

Article original : How to import Google BigQuery tables to AWS Athena
Par Aftab Ansari
En tant qu'ingénieur de données, il est très probable que vous utilisiez l'une des principales plateformes cloud de big data telles que AWS, Microsoft Azure ou Google Cloud pour le traitement de vos données. De plus, la migration de données d'une plateforme à une autre est quelque chose que vous avez peut-être déjà rencontré ou que vous rencontrerez à un moment donné.
Dans cet article, je vais montrer comment j'ai importé des tables Google BigQuery vers AWS Athena. Si vous avez seulement besoin d'une liste d'outils à utiliser avec quelques conseils de haut niveau, vous pouvez rapidement consulter cet article qui montre comment importer une seule table BigQuery dans le métastore Hive. Dans cet article, je vais montrer une façon d'importer un projet BigQuery complet (plusieurs tables) dans les métastores Hive et Athena.
Il existe quelques limitations d'importation : par exemple, lorsque vous importez des données de tables partitionnées, vous ne pouvez pas importer des partitions individuelles. Veuillez vérifier les limitations avant de commencer le processus.
Pour importer avec succès des tables Google BigQuery vers Athena, j'ai effectué les étapes montrées ci-dessous. J'ai utilisé le format AVRO lors du vidage des données et des schémas de Google BigQuery et de leur chargement dans AWS Athena.
Étape 1. Vider les données BigQuery vers Google Cloud Storage
Étape 2. Transférer les données de Google Cloud Storage vers AWS S3
Étape 3. Extraire le schéma AVRO des fichiers AVRO stockés dans S3
Étape 4. Créer des tables Hive sur les données AVRO, utiliser le schéma de l'Étape 3
Étape 5. Extraire la définition de la table Hive des tables Hive
Étape 6. Utiliser le résultat des Étapes 3 et 5 pour créer des tables Athena
Alors pourquoi dois-je créer des tables Hive en premier lieu alors que l'objectif final est d'avoir les données dans Athena ? Cela est dû au fait que :
- Athena ne supporte pas l'utilisation de
avro.schema.urlpour spécifier le schéma de la table. - Athena nécessite que vous spécifiiez explicitement les noms des champs et leurs types de données dans l'instruction CREATE.
- Athena nécessite également le schéma AVRO au format JSON sous
avro.schema.literal. - Vous pouvez consulter cette documentation AWS doc pour plus de détails.
Ainsi, les tables Hive peuvent être créées directement en pointant vers les fichiers de schéma AVRO stockés sur S3. Mais pour avoir la même chose dans Athena, les colonnes et le schéma sont nécessaires dans l'instruction CREATE TABLE.
Une façon de surmonter cela est d'abord d'extraire le schéma des données AVRO à fournir en tant que avro.schema.literal. Ensuite, pour les noms de champs et les types de données nécessaires à l'instruction CREATE, créez des tables Hive basées sur les schémas AVRO stockés dans S3 et utilisez SHOW CREATE TABLE pour vider/exporter les définitions de tables Hive qui contiennent les noms de champs et les types de données. Enfin, créez des tables Athena en combinant le schéma AVRO extrait et la définition de la table Hive. Je vais en discuter en détail dans les sections suivantes.
Pour la démonstration, j'ai les tables BigQuery suivantes que je souhaite importer vers Athena.

Alors, commençons !
Étape 1. Vider les données BigQuery vers Google Cloud Storage
Il est possible de vider les données BigQuery dans le stockage Google à l'aide de l'interface utilisateur du cloud Google. Cependant, cela peut devenir une tâche fastidieuse si vous devez vider plusieurs tables manuellement.
Pour résoudre ce problème, j'ai utilisé Google Cloud Shell. Dans Cloud Shell, vous pouvez combiner des scripts shell réguliers avec des commandes BigQuery et vider plusieurs tables relativement rapidement. Vous pouvez activer Cloud Shell comme montré dans l'image ci-dessous.

