

Article original : How to implement Change Data Capture using Kafka Streams
Par Luca Florio
La Capture de Données Modifiées (CDC) consiste à observer les changements survenant dans une base de données et à les rendre disponibles sous une forme exploitable par d'autres systèmes.
L'un des cas d'utilisation les plus intéressants est de les rendre disponibles sous forme de flux d'événements. Cela signifie que vous pouvez, par exemple, capturer les événements et mettre à jour un index de recherche au fur et à mesure que les données sont écrites dans la base de données.
Intéressant, n'est-ce pas ? Voyons comment implémenter un système CDC capable d'observer les changements apportés à une base de données NoSQL (MongoDB), de les transmettre via un courtier de messages (Kafka), de traiter les messages du flux (Kafka Streams), et de mettre à jour un index de recherche (Elasticsearch) !?
TL;DR
Le code complet du projet est disponible sur GitHub dans ce dépôt. Si vous souhaitez sauter toutes mes explications et simplement exécuter l'exemple, allez directement à la section Comment exécuter le projet vers la fin de l'article !?
Cas d'utilisation & infrastructure
Nous exécutons une application web qui stocke les photos téléchargées par les utilisateurs. Les gens peuvent partager leurs clichés, permettre aux autres de les télécharger, créer des albums, etc. Les utilisateurs peuvent également fournir une description de leurs photos, ainsi que des métadonnées Exif et d'autres informations utiles.
Nous voulons stocker ces informations et les utiliser pour améliorer notre moteur de recherche. Nous nous concentrerons sur cette partie de notre système, illustrée dans le diagramme suivant.
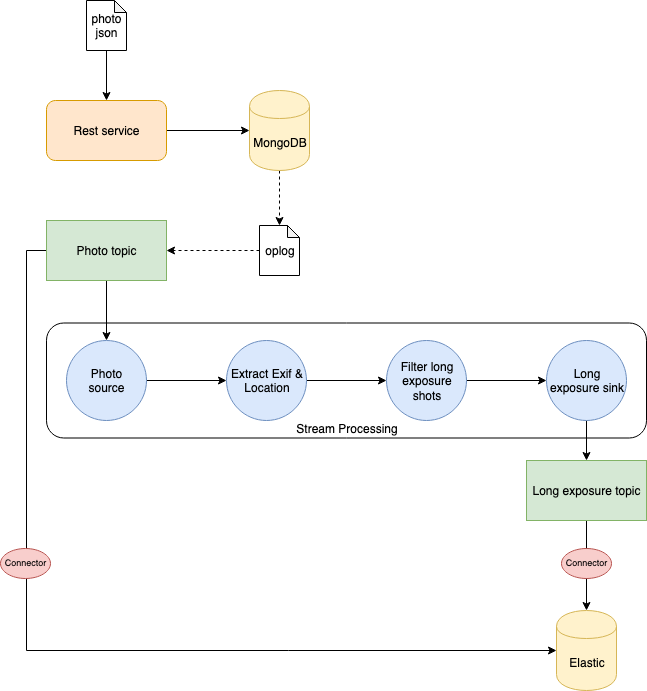 Architecture de stockage des informations sur les photos
Architecture de stockage des informations sur les photos
Les informations sont fournies au format JSON. Comme j'aime publier mes clichés sur Unsplash, et que le site offre un accès gratuit à son API, j'ai utilisé leur modèle pour le document JSON des photos.
Une fois le JSON envoyé via une requête POST à notre serveur, nous stockons le document dans une base de données MongoDB. Nous le stockerons également dans Elasticsearch pour l'indexation et la recherche rapide.
Cependant, nous adorons les photos en longue exposition, et nous aimerions stocker dans un index séparé un sous-ensemble d'informations concernant ce type de photo. Cela peut être le temps d'exposition, ainsi que l'emplacement (latitude et longitude) où la photo a été prise. De cette manière, nous pouvons créer une carte des lieux où les photographes prennent généralement des photos en longue exposition.
Voici la partie intéressante : au lieu d'appeler explicitement Elasticsearch dans notre code une fois que les informations sur la photo sont stockées dans MongoDB, nous pouvons implémenter un CDC exploitant Kafka et Kafka Streams.
Nous écoutons les modifications de l'oplog MongoDB en utilisant l'interface fournie par MongoDB lui-même. Lorsque la photo est stockée, nous l'envoyons à un sujet Kafka photo. En utilisant Kafka Connect, un puits Elasticsearch est configuré pour sauvegarder tout ce qui est envoyé à ce sujet dans un index spécifique. De cette manière, nous pouvons indexer automatiquement toutes les photos stockées dans MongoDB.
