

Salut à tous ! Aujourd'hui, vous allez apprendre à déployer un conteneur Postgres dans Azure Kubernetes Service (AKS) et à le connecter à une application Node.js.
Dans ce paysage de développement rapide, le déploiement via des conteneurs, en particulier avec Kubernetes, devient de plus en plus populaire. Certaines entreprises effectuent de nombreux déploiements quotidiennement, il est donc crucial pour vous d'apprendre ces technologies.
Kubernetes est un choix populaire pour déployer des applications conteneurisées comme des serveurs web, des bases de données et des API. Vous pouvez configurer Kubernetes soit localement, soit dans le cloud. Dans ce tutoriel, nous explorerons la configuration de Kubernetes sur une plateforme cloud, spécifiquement Azure.
Je vais vous guider à travers le processus de configuration de Kubernetes en utilisant Azure Kubernetes Service (AKS). Vous configurerez votre fichier YAML en utilisant StatefulSet, Persistent Volume et Services pour déployer une base de données PostgreSQL sur Azure Kubernetes. Ensuite, vous obtiendrez les informations d'identification de la base de données PostgreSQL s'exécutant à l'intérieur de l'AKS et les utiliserez pour établir une connexion avec une application Node.js.
Nous aborderons des concepts clés tels que le déploiement, les stateful sets, les volumes persistants et les services, vous préparant à déployer efficacement un conteneur Postgres sur AKS. Je vous aiderai également à connecter votre application Node.js Express au conteneur Postgres dans le cluster AKS.
Alors, installez-vous confortablement et préparez-vous, car nous allons plonger dans le sujet.
Prérequis
Avant de commencer, il est important de comprendre certains concepts de base dans Kubernetes comme les pods, les deployments, les services et les nodes.
Si vous êtes nouveau dans ce domaine, je vous recommande de consulter la vidéo Stashchuk freeCodeCamp vidéo pour un tutoriel adapté aux débutants.
Vous aurez également besoin d'un compte et d'un abonnement actif Azure pour suivre.
Table des matières
Problèmes que nous essayons de résoudre
– Deployments
– StatefulSets
– Persistent VolumesAzure Kubernetes Service (AKS)
– Connectez-vous à votre portail Azure
– Créer une ressource
– Créer un nouveau conteneur
– Créer un nouveau Azure Kubernetes Service (AKS)
– Créer un nouveau groupe de ressources
– Donnez un nom à votre cluster Kubernetes
– Accédez à la page du pool de nœuds
– Activer les journaux de conteneurs et configurer les alertes
– Section avancée
– BalisesSe connecter à votre cluster AKS
– Télécharger Azure CLI et kubectl
– Vérifier si Azure CLI est installé
– Vérifier si kubectl est installé
– Se connecter au compte Azure
– Configurer kubectlComment créer des ressources avec YAML
– Cloner le dépôt
– Ouvrir le dépôt
– Installer les dépendancesConfiguration YAML
– StorageClass
– PersistentVolumeClaim
– ConfigMap
– StatefulSet
– ServiceComment déployer une ressource YAML vers Azure
– Déployer la ressource YAMLApplication Node.js
– Configurer Nodejs
– Exécuter l'application Nodejs
– Tester l'application
– Ouvrir Postman
– Confirmer les données
– Supprimer le Pod
– Persistance des données
Problèmes que nous essayons de résoudre
Tout d'abord, qu'est-ce que Kubernetes ? Eh bien, c'est comme un gestionnaire pour vos conteneurs logiciels. Il vous aide à exécuter et à gérer de nombreux conteneurs comme des serveurs web, des bases de données, des microservices et des API qui sont comme de petits paquets contenant vos applications.
Kubernetes s'occupe de choses comme le démarrage, l'arrêt et la mise à l'échelle de ces conteneurs, afin que vos applications fonctionnent sans problème même lorsqu'il y a plus de charge sur votre application. Il est populaire car il facilite l'exécution de logiciels dans le cloud et les rend plus fiables.
Maintenant, parlons de la manière de résoudre certains problèmes que vous pourriez rencontrer avec une application réelle exécutant Postgres dans un cluster de production Kubernetes.
Imaginez que l'infrastructure hébergeant votre Postgres tombe en panne, vous faisant perdre tous les services et données stockés dans la base de données. Ou imaginez un scénario où la base de données Postgres devient corrompue, entraînant une perte de données.
Dans les deux cas, vous avez besoin d'un moyen de sauvegarder votre application afin de pouvoir la restaurer à un état fonctionnel si un désastre survient.
Alors, comment capturez-vous une sauvegarde complète de l'application qui inclut toutes les données nécessaires ? Cette sauvegarde devrait vous permettre de restaurer l'ensemble de l'application, y compris la base de données, si vous perdez votre cluster ou rencontrez une perte de données.
Dans Kubernetes, pensez à un Pod comme la plus petite unité que vous pouvez déployer. C'est comme une petite boîte qui contient une chose, comme un serveur web ou une base de données. Donc, si votre Pod ne fonctionne pas, votre serveur web ou votre base de données non plus.
Cela signifie que si le cluster où votre Pod s'exécute est détruit, toutes les données dans le Pod disparaissent également. Tous les nœuds (machines virtuelles qui exécutent votre application sur le réseau) seront également effacés.
Comment pouvez-vous faire en sorte qu'un pod reste sur un nœud spécifique où se trouvent les données et ne bouge jamais ? Et comment pouvez-vous vous assurer que chaque pod peut être trouvé séparément lorsque vous utilisez un équilibreur de charge ?
Une solution consiste à considérer comment vous déployez votre application sur Kubernetes. Typiquement, vous créez un déploiement et l'exposez en utilisant un service, en spécifiant le type de service comme Cluster type, NodePort, ou LoadBalancer.
Mais toutes les applications ne sont pas identiques en ce qui concerne l'état. Certaines applications, connues sous le nom d'applications sans état, ne dépendent pas du stockage de données localement, donc perdre leur état n'est pas un gros problème.
Mais pour des applications comme les bases de données ou les caches, maintenir l'état est crucial car elles dépendent du stockage. Dans Kubernetes, déployer des applications avec état comme les bases de données en utilisant simplement un déploiement n'est pas idéal. Vous avez besoin d'une solution qui garantit que les données de votre application sont stockées en toute sécurité et peuvent être récupérées en cas de défaillance.
Deployments
Vous vous demandez peut-être pourquoi nous ne pouvons pas simplement utiliser un déploiement Kubernetes pour déployer Postgres dans le cluster Kubernetes ? Eh bien, le problème est que beaucoup de gens ne connaissent pas la différence entre un déploiement et un stateful set.
Imaginons que vous avez un pod qui s'exécute dans votre cluster que vous avez créé en utilisant un déploiement. Ensuite, vous avez mis à l'échelle jusqu'à deux pods, donc vous avez maintenant le Pod A et le Pod B.
Le problème survient parce que, par défaut, les pods créés dans le cadre du même déploiement partagent le même volume persistant (PV) dans le cluster. Donc, lorsque vous avez mis à l'échelle, les deux instances de Postgres écriront sur le même stockage, ce qui pourrait entraîner une corruption des données.
Un autre problème survient du point de vue du réseau. Les Pods A et B n'ont pas de moyen fiable de communiquer entre eux sur le réseau. Par défaut, les pods Kubernetes n'ont pas leurs propres noms DNS. Au lieu de cela, vous dépendez des services pour exposer les ports à d'autres applications dans le cluster.
Si vous examinez de plus près les noms des pods, vous remarquerez que les pods se voient attribuer un hachage aléatoire à la fin de leurs noms. À cause de cela, les pods manquent d'une identité réseau cohérente. Chaque fois qu'un pod est détruit et recréé, il reçoit un nouveau nom aléatoire. Cette incohérence n'est pas idéale pour un réseau fiable.
Postgres n'est pas naturellement conçu pour Kubernetes, et Kubernetes peut être difficile lorsqu'il gère des tâches avec état. Pour configurer une instance Postgres, vous devez connaître la bonne configuration Kubernetes. Vous ne pouvez pas simplement le mettre dans un pod, car si le pod tombe en panne, vos données aussi. Mais, pour une intégration rapide, un pod pourrait fonctionner correctement.
Les déploiements ne sont pas non plus idéaux, puisque vous ne voulez pas que votre pod soit placé aléatoirement sur un nœud. Mais pour les tests, les déploiements sont pratiques si vous avez juste besoin d'une instance Postgres pour fonctionner temporairement.
Ce que vous voulez vraiment, c'est un pod qui reste sur un nœud particulier où se trouvent vos données, et qui ne bouge pas. De plus, vous voulez également que votre pod soit adressable individuellement. Pour cela, nous avons besoin de ce que nous appelons un statefulSet.
StatefulSets
Lorsque vous mettez à jour votre déploiement pour devenir un StatefulSet, Kubernetes introduit certaines améliorations pour le déploiement de charges de travail avec état. Un changement majeur est la manière dont il gère la mise à l'échelle.
Si vous spécifiez que vous voulez trois répliques de votre StatefulSet, Kubernetes ne créera pas les trois pods en même temps. Au lieu de cela, il les crée un par un. Chaque pod obtient son propre nom DNS unique, commençant par le nom du pod suivi d'un numéro ordinal commençant à zéro. Donc, lorsque vous mettez à l'échelle, le numéro ordinal augmente pour chaque nouveau pod.
Voici la partie intéressante : si un pod comme Pod-0 est détruit et doit être recréé, il reviendra avec le même nom. Cela signifie que chaque pod a une adresse spécifique, même s'il est remplacé.
Et voici une autre fonctionnalité intéressante : chaque pod dans un StatefulSet obtient son propre volume persistant (PV). Cela vous permet de conserver le même stockage même si vous mettez à l'échelle ou réduisez. Cela nous amène à un autre concept appelé volumes persistants.
Persistent Volumes
Oublions un instant les pods, le déploiement et les conteneurs. Qu'est-ce que l'"état" exactement ? En termes simples, l'état est les données dont vos applications ont besoin pour fonctionner correctement.
Maintenant, lorsque nous parlons de processus, il existe deux types : sans état et avec état. Les processus sans état ne dépendent d'aucune donnée pour fonctionner. Ils font simplement leur travail sans avoir besoin d'informations spécifiques. En revanche, les processus avec état ont besoin de données ou d'état pour fonctionner correctement.
Maintenant, où stockez-vous cet état ? Il y a deux endroits principaux : la mémoire et le disque. La mémoire permet un accès rapide aux données, ce qui est idéal pour des applications comme Redis, MongoDB, Postgres ou MySQL. Ils stockent leur état en mémoire pour un accès rapide. Mais pour la persistance, ils le stockent sur disque dans le système de fichiers (pour un stockage plus permanent).
Pourquoi le système de fichiers ? Parce que c'est le seul moyen de maintenir l'état persistant même lorsque le système redémarre. Donc, lorsqu'un processus meurt et est recréé, il peut lire son état à partir du système de fichiers.
J'aime décomposer les choses car j'enseignais des trucs techniques. Maintenant, plongeons dans la configuration de Kubernetes dans Azure.
Azure Kubernetes Service (AKS)
Dans cette section, je vais vous guider à travers la configuration d'un cluster Kubernetes sur Azure.
Étape 1 : Connectez-vous à votre portail Azure
Pour commencer, vous devrez vous connecter à votre portail Azure. Une fois connecté, vous devriez voir un tableau de bord similaire à celui-ci :
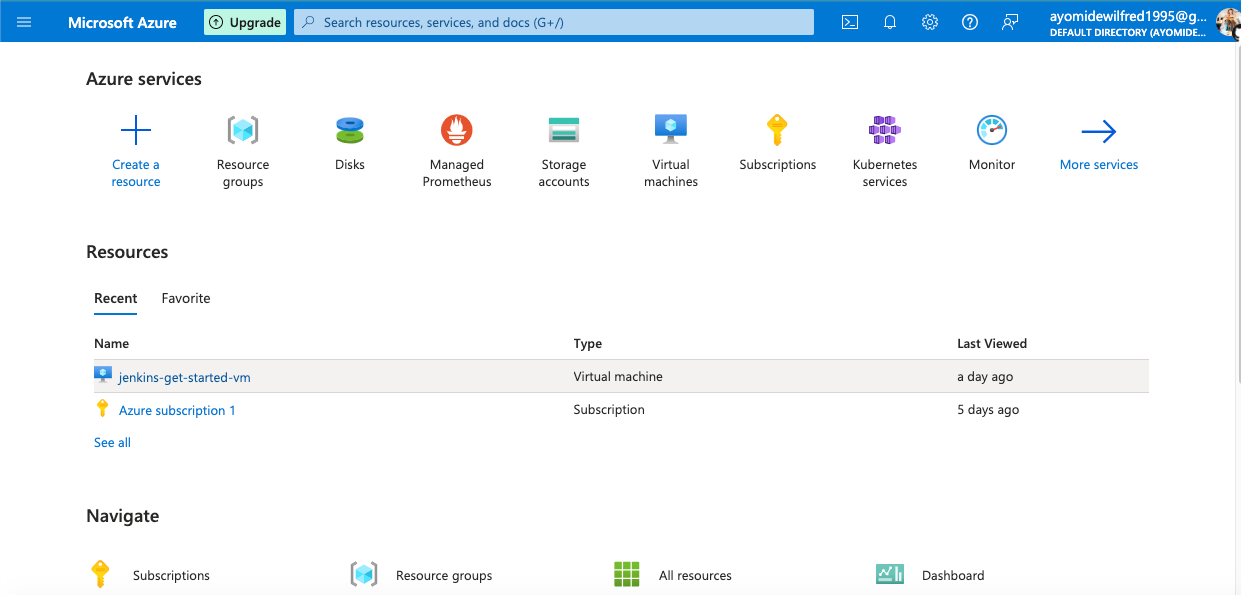
Page d'accueil du portail Azure
Étape 2 : Créer une ressource
Cliquez sur "créer une ressource" pour créer une ressource.
Les ressources sont les divers services, composants et actifs que vous pouvez créer et gérer au sein de la plateforme cloud Azure. Ces ressources peuvent inclure des machines virtuelles, des bases de données, des comptes de stockage, des composants réseau, des applications web, et plus encore.

