


Article original : How to Host Local LLMs in a Docker Container on Azure
Avez-vous déjà été confronté à une situation où vous souhaitez tester certains modèles d'IA locaux, mais votre ordinateur n'a pas les spécifications nécessaires pour les exécuter ? Ou peut-être que vous ne voulez tout simplement pas encombrer votre ordinateur avec une tonne de modèles d'IA ?
Vous n'êtes pas seul dans ce cas. J'ai rencontré ce problème exact, et j'ai pu le résoudre avec l'aide d'une VM de rechange. Donc, la seule chose dont vous aurez besoin est un PC de rechange quelque part que vous pouvez accéder.
Ici, j'utilise Azure, mais le processus devrait être assez simple pour les autres fournisseurs de cloud également. Même si vous avez un homelab avec votre ancien PC ou autre chose sur lequel vous pouvez vous connecter en SSH, la seule chose que vous devrez changer est les commandes qui traitent avec Azure. Tout le reste devrait fonctionner parfaitement.
Et le meilleur dans tout ça ? Nous allons tout faire à l'intérieur d'un conteneur Docker. Donc, si vous voulez un jour supprimer tous les modèles d'IA, il suffit de supprimer le conteneur, et c'est tout. Même votre VM n'ira pas installer quoi que ce soit localement, purement Docker ! \ud83d\udc4c
Dans cet article, je vais vous montrer comment héberger des LLMs locaux avec Ollama dans un conteneur Docker sur une machine virtuelle Azure.
Ce que vous allez apprendre : \ud83d\udc40
Comment utiliser Ollama pour exécuter plusieurs LLMs sur une seule machine.
Comment configurer les conteneurs
ollamaetollama-webuiavecdocker-compose.Comment créer une VM sur Azure et tout configurer en utilisant l'Azure CLI.
Comment restreindre l'accès à la VM Azure à votre IP publique en utilisant l'Azure CLI.
À la fin de l'article, vous aurez une VM Azure entièrement fonctionnelle capable d'exécuter tous vos modèles d'IA choisis (en fonction de ses spécifications, bien sûr).
Table des matières
Comment configurer l'environnement
\ud83d\udc81 Vous allez principalement écrire en Bash, alors assurez-vous de connaître quelques bases de script shell avant de continuer.
Créez un dossier pour garder tout votre code source pour le projet :
mkdir run-local-ai-models-docker-azure \
&& cd run-local-ai-models-docker-azure
mkdir azure scripts
Ici, le répertoire azure contiendra tous les scripts nécessaires pour travailler avec la VM Azure, et le répertoire scripts contiendra tout ce qui est nécessaire pour configurer la VM pour exécuter les LLMs.
Créez un nouveau fichier .env à la racine du projet avec les variables d'environnement suivantes. Assurez-vous de changer la taille, le nom, l'emplacement et les modèles comme vous le souhaitez.
RESOURCE_GROUP="ollama-vm-rg"
LOCATION="eastus"
VM_NAME="ollama-vm"
VM_SIZE="Standard_D2s_v3"
USERNAME="<votre-nom-utilisateur>"
# Cela sera utilisé comme sauvegarde lorsque nous ne pouvons pas récupérer l'IP
# depuis 'api.ipify.org'
IP_ADDRESS="<votre-adresse-ip>"
# Changez-le pour les modèles que vous préférez.
OLLAMA_DEFAULT_MODEL="qwen2.5-coder:3b"
# Assurez-vous d'utiliser "," lors de la séparation de plusieurs modèles.
OLLAMA_ADDITIONAL_MODELS="deepseek-r1:1.5b,tinyllama:1.1b"
WEBUI_PORT=3000
OLLAMA_PORT=11434
Et enfin, vous devez avoir Azure CLI installé. Suivez les instructions d'installation montrées ici pour l'installer localement sur votre machine.
Une fois installé, authentifiez le CLI avec votre compte Azure en utilisant la commande suivante :
az login
Une fois connecté, la configuration est complète et vous pouvez commencer à coder le projet. \ud83c\udf89
Comment configurer la machine virtuelle Azure
Dans cette section, je vais vous montrer comment configurer votre VM Azure en utilisant l'Azure CLI az. Vous allez tout faire, de la création d'un groupe de ressources séparé à la configuration du réseau pour permettre l'accès uniquement depuis votre adresse IP, et enfin, créer la VM.
Lors de la création d'un nouveau fichier pour cette section, assurez-vous de le faire dans le répertoire azure.
Créer un groupe de ressources
Tout d'abord, commencez par créer un nouveau groupe de ressources pour votre machine virtuelle. Mais qu'est-ce qu'un groupe de ressources ? En gros, un groupe de ressources est comme un conteneur qui contient des ressources connexes, telles que la VM, le stockage, les NSG et tout le reste. Il aide à organiser ces ressources rapidement, ce qui facilite leur déploiement, leur mise à jour et leur suppression en une seule fois. En bref, pensez simplement à cela comme un moyen de regrouper des éléments connexes.