Nous devons également nous occuper des photos en longue exposition. Cela nécessite un certain traitement des informations pour extraire ce dont nous avons besoin. Pour cette raison, nous utilisons Kafka Streams pour créer une topologie de traitement afin de :
- Lire à partir du sujet
photo - Extraire les informations Exif et de localisation
- Filtrer les photos en longue exposition (temps d'exposition > 1 sec.)
- Écrire dans un sujet
long-exposure.
Ensuite, un autre puits Elasticsearch lira les données du sujet long-exposure et les écrira dans un index spécifique dans Elasticsearch.
C'est assez simple, mais c'est suffisant pour s'amuser avec CDC et Kafka Streams ! ?
Implémentation du serveur
Examinons ce que nous devons implémenter : notre serveur exposant les API REST !
Modèles et DAO
D'abord, nous avons besoin d'un modèle de nos données et d'un Data Access Object (DAO) pour communiquer avec notre base de données MongoDB.
Comme je l'ai dit, le modèle pour les informations JSON des photos est celui utilisé par Unsplash. Consultez la documentation de l'API gratuite documentation pour un exemple du JSON que nous utiliserons.
J'ai créé le mapping pour la sérialisation/désérialisation des informations JSON des photos en utilisant spray-json. Je vais sauter les détails à ce sujet, si vous êtes curieux, regardez simplement le dépôt !
Concentrons-nous sur le modèle pour la photo en longue exposition.
case class LongExposurePhoto(id: String, exposureTime: Float, createdAt: Date, location: Location)
object LongExposurePhotoJsonProtocol extends DefaultJsonProtocol {
implicit val longExposurePhotoFormat:RootJsonFormat[LongExposurePhoto] = jsonFormat(LongExposurePhoto, "id", "exposure_time", "created_at", "location")
}
C'est assez simple : nous conservons du JSON de la photo les informations sur l'id, le temps d'exposition (exposureTime), quand la photo a été créée (createdAt), et le location où elle a été prise. Le location comprend le city, le country, et le position composé de latitude et longitude.
Le DAO se compose simplement de la classe PhotoDao.scala.
class PhotoDao(database: MongoDatabase, photoCollection: String) {
val collection: MongoCollection[Document] = database.getCollection(photoCollection)
def createPhoto(photo: Photo): Future[String] = {
val doc = Document(photo.toJson.toString())
doc.put("_id", photo.id)
collection.insertOne(doc).toFuture()
.map(_ => photo.id)
}
}
Puisque je veux garder cet exemple minimal et axé sur l'implémentation du CDC, le DAO n'a qu'une seule méthode pour créer un nouveau document photo dans MongoDB.
C'est simple : créer un document à partir du JSON de la photo, et l'insérer dans Mongo en utilisant id comme celui de la photo elle-même. Ensuite, nous pouvons retourner l'id de la photo nouvellement insérée dans un Future (l'API MongoDB est asynchrone).
Producteur Kafka
Une fois la photo stockée dans MongoDB, nous devons l'envoyer au sujet Kafka photo. Cela signifie que nous avons besoin d'un producteur pour écrire le message dans son sujet. La classe PhotoProducer.scala ressemble à ceci.
case class PhotoProducer(props: Properties, topic: String) {
createKafkaTopic(props, topic)
val photoProducer = new KafkaProducer[String, String](props)
def sendPhoto(photo: Photo): Future[RecordMetadata] = {
val record = new ProducerRecord[String, String](topic, photo.id, photo.toJson.compactPrint)
photoProducer.send(record)
}
def closePhotoProducer(): Unit = photoProducer.close()
}
Je dirais que cela est assez explicite. La partie la plus intéressante est probablement la méthode createKafkaTopic qui est implémentée dans le package utils.
def createKafkaTopic(props: Properties, topic: String): Unit = {
val adminClient = AdminClient.create(props)
val photoTopic = new NewTopic(topic, 1, 1)
adminClient.createTopics(List(photoTopic).asJava)
}
Cette méthode crée le sujet dans Kafka en définissant 1 comme partition et facteur de réplication (c'est suffisant pour cet exemple). Ce n'est pas obligatoire, mais créer le sujet à l'avance permet à Kafka d'équilibrer les partitions, de sélectionner les leaders, etc. Cela sera utile pour que notre topologie de flux soit prête à traiter dès que nous démarrons notre serveur.
