


Article original : How to Run SQL-Like Queries on C/C++ Files
Bonjour à tous ! Je suis un ingénieur logiciel passionné par la programmation bas niveau, les compilateurs et le développement d'outils.
À la fin de l'année 2023, j'ai publié mon premier article sur freeCodeCamp expliquant comment j'ai créé un langage de type SQL pour exécuter des requêtes sur des dépôts Git locaux. Si vous souhaitez plus de contexte, n'hésitez pas à le lire.
Au début de 2024, le projet a pris de l'ampleur avec plus de fonctionnalités et des contributeurs incroyables, et je me suis demandé : et si je pouvais exécuter des requêtes de type SQL non seulement sur des fichiers .git, mais aussi sur tout type de données locales et distantes ?
Dans mon dernier article sur Comment exécuter des requêtes de type SQL sur des fichiers, j'ai expliqué la conception interne des composants du SDK GitQL et comment l'utiliser avec tout type de données en général, ainsi que la mise en œuvre du projet FileQL.
Dans cet article, je vais expliquer comment j'ai utilisé le SDK GitQL pour implémenter le projet ClangQL (Clang Query Language), un outil qui vous aide à exécuter des requêtes de type SQL sur des fichiers C/C++ locaux.
Comment j'ai eu l'idée du projet ClangQL
Comme je l'ai mentionné dans mes articles précédents, le SDK GitQL peut exécuter des requêtes de type SQL sur toute donnée structurée locale ou distante. De plus, le compilateur analyse votre code en une structure de données AST (Abstract Syntax Tree). La question qui m'est venue à l'esprit était donc : pourquoi ne pas exécuter la requête sur l'Abstract Syntax Tree ?
Je n'ai pas trouvé de limitations à la mise en œuvre de cette idée, alors j'ai commencé à réfléchir aux deux principales exigences pour utiliser GitQL : créer le schéma de données pour décrire les structures de tables et les types de colonnes, et implémenter le composant Data Provider pour fournir les données, qui dans notre cas sont les informations de l'AST, et les mapper au format du moteur.
Le schéma de données pour le code C/C++
Vous pouvez considérer le schéma de données comme l'endroit où nous définissons la structure et les relations de nos données – par exemple, quelles tables nous avons, et pour chaque table, quelles colonnes elles contiennent, et enfin les types de chaque colonne.
Ces informations sont très utiles lorsque vous effectuez des vérifications de type et détectez si l'utilisateur a écrit un nom de colonne incorrect, par exemple, qui n'est pas défini dans la table sélectionnée qu'il souhaite utiliser.
Dans notre cas, les tables peuvent être des classes, des structures, des énumérations, des fonctions, des variables et toute autre donnée pouvant être lue à partir de C++ comme des macros, etc. Mais j'ai décidé de commencer simplement avec les fonctions et les variables uniquement, puis j'ai prévu d'ajouter d'autres types.
Pour la table des fonctions, définissons les colonnes dont nous avons besoin. Les colonnes et les types ne sont pas difficiles à deviner, alors prenons une fonction normale comme exemple. Elle a un nom Text, et elle retourne un type Text, le nombre de paramètres en tant que Int, d'autres drapeaux C++ en tant que Booléens (par exemple, est-ce une fonction virtuelle is_virtual ou une fonction virtuelle pure is_pure_virtual ?), et un autre drapeau pour indiquer si c'est une fonction statique is_static.
Pour créer un schéma de données, vous devez définir deux choses : quelles tables vous avez, et quelles colonnes se trouvent dans cette table. Par exemple, dans la table des fonctions, cela ressemblera à ceci :
lazy_static! {
pub static ref TABLES_FIELDS_NAMES: HashMap<&'static str, Vec<&'static str>> = {
let mut map = HashMap::new();
map.insert(
"functions",
vec![
"name",
"signature",
"args_count",
"return_type",
"class_name",
"is_method",
"is_virtual",
"is_pure_virtual",
"is_static",
"is_const",
"has_template",
"access_modifier",
"is_variadic",
"file",
"line",
"column",
"offset",
],
);
}
}
Vous devez également définir le type de données attendu pour chaque colonne :
lazy_static! {
pub static ref TABLES_FIELDS_TYPES: HashMap<&'static str, DataType> = {
let mut map = HashMap::new();
map.insert("name", DataType::Text);
map.insert("type", DataType::Text);
map.insert("signature", DataType::Text);
map.insert("args_count", DataType::Integer);
map.insert("return_type", DataType::Text);
map.insert("class_name", DataType::Text);
map.insert("is_method", DataType::Boolean);
map.insert("is_virtual", DataType::Boolean);
map.insert("is_pure_virtual", DataType::Boolean);
map.insert("is_static", DataType::Boolean);
map.insert("is_const", DataType::Boolean);
map.insert("has_template", DataType::Boolean);
map.insert("access_modifier", DataType::Integer);
map.insert("is_variadic", DataType::Boolean);
map
};
}
Passons maintenant à la partie la plus excitante : le Data Provider.