Créez un nouveau fichier appelé create-resource-group.sh et ajoutez les lignes de code suivantes :
#!/usr/bin/env bash
set -e
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
PROJECT_ROOT="$(dirname "$SCRIPT_DIR")"
source "$PROJECT_ROOT/.env"
echo "Création du groupe de ressources '$RESOURCE_GROUP' dans l'emplacement '$LOCATION'..."
az group create --name $RESOURCE_GROUP --location $LOCATION
echo "Groupe de ressources créé avec succès."
Remarquez la commande set -e. En ajoutant cela, cela indique au script de s'arrêter si une étape provoque une erreur. Sans cela, le script continuerait à s'exécuter même si une étape échoue, ce qui entraînerait des erreurs. Retenez cette commande, car elle est dans tous les scripts que vous allez écrire.
Ensuite, il source le fichier .env pour accéder aux variables d'environnement. Après cela, il exécute la commande az pour créer un groupe de ressources avec le nom et l'emplacement donnés.
Maintenant, exécutez la commande suivante :
bash create-resource-group.sh
Pour vérifier si cela a fonctionné, allez dans votre compte Azure et regardez sous la section Groupes de ressources pour votre nouveau groupe de ressources.
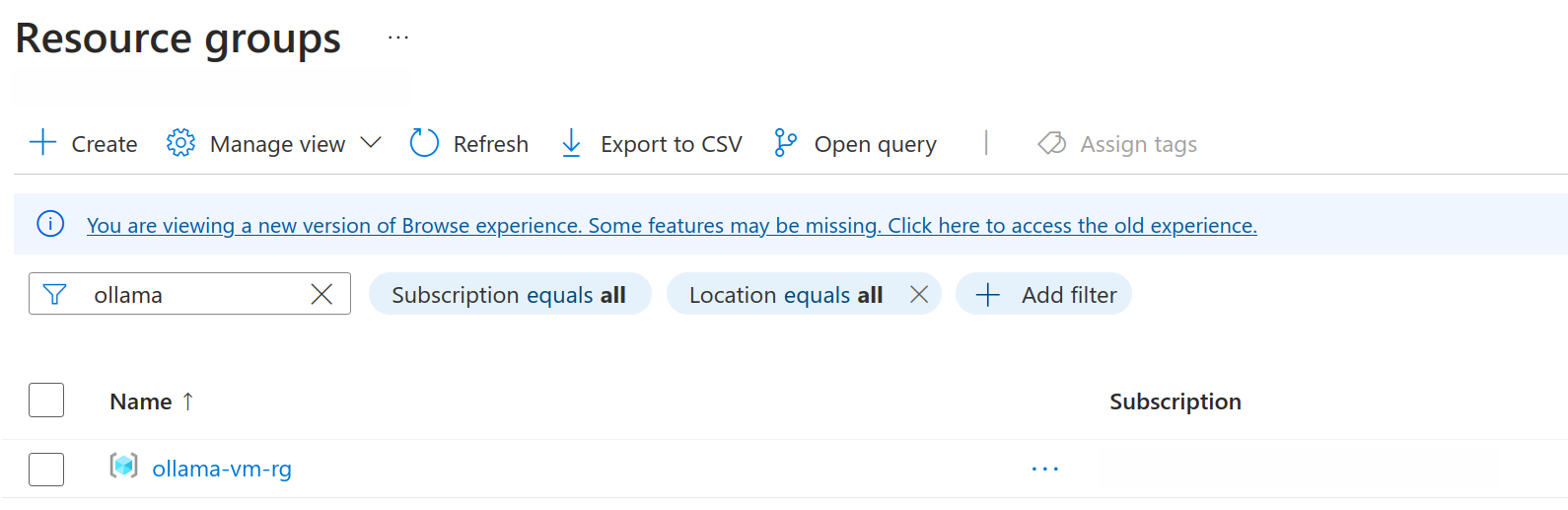
Si vous voyez votre groupe de ressources dans la liste, vous êtes prêt à continuer.
Créer la machine virtuelle
Maintenant que le groupe de ressources est créé, vous pouvez passer à la création de la machine virtuelle elle-même. Ce script sera également assez similaire au précédent.
