


Article original : How to Run SQL-Like Queries on Files
Bonjour à tous ! Je suis un ingénieur logiciel intéressé par la programmation de bas niveau, les compilateurs et le développement d'outils.
À la fin de l'année 2023, j'ai publié mon premier article sur freeCodeCamp sur la façon dont j'ai créé un langage de type SQL pour exécuter des requêtes sur des dépôts Git locaux. Si vous souhaitez un peu plus de contexte, lisez-le.
Au début de 2024, le projet a grandi avec plus de fonctionnalités et des contributeurs incroyables, et j'ai commencé à penser : et si je pouvais exécuter des requêtes de type SQL non seulement sur des fichiers .git mais sur tout type de données locales et distantes ?
Dans cet article, je vais vous emmener dans un voyage de mise à jour de la conception du projet GitQL pour qu'il soit également utilisé comme un SDK. Je vais également expliquer comment je l'ai utilisé pour implémenter le projet FileQL, qui est un outil pour exécuter des requêtes de type SQL sur des fichiers locaux.
Le premier cas d'utilisation pour cette idée
Ma première idée était de pouvoir utiliser les mêmes fonctionnalités de GitQL pour construire FileQL, qui est un outil permettant d'exécuter des requêtes sur un système de fichiers local.
Par la suite, tout le monde peut utiliser le projet GitQL comme un SDK pour construire leur propre XQL. Par exemple, LogQL, WeatherQL, CodeQL, AudioQL, BookQL, et ainsi de suite.
Comment j'ai commencé à penser au SDK GitQL
La première question était : quelle peut être la différence entre GitQL et FileQL ? Cette partie pourrait être dynamique en fonction du format des données et de la manière de les lire.
La réponse était deux composants. Passons-les en revue dans les sections suivantes.
Le premier composant est le schéma de données
Dans chaque requête de type SQL, nous devons effectuer certaines vérifications pour nous assurer que tout est valide. Par exemple, dans une requête comme SELECT UPPER(name), commit_count + 1 FROM branches, nous devons effectuer les vérifications suivantes :
Vérifier qu'il existe une table avec le nom branches.
Le champ
namea le type texte afin qu'il puisse être passé à la fonctionUPPERsans aucun problème.Le champ
commit_counta le type entier, afin que nous puissions l'utiliser avec l'opérateur plus et un autre entier.
Ces vérifications peuvent être implémentées si nous connaissons les noms des tables, les noms des champs et les types. Ces informations étaient statiques dans le projet GitQL, mais maintenant, lorsque je veux le convertir en un SDK, je dois le rendre dynamique afin que tout utilisateur du SDK puisse le modifier en fonction de ses propres données.
J'ai donc encapsulé toutes les informations nécessaires dans un composant appelé DataSchema, et une fois que l'utilisateur le passe au SDK, toutes les vérifications fonctionneront correctement.
Le deuxième composant est le fournisseur de données
Une fois que nous avons défini le composant DataSchema pour faciliter les vérifications des données, nous devons passer à la question suivante : comment pouvons-nous fournir les données au moteur GitQL ?
Dans GitQL, nous avons des fonctions statiques pour fournir les données à partir des fichiers .git, mais dans le SDK, nous ne travaillons pas seulement avec des fichiers .git, et nous devons supporter le travail avec tout type de données.
L'idée est donc de définir une interface entre le moteur GitQL et l'utilisateur du SDK pour fournir tout type de données dans le format nécessaire pour le moteur. Ce composant est appelé DataProvider, et j'expliquerai les détails d'implémentation dans la section suivante.
La conception et l'implémentation du SDK GitQL
L'objectif est de permettre à l'utilisateur du SDK de passer sa propre définition de Data Schema et Provider et de les intégrer facilement avec les autres composants GitQL tels que Tokenizer, Parser, Checker, Functions et Engine.
Comment concevoir le schéma de données
Le schéma de données doit contenir deux types d'informations. Premièrement, il doit définir les noms corrects des tables et des champs, et deuxièmement, il doit spécifier les types de données pour ces champs.
Par exemple, dans le cas de FileQL, les noms corrects des tables et des champs sont :
pub static ref TABLES_FIELDS_NAMES: HashMap<&'static str, Vec<&'static str>> = {
let mut map = HashMap::new();
map.insert(
"files",
vec!["path", "parent", "extension", "is_dir", "is_file", "size"],
);
map
};
Ici, nous définissons une seule table appelée files, qui a six champs : path, parent, extension, is_dir, is_file et size.