À partir de Cloud Shell, l'opération suivante fournit les commandes BigQuery extract pour vider chaque table du dataset « backend » vers Google Cloud Storage.
bq ls backend | cut -d ' ' -f3 | tail -n+3 | xargs -I@ echo bq --location=US extract --destination_format AVRO --compression SNAPPY <dataset>.@ gs://<bucket>@
Dans mon cas, cela imprime :
aftab_ansari@cloudshell:~ (project-ark-archive)$ bq ls backend | cut -d ' ' -f3 | tail -n+3 | xargs -I@ echo bq --location=US extract --destination_format AVRO --compression SNAPPY backend.@ gs://plr_data_transfer_temp/bigquery_data/backend/@/@-*.avro
bq --location=US extract --destination_format AVRO --compression SNAPPY backend.sessions_daily_phase2 gs://plr_data_transfer_temp/bigquery_data/backend/sessions_daily_phase2/sessions_daily_phase2-*.avro
bq --location=US extract --destination_format AVRO --compression SNAPPY backend.sessions_detailed_phase2 gs://plr_data_transfer_temp/bigquery_data/backend/sessions_detailed_phase2/sessions_detailed_phase2-*.avro
bq --location=US extract --destination_format AVRO --compression SNAPPY backend.sessions_phase2 gs://plr_data_transfer_temp/bigquery_data/backend/sessions_phase2/sessions_phase2-*.avro
Veuillez noter : --compression SNAPPY, cela est important, car des fichiers non compressés et volumineux peuvent faire bloquer la commande gsutil (qui est utilisée pour transférer les données vers AWS S3). Le caractère générique (*) fait en sorte que bq extract divise les tables plus grandes (>1GB) en plusieurs fichiers de sortie. L'exécution de ces commandes sur Cloud Shell copie les données vers le répertoire Google Storage suivant.
gs://plr_data_transfer_temp/bigquery_data/backend/table_name/table_name-*.avro
Faisons un ls pour voir le fichier AVRO vidé.
aftab_ansari@cloudshell:~ (project-ark-archive)$ gsutil ls gs://plr_data_transfer_temp/bigquery_data/backend/sessions_daily_phase2
gs://plr_data_transfer_temp/bigquery_data/backend/sessions_daily_phase2/sessions_daily_phase2-000000000000.avro
Je peux également naviguer depuis l'interface utilisateur et trouver les données comme montré ci-dessous.
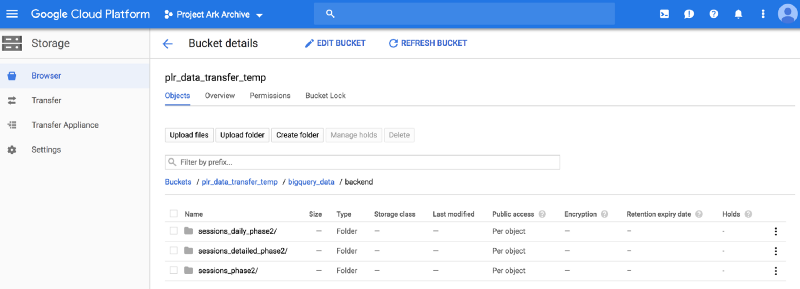
Étape 2. Transférer les données de Google Cloud Storage vers AWS S3
Le transfert de données de Google Storage vers AWS S3 est simple. Tout d'abord, configurez vos identifiants S3. Sur Cloud Shell, créez ou modifiez le fichier .boto ( vi ~/.boto) et ajoutez ceci :
[Credentials]aws_access_key_id = <votre clé d'accès aws>aws_secret_access_key = <votre clé secrète d'accès aws>[s3]host = s3.us-east-1.amazonaws.comuse-sigv4 = True
Veuillez noter : s3.us-east-1.amazonaws.com doit correspondre à la région où se trouve le bucket.
Après avoir configuré les identifiants, exécutez gsutil pour transférer les données de Google Storage vers AWS S3. Par exemple :
gsutil rsync -r gs://your-gs-bucket/your-extract-path/your-schema s3://your-aws-bucket/your-target-path/your-schema
Ajoutez le drapeau -n à la commande ci-dessus pour afficher les opérations qui seraient effectuées en utilisant la commande spécifiée sans les exécuter réellement.
