

Article original : How to Handle Processing Multilingual Names in Your Applications
Par Apoorv Tyagi
Plus tôt cette année, mon équipe au travail et moi-même examinions les erreurs survenant dans l'une de nos API d'inscription. Nous avons constaté que près de 5 % de nos requêtes échouaient, toutes en raison d'erreurs 400 BAD REQUEST. Et la cause racine a été retracée à une vérification par regex.
Cette regex était une contrainte, où notre système n'autorise que l'utilisation de caractères anglais pour saisir les prénoms et noms de famille. Le problème était que de nombreuses personnes choisissaient de saisir leurs noms dans leur langue maternelle.
Ces clients étaient des personnes intéressées par l'achat de polices d'assurance santé sur notre plateforme, ce qui en faisait un segment crucial de notre base d'utilisateurs.
En réponse à cela, nous avons décidé de répondre à ces 5 % de nos utilisateurs en leur permettant de saisir leurs noms dans la langue de leur choix. Mais cela a soulevé de nombreux défis que nous devions résoudre – et je vais expliquer comment nous avons fait cela ici.
Défis liés au traitement des noms multilingues
1. Stratégie de stockage des données
Nous utilisons MongoDB pour stocker et récupérer les noms d'utilisateurs. Bien que MongoDB permette le stockage de tous les caractères compatibles UTF-8, le problème survient lors de la recherche.
Pour les noms anglais, nos opérations de recherche utilisent la méthode de collation simple. Les champs correspondants sont indexés de manière appropriée pour optimiser les performances des requêtes.
Bien que l'option d'implémenter un index de collation pour d'autres langues existe également dans MongoDB, cette approche signifie que vous devez informer la base de données de la langue spécifique pour laquelle vous souhaitez effectuer la recherche. Le défi ici est que notre base d'utilisateurs couvre de nombreuses langues, l'Inde seule ayant plus de 20 langues diverses.
Notre objectif était d'étendre le support à au moins toutes les langues indiennes. Mais cela signifiait que l'implémentation d'index de collation pour chaque langue prise en charge entraînerait une augmentation du nombre d'index – et une augmentation de la taille des index au fil du temps également.
Cette approche placerait également la responsabilité sur les développeurs de se souvenir d'ajouter un index pour chaque nouvelle langue à mesure que notre support linguistique s'étend, ce qui est loin d'être une solution efficace.
2. Contrainte de la passerelle API
Toutes nos API sont exposées derrière une passerelle API. Juste avant que la passerelle ne transfère une requête au service API respectif, une politique entrante vérifie le statut d'authentification de l'utilisateur. Une fois l'utilisateur authentifié, elle récupère les détails de base de l'utilisateur tels que le nom, le numéro de mobile et d'autres métadonnées, et les ajoute à un en-tête de requête de cette API.
De nombreuses API dépendent de ces données spécifiques à l'utilisateur dans les en-têtes pour leur traitement ultérieur.
Mais il y a une restriction imposée par la passerelle – elle n'autorise que les caractères ASCII pour le traitement et l'inclusion dans les en-têtes. Nous devions donc nous assurer que même si le nom pouvait être dans une autre langue, la réponse que nous partagions devait être exclusivement en anglais.
De plus, ce processus devait rester rapide, car tout retard dans l'authentification pouvait entraîner des performances lentes de l'API.
3. Défis des partenaires externes avec les noms vernaculaires
Même si nous avons commencé à accepter les noms dans plusieurs langues, il y avait nos partenaires qui devaient accepter ces noms de notre part. S'ils ne supportent pas les noms multilingues, le parcours utilisateur est interrompu.
Un exemple était notre partenaire de paiement. Nous devions nous assurer que notre équipe de paiement recevait toujours le nom en anglais, même lorsque les utilisateurs fournissaient des noms dans d'autres langues.
De plus, nous voulions éviter ces pop-ups ennuyeux demandant aux utilisateurs de saisir leurs noms en anglais chaque fois que possible. En gardant ces problèmes à l'esprit, nous devions construire une solution viable.
Comment nous avons résolu ces défis
Bien que l'utilisation d'un service de translittération tiers aurait pu être la solution la plus facile, nous avons opté pour le développement d'une solution interne pour contrôler les coûts et maintenir un contrôle total.
En tenant compte de la passerelle API et des exigences des partenaires de paiement, il est devenu clair que nous devions transformer les noms non anglais en équivalents anglais. Mais présenter ce nom anglais à l'utilisateur était contre-intuitif – par exemple, saisir un nom en hindi pour le voir transformé en anglais lors de la connexion semblait contradictoire.