Dans l'autre map, nous définissons le type de données correct pour chaque champ. Par exemple :
pub static ref TABLES_FIELDS_TYPES: HashMap<&'static str, DataType> = {
let mut map = HashMap::new();
map.insert("path", DataType::Text);
map.insert("parent", DataType::Text);
map.insert("extension", DataType::Text);
map.insert("is_dir", DataType::Boolean);
map.insert("is_file", DataType::Boolean);
map.insert("size", DataType::Integer);
map
};
Ensuite, nous créons une instance de Schema, et nous la construisons en utilisant les deux maps. Elle doit les passer à la liste d'instances de Data Schema comme ceci :
let schema = Schema {
tables_fields_names: TABLES_FIELDS_NAMES.to_owned(),
tables_fields_types: TABLES_FIELDS_TYPES.to_owned(),
};
Comment concevoir le fournisseur de données
L'objectif du composant Data Provider est de charger les données et de les mapper dans la structure d'objet du moteur GitQL, nous pouvons donc le définir comme une interface avec une seule fonction :
pub trait DataProvider {
fn provide(
&self,
env: &mut Environment,
table: &str,
fields_names: &[String],
titles: &[String],
fields_values: &[Box<dyn Expression>],
) -> GitQLObject;
}
L'utilisateur du SDK peut implémenter cette interface pour son propre type de données et la faire fonctionner avec différentes données.
Vous pouvez également contrôler le nombre de threads dont vous avez besoin et les paramètres supplémentaires que vous souhaitez. Par exemple, dans FileQL, je l'ai implémenté avec le nom FileDataProvider, et j'ai passé le chemin de base à rechercher comme paramètre.
Vous pouvez également l'implémenter de n'importe quelle manière. Par exemple, APIDataprovider, et charger les données depuis un serveur et les mapper dans GitQLObject. Vous pourriez également l'implémenter en tant que LogDataProvider, et ainsi de suite. L'idée principale est la même : fournir simplement les données au moteur.
Comment utiliser les composants du SDK ensemble
Le SDK GitQL a quatre composants principaux, et chacun peut être utilisé pour de nombreux objectifs. Cependant, tous peuvent être utilisés et intégrés facilement les uns avec les autres pour exécuter la requête de type SQL sur vos données.
Tout d'abord, il y a le composant GitQL CLI, qui contient les fonctions requises pour gérer l'interface de ligne de commande, telles que l'analyseur d'arguments, le rapporteur de diagnostics et le rendu de tableau.
Ensuite, il y a le composant GitQL AST. Ce composant contient les structures requises pour le SDK, telles que les nœuds AST, les fonctions, le schéma, les types de données et les valeurs.
Il y a également le composant GitQL Parser, qui est utilisé pour effectuer l'analyse lexicale, syntaxique et sémantique de la requête. Il prend la requête de type SQL sous forme de chaîne. Si tout est correct, il retourne un nœud AST. Sinon, il retourne un message d'erreur de compilation sous forme de chaîne.
Enfin, il y a le composant GitQL Engine. Le composant Engine contient l'Engine et le DataProvider, il prend donc votre implémentation du DataProvider et l'AST et évalue chaque nœud sur les données. À la fin, il retourne les données sous forme de résultat ou une erreur d'exécution sous forme de chaîne.
Après avoir ajouté les crates GitQL SDK à votre projet et configuré le Data Schema et le Provider pour vos données, nous pouvons commencer à utiliser le SDK GitQL :
let mut env = Environment::new(schema);
let query = ...;
let mut reporter = DiagnosticReporter::default();
let tokenizer_result = tokenizer::tokenize(query.to_owned());
let tokens = tokenizer_result.ok().unwrap();
if tokens.is_empty() {
return;
}
let parser_result = parser::parse_gql(tokens, &mut env);
if parser_result.is_err() {
let diagnostic = parser_result.err().unwrap();
reporter.report_diagnostic(&query, *diagnostic);
return;
}
let query_node = parser_result.ok().unwrap();
let provider: Box<dyn DataProvider> = Box::new(FileDataProvider::new(base_path.to_owned()));
let evaluation_result = engine::evaluate(&mut env, &provider, query_node);
Le code ci-dessus prend la requête sous forme de chaîne et la traite jusqu'à obtenir le résultat de l'évaluation du moteur :
Créer une instance d'Environment en utilisant le
DataSchemapour suivre les types.Créer une instance de
DiagnosticEnginepour l'utiliser pour le rapport d'erreurs.Passer la requête au tokenizer pour convertir la chaîne en une liste de tokens.
Passer la liste de tokens au parser pour la convertir en
TreeDataStructure.Créer une instance de votre
DataProvideret la passer avec l'arbre au moteur.Le moteur retourne le résultat de l'évaluation qui est une erreur ou des données.
Ces composants ne sont pas nouveaux du tout, à part Data Schema et Provider, et vous pouvez profiter de la lecture sur les détails de conception et d'implémentation dans le premier article.
