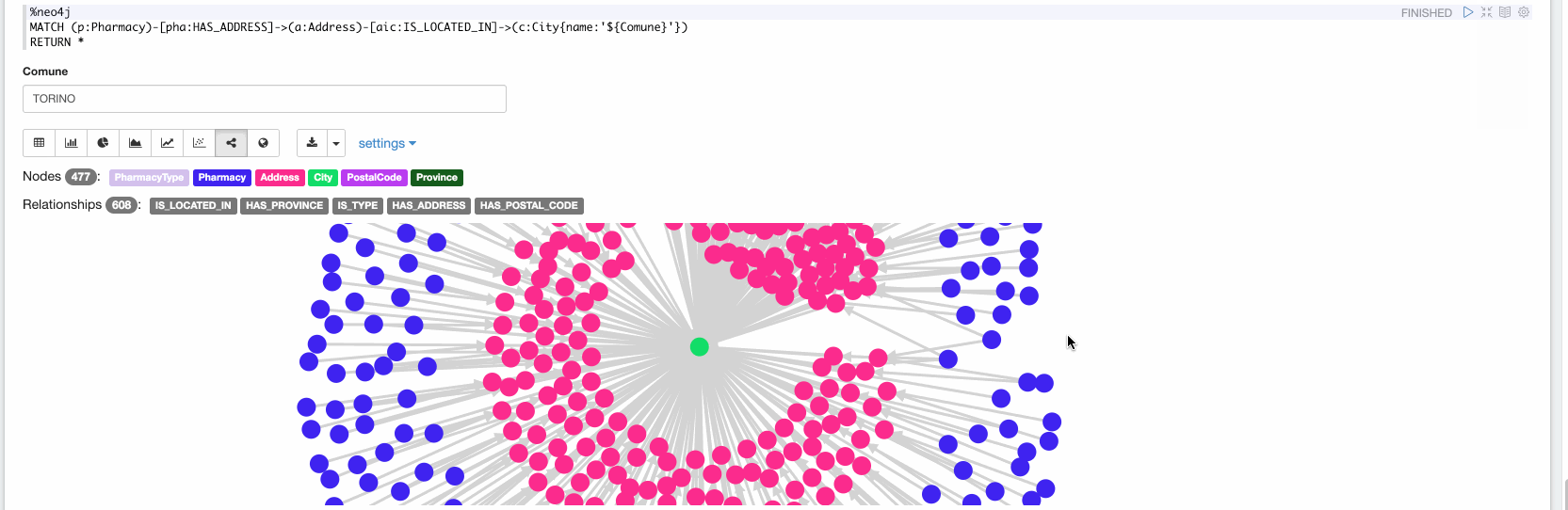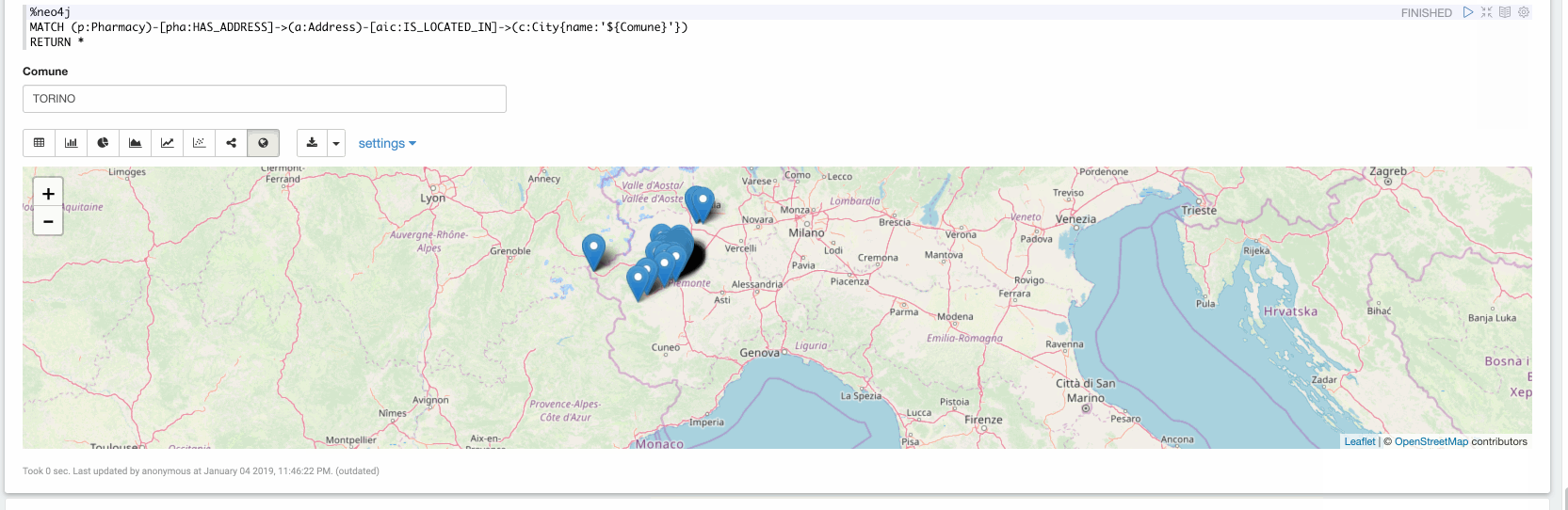
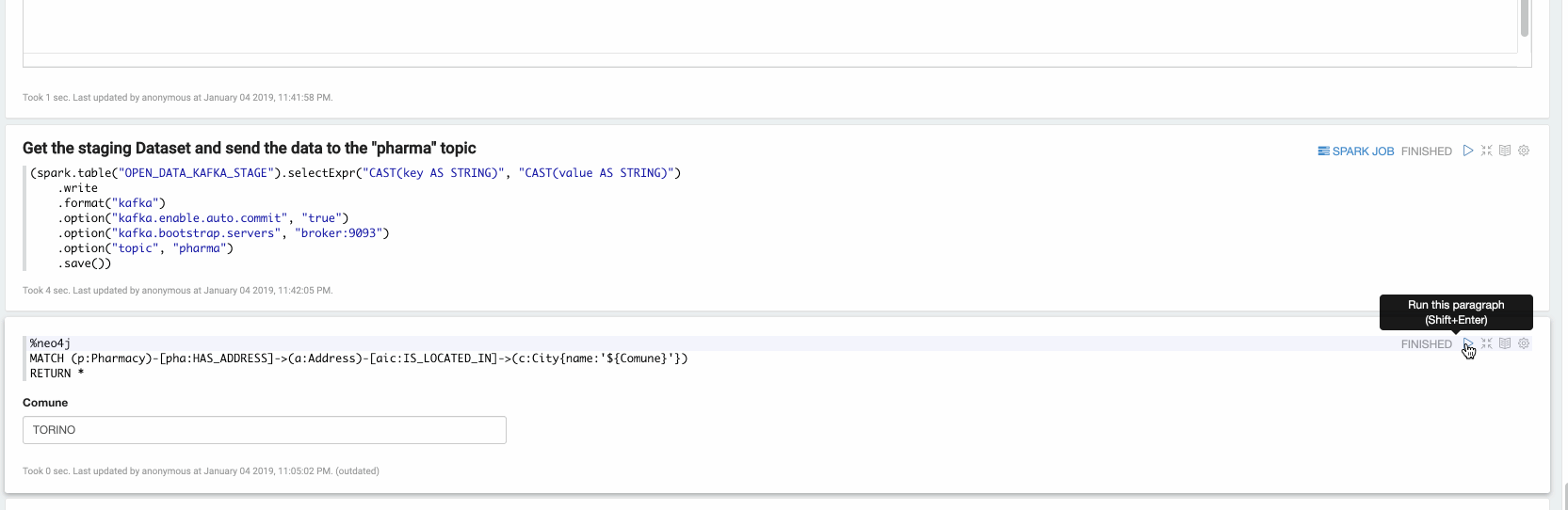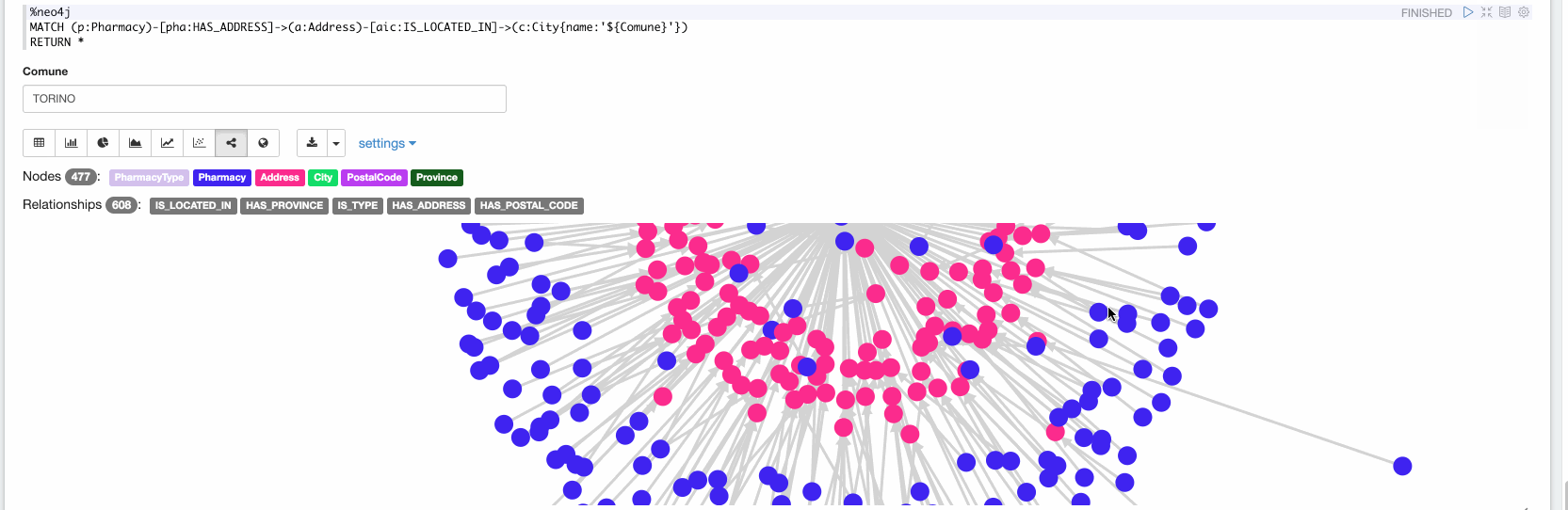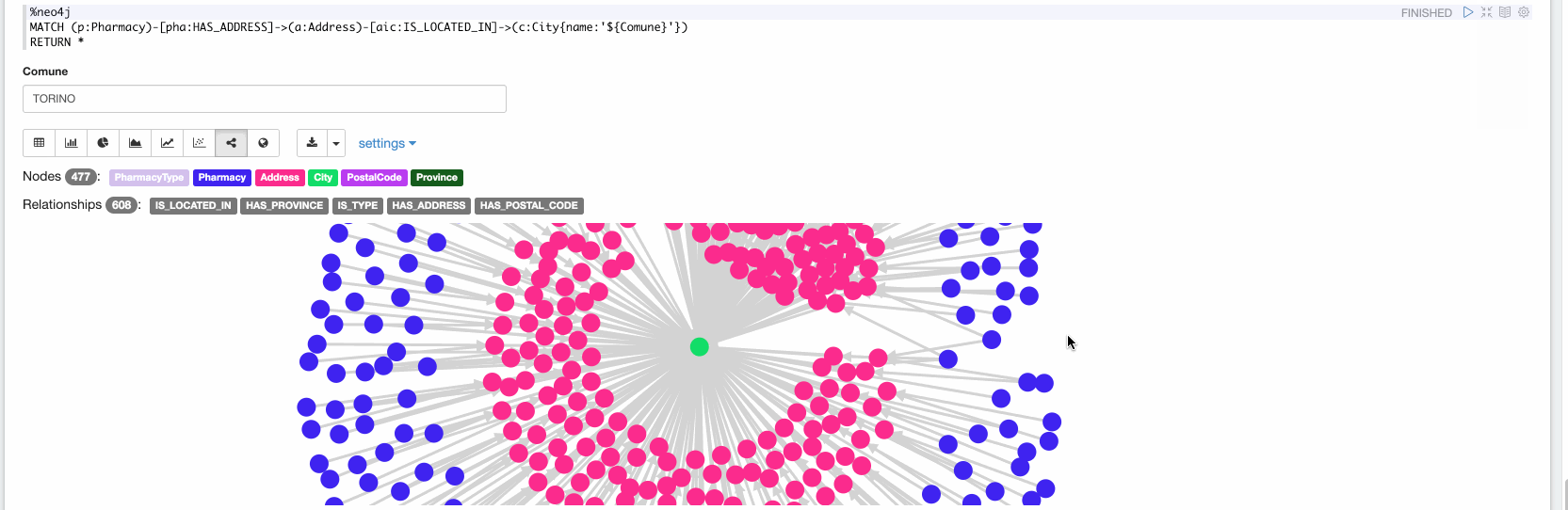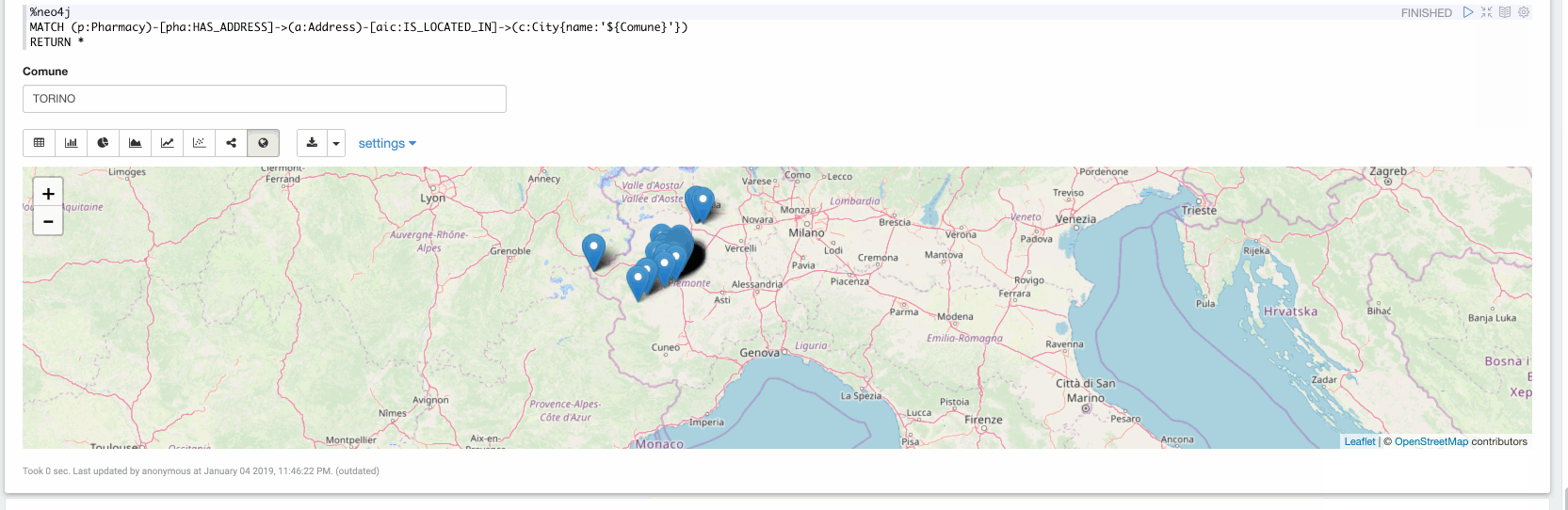
Maintenant, dans le dernier paragraphe, nous pouvons explorer les données ingérées. Dans la vidéo suivante, nous explorons toutes les pharmacies situées à Turin :
Conclusion
Dans cet article (veuillez consulter le premier si vous ne l'avez pas encore fait), nous avons vu comment utiliser le module SINK afin de transformer des événements Apache Kafka en structures de graphe arbitraires. Vous pouvez le faire de manière très simple en utilisant les API Apache Spark.
Dans la partie 3, nous découvrirons comment utiliser la procédure Streams afin de produire/consommer des données directement via des requêtes Cypher, alors restez à l'écoute !
Si vous avez déjà testé le module Neo4j-Streams ou l'avez testé via ce notebook, veuillez remplir notre enquête de feedback.
Si vous rencontrez des problèmes ou avez des idées pour améliorer notre travail, veuillez ouvrir une issue GitHub.