Pour gérer cela, nous avons développé une stratégie de double nom. Les champs d'origine, "firstName" et "lastName", conserveraient les noms saisis par l'utilisateur dans leur langue d'entrée. Ensuite, nous avons introduit deux champs supplémentaires, "englishFirstName" et "englishLastName", dédiés au stockage des équivalents anglais de ces noms. Ces noms anglais pouvaient ensuite être partagés avec la passerelle API et nos partenaires de paiement.
Revenant au défi du stockage efficace de ces noms, nous avons anticipé que la gestion des index de collation à mesure que le nombre de langues prises en charge augmentait deviendrait ingérable. La recherche nécessiterait également de spécifier la collation pour chaque requête, créant une couche supplémentaire de complexité. Nous avons donc décidé de nous éloigner de cette approche.
Notre deuxième approche impliquait l'utilisation d'Unicode. Comme nous visions à supporter plusieurs langues sans contraintes, nous avons reconnu qu'Unicode pouvait représenter efficacement des caractères dans presque toutes les langues. Pour cette raison, nous avons décidé de stocker les représentations Unicode pour les prénoms et noms dans leurs champs MongoDB respectifs.
Nous avons simplement ajouté une autre couche entre notre base de données et l'application. Elle convertit ces chaînes Unicode en valeurs originales dans la langue locale lors de la récupération des noms de la base de données et convertit les noms locaux en leurs noms anglais respectifs. Ensuite, elle les stocke dans englishFirstName et englishLastName au moment de toute insertion ou mise à jour.
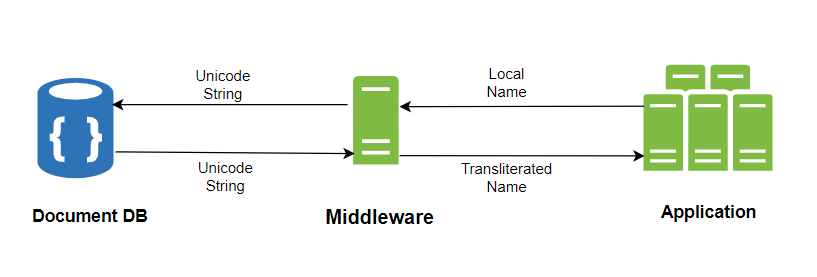
Cette stratégie nous a fourni la flexibilité dont nous avions besoin pour gérer les noms multilingues de manière transparente.
Considérations clés de conception
1. Optimisation Unicode
La représentation Unicode comprend généralement une chaîne de 6 caractères, avec 'a' représenté comme 'U+0061' et 'P' comme 'U+0050', commençant couramment par 'U+00'. Pour économiser de l'espace dans notre stockage de base de données, nous avons choisi d'omettre le préfixe 'U+' et les zéros de tête, optimisant ainsi notre stockage de données.
2. Translittération vs. Traduction
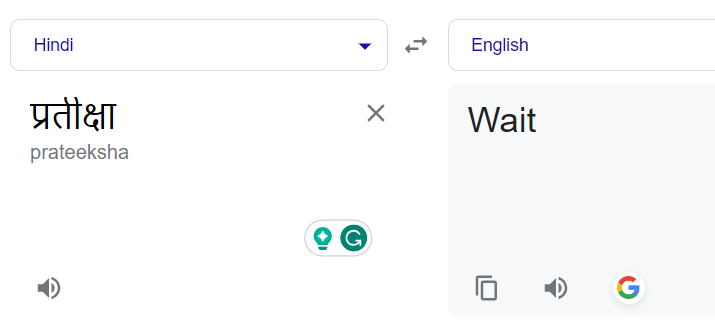
Initialement, notre objectif était la translittération, qui nécessite de convertir les noms d'un script à un autre tout en conservant leur son phonétique.
Par exemple, le mot hindi " 2a 4d 30 24 40 15 4d 37 3e" devrait être transformé en "Partiksha" et non traduit en son équivalent anglais, "Wait".
Mais nous avons reconnu que Google Translate se concentre principalement sur la traduction, et non sur la translittération. Encore une fois, nous ne voulions pas utiliser directement le service de translittération payant de Google dans notre première itération, nous avons donc développé notre service de translittération en utilisant la version gratuite de Google Translate.
