


Article original : How Search Works Under the Hood – Data Structures and Search Algorithms Explained
La recherche est une activité que les gens effectuent tous les jours. Qu'il s'agisse de rechercher des mots dans des documents et des bases de données, ou de faire correspondre des motifs en bioinformatique pour détecter des anomalies dans l'ADN, les applications de la recherche sont pratiquement sans fin.
Et ces applications nécessitent beaucoup de calcul. Imaginez rechercher une séquence d'ADN particulière parmi des millions, ou rechercher un utilisateur dans la base de données de Google.
C'est pourquoi nous avons besoin d'un algorithme qui s'exécute très rapidement sans consommer beaucoup de mémoire. Et c'est ce que vous apprendrez ici.
Dans ce tutoriel, nous allons plonger profondément dans deux algorithmes de recherche célèbres : l'algorithme de Rabin-Karp et l'algorithme de Knuth-Morris-Pratt. Nous discuterons également de leur complexité temporelle et spatiale, qui est équivalente au temps et à l'espace qu'un algorithme consomme, en fonction de la taille de son entrée. Vous apprendrez également les structures de données courantes pour la recherche.
Une connaissance très basique de la programmation est requise pour suivre. Nous utiliserons des exemples en Python dans ce tutoriel.
Table des matières
- Structures de données pour la bioinformatique et la recherche
- Algorithme de recherche naïf
- Algorithme de Rabin-Karp
- Algorithme de Knuth-Morris-Pratt
- Conclusion
Structures de données pour la bioinformatique et la recherche
Discutons d'abord de certaines structures de données que vous devriez connaître même si nous n'approfondissons pas trop le sujet.
La structure de données Trie
Un trie est une structure de données en forme d'arbre où chaque nœud stocke une lettre de l'alphabet. Vous pouvez structurer les nœuds de manière à ce que les mots et les chaînes puissent être récupérés à partir de la structure en parcourant une branche (chemin) de l'arbre.
Prenons par exemple les mots ANA, AND et BOT – leur arbre de préfixes ou trie ressemblera à ceci :
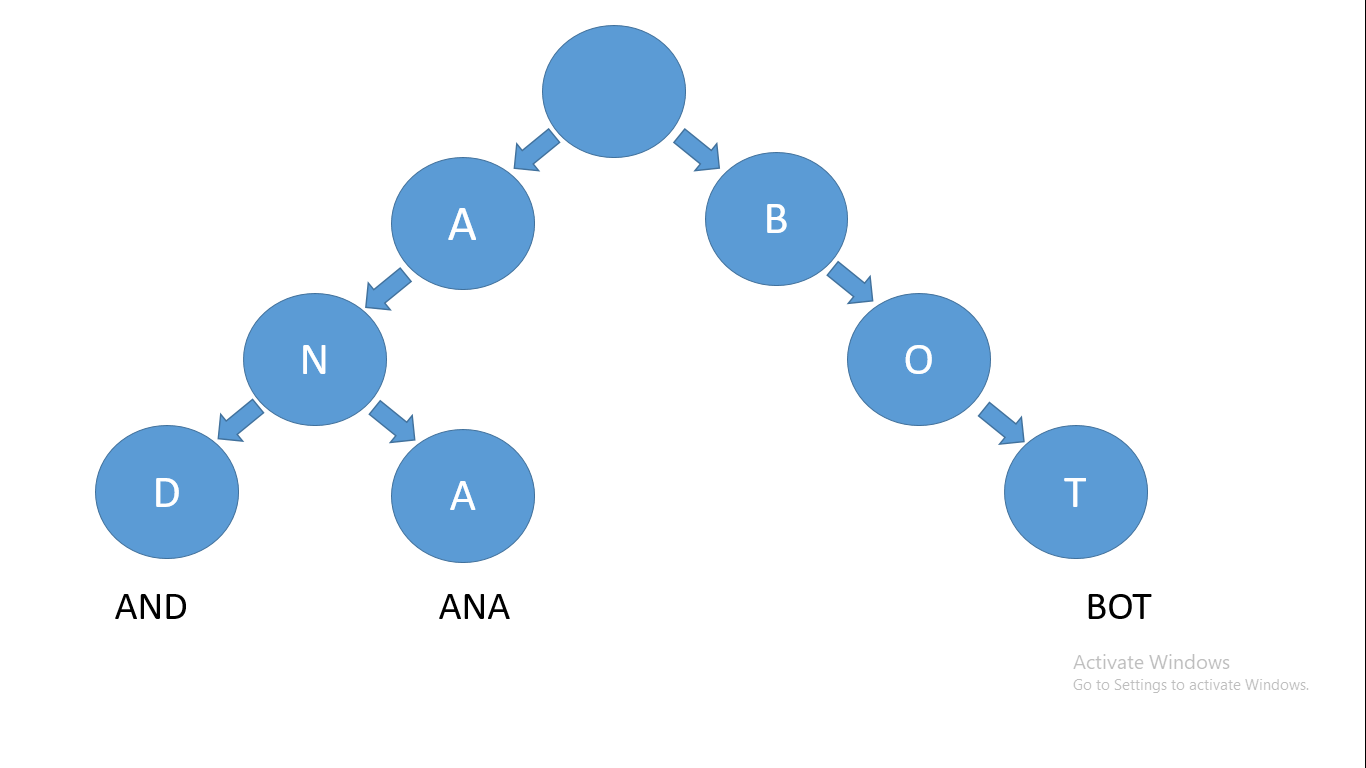 À quoi ressemble un trie
À quoi ressemble un trie
Les tries sont largement utilisés pour :
- Complétion automatique
- Correcteurs orthographiques
- Correspondance du plus long préfixe
- Historique du navigateur
Arbres de suffixes
Les arbres de suffixes sont des structures de données basées sur des arbres, mais au lieu de prendre plusieurs mots pour construire l'arbre, nous utiliserons les suffixes d'un seul mot.
Si nous considérons la chaîne AABA, nous ajouterons d'abord un signe $ à la fin de la chaîne. Ce $ facilitera la comparaison des chaînes. Maintenant, la chaîne est AABA$.
Nous considérerons tous ses suffixes et l'arbre ressemblera à ceci :
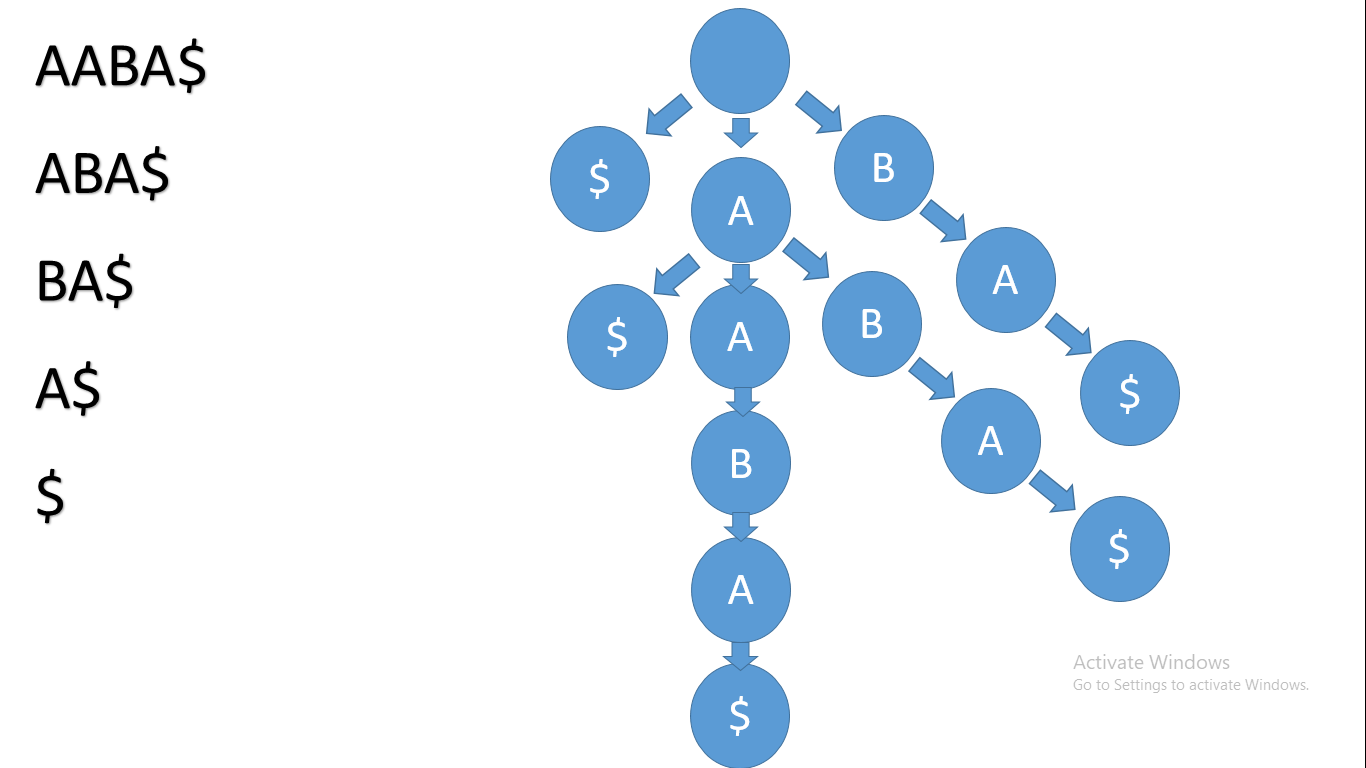 Un arbre de suffixes
Un arbre de suffixes
Transformation de Burrows Wheeler
Maintenant, nous allons discuter de la transformation de Burrows Wheeler, qui est une structure de données très utile pour la compression de chaînes.
Cette structure de données est largement utilisée en bioinformatique pour une raison très spécifique. Je veux que vous imaginiez une chaîne représentant un génome. Elle peut être très longue, comme 20 millions de caractères.
Mais il existe en fait un moyen de stocker les génomes efficacement. Imaginez la chaîne AAAAABBBAAA. Cette chaîne a de nombreuses répétitions et nous pouvons en fait compresser cette chaîne pour qu'elle ressemble à ceci : A5B3A3. Cela est très utile pour les génomes également, qui ont de nombreux caractères répétitifs.
Maintenant, prenons la chaîne BANANA. Nous ajouterons d'abord un signe $ au début de la chaîne, puis nous calculerons toutes les rotations cycliques de $BANANA. Ensuite, nous trions les rotations cycliques – et voici l'importance du signe dollar : cette valeur, lors du tri, est inférieure à toutes les valeurs de l'alphabet, ce qui facilitera grandement le tri.
Après avoir trié les rotations cycliques, la chaîne formée par les derniers caractères des rotations cycliques triées est la transformation de Burrows Wheeler. Elle ressemblera à ceci :
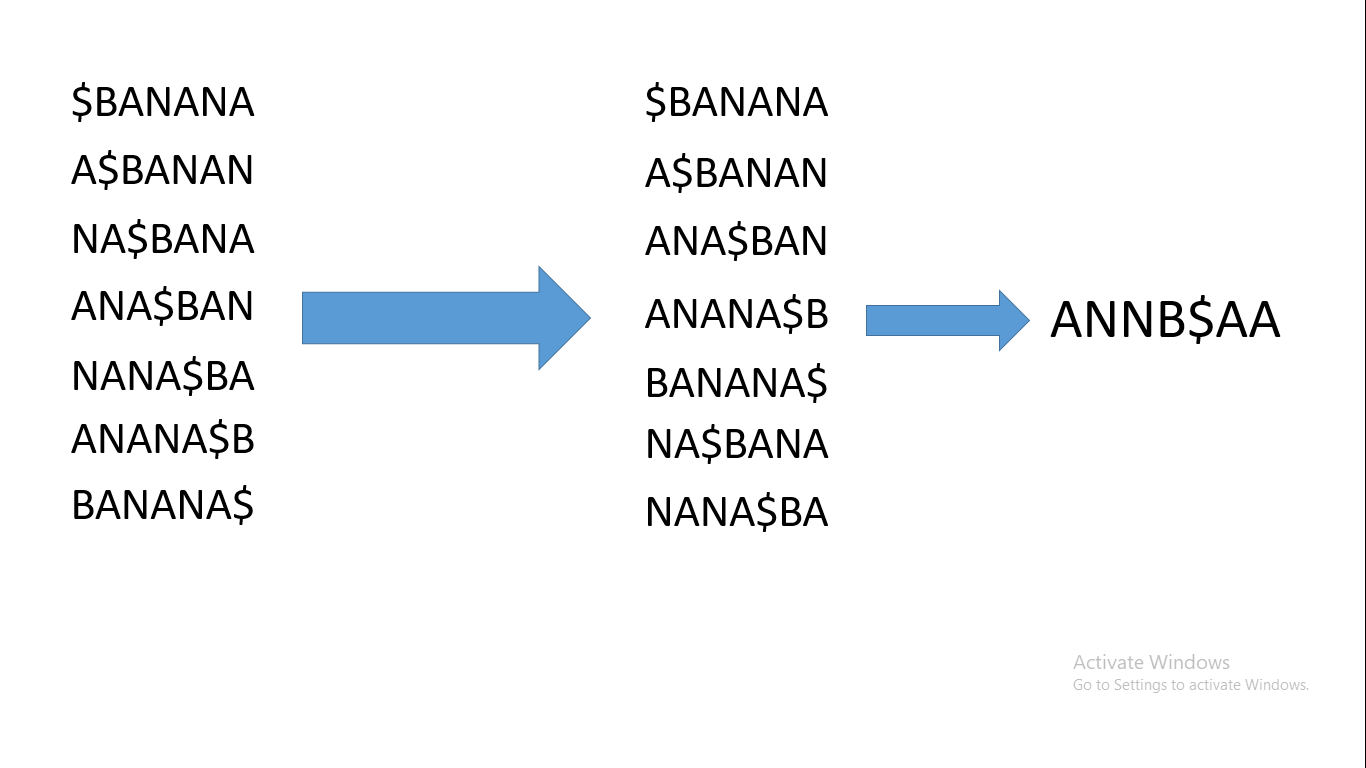 Transformation de Burrows Wheeler
Transformation de Burrows Wheeler
Maintenant, comme vous pouvez le voir, la transformation de Burrows Wheeler tend à avoir de nombreuses répétitions. Vous pourriez également demander comment inverser l'opération. Pour ce faire, regardez les premiers caractères des rotations cycliques triées. Ils sont les mêmes que les caractères de la transformation de Burrows Wheeler mais dans l'ordre trié.
Ainsi, en triant la transformation de Burrows Wheeler, nous obtiendrons les premières et les dernières lettres et nous calculerons la chaîne originale.
Algorithme de recherche naïf
Maintenant, examinons une solution par force brute pour trouver un motif dans une chaîne. Cette approche n'est pas optimale, car elle s'exécute avec une complexité temporelle de O(n*m) (où m est la longueur du motif et n est la longueur de la chaîne).
Nous considérerons deux pointeurs, I et J. Tout d'abord, nous initialiserons I et J à 0. Ensuite, nous exécuterons une boucle while qui continuera à s'exécuter tant que I est inférieur à la longueur de la chaîne.
Chaque fois que la boucle s'exécute, nous comparerons les caractères à l'index I+J dans la chaîne et le caractère à l'index J dans le motif. S'ils sont égaux, nous incrémenterons J, mais sinon, nous incrémenterons I et réinitialiserons J à 0. Si j dépasse jamais la longueur du motif, alors il y a une correspondance.
Le code pour cela ressemblera à ceci :
def Find_Match(pattern, string):
# initialiser i et j
i = 0
j = 0
while i < len(string):
if string[i+j] == pattern[j]:
j += 1
if string[i] != pattern[j]:
j = 0
i += 1
# Supposons que j est égal à la longueur du motif. Alors pour atteindre l'index de la première correspondance, nous pouvons revenir en arrière d'un nombre d'étapes égal à la longueur du motif.
if j == len(pattern):
return i - j
# Au cas où il n'y a pas de correspondance
return -1
Algorithme de Rabin-Karp
Le problème avec l'approche naïve est qu'elle s'exécute en O(n**2) de complexité temporelle, ce qui est horrible lorsqu'il s'agit de grandes entrées comme les génomes. Cela signifie que nous avons besoin de quelque chose de mieux.
Comparer deux chaînes est linéaire en temps, car nous devons comparer chaque caractère pour chaque index. Mais que se passerait-il si nous n'avions pas besoin de faire cela – que se passerait-il si nous transformions les chaînes en nombres ?
Voici l'idée principale de cet algorithme. Supposons qu'il existe une fonction qui retourne un nombre associé à chaque chaîne de l'alphabet. Nous utiliserons la valeur ASCII des chaînes pour cela.
Et ensuite, pour transformer une chaîne en un nombre, nous calculerons la somme des valeurs ASCII de tous ses caractères. Ceci est une fonction de hachage simple :
def hash(string):
count = 0
# en python ord retourne la valeur ascii d'un caractère
for i in string:
count += ord(i)
return count
Maintenant, supposons que nous voulons trouver an dans banana. Ensuite, nous comparerons d'abord hash(an) à hash(ba) puis à hash(an) et ainsi de suite jusqu'à ce que nous atteignions la fin de la chaîne. Lorsque les valeurs de hachage correspondent, nous pouvons ensuite comparer le motif et la sous-chaîne car hash(na) et hash(an) sont égaux, donc nous avons besoin d'une vérification supplémentaire.
Vous pourriez penser que c'est stupide – pourquoi devons-nous faire tout cela ? Calculer la fonction de hachage nécessite d'itérer sur la chaîne, donc nous n'avons pas atteint une meilleure complexité temporelle. Et vous avez complètement raison.
Mais que se passerait-il si nous pouvions calculer la valeur de hachage d'une sous-chaîne à partir de sa sous-chaîne précédente ? La différence est dans les caractères de début et de fin – et cela s'appelle un hachage roulant. C'est ce qui fait que cet algorithme s'exécute en O(n*m) dans le pire des cas et O(n+m) en moyenne : à cause des collisions.
Par exemple, hash(na) est égal à hash(an), donc ici nous devons comparer na et an. La fonction de hachage que je vous ai montrée est très simple. Meilleure est la fonction de hachage, moins nous aurons de collisions. Mais je ne veux pas rendre cela trop compliqué, donc je vais utiliser cette fonction de hachage.
 hachage roulant
hachage roulant
def Rabin_Karp(string, pattern):
# calculer la valeur de hachage du motif
hashed_pattern = hash(pattern)
# calculer la valeur de hachage de la première sous-chaîne avec une longueur égale à la longueur du motif
first_hash = hash(string[0:len(pattern)])
for i in range(len(string)-len(pattern)+1):
if i != 0:
first_hash -= hash(string[i-1])
first_hash += hash(string[i+len(pattern)-1])
if hashed_pattern == first_hash:
# deuxième vérification
if pattern == string[i:len(pattern)]:
return i
# au cas où aucune correspondance n'est trouvée
return -1
Algorithme de Knuth-Morris-Pratt
Maintenant, nous allons discuter du dernier algorithme pour aujourd'hui. Celui-ci est très compliqué mais je vais essayer de le rendre aussi simple que possible.
L'idée derrière cet algorithme est que l'approche naïve est excellente sauf si la chaîne et le motif ont de nombreuses répétitions – comme par exemple rechercher AAAB dans AAAXAAA. Dans ce cas, devons-nous vraiment réinitialiser le pointeur j à 0 après la première non-correspondance ? En fait, non, et je vais vous montrer pourquoi.
Lorsque nous analysons ce motif, nous pouvons voir qu'il est assez spécial. Supposons que nous avons commencé à i=0 et que nous avons atteint j=3. Ensuite, à l'itération suivante, nous avons obtenu une non-correspondance.
Nous n'avons pas vraiment besoin de réinitialiser j, puisque pour ce motif donné, nous avons les deux premiers caractères égaux aux deuxième et troisième caractères. Et puisque j était déjà 3, alors les trois premiers caractères dans la chaîne sont égaux aux trois premiers caractères dans le motif. Et les deuxième et troisième caractères dans la chaîne sont égaux aux premier et deuxième caractères dans le motif. Donc nous pouvons sauter deux positions en réinitialisant j à 2 au lieu de 0.
Maintenant, vous pourriez demander comment nous connaîtrons la valeur de j après la non-correspondance. Eh bien, la réponse dépend du motif. Par exemple abac, si nous avons obtenu une non-correspondance lorsque nous avons atteint j=3 (lorsque nous avons atteint c) et puisque ab est égal à ba, nous pouvons en fait sauter b pour l'itération suivante.
Comme vous pouvez le voir, cela fonctionne lorsque nous avons un suffixe et un préfixe communs dans une sous-chaîne d'un motif, donc nous devons pré-traiter la chaîne. Et pour chaque index de cette sous-chaîne, nous pouvons calculer le nombre de sauts et le stocker dans un tableau connu sous le nom de tableau du plus long suffixe préfixe.

Maintenant, nous allons écrire la fonction pour calculer le tableau LSP. Mais d'abord, je vais expliquer ce que je vais faire :
- le premier élément du tableau est toujours 0
- nous allons créer un tableau LSP de la même longueur que le motif
- nous aurons deux pointeurs i et prevlps. i est une variable d'itération initialement définie à 1, puisque le premier élément du tableau est toujours 0. prevlps garde une trace du précédent plus long préfixe suffixe.
- nous allons exécuter une boucle while qui continuera à s'exécuter tant que i est inférieur à la longueur du motif. Elle comparera pattern[i] et pattern[prevLps]. S'ils correspondent, nous définirons LCP[i] à prevlps +1, et nous incrémenterons i et prevlps de 1.
- s'ils ne correspondent pas et que prevlps était déjà 0, nous définirons LCP[i] à 0 et incrémenterons i.
- si prevlps n'était pas 0, nous définirons prevlps à LCP[prevlcp-1].
Prenons un exemple en utilisant la chaîne ANAN. D'abord, i était 1 et prevlps était 0. La première itération se produit, et A n'est pas égal à n et prevlps est 0 – donc le LCP est maintenant [0,0,0,0].
Maintenant, pour la deuxième itération, nous comparerons pattern[prevlps] qui est A et A qui s'évalue à vrai. Donc maintenant i est 3, prevlps est 1, et LCP est [0,0,1,0].
Et enfin, dans l'itération finale, nous comparerons N et N. La même chose se produit que dans l'itération précédente, et LCP est [0,0,1,2].
Le code pour LCP est le suivant :
def LCP(pattern):
LCP_array = [0] * len(pattern)
i = 1
prevlcp = 0
while i < len(pattern):
if pattern[i] == pattern[prevlcp]:
LCP_array[i] = prevlcp + 1
i += 1
prevlcp += 1
elif prevlcp == 0:
LCP_array[i] = 0
else:
prevlcp = LCP_array[prevlcp - 1]
return LCP_array
Maintenant que nous avons le tableau LCP, nous pouvons exécuter l'algorithme KMP. Il est similaire à l'algorithme naïf mais avec quelques améliorations. Il ressemblera à ceci :
def KMP(pattern, string):
LCP_array = LCP(pattern)
# initialiser i et j
i = 0
j = 0
while i < len(string):
if string[i+j] == pattern[j]:
j += 1
if string[i] != pattern[j]:
# La ligne qui a changé
j = LCP_array[j-1]
i += 1
# Supposons que j est égal à la longueur du motif. Alors pour atteindre l'index de la première correspondance, nous pouvons revenir en arrière d'un nombre d'étapes égal à la longueur du motif.
if j == len(pattern):
return i - j
# Au cas où il n'y a pas de correspondance
return -1
Cet algorithme s'exécute avec une complexité temporelle de O(n+m), ce qui est excellent – mais il est un peu compliqué. Si vous avez remarqué, presque rien n'a changé (juste dans le calcul du LCP et une seule ligne a changé). Cette seule ligne est ce qui rend l'algorithme si efficace.
Conclusion
En fin de compte, j'espère que vous avez appris quelque chose de nouveau dans cet article. Nous avons appris les structures de données pour la recherche ainsi que quelques algorithmes célèbres pour la recherche.
Ce tutoriel est le résultat de deux semaines de recherche. Il y a beaucoup de choses que je voulais couvrir, mais je voulais garder cela gérable.
Si vous avez trouvé cela utile et que vous souhaitez obtenir plus de contenu génial, suivez-moi sur LinkedIn. Cela aidera beaucoup.