Écouteur d'événements
Nous avons le DAO qui écrit dans MongoDB et le producteur qui envoie le message dans Kafka. Nous devons les relier d'une manière ou d'une autre afin que lorsque le document est stocké dans MongoDB, le message soit envoyé au sujet photo. C'est le but de la classe PhotoListener.scala.
case class PhotoListener(collection: MongoCollection[Document], producer: PhotoProducer) {
val cursor: ChangeStreamObservable[Document] = collection.watch()
cursor.subscribe(new Observer[ChangeStreamDocument[Document]] {
override def onNext(result: ChangeStreamDocument[Document]): Unit = {
result.getOperationType match {
case OperationType.INSERT => {
val photo = result.getFullDocument.toJson().parseJson.convertTo[Photo]
producer.sendPhoto(photo).get()
println(s"Sent photo with Id ${photo.id}")
}
case _ => println(s"Operation ${result.getOperationType} not supported")
}
}
override def onError(e: Throwable): Unit = println(s"onError: $e")
override def onComplete(): Unit = println("onComplete")})
}
Nous exploitons l'interface Change Streams fournie par la bibliothèque scala de MongoDB.
Voici comment cela fonctionne : nous watch() la collection où les photos sont stockées. Lorsqu'il y a un nouvel événement (onNext), nous exécutons notre logique.
Pour cet exemple, nous ne nous intéressons qu'à la création de nouveaux documents, donc nous vérifions explicitement que l'opération est de type OperationType.INSERT. Si l'opération est celle qui nous intéresse, nous obtenons le document et le convertissons en un objet Photo à envoyer par notre producteur.
C'est tout ! Avec quelques lignes de code, nous avons connecté la création de documents dans MongoDB à un flux d'événements dans Kafka. ?
En tant que note supplémentaire, soyez conscient que pour utiliser l'interface Change Streams, nous devons configurer un ensemble de réplicas MongoDB. Cela signifie que nous devons exécuter 3 instances de MongoDB et les configurer pour qu'elles agissent comme un ensemble de réplicas en utilisant la commande suivante dans le client mongo :
rs.initiate({_id : "r0", members: [{ _id : 0, host : "mongo1:27017", priority : 1 },{ _id : 1, host :"mongo2:27017", priority : 0 },{ _id : 2, host : "mongo3:27017", priority : 0, arbiterOnly: true }]})
Ici, nos instances sont les conteneurs que nous exécuterons dans le fichier docker-compose, à savoir mongo1, mongo2 et mongo3.
Topologie de traitement
Il est temps de construire notre topologie de traitement ! Elle sera responsable de la création de l'index long-exposure dans Elasticsearch. La topologie est décrite par le diagramme suivant :
 Topologie de traitement
Topologie de traitement
et elle est implémentée dans la classe d'objet LongExposureTopology.scala.
Analysons chaque étape de notre topologie de traitement.
val stringSerde = new StringSerde
val streamsBuilder = new StreamsBuilder()
val photoSource: KStream[String, String] = streamsBuilder.stream(sourceTopic, Consumed.`with`(stringSerde, stringSerde))
La première étape consiste à lire à partir d'un sujet source. Nous démarrons un flux à partir du sourceTopic (qui est le sujet photo) en utilisant l'objet StreamsBuilder(). L'objet stringSerde est utilisé pour sérialiser et désérialiser le contenu du sujet en tant que String.
Veuillez noter qu'à chaque étape du traitement, nous créons un nouveau flux de données avec un objet KStream. Lors de la création du flux, nous spécifions la clé et la valeur produites par le flux. Dans notre topologie, la clé sera toujours une String. À cette étape, la valeur produite est encore une String.
val covertToPhotoObject: KStream[String, Photo] =
photoSource.mapValues((_, jsonString) => {
val photo = jsonString.parseJson.convertTo[Photo]
println(s"Processing photo ${photo.id}")
photo
})
L'étape suivante consiste à convertir la valeur extraite du sujet photo en un objet Photo approprié.