Dans ce cas, pour transférer les données vers S3, j'ai utilisé ce qui suit :
aftab_ansari@cloudshell:~ (project-ark-archive)$ gsutil rsync -r gs://plr_data_transfer_temp/bigquery_data/backend s3://my-bucket/bq_data/backend
Building synchronization state…Starting synchronization…Copying gs://plr_data_transfer_temp/bigquery_data/backend/sessions_daily_phase2/sessions_daily_phase2-000000000000.avro [Content-Type=application/octet-stream]...Copying gs://plr_data_transfer_temp/bigquery_data/backend/sessions_detailed_phase2/sessions_detailed_phase2-000000000000.avro [Content-Type=application/octet-stream]...Copying gs://plr_data_transfer_temp/bigquery_data/backend/sessions_phase2/sessions_phase2-000000000000.avro [Content-Type=application/octet-stream]...| [3 files][987.8 KiB/987.8 KiB]Operation completed over 3 objects/987.8 KiB.
Vérifions si les données ont été transférées vers S3. J'ai vérifié cela depuis ma machine locale :
aws s3 ls --recursive s3://my-bucket/bq_data/backend --profile smoke | awk '{print $4}'
bq_data/backend/sessions_daily_phase2/sessions_daily_phase2-000000000000.avrobq_data/backend/sessions_detailed_phase2/sessions_detailed_phase2-000000000000.avrobq_data/backend/sessions_phase2/sessions_phase2-000000000000.avro
Étape 3. Extraire le schéma AVRO des fichiers AVRO stockés dans S3
Pour extraire le schéma des données AVRO, vous pouvez utiliser l'outil Apache avro-tools-<version>.jar avec le paramètre getschema. L'avantage d'utiliser cet outil est qu'il retourne le schéma dans un format que vous pouvez utiliser directement dans l'instruction WITH SERDEPROPERTIES lors de la création de tables Athena.
Vous avez remarqué que j'ai obtenu un seul fichier .avro par table lors du vidage des tables BigQuery. Cela était dû au faible volume de données — sinon, j'aurais obtenu plusieurs fichiers par table. Peu importe qu'il y ait un seul fichier ou plusieurs fichiers par table, il suffit d'exécuter avro-tools contre n'importe quel fichier unique par table pour extraire le schéma de cette table.
J'ai téléchargé la dernière version de avro-tools qui est avro-tools-1.8.2.jar. J'ai d'abord copié tous les fichiers .avro de s3 vers le disque local :
[hadoop@ip-10-0-10-205 tmpAftab]$ aws s3 cp s3://my-bucket/bq_data/backend/ bq_data/backend/ --recursive
download: s3://my-bucket/bq_data/backend/sessions_detailed_phase2/sessions_detailed_phase2-000000000000.avro to bq_data/backend/sessions_detailed_phase2/sessions_detailed_phase2-000000000000.avro
download: s3://my-bucket/bq_data/backend/sessions_phase2/sessions_phase2-000000000000.avro to bq_data/backend/sessions_phase2/sessions_phase2-000000000000.avro
download: s3://my-bucket/bq_data/backend/sessions_daily_phase2/sessions_daily_phase2-000000000000.avro to bq_data/backend/sessions_daily_phase2/sessions_daily_phase2-000000000000.avro
La commande Avro-tools devrait ressembler à java -jar avro-tools-1.8.2.jar getschema your_data.avro > schema_file.avsc. Cela peut devenir fastidieux si vous avez plusieurs fichiers AVRO (en réalité, je l'ai fait pour un projet avec beaucoup plus de tables). Encore une fois, j'ai utilisé un script shell pour générer des commandes. J'ai créé extract_schema_avro.sh avec le contenu suivant :
schema_avro=(bq_data/backend/*)for i in ${!schema_avro[*]}; do input_file=$(find ${schema_avro[$i]} -type f) output_file=$(ls -l ${schema_avro[$i]} | tail -n+2 \ | awk -v srch="avro" -v repl="avsc" '{ sub(srch,repl,$9); print $9 }') commands=$( echo "java -jar avro-tools-1.8.2.jar getschema " \ $input_file" > bq_data/schemas/backend/avro/"$output_file ) echo $commandsdone
L'exécution de extract_schema_avro.sh fournit ce qui suit :
[hadoop@ip-10-0-10-205 tmpAftab]$ sh extract_schema_avro.sh
java -jar avro-tools-1.8.2.jar getschema bq_data/backend/sessions_daily_phase2/sessions_daily_phase2-000000000000.avro > bq_data/schemas/backend/avro/sessions_daily_phase2-000000000000.avsc
java -jar avro-tools-1.8.2.jar getschema bq_data/backend/sessions_detailed_phase2/sessions_detailed_phase2-000000000000.avro > bq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avsc
java -jar avro-tools-1.8.2.jar getschema bq_data/backend/sessions_phase2/sessions_phase2-000000000000.avro > bq_data/schemas/backend/avro/sessions_phase2-000000000000.avsc
L'exécution des commandes ci-dessus copie le schéma extrait sous bq_data/schemas/backend/avro/ :
[hadoop@ip-10-0-10-205 tmpAftab]$ ls -l bq_data/schemas/backend/avro/* | awk '{print $9}'
bq_data/schemas/backend/avro/sessions_daily_phase2-000000000000.avscbq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avscbq_data/schemas/backend/avro/sessions_phase2-000000000000.avsc
Vérifions également ce qu'il y a dans un fichier .avsc.