Créez un nouveau fichier appelé create-vm.sh et ajoutez les lignes de code suivantes :
#!/usr/bin/env bash
set -e
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
PROJECT_ROOT="$(dirname "$SCRIPT_DIR")"
source "$PROJECT_ROOT/.env"
VM_EXISTS=$(az vm show --resource-group $RESOURCE_GROUP --name $VM_NAME --query "name" -o tsv 2>/dev/null || echo "")
if [ -n "$VM_EXISTS" ]; then
echo "La VM '$VM_NAME' existe déjà dans le groupe de ressources '$RESOURCE_GROUP'."
echo "Veuillez choisir un nom de VM différent ou utiliser la VM existante."
exit 1
fi
echo "Création de la VM '$VM_NAME'..."
az vm create \
--resource-group $RESOURCE_GROUP \
--name $VM_NAME \
--image Ubuntu2204 \
--admin-username $USERNAME \
--generate-ssh-keys \
--size $VM_SIZE \
--public-ip-sku Standard
# La commande ci-dessus génère la clé ssh sous le nom "id_rsa", si vous avez déjà
# une clé appelée id_rsa dans le répertoire ~/.ssh, assurez-vous de la renommer en autre chose
ssh-add ~/.ssh/id_rsa
echo "VM créée avec succès."
Tout d'abord, il vérifie si une VM avec le même nom existe déjà dans le groupe de ressources. Si ce n'est pas le cas, il crée une nouvelle VM, en fournissant des détails tels que la taille, l'image, le nom d'utilisateur, et en demandant de générer une clé SSH qu'il utilisera pour se connecter à la VM.
J'ai choisi Ubuntu parce que, dans une autre section où vous allez configurer Docker, j'ai utilisé des étapes Debian. Si vous souhaitez utiliser une autre distribution, assurez-vous de mettre à jour ce script également.
Maintenant, exécutez la commande suivante :
bash create-vm.sh
Après avoir exécuté la commande, sous la section VM, vous devriez voir votre VM nouvellement créée.
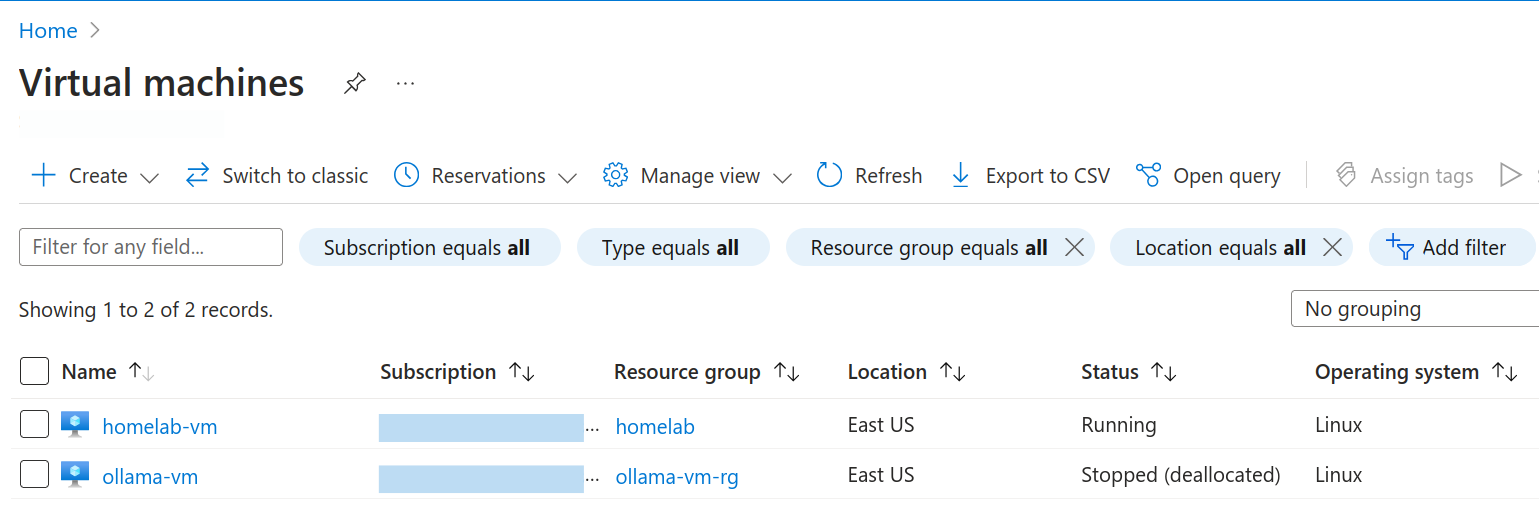
Voilà, la VM est opérationnelle. Vous pourriez manuellement accéder à la VM et la configurer, mais je vais vous montrer comment automatiser toutes ces étapes également, car nous sommes des développeurs, n'est-ce pas ? \ud83d\ude09
Obtenir l'IP publique de la machine virtuelle
Maintenant que vous avez créé la VM parfaitement, il est temps de récupérer l'IP publique de la VM afin que vous puissiez ensuite utiliser SSH pour vous connecter.
Créez un nouveau fichier appelé get-vm-details.sh et ajoutez les lignes de code suivantes :
#!/usr/bin/env bash
set -e
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
PROJECT_ROOT="$(dirname "$SCRIPT_DIR")"
source "$PROJECT_ROOT/.env"
echo "Récupération des détails de la VM..."
