

Article original : How Trie Data Structures Work – Validate User Input with Automated Trie Visualization
Les structures de données jouent un rôle vital en informatique. Elles sont essentielles pour concevoir une infrastructure logicielle efficace.
En termes simples, une structure de données est une manière d'organiser et de stocker des données dans un ordinateur afin qu'elles puissent être accédées et manipulées de manière fiable. De plus, elle fournit un ensemble d'opérations telles que l'insertion, la suppression ou la recherche, avec leurs coûts computationnels respectifs.
Pourquoi les structures de données sont-elles utiles ?
La valeur des structures de données réside dans leur capacité à aborder des problèmes complexes de manière plus simple et plus complète. Comme elles permettent le stockage et la récupération de grandes quantités de données, elles deviennent particulièrement importantes dans le monde d'aujourd'hui. Les données sont générées à un rythme sans précédent. Et ces données sont ensuite traitées pour en extraire des informations précieuses dans le but de développer de nouveaux produits et services qui facilitent notre vie.
Un autre des principaux avantages des structures de données est leur capacité à réduire la complexité temporelle de certains algorithmes. En utilisant la structure de données appropriée, vous pouvez effectuer des opérations telles que la recherche, le tri et l'insertion de données en temps sous-linéaire.
Par exemple, l'utilisation d'une table de hachage au lieu d'une liste chaînée pour stocker des données nous permet d'accéder à n'importe quel élément de la structure en temps constant, réduisant la complexité de O(n) à O(1).
Dans ce contexte, l'un des aspects les plus importants des structures de données est leur capacité à organiser les données de manière à permettre une utilisation efficace de la mémoire et à réduire le temps nécessaire pour effectuer des tâches spécifiques.
Choisir la bonne structure de données pour un problème à grande échelle est une décision cruciale qui peut grandement influencer les performances d'un algorithme ou d'une application logicielle. Elles servent également de base à de nombreux concepts fondamentaux en informatique, tels que les algorithmes, les bases de données et les compilateurs.
Ainsi, pour saisir pleinement leur signification, vous devez comprendre leur fonctionnement interne et analyser leurs forces et leurs faiblesses.
 Un exemple de structure de données Rope. Principalement utilisée pour gérer de grandes chaînes de caractères brutes. Image obtenue de [Wikipedia](https://en.wikipedia.org/wiki/Rope%28datastructure%29)
Un exemple de structure de données Rope. Principalement utilisée pour gérer de grandes chaînes de caractères brutes. Image obtenue de [Wikipedia](https://en.wikipedia.org/wiki/Rope%28datastructure%29)
Différents types de structures de données
Il existe de nombreux types de structures de données, y compris les listes chaînées, les tableaux, les piles, les files d'attente, les arbres et les graphes mentionnés précédemment. Chacun a ses propres cas d'utilisation et avantages.
Qu'est-ce qu'une structure de données Trie ?
Une structure de données particulièrement intéressante sur laquelle nous allons nous concentrer dans cet article est le Trie, une structure de données en forme d'arbre utilisée pour stocker un ensemble dynamique ou un tableau associatif où les clés sont généralement des chaînes de caractères.
Communément, nous utilisons les tries dans des tâches telles que la recherche et l'auto-complétion, où un grand ensemble de données de chaînes doit être stocké, vérifié ou recherché de manière efficace.
Le Trie est particulièrement efficace pour les tâches qui impliquent la recherche dans un grand ensemble de chaînes, car il peut effectuer ces tâches avec une complexité temporelle de O(m), où m est la longueur de la chaîne recherchée. Cela fait du Trie un choix attrayant pour des applications telles que les dictionnaires, les fonctionnalités d'auto-complétion et les tables de routage IP.
Malgré les nombreux avantages offerts par les Tries, l'un des principaux défis associés à leur implémentation est leur complexité potentielle, en particulier dans leur instanciation et leur visualisation.
La visualisation des structures de données est un aspect essentiel pour comprendre leurs bases et évaluer leurs performances. Mais visualiser les Tries peut devenir de plus en plus difficile à mesure que le nombre de nœuds et de branches augmente.
Cela peut entraîner de la confusion et des incompréhensions, rendant plus difficile pour les développeurs et les chercheurs de comprendre de manière exhaustive le comportement et le débit du Trie. Pour cette raison, cet article vous montre comment automatiser la visualisation des structures de données Trie.
Avantages de l'automatisation du processus de visualisation
En automatisant le processus de visualisation, nous débloquons une multitude d'avantages qui peuvent avoir un impact positif sur l'ensemble du processus de développement logiciel, transcendant les limites des techniques de visualisation traditionnelles.
Tout d'abord, l'automatisation apporte avec elle le don de l'efficacité. En éliminant le besoin de visualisation manuelle et en permettant la génération instantanée de représentations visuelles, nous réduisons considérablement le temps passé à créer et à comprendre les diagrammes de Trie.
Cette nouvelle efficacité libère un temps précieux pour d'autres tâches, nous permettant de nous concentrer sur l'optimisation et la résolution de défis abstraits majeurs, favorisant ainsi le progrès dans le domaine.
De plus, l'automatisation ouvre la voie à la cohérence et à la précision dans la visualisation des Tries. L'élément humain est sujet à des erreurs, conduisant à des incompréhensions et à des interprétations erronées de la structure de données sous-jacente. L'automatisation du processus de visualisation élimine ces pièges potentiels, garantissant que les représentations visuelles générées sont fiables, précises et fidèles à la structure de données.
De plus, l'automatisation favorise la scalabilité, permettant la visualisation même des ensembles de données les plus complexes et à grande échelle. À mesure que la taille d'un Trie augmente, la difficulté de la visualisation manuelle augmente également. L'automatisation contourne ce problème en générant des représentations visuelles indépendamment de la complexité ou de la taille du Trie. Cela offre aux chercheurs et aux développeurs un niveau de compréhension sans précédent de leurs systèmes.
Enfin, l'automatisation favorise l'accessibilité et l'inclusivité dans le monde de la visualisation des structures de données.
Traditionnellement, la création et l'interprétation de visualisations nécessitaient un certain niveau d'expertise et d'expérience. Mais en automatisant ce processus, nous démocratisons l'accès aux avantages de la visualisation. Cela permet à des individus de différents niveaux d'expertise d'analyser et de comprendre les structures de données Trie.