Le Data Provider pour le code C/C++
Le composant Data Provider est utilisé pour indiquer au moteur comment charger les données cibles – par exemple, d'où et sur quel thread – et fournir ces données dans un format connu par notre moteur GitQL. Alors, comment pouvons-nous extraire ces informations de notre code C/C++ ?
Eh bien, nous devons obtenir l'AST après avoir analysé le code C/C++. La première option est donc d'écrire un analyseur C/C++ pour analyser les fichiers et fournir l'AST. Mais cette option pose quelques problèmes : elle nécessitera beaucoup de travail, car C++ est un langage vaste. Écrire un analyseur à partir de zéro signifie que vous devez supporter chaque nouvelle fonctionnalité, gérer les erreurs, etc.
L'autre option est de prendre un analyseur C/C++ bien écrit à partir de n'importe quel compilateur qui fournit l'analyseur en tant que bibliothèque et de l'utiliser pour fournir l'AST. Après quelques recherches, j'ai découvert que le compilateur Clang est bien conçu et peut fournir l'analyseur en tant que bibliothèque pour l'utiliser afin de construire d'autres outils tels qu'un formateur de code et un linter.
LibClang est écrit en C++, donc j'ai utilisé une liaison pour le langage de programmation Rust pour analyser le fichier source en tant que TranslationUnit. Il s'agit du nœud parent qui contient des informations sur les classes, les fonctions, etc.
LibClang fournit plus d'une façon de visiter la TranslationUnit et tous ses enfants. L'une d'elles consiste à utiliser la fonction clang_visitChildren. Elle prend un pointeur de fonction qui vous donne le nœud et son parent et retourne le drapeau en tant que int. En utilisant ce drapeau, vous pouvez contrôler si vous souhaitez interrompre, continuer ou parcourir ce nœud en utilisant le type de retour.
Par exemple, si vous visitez le nœud de classe ou de structure et souhaitez visiter les méthodes à l'intérieur, vous devez retourner CXChildVisit_Recurse – et clang_visitChildren vous fournira les méthodes. Mais si vous souhaitez simplement lire les informations de la classe, vous devez retourner CXChildVisit_Continue pour continuer vers d'autres nœuds. L'utilisation incorrecte de ces drapeaux peut entraîner des problèmes de performance et la visite de nombreux nœuds inutiles.
Pour obtenir les informations d'une fonction, nous devons appeler clang_visitChildren tout en passant un pointeur vers nos données pour sauvegarder les informations obtenues. Par exemple :
let mut functions: Vec<FunctionNode> = Vec::new();
let data = &mut functions as *mut Vec<FunctionNode> as *mut c_void;
let cursor = clang_getTranslationUnitCursor(translation_unit);
clang_visitChildren(cursor, visit_children, data);
Nous avons passé visit_children qui pointe vers la fonction qui extrait les informations des fonctions C/C++. Cela ressemblera à ceci :
extern "C" fn visit_children(
cursor: CXCursor,
parent: CXCursor,
data: *mut c_void,
) -> CXChildVisitResult {
let cursor_kind = clang_getCursorKind(cursor);
if cursor_kind == CXCursor_FunctionDecl
|| cursor_kind == CXCursor_CXXMethod
|| cursor_kind == CXCursor_FunctionTemplate
{
let function_name = clang_getCursorSpelling(cursor);
let function_type = clang_getCursorType(cursor);
let result_type = clang_getResultType(function_type);
let arguments_count = clang_getNumArgTypes(function_type);
// ... Extraction de plus d'informations
return CXChildVisit_Continue
}
CXChildVisit_Recurse
}
De plus, si vous souhaitez refactoriser ou construire des outils de recherche avancés sur ClangQL, vous devrez obtenir l'emplacement du code source. Par exemple, où exactement se trouve la fonction que vous recherchez – dans quel fichier et à quelle ligne ?
Pour les obtenir à partir de Clang, vous pouvez utiliser le code ci-dessous. Il fournit le nom du fichier, la ligne, la colonne et les données de décalage du nœud sélectionné :
let cursor_location = clang_getCursorLocation(cursor);
let mut file: CXFile = std::ptr::null_mut();
let mut line: u32 = 0;
let mut column: u32 = 0;
let mut offset: u32 = 0;
clang_getFileLocation(
cursor_location,
&mut file,
&mut line,
&mut column,
&mut offset,
);
let file_name = clang_getFileName(file);
let file_name_str = CStr::from_ptr(clang_getCString(file_name)).to_string_lossy();
Le code source de visit_children est trop long à inclure car, comme vous pouvez le voir, le nœud de fonction contient beaucoup d'informations. Vous pouvez donc consulter le code complet et mis à jour pour tous les visiteurs à partir de ce fichier dans le dépôt ClangQL : DataProviderFile.
Les créateurs de LibClang fournissent une documentation claire sur la manière de parcourir l'unité de traduction et d'extraire les données nécessaires.