3. Améliorations contextuelles
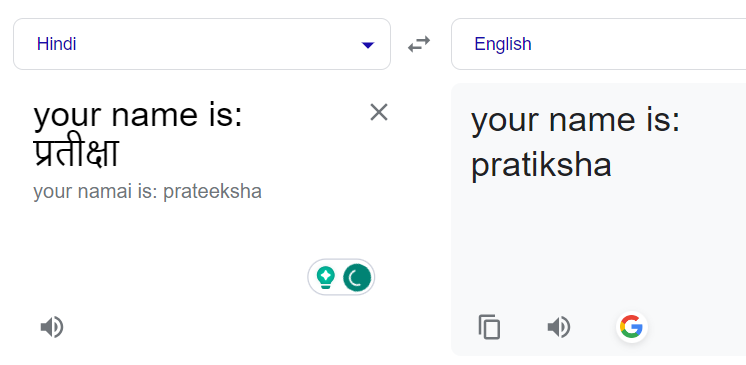
Une autre observation, et la plus cruciale, que nous avons faite était de fournir un contexte à l'API Google Translate qui influençait ses réponses.
Pour tirer parti de cela, nous avons expérimenté en ajoutant des préfixes de déclaration aux noms non anglais pour établir un contexte. Après quelques essais, nous avons réalisé que pour les noms plus courts (moins de 5 caractères), une déclaration de préfixe plus longue ne donnait pas de résultats souhaitables, et Google retournait souvent le même mot hindi. Pour les noms plus longs, nous avons utilisé des déclarations plus longues, déterminant l'équilibre optimal par essai et erreur.
La traduction normale des noms conduisait à leur traduction littérale. Par exemple, " 2a 4d 30 24 40 15 4d 37 3e" en "Wait" au lieu de "Pratiksha" :
L'ajout d'une déclaration de préfixe l'a corrigé :
D'accord, voyons maintenant comment nous avons réellement implémenté tout cela.
Code initial
Après notre première itération, nous avons développé le code suivant pour la translittération. Ici, nous utilisons la bibliothèque @iamtraction/google-translate qui est un wrapper écrit sur l'API gratuite de Google Translate.
const translate = require('@iamtraction/google-translate');
function getGoogleTranslateText(localName) {
/*
Ajout d'une phrase en anglais avant le nom pour qu'il
ne soit pas traduit par sa signification littérale.
Par exemple, 2a 30 40 15 4d 37 3e en Exam au lieu de Pariksha.
*/
if (localName.length <= 5) {
return `name: ${localName}`;
}
return `your name is: ${localName}`;
}
async function translateNameToEnglish(localName) {
if (localName.match(/^[a-zA-Z ]+$/i)) {
// Si le nom est déjà en anglais, retourne simplement
return localName;
}
try {
const res = await translate(getGoogleTranslateText(localName), {
to: 'en',
});
const translatedName = res.text.split(':')[1].trim();
return translatedName;
} catch (err) {}
// En cas d'erreur, retourne la chaîne Unicode
return localName;
}
Version bêta et défis de production
Une fois que nous avons construit cela, nous avons publié la fonctionnalité en bêta, et environ 250 utilisateurs se sont inscrits avec des noms non anglais au cours des premiers jours.
Après avoir simplement examiné certains textes traduits, nous avons constaté que le processus de conversion du nom de sa langue locale vers Unicode fonctionnait parfaitement bien et que les utilisateurs étaient en mesure de voir leurs noms correctement dans l'application dans la langue de leur choix.
Néanmoins, nous avons identifié deux problèmes en ce qui concerne le processus de translittération vers l'anglais :
- Certains noms étaient incorrectement translittérés. Cela pouvait être attribué à notre dépendance à Google Translate, un service de traduction général, plutôt qu'un service de translittération spécialisé.
- Certains noms sont restés inchangés et n'ont pas été translittérés. Ces noms étaient retournés dans la même langue que l'original. Cela signifiait que l'ajout de contexte avec des phrases de préfixe avant la traduction posait problème pour des noms spécifiques.
Cela a suscité une enquête plus approfondie qui nous a conduit à un autre package npm appelé "unidecode", qui convertit Unicode en chaîne originale. Bien que les tests initiaux avec unidecode aient montré une précision, ils ont également révélé de légères différences d'orthographe. En revanche, Google fournissait systématiquement des traductions avec des orthographes correctes. Nous devions simplement trouver un moyen d'utiliser le meilleur des deux mondes.
Nous avons donc intégré unidecode dans notre algorithme dans le cadre de notre solution.
