


Article original : How to Handle Errors in Computer Networks
Il y a des choses magiques à propos d'Internet, et une chose en particulier est qu'il fonctionne. Malgré tant d'obstacles, nous pouvons livrer nos paquets à travers le globe, et le faire rapidement.
Plus spécifiquement, une chose amazing à propos d'Internet est sa capacité à gérer les erreurs.
Que veux-je dire par erreurs ? Lorsqu'un paquet ou une trame est reçu par une machine, nous disons qu'il contient une erreur si les données qui ont été envoyées ne sont pas les données qui ont été reçues. Par exemple, un seul 1 a été reçu par erreur comme un 0 après sa transmission.
Cela peut se produire pour de nombreuses raisons différentes. Peut-être qu'il y a eu une perturbation dans le fil où les données ont été transmises - disons, un enfant a roulé à vélo sur le fil. Peut-être qu'il y a eu une collision dans l'air car beaucoup de gens ont transmis en même temps. Peut-être que c'était une erreur de l'appareil.
Quelle que soit la raison spécifique, vous obtenez toujours des données valides sur Internet. Sans gérer les erreurs, vous pourriez lire la dernière phrase et au lieu de errors lire errbbb. Bizarre, n'est-ce pas ? Alors, comment Internet gère-t-il les erreurs ?
Il existe deux approches principales pour gérer les erreurs - la détection et la correction. Nous commencerons par décrire la détection, puis nous parlerons de la correction.
Qu'est-ce que la détection d'erreurs ?
Lorsqu'on traite de la détection d'erreurs, nous cherchons un résultat booléen - True ou False. La trame/le paquet est-il valide ou non. C'est tout. Nous ne voulons pas savoir où l'erreur s'est produite. Si la trame est invalide, nous la supprimerons simplement.
Ainsi, lorsque le récepteur reçoit une trame, il déterminera si une erreur s'est produite. Si la trame est valide, il la lira. Si la trame contient des erreurs - le récepteur la supprimera.
 _Détection d'erreurs : nous voulons seulement savoir si la trame/le paquet est valide ou non. (Source : Brief)_
_Détection d'erreurs : nous voulons seulement savoir si la trame/le paquet est valide ou non. (Source : Brief)_
Une méthode de détection d'erreurs consiste à utiliser une somme de contrôle. Une implémentation courante d'une somme de contrôle est appelée CRC - Cyclic Redundancy Check.
Dans cet article, nous ne nous préoccuperons pas de l'implémentation mathématique des CRCs dans le monde réel (si vous êtes intéressé, consultez Wikipedia). Plutôt, nous essaierons simplement de comprendre le concept. Pour ce faire, implémentons nous-mêmes un mécanisme de somme de contrôle très simple.
Considérons un protocole pour transmettre des numéros de téléphone à 10 chiffres entre des points d'extrémité. Ce protocole est extrêmement simple : chaque paquet contient exactement 10 octets, chacun représentant un chiffre. Par exemple, un paquet pourrait contenir les chiffres suivants :
5551234567
 _Un paquet avec une charge utile de 10 chiffres (Source : Brief)_
_Un paquet avec une charge utile de 10 chiffres (Source : Brief)_
Pour simplifier, nous omettons les en-têtes du paquet et nous concentrons uniquement sur la charge utile.
Maintenant, nous allons ajouter une somme de contrôle. Disons que nous additionnons tous les chiffres. Donc dans cet exemple, nous calculerions 5 + 5 + 5 + 1 + ... jusqu'à 7. Nous obtiendrions 43. Ce serait notre valeur de somme de contrôle.
Maintenant, l'expéditeur n'enverra pas seulement le numéro de téléphone, mais aussi la valeur de la somme de contrôle juste après. Dans cet exemple, l'expéditeur enverrait :
 _Les données du paquet sont suivies d'une somme de contrôle. (Source : Brief)_
_Les données du paquet sont suivies d'une somme de contrôle. (Source : Brief)_
Maintenant, en tant que récepteur, vous pouvez faire la même chose. Vous lirez le numéro de téléphone et calculerez la somme de contrôle. Vous additionnerez les chiffres et obtiendrez 43.
Puisque vous avez reçu le résultat correct (c'est-à-dire que votre calcul basé sur les données correspond à la valeur de la somme de contrôle envoyée dans le paquet), vous pouvez supposer que la trame est valide.