PUBLIC_IP=$(az vm show --resource-group $RESOURCE_GROUP --name $VM_NAME --show-details --query publicIps -o tsv)
if [ -z "$PUBLIC_IP" ]; then
echo "Erreur : Impossible de récupérer l'IP publique pour la VM '$VM_NAME'"
exit 1
fi
echo "IP publique de la VM : $PUBLIC_IP"
echo "Point de terminaison de l'API Ollama : http://$PUBLIC_IP:$OLLAMA_PORT"
echo "Interface Web : http://$PUBLIC_IP:$WEBUI_PORT"
echo "PUBLIC_IP=$PUBLIC_IP" > "$PROJECT_ROOT/.vm_details.env"
echo "Détails de la VM récupérés avec succès."
Tout ce qu'il fait, c'est sourcer le .env et utiliser la commande az pour récupérer l'IP publique de la VM et la stocker dans un fichier séparé appelé .vm_details.env. De cette façon, dans d'autres scripts, il n'a pas besoin de récupérer l'IP publique à plusieurs reprises et peut simplement sourcer le fichier pour y accéder.
Maintenant, exécutez la commande suivante :
bash get-vm-details.sh
Configurer le réseau de la VM pour permettre l'accès uniquement depuis l'IP de l'utilisateur
Maintenant que vous avez la VM en fonctionnement, il y a un léger problème de sécurité avec celle-ci. Si vous vérifiez les paramètres réseau de votre VM, vous verrez qu'il n'y a aucune restriction d'IP. Cela signifie que n'importe qui peut facilement essayer de se connecter en SSH à votre VM.

Permettre l'accès depuis n'importe quelle adresse IP source n'est définitivement pas une bonne idée. Vous devez configurer cela pour permettre l'accès uniquement depuis votre IP publique, et vous devez également configurer le port pour ollama et ollama-webui.
Créez un nouveau fichier appelé configure-network.sh et ajoutez les lignes de code suivantes :
#!/usr/bin/env bash
set -e
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
PROJECT_ROOT="$(dirname "$SCRIPT_DIR")"
source "$PROJECT_ROOT/.env"
echo "Configuration de la sécurité du réseau..."
# Obtenir l'adresse IP publique actuelle avec une sauvegarde sur celle du .env.
echo "Récupération de l'adresse IP publique actuelle..."
IP_ADDRESS_CURRENT=$(curl -s https://api.ipify.org || echo "")
if [ -z "$IP_ADDRESS_CURRENT" ]; then
echo "Avertissement : Impossible de récupérer l'IP depuis api.ipify.org, utilisation de la valeur .env"
IP_ADDRESS_CURRENT=$IP_ADDRESS
fi
echo "Utilisation de l'adresse IP : $IP_ADDRESS_CURRENT"
NSG_NAME=$(az network nsg list --resource-group $RESOURCE_GROUP --query "[?contains(name, '${VM_NAME}')].name" -o tsv)
if [ -z "$NSG_NAME" ]; then
echo "Erreur : Impossible de trouver le NSG pour la VM '$VM_NAME'"
exit 1
fi
create_or_update_nsg_rule() {
local RULE_NAME=$1
local PORT=$2
local PRIORITY=$3
RULE_EXISTS=$(az network nsg rule list --resource-group $RESOURCE_GROUP --nsg-name $NSG_NAME --query "[?name=='$RULE_NAME'].name" -o tsv)
if [ -z "$RULE_EXISTS" ]; then
echo "Création de la nouvelle règle : $RULE_NAME pour le port $PORT..."
az network nsg rule create --resource-group $RESOURCE_GROUP --nsg-name $NSG_NAME \
--name "$RULE_NAME" \
--protocol tcp --direction inbound --priority $PRIORITY \
--source-address-prefix $IP_ADDRESS_CURRENT --source-port-range "*" \
--destination-address-prefix "*" --destination-port-range $PORT \
--access allow
else
echo "Mise à jour de la règle existante : $RULE_NAME avec la nouvelle adresse IP..."
az network nsg rule update --resource-group $RESOURCE_GROUP --nsg-name $NSG_NAME \
--name "$RULE_NAME" \
--source-address-prefix $IP_ADDRESS_CURRENT
fi
}
# Vérifier si 'default-allow-ssh' existe
SSH_RULE_EXISTS=$(az network nsg rule list --resource-group $RESOURCE_GROUP --nsg-name $NSG_NAME --query "[?name=='default-allow-ssh'].name" -o tsv)
if [ -n "$SSH_RULE_EXISTS" ]; then
echo "Mise à jour de la règle SSH existante (default-allow-ssh) avec une IP restreinte..."
