

Article original : How to leverage Neo4j Streams and build a just-in-time data warehouse
Par Andrea Santurbano
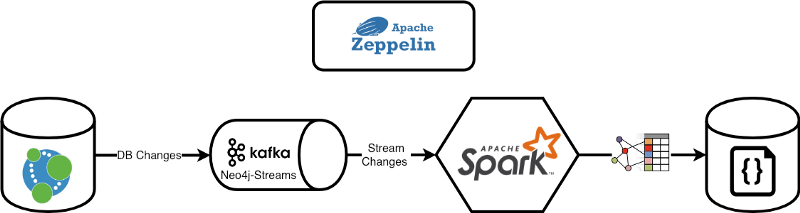
Dans cet article, nous allons montrer comment créer un Entrepôt de Données Juste-à-Temps en utilisant Neo4j et le module Neo4j Streams avec les API de Structured Streaming d'Apache Spark et Apache Kafka.
Afin de montrer comment les intégrer, simplifier l'intégration et vous permettre de tester l'ensemble du projet manuellement, j'utiliserai Apache Zeppelin, un exécutateur de notebooks qui permet d'interagir nativement avec Neo4j.
Exploiter Neo4j Streams
Le projet Neo4j Streams est composé de trois piliers principaux :
- Le Change Data Capture (le sujet de cet article) qui permet de diffuser les changements de la base de données sur des topics Kafka
- Le Sink qui permet de consommer des flux de données à partir du topic Kafka
- Un ensemble de procédures qui permet de produire/consommer des données vers/depuis des topics Kafka
Qu'est-ce qu'un Change Data Capture ?
C'est un système qui capture automatiquement les changements d'un système source (une base de données, par exemple) et fournit automatiquement ces changements aux systèmes en aval pour une variété de cas d'utilisation.
Le CDC fait généralement partie d'un pipeline ETL. C'est un composant important pour s'assurer que les entrepôts de données (DWH) sont maintenus à jour avec les changements de données.
Traditionnellement, les applications CDC fonctionnaient à partir des journaux de transactions, permettant ainsi de répliquer les bases de données sans avoir un impact significatif sur leurs performances.
Comment le module CDC de Neo4j Streams gère-t-il les changements de la base de données ?
Chaque transaction dans Neo4j est capturée et transformée pour diffuser un élément atomique de la transaction.
Supposons que nous avons une création simple de deux nœuds et une relation entre eux :
CREATE (andrea:Person{name:"Andrea"})-[knows:KNOWS{since:2014}]->(michael:Person{name:"Michael"})
Le module CDC transformera cette transaction en 3 événements (2 créations de nœuds, 1 création de relation).
La structure de l'événement a été inspirée par le format Debezium et a la structure générale suivante :
{ "meta": { /* méta-données de la transaction */ }, "payload": { /* les données liées à la transaction */ "before": { /* les données avant la transaction */}, "after": { /* les données après la transaction */} }}
Nœud source (andrea) :
{ "meta": { "timestamp": 1532597182604, "username": "neo4j", "tx_id": 1, "tx_event_id": 0, "tx_events_count": 3, "operation": "created", "source": { "hostname": "neo4j.mycompany.com" } }, "payload": { "id": "1004", "type": "node", "after": { "labels": ["Person"], "properties": { "name": "Andrea" } } }}
Nœud cible (michael) :
{ "meta": { "timestamp": 1532597182604, "username": "neo4j", "tx_id": 1, "tx_event_id": 1, "tx_events_count": 3, "operation": "created", "source": { "hostname": "neo4j.mycompany.com" } }, "payload": { "id": "1006", "type": "node", "after": { "labels": ["Person"], "properties": { "name": "Michael" } } }}
Relation knows :
{ "meta": { "timestamp": 1532597182604, "username": "neo4j", "tx_id": 1, "tx_event_id": 2, "tx_events_count": 3, "operation": "created", "source": { "hostname": "neo4j.mycompany.com" } }, "payload": { "id": "1007", "type": "relationship", "label": "KNOWS", "start": { "labels": ["Person"], "id": "1005" }, "end": { "labels": ["Person"], "id": "106" }, "after": { "properties": { "since": 2014 } } }}
Par défaut, toutes les données seront diffusées sur le topic neo4j. Le module CDC permet de contrôler quels nœuds sont envoyés à Kafka, et quelles propriétés de ces nœuds vous souhaitez envoyer au topic :
streams.source.topic.nodes.<TOPIC_NAME>=<PATTERN>
Avec l'exemple suivant :
streams.source.topic.nodes.products=Product{name, code}
Le module CDC enverra au topic products tous les nœuds qui ont le label Product. Il envoie ensuite, à ce topic, uniquement les changements concernant les propriétés name et code. Veuillez consulter la documentation officielle pour une description complète sur le fonctionnement du filtrage des labels.
Pour une description plus approfondie du projet Neo4j Streams et comment/nous avons construit ce projet chez LARUS et Neo4j, consultez cet article qui fournit une description approfondie.
Au-delà de l'entrepôt de données traditionnel
Un DWH traditionnel nécessite que les équipes de données construisent constamment plusieurs pipelines coûteux et chronophages d'extraction, transformation et chargement (ETL) pour finalement obtenir des informations commerciales.
L'un des plus grands points de douleur est que, en raison de son architecture rigide difficile à changer, les entrepôts de données d'entreprise sont inherently rigides. Cela est dû au fait que :
- ils sont basés sur l'architecture Schema-On-Write : d'abord, vous définissez votre schéma, puis vous écrivez vos données, puis vous lisez vos données et elles reviennent dans le schéma que vous avez défini au préalable
- ils sont basés sur des travaux par lots/planifiés (coûteux)
Cela entraîne la nécessité de construire des pipelines ETL coûteux et chronophages pour accéder et manipuler les données. Et comme de nouveaux types de données et sources sont introduits, le besoin d'augmenter vos pipelines ETL aggrave le problème.
Grâce à la combinaison du traitement des données en flux avec le module CDC de Neo4j Streams et l'approche Schema-On-Read fournie par Apache Spark, nous pouvons surmonter cette rigidité et construire un nouveau type de DWH (flexible).
Un changement de paradigme : Entrepôt de Données Juste-à-Temps
Une solution JIT-DWH est conçue pour gérer facilement une plus grande variété de données provenant de différentes sources et commence à partir d'une approche différente sur la manière de traiter et de gérer les données : Schema-On-Read.
Schema-On-Read
Schema-On-Read suit une séquence différente : il charge simplement les données telles qu'elles sont et applique votre propre interprétation aux données lorsque vous les lisez. Avec ce type d'approche, vous pouvez présenter les données dans un schéma qui est le mieux adapté aux requêtes émises. Vous n'êtes pas coincé avec un schéma unique. Avec le schema-on-read, vous pouvez présenter les données dans un schéma qui est le plus pertinent pour la tâche à accomplir.
Installation de l'Environnement
En allant sur le dépôt Github, vous trouverez tout ce dont vous avez besoin pour reproduire ce que je présente dans cet article. Ce dont vous aurez besoin pour commencer est Docker. Ensuite, vous pouvez simplement démarrer la pile en entrant dans le répertoire et, depuis le terminal, exécuter la commande suivante :
$ docker-compose up
Cela démarrera l'ensemble de l'environnement qui comprend :
- Neo4j + module Neo4j Streams + procédures APOC
- Apache Kafka
- Apache Spark
- Apache Zeppelin
En allant dans Apache Zeppelin @ http://localhost:8080, vous trouverez dans le répertoire Medium/Part 1 deux notebooks :
- Créer un Entrepôt de Données Juste-à-Temps : dans ce notebook, nous construirons le JIT-DWH
- Interroger le JIT-DWH : dans ce notebook, nous effectuerons quelques requêtes sur le JIT-DWH
Le Cas d'Utilisation :
Nous créerons un jeu de données de type réseau social fictif. Cela activera le module CDC de Neo4j Stream, et via Apache Spark, nous intercepterons cet événement et les persisterons sur le système de fichiers au format JSON.
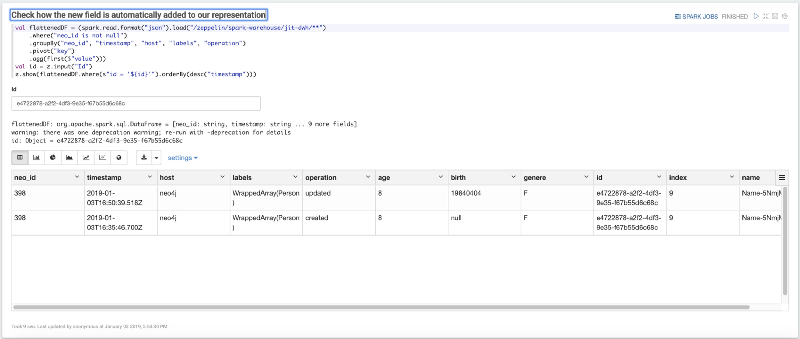
Ensuite, nous démontrerons comment de nouveaux champs ajoutés dans nos nœuds seront automatiquement ajoutés à notre JIT-DWL sans modification du pipeline ETL, grâce à l'approche Schema-On-Read.
Nous exécuterons les étapes suivantes :
- Créer le jeu de données fictif
- Construire notre pipeline de données qui intercepte les événements Kafka publiés par le module CDC de Neo4j Streams
- Effectuer la première requête sur notre JIT-DWH sur Spark
- Ajouter un nouveau champ dans notre modèle de graphe
- Montrer comment le nouveau champ est automatiquement exposé en temps réel grâce au module CDC de Neo4j Streams (sans besoin de modifications de notre pipeline ETL grâce à l'approche Schema-On-Read).
Notebook 1 : Créer un Entrepôt de Données Juste-à-Temps
Nous créerons un réseau social fictif en utilisant la procédure APOC apoc.periodic.repeat qui exécute cette requête toutes les 15 secondes :
WITH ["M", "F", ""] AS genderUNWIND range(1, 10) AS idCREATE (p:Person {id: apoc.create.uuid(), name: "Name-" + apoc.text.random(10), age: round(rand() * 100), index: id, gender: gender[toInteger(size(gender) * rand())]})WITH collect(p) AS peopleUNWIND people AS p1UNWIND range(1, 3) AS friendWITH p1, people[(p1.index + friend) % size(people)] AS p2CREATE (p1)-[:KNOWS{years: round(rand() * 10), engaged: (rand() > 0.5)}]->(p2)
Si vous avez besoin de plus de détails sur le projet APOC, veuillez suivre ce lien.
Ainsi, le modèle de graphe résultant est assez simple :

Créons un index sur le nœud Person :
%neo4jCREATE INDEX ON :Person(id)
Maintenant, définissons le travail en arrière-plan dans Neo4j :
%neo4jCALL apoc.periodic.repeat('create-fake-social-data', 'WITH ["M", "F", "X"] AS gender UNWIND range(1, 10) AS id CREATE (p:Person {id: apoc.create.uuid(), name: "Name-" + apoc.text.random(10), age: round(rand() * 100), index: id, gender: gender[toInteger(size(gender) * rand())]}) WITH collect(p) AS people UNWIND people AS p1 UNWIND range(1, 3) AS friend WITH p1, people[(p1.index + friend) % size(people)] AS p2 CREATE (p1)-[:KNOWS{years: round(rand() * 10), engaged: (rand() > 0.5)}]->(p2)', 15) YIELD nameRETURN name AS created
Cette requête en arrière-plan amène le module CDC de Neo4j-Streams à diffuser des événements liés sur le topic Kafka "neo4j" (le topic par défaut du CDC).
Maintenant, créons un jeu de données de streaming structuré qui consomme les données du topic "neo4j" :
val kafkaStreamingDF = (spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "broker:9093") .option("startingoffsets", "earliest") .option("subscribe", "neo4j") .load())
Le Dataframe kafkaStreamingDF est essentiellement une représentation de ProducerRecord. Et en fait, son schéma est :
root|-- key: binary (nullable = true)|-- value: binary (nullable = true)|-- topic: string (nullable = true)|-- partition: integer (nullable = true)|-- offset: long (nullable = true)|-- timestamp: timestamp (nullable = true)|-- timestampType: integer (nullable = true)
Maintenant, créons la structure des données diffusées par le CDC en utilisant les API Spark afin de lire les données diffusées :
val cdcMetaSchema = (new StructType() .add("timestamp", LongType) .add("username", StringType) .add("operation", StringType) .add("source", MapType(StringType, StringType, true))) val cdcPayloadSchemaBeforeAfter = (new StructType() .add("labels", ArrayType(StringType, false)) .add("properties", MapType(StringType, StringType, true))) val cdcPayloadSchema = (new StructType() .add("id", StringType) .add("type", StringType) .add("label", StringType) .add("start", MapType(StringType, StringType, true)) .add("end", MapType(StringType, StringType, true)) .add("before", cdcPayloadSchemaBeforeAfter) .add("after", cdcPayloadSchemaBeforeAfter)) val cdcSchema = (new StructType() .add("meta", cdcMetaSchema) .add("payload", cdcPayloadSchema))
Le cdcSchema est adapté pour les événements de nœuds et de relations.
Ce dont nous avons besoin maintenant, c'est d'extraire uniquement l'événement CDC du Dataframe, alors effectuons une simple requête de transformation sur Spark :
val cdcDataFrame = (kafkaStreamingDF .selectExpr("CAST(value AS STRING) AS VALUE") .select(from_json('VALUE, cdcSchema) as 'JSON))
Le cdcDataFrame contient juste une colonne JSON qui est la donnée diffusée par le module CDC de Neo4j-Streams.
Effectuons une simple requête ETL afin d'extraire les champs d'intérêt :
val dataWarehouseDataFrame = (cdcDataFrame .where("json.payload.type = 'node' and (array_contains(nvl(json.payload.after.labels, json.payload.before.labels), 'Person'))") .selectExpr("json.payload.id AS neo_id", "CAST(json.meta.timestamp / 1000 AS Timestamp) AS timestamp", "json.meta.source.hostname AS host", "json.meta.operation AS operation", "nvl(json.payload.after.labels, json.payload.before.labels) AS labels", "explode(json.payload.after.properties)"))
Cette requête est assez importante, car elle représente comment les données seront persistées sur le système de fichiers. Chaque nœud sera explosé en un certain nombre de fragments JSON, un pour chaque propriété de nœud, comme ceci :
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"name","value":"Name-5wc62uKO5l"}
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"index","value":"8"}
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"id","value":"944e58bf-0cf7-49cf-af4a-c803d44f222a"}
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"gender","value":"F"}
Ce type de structure peut être facilement transformé en représentation tabulaire (nous verrons dans les prochaines étapes comment faire cela).
Maintenant, écrivons une requête de streaming continue Spark qui sauvegarde les données sur le système de fichiers au format JSON :
val writeOnDisk = (dataWarehouseDataFrame .writeStream .format("json") .option("checkpointLocation", "/zeppelin/spark-warehouse/jit-dwh/checkpoint") .option("path", "/zeppelin/spark-warehouse/jit-dwh") .queryName("nodes") .start())
Nous avons maintenant créé un simple JIT-DWH. Dans le deuxième notebook, nous apprendrons comment l'interroger et à quel point il est simple de gérer les changements dynamiques dans les structures de données grâce au schéma à la lecture.
Notebook 2 : Interroger le JIT-DWH
Le premier paragraphe nous permet d'interroger et d'afficher notre JIT-DWH
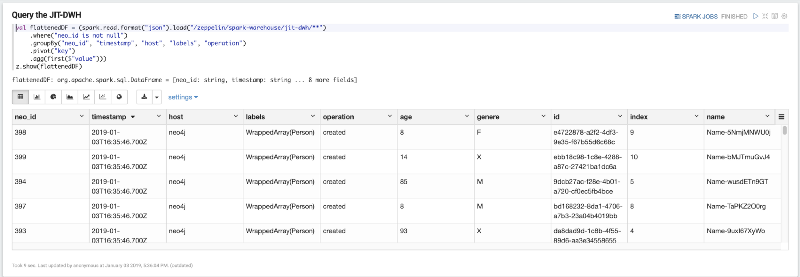
val flattenedDF = (spark.read.format("json").load("/zeppelin/spark-warehouse/jit-dwh/**") .where("neo_id is not null") .groupBy("neo_id", "timestamp", "host", "labels", "operation") .pivot("key") .agg(first($"value")))z.show(flattenedDF)
Souvenez-vous comment nous avons sauvegardé les données en JSON quelques lignes plus haut ? Le flattenedDF a simplement pivoté les JSON sur le champ key, regroupant ainsi les données sur 5 colonnes qui représentent la "clé unique" (_"neoid", "timestamp", "host", "labels", "operation"). Cela nous permet d'avoir cette représentation tabulaire des données sources comme suit :
Maintenant, imaginez que notre jeu de données Person obtient un nouveau champ : birth. Ajoutons ce nouveau champ à un nœud ; dans ce cas, vous devez choisir un id dans votre jeu de données et le mettre à jour avec le paragraphe suivant :
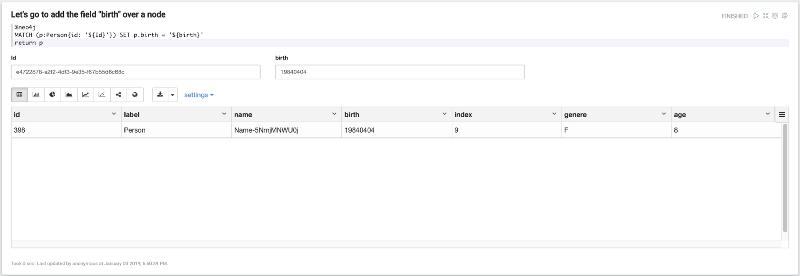
Maintenant, la dernière étape : réutilisez la même requête et filtrez le DWH par l'id que nous avons précédemment modifié afin de vérifier comment notre jeu de données a changé selon les modifications apportées à Neo4j.
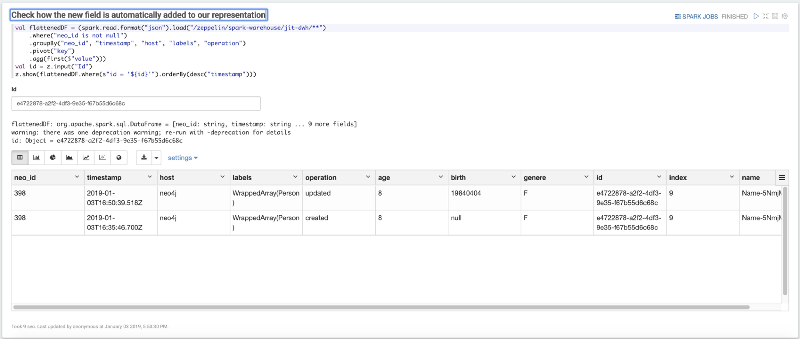
Conclusions
Dans cette première partie, nous avons appris comment exploiter les événements produits par le module CDC de Neo4j Stream afin de construire un simple (en temps réel) JIT-DWL qui utilise l'approche Schema-On-Read.
Dans la partie 2, nous découvrirons comment utiliser le module Sink afin d'ingérer des données dans Neo4j directement depuis Kafka.
Si vous avez déjà testé le module Neo4j-Streams ou l'avez testé via ces notebooks, veuillez remplir notre enquête de feedback.
Si vous rencontrez des problèmes ou avez des idées pour améliorer notre travail, veuillez ouvrir une issue GitHub.