[hadoop@ip-10-0-10-205 tmpAftab]$ cat bq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avsc
{"type" : "record","name" : "Root","fields" : [ {"name" : "uid","type" : [ "null", "string" ]}, {"name" : "platform","type" : [ "null", "string" ]}, {"name" : "version","type" : [ "null", "string" ]}, {"name" : "country","type" : [ "null", "string" ]}, {"name" : "sessions","type" : [ "null", "long" ]}, {"name" : "active_days","type" : [ "null", "long" ]}, {"name" : "session_time_minutes","type" : [ "null", "double" ]} ]}
Comme vous pouvez le voir, le schéma est dans un format qui peut être directement utilisé dans Athena WITH SERDEPROPERTIES. Mais avant Athena, j'ai utilisé les schémas AVRO pour créer des tables Hive. Si vous souhaitez éviter la création de tables Hive, vous pouvez lire les fichiers .avsc pour extraire les noms de champs et les types de données, mais vous devez alors mapper les types de données vous-même du format AVRO au DDL de création de table Athena.
La complexité de la tâche de mappage dépend de la complexité des types de données dans vos tables. Pour simplifier (et couvrir la plupart des types de données simples à complexes), j'ai laissé Hive faire le mappage pour moi. J'ai donc d'abord créé les tables dans le métastore Hive. Ensuite, j'ai utilisé SHOW CREATE TABLE pour obtenir les noms de champs et les types de données faisant partie du DDL.
Étape 4. Créer des tables Hive sur les données AVRO, utiliser le schéma de l'Étape 3
Comme discuté précédemment, Hive permet de créer des tables en utilisant avro.schema.url. Une fois que vous avez le schéma (fichier .avsc) extrait des données AVRO, vous pouvez créer des tables comme suit :
CREATE EXTERNAL TABLE table_nameSTORED AS AVROLOCATION 's3://your-aws-bucket/your-target-path/avro_data'TBLPROPERTIES ('avro.schema.url'='s3://your-aws-bucket/your-target-path/your-avro-schema');
Tout d'abord, téléchargez les schémas extraits vers S3 afin que avro.schema.url puisse faire référence à leurs emplacements S3 :
[hadoop@ip-10-0-10-205 tmpAftab]$ aws s3 cp bq_data/schemas s3://my-bucket/bq_data/schemas --recursive
upload: bq_data/schemas/backend/avro/sessions_daily_phase2-000000000000.avsc to s3://my-bucket/bq_data/schemas/backend/avro/sessions_daily_phase2-000000000000.avsc
upload: bq_data/schemas/backend/avro/sessions_phase2-000000000000.avsc to s3://my-bucket/bq_data/schemas/backend/avro/sessions_phase2-000000000000.avsc
upload: bq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avsc to s3://my-bucket/bq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avsc
Après avoir les données AVRO et le schéma dans S3, le DDL pour la table Hive peut être créé en utilisant le modèle montré au début de cette section. J'ai utilisé un autre script shell create_tables_hive.sh (montré ci-dessous) pour couvrir n'importe quel nombre de tables :
schema_avro=$(ls -l bq_data/backend | tail -n+2 | awk '{print $9}')for table_name in $schema_avro; do file_name=$(ls -l bq_data/backend/$table_name | tail -n+2 | awk \ -v srch="avro" -v repl="avsc" '{ sub(srch,repl,$9); print $9 }') table_definition=$( echo "CREATE EXTERNAL TABLE IF NOT EXISTS backend."$table_name"\\nSTORED AS AVRO""\\nLOCATION 's3://my-bucket/bq_data/backend/"$table_name"'""\\nTBLPROPERTIES('avro.schema.url'='s3://my-bucket/bq_data/\schemas/backend/avro/"$file_name"');" ) printf "\n$table_definition\n"done