az network nsg rule update --resource-group $RESOURCE_GROUP --nsg-name $NSG_NAME \
--name "default-allow-ssh" \
--source-address-prefix $IP_ADDRESS_CURRENT
else
# Si aucune règle SSH par défaut, créer la nôtre avec une priorité différente
create_or_update_nsg_rule "SSH_Restricted" 22 1010
fi
# Configurer les règles pour Ollama et l'interface Web
echo "Ouverture des ports pour l'API Ollama et l'interface Web (restreinte à votre IP)..."
create_or_update_nsg_rule "Port_${OLLAMA_PORT}_Restricted" $OLLAMA_PORT 1001
create_or_update_nsg_rule "Port_${WEBUI_PORT}_Restricted" $WEBUI_PORT 1002
echo "Sécurité du réseau configurée avec succès."
echo "Remarque : Si votre adresse IP change, vous devrez exécuter ce script à nouveau pour mettre à jour les règles."
Ne soyez pas effrayé par ce script. Il peut sembler complexe, mais il est en réalité assez simple. La première chose qu'il fait est d'essayer d'obtenir l'adresse IP de l'utilisateur. Il tente d'abord de récupérer l'IP de l'utilisateur depuis un service appelé api.ipify.org (car les IP publiques peuvent changer fréquemment), qui retourne votre IP publique actuelle. Si une erreur survient, il utilise l'adresse IP stockée dans le fichier .env.
Ensuite, il essaie d'obtenir le NSG (Network Security Group) de la VM car il est nécessaire lors de la création d'une nouvelle règle NSG. Si une erreur survient, il n'y a aucun intérêt à continuer avec le script, donc il quitte avec un statut d'erreur.
Il y a aussi une fonction appelée create_or_update_nsg_rule, qui est utilisée pour créer une nouvelle règle NSG si elle n'existe pas. Si elle existe, elle la met simplement à jour pour permettre l'accès uniquement depuis l'adresse IP de l'utilisateur.
Enfin, il crée ou met à jour la règle SSH en fonction de son existence. Il configure également les règles pour ollama et ollama-webui afin que vous puissiez accéder au port exposé sur votre machine locale pour tester les modèles avec ollama-webui.
Maintenant, exécutez la commande suivante :
bash configure-network.sh
Après avoir exécuté cette commande, vous pouvez voir les paramètres réseau modifiés. Il devrait y avoir deux nouvelles règles pour le port 11434 et 3000, et surtout, vous devriez voir que l'IP source est limitée à votre IP publique.

Toute la configuration côté Azure est maintenant terminée. Tout ce que vous devez faire ensuite est d'écrire quelques scripts supplémentaires pour configurer l'exécution des modèles d'IA sur votre VM configurée. \u270c\ufe0f
Comment configurer la VM pour exécuter des modèles d'IA
Maintenant que toute la configuration côté Azure est terminée, dans cette section, je vais vous montrer comment vous pouvez tout configurer côté VM, de l'installation de Docker à la configuration des conteneurs, et au déploiement de ces conteneurs dans la VM Azure que vous venez de créer.
Lors de la création d'un nouveau fichier pour cette section, assurez-vous de le faire dans le répertoire scripts, sauf pour le fichier docker-compose.yaml.
Configurer la machine virtuelle
D'accord, maintenant que vous avez une VM opérationnelle avec certains paramètres réseau configurés, configurons cette machine pour installer et configurer Docker et démarrer le service.
Créez un nouveau fichier appelé setup-vm.sh et ajoutez les lignes de code suivantes :
#!/usr/bin/env bash
set -e
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
PROJECT_ROOT="$(dirname "$SCRIPT_DIR")"
source "$PROJECT_ROOT/.env"
source "$PROJECT_ROOT/.vm_details.env"
echo "Configuration de la VM avec Docker et les dépendances..."
ssh $USERNAME@$PUBLIC_IP << 'EOF'
# Installer le moteur Docker
echo "Installation de Docker..."
# Depuis la documentation Docker pour les distributions basées sur Debian
# Ajouter la clé GPG officielle de Docker :
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Fin des instructions d'installation de Docker pour Debian
sudo usermod -aG docker $USER
sudo apt-get install -y docker-compose
sudo systemctl start docker.service
sudo docker volume create ollama_data
# Ici, nous placerons notre fichier docker-compose.yaml
mkdir -p ~/ollama-project
EOF
echo "Configuration de la VM terminée avec succès."
Et comme je l'ai dit plus tôt, dans cet exemple, j'utilise Ubuntu, donc je suis les instructions Debian pour installer Docker. Si vous utilisez une autre distribution, assurez-vous de changer les commandes de configuration de Docker. Ensuite, il crée simplement un volume Docker car vous voudrez persister l'état du conteneur et ne pas le perdre à chaque fois.