Création d'une ressource dans le portail Azure
Étape 3 : Créer un nouveau conteneur
Ensuite, naviguez vers la catégorie "Conteneurs" à partir des options disponibles dans le volet de gauche. Cliquez sur Conteneurs comme indiqué par la flèche dans la capture d'écran.
Encore une fois, Kubernetes est une plateforme d'orchestration de conteneurs. Elle gère et orchestrer le déploiement, la mise à l'échelle et l'exploitation des conteneurs d'applications à travers des clusters de machines. Kubernetes fournit un cadre pour automatiser le déploiement, la mise à l'échelle et la gestion des applications conteneurisées.

Création d'un nouveau conteneur (Kubernetes) dans Azure
Étape 4 : Créer un nouveau Azure Kubernetes Service (AKS)
Sélectionnez "Azure Kubernetes Service (AKS)" dans la liste des services de conteneurs disponibles et cliquez sur Créer. Cela vous mènera à la page de création d'AKS.
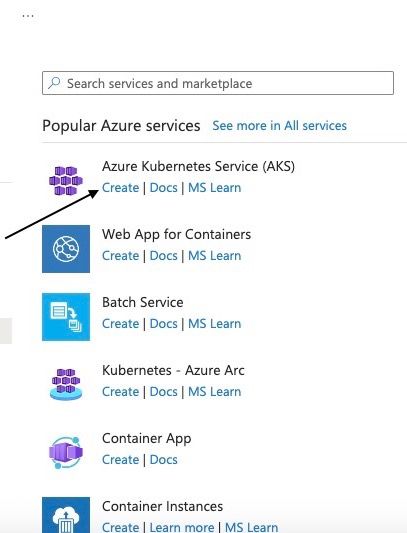
Création d'un nouveau service Azure Kubernetes
Étape 5 : Créer un nouveau groupe de ressources
Dans la section "Groupe de ressources", cliquez sur "Créer nouveau" pour créer un nouveau groupe de ressources pour votre déploiement Azure Kubernetes Service (AKS).
Dans Azure, un "groupe de ressources" est un conteneur logique utilisé pour regrouper des ressources Azure connexes. Il sert de moyen pour organiser et gérer ces ressources collectivement, plutôt que individuellement.
Lorsque vous créez des ressources telles que des machines virtuelles, des bases de données, des comptes de stockage ou tout autre service Azure, vous les associez généralement à un groupe de ressources.
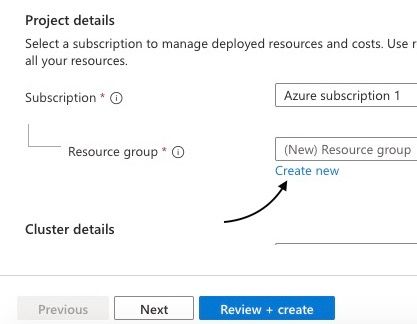
Création d'un nouveau groupe de ressources dans le portail azure
Nommons le groupe de ressources "AZURE-POSTGRES-RG" comme indiqué ci-dessous. Vous pouvez le nommer comme vous le souhaitez. Ensuite, cliquez sur OK.
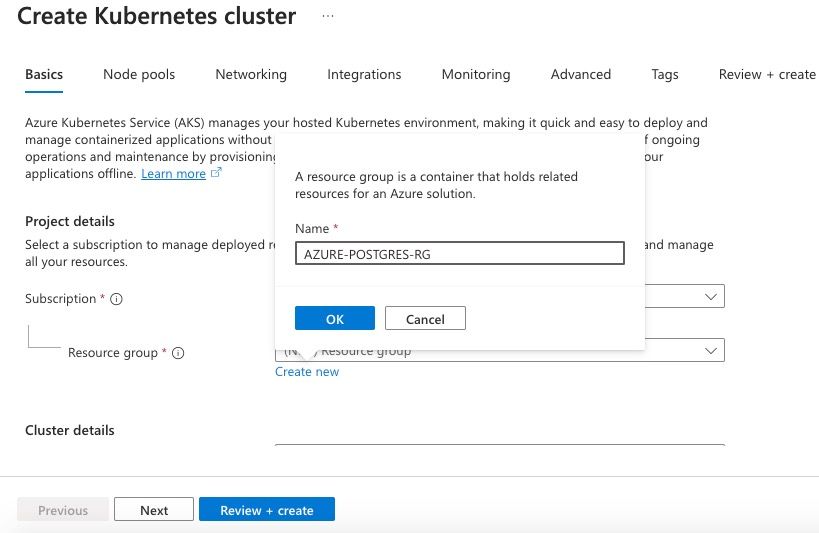
Saisie du nom pour le groupe de ressources
Étape 6 : Donnez un nom à votre cluster Kubernetes
Maintenant, nommons la session de configuration du cluster Kubernetes "Nom du cluster Kubernetes".
Dans Azure, un cluster Kubernetes est un service d'orchestration de conteneurs géré fourni par Azure Kubernetes Service (AKS). Il vous permet de déployer, gérer et mettre à l'échelle des applications conteneurisées en utilisant Kubernetes sans avoir à gérer l'infrastructure sous-jacente.
Donnez-lui un nom comme "AZURE-POSTGRES-KC" et sélectionnez une région proche de vous. Dans mon cas, je sélectionne (Asie Pacifique) Asie de l'Est et cliquez sur suivant.
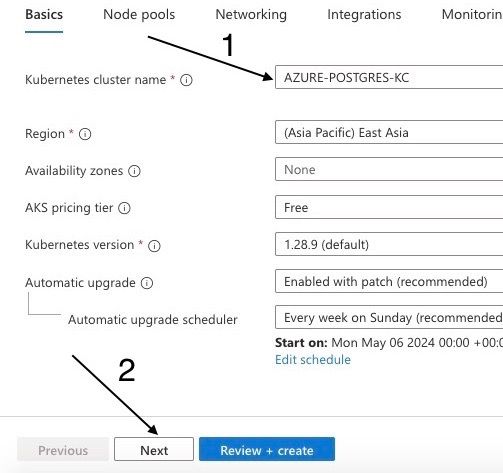
Nommer le cluster Kubernetes
Étape 7 : Accédez à la page du pool de nœuds
Il est maintenant temps de configurer la session du pool de nœuds en cliquant sur agentpool.
Dans Azure, un pool de nœuds est un groupe de machines virtuelles (VM) qui sont provisionnées et gérées ensemble au sein d'un cluster Azure Kubernetes Service (AKS). Chaque pool de nœuds exécute une version spécifique de Kubernetes et a son propre ensemble de configurations, telles que la taille de la VM, l'image du système d'exploitation et le nombre de nœuds.
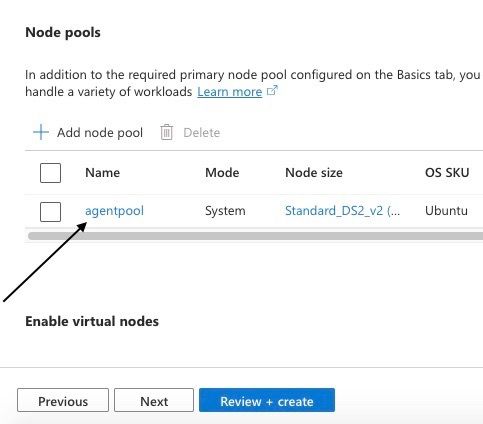
Édition de l'agentpool
Définissez le nombre minimum de nœuds à 1, le nombre maximum de nœuds à 2 et le nombre maximum de pods par nœud à 30 pour minimiser les coûts. Ensuite, cliquez sur mettre à jour.
Ces paramètres aident à contrôler la taille et le comportement du pool de nœuds dans un cluster Azure Kubernetes Service (AKS) :
Nombre minimum de nœuds : Garantit qu'un nombre minimum de nœuds sont toujours disponibles pour des performances et une disponibilité constantes, même pendant les périodes de faible demande.
Nombre maximum de nœuds : Définit une limite supérieure au nombre de nœuds dans le pool de nœuds pour gérer les coûts et éviter le sur-provisionnement.
Nombre maximum de pods par nœud : Définit le nombre maximum de pods qui peuvent s'exécuter sur chaque nœud, optimisant l'utilisation des ressources et évitant la surcharge.
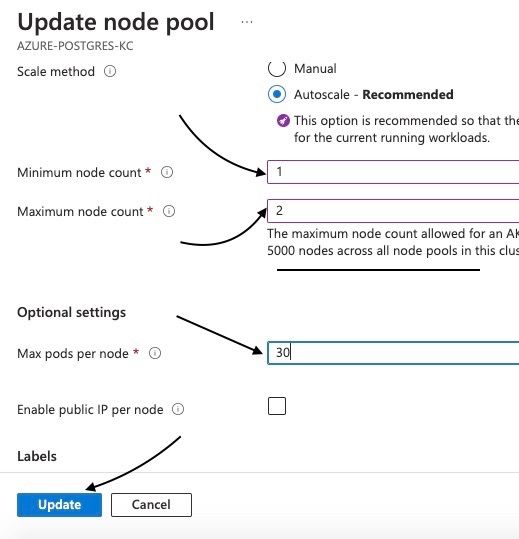
Mise à jour des détails de l'agentpool
Une fois que vous avez cliqué sur "Mettre à jour", vous serez dirigé vers la section "Réseau" comme indiqué ci-dessous. Gardez la page telle quelle et procédez en cliquant sur "Suivant". Cela vous mènera à la session d'intégration.
Navigation vers la page suivante