L'exécution du script fournit ce qui suit :
[hadoop@ip-10-0-10-205 tmpAftab]$ sh create_tables_hive.sh
CREATE EXTERNAL TABLE IF NOT EXISTS backend.sessions_daily_phase2STORED AS AVROLOCATION 's3://my-bucket/bq_data/backend/sessions_daily_phase2' TBLPROPERTIES ('avro.schema.url'='s3://my-bucket/bq_data/schemas/backend/avro/sessions_daily_phase2-000000000000.avsc');
CREATE EXTERNAL TABLE IF NOT EXISTS backend.sessions_detailed_phase2 STORED AS AVROLOCATION 's3://my-bucket/bq_data/backend/sessions_detailed_phase2'TBLPROPERTIES ('avro.schema.url'='s3://my-bucket/bq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avsc');
CREATE EXTERNAL TABLE IF NOT EXISTS backend.sessions_phase2STORED AS AVROLOCATION 's3://my-bucket/bq_data/backend/sessions_phase2' TBLPROPERTIES ('avro.schema.url'='s3://my-bucket/bq_data/schemas/backend/avro/sessions_phase2-000000000000.avsc');
J'ai exécuté ce qui précède sur la console Hive pour créer réellement les tables Hive :
[hadoop@ip-10-0-10-205 tmpAftab]$ hiveLogging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j2.properties Async: false
hive> CREATE EXTERNAL TABLE IF NOT EXISTS backend.sessions_daily_phase2> STORED AS AVRO> LOCATION 's3://my-bucket/bq_data/backend/sessions_daily_phase2' TBLPROPERTIES ('avro.schema.url'='s3://my-bucket/bq_data/schemas/backend/avro/sessions_daily_phase2-000000000000.avsc');OKTime taken: 4.24 seconds
hive>> CREATE EXTERNAL TABLE IF NOT EXISTS backend.sessions_detailed_phase2 STORED AS AVRO> LOCATION 's3://my-bucket/bq_data/backend/sessions_detailed_phase2'> TBLPROPERTIES ('avro.schema.url'='s3://my-bucket/bq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avsc');OKTime taken: 0.563 seconds
hive>> CREATE EXTERNAL TABLE IF NOT EXISTS backend.sessions_phase2> STORED AS AVRO> LOCATION 's3://my-bucket/bq_data/backend/sessions_phase2' TBLPROPERTIES ('avro.schema.url'='s3://my-bucket/bq_data/schemas/backend/avro/sessions_phase2-000000000000.avsc');OKTime taken: 0.386 seconds
J'ai donc créé les tables Hive avec succès. Pour vérifier que les tables fonctionnent, j'ai exécuté cette requête simple :
hive> select count(*) from backend.sessions_detailed_phase2;Query ID = hadoop_20190214152548_2316cb5b-29f1-4416-922e-a6ff02ec1775Total jobs = 1Launching Job 1 out of 1Status: Running (Executing on YARN cluster with App id application_1550010493995_0220)----------------------------------------------------------------------------------------------VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED----------------------------------------------------------------------------------------------Map 1 .......... container SUCCEEDED 1 1 0 0 0 0Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0----------------------------------------------------------------------------------------------VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 8.17 s----------------------------------------------------------------------------------------------OK6130
Donc cela fonctionne !