Maintenant, exécutez la commande suivante :
bash setup-vm.sh
Si tout se passe bien, vous devriez avoir le moteur Docker installé sur votre machine. Vous pouvez le vérifier avec la commande suivante :
ssh <YOUR_VM_USERNAME>@<YOUR_VM_PUBLIC_IP> << 'EOF'
docker --version
EOF
Configurer Docker Compose
Créez un nouveau fichier appelé docker-compose.yaml à la racine du projet – pas dans le répertoire scripts cette fois – et ajoutez les lignes de code suivantes :
version: "3.9"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- ~/ollama_data:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
restart: unless-stopped
ollama-webui:
image: ghcr.io/ollama-webui/ollama-webui:main
container_name: ollama-webui
ports:
- "${WEBUI_PORT:-3000}:8080"
environment:
- OLLAMA_API_BASE_URL=http://ollama:11434/api
depends_on:
- ollama
restart: unless-stopped
Le fichier Docker Compose devrait être assez simple à comprendre. Il configure deux services, ou plutôt deux conteneurs : ollama et ollama-webui. Vous devez exposer le port du conteneur afin de pouvoir y accéder dans la VM, dont le port est déjà exposé lors de la configuration du réseau de la VM, vous permettant d'y accéder sur votre machine locale. Enfin, il spécifie les volumes Docker et quelques variables d'environnement, et c'est tout.
Pour le conteneur ollama-webui, il est nécessaire que le service ollama soit opérationnel en premier, donc il dépend du conteneur ollama. Après tout, à quoi bon démarrer l'interface utilisateur si le service lui-même ne fonctionne pas, n'est-ce pas ?
Déployer les conteneurs
Maintenant que Docker est installé sur la VM, il est temps de copier le fichier docker-compose.yaml dans la VM et de démarrer les conteneurs.
Créez un nouveau fichier appelé deploy-containers.sh et ajoutez les lignes de code suivantes :
#!/usr/bin/env bash
set -e
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
PROJECT_ROOT="$(dirname "$SCRIPT_DIR")"
source "$PROJECT_ROOT/.env"
source "$PROJECT_ROOT/.vm_details.env"
echo "Déploiement des conteneurs Docker sur la VM..."
scp "$PROJECT_ROOT/docker-compose.yaml" $USERNAME@$PUBLIC_IP:~/ollama-project/
ssh $USERNAME@$PUBLIC_IP << 'EOF'
cd ~/ollama-project
export WEBUI_PORT=3000
sudo docker-compose up -d
echo "Conteneurs Docker démarrés avec succès."
EOF
echo "Déploiement terminé avec succès."
echo "Interface Web disponible à l'adresse : http://$PUBLIC_IP:$WEBUI_PORT"
C'est assez simple ici aussi. Tout d'abord, il copie le fichier docker-compose dans le répertoire ~/ollama-project, puis démarre le conteneur en mode détaché.
Maintenant, le moment de vérité. Exécutez la commande suivante, et si tout se passe bien, vous devriez avoir deux conteneurs Docker en cours d'exécution dans votre VM.
bash deploy-containers.sh
Pour voir si cela a fonctionné, exécutez la commande suivante pour vous connecter en ssh à la VM et exécuter la commande docker ps.
ssh <YOUR_VM_USERNAME>@<YOUR_VM_PUBLIC_IP> << 'EOF'
docker ps
EOF
Avec une sortie SSH, vous devriez voir quelque chose comme ceci, et si le statut des deux conteneurs indique Up, tout est bon.