 _L'expéditeur compare leur valeur de somme de contrôle calculée et la somme de contrôle dans le paquet. Si les valeurs correspondent, le paquet est supposé être valide (Source : Brief)_
_L'expéditeur compare leur valeur de somme de contrôle calculée et la somme de contrôle dans le paquet. Si les valeurs correspondent, le paquet est supposé être valide (Source : Brief)_
Que se passe-t-il en cas d'erreur ? 🤔
Disons, par exemple, que le chiffre 2 a été remplacé par un 8. Maintenant, même si l'expéditeur a envoyé le même flux qu'avant (555123456743), vous, en tant que récepteur, voyez quelque chose un peu différent :
 _Un paquet contenant une erreur (Source : Brief)_
_Un paquet contenant une erreur (Source : Brief)_
Maintenant, vous calculez la somme de contrôle, en additionnant tous les chiffres. Vous obtenez 49. Puisque cette valeur est différente de la valeur de la somme de contrôle spécifiée dans la trame originale, 43, la trame est considérée comme invalide et vous la supprimez.
 _L'expéditeur compare leur valeur de somme de contrôle calculée et la somme de contrôle dans le paquet. Si les valeurs ne correspondent pas, le paquet est supposé être invalide (Source : Brief)_
_L'expéditeur compare leur valeur de somme de contrôle calculée et la somme de contrôle dans le paquet. Si les valeurs ne correspondent pas, le paquet est supposé être invalide (Source : Brief)_
Y a-t-il des problèmes avec cette méthode ? 🤔
Oui, il y en a. Considérez, par exemple, ce qui se passe s'il y a deux erreurs - et au lieu du flux original (555123456743), vous recevez ce qui suit :
 _Un paquet reçu avec deux erreurs, résultant en le flux
_Un paquet reçu avec deux erreurs, résultant en le flux 456123456743 (Source : Brief)_
Que se passe-t-il lorsque vous additionnez les chiffres ?
Même si les chiffres ne sont pas les mêmes que ceux du paquet original, la somme de contrôle restera correcte, et la trame sera considérée comme valide.
 _Malgré les erreurs, la valeur de la somme de contrôle se trouve être correcte, résultant en une fausse supposition que le paquet est valide (Source : Brief)_
_Malgré les erreurs, la valeur de la somme de contrôle se trouve être correcte, résultant en une fausse supposition que le paquet est valide (Source : Brief)_
Les fonctions de somme de contrôle réelles, telles que les CRCs, sont bien sûr beaucoup mieux implémentées que celle de notre exemple - mais dans des cas extrêmement rares, de tels problèmes peuvent survenir.
Remarquez qu'en utilisant ce type de méthode, la détection d'erreurs, nous ne savons pas où le problème s'est produit, mais seulement si la trame est valide ou non. Si la valeur de la somme de contrôle est invalide, nous supposons que la trame est invalide et nous la supprimons.
Qu'est-ce que la correction d'erreurs ?
Comme mentionné précédemment, la détection n'est pas la seule façon de gérer les erreurs. Une autre approche pourrait être de trouver l'erreur et de la corriger. Comment pouvons-nous faire cela ?
Une façon extrêmement simple serait de transmettre les données plusieurs fois - disons, trois fois. Par exemple, le flux 5551234567 serait transmis comme suit :
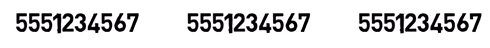 _Envoyer les mêmes données plusieurs fois (Source : Brief)_
_Envoyer les mêmes données plusieurs fois (Source : Brief)_
Donc, nous avons essentiellement envoyé les données trois fois.
Maintenant, en cas d'erreur sur un chiffre, le récepteur peut regarder les deux autres chiffres et choisir celui qui apparaît deux fois sur trois.
Ainsi, par exemple, si nous avions un problème et que 2 était remplacé par un 8, le récepteur recevrait ce flux :
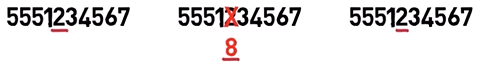 _Une erreur dans l'une des occurrences des données (Source : Brief)_
_Une erreur dans l'une des occurrences des données (Source : Brief)_
Maintenant, en tant que récepteur, vous pouvez dire : « J'ai 2, 8, 2... donc c'était probablement 2 dans le message original ».
Cela pose-t-il problème ? Eh bien, dans certains cas rares, nous pourrions obtenir la même erreur deux fois. Il est donc possible, bien que peu probable, que deux des deux originaux aient été reçus comme des huit.
Ainsi, alors que l'expéditeur a envoyé ce flux :
_Envoyer les mêmes données plusieurs fois (Source : Brief)_
Le premier 2 a été lu par erreur comme un 8, et aussi le deuxième 2 a été reçu comme un 8 :
 _Deux erreurs identiques ; Rares, mais possibles (Source : Brief)_
_Deux erreurs identiques ; Rares, mais possibles (Source : Brief)_
Maintenant, il semble que le message original comprenait un 8, et non un 2.