Azure Container Registry (ACR) est un service de registre Docker privé entièrement géré fourni par Microsoft Azure. Il permet aux développeurs de stocker, gérer et déployer des images de conteneurs Docker de manière sécurisée dans leur environnement Azure.
Vous aurez besoin d'un endroit pour stocker l'image Docker qui est extraite.
Pour commencer, sélectionnez "Créer nouveau" pour configurer un nouveau registre de conteneurs. Cette action ouvrira une page où vous pourrez saisir les détails nécessaires, comme illustré sur le côté droit de l'image ci-dessous. Saisissez les détails comme indiqué par les flèches, puis cliquez sur "OK". Une fois terminé, procédez en cliquant sur "Suivant".
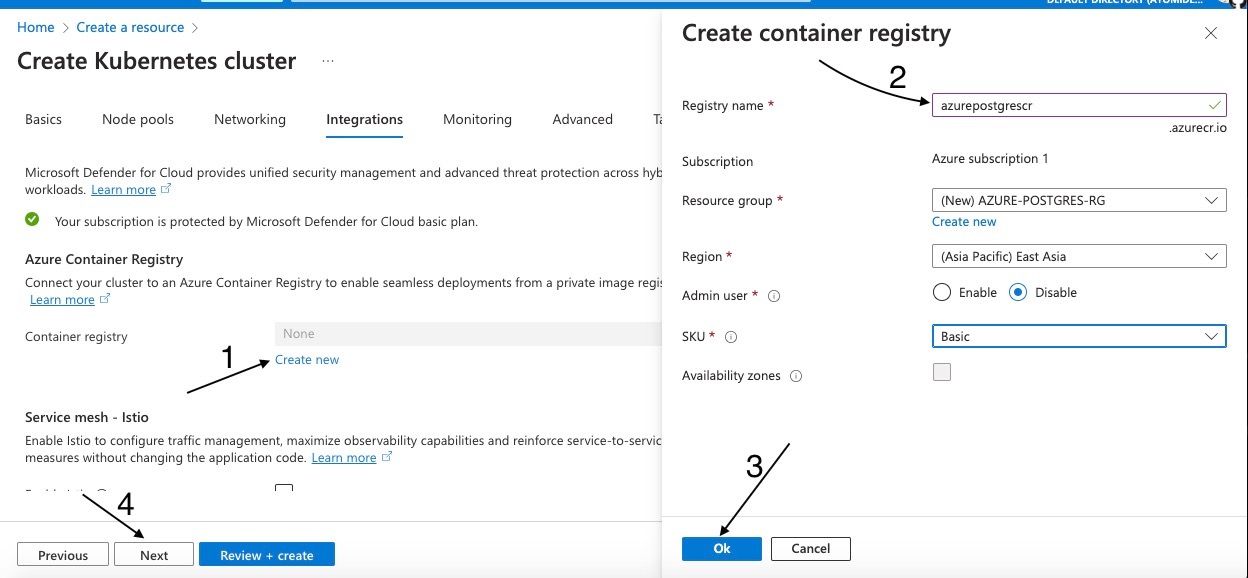
Nommer et éditer les détails du registre de conteneurs Azure
Étape 8 : Activer les journaux de conteneurs et configurer les alertes
L'option Activer les journaux de conteneurs vous permet d'activer la journalisation pour vos conteneurs. La journalisation enregistre des informations importantes sur ce qui se passe à l'intérieur de vos conteneurs, comme les erreurs, les avertissements et autres événements. C'est utile pour le dépannage et la surveillance de vos applications.
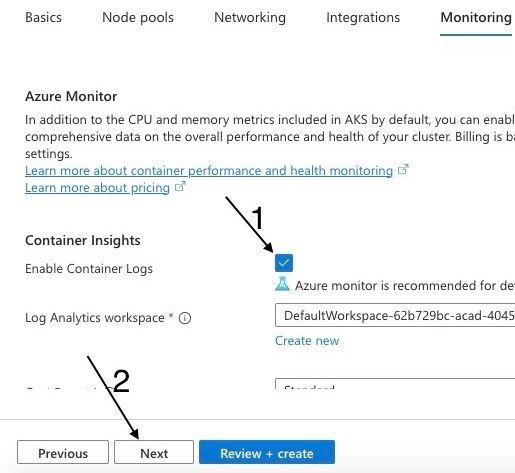
Choix des journaux de conteneurs
Étape 9 : Section avancée
Gardez la section Surveillance inchangée et procédez en cliquant sur "Suivant".
Navigation vers la page suivante
Étape 10 : Balises
Gardez la section Balises inchangée et procédez en cliquant sur "Suivant".
Navigation vers la page suivante
Étape 11 : Cliquez sur "Vérifier + créer" pour finaliser le déploiement
Une fois terminé, votre groupe de ressources, Azure Kubernetes Service (AKS), Azure Container Registry et le cluster Kubernetes seront créés.
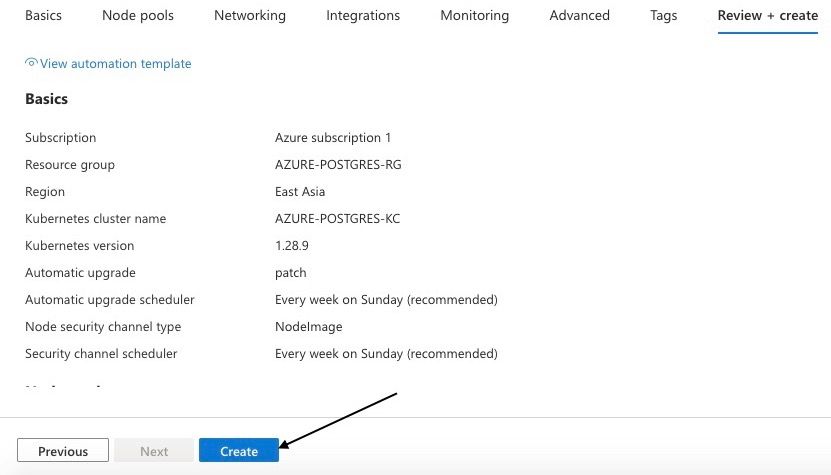
Finalisation de la configuration Azure Kubernetes
La capture d'écran ci-dessous montre que le déploiement a réussi.
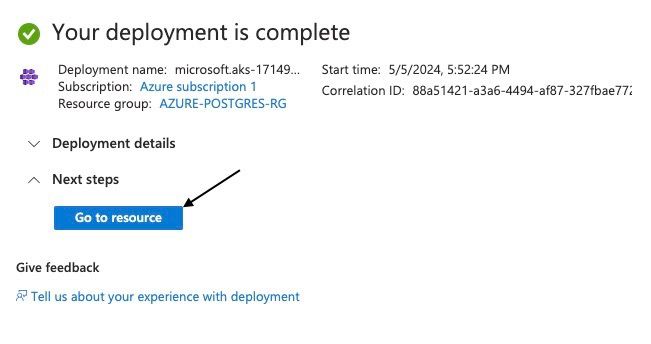
Déploiement réussi
Vous venez de créer avec succès un service Azure Kubernetes à partir du portail Azure. Félicitations !
Comment se connecter à votre cluster AKS en utilisant la ligne de commande
Après avoir créé avec succès un nouveau AKS dans le portail Azure, l'étape suivante consiste à établir une connexion à ce cluster.
Dans cette section, je vais vous guider à travers la connexion Azure, la configuration de kubectl pour utiliser le contexte actuel, et la création du fichier YAML pour notre conteneur Postgres. Ce fichier inclura StatefulSet, volume persistant, réclamation de volume persistant, config map, et l'utilisation d'Azure File pour le stockage des données.
Je vais également vous montrer comment exécuter une application Node.js Express localement, utiliser Postman pour tester les endpoints, et recevoir une réponse confirmant que les données ont été envoyées à la base de données avec succès.
Télécharger Azure CLI et kubectl
Pour commencer, vous devrez télécharger Azure CLI et kubectl.
Azure CLI (Interface de ligne de commande) : un outil en ligne de commande fourni par Microsoft pour gérer les ressources Azure. Il permet aux utilisateurs d'interagir avec les services et ressources Azure directement depuis la ligne de commande, facilitant ainsi l'automatisation des tâches, la création de scripts et la gestion programmatique des ressources Azure.
kubectl : un outil en ligne de commande pour gérer les clusters Kubernetes, utilisé pour déployer, mettre à l'échelle et gérer des applications conteneurisées. Il permet aux utilisateurs d'effectuer des opérations telles que le déploiement d'applications, la gestion de pods, de services et de déploiements, l'inspection des ressources du cluster, la mise à l'échelle des applications et le débogage des problèmes, simplifiant ainsi la gestion des charges de travail conteneurisées dans un environnement Kubernetes.
J'utilise le terminal warp. Warp est le terminal réimaginé avec l'IA et des outils collaboratifs pour une meilleure productivité. Vous pouvez exécuter la commande en utilisant PowerShell sur Windows ou Terminal sur Mac. J'utilise un MacBook.
Vérifier si Azure CLI est installé en tapant la commande az --version
Une fois le téléchargement terminé, vérifiez si Azure CLI est installé sur votre ordinateur en exécutant la commande az --version. Si l'installation est réussie, vous devriez voir une sortie similaire à celle-ci :
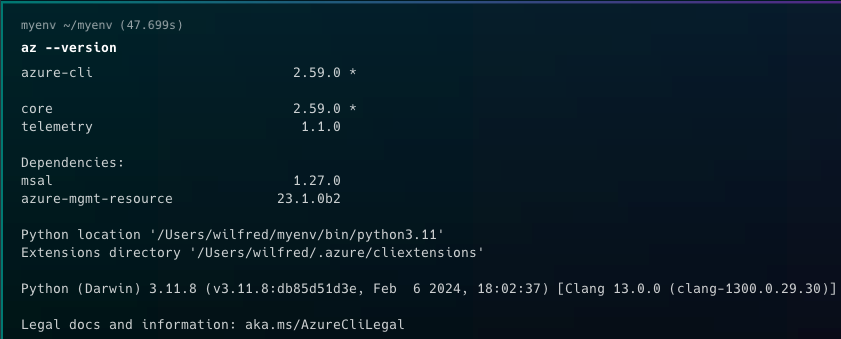
Vérification de l'installation d'Azure CLI
Vérifier si kubectl est installé
Pour vérifier si kubectl est installé, tapez simplement kubectl version dans la ligne de commande.