Cela, à son tour, peut inspirer la collaboration et l'innovation dans un large éventail de disciplines et d'industries.
Voici ce que nous allons couvrir dans ce guide :
- Qu'est-ce qu'un Trie ?
- Principaux composants d'une structure de données Trie
- Opérations que vous pouvez effectuer sur un Trie
- Comment implémenter un Trie
- Comment visualiser un Trie
Qu'est-ce qu'un Trie ?
Un Trie est une structure de données unique et puissante en informatique. Il est utilisé pour stocker et manipuler des tableaux associatifs ou des ensembles dynamiques où les clés sont généralement des chaînes de caractères. Il est également connu sous le nom d'arbre de préfixes, radix ou digital.
Provenant du terme "retrieval", le Trie est une structure en forme d'arbre qui organise et recherche efficacement de grands ensembles de chaînes de caractères en fonction de leurs préfixes. Cela en fait un choix idéal pour des applications telles que les dictionnaires ou les fonctionnalités de vérification orthographique.
Le Trie se compose de nœuds connectés par des branches, chacun représentant un seul caractère dans une chaîne. Le nœud racine est généralement vide ou contient une valeur spéciale, tandis que les nœuds feuilles signalent la fin d'une chaîne.
Alors que nous parcourons du nœud racine à un nœud feuille, nous construisons la chaîne en concaténant les caractères représentés par chaque nœud.
Avantages de la structure de données Trie
Contrairement à d'autres structures de données arborescentes comme les arbres de recherche binaires, les Tries ne stockent pas les clés réelles associées aux nœuds. Au lieu de cela, la position d'un nœud au sein de la structure Trie définit la clé.
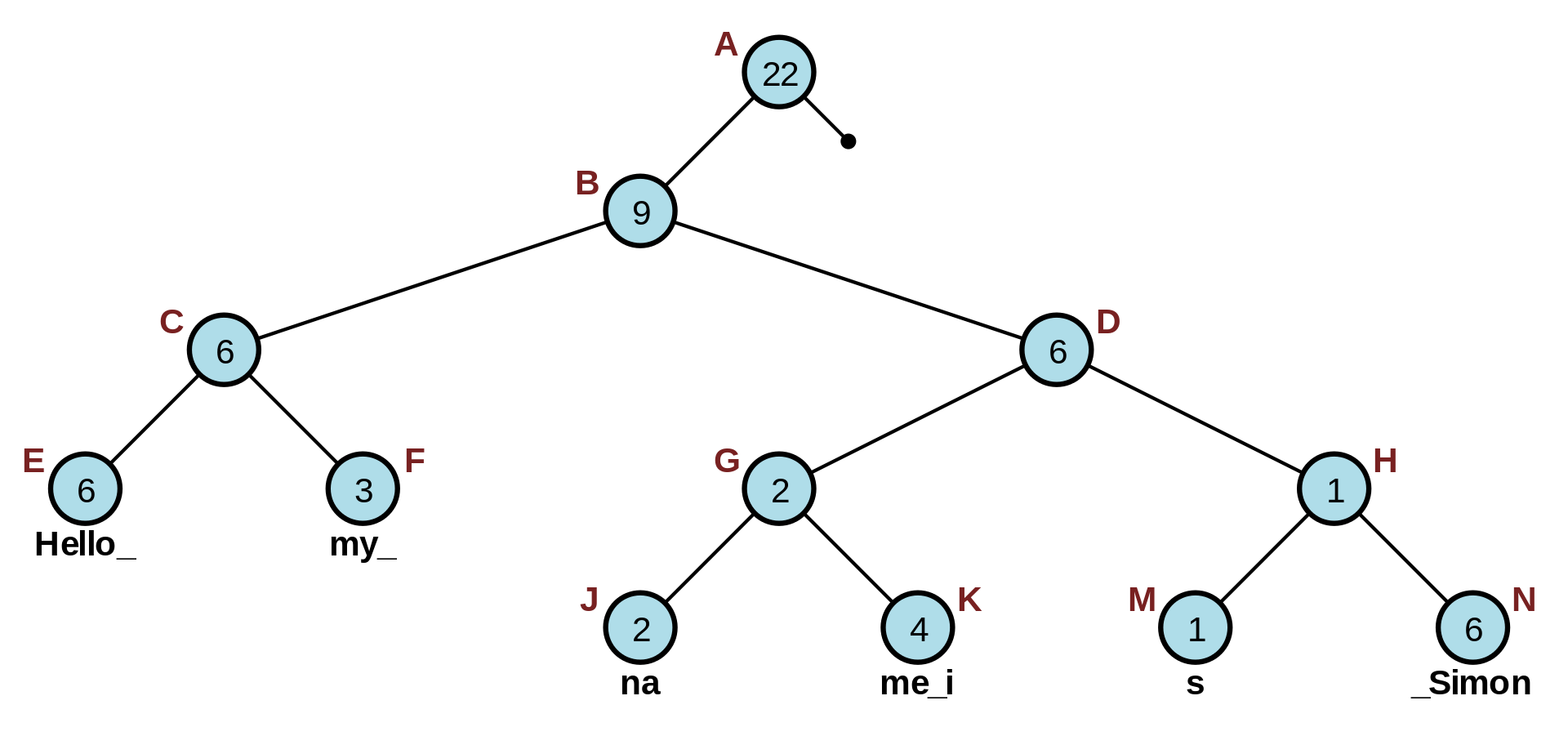
 Exemple d'un Trie contenant 4 mots anglais
Exemple d'un Trie contenant 4 mots anglais
L'un des principaux avantages des Tries par rapport à d'autres alternatives comme les BSTs (Binary Search Trees) est leur capacité à effectuer des opérations de recherche, d'insertion et de suppression avec une complexité temporelle de O(m). Dans ce cas, m est la longueur de la clé (mot) recherchée, insérée ou supprimée.
Cela est particulièrement efficace lors de la manipulation de grands ensembles de données, car la complexité est indépendante du nombre de clés stockées dans le Trie. En d'autres termes, les performances de ces opérations ne se dégradent pas à mesure que le Trie grandit en taille.
Les Tries ont plusieurs autres caractéristiques notables, notamment :
- Partage de préfixes : Un Trie stocke des chaînes en partageant leurs préfixes communs, réduisant l'utilisation de la mémoire et fournissant une représentation compacte des données. Cette fonctionnalité est particulièrement bénéfique lors de la manipulation de grands ensembles de chaînes qui partagent de nombreux préfixes communs.
- Taille indépendante de l'alphabet : La taille d'un Trie ne dépend pas de la taille de l'alphabet des mots qu'il contient, ce qui le rend adapté à une large gamme d'applications et d'ensembles de données.
- Prise en charge des opérations de recherche avancées : Les Tries peuvent effectuer des opérations de recherche avancées, telles que la correspondance de préfixes, les suggestions d'auto-complétion et la correspondance approximative de chaînes, qui sont difficiles ou inefficaces à implémenter en utilisant d'autres structures de données.
- Optimisation de l'espace avec des Tries compressés : Des variations de la structure de données Trie, telles que les Radix Tries, peuvent optimiser davantage l'utilisation de la mémoire en fusionnant plusieurs nœuds avec des nœuds enfants uniques en un seul nœud, résultant en une structure plus compacte.
Néanmoins, les Tries ne sont pas sans leurs inconvénients. Une préoccupation primaire est leur inefficacité spatiale potentielle. Les Tries peuvent consommer une quantité considérable de mémoire, en particulier lors de la manipulation de grands alphabets ou d'ensembles de données avec peu de préfixes partagés. Ce problème peut être atténué dans une certaine mesure par des techniques de compression et des implémentations alternatives de Trie.
En résumé, lors de la décision d'utiliser ou non un Trie, vous devez considérer attentivement les exigences spécifiques de votre application, la nature de votre ensemble de données et les compromis entre performance, utilisation de la mémoire et complexité.
Principaux composants d'une structure de données Trie
Un Trie se compose de plusieurs composants fondamentaux qui travaillent ensemble pour composer sa base. Comprendre ces éléments est crucial pour une compréhension solide des Tries et de leur potentiel complet.
Ici, nous allons discuter des principales parties d'un trie, certaines d'entre elles ayant été mentionnées précédemment :
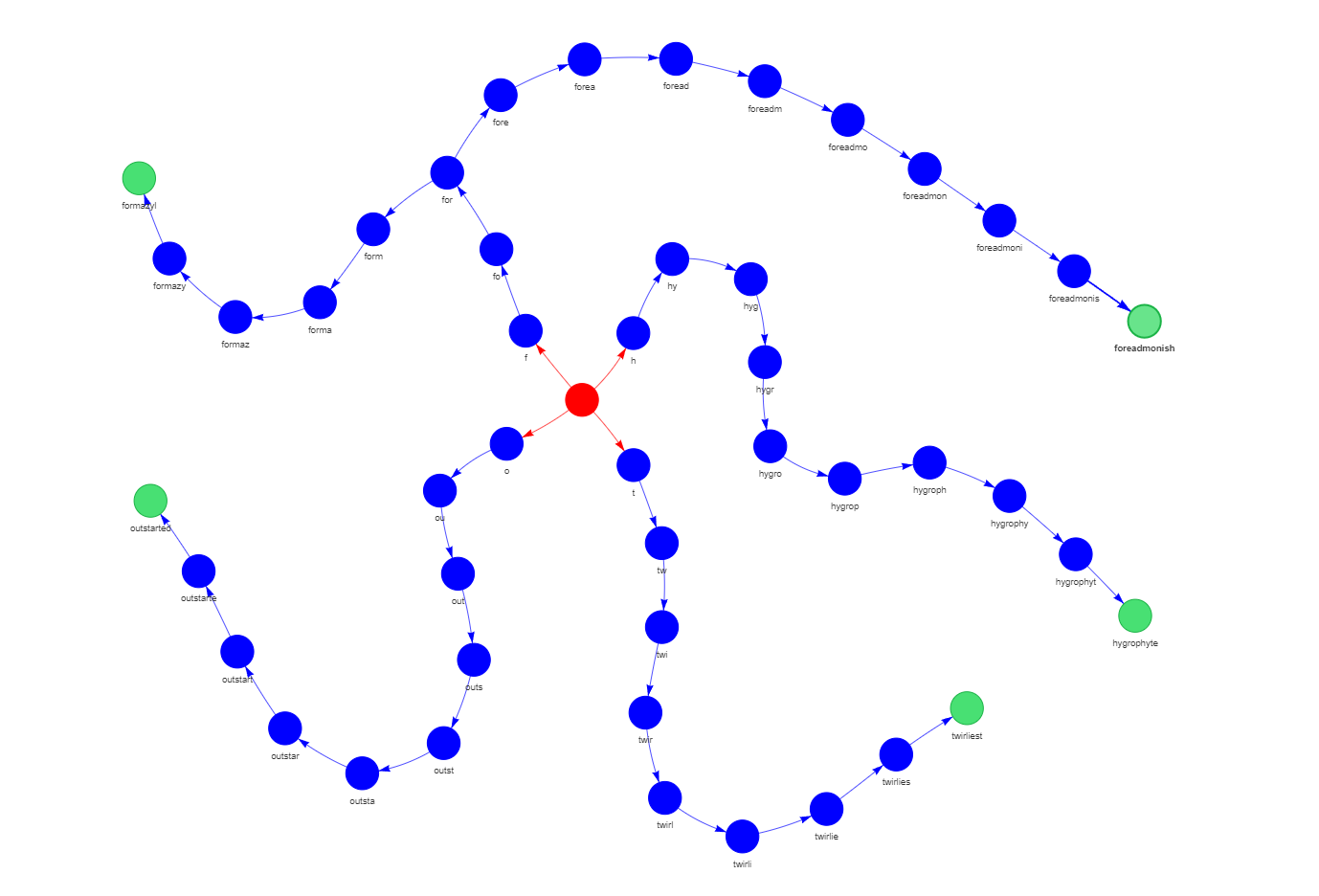 Exemple de Trie pour localiser et visualiser les éléments correspondants
Exemple de Trie pour localiser et visualiser les éléments correspondants
- Nœuds : Un Trie se compose de nœuds, chacun représentant un seul caractère dans une chaîne. Chaque Trie a un nœud racine, ci-dessus coloré en rouge, qui est généralement vide ou contient une valeur spéciale. Les autres nœuds du Trie correspondent à des caractères individuels des chaînes stockées.
- Arêtes : Les arêtes, ou branches, relient les nœuds dans un Trie. Chaque arête relie un nœud parent à un nœud enfant et représente une transition entre deux caractères dans une chaîne. Les arêtes aident à former les chemins du nœud racine aux nœuds feuilles, qui correspondent à des chaînes complètes.
- Nœuds feuilles : Les nœuds feuilles (colorés en vert) sont les nœuds terminaux, signalant la fin d'une chaîne. Selon l'application spécifique, ils peuvent contenir des informations supplémentaires, telles que la fréquence de la chaîne, sa valeur ou les données associées.
- Pointeurs : Chaque nœud dans un Trie contient généralement un tableau ou un ensemble de pointeurs, un pour chaque caractère possible de l'alphabet. Ces pointeurs référencent les nœuds enfants correspondant au caractère suivant d'une chaîne. Si un pointeur est nul ou n'est pas contenu dans l'ensemble, cela indique qu'il n'y a pas de nœud enfant pour ce caractère.
- Préfixes communs : L'une des caractéristiques définissant le Trie est sa capacité à partager des préfixes communs parmi les chaînes stockées. Cette fonctionnalité (optionnelle selon le problème appliqué) fournit un support lors de l'exécution d'opérations et de recherches basées sur les préfixes.
- Indicateur de fin de mot : Un marqueur ou un indicateur end est souvent utilisé pour différencier les chaînes complètes des préfixes. Cette valeur booléenne est définie dans un nœud pour indiquer que le chemin du nœud racine à ce nœud représente une chaîne complète dans le Trie.
Opérations que vous pouvez effectuer sur un Trie
Maintenant que vous avez vu les éléments fondamentaux d'un Trie, vous avez une idée générale de leurs opérations sous-jacentes. Vous comprenez également la valeur du trie en tant que structure de données.
À ce stade, vous devriez essayer de comprendre techniquement la complexité de chaque opération qui peut être effectuée sur eux.
Comment insérer une chaîne dans un Trie
Imaginez le Trie comme un arbre avec de nombreuses branches, commençant par un nœud racine. Pour insérer une chaîne, commencez par la racine et suivez ces étapes :
- Pour chaque caractère de la chaîne, vérifiez s'il existe une arête (branche) correspondant au caractère.
- Si c'est le cas, passez au nœud enfant connecté par l'arête.
- Sinon, créez un nouveau nœud pour le caractère, connectez-le au nœud actuel avec une arête, et passez au nouveau nœud.
- Une fois que vous atteignez la fin de la chaîne, marquez le nœud final comme la fin d'un mot.
Exemple : Insérer "apple" et "ape" dans un Trie vide
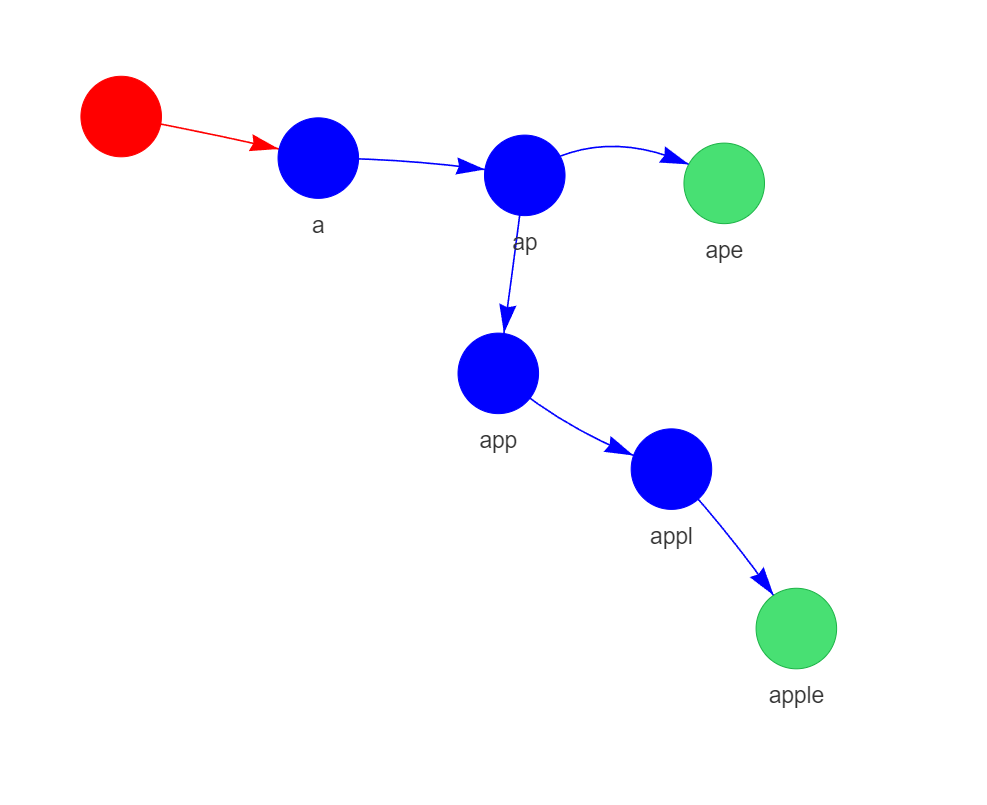
Comment rechercher une chaîne dans un Trie
Pour rechercher une chaîne dans un Trie, commencez par la racine et suivez ces étapes :
- Pour chaque caractère de la chaîne, vérifiez s'il existe une arête correspondant au caractère.
- Si c'est le cas, passez au nœud enfant connecté par l'arête.
- Si ce n'est pas le cas, la chaîne n'est pas dans le Trie, et la recherche échoue.
- Si vous atteignez la fin de la chaîne, vérifiez si le nœud final est marqué comme la fin d'un mot. Si c'est le cas, la recherche est réussie.
Exemple : Rechercher "ape" dans le Trie contenant "apple" et "ape"
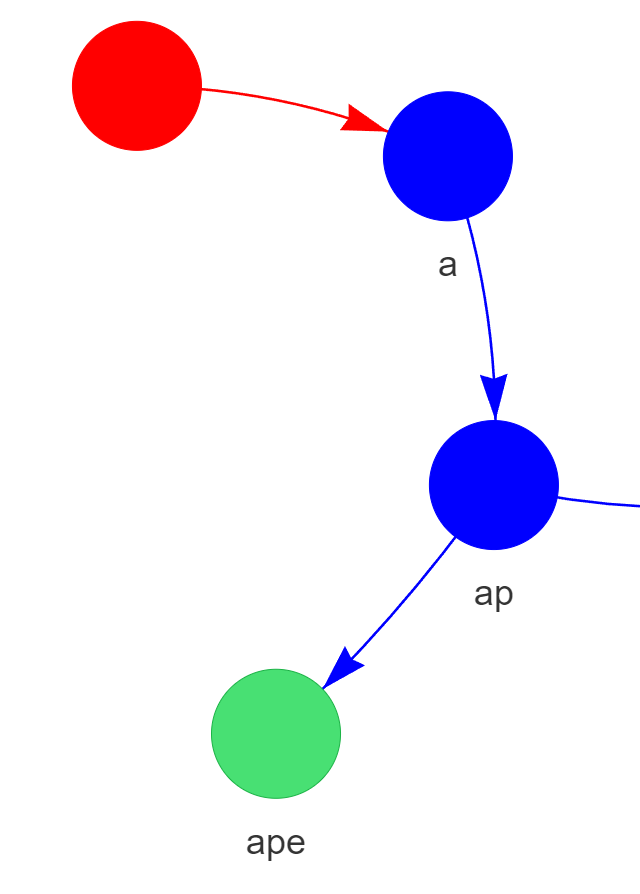 Chemin suivi par l'algorithme de recherche pour vérifier le mot "ape"
Chemin suivi par l'algorithme de recherche pour vérifier le mot "ape"
Comment supprimer une chaîne d'un Trie
Pour supprimer une chaîne d'un Trie, commencez par la racine et suivez ce processus :
- Recherchez la chaîne, en gardant une trace des nœuds et des arêtes parcourus.
- Si la chaîne n'est pas trouvée, la suppression échoue.
- Supprimez l'indicateur end du nœud final si la chaîne est trouvée.
- En commençant par le nœud final, remontez vers la racine, en supprimant les nœuds et les arêtes qui n'ont pas d'autres enfants ou qui n'appartiennent pas à d'autres mots complets.
Exemple : Supprimer "ape" du Trie contenant "apple" et "ape"
 Trie après la suppression du mot "ape"
Trie après la suppression du mot "ape"
En considérant ces opérations comme des traversées à travers les branches du Trie, nous pouvons alors plus facilement rendre compte de la complexité mémoire et temporelle de chacune d'entre elles. Elles sont équivalentes à des tâches de traversée d'arbre (ou de liste chaînée).
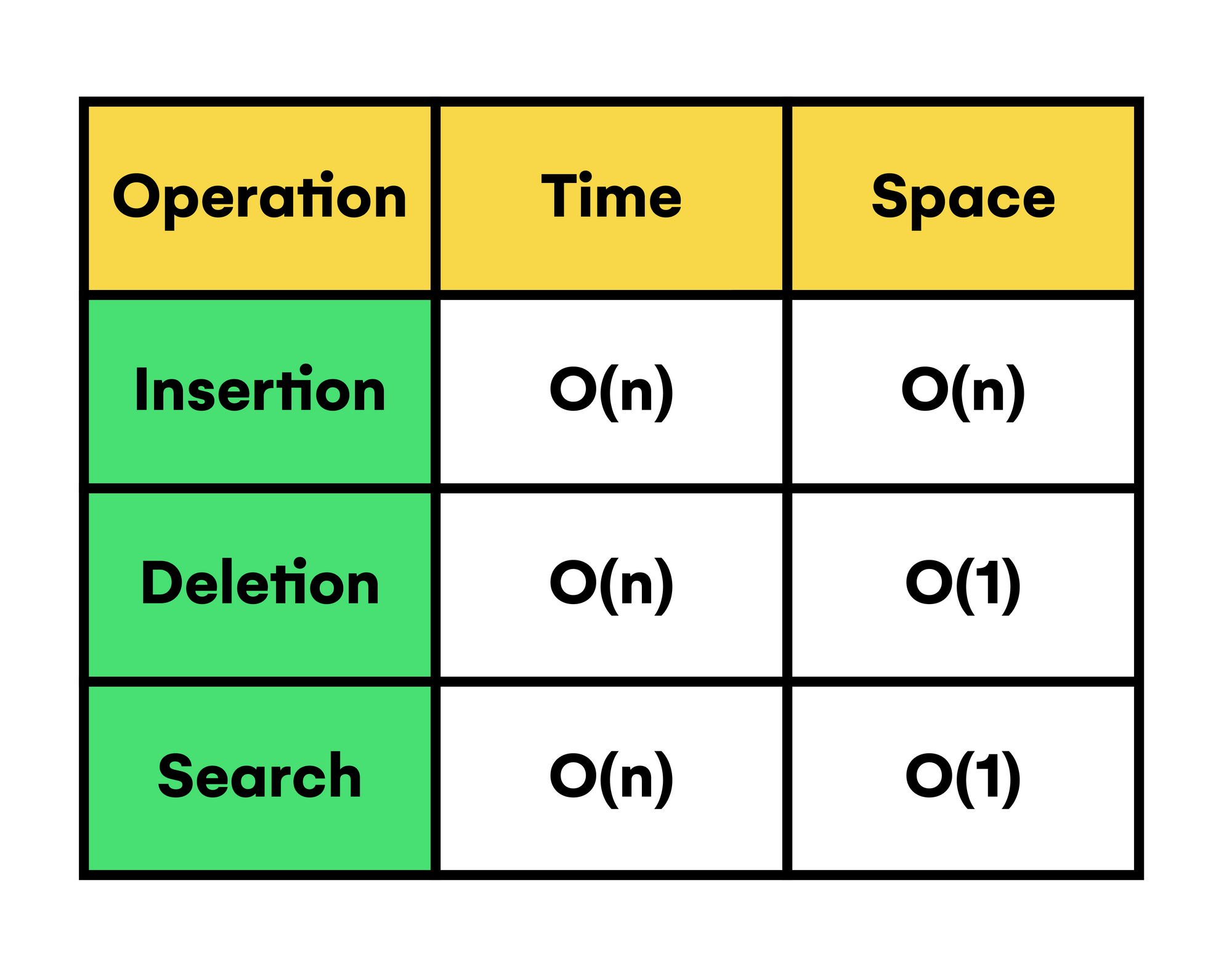 Tableau des complexités temporelles et spatiales moyennes des opérations de Trie
Tableau des complexités temporelles et spatiales moyennes des opérations de Trie
Comme on peut le voir dans le tableau, toutes les opérations ont la même complexité temporelle linéaire (étant n la longueur du mot traité). Cela signifie qu'elles nécessitent uniquement d'effectuer une seule traversée des caractères du mot pour obtenir le résultat souhaité.
Mais en termes d'espace, la suppression et la recherche n'ont pas besoin de mémoire supplémentaire. Cela signifie qu'elles ont une complexité constante.
Enfin, il est intéressant de noter que la complexité temporelle dans le pire des cas de l'opération de suppression pourrait être de l'ordre de O(2n), devant traverser à nouveau la branche où se trouve le mot à supprimer afin de supprimer les nœuds éventuellement inutilisés dans le Trie.
Comment implémenter un Trie
Nous allons maintenant utiliser Python pour implémenter un Trie spécifiquement conçu pour un problème de validation (mais vous pouvez l'adapter pour toute application donnée).
Le problème exemple que notre implémentation résoudra est le suivant : étant donné un plateau avec des cases NxN, nous voulons qu'un utilisateur puisse introduire les coordonnées d'une case spécifique en utilisant un message texte afin de la sélectionner et d'opérer avec elle.
À cette fin, l'entrée consistera en une série de caractères alphabétiques pour se référer à l'axe vertical du plateau, suivie d'un autre ensemble de caractères numériques pour sélectionner l'axe restant.
 Plateau exemple 6x6
Plateau exemple 6x6
Dans ce cas, nous pouvons utiliser des expressions régulières ou des techniques similaires pour valider si l'entrée de l'utilisateur correspond à la structure et au format requis. Mais si nous ne nous soucions pas de la consommation de mémoire de notre programme, nous avons l'alternative d'utiliser un Trie.
Ce choix peut, à première vue, sembler excessivement inefficace en termes de mémoire puisque nous devons créer et utiliser une structure de données spécifique qui consomme de l'espace pendant toute l'exécution du programme.
Mais l'utilisation d'un Trie fournit un temps de validation constant pour toutes les entrées possibles, et puisque dans cet exemple les coordonnées sont des chaînes de courte longueur, leur stockage en mémoire s'avère raisonnable.
Notez que dans cet exemple, l'opération de recherche de Trie (validation) s'exécute en temps "constant" en raison de la longueur fixe de tous ses mots. C'est-à-dire, comme le plateau ne s'agrandira pas pendant l'exécution du programme, la complexité temporelle pour rechercher une chaîne reste constante.
import random
import math
import urllib, json
from pyvis.network import Network
import matplotlib.pyplot as plt
class TrieNode:
def __init__(self, inputChar):
self.char = inputChar
self.end = False
self.children = {}
class Trie():
def __init__(self, startingElements=None):
self.root = TrieNode("")
if startingElements!=None:
for i in startingElements: self.insert(i)
def insert(self, word):
node = self.root
for char in word:
if char in node.children:
node = node.children[char]
else:
new_node = TrieNode(char)
node.children[char] = new_node
node = new_node
node.end = True
def searchAndSplit(self, x):
node = self.root
output = ["", ""]
for char in x:
if char in node.children:
node = node.children[char]
else:
return []
output[1 if node.end else 0] += node.char
return output if node.end else []
def remove(self, root, word, index = 0):
if not root:
return None
if index==len(word):
if root.end:
root.end = False
if root.children=={}:
del root
root = None
return root
root.children[word[index]] = self.remove(root.children[word[index]], word, index + 1)
if (root.children=={}) and not root.end:
del root
root = None
return root
Ci-dessus, vous pouvez voir l'implémentation complète. En bref, elle se compose de deux classes, TrieNode et Trie, qui définissent respectivement les nœuds du Trie et la structure du Trie elle-même.
La classe Trie fournit des méthodes pour insérer, rechercher, diviser (qui est une fonctionnalité personnalisée que nous discuterons dans la section de visualisation), et supprimer des mots du Trie. La classe TrieNode représente les nœuds individuels et leurs attributs associés. Dans ce cas, il s'agit d'une chaîne contenant le caractère correspondant au nœud et d'une table de hachage de caractères associés aux pointeurs des sous-branches du Trie.
Comment visualiser un Trie
Enfin, après avoir implémenté fonctionnellement le Trie, nous allons utiliser la bibliothèque Python pyvis pour définir une fonction à l'intérieur de la classe Trie qui produit automatiquement une visualisation graphique de la structure de données. Cela résultera en un fichier HTML dans lequel nous pouvons interagir avec les éléments qu'il contient.
def toGraph(self):
g = Network(directed =True)
g.show_buttons()
nodeIndex = 1
currentNode = 0
q = [self.root]
g.add_node(currentNode, label="", color="red")
tempLabels = {0:""}
while q!=[]:
n = q.pop(0)
for i in n.children.values():
if i:
tempLabels[nodeIndex] = tempLabels[currentNode]+i.char
g.add_node(nodeIndex, label=tempLabels[currentNode]+i.char, color="#48e073" if i.end else "blue")
g.add_edge(currentNode, nodeIndex)
nodeIndex+=1
q.append(i)
currentNode+=1
g.show('nx.html')
Comme vous pouvez l'observer dans la fonction toGraph(), nous effectuons une recherche en largeur d'abord sur l'ensemble du Trie tout en créant les nœuds et les arêtes nécessaires (connexions entre eux) à l'intérieur d'un objet pyvis.network.Network.
De plus, elle donne aux nœuds finaux une couleur différente des autres. Cela nous aidera à comprendre les avantages que cette visualisation fournit afin que nous puissions simplifier l'exécution des fonctions liées au traitement et à la validation des chaînes dans l'exemple précédent.
Ainsi, pour instancier un Trie avec les coordonnées de chaîne du plateau exemple 6x6, nous allons passer un objet générateur Python au constructeur du Trie pour insérer chaque chaîne dans la structure de données et la tracer dans un graphe :
tr = Trie((''.join(chr(97+int(j)) for j in str(i))+str(k) for k in range(6) for i in range(6)))
tr.toGraph()

Selon les règles de coloration de la fonction toGraph(), tous les nœuds contenant uniquement un caractère alphabétique sont colorés en bleu, tandis que tous les autres nœuds, sauf le nœud racine, sont colorés en vert.
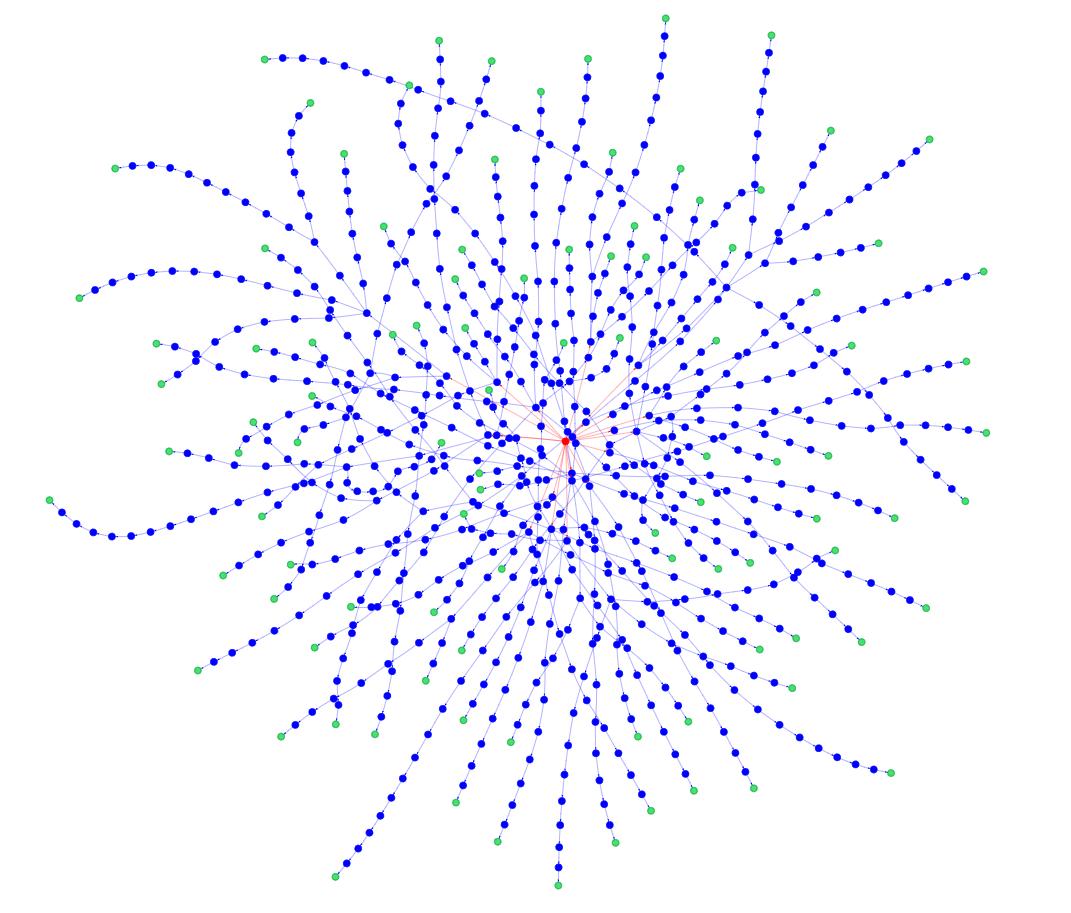
Si nous augmentons la taille du plateau, nous remarquerons que tous les nœuds finaux auront une couleur différente des nœuds avec des caractères alphabétiques, comme le montre la section de graphe suivante d'un plateau 16x16 :
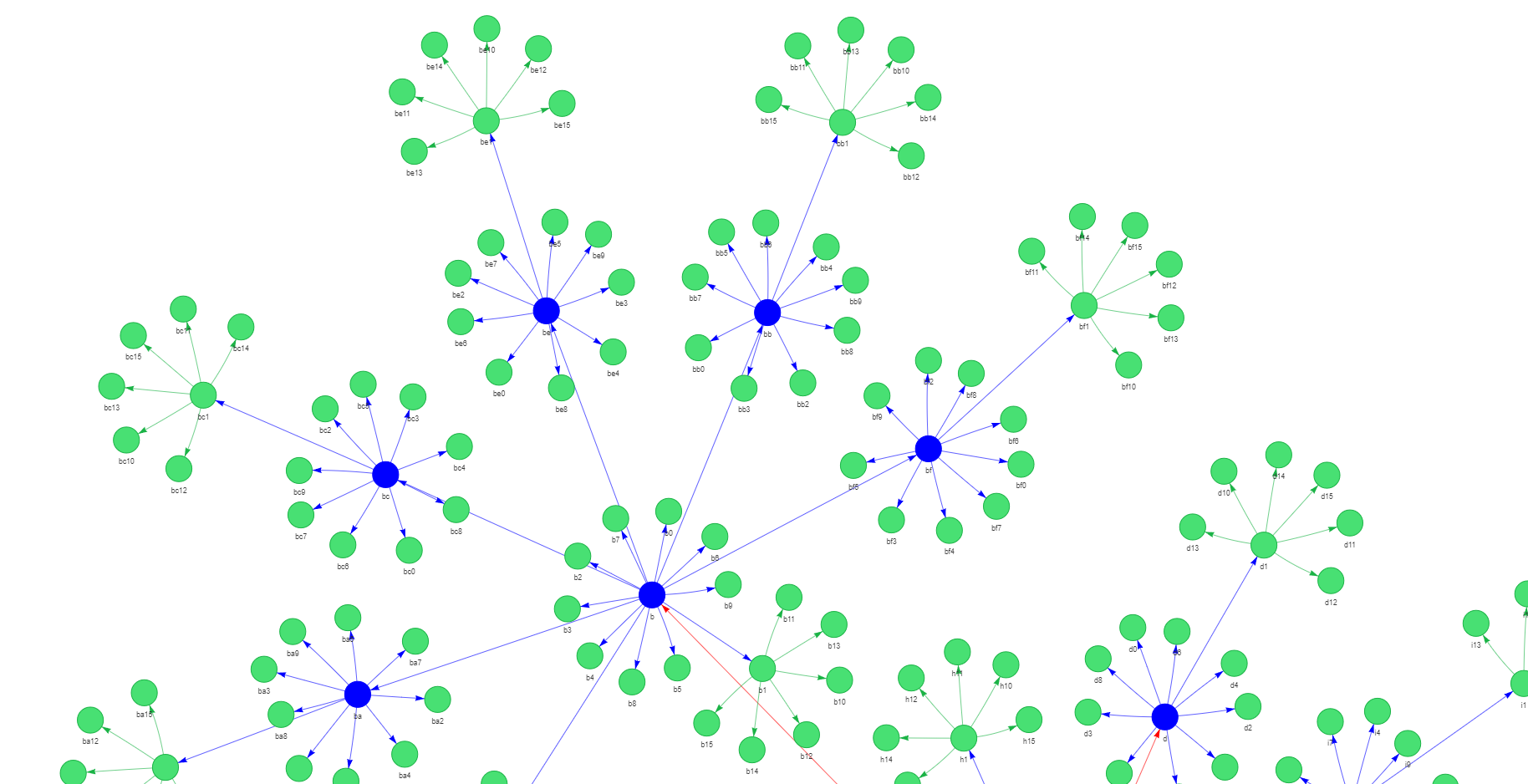
Ainsi, lors de l'exécution d'une recherche ou d'une traversée BFS, nous pouvons tirer parti de l'indicateur end pour diviser les coordonnées entre les caractères alphabétiques et numériques. Cela évite une étape de post-traitement supplémentaire après la validation de l'entrée utilisateur.
Enfin, nous pouvons créer un Trie plus grand pour voir comment il se comporte à plus grande échelle.
data = json.loads(urllib.request.urlopen("https://raw.githubusercontent.com/dwyl/english-words/master/words_dictionary.json").read())
data = list(data.keys())
tr = Trie(random.sample(data, 100))
tr.toGraph()
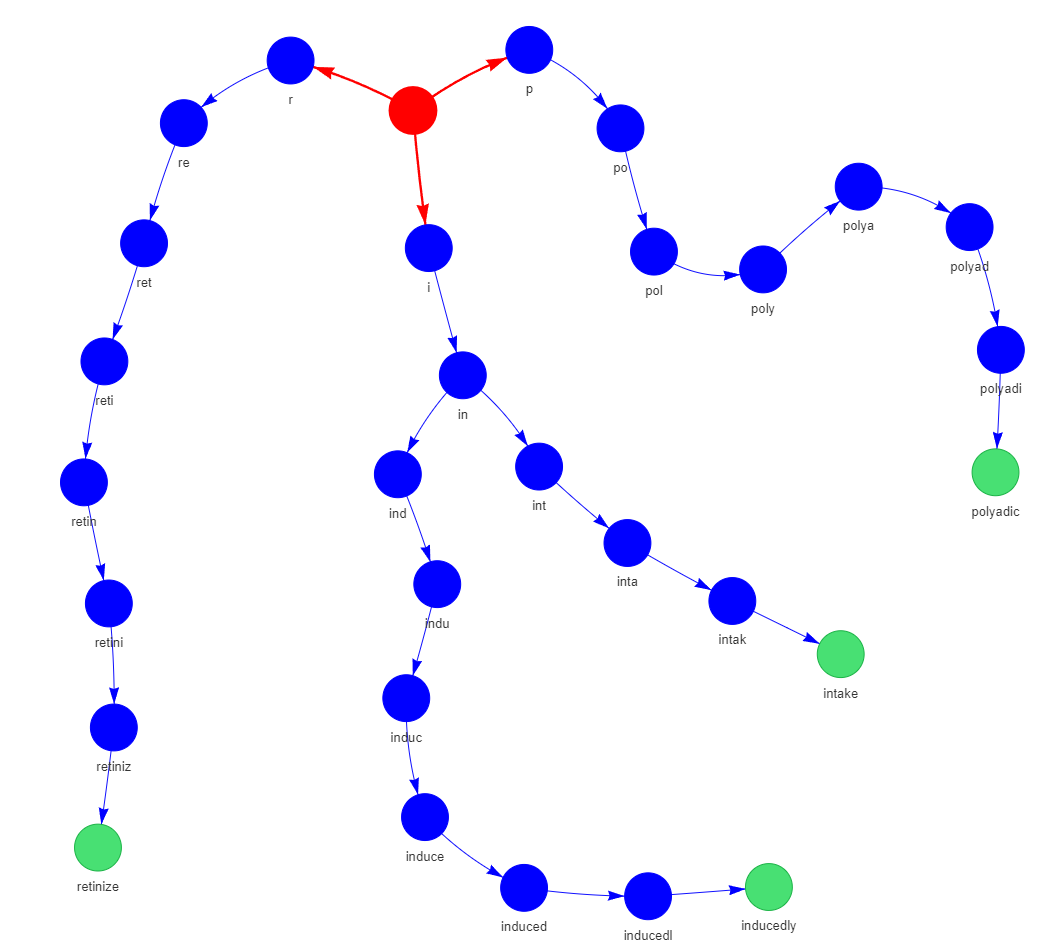
En utilisant ce code, nous accédons à un ensemble de données de mots anglais open-source, sélectionnons 100 mots aléatoires et les insérons dans un nouveau Trie. Cela donne en sortie de visualisation le graphe suivant :

Si vous souhaitez travailler et personnaliser des Tries pour des projets spécifiques de manière interactive, vous pouvez accéder au code complet dans le notebook Colab fourni ci-dessous :
Conclusion
Nous avons vu comment la visualisation d'une structure de données ou des données d'entrée d'un problème peut améliorer considérablement notre compréhension de ses relations et de ses intrications. Elle nous offre également la possibilité d'introduire de nouvelles fonctionnalités qui, autrement, n'auraient pas pu être développées aussi facilement sans une vision automatisée et appropriée.
En plus des Tries, les avantages de la visualisation peuvent être étendus à d'autres structures de données et algorithmes. Et cela peut favoriser une compréhension plus approfondie de la logique sous-jacente et de la fonctionnalité.
L'incorporation de techniques de visualisation dans le processus de développement peut améliorer considérablement l'efficacité et la créativité de notre travail en informatique et en analyse de données.
En conclusion, en adoptant la visualisation comme composant clé de notre processus de développement, nous pouvons débloquer de nouvelles opportunités pour optimiser, résoudre les problèmes et explorer le potentiel complet des structures de données et des algorithmes dans diverses applications.