C'est presque tout ce dont vous avez besoin pour faire fonctionner le projet, mais vous pouvez ajouter plus de personnalisation et de composants supplémentaires, tels que des arguments CLI. Le résultat final sera comme ceci :
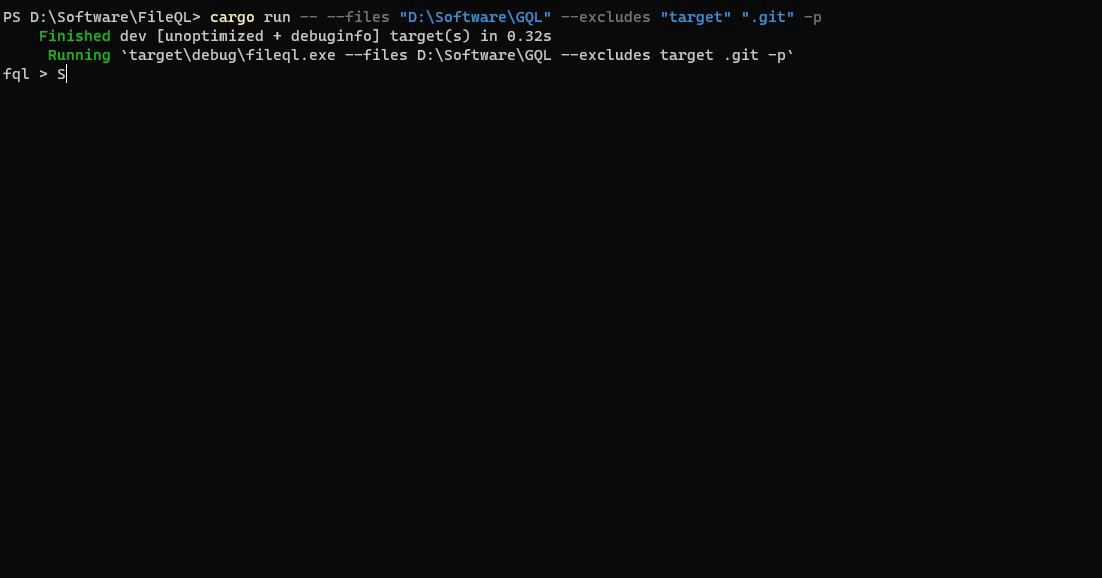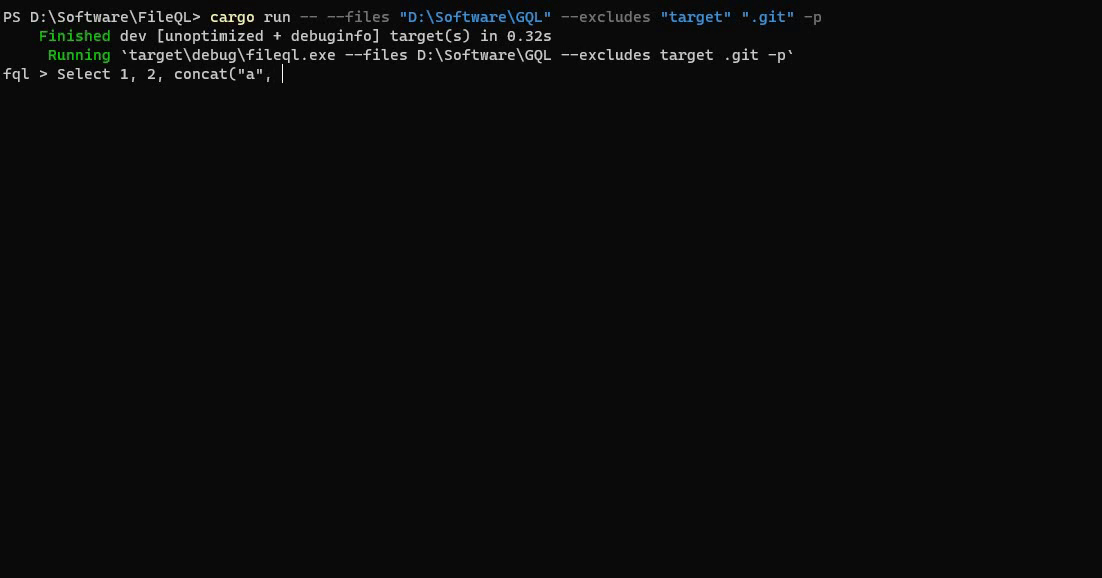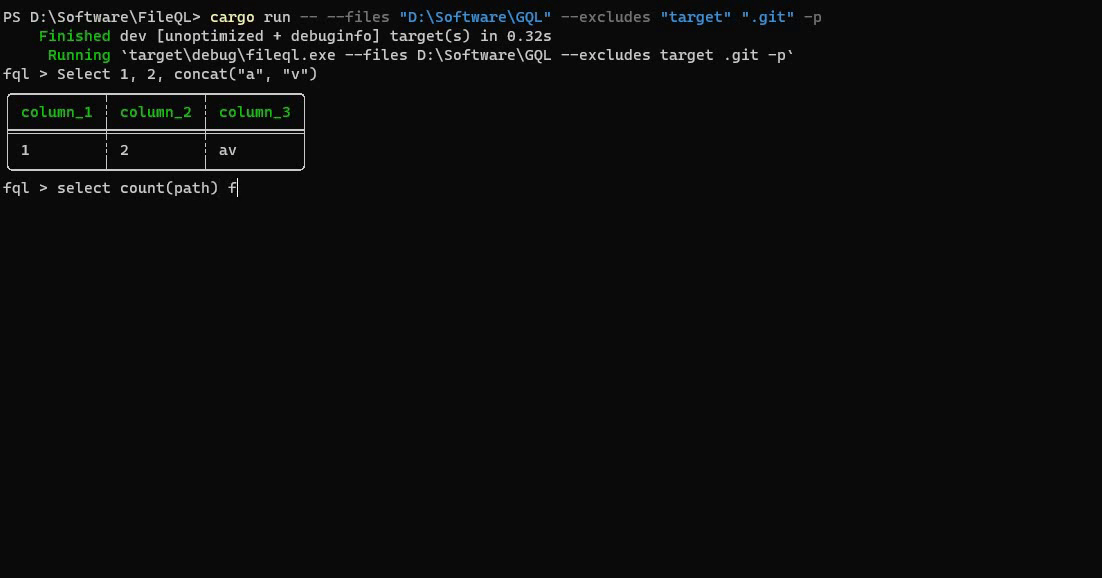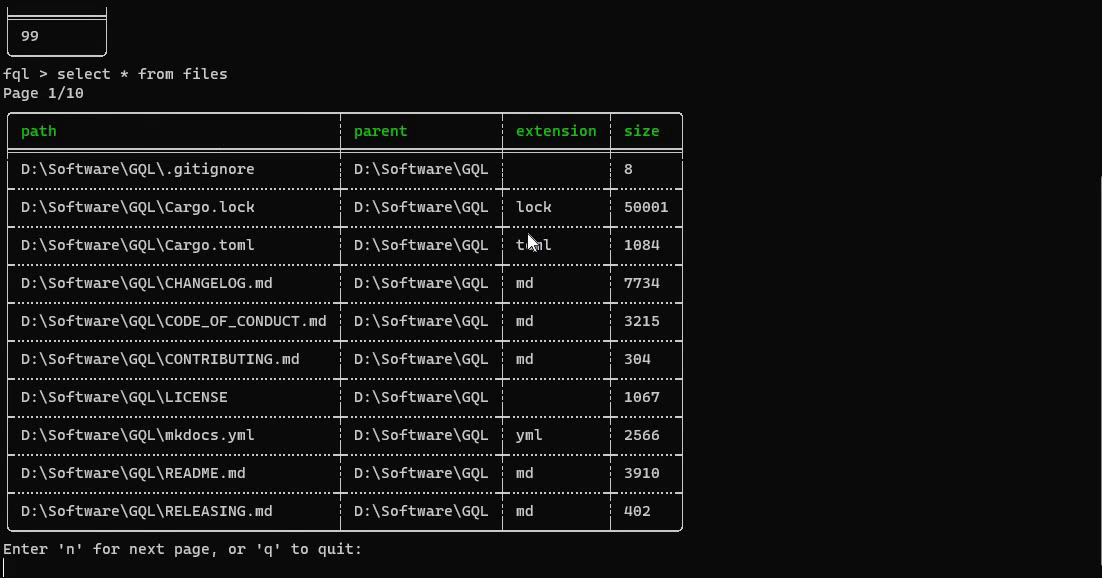
Démonstration du projet FileQL en cours d'exécution sur des fichiers locaux
Vous pouvez trouver le code source complet avec toutes les personnalisations dans le dépôt FileQL.
Conclusion
Vous pouvez vérifier le projet FileQL comme un exemple complet créé en seulement trois fichiers.
Si vous avez aimé le projet, vous pouvez lui donner une étoile ⭐ sur GitQL et FileQL
Vous pouvez consulter le site web pour savoir comment télécharger et utiliser le projet sur différents systèmes d'exploitation.
Le projet n'est pas encore terminé – ce n'est que le début. Tout le monde est le bienvenu pour rejoindre et contribuer au projet et suggérer des idées ou signaler des bugs.
Merci d'avoir lu !