Étape 5. Extraire la définition de la table Hive des tables Hive
Comme discuté précédemment, Athena nécessite que vous spécifiiez explicitement les noms des champs et leurs types de données dans l'instruction CREATE. À l'Étape 3, j'ai extrait le schéma AVRO, qui peut être utilisé dans WITH SERDEPROPERTIES du DDL de la table Athena, mais je dois également spécifier tous les noms de champs et leurs types de données (Hive). Maintenant que j'ai les tables dans le métastore Hive, je peux facilement obtenir ceux-ci en exécutant SHOW CREATE TABLE. Tout d'abord, préparez les requêtes DDL Hive pour toutes les tables :
[hadoop@ip-10-0-10-205 tmpAftab]$ ls -l bq_data/backend | tail -n+2 | awk '{print "hive -e '\''SHOW CREATE TABLE backend."$9"'\'' > bq_data/schemas/backend/hql/backend."$9".hql;" }'
hive -e 'SHOW CREATE TABLE backend.sessions_daily_phase2' > bq_data/schemas/backend/hql/backend.sessions_daily_phase2.hql;
hive -e 'SHOW CREATE TABLE backend.sessions_detailed_phase2' > bq_data/schemas/backend/hql/backend.sessions_detailed_phase2.hql;
hive -e 'SHOW CREATE TABLE backend.sessions_phase2' > bq_data/schemas/backend/hql/backend.sessions_phase2.hql;
L'exécution des commandes ci-dessus copie les définitions des tables Hive sous bq_data/schemas/backend/hql/. Voyons ce qu'il y a à l'intérieur :
[hadoop@ip-10-0-10-205 tmpAftab]$ cat bq_data/schemas/backend/hql/backend.sessions_detailed_phase2.hql
CREATE EXTERNAL TABLE `backend.sessions_detailed_phase2`(`uid` string COMMENT '',`platform` string COMMENT '',`version` string COMMENT '',`country` string COMMENT '',`sessions` bigint COMMENT '',`active_days` bigint COMMENT '',`session_time_minutes` double COMMENT '')ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'LOCATION's3://my-bucket/bq_data/backend/sessions_detailed_phase2'TBLPROPERTIES ('avro.schema.url'='s3://my-bucket/bq_data/schemas/backend/avro/sessions_detailed_phase2-000000000000.avsc','transient_lastDdlTime'='1550157659')
À présent, tous les éléments nécessaires pour créer des tables AVRO dans Athena sont là :
- Les noms de champs et les types de données peuvent être obtenus à partir du DDL de la table Hive (à utiliser dans la section des colonnes de l'instruction
CREATE) - Le schéma AVRO (JSON) peut être obtenu à partir des fichiers
.avscextraits (à fournir dansWITH SERDEPROPERTIES).
Étape 6. Utiliser le résultat des Étapes 3 et 5 pour créer des tables Athena
Si vous êtes toujours avec moi, vous avez fait un excellent travail en arrivant jusqu'ici. Je vais maintenant effectuer l'étape finale qui consiste à créer des tables Athena. J'ai utilisé le script suivant pour combiner les fichiers .avsc et .hql afin de construire les définitions des tables Athena :
[hadoop@ip-10-0-10-205 tmpAftab]$ cat create_tables_athena.sh