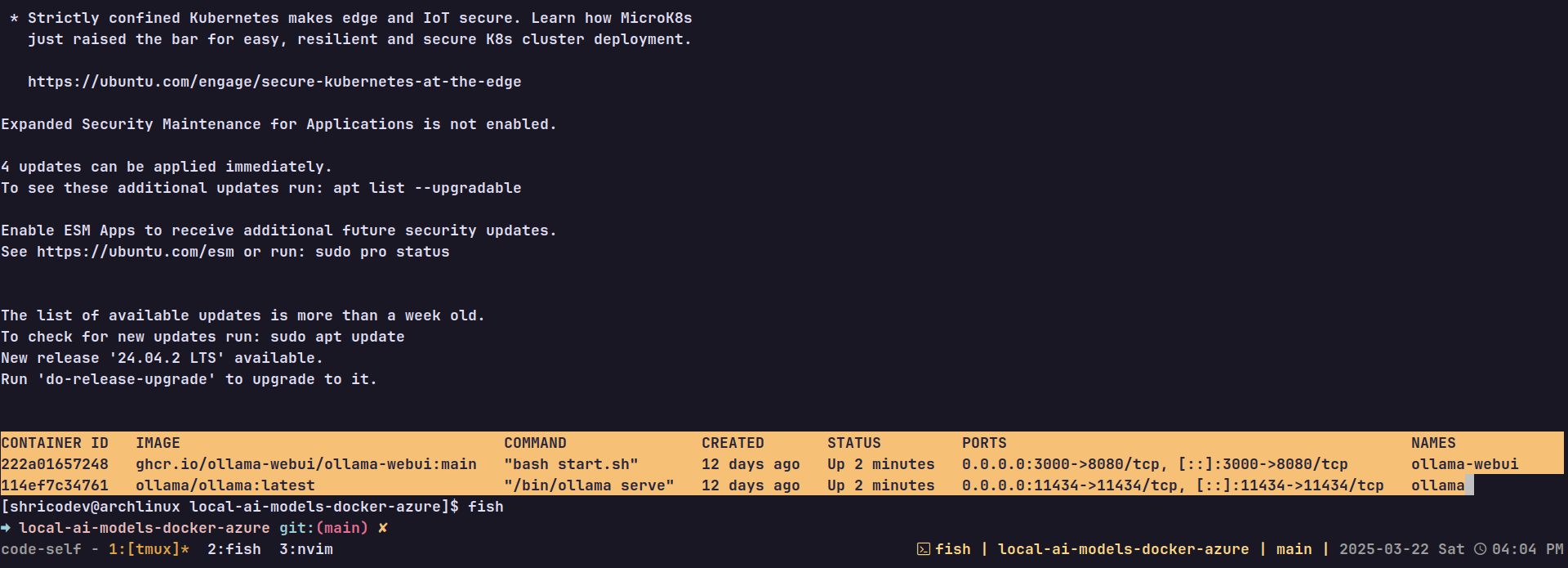
À ce stade, vous devriez pouvoir visiter cette URL (http://<VM_PUBLIC_IP>:3000) pour voir l'interface Web en cours d'exécution. Mais il n'y a pas de modèles d'IA avec lesquels discuter, alors corrigeons cela.

Exécuter les LLMs localement à l'intérieur du conteneur Docker
Vous y êtes presque. Il ne reste plus qu'à installer quelques modèles dans Ollama. Pour installer un modèle, tout ce que vous avez à faire est ollama run <MODEL_NAME>. Alors, faisons cela dans un script qui exécute cette commande à l'intérieur d'un conteneur Docker, car rappelez-vous que vous avez Ollama qui s'exécute dans un conteneur Docker.
\ud83d\udca1 BON À SAVOIR : Vous pouvez exécuter n'importe quelle commande à l'intérieur d'un conteneur Docker depuis l'extérieur en utilisant docker exec <CONTAINER_NAME> <COMMAND>. C'est parfait pour notre situation car il n'est pas nécessaire d'être à l'intérieur du conteneur Docker. Vous avez juste besoin d'exécuter une commande, et c'est tout.
Créez un nouveau fichier appelé run-models.sh et ajoutez les lignes de code suivantes :
#!/usr/bin/env bash
set -e
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
PROJECT_ROOT="$(dirname "$SCRIPT_DIR")"
source "$PROJECT_ROOT/.env"
source "$PROJECT_ROOT/.vm_details.env"
if [ -n "$OLLAMA_DEFAULT_MODEL" ]; then
echo "Exécution du modèle par défaut $OLLAMA_DEFAULT_MODEL..."
ssh $USERNAME@$PUBLIC_IP << EOF
sudo docker exec ollama ollama run $OLLAMA_DEFAULT_MODEL
EOF
echo "Modèle par défaut $OLLAMA_DEFAULT_MODEL exécuté avec succès."
fi
if [ -n "$OLLAMA_ADDITIONAL_MODELS" ]; then
echo "Modèles supplémentaires $OLLAMA_ADDITIONAL_MODELS..."
IFS=',' read -ra MODELS <<< "$OLLAMA_ADDITIONAL_MODELS"
for MODEL in "${MODELS[@]}"; do
# Supprimer les espaces
MODEL=$(echo "$MODEL" | xargs)
echo "Exécution du modèle supplémentaire $MODEL..."
ssh $USERNAME@$PUBLIC_IP << EOF
sudo docker exec ollama ollama run $MODEL
EOF
echo "Modèle supplémentaire $MODEL exécuté avec succès."
done
fi
echo "Tous les modèles ont été traités avec succès."
Tout ce que fait ce script, c'est d'abord vérifier si le modèle par défaut est configuré dans l'environnement avec OLLAMA_DEFAULT_MODEL. Si c'est le cas, le script l'exécute et exécute également tous les autres modèles séparés par des virgules dans la variable d'environnement OLLAMA_ADDITIONAL_MODELS.
Maintenant, exécutez la commande suivante :
bash run-models.sh
Si tout se passe bien et que vous voyez le message echo final, alors hourra ! \ud83c\udf89 Vous avez réussi à configurer l'exécution de LLMs à l'intérieur d'un conteneur Docker dans une VM Azure.