Nous avons donc notre schéma de données et notre fournisseur de données, et nous pouvons effectuer une requête comme SELECT * FROM functions. Le résultat sera similaire à ceci :
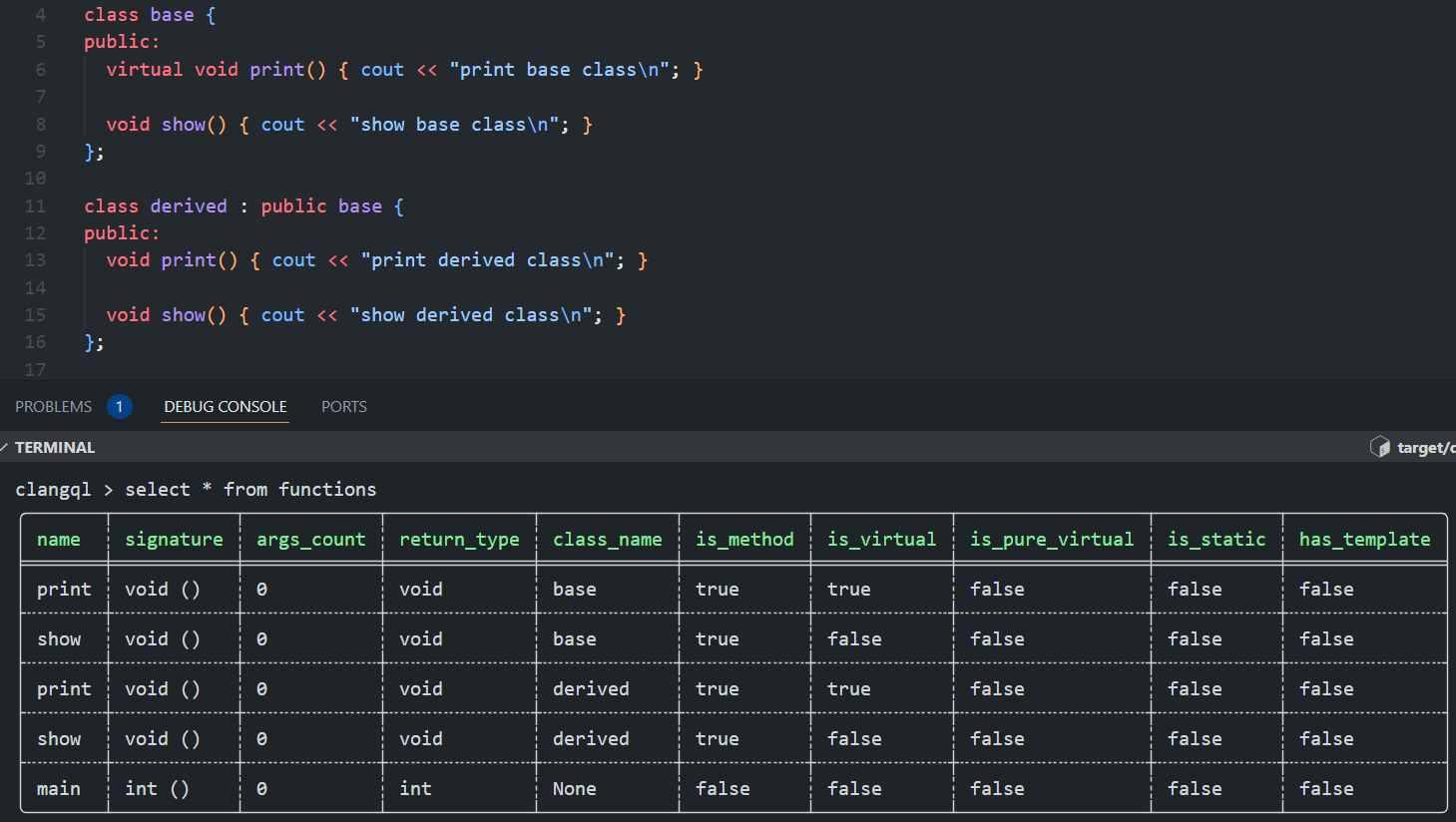
Le résultat de l'exécution d'une requête pour sélectionner toutes les informations de fonction d'un fichier
Après cela, j'ai décidé de nommer le projet ClangQL, qui signifie Clang Query Language. Je travaille maintenant à extraire de plus en plus d'informations importantes de l'AST (n'hésitez pas à contribuer).
Vous pouvez trouver le code source complet avec toutes les personnalisations dans le dépôt ClangQL.
Conclusion
Vous pouvez consulter le projet ClangQL en tant qu'exemple complet créé en seulement trois fichiers.
Si vous avez aimé le projet, vous pouvez lui donner une étoile ⭐ sur GitQL et ClangQL.
Vous pouvez consulter le site web pour savoir comment télécharger et utiliser le projet sur différents systèmes d'exploitation.
Le projet n'est pas encore terminé – ce n'est que le début. Tout le monde est le bienvenu pour rejoindre et contribuer au projet, suggérer des idées ou signaler des bugs.
Vous pouvez sponsoriser mon travail sur GitHub ❤️.
Merci d'avoir lu.