Que pouvez-vous faire pour réduire la probabilité d'un tel scénario ?
La solution la plus simple serait d'envoyer les données encore plus de fois. Disons, cinq fois. Donc maintenant, nous dupliquons toutes les données et les envoyons 5 fois au total...
 _Envoyer les données cinq (!) fois (Source : Brief)_
_Envoyer les données cinq (!) fois (Source : Brief)_
Maintenant, disons que deux erreurs se sont produites, et encore une fois deux des chiffres 2 ont été remplacés par des 8.
 _Deux erreurs identiques ; Rares, mais possibles (Source : Brief)_
_Deux erreurs identiques ; Rares, mais possibles (Source : Brief)_
Clairement, il est très improbable d'obtenir la même erreur deux fois, mais même dans ce cas, nous avons toujours 2 trois fois, donc en tant que récepteur, vous pouvez dire, avec une forte probabilité, que le message original contenait un 2, plutôt qu'un 8.
Quel est le surcoût ?
Maintenant serait un bon moment pour introduire le terme surcoût. Lorsque nous parlons de surcoût, nous voulons essentiellement dire les données ou le temps nécessaires pour transmettre le message réel. Commençons par comprendre ce que signifie ce terme en général, puis considérons-le dans le contexte de la gestion des erreurs.
Disons que j'ai une leçon à enseigner dans mon université. Mon objectif est d'enseigner la leçon elle-même, qui est également appelée la charge utile dans ce contexte - c'est-à-dire les données ou le message réel que je souhaite transmettre.
Pour enseigner la leçon, ou pour transmettre la charge utile, je dois d'abord me rendre physiquement à l'université - donc je sors de chez moi, marche jusqu'à la station de bus, attends le bus, prends le bus, descends du bus, marche jusqu'au bâtiment, attends que la leçon commence - et seulement alors je commence réellement à enseigner la leçon.
Ce processus entier est un surcoût que je dois payer pour livrer la charge utile, dans ce cas - pour enseigner la leçon.
 _Surcoût et charge utile sont deux termes extrêmement importants dans les réseaux informatiques (Source : Brief)_
_Surcoût et charge utile sont deux termes extrêmement importants dans les réseaux informatiques (Source : Brief)_
La même chose s'applique dans les réseaux informatiques. Notre charge utile est les données, et il y a toujours un certain surcoût associé à leur envoi.
Retour à la gestion des erreurs
Dans le contexte ici - envoyer les données trois fois, comme suggéré précédemment, signifie que pour chaque octet de charge utile, nous avons deux octets de surcoût. Si nous envoyons les données cinq fois, alors pour chaque octet de charge utile, nous avons quatre octets de surcoût. C'est BEAUCOUP !
Considérez la détection d'erreurs, en revanche. Dans notre exemple de protocole pour envoyer des numéros de téléphone, combien de surcoût avions-nous ?
Rappelons que pour chaque numéro de téléphone à 10 chiffres, c'est-à-dire dix octets, nous avons inclus une valeur de somme de contrôle à deux chiffres. En d'autres termes, nous avions deux octets de surcoût pour dix octets de charge utile. Il est clair que dans notre exemple, la détection d'erreurs donne un surcoût beaucoup plus petit par rapport à la correction d'erreurs.
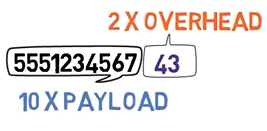 _Dans le protocole d'exemple, pour chaque numéro de téléphone à 10 chiffres (dix octets de charge utile), nous avons inclus une valeur de somme de contrôle à deux chiffres (deux octets de surcoût) (Source : Brief)_
_Dans le protocole d'exemple, pour chaque numéro de téléphone à 10 chiffres (dix octets de charge utile), nous avons inclus une valeur de somme de contrôle à deux chiffres (deux octets de surcoût) (Source : Brief)_
Il existe de meilleures façons d'atteindre la correction d'erreurs avec une grande précision que d'envoyer simplement les données autant de fois, mais elles sont plus compliquées et hors de portée pour cet article. Même avec des techniques de correction d'erreurs très compliquées, elles nécessitent encore beaucoup de surcoût par rapport à la détection d'erreurs.
De plus, remarquez qu'à l'exception des octets envoyés en tant que surcoût en cas de correction d'erreurs, la détection d'erreurs est beaucoup plus simple.
Correction d'erreurs vs Détection d'erreurs - Quelle est la meilleure ?
Nous avons déjà conclu que la détection d'erreurs est plus simple et avec une charge utile plus petite par rapport à la correction d'erreurs.
Alors, quand préférerions-nous la correction d'erreurs ?