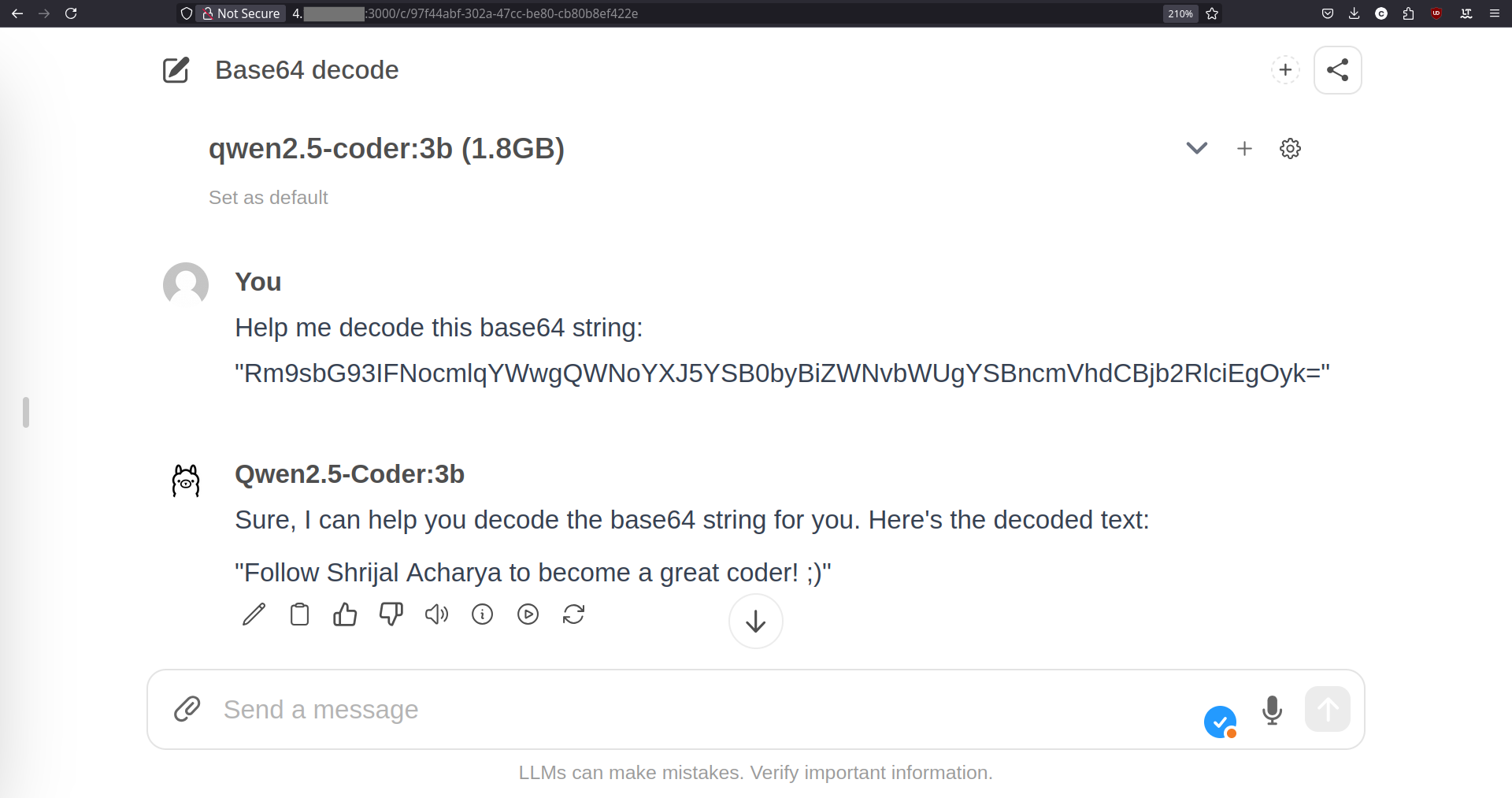
Allez-y et actualisez l'interface Web, et vous devriez voir tous vos LLMs apparaître dans la liste des modèles disponibles. Choisissez celui que vous préférez et commencez à discuter ! \ud83d\udd25
Conclusion
C'est tout pour celui-ci. J'espère que vous l'avez apprécié et, mieux encore, que vous avez tout compris ce que nous avons fait ensemble. Je construis ce genre de choses toutes les deux semaines et je les documente avec des blogs. N'hésitez pas à consulter certains de mes tutoriels précédents sur DEV et freeCodeCamp.
Vous pouvez trouver le code source complet ici.
Et hé, si vous êtes d'accord avec la réponse du modèle qwen2.5-coder ci-dessus, voici mes réseaux sociaux \ud83d\ude09 :
GitHub : github.com/shricodev
Portfolio : techwithshrijal.com
LinkedIn : linkedin.com/in/iamshrijal