Solution améliorée
Voici ce que nous avons proposé :
const translate = require('@iamtraction/google-translate');
const unidecode = require('unidecode');
const { isAlmostEqualStrings } = require('./levenshtein');
/**
*
* @param {String} localName
* @description Génère du texte pour Google (contexte de déclaration plus court pour les noms courts) en fonction de la longueur de localName
* @returns {String} retourne le texte à traduire
*/
function getGoogleTranslateText(localName) {
/*
Ajout d'une phrase en anglais avant le nom pour qu'il
ne soit pas traduit par sa signification littérale.
Par exemple, 2a 30 40 15 4d 37 3e en Exam au lieu de Pariksha.
*/
if (localName.length <= 5) {
return `name: ${localName}`;
}
return `your name is: ${localName}`;
}
/**
*
* @param {String} localName
* @description Donne un nom QUASIMENT translittéré
* @returns {String} retourne un nom translittéré converti de la langue locale
*/
function transliterate(localName, googleTranslatedName) {
const decodedName = unidecode(localName);
if (
decodedName &&
Array.from(decodedName)[0]?.toLowerCase() !==
Array.from(googleTranslatedName)[0]?.toLowerCase() &&
!isAlmostEqualStrings(decodedName, googleTranslatedName)
) {
return decodedName;
}
return googleTranslatedName;
}
/**
*
* @param {String} Input non English string
* @description traduit une chaîne non anglaise en anglais
* @returns {String} retourne la chaîne traduite
*/
async function translateNameToEnglish(localName) {
if (!localName || localName.match(/^[a-zA-Z ]+$/i)) {
// Si le nom est déjà en anglais, retourne simplement
return localName;
}
try {
const res = await translate(getGoogleTranslateText(localName), {
to: 'en',
});
const translatedName = res.text.split(':')[1].trim();
return transliterate(localName, translatedName);
} catch (err) {}
// En cas d'erreur, retourne la chaîne originale
return localName;
}
Après avoir obtenu le nom traduit, nous le transmettons à la fonction transliterate récemment introduite. À l'intérieur de cette fonction, notre première étape consiste à extraire la chaîne décodée à l'aide de la bibliothèque Unidecode. Mais ensuite, le cœur du problème se pose : comment déterminer quelle résultat privilégier – la chaîne décodée ou la chaîne traduite ?
Pour résoudre cela, nous avons implémenté la Distance de Levenshtein, un algorithme qui calcule la similarité entre deux chaînes.
Initialement, nous vérifions si le premier caractère du nom décodé correspond au premier caractère du nom traduit. S'il ne correspond pas, alors le nom traduit était sûrement incorrect, donc nous retournons le nom décodé, même s'il peut contenir de légères différences d'orthographe, c'est mieux que la traduction incorrecte.
S'il correspond, alors nous utilisons l'algorithme de la Distance de Levenshtein.
La distance de Levenshtein est un nombre qui indique à quel point deux chaînes sont similaires. Plus le nombre est élevé, plus les deux chaînes sont dissemblables.
Dans l'implémentation, nous avons une fonction isAlmostEqualStrings qui génère une valeur de 0 à 1 et retourne vrai si la valeur est supérieure à un certain seuil. Dans notre cas, nous avons fixé le seuil à 0,8.
Si la distance de Levenshtein indique une correspondance dépassant 80 %, nous retournons le nom traduit. Sinon, nous retournons le nom décodé. Cette approche garantit que nous privilégions la précision, offrant un résultat fiable basé sur le seuil de similarité établi.
Cet algorithme mis à jour a considérablement réduit les problèmes mentionnés ci-dessus. Bien qu'il ne soit pas 100 % précis, il a très bien résolu nos 5 % de cas.
Conclusion
L'algorithme que nous avons développé était entièrement interne et n'a entraîné aucun coût. Bien qu'investir dans une solution payante aurait potentiellement offert de meilleurs résultats, des décisions d'ingénierie judicieuses prises de manière itérative et quelques astuces intelligentes ont joué un rôle vital à la fois dans la réduction des coûts et la résolution efficace du problème spécifique que nous avions.
Le code complet pour l'implémentation ci-dessus, ainsi que l'algorithme de la Distance de Levenshtein, peut être trouvé sur GitHub (les contributions/corrections sont les bienvenues).
Avec cela, nous arrivons à la fin de l'article. Mes messages directs sont toujours ouverts si vous souhaitez discuter davantage de tout sujet technique ou si vous avez des questions, des suggestions ou des commentaires en général :
Bon apprentissage !