Un cas pourrait être lorsque nous avons une liaison unidirectionnelle. C'est-à-dire, un réseau où nous ne pouvons transférer des données que dans une seule direction.
Par exemple, disons que vous avez un agent secret auquel vous devez envoyer un message. L'agent sait qu'il doit regarder le ciel exactement à minuit, et il verra une série d'éclairs indiquant le message secret.
L'agent secret ne peut pas répondre, ou son emplacement et son identité seront révélés. De plus, vous ne voulez pas envoyer le message encore et encore, pour ne pas attirer trop d'attention et pour rendre plus difficile pour quelqu'un d'intercepter le message.
Dans ce cas, vous voulez définitivement que votre agent reçoive le message exact que vous avez envoyé. Considérez un cas où vous voulez lui envoyer le message « ne placez pas la bombe ».
 _Un message sensible pour un agent secret (Source : Brief)_
_Un message sensible pour un agent secret (Source : Brief)_
Bien sûr, vous ne voulez pas risquer le scénario malheureux où l'agent lit le message comme « placez la bombe maintenant », à cause d'une erreur.
 _Une erreur peut changer le sens du message de manière substantielle (Source : Brief)_
_Une erreur peut changer le sens du message de manière substantielle (Source : Brief)_
Si vous utilisez la détection d'erreurs, l'agent pourrait être conscient que le message qu'il a reçu est invalide en cas d'erreur, mais il ne pourra pas vous dire qu'il a besoin que vous envoyiez à nouveau le message. Comme vous voulez que l'agent puisse lire votre message correctement et sans envoyer de données en retour, la correction d'erreurs est préférée.
Ainsi, une liaison unidirectionnelle est un cas où nous préférons la correction d'erreurs. Qu'en est-il des autres cas ?
Parfois, vous ne pouvez tout simplement pas envoyer les données à nouveau, peut-être parce qu'elles ont été effacées de la mémoire de votre machine. C'est-à-dire que les données sont supprimées juste après avoir été envoyées. Dans ce cas, vous préféreriez clairement la correction d'erreurs, car envoyer les données à nouveau, comme nous le ferions avec la détection d'erreurs, est tout simplement impossible.
De plus, si l'envoi des données à nouveau est possible, mais extrêmement coûteux, la correction d'erreurs peut être préférable.
Par exemple, si vous envoyez un message sur la lune, disons, avec un vaisseau spatial - il pourrait être vraiment coûteux de l'envoyer à nouveau en cas d'erreur. En utilisant la correction d'erreurs, vous envoyez les données une seule fois et le récepteur devrait être en mesure de les traiter, même si une erreur s'est produite.
 _Cas où la correction est préférée (Source : Brief)_
_Cas où la correction est préférée (Source : Brief)_
En général, nous préférons la correction d'erreurs lorsque la retransmission des données est coûteuse ou impossible.
Quand préférerions-nous la détection d'erreurs ?
Eh bien, dans le cas où nous pouvons retransmettre les données, nous préférons généralement la détection d'erreurs car elle s'accompagne de très peu de surcoût par rapport à la correction d'erreurs. Surtout lorsque l'envoi des données est relativement bon marché.
Par exemple, sur Internet, si une erreur se produit lorsque vous envoyez une trame, pas de problème - vous pouvez simplement l'envoyer à nouveau !
Par exemple, lorsque j'ai couvert le protocole Ethernet dans un article précédent, j'ai mentionné que le protocole Ethernet utilise la détection de changement, à savoir CRC32 - c'est-à-dire 32 bits (ou 4 octets) d'une somme de contrôle pour chaque trame.
Notez que cela ne signifie pas que la détection d'erreurs est simplement meilleure. Elle convient simplement mieux à Internet que la correction d'erreurs. Comme mentionné précédemment, la correction d'erreurs est préférable dans d'autres cas.
Conclusion
Dans ce tutoriel, nous avons discuté de diverses méthodes pour gérer les erreurs. Nous avons examiné la détection d'erreurs, où nous savons seulement si une trame est valide ou non. Nous avons également considéré la correction d'erreurs, où le récepteur peut restaurer la valeur correcte d'une trame erronée. Nous avons également introduit le terme surcoût.
Nous avons ensuite compris pourquoi nous utilisons la détection d'erreurs sur Internet, plutôt que la correction d'erreurs. Restez à l'écoute pour plus d'articles dans cette série sur les réseaux informatiques 📺🏽
À propos de l'auteur
Omer Rosenbaum est le Chief Technology Officer de Swimm. Il est l'auteur de la chaîne Brief YouTube Channel. Il est également un expert en formation cybernétique et fondateur de Checkpoint Security Academy. Il est l'auteur de Computer Networks (en hébreu). Vous pouvez le trouver sur Twitter.