# directory where extracted avro schemas are storedschema_avro=(bq_data/schemas/backend/avro/*)# directory where extracted HQL schemas are storedschema_hive=(bq_data/schemas/backend/hql/*)for i in ${!schema_avro[*]}; do schema=$(awk -F '{print $0}' '/CREATE/{flag=1}/STORED/{flag=0}\ flag' ${schema_hive[$i]}) location=$(awk -F '{print $0}' '/LOCATION/{flag=1; next}\ /TBLPROPERTIES/{flag=0} flag' ${schema_hive[$i]}) properties=$(cat ${schema_avro[$i]}) table=$(echo $schema '\n' \ "WITH SERDEPROPERTIES ('avro.schema.literal'='\n"$properties \ "\n""')STORED AS AVRO \n" \ "LOCATION" $location";\n\n") printf "\n$table\n"done \ > bq_data/schemas/backend/all_athena_tables/all_athena_tables.hql
L'exécution du script ci-dessus copie les définitions des tables Athena vers bq_data/schemas/backend/all_athena_tables/all_athena_tables.hql. Dans mon cas, il contient :
[hadoop@ip-10-0-10-205 all_athena_tables]$ cat all_athena_tables.hql
CREATE EXTERNAL TABLE `backend.sessions_daily_phase2`( `uid` string COMMENT '', `activity_date` string COMMENT '', `sessions` bigint COMMENT '', `session_time_minutes` double COMMENT '')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'WITH SERDEPROPERTIES ('avro.schema.literal'='{ "type" : "record", "name" : "Root", "fields" : [ { "name" : "uid", "type" : [ "null", "string" ] }, { "name" : "activity_date", "type" : [ "null", "string" ] }, { "name" : "sessions", "type" : [ "null", "long" ] }, { "name" : "session_time_minutes", "type" : [ "null", "double" ] } ] }')STORED AS AVROLOCATION 's3://my-bucket/bq_data/backend/sessions_daily_phase2';
CREATE EXTERNAL TABLE `backend.sessions_detailed_phase2`( `uid` string COMMENT '', `platform` string COMMENT '', `version` string COMMENT '', `country` string COMMENT '', `sessions` bigint COMMENT '', `active_days` bigint COMMENT '', `session_time_minutes` double COMMENT '')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'WITH SERDEPROPERTIES ('avro.schema.literal'='{ "type" : "record", "name" : "Root", "fields" : [ { "name" : "uid", "type" : [ "null", "string" ] }, { "name" : "platform", "type" : [ "null", "string" ] }, { "name" : "version", "type" : [ "null", "string" ] }, { "name" : "country", "type" : [ "null", "string" ] }, { "name" : "sessions", "type" : [ "null", "long" ] }, { "name" : "active_days", "type" : [ "null", "long" ] }, { "name" : "session_time_minutes", "type" : [ "null", "double" ] } ] } ')STORED AS AVROLOCATION 's3://my-bucket/bq_data/backend/sessions_detailed_phase2';
CREATE EXTERNAL TABLE `backend.sessions_phase2`( `uid` string COMMENT '', `sessions` bigint COMMENT '', `active_days` bigint COMMENT '', `session_time_minutes` double COMMENT '')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'WITH SERDEPROPERTIES ('avro.schema.literal'='{ "type" : "record", "name" : "Root", "fields" : [ { "name" : "uid", "type" : [ "null", "string" ] }, { "name" : "sessions", "type" : [ "null", "long" ] }, { "name" : "active_days", "type" : [ "null", "long" ] }, { "name" : "session_time_minutes", "type" : [ "null", "double" ] } ] }')STORED AS AVROLOCATION 's3://my-bucket/bq_data/backend/sessions_phase2';
Et enfin, j'ai exécuté les scripts ci-dessus dans Athena pour créer les tables :
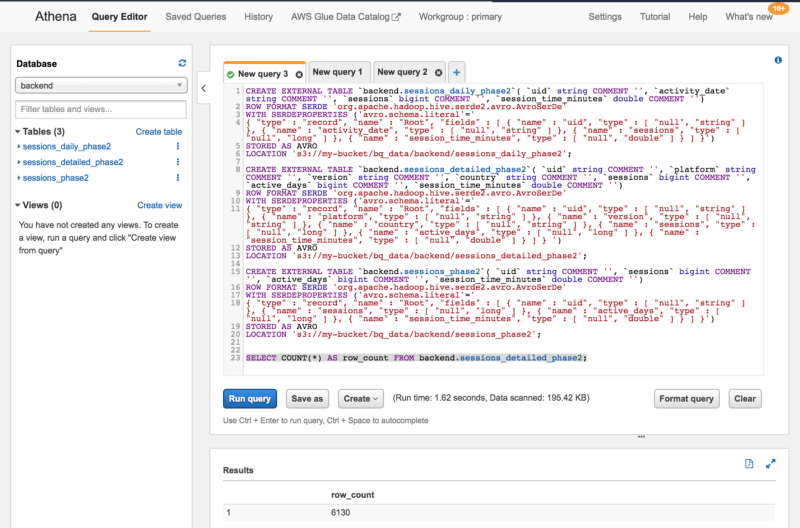
Voilà.
Je pense que le processus est un peu long. Cependant, cela a bien fonctionné pour moi. L'autre approche serait d'utiliser l'assistant AWS Glue pour explorer les données et déduire le schéma. Si vous avez utilisé l'assistant AWS Glue, veuillez partager votre expérience dans la section des commentaires ci-dessous.