Nous partons donc du flux photoSource et travaillons sur les valeurs en utilisant la fonction mapValues. Nous analysons simplement la valeur en tant que JSON et créons l'objet Photo qui sera envoyé dans le flux convertToPhotoObject.
val filterWithLocation: KStream[String, Photo] = covertToPhotoObject.filter((_, photo) => photo.location.exists(_.position.isDefined))
Il n'y a aucune garantie que la photo que nous traitons contiendra des informations sur l'emplacement, mais nous en avons besoin dans notre objet de longue exposition. Cette étape de la topologie filtre le flux covertToPhotoObject pour ne garder que les photos contenant des informations sur l'emplacement, et crée le flux filterWithLocation.
val filterWithExposureTime: KStream[String, Photo] = filterWithLocation.filter((_, photo) => photo.exif.exists(_.exposureTime.isDefined))
Un autre fait important pour notre traitement est le temps d'exposition de la photo. Pour cette raison, nous filtrons le flux filterWithLocation pour ne garder que les photos contenant des informations sur le temps d'exposition, créant ainsi le flux filterWithExposureTime.
val dataExtractor: KStream[String, LongExposurePhoto] =
filterWithExposureTime.mapValues((_, photo) => LongExposurePhoto(photo.id, parseExposureTime(photo.exif.get.exposureTime.get), photo.createdAt, photo.location.get))
Nous avons maintenant tout ce dont nous avons besoin pour créer un objet LongExposurePhoto ! C'est le résultat de dataExtractor : il prend la Photo provenant du flux filterWithExposureTime et produit un nouveau flux contenant LongExposurePhoto.
val longExposureFilter: KStream[String, String] =
dataExtractor.filter((_, item) => item.exposureTime > 1.0).mapValues((_, longExposurePhoto) => {
val jsonString = longExposurePhoto.toJson.compactPrint
println(s"completed processing: $jsonString")
jsonString
})
Nous y sommes presque. Nous devons maintenant conserver les photos avec un temps d'exposition long (que nous avons décidé être supérieur à 1 sec.). Nous créons donc un nouveau flux longExposureFilter sans les photos qui ne sont pas en longue exposition.
Cette fois, nous sérialisons également les LongExposurePhotos en chaîne JSON correspondante, qui sera écrite dans Elasticsearch à l'étape suivante.
longExposureFilter.to(sinkTopic, Produced.`with`(stringSerde, stringSerde))
streamsBuilder.build()
C'est la dernière étape de notre topologie. Nous écrivons to notre sinkTopic (qui est le sujet long-exposure) en utilisant le sérialiseur/désérialiseur de chaîne ce qui est à l'intérieur du flux longExposureFilter.
La dernière commande build simplement la topologie que nous venons de créer.
Maintenant que nous avons notre topologie, nous pouvons l'utiliser dans notre serveur. La classe PhotoStreamProcessor.scala est ce qui gère le traitement.
class PhotoStreamProcessor(kafkaProps: Properties, streamProps: Properties, sourceTopic: String, sinkTopic: String) {
createKafkaTopic(kafkaProps, sinkTopic)
val topology: Topology = LongExposureTopology.build(sourceTopic, sinkTopic)
val streams: KafkaStreams = new KafkaStreams(topology, streamProps)
sys.ShutdownHookThread {
streams.close(java.time.Duration.ofSeconds(10))
}
def start(): Unit = new Thread {
override def run(): Unit = {
streams.cleanUp()
streams.start()
println("Started long exposure processor")
}
}.start()
}
Tout d'abord, nous créons le sinkTopic, en utilisant la même méthode utilitaire que nous avons vue précédemment. Ensuite, nous construisons la topologie de flux et initialisons un objet KafkaStreams avec cette topologie.
Pour démarrer le traitement du flux, nous devons créer un Thread dédié qui exécutera le flux tant que le serveur sera en vie. Selon la documentation officielle, il est toujours bon de cleanUp() le flux avant de le démarrer.
Notre PhotoStreamProcessor est prêt à être utilisé !?
API REST
Le serveur expose des API REST pour lui envoyer les informations sur les photos à stocker. Nous utilisons Akka HTTP pour l'implémentation de l'API.
trait AppRoutes extends SprayJsonSupport {
implicit def system: ActorSystem
implicit def photoDao: PhotoDao
implicit lazy val timeout = Timeout(5.seconds)
lazy val healthRoute: Route = pathPrefix("health") {
concat(
pathEnd {
concat(
get {
complete(StatusCodes.OK)
}
)
}
)
}
lazy val crudRoute: Route = pathPrefix("photo") {
concat(
pathEnd {
concat(
post {
entity(as[Photo]) { photo =>
val photoCreated: Future[String] =
photoDao.createPhoto(photo)
onSuccess(photoCreated) { id =>
complete((StatusCodes.Created, id))
}
}
}
)
}
)
}
}
Pour garder l'exemple minimal, nous n'avons que deux routes :
GET /health- pour vérifier si le serveur est opérationnelPOST /photo- pour envoyer au système leJSONdes informations sur la photo que nous voulons stocker. Ce point de terminaison utilise le DAO pour stocker le document dans MongoDB et retourne un201avec l'id de la photo stockée si l'opération a réussi.
Ce n'est en aucun cas un ensemble complet d'API, mais c'est suffisant pour exécuter notre exemple. ?
Classe principale du serveur
D'accord, nous avons implémenté tous les composants de notre serveur, il est donc temps de tout rassembler. Voici notre classe d'objet Server.scala.
implicit val system: ActorSystem = ActorSystem("kafka-stream-playground")
implicit val materializer: ActorMaterializer = ActorMaterializer()
D'abord, quelques valeurs utilitaires Akka. Puisque nous utilisons Akka HTTP pour exécuter notre serveur et notre API REST, ces valeurs implicites sont requises.
val config: Config = ConfigFactory.load()
val address = config.getString("http.ip")
val port = config.getInt("http.port")
val mongoUri = config.getString("mongo.uri")
val mongoDb = config.getString("mongo.db")
val mongoUser = config.getString("mongo.user")
val mongoPwd = config.getString("mongo.pwd")
val photoCollection = config.getString("mongo.photo_collection")
val kafkaHosts = config.getString("kafka.hosts").split(',').toList
val photoTopic = config.getString("kafka.photo_topic")
val longExposureTopic = config.getString("kafka.long_exposure_topic")
Ensuite, nous lisons toutes les propriétés de configuration. Nous reviendrons sur le fichier de configuration dans un instant.
val kafkaProps = new Properties()
kafkaProps.put("bootstrap.servers", kafkaHosts.mkString(","))
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
val streamProps = new Properties()
streamProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "long-exp-proc-app")
streamProps.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaHosts.mkString(","))
val photoProducer = PhotoProducer(kafkaProps, photoTopic)
val photoStreamProcessor = new PhotoStreamProcessor(kafkaProps, streamProps, photoTopic, "long-exposure")
photoStreamProcessor.start()
Nous devons configurer à la fois notre producteur Kafka et le processeur de flux. Nous démarrons également le processeur de flux, afin que le serveur soit prêt à traiter les documents qui lui sont envoyés.
val client = MongoClient(s"mongodb://$mongoUri/$mongoUser")
val db = client.getDatabase(mongoDb)
val photoDao: PhotoDao = new PhotoDao(db, photoCollection)
val photoListener = PhotoListener(photoDao.collection, photoProducer)
MongoDB doit également être configuré. Nous établissons la connexion et initialisons le DAO ainsi que l'écouteur.
lazy val routes: Route = healthRoute ~ crudRoute
Http().bindAndHandle(routes, address, port)
Await.result(system.whenTerminated, Duration.Inf)
Tout a été initialisé. Nous créons les routes REST pour la communication avec le serveur, les relions aux gestionnaires, et démarrons enfin le serveur !?
Configuration du serveur
Voici le fichier de configuration utilisé pour configurer le serveur :
http {
ip = "127.0.0.1"
ip = ${?SERVER_IP}
port = 8000
port = ${?SERVER_PORT}
}
mongo {
uri = "127.0.0.1:27017"
uri = ${?MONGO_URI}
db = "kafka-stream-playground"
user = "admin"
pwd = "admin"
photo_collection = "photo"
}
kafka {
hosts = "127.0.0.1:9092"
hosts = ${?KAFKA_HOSTS}
photo_topic = "photo"
long_exposure_topic = "long-exposure"
}
Je pense que celui-ci ne nécessite pas beaucoup d'explications, n'est-ce pas ? ?
Configuration des connecteurs
Le serveur que nous avons implémenté écrit dans deux sujets Kafka : photo et long-exposure. Mais comment les messages sont-ils écrits dans Elasticsearch en tant que documents ? En utilisant Kafka Connect !
Nous pouvons configurer deux connecteurs, un par sujet, et dire aux connecteurs d'écrire chaque message passant par ce sujet dans Elasticsearch.
Tout d'abord, nous avons besoin de Kafka Connect. Nous pouvons utiliser le conteneur fourni par Confluent dans le fichier docker-compose :
connect:
image: confluentinc/cp-kafka-connect
ports:
- 8083:8083
networks:
- kakfa_stream_playground
depends_on:
- zookeeper
- kafka
volumes:
- $PWD/connect-plugins:/connect-plugins
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:9092
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.storage.StringConverter"
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "false"
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_ZOOKEEPER_CONNECT: zookeeper:2181
CONNECT_PLUGIN_PATH: /connect-plugins
CONNECT_LOG4J_ROOT_LOGLEVEL: INFO
Je veux me concentrer sur certaines des valeurs de configuration.
Tout d'abord, nous devons exposer le port 8083 - qui sera notre point de terminaison pour configurer les connecteurs (CONNECT_REST_PORT).
Nous devons également mapper un volume au chemin /connect-plugins, où nous placerons le Elasticsearch Sink Connector pour écrire dans Elasticsearch. Cela est reflété également dans le CONNECT_PLUGIN_PATH.
Le conteneur connect doit savoir comment trouver les serveurs Kafka, donc nous définissons CONNECT_BOOTSTRAP_SERVERS comme kafka:9092.
Une fois que Kafka Connect est prêt, nous pouvons envoyer les configurations de nos connecteurs au point de terminaison http://localhost:8083/connectors. Nous avons besoin de 2 connecteurs, un pour le sujet photo et un pour le sujet long-exposure. Nous pouvons envoyer la configuration sous forme de JSON avec une requête POST.
{
"name": "photo-connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "photo",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"schema.ignore": "true",
"connection.url": "http://elastic:9200",
"type.name": "kafka-connect",
"behavior.on.malformed.documents": "warn",
"name": "photo-connector"
}
}
Nous disons explicitement que nous allons utiliser le ElasticsearchSinkConnector comme connector.class, ainsi que les topics que nous voulons envoyer - dans ce cas photo.
Nous ne voulons pas utiliser de schéma pour le value.converter, donc nous pouvons le désactiver (value.converter.schemas.enable) et dire au connecteur d'ignorer le schéma (schema.ignore).
Le connecteur pour le sujet long-exposure est exactement comme celui-ci. La seule différence est le name et bien sûr les topics.
Comment exécuter le projet
Nous avons tout ce dont nous avons besoin pour tester le CDC ! Comment pouvons-nous le faire ? C'est assez facile : il suffit d'exécuter le script setup.sh dans le dossier racine du dépôt !
Que fera le script ?
- Exécuter le fichier
docker-composeavec tous les services. - Configurer l'ensemble de réplicas MongoDB. Cela est nécessaire pour activer l'interface Change Stream afin de capturer les modifications de données. Plus d'informations à ce sujet ici.
- Configurer les connecteurs Kafka.
- Se connecter aux journaux du serveur.
Le docker-compose exécutera les services suivants :
- Notre serveur
- 3 instances de MongoDB (nécessaires pour l'ensemble de réplicas)
- Mongoku, un client MongoDB
- Kafka (nœud unique)
- Kafka connect
- Zookeeper (nécessaire par Kafka)
- Elasticsearch
- Kibana
Il y a beaucoup de conteneurs à exécuter, alors assurez-vous d'avoir suffisamment de ressources pour tout exécuter correctement. Si vous le souhaitez, supprimez Mongoku et Kibana du fichier compose, car ils sont utilisés uniquement pour un rapide coup d'œil à l'intérieur des bases de données.
Une fois que tout est opérationnel, vous n'avez plus qu'à envoyer des données au serveur.
J'ai collecté quelques documents JSON de photos provenant d'Unsplash que vous pouvez utiliser pour tester le système dans le fichier photos.txt.
Il y a un total de 10 documents, dont 5 contiennent des informations sur les photos en longue exposition. Envoyez-les au serveur en exécutant le script send-photos.sh à la racine du dépôt. Vérifiez que tout est stocké dans MongoDB en vous connectant à Mongoku à l'adresse http://localhost:3100. Ensuite, connectez-vous à Kibana à l'adresse http://localhost:5601 et vous trouverez deux index dans Elasticsearch : photo, contenant le JSON de toutes les photos stockées dans MongoDB, et long-exposure, contenant uniquement les informations des photos en longue exposition.
Incroyable, n'est-ce pas ? ?
Conclusion
Nous l'avons fait, les gars ! ?
En partant de la conception du cas d'utilisation, nous avons construit notre système qui a connecté une base de données MongoDB à Elasticsearch en utilisant le CDC.
Kafka Streams est l'élément clé, nous permettant de convertir les événements de la base de données en un flux que nous pouvons traiter.
Vous avez besoin de voir le projet complet ? Consultez simplement le dépôt sur GitHub ! ?
C'est tout, profitez-en ! ?