Vérification de l'installation de Kubectl
Se connecter à votre compte Azure
Entrez az login dans la ligne de commande. Cela ouvrira votre navigateur et vous invitera à vous connecter à votre compte Azure.
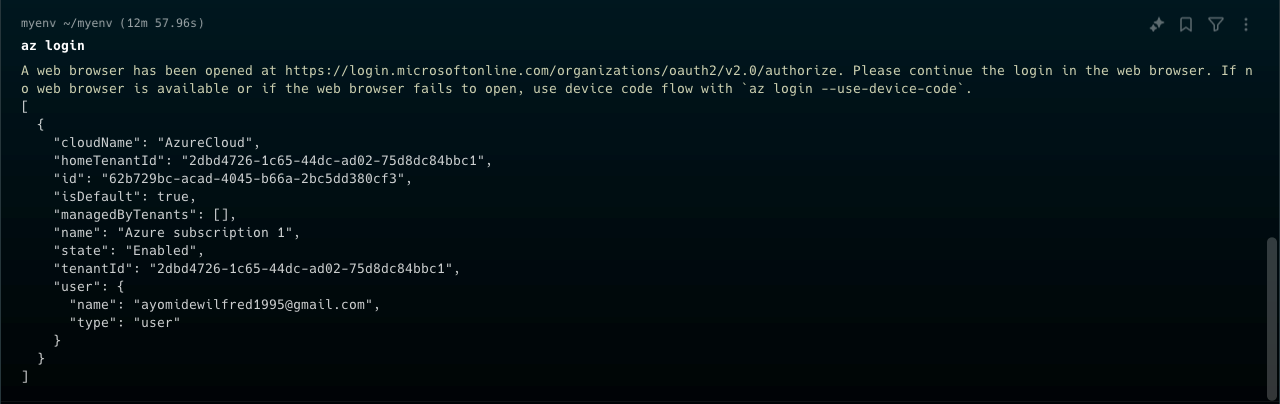
Connexion à Azure
Après vous être connecté, il affiche des détails sur votre abonnement Azure, y compris le nom de l'abonnement, l'ID et les informations utilisateur.
Sélectionner un abonnement Azure
Les abonnements Azure sont des conteneurs logiques utilisés pour provisionner des ressources dans Azure. Vous devrez localiser l'ID d'abonnement que vous prévoyez d'utiliser dans ce module. Utilisez la commande pour lister vos abonnements Azure :
az account list --output table
Utilisez la commande suivante pour vous assurer que vous utilisez un abonnement Azure qui vous permet de créer des ressources à des fins de ce module, en remplaçant votre ID d'abonnement (SubscriptionId) :
az account set --subscription "Nom de l'abonnement"
Configurer kubectl pour se connecter à votre Azure Kubernetes
Remplacez Your_Azure_Resource_groups_name dans le code ci-dessous par le nom que vous avez choisi lors de la création d'un groupe de ressources. Remplacez également your_azure_kubernetes_service_name par le nom de votre cluster Kubernetes. Ensuite, exécutez la commande suivante :
az aks get-credentials --resource-group [Your_Azure_Resource_groups_name] --name [your_azure_kubernetes_service_name]
La sortie devrait ressembler à ceci :

Fusion de kubectl avec Azure Kubernetes Service
Vérifier si kubectl a été fusionné avec succès
Exécutez la commande suivante kubectl get nodes :

Vérification si la fusion est réussie
Lorsque vous exécutez cette commande, Kubernetes communique avec le plan de contrôle du cluster pour récupérer une liste de tous les nœuds qui font partie du cluster que vous avez créé. Comme vous pouvez le voir, il s'agit du nœud qui s'exécutait dans le cluster Kubernetes que nous avons créé dans Azure.

Nœud virtuel s'exécutant dans le cluster AKS
Exécuter la commande kubectl get pods

Affichage des informations sur les pods
Lorsque vous exécutez la commande kubectl get pods, Kubernetes tente de récupérer des informations sur tous les pods dans l'espace de noms par défaut de votre cluster. Mais dans ce cas, la sortie indique qu'il n'y a pas de ressources (pods) trouvées dans l'espace de noms par défaut, ce qui implique qu'aucun pod n'existe actuellement dans cet espace de noms.
Un namespace dans Kubernetes est un environnement de cluster virtuel dans lequel des ressources comme les pods, les services et les déploiements sont organisés et isolés. C'est un moyen de diviser les ressources du cluster entre plusieurs utilisateurs, équipes ou projets. Les namespaces fournissent une portée pour les noms et facilitent la gestion et le contrôle de l'accès aux ressources.
Par défaut, Kubernetes commence avec un espace de noms "default", mais vous pouvez créer des espaces de noms supplémentaires pour organiser et gérer les ressources plus efficacement. Les espaces de noms aident à prévenir les conflits de noms et fournissent une séparation logique des ressources, permettant à différentes équipes ou projets de travailler indépendamment au sein du même cluster Kubernetes.
Créer un namespace

Création d'un namespace
Lorsque vous exécutez la commande kubectl create namespace database, Kubernetes crée un nouvel espace de noms nommé "database". La sortie "namespace/database created" confirme que l'espace de noms a été créé avec succès.
Vous pouvez maintenant utiliser cet espace de noms pour organiser et gérer les ressources liées aux bases de données dans le cluster Kubernetes.
Confirmer le namespace
La commande kubectl get namespace liste tous les espaces de noms dans le cluster Kubernetes, y compris l'espace de noms de la base de données que nous venons de créer, en montrant leurs noms, leur statut (actif) et leur âge.

Confirmation du namespace
Obtenir les informations sur les pods dans l'espace de noms de la base de données

Affichage des informations sur les pods liées à l'espace de noms de la base de données
Cette commande, kubectl get pods -n database, tente de récupérer des informations sur les pods spécifiquement dans l'espace de noms "database". Mais la sortie No resources found in database namespace indique qu'il n'y a actuellement aucun pod déployé dans l'espace de noms "database".
Comment créer des ressources avec YAML
Explorons la création de ressources avec YAML pour provisionner notre base de données PostgreSQL s'exécutant dans un cluster Azure Kubernetes. Mais d'abord, qu'est-ce que YAML exactement ?
Kubernetes YAML est un fichier de configuration écrit en YAML (YAML Ain't Markup Language). Ils définissent comment les ressources Kubernetes comme les pods, les déploiements et les services doivent être configurés dans un cluster. Ces fichiers sont faciles à lire et spécifient des détails comme les noms des ressources, les types, les spécifications, les étiquettes et les annotations. Ils sont cruciaux pour déployer des applications et des infrastructures sur des clusters Kubernetes.
YAML est ce que vous allez utiliser pour créer des ressources Kubernetes qui exécuteront Postgres.
Tout d'abord, vous devez cloner ce dépôt GitHub. À l'intérieur, vous trouverez une application Node.js Express et un fichier YAML. L'application Node.js permet aux utilisateurs de s'inscrire avec leur email, mot de passe et nom complet, et leur permet également de se connecter en vérifiant leurs détails dans la base de données. Si leurs détails sont trouvés, elle affiche un message de succès.
Cloner le dépôt
Créez un nouveau dossier sur votre ordinateur, puis clonez ce dépôt à l'intérieur.
Ouvrez votre terminal ou PowerShell, allez dans le dossier que vous souhaitez, et utilisez la commande ci-dessous pour cloner le dépôt dans votre ordinateur à cet emplacement.
git clone https://github.com/ayowilfred95/Azure-k8s-postgres.git
Ouvrir le dépôt clonné dans n'importe quel éditeur de texte
J'utilise Visual Studio Code, mais vous pouvez utiliser n'importe quel éditeur de texte que vous préférez. Voici la structure du projet :
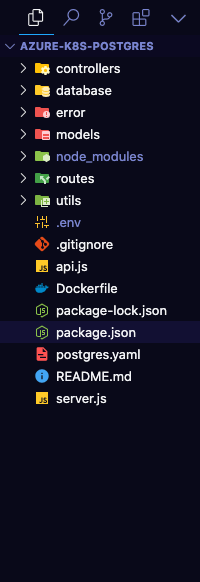
Structure du dossier du projet
Installer les dépendances du projet
Ouvrez le terminal dans VS Code et allez dans le répertoire principal du projet. Ensuite, exécutez la commande npm install pour installer tous les packages et dépendances requis pour le projet :
npm install
Puisque l'application backend est une application Node.js Express, vous utilisez npm pour installer les dépendances (similaire à la façon dont nous utilisons maven clean install en Java).
Après l'installation des dépendances, ouvrez le fichier nommé "postgres.yaml". Il contient toutes les configurations YAML nécessaires pour configurer votre base de données PostgreSQL qui s'exécutera dans le cluster Kubernetes.
Configuration YAML
Dans le fichier postgres.yaml, il y a cinq configurations séparées par ---. Il est important d'utiliser ce symbole "---" lors de la déclaration de différents types de ressources Kubernetes. Si vous oubliez de le faire, vous rencontrerez une erreur.
StorageClass
La première est la StorageClass. Cette configuration YAML définit une StorageClass dans Kubernetes pour gérer les ressources de stockage.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azuredisk-premium-retain
provisioner: kubernetes.io/azure-disk
reclaimPolicy: Retain # Retain ou Delete
volumeBindingMode: WaitForFirstConsumer # WaitForFirstConsumer ou Immediate
allowVolumeExpansion: true # true ou false
parameters:
storageaccounttype: Premium_LRS # Premium ou Standard
kind: Managed
Décomposons ce que signifie chaque partie :
kind: StorageClass: Indique le type de ressource Kubernetes en cours de définition, qui est uneStorageClass. UneStorageClassdéfinit la classe de stockage offerte par un cluster.apiVersion: storage.k8s.io/v1: Spécifie la version de l'API Kubernetes utilisée pour cette ressource.metadata: name: azuredisk-premium-retain: Fournit des métadonnées pour laStorageClass, y compris son nom, qui dans ce cas est "azuredisk-premium-retain".provisioner: kubernetes.io/azure-disk: Spécifie le provisionneur responsable de la provision des ressources de stockage. Dans ce cas, il s'agit de "kubernetes.io/azure-disk", indiquant que Azure Disk sera utilisé comme provisionneur de stockage.reclaimPolicy: Retain: Définit la politique de récupération pour les ressources de stockage. Elle spécifie quelle action doit être entreprise lorsque le volume persistant associé est libéré. Ici, elle est définie sur "Retain", ce qui signifie que le volume est conservé même après qu'il ne soit plus utilisé par un pod.volumeBindingMode: WaitForFirstConsumer: Spécifie le mode de liaison de volume, qui détermine quand la liaison de volume doit se produire. Dans ce cas, elle est définie sur "WaitForFirstConsumer", ce qui signifie que le volume sera lié lorsque le premier pod l'utilisant est créé.allowVolumeExpansion: true: Indique si l'expansion de volume est autorisée. La définir sur "true" signifie que la taille du volume peut être augmentée si nécessaire.parameters: Contient des paramètres supplémentaires spécifiques au provisionneur. Ici, elle spécifie le type de compte de stockage comme "Premium_LRS" et le type de stockage comme "Managed".
Dans l'ensemble, cette configuration met en place une StorageClass nommée "azuredisk-premium-retain" utilisant Azure Disk comme provisionneur, avec des politiques et paramètres spécifiques adaptés pour le stockage Azure.
PersistentVolumeClaim
La deuxième configuration dans le fichier postgres.yaml est le persistent volume claim.
Cette configuration YAML définit un PersistentVolumeClaim (PVC) dans Kubernetes, qui est utilisé pour demander des ressources de stockage.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: azure-managed-disk-pvc
spec:
accessModes:
- ReadWriteOnce # ReadWriteOnce, ReadOnlyMany ou ReadWriteMany
storageClassName: azuredisk-premium-retain
resources:
requests:
storage: 4Gi
Décomposons ce que signifie chaque partie :
apiVersion: v1: Spécifie la version de l'API Kubernetes utilisée pour cette ressource.kind: PersistentVolumeClaim: Indique le type de ressource Kubernetes en cours de définition, qui est un PersistentVolumeClaim. Un PVC est utilisé par les pods pour demander des ressources de stockage.metadata: name: azure-managed-disk-pvc: Fournit des métadonnées pour le PersistentVolumeClaim, y compris son nom, qui est "azure-managed-disk-pvc".spec: Décrit l'état souhaité du PersistentVolumeClaim.accessModes: - ReadWriteOnce: Spécifie le mode d'accès pour le volume. Ici, il est défini sur "ReadWriteOnce", ce qui signifie que le volume peut être monté en lecture-écriture par un seul nœud à la fois.storageClassName: azuredisk-premium-retain: Spécifie laStorageClassà utiliser pour le provisionnement du volume. Ce PVC utilisera laStorageClassnommée "azuredisk-premium-retain" définie précédemment.resources: requests: storage: 4Gi: Spécifie la capacité de stockage souhaitée pour le volume. Ici, il demande 4 gigaoctets (Gi) de stockage.
Dans l'ensemble, cette configuration met en place un PersistentVolumeClaim nommé "azure-managed-disk-pvc" demandant des ressources de stockage avec des modes d'accès spécifiques, une classe de stockage et une capacité de stockage.
ConfigMap
La troisième configuration dans le fichier postgres.yaml est la config map. Cette configuration YAML définit un ConfigMap dans Kubernetes, qui est utilisé pour stocker des données de configuration sous forme de paires clé-valeur.
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-config
labels:
app: postgres
data:
POSTGRES_DB: freecodecamp
POSTGRES_USER: freecodecamp1
POSTGRES_PASSWORD: freecodecamp@
PGDATA: /var/lib/postgresql/data/pgdata
Décomposons ce que signifie chaque partie :
apiVersion: v1: Spécifie la version de l'API Kubernetes utilisée pour cette ressource.kind: ConfigMap: Indique le type de ressource Kubernetes en cours de définition, qui est unConfigMap. UnConfigMapest utilisé pour stocker des données non confidentielles sous forme de paires clé-valeur.metadata: name: postgres-config: Fournit des métadonnées pour leConfigMap, y compris son nom, qui est "postgres-config".labels: app: postgres: Les étiquettes sont des paires clé-valeur utilisées pour organiser et sélectionner des ressources. Ici, une étiquette "app" avec la valeur "postgres" est appliquée auConfigMap.data: Contient les paires clé-valeur des données de configuration.POSTGRES_DB: pisonitsha: Spécifie le nom de la base de données PostgreSQL comme "pisonitsha".POSTGRES_USER: pisonitsha1: Spécifie le nom d'utilisateur pour accéder à la base de données PostgreSQL comme "pisonitsha1".POSTGRES_PASSWORD: pisonitsha@: Spécifie le mot de passe pour accéder à la base de données PostgreSQL comme "pisonitsha@".PGDATA: /var/lib/postgresql/data/pgdata: Spécifie l'emplacement du répertoire de données PostgreSQL comme "/var/lib/postgresql/data/pgdata".
Dans l'ensemble, cette configuration met en place un ConfigMap nommé "postgres-config" contenant des paires clé-valeur de données de configuration, telles que le nom de la base de données, le nom d'utilisateur, le mot de passe et l'emplacement du répertoire de données, qui peuvent être utilisées par d'autres ressources Kubernetes.
Note : Il est recommandé d'éviter de coder en dur les variables secrètes telles que POSTGRES_DB, POSTGRES_PASSWORD, PGDATA et de les stocker plutôt dans des fichiers secrets, pour la simplicité de ce tutoriel, nous les garderons codées en dur.
StatefulSet
La quatrième configuration est le stateful set. Cette configuration YAML définit un StatefulSet dans Kubernetes, qui est utilisé pour gérer des applications avec état comme les bases de données.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: postgres
selector:
matchLabels:
app: postgres
replicas: 1
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:10.4
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 5432
envFrom:
- configMapRef:
name: postgres-config
volumeMounts:
- name: azure-managed-disk-pvc
mountPath: /var/lib/postgresql/data
volumes:
- name: azure-managed-disk-pvc
persistentVolumeClaim:
claimName: azure-managed-disk-pvc
Décomposons ce que signifie chaque partie :
apiVersion: apps/v1: Spécifie la version de l'API Kubernetes utilisée pour cette ressource.kind: StatefulSet: Indique le type de ressource Kubernetes en cours de définition, qui est unStatefulSet. LesStatefulSetssont utilisés pour gérer des applications avec état en fournissant des identités uniques et des identités réseau stables à chaque pod.metadata: name: postgres: Fournit des métadonnées pour leStatefulSet, y compris son nom, qui est "postgres".spec: Décrit l'état souhaité duStatefulSet.serviceName: postgres: Spécifie le nom du service Kubernetes qui sera utilisé pour accéder aux pods duStatefulSet.selector: matchLabels: app: postgres: Sélectionne les pods contrôlés par ceStatefulSeten fonction de l'étiquette "app: postgres".replicas: 1: Spécifie le nombre souhaité de répliques (instances) du StatefulSet, qui est 1 dans ce cas.template: Définit le modèle de pod utilisé pour créer des pods gérés par leStatefulSet.metadata: labels: app: postgres: Étiquettes appliquées aux pods créés à partir de ce modèle.spec: Décrit la spécification des conteneurs au sein du pod.containers: Spécifie les conteneurs s'exécutant dans le pod.name: postgres: Définit le nom du conteneur comme "postgres".image: postgres:10.4: Spécifie l'image Docker utilisée pour le conteneur, qui est "postgres:10.4".imagePullPolicy: "IfNotPresent": Spécifie la politique de récupération de l'image du conteneur, qui est "IfNotPresent", ce qui signifie qu'elle ne récupérera l'image que si elle n'est pas déjà présente sur le nœud.ports: containerPort: 5432: Spécifie le port sur lequel le service PostgreSQL à l'intérieur du conteneur écoute.envFrom: configMapRef: name: postgres-config: Injecte des variables d'environnement à partir d'un ConfigMap nommé "postgres-config" que vous avez défini précédemment.volumeMounts: name: azure-managed-disk-pvc mountPath: /var/lib/postgresql/data: Monte une réclamation de volume persistant nommée "azure-managed-disk-pvc" sur le conteneur au chemin spécifié.volumes: name: azure-managed-disk-pvc persistentVolumeClaim: claimName: azure-managed-disk-pvc: Définit la réclamation de volume persistant nommée "azure-managed-disk-pvc" à utiliser par le pod.
Dans l'ensemble, cette configuration met en place un StatefulSet nommé "postgres" avec une réplique, exécutant un conteneur PostgreSQL avec des paramètres spécifiques et un stockage persistant monté.
Service
La cinquième configuration est le service. Cette configuration YAML définit un Service dans Kubernetes, qui est utilisé pour exposer le StatefulSet que nous avons déclaré précédemment en tant que service réseau.
apiVersion: v1
kind: Service
metadata:
name: postgres
labels:
app: postgres
spec:
type: LoadBalancer
selector:
app: postgres
ports:
- protocol: TCP
name: https
port: 5432
targetPort: 5432
Décomposons ce que signifie chaque partie :
apiVersion: v1: Spécifie la version de l'API Kubernetes utilisée pour cette ressource.kind: Service: Indique le type de ressource Kubernetes en cours de définition, qui est un Service. Les Services permettent aux pods d'être accessibles par d'autres pods ou utilisateurs externes.metadata: name: postgres: Fournit des métadonnées pour le Service, y compris son nom, qui est "postgres".labels: app: postgres: Les étiquettes sont des paires clé-valeur utilisées pour organiser et sélectionner des ressources. Ici, une étiquette "app" avec la valeur "postgres" est appliquée au Service.spec: Décrit l'état souhaité du Service.type: LoadBalancer: Spécifie le type de Service, qui est "LoadBalancer". Ce type permet au Service d'être exposé externement avec un équilibreur de charge du fournisseur de cloud.selector: app: postgres: Sélectionne les pods contrôlés par le Service en fonction de l'étiquette "app: postgres".ports: Spécifie les ports sur lesquels le Service écoutera.protocol: TCP: Spécifie le protocole utilisé pour le port, qui est TCP.name:https: Spécifie un nom pour le port, qui est "https".port: 5432: Spécifie le numéro de port sur lequel le Service écoutera, qui est 5432.targetPort: 5432: Spécifie le port cible sur les pods vers lequel le trafic sera transféré, qui est également 5432. Cela signifie que le trafic reçu sur le port 5432 du Service sera transféré au port 5432 sur les pods.
Dans l'ensemble, cette configuration met en place un Service nommé "postgres" avec un type LoadBalancer, transférant le trafic sur le port 5432 vers les pods étiquetés avec "app: postgres".
Comment déployer une ressource YAML vers Azure Kubernetes Service (AKS)
Vous avez précédemment connecté "kubectl" avec le service Azure Kubernetes (AKS) que vous avez configuré. Vérifions cela à nouveau.
Dans votre terminal VS Code, réexécutez la commande kubectl get nodes. Vous verrez une sortie comme celle-ci, bien que la valeur de votre nœud sera différente.

Affichage des informations sur les nœuds s'exécutant dans le cluster Azure Kubernetes
Ensuite, vérifiez l'espace de noms que vous avez précédemment créé en exécutant la commande : kubectl get namespace database. Votre sortie devrait ressembler à ceci :

Récupération des informations sur l'espace de noms
Déployer la ressource YAML
Une fois que vous avez confirmé que tout est prêt, vous pouvez déployer la ressource YAML. Cela établira votre base de données PostgreSQL dans le cluster Azure Kubernetes que vous avez configuré.
Exécutez la commande ci-dessous dans le répertoire principal où se trouve le fichier de configuration. Actuellement, je suis dans le répertoire racine du projet (azure-k8s-postgres). Pour déployer la base de données, exécutez simplement cette commande ci-dessous :
kubectl apply -n database -f postgres.yaml
Votre sortie devrait ressembler à ceci. Cette sortie confirme que tous ces composants ont été créés avec succès dans Kubernetes.

Application de la configuration à l'espace de noms
Exécutez la commande ci-dessous pour vérifier que le pod est en cours d'exécution :
kubectl get pods -n database
Votre sortie devrait ressembler à ceci :

Récupération des pods dans l'espace de noms
Cette sortie confirme qu'un pod nommé "postgres-0" est en cours d'exécution dans votre cluster Azure Kubernetes. Mais ce n'est pas le seul pod que vous avez créé. Comme je l'ai dit plus tôt, pour se connecter à un pod, vous avez besoin de ce que l'on appelle un service. Et vous avez déclaré une ressource de service dans notre fichier de configuration qui a également été déployée dans votre Kubernetes.
Pour obtenir l'état du service, exécutez cette commande :
kubectl get services -n database
Votre sortie devrait ressembler à ceci :

Récupération des services dans l'espace de noms
Cette sortie affiche les services dans l'espace de noms "database", y compris un service nommé "postgres" avec le type "LoadBalancer", son IP de cluster interne, son IP externe et les mappages de ports. Vous utiliserez l'IP externe ainsi que le port Postgres "5432" pour connecter votre base de données avec l'application Node.js. Notez que votre IP externe sera différente de la mienne.
Application Node.js
Dans cette section, je vais vous guider à travers la configuration de votre application Node.js pour la connecter à une base de données PostgreSQL dans votre service Azure Kubernetes.
Nous allons couvrir l'envoi de données dans la base de données et leur récupération en utilisant Postman. De plus, je vais démontrer comment vérifier si les données restent dans la base de données même si le pod exécutant PostgreSQL dans le cluster est supprimé.
Configurer votre application Node.js
Allez dans le dossier de la base de données et ouvrez le fichier database.js. Remplacez l'hôte par votre EXTERNAL-IP obtenu à partir du service, et laissez le reste inchangé puisque vous avez déjà défini ces variables dans votre config map.
Votre fichier database.js devrait ressembler au CodeSnap ci-dessous :

CodeSnap de la configuration database.js
Exécuter votre application Node.js
Dans votre terminal VS Code, exécutez cette commande pour démarrer l'application Node.js localement :
npm start
Votre sortie devrait ressembler à ceci si la connexion est établie avec succès.

Serveur écoutant sur le port 4000
Si votre sortie ressemble à la mienne, cela indique que vous avez réussi à connecter votre application Node.js à la base de données PostgreSQL s'exécutant dans votre cluster Azure Kubernetes. Félicitations ! 🎉
Tester l'application
Les tests sont un principe fondamental dans les opérations DevOps. Ils nous aident à comprendre l'état de l'application que nous avons construite avant de la publier pour les utilisateurs. Toute application qui ne passe pas l'étape de test ne sera pas déployée. C'est une règle en DevOps.
Pour ce tutoriel, vous allez utiliser Postman. Vous pouvez télécharger Postman ici. Postman vous permet de tester les endpoints d'API en recevant des réponses de statut.
Consultez cet article sur la façon d'utiliser Postman pour tester les API. Si vous souhaitez en savoir plus, voici un cours complet sur le sujet.
Ouvrir votre application Postman
Pour commencer à utiliser Postman, commencez par créer une nouvelle requête API dans votre espace de travail préféré. Choisissez POST. Les requêtes POST ajoutent de nouvelles données à la base de données ou au serveur. Ensuite, collez l'URL de l'endpoint (localhost:4000/api/v1/admin/register) pour votre test Postman.
La capture d'écran ci-dessous illustre comment vous allez créer une requête POST.

Configuration de l'URL de l'endpoint Postman
Dans le corps, collez les données JSON ci-dessous à l'intérieur comme indiqué ci-dessous :
{
"fullName":"Azure postgres freecodecamp",
"email":"freecodecamp@gmail.com",
"password":"freecodecamp"
}
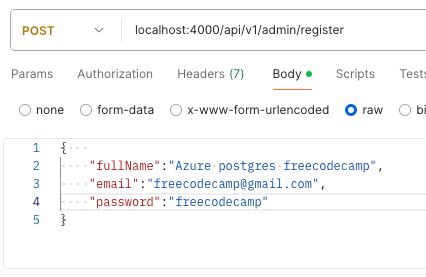
Corps de la requête Postman
Une fois que vous avez configuré la requête, cliquez simplement sur le bouton "Envoyer" pour l'envoyer. Postman affichera alors les codes de statut et la charge utile de la réponse comme indiqué ci-dessous.
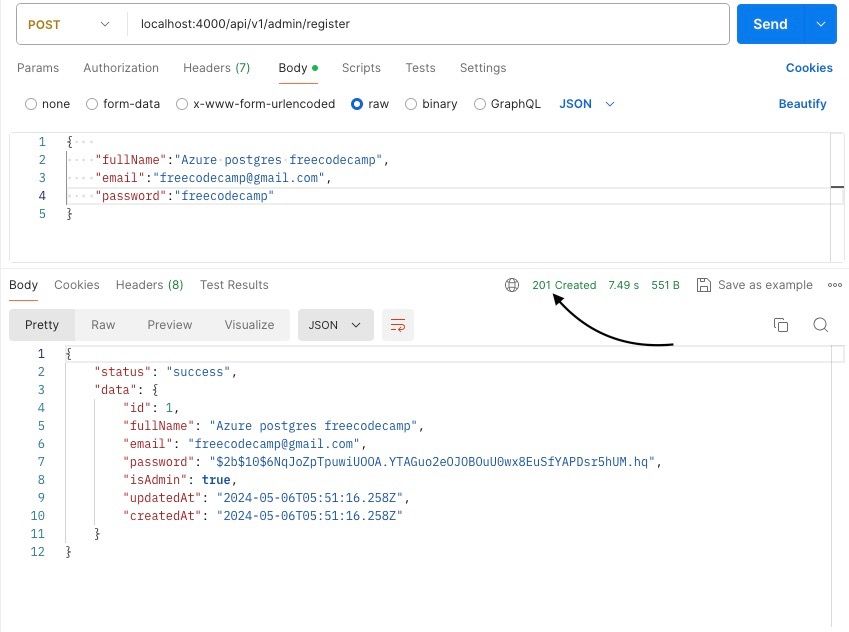
Réponse de l'API Postman
Confirmer les données
Pour confirmer que les données que vous avez envoyées dans la base de données existent, faites une requête GET à cette URL d'endpoint : localhost:4000/api/v1/admin/freecodecamp@gmail.com
URL de l'endpoint de la requête GET Postman
Lorsque vous cliquez sur envoyer, Postman affichera alors les codes de statut et la charge utile de la réponse comme indiqué ci-dessous. Remarquez que nous n'avons rien mis dans le corps car il s'agit d'une requête GET.
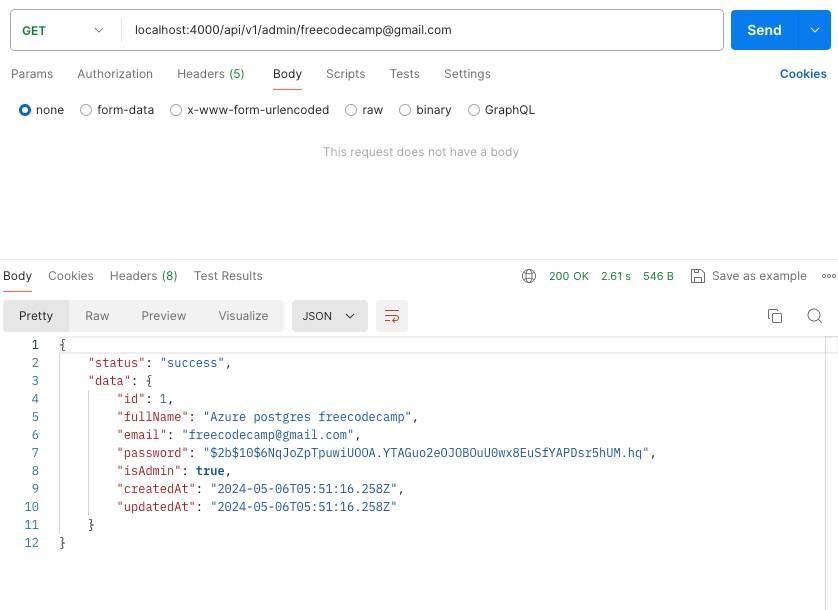
Réponse de la requête GET Postman par récupération par email
Supprimer le pod pour confirmer la persistance des données
Nous avons choisi de créer notre base de données PostgreSQL en utilisant un StatefulSet pour nous assurer que les données persistent même si le pod est détruit. Testons cela en supprimant le pod et en vérifiant si les données restent intactes.
Dans votre terminal VS Code, exécutez la commande : kubectl delete pod -n database postgres-0.
Cette commande supprime un pod nommé "postgres-0" dans l'espace de noms "database" de votre cluster Kubernetes. Votre sortie devrait ressembler à ceci.

Suppression du pod dans l'espace de noms :
Recréation du pod
Kubernetes dispose d'une fonctionnalité intégrée appelée contrôleurs de réplication ou ensembles de répliques qui garantissent qu'un nombre spécifié de répliques de pod sont en cours d'exécution à tout moment. Si un pod est supprimé, Kubernetes le recréera automatiquement pour maintenir le nombre souhaité de répliques, assurant ainsi une haute disponibilité.
Si vous exécutez kubectl get pods -n database, vous remarquerez que Kubernetes a créé un nouveau pod avec le même nom, "postgres-0", pour remplacer celui qui a été supprimé. Cela garantit que l'application reste disponible et continue de fonctionner comme prévu.

Pod recréé dans l'espace de noms
Persistance des données
Revenez à Postman et faites une requête GET à l'URL de l'endpoint localhost:4000/api/v1/admin/freecodecamp@gmail.com.
Vous devriez obtenir la même réponse qu'auparavant. Donc, sous le capot, lorsque nous supprimons le pod, le disque de stockage n'a pas été supprimé. Le disque de stockage est à l'intérieur du disque Azure. Comment le savons-nous ? Si vous exécutez cette commande :
kubectl get pvc -n database
vous devriez obtenir cette sortie :

Détails de la réclamation de volume persistant dans l'espace de noms
Cela montre des détails sur un stockage appelé "azure-managed-disk-pvc" dans votre Kubernetes. Il est actuellement en cours d'utilisation et dispose de 4 gigaoctets d'espace disponible. Il est configuré pour être lu et écrit par un système à la fois. Ce stockage est fourni par un service appelé "azuredisk-premium-retain" que nous avons configuré précédemment.
Nettoyer les ressources
Dans ce tutoriel, vous avez créé des ressources Azure dans un groupe de ressources. Si vous n'aurez pas besoin de ces ressources plus tard, supprimez le groupe de ressources depuis le portail Azure ou exécutez la commande suivante dans votre terminal :
az group delete --name AZURE-POSTGRES-RG --yes
Cette commande peut prendre une minute à s'exécuter.
Conclusion
Nous avons parcouru un long chemin ici ! Vous avez appris à déployer un conteneur Postgres dans Azure Kubernetes Service (AKS) et à l'intégrer avec une application Node.js.
Dans ce tutoriel, je vous ai guidé à travers le processus de configuration de Kubernetes en utilisant Azure Kubernetes Service (AKS). Vous avez appris à personnaliser les fichiers YAML en utilisant StatefulSet, Persistent Volume et Services pour déployer une base de données PostgreSQL sur Azure Kubernetes. Vous avez également acquis les informations d'identification de la base de données PostgreSQL s'exécutant dans AKS pour établir une connectivité avec une application Node.js. J'ai ensuite fourni des instructions détaillées sur la connexion de votre application Node.js Express au conteneur Postgres dans le cluster AKS.
